融入歷史信息的多輪對話意圖識別
2023-07-13 09:12:04孟佳娜孫世昶姜笑君劉玉寧馬騰飛
大連民族大學學報 2023年3期
孟佳娜,單 明,孫世昶,姜笑君,劉玉寧,馬騰飛
(大連民族大學 a.計算機科學與工程學院;b.文法學院,遼寧 大連 116650)
近年來社交網絡發展迅速,海量數據推動著人機對話系統不斷的發展,促進了數據驅動的開放領域對話系統的研究[1]。如今,任務型人機對話系統[2]已經在生活中被廣泛的應用。但是在任務型人機對話系統研究歷程中,大多數的研究都是針對單輪對話開展的,并且意圖分類和語義槽填充單獨處理語句,傳統任務型對話面臨新的挑戰。
Sarikaya等[3]提出基于卷積神經網絡的聯合模型用于意圖識別和語義槽填充兩個任務。Tur等[4]使用了一種聯合模型,通過遞歸神經網絡將離散的語法結構和連續空間的單詞和短語表示合并到一個強大的合成模型中,用于執行人機對話系統中的NLU任務。Zhang等[5]提出了基于膠囊的神經網絡模型,通過動態路由協議模式進行聯合建模,從而使用推斷的意圖表示進一步協同插槽填充提高模型性能。通常訓練詞向量的方法都是使用 Word2Vec,但是Word2Vec主要是從詞義的分布式假設出發,最終得到相應的向量,其弊端就是它是靜態的,無法聯系上下文并且該技術不能從根本上解決一詞多義的問題。
針對上述問題,本文從聯合建模、引入歷史信息和預訓練模型微調三個方面對自然語言理解任務進行研究。實驗結果表明,通過使用提出的基于多任務學習的聯合模型和微調預訓練模型的方式,可以提升意圖識別和語義槽填充任務的效果。
1 相關工作
1.1 預訓練模型
BERT是用來處理詞向量的工具,2018年谷歌公司發布了全新的預訓練模型BERT,在各大自然語言處理的比賽中脫穎而出。在BERT[6](Bidirectional Encoder Representations from Transformers)誕生之前,通常都是使用Word2Vec訓練詞向量,但是Word2Vec所具有的泛化能力使其包含了某一個詞的全部含義,因此分布式的表示方法只能夠把兩種含義編碼成一種向量,無法很好地解決一詞多義的問題,這也是詞向量目前存在的問題。
而BERT的提出恰好解決了這一問題,通過尋找詞與詞之間的特征更好地表達句子的完整語義。BERT采用無監督學習的方式使用Transformer模型的Encoder部分,同時也沿用了Transformer模型的多頭注意力機制,使得BERT能夠在訓練的過程中能夠聯系上下文,解決一詞多義的問題。BERT模型圖如圖1。
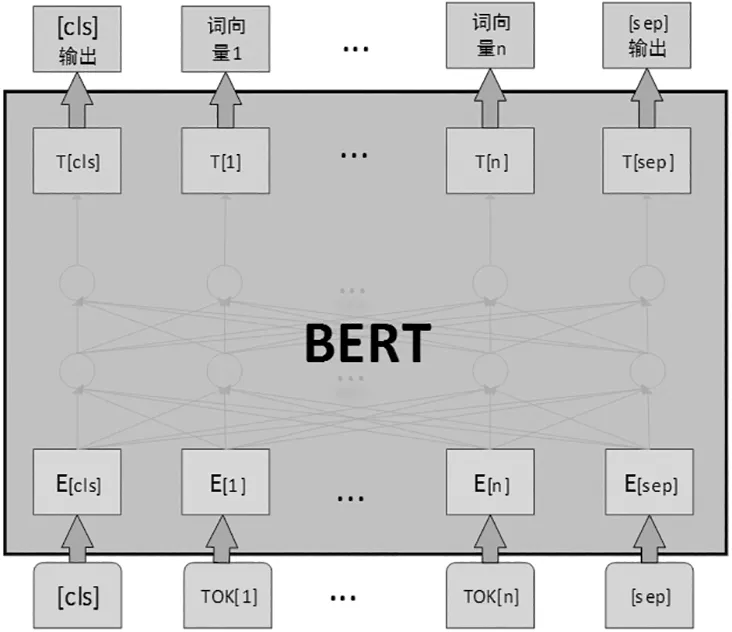
圖1 BERT模型圖
1.2 融入多輪對話
為了使得模型能夠聯系上下文,循環神經網絡(Recurrent Neural Network, RNN)[7]應運而生。同時RNN的出現也很好的解決了全連接神經網絡的弊端。但是在處理長句子時RNN容易丟失記憶信息,導致模型性能表現不佳。長短期記憶網絡(Long Short-Term Memory, LSTM)[8]的提出很好的解決了這些問題,LSTM實際上是RNN的一種變體,其實質是將RNN的隱藏層變換成了一個長短期記憶的模塊,能有效解決長距離的依賴問題。Chuang等[9]通過比較了不同類型的RNN,在音樂建模和語音信號建模的任務上評估這些循環單元,證明了長短期記憶網絡比傳統的循環單元效果要好。
2 本文方法
本文提出基于多任務學習的多輪對話語言理解聯合模型,該聯合模型的兩個任務分別是意圖識別和語義槽填充。代表當前輪次的對話預測,歷史輪次的對話用到表示。同時模型的設計中添加LSTM模塊來引入歷史信息,其中LSTM1代表第一輪輸入的句子訓練時使用的歷史信息編碼器,LSTMt代表當前輪次LSTM的歷史編碼器模塊,此時的LSTM已經融入了1到t-1輪次的對話歷史信息。
2.1 基于預訓練模型的語義編碼器
本文分別使用BERT和RoBERTa作為多輪對話的語義編碼器,以使用BERT模型作為語義編碼器為例,對于多輪對話任務一共有T輪次的對話,輸入每輪對話的文本M=(m1,m2,...,mn)首先送進BERT訓練其語義表示,計算之后合成ut,ut代表輸入文本中[CLS]位置,最后完成對輸入文本的分類,計算過程如下公式。
Xt=BERT(mt,1,mt,2,…mt,n)=(ut,xt,1,xt,2,…xt,n)。
(1)
式中:ut代表第t輪對話BERT輸出的[CLS]隱狀態向量;xt,n表示第t輪次對話的第n個詞所對應的向量表示。
2.2 進一步預訓練
在多任務聯合模型基礎上,將預訓練模型進行進一步訓練,使得預訓練模型更適應此任務型人機對話任務,提升模型的性能。通過采用三階段模式進行進一步預訓練,選用預訓練好的BERT和RoBERTa,然后用相關的小數據進一步訓練,保留訓練后的權重,再對模型進行微調得到更好的性能如圖2。

圖2 預訓練模型進一步預訓練的方法圖
2.3 引入歷史信息的編碼器
2.3.1 LSTM模型
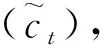
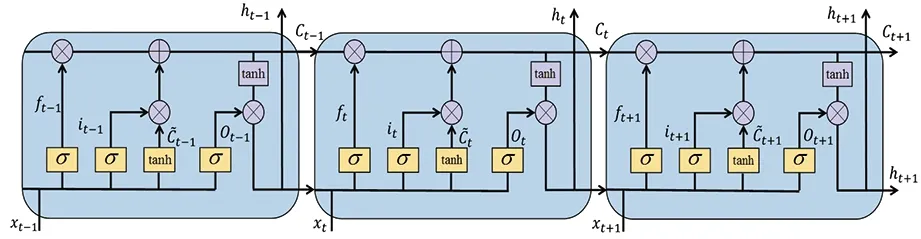
圖3 LSTM模型
計算過程如下公式:
輸入門:it=σ(wi·[ht-1,ut]+bi),
(2)
遺忘門:ft=σ(wf·[ht-1,ut]+bf),
(3)

(4)
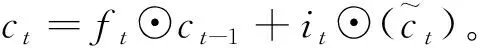
(5)
最后根據細胞的狀態得到輸出門輸出當前值ht,如式:
ht=ot⊙tanh(ct)。
(6)
2.3.2 意圖識別和語義槽填充解碼器
通過全連接層映射標簽,最后通過softmax得到意圖標簽yI如式。
ytI=softmax(WIht+bI)(t∈1,2,…T)。
(7)
由于本文任務是多輪對話,其中模型中的第n次slot輸出狀態就是指當前輪次的輸出狀態。因此直接將除CLS和SEP的當前輪次的輸出狀態通過全連接層將其映射到標簽集合,然后通過softmax層對每個詞處理后,得到每個維度的數值就是這個詞的標簽概率,從而得出每個詞相應的標簽所屬的類別。將每一輪次的文本的長度設置為n,WS是語義槽任務的權重矩陣,bS是語義槽填充部分的偏置項,xt,i是經過BERT處理后代表當前輪次的第i個文本向量輸入到softmax層。公式如下:
(8)
2.4 基于多任務學習聯合訓練
本模型采用多任務學習的方法,聯合訓練意圖識別和語義槽填充任務,通過使用交叉熵函數作為損失函數,其中Number代表樣本的數量,類別的數量為ClassNumber,pik代表對樣本i預測為k的概率,yik代表當k和樣本i是相同的種類時,其值是1,其他的均為0。
(9)
由于意圖識別和語義槽填充這兩個任務有很明顯的聯系,在實際的訓練當中LossI,LossS分別代表意圖識別和語義槽填充的損失,LossJ代表整個聯合模型的整體損失。
(10)
聯合模型最終訓練目標損失函數如下所式:
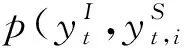
(11)
2.5 微調聯合模型
2.5.1 Lookhead優化器
想要在神經網絡中獲得更好的性能,往往需要代價高昂的超參數調節。使用Lookahead[10]可以改進內部優化器的收斂性,并經常提高泛化性能,同時對超參數變化魯棒性很好,實驗證明,Lookahead對內循環優化器的變化,快速權值更新的次數和慢的權重學習速率具有很強的魯棒性,因此本文選用Lookahead提升模型的性能。
2.5.2 自蒸餾微調策略
為了提升BERT的自適應能力,提出了自蒸餾微調策略[11],進一步對BERT的微調進行了改進。自蒸餾主要是采用了監督學習的方式去進行知識蒸餾。自蒸餾主要是采用了監督學習的方式去進行知識蒸餾。本文選用了SDA (Self-Distillation-Averaged)[12]的方法如圖4。先計算出過去K個time step參數的平均值作為教師模型,進一步提升了模型的性能。
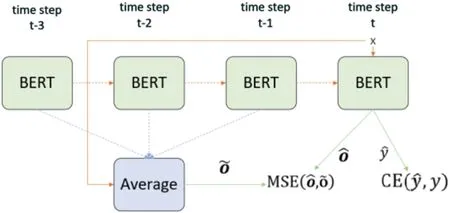
圖4 SDA微調的策略圖
2.5.3 對抗訓練
對抗訓練(adversarial training)是增強神經網絡魯棒性一種的重要方式[13]。在自然語言處理領域中,在語言模型中使用對抗訓練,既提高了魯棒性同時也提高了泛化能力。對抗訓練的一般性原理其公式可以概括為如下的最大最小化公式:
(12)
實際上,對抗訓練的研究基本上就是在尋找合適的擾動,使得模型具有更強的魯棒性。FGM(Fast Gradient Method)[14]采用了L2歸一化的方法。其核心思想就是通過利用梯度的每個維度的值除以梯度的L2范數,保留梯度的方向可以使訓練后模型的效果更好。FGM的公式如下:
(13)
式中,g代表損失函數L輸入x的梯度,公式如下:
g=▽xL(θ,x,y)。
(14)
3 實驗結果與分析
3.1 數據集
本文選用三個數據量依次遞增的數據集,分別是KVRETA[15]、MultiWOZ[16]、DSTC8[17]。KVRET數據集是斯坦福自然語言處理小組收集的。斯坦福自然語言處理小組發布的這個數據集里面包含了3031段任務型多輪對話的數據,主要里面包含了導航類,日程安排類和天氣搜索類。MultiWOZ采用的2.2版本的數據集,MultiWOZ一個大型多領域用于特定任務對話模型的人機對話實驗數據集。該語料庫由Attraction、Hospital、Police、Hotel、Restaurant、Taxi、Bus和Train這8個領域組成。DSTC8是2019年第八屆對話系統挑戰賽發布的數據集,對話系統挑戰賽DSTC由微軟、卡內基梅隆大學的科學家于2013年發起。實驗所使用的數據集的具體描述見表1。
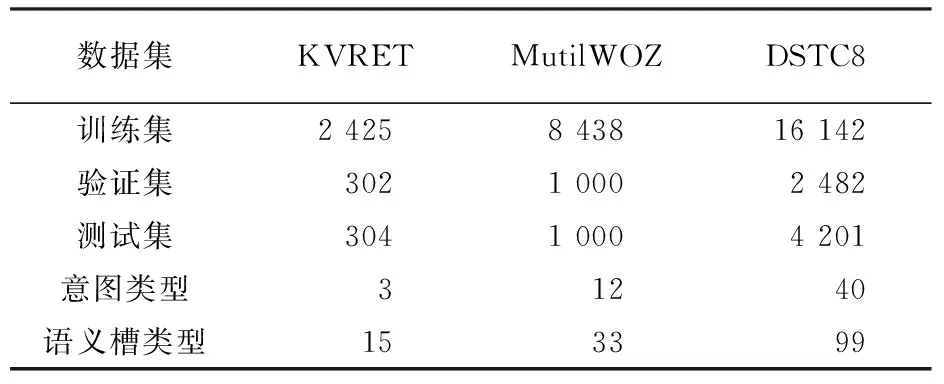
表1 KVRET、MultiWOZ和DSTC8數據集統計
3.2 實驗結果與分析
3.2.1 基線模型
SDEN[18]:模型通過使用記憶網絡的方法,把記憶后的編碼存儲,通過順序對話編碼網絡,允許按時間順序從對話歷史中編碼上下文,在多域對話數據集上的實驗表明,該結構降低了語義幀錯誤率。
MNMDLJ[19]: 提出了一種新的對話邏輯推理(DLI)任務,該任務在多任務框架下與SLU共同鞏固上下文記憶, 采用聯合學習的方法進行訓練。
CDS[20]:提出了模型采用基于方法的語義組合機制。
Joint BERT:基線模型,采用基于BERT意圖分類和語義槽填充的聯合學習模型。
Joint RoBERTa:將基線模型中的BERT模型換為RoBERTa意圖分類和語義槽填充的聯合學習模型。
Joint BERT+LSTM:本文提出的實驗模型。
Joint RoBERTa+LSTM:在本文Joint BERT-LSTM模型基礎上,將BERT換成RoBERTa模型。
本文模型基于Joint BERT再加入LSTM后,引入歷史信息之后意圖分類的準確率達到99.9%,本文的模型捕捉詞語中的隱藏依賴關系,提升意圖識別的表現,意圖識別表現的提升意味著模型對于意圖識別的困惑度降低,使該部分的訓練的效率更高,同時由于本文的模型是聯合建模,BERT的訓練效率的提高也就提升了槽填充的表現。在KVRET數據集上的實驗的結果見表2。

表2 KVRET數據集中的實驗結果 %
3.2.2 實驗結果分析
在實驗的訓練過程中,以KVRET數據集和MultiWOZ數據集為例,對比Joint BERT+LSTM、Joint RoBERTa+LSTM、Joint BERT和Joint RoBERTa這四種模型的變化過程。KVRET數據集中Joint RoBERTa+LSTM模型收斂的更快,雖然意圖分類的準確率略低于Joint BERT+LSTM模型,但是語義槽填充的F1值更高,整體來看Joint RoBERTa+LSTM模型在KVRET數據集上的效果更好。在KVRET數據集當中,其loss下降的變化圖如圖5,意圖準確率和語義槽填充的F1值如圖6。
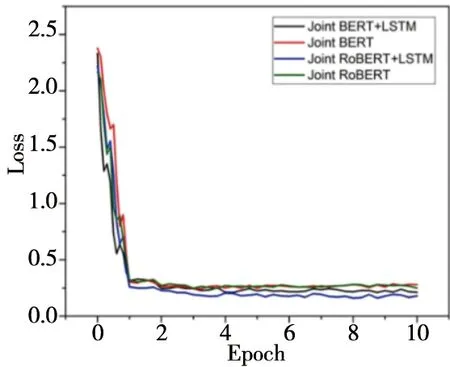
圖5 KVRET數據集loss變化圖
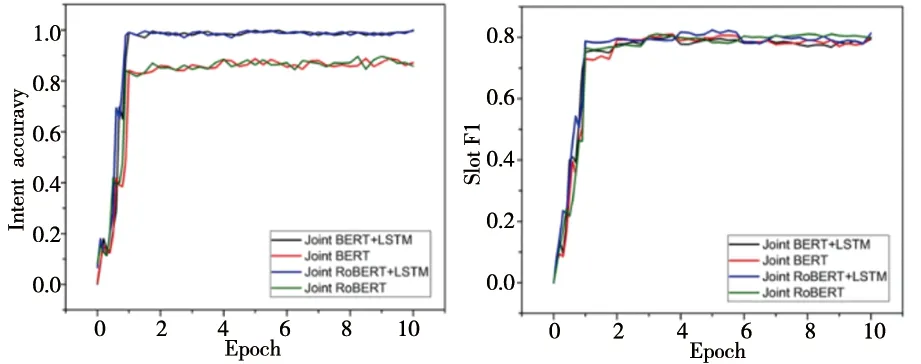
a)Intent準確率變化圖 b)Slot F1值變化圖圖6 KVRET數據集意圖準確率和語義槽填充變化圖
在MultiWOZ數據集當中,其loss下降的變化圖如圖7。意圖準確率和語義槽填充的F1值分別如圖8。Joint BERT+LSTM模型收斂的更快,并且意圖分類的準確率和語義槽填充的F1值最高,因此Joint BERT+LSTM模型在MultiWOZ數據集上效果更好。
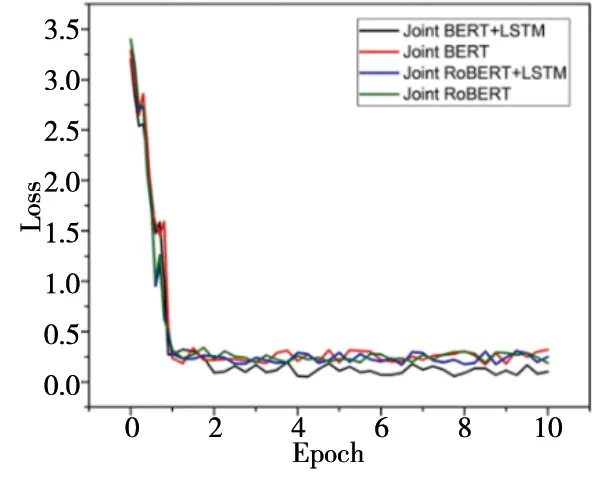
圖7 MultiWOZ數據集的loss變化圖

a)Intent準確率變化圖 b)Slot F1值變化圖圖8 MultiWOZ數據集意圖準確率和語義槽填充變化圖
綜合以上兩個數據集的訓練變化圖中可知,在模型引入LSTM之后,模型的在訓練時收斂的更快,模型的性能也有了大幅的提升。
在這兩個數據集上實驗的結果見表3,由于KVRET多輪對話中的數據較少,為了證明模型應用在其他任務上仍然有效果,本文也選用了數據量較大的數據集,分別是超10 000段對話的跨越8個域的帶注釋對話數據集MultiWOZ和超16 000段對話覆蓋16個領域的數據集DSTC8。可以看出使用相同預訓練模型加入LSTM融入歷史信息之后,意圖識別的準確率都大幅提高,語義槽的F1值也有略微提升。
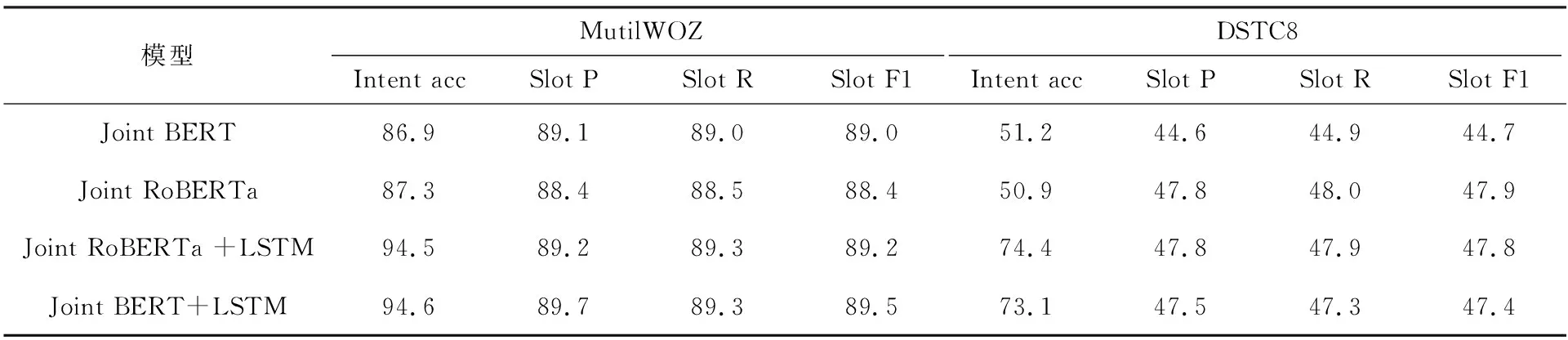
表3 MultiWOZ和DSTC8中的實驗結果 %
綜上所述,在引入了LSTM對多輪對話的歷史信息進行建模,并對意圖分類和語義槽填充任務進行聯合建模后,無論是使用BERT和RoBERTa其模型性能都有所提升,同時也證明了引入歷史信息的預訓練聯合模型具有較強泛化能力。
4 結 論
提出了一種基于預訓練模型的多輪對話自然語言理解聯合建模的方法,將BERT和RoBERTa作為語義編碼器對意圖分類和語義槽填充進行聯合建模,通過多任務學習共享特征的特性,聯合建模可以提升兩個任務的效果。同時本文加入BERT到多輪對話上,引入LSTM用歷史信息進行多輪對話語言理解任務的聯合建模,輔助意圖識別任務,在大幅度提高意圖識別準確率的同時,提高了槽填充任務的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
核科學與工程(2015年4期)2015-09-26 11:59:03
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
