基于平均模型和誤差削減網絡的語聲轉換系統?
2023-07-13 12:20:14王媛媛王新宇張明陽
應用聲學 2023年3期
王媛媛 王新宇 張明陽 周 鋒 趙 力
(1 鹽城工學院信息工程學院 鹽城 224051)
(2 新加坡國立大學電子與計算機工程系 新加坡 117583)
(3 東南大學信息科學與工程學院 南京 210096)
0 引言
語聲轉換是一種修改源說話人的語聲,使其聽起來像目標說話人的技術。語聲轉換技術已被成功應用于許多領域中,如文本到語聲系統(Textto-Speech,TTS)[1]、說話人去識別化[2]和言語輔助[3]。
語聲轉換可以被描述為估計源特征和目標特征之間映射函數的回歸問題。研究者們已經提出了許多成功的語聲轉換方法,如高斯混合模型的方法[4?5],它是基于頻譜參數軌跡的最大似然估計。動態內核偏最小二乘法[6]將內核變換集成到偏最小二乘法中,以對非線性轉換關系進行建模以及捕捉數據中的動態特性。稀疏表示方法[7?8]可以看作是一種數據驅動的非參數化方法,作為傳統的參數化語聲轉換方法的替代。基于頻率彎曲的方法[9?10]旨在改變源頻譜的頻率軸,使其接近目標頻譜。此外,還有一些語聲轉換的后置濾波器方法來提高語聲質量[11]。
近年來,深度學習方法在語聲轉換領域開始流行。例如,基于深度神經網絡(Deep neural network,DNN)的方法[12?14]研究了平行訓練數據條件下的頻譜轉換,通過使用大量的平行訓練數據來實現高質量的語聲轉換。此外,關于變分自動編碼器方法的研究[15],有效提高了語聲轉換的性能。
上述語聲轉換框架將每幀的頻譜特征視為獨立的特征,并不關注語聲序列所特有的長時依賴性。標準的遞歸神經網絡(Recurrent neural network,RNN)可以用來解決這個問題[16?17],但由于RNN存在梯度消失的問題[18],限制了其在上下文信息建模方面的能力。此外,標準的RNN 只能捕獲前向序列的信息,而忽略了后向序列的信息。
為了解決RNN 的這些問題,研究者們提出了深度雙向長短時記憶(Deep bidirectional long short-term memory,DBLSTM)的方法來進行語聲轉換[19?20],與傳統的基于DNN 的語聲轉換框架相比,DBLSTM 的應用獲得了顯著的性能提升[19]。CBHG(1-D convolution bank+highway network+bidirectional gated recurrent unit(GRU)) module 最早出現于一個端到端的語聲合成系統Tacotron 中[21],它由一組一維卷積濾波器、高速公路網絡和一個雙向門控循環單元(Bidirectional gated recurrent unit,BiGRU)組成。CBHG網絡可以更好地對序列數據處理,提取序列信息。
雖然這些基于深度學習的語聲轉換框架可以實現很好的語聲轉換性能,但仍然存在對大量訓練數據的依賴性問題。而對于語聲轉換任務來說,在實際應用時大量數據通常是很難獲取的,只能采用有限的數據。剩下的問題就是如何找到一種方法,使有限的數據得到很好的利用。與以往的研究不同,本文利用CBHG 這一強大的深度學習框架,提出了一種在有限的平行數據條件下能夠產生高質量語聲的語聲轉換框架。具體來說,本文做出了以下貢獻:(1) 由于CBHG 網絡可以通過對語聲語句的長時依賴性進行建模來實現高性能的語聲轉換,本文利用多說話人的數據建立了一個基于CBHG的平均模型。(2) 由于基于CBHG 的平均模型可以很容易地用少量數據進行自適應,本文利用有限的目標數據對基于CBHG 的平均模型進行自適應訓練,以實現轉換后的聲音接近于目標聲音。(3) 誤差削減網絡只需要用少量的源和目標的平行訓練數據進行訓練,所以本文提出了一個應用于自適應的CBHG 網絡的誤差削減網絡,可以進一步提高語聲轉換質量。總的來說,本文提出了一種基于平均模型和誤差削減網絡的語聲轉換框架,可以用少量的訓練數據產生高質量的語聲。
1 基于CBHG網絡的語聲轉換
CBHG 網絡用于更好地從序列數據中提取上下文信息,模型結構如圖1 所示。輸入序列首先與K個一維卷積濾波器進行卷積,其中第k個卷積濾波器的卷積寬度為k(k=1,2,···,K)。這些濾波器顯式地對局部信息和上下文信息進行建模(類似于對一元、二元,直到K元信息進行建模)。卷積輸出堆疊在一起,并在時間軸上進行最大池化處理,以增加局部穩定性。所有的卷積濾波器步長均設為1,以用于保留原始的時間分辨率。濾波器處理后的序列進一步傳遞給幾個固定寬度的一維卷積,其輸出通過殘差連接與原始序列相加。同時將批歸一化操作應用于所有的卷積層。接著,卷積輸出被送入一個多層的高速公路網絡,以提取高層次的特征。最后,序列經過了一個雙向門控循環單元,以從前向和后向上下文中提取序列特征。
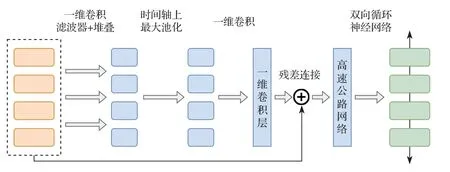
圖1 CBHG 網絡模型結構Fig.1 Model architecture of CBHG network
基于CBHG網絡的語聲轉換的整體框架如圖2所示。在這個模型框架中,對包括頻譜特征、logF0和非周期分量(Aperiodicity,AP)在內的3 個特征流分別進行轉換。頻譜特征由CBHG 模型進行轉換,基頻轉換通過將源說話人logF0的平均數和標準差歸一化為目標說話者的平均數和標準差進行線性轉換,AP 分量則是直接從源特征中復制而不進行轉換。模型將整個語句的特征作為輸入,使系統可以從前向和后向序列中獲取長程上下文信息。本文中所提出的方法是在有限的訓練數據條件下,利用CBHG模型進行語聲轉換。
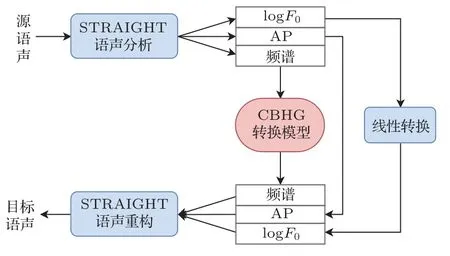
圖2 基于CBHG 網絡的語聲轉換系統Fig.2 Voice conversion system based on CBHG network
2 基于平均模型和誤差削減網絡的語聲轉換
雖然第1 節所描述的基于CBHG 網絡的語聲轉換具有很好的性能,但是需要同時收集大量的來自源說話人和目標說話人的平行數據,在實際應用中成本較高。為了解決這個問題,提出了一種基于平均模型和誤差削減網絡的語聲轉換。
2.1 訓練階段
本文所提出的語聲轉換框架如圖3 所示,整個訓練過程可以分為3 個訓練階段。在訓練階段1 中,利用除源說話人和目標說話人以外的多說話人數據,訓練一個CBHG 平均模型,用于語聲后驗圖(Phonetic posterior grams,PPG)到梅爾倒譜系數(Mel-cepstral coefficients,MCEPs)的映射。MCEP是一種梅爾對數頻譜逼近參數(Mel-log spectrum approximation,MLSA),表示梅爾頻率倒譜系數(Mel-frequency cepstral coefficients,MFCC)的近似。輸入語聲的音素信息是使用一個預訓練好的ASR 系統提取的,ASR 模型的輸入是語聲幀的MFCC 特征,輸出是PPG 特征,表示對應語聲幀的音素類別的后驗概率。訓練一個基于CBHG 網絡結構的模型,學習PPG 特征和對應的MCEP 特征幀之間的映射關系,MCEP 由STRAIGHT 聲碼器[22]提取。將訓練好的模型稱為平均模型,它只能生成訓練數據中說話人的平均語聲的MCEP特征。
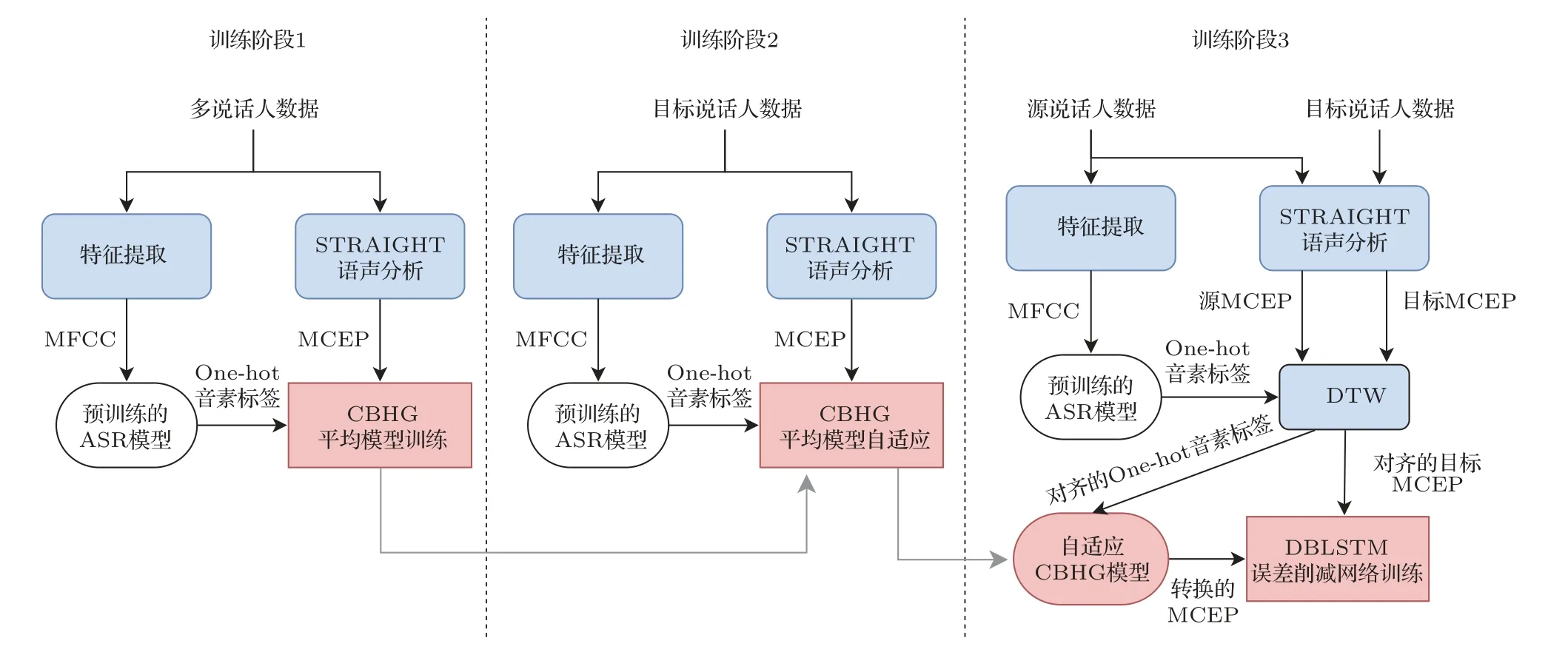
圖3 本文所提出的語聲轉換系統Fig.3 Thevoice conversion system proposed in this paper
在訓練階段2,使用少量的目標說話人數據對平均模型進行自適應。自適應過程與平均模型的訓練類似,不同點在于使用訓練好的平均模型對網絡進行初始化,自適應訓練使用的數據是目標說話人語聲數據。自適應訓練后,模型的輸出將從平均語聲向目標說話人靠近。將該階段訓練好的模型稱為自適應平均模型。然而值得注意的是,不管轉換網絡的性能如何,轉換后的特征和目標特征之間總是存在一個誤差,這種誤差會降低轉換后語聲的質量和說話人相似度[23]。為了減少這種誤差,提出了應用于自適應平均模型的誤差削減網絡。
訓練階段3 中涉及誤差削減網絡的訓練,它本質上是一個附加的DBLSTM 網絡,用于將轉換后的MCEP 映射到目標MCEP。誤差削減網絡的目的就是使最終的輸出MCEP 特征更接近于目標說話人。誤差削減網絡訓練時使用的數據為來自源說話人和目標說話人的平行數據,同訓練階段2 中自適應平均模型訓練所使用的目標數據為同一組數據。使用相同的ASR 系統來生成源語聲的PPG特征,通過動態時間規整(Dynamic time warping,DTW)技術對來自源語聲和目標語聲的平行語句MCEP特征進行對齊,同時利用對齊信息得到對齊的PPG 特征。然后將PPG 特征輸入到自適應平均模型中,生成對齊的轉換后MCEP。在誤差削減網絡的訓練中,輸入的是對齊的轉換后MCEP,輸出是目標語聲的原始MCEP 特征。訓練后得到的誤差削減網絡可以進一步降低之前訓練階段中所產生的誤差。
在所有的訓練階段中,均采用生成的MCEP和原始MCEP 特征之間的均方差作為模型的優化目標函數。
2.2 實際運行階段
在轉換階段,輸入的是來自源說話人的一整個語句。logF0和AP的轉換與第1節中所描述的基于CBHG 的語聲轉換系統相同。將源語聲的MFCC特征輸入到預訓練的ASR模型中,獲得輸入源語聲的PPG 特征。然后,訓練好的自適應平均模型用于將PPG特征轉換為MCEP特征。最后,將轉換后的MCEP 特征輸入到誤差削減網絡中,得到最終的轉換結果。最終的輸出MCEP 特征與轉換后的logF0和AP分量結合,由STRAIGHT聲碼器重構得到輸出語聲。
3 實驗結果與分析
3.1 實驗設置
本節中進行了一系列測試實驗來評估本文所提出的框架性能,即基于平均模型和誤差削減網絡的語聲轉換系統。第1 節中所描述的基于CBHG 的語聲轉換系統和第2 節中所描述的基于CBHG 的自適應平均模型作為本文實驗的基線模型,同所提出系統進行了比較。自適應平均模型是本文提出的算法的一個中間步驟,圖4 展示了自適應平均模型在實際運行時的轉換過程。圖5 展示了本文提出的系統在實際運行時和自適應平均模型之間的差異。
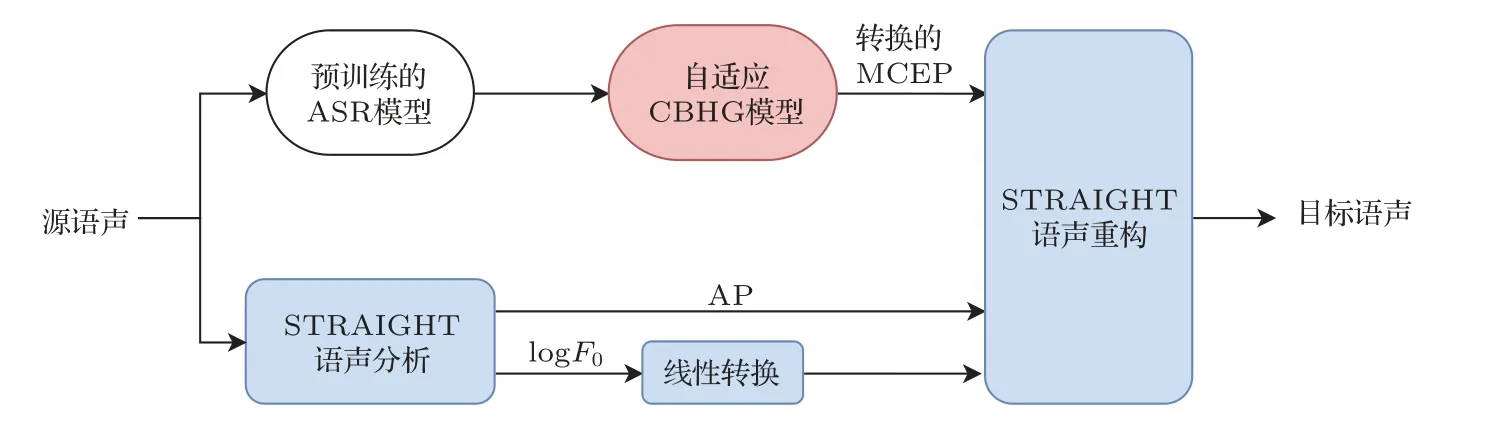
圖4 自適應平均模型的實際轉換過程Fig.4 The actual conversion process of adaptive average model
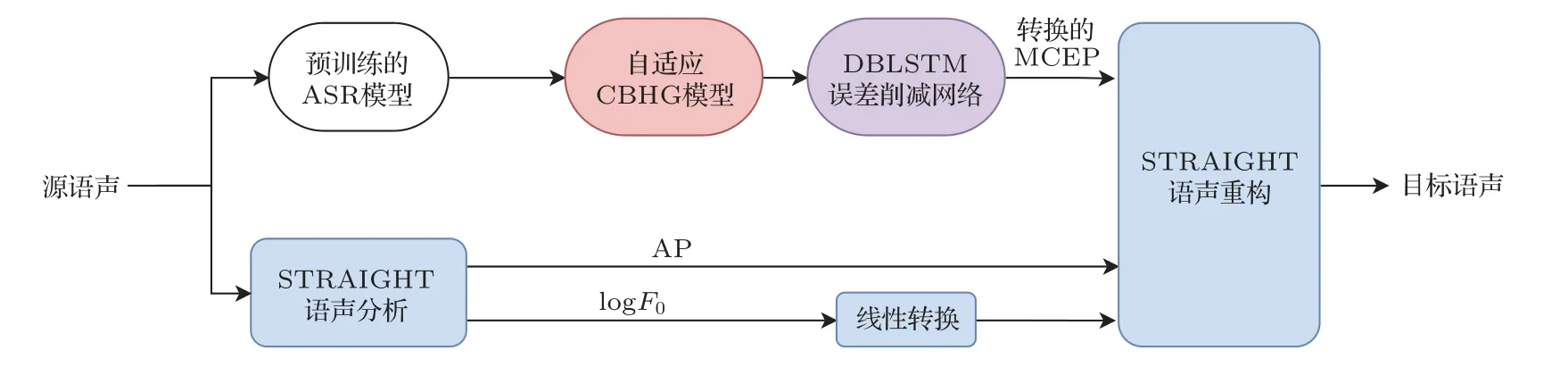
圖5 本文所提出模型的實際轉換過程Fig.5 The actual conversion process of the proposed model
實驗中使用的數據庫是CMU ARCTIC 語料庫[24]。由于語聲轉換研究中跨性別語聲轉換是最具挑戰性的工作,本文選擇了跨性別的語聲轉換作為任務目標。語聲信號的采樣頻率為16 kHz,單聲道,通過STRAIGHT 提取40 維MCEP 作為聲學特征,窗長為25 ms,幀移為5 ms。在基于CBHG 網絡的平均模型訓練中,使用了4個男性說話者(awb、jmk、ksp、rms)的數據,其中訓練數據和測試數據分別為4433 句和489 句。在訓練階段2 中,分別使用目標說話人(slt)的45 個和5 個句子來作為訓練數據和測試數據進行平均模型自適應訓練。在誤差削減網絡的訓練中,來自源說話人(bdl)的訓練數據是自適應平均模型中使用的目標語聲的平行數據。PPG 特征的維度為171,通過一個基于DNN-HMM的預訓練ASR系統獲取[25]。
詳細的模型結構和參數如表1 所示。CBHG 網絡中的一維卷積濾波器組K設為16,最大池化步長為1 寬度為2,之后的一維卷積投影層寬度為3,所有卷積層的通道數均為128。高速公路網絡由4 層全連接層組成,每層包含128個單元。雙向門控循環網絡包含128 個單元,最后通過線性映射層生成40維MCEP。模型訓練前,將所有訓練樣本歸一化為零均值和單位方差。在誤差削減網絡訓練中,為了更好地利用上下文信息,采用3 個連續幀的轉換后MCEP 作為輸入特征,即當前幀、當前幀的上一幀和當前幀的下一幀特征。誤差削減網絡的網絡結構中共有3個隱層,每層的單元數分別為[120 128 256 128 40]。
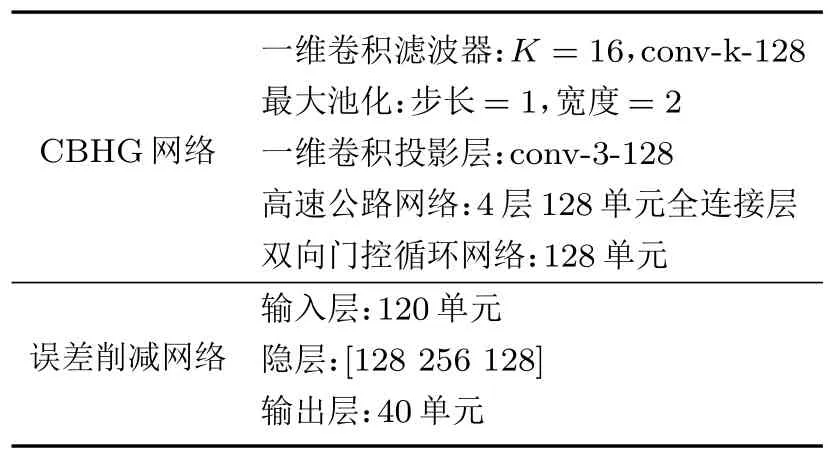
表1 詳細的模型結構和參數Table 1 Detailsof model architecture and hyper-parameters
在作為基線系統的基于CBHG 網絡的平行語聲轉換系統訓練中,采用來自源說話人和目標說話人的100 個平行語句作為訓練數據。基線模型網絡結構與自適應平均模型的配置相同。在模型訓練中,學習率為10?5,動量因子為0.9。
3.2 客觀評估
使用梅爾倒譜失真(Mel-cepstral distortion,MCD)作為客觀評價指標,評測轉換后的頻譜和真實目標頻譜之間的距離,用公式表示為
表2 中列出了不同系統的跨性別語聲轉換的MCD得分結果。從結果中可以看出,本文提出的方法優于CBHG基線模型和自適應的平均模型。還可以看到,自適應平均模型的訓練中沒有使用平行數據,因此自適應平均模型的MCD 得分不如CBHG基線模型。但是經過僅使用50 組平行數據訓練得到的誤差削減網絡后,性能可以得到明顯的提升,優于自適應平均模型和使用100組平行訓練數據的CBHG基線模型。

表2 不同語聲轉換系統的MCD 結果比較Table 2 Comparison of MCD results of different speech conversion systems
3.3 主觀評估
為了評估不同系統轉換后語聲的質量和說話人相似度,進行了主觀聽力測試,邀請10 名參與者對每個系統所生成的10個語句進行評價。
進行了平均意見得分(Mean opinion score,MOS)測試,參與者對聽到的語聲質量按照5 分制的規定進行評分: 1=極差,2=差,3=一般,4=好,5=極好。在本節實驗中,分別對以下3 個系統進行了MOS 測試:(1) 基線方法,基于CBHG的平行語聲轉換系統,訓練數據為100 組平行數據;(2) 第2 節中所描述自適應平均模型;(3) 本文所提出的方法。MOS 測試的結果和95%的置信區間如圖6 所示。基線方法、自適應平均模型和所提出的方法得分分別為3.28、3.57和3.83。
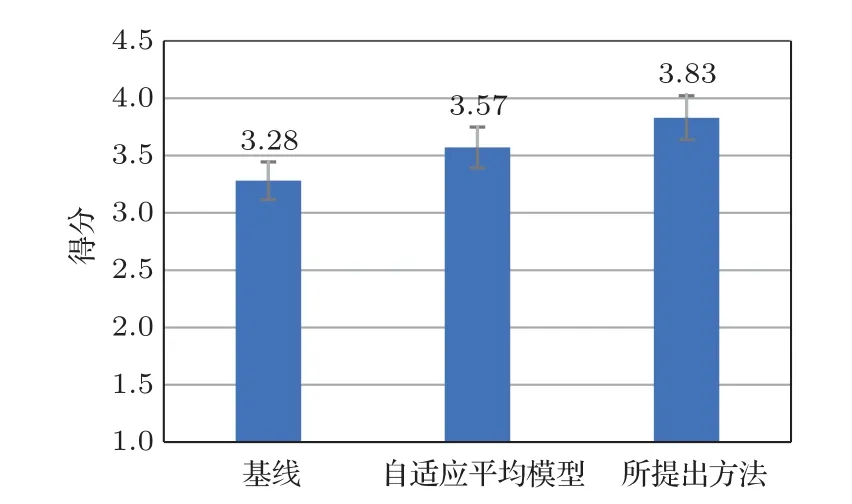
圖6 語聲質量和自然度的MOS 測試結果及其95%置信區間Fig.6 MOS test results of speech quality and naturalness and their 95% confidence intervals
此外,還進行了ABX 偏好測試來評估兩個不同系統生成的轉換語聲的說話人相似度。在基線方法和本文提出的方法之間,以及自適應平均模型和所提出方法之間進行ABX 偏好測試,參與者要求從給出的A 語句和B 語句中,選擇出聽起來更接近目標說話人語聲X的一個。說話人相似度的偏好測試結果如圖7所示。
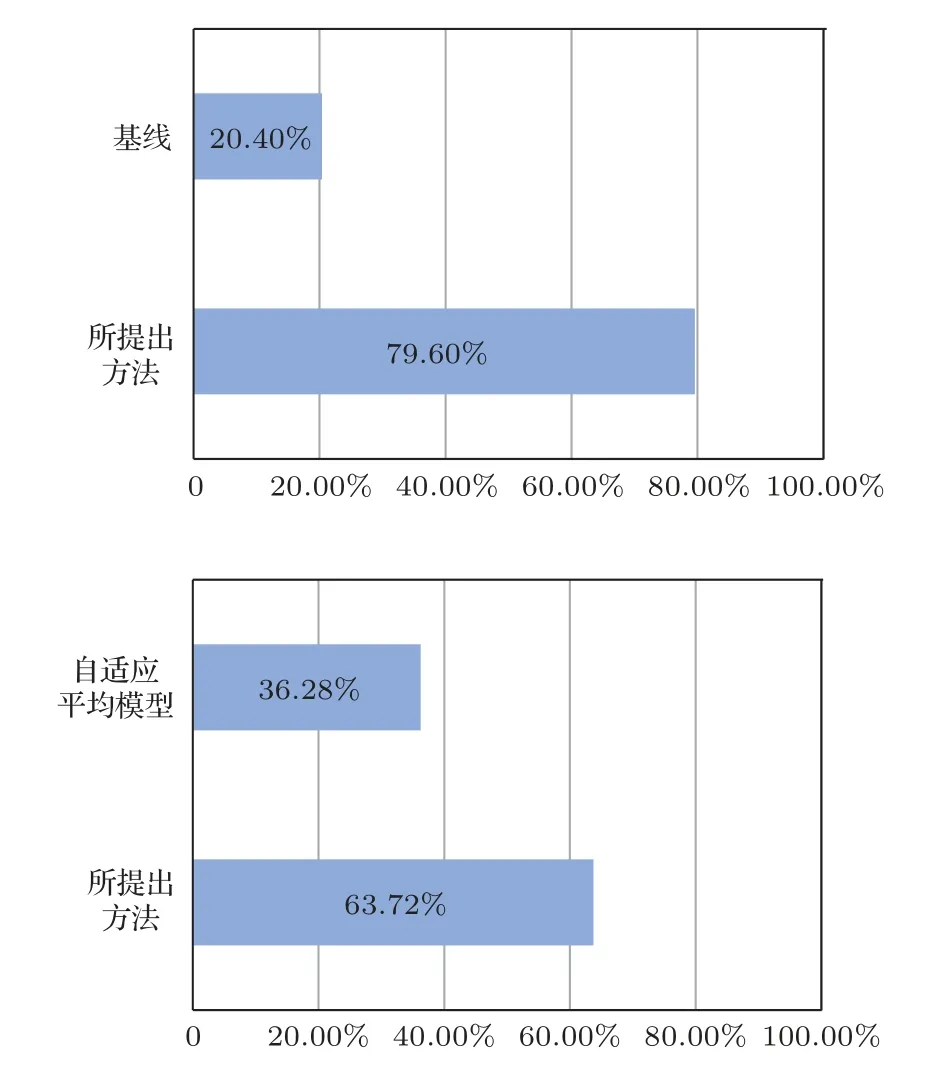
圖7 說話人相似度的ABX 測試結果Fig.7 ABX test results of speaker similarity
總的來說,MOS 測試和ABX 偏好測試的結果都表明,本文提出的基于平均模型和誤差削減網絡的語聲轉換方法,在有限的平行訓練數據條件下,在語聲質量和說話人相似度的評估上都優于使用大量平行數據的基線方法。由于平均模型的訓練中使用大量的訓練數據,達到了比基線方法更好的平均語聲質量,對接下來系統模塊的性能提升有很大幫助。
4 結論
本文提出了一種基于平均模型和誤差削減網絡的語聲轉換系統,在源說話人和目標說話人的平行數據有限的情況下,可以實現良好的轉換性能。首先,提出使用排除源說話人和目標說話人的多說話人數據,訓練一個PPG 特征到MCEP 映射的平均模型。然后,提出用有限的目標說話人數據來進行平均模型的自適應。此外,還實現了一個可以提高語聲轉換質量的誤差削減網絡。客觀和主觀評估的實驗結果表明,本文提出的方法可以很好地利用有限的數據,實現優于基線方法的系統性能。在接下來的工作中,將研究使用WaveNet 聲碼器來替代STRAIGHT 聲碼器,逐樣本生成原始聲頻波形,以提高轉換語聲的質量和自然度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
