注意力機制和BiLSTM在SQL注入檢測中的應(yīng)用
2023-07-19 09:04:12孟順建李亞王海瑞朱貴富王清宇
化工自動化及儀表 2023年3期
關(guān)鍵詞:深度學(xué)習(xí)
孟順建 李亞 王海瑞 朱貴富 王清宇


摘 要 針對目前SQL注入檢測方法檢測效率和檢測準(zhǔn)確率不高的問題,提出了一種基于注意力機制的檢測模型Att?BiLSTM。首先,對收集到的數(shù)據(jù)集在預(yù)處理后采用RoBERTa進(jìn)行詞嵌入,得到融合上下文信息的語言表征;再使用編碼后的詞向量在基于注意力機制的雙向長短時記憶網(wǎng)絡(luò)中進(jìn)行訓(xùn)練,以獲取數(shù)據(jù)之間的關(guān)聯(lián)性,得到忽略無關(guān)噪聲信息、關(guān)注重點信息的特征表征;最后,將融合了注意力信息的輸出在全連接層和softmax層進(jìn)行分類或反向傳播給訓(xùn)練層更新參數(shù)。實驗結(jié)果表明,基于注意力機制的SQL注入檢測模型有效提高了檢測精度,準(zhǔn)確率為99.58%,召回率為99.64%,與原始BiLSTM相比,準(zhǔn)確率和召回率分別提高了0.52%和0.28%,與BiRNN相比,準(zhǔn)確率和召回率分別提高了6.18%和6.91%。
關(guān)鍵詞 SQL注入檢測 深度學(xué)習(xí) BiLSTM 注意力機制
中圖分類號 TP309? ?文獻(xiàn)標(biāo)識碼 A? ?文章編號 1000?3932(2023)03?0348?08
基金項目:國家自然科學(xué)基金項目(61863016,61263023)。
作者簡介:孟順建(1995-),碩士研究生,從事WEB安全、機器學(xué)習(xí)的研究。
通訊作者:朱貴富(1984-),工程師,從事教育大數(shù)據(jù)、機器學(xué)習(xí)和智能技術(shù)的研究,zhuguifu@kust.edu.cn。
引用本文:孟順建,李亞,王海瑞,等.注意力機制和BiLSTM在SQL注入檢測中的應(yīng)用[J].化工自動化及儀表,2023,50(3):348-355.
數(shù)據(jù)庫技術(shù)是信息技術(shù)領(lǐng)域的核心技術(shù)之一,幾乎所有的信息系統(tǒng)都需要使用數(shù)據(jù)庫系統(tǒng)來組織、存儲、操縱和管理業(yè)務(wù)數(shù)據(jù)。數(shù)據(jù)庫技術(shù)在給各企業(yè)帶來便利的同時也帶來了數(shù)據(jù)安全問題,SQL注入[1]攻擊是影響WEB應(yīng)用程序安全運行和數(shù)據(jù)安全的原因之一。非法用戶會利用WEB應(yīng)用程序的這一安全漏洞,在輸入字符串中拼接惡意SQL指令,以達(dá)到注入目的。若應(yīng)用程序設(shè)計不良,忽略了檢查,那么這些注入進(jìn)去的惡意指令就會被數(shù)據(jù)庫服務(wù)器誤認(rèn)為是正常的SQL指令而運行,從而使數(shù)據(jù)庫遭到破壞或入侵。因此,數(shù)據(jù)庫的安全面臨著嚴(yán)峻的挑戰(zhàn)。
SQL注入檢測能夠降低應(yīng)用程序遭受此類攻擊的風(fēng)險,提高數(shù)據(jù)庫的安全性和風(fēng)險應(yīng)對能力。近年來,數(shù)據(jù)庫安全領(lǐng)域中SQL注入攻擊的方式越來越復(fù)雜,導(dǎo)致傳統(tǒng)檢測方法難以應(yīng)對這種情況。在國外,關(guān)于SQL注入防御的研究起步較早,目前比較成熟的檢測方法主要有黑名單匹配法、SQL DOM樹檢測法、動態(tài)檢測法、靜態(tài)檢測法以及動靜相結(jié)合的檢測法[2,3]等。隨著機器學(xué)習(xí)的興起,很多人也將機器學(xué)習(xí)的方法應(yīng)用到了SQL注入檢測中,LI Q等提出了一種基于長短期記憶(Long Short?Term Memory,LSTM)的SQL注入檢測方法[4],并通過數(shù)據(jù)傳輸信道生成大量正樣本,有效解決了正樣本不足引起的過擬合問題,同時還提高了攻擊檢測的準(zhǔn)確性,降低了誤報率。FAROOQ? U將4種梯度提升機應(yīng)用于SQL注入檢測中[5],并證明了輕量的梯度提升機(Light Gradient Boosting Machine,LGBM)具有最好的檢測率。XIE X等提出了一種基于彈性池化的卷積網(wǎng)絡(luò)SQL注入檢測方法[6],該方法可以輸出固定的二維矩陣而不截斷數(shù)據(jù),能夠識別新的攻擊,而且更難被繞過。
現(xiàn)有的檢測方法大多使用從簡單預(yù)處理后的完整攻擊語句中提取的特征進(jìn)行檢測,忽略了詞嵌入時的上下文信息和訓(xùn)練過程中無關(guān)噪聲的影響,這導(dǎo)致模型沒有關(guān)注到重要的特征,而是對所有的特征一視同仁。針對上述問題,筆者在文本語言表征時使用了RoBERTa進(jìn)行詞嵌入,得到了融合上下文信息的詞向量特征表征[7],同時在雙向長短時記憶網(wǎng)絡(luò)(Bi?direction Long Short?Term Memory,BiLSTM)中加入了注意力機制,改善了模型對重要特征的敏感度,忽略了一些噪聲數(shù)據(jù),有助于提高SQL注入攻擊檢測的準(zhǔn)確率。
1 注意力機制
1.1 Encoder?Decoder模型
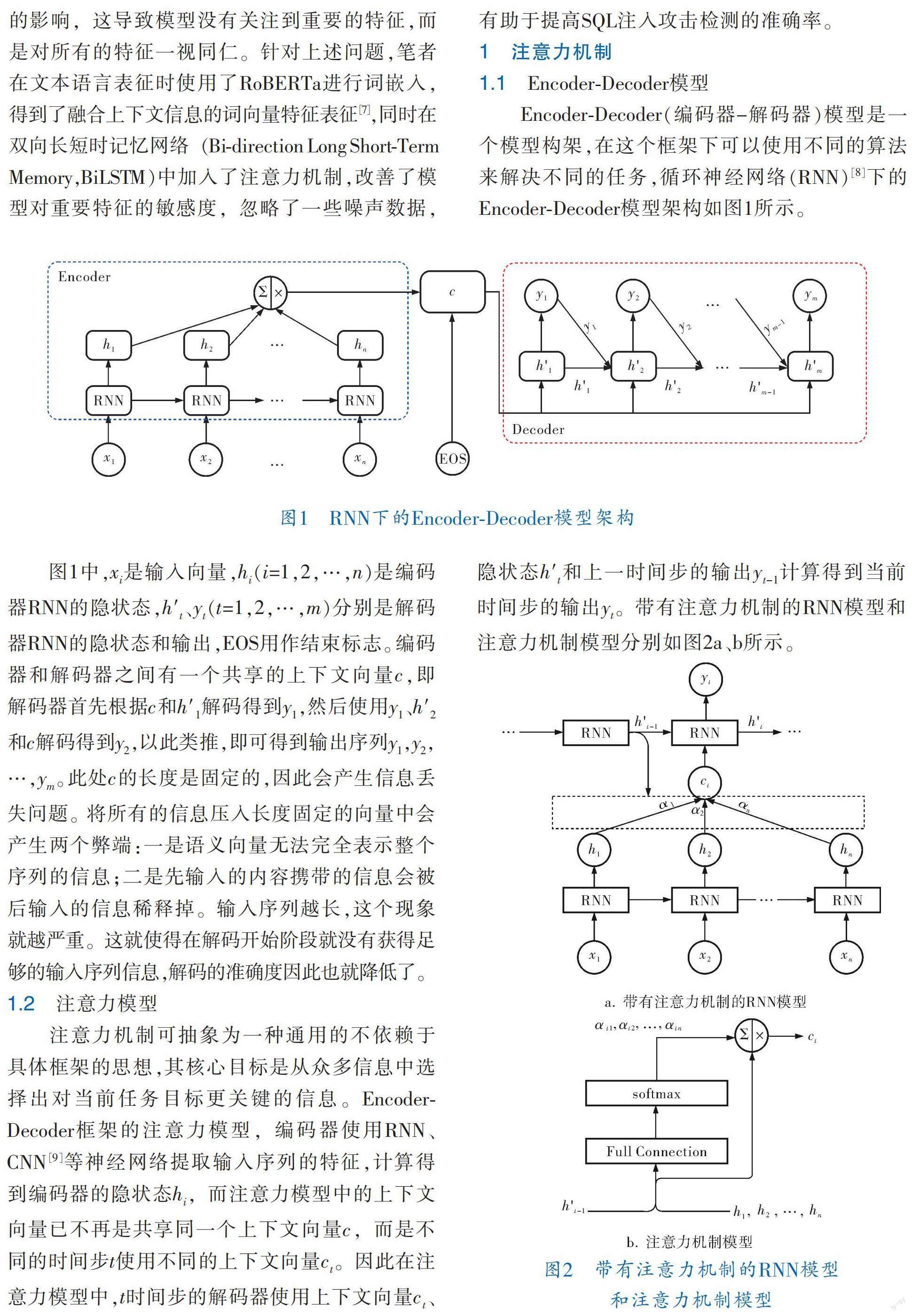
Encoder?Decoder(編碼器-解碼器)模型是一個模型構(gòu)架,在這個框架下可以使用不同的算法來解決不同的任務(wù),循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)[8]下的Encoder?Decoder模型架構(gòu)如圖1所示。
圖1中,x是輸入向量,h(i=1,2,…,n)是編碼器RNN的隱狀態(tài),h′、y(t=1,2,…,m)分別是解碼器RNN的隱狀態(tài)和輸出,EOS用作結(jié)束標(biāo)志。編碼器和解碼器之間有一個共享的上下文向量c,即解碼器首先根據(jù)c和h′解碼得到y(tǒng),然后使用y、h′和c解碼得到y(tǒng),以此類推,即可得到輸出序列y,y,…,y。此處c的長度是固定的,因此會產(chǎn)生信息丟失問題。將所有的信息壓入長度固定的向量中會產(chǎn)生兩個弊端:一是語義向量無法完全表示整個序列的信息;二是先輸入的內(nèi)容攜帶的信息會被后輸入的信息稀釋掉。輸入序列越長,這個現(xiàn)象就越嚴(yán)重。這就使得在解碼開始階段就沒有獲得足夠的輸入序列信息,解碼的準(zhǔn)確度因此也就降低了。
1.2 注意力模型
注意力機制可抽象為一種通用的不依賴于具體框架的思想,其核心目標(biāo)是從眾多信息中選擇出對當(dāng)前任務(wù)目標(biāo)更關(guān)鍵的信息。Encoder?Decoder框架的注意力模型,編碼器使用RNN、CNN[9]等神經(jīng)網(wǎng)絡(luò)提取輸入序列的特征,計算得到編碼器的隱狀態(tài)h,而注意力模型中的上下文向量已不再是共享同一個上下文向量c,而是不同的時間步t使用不同的上下文向量c。因此在注意力模型中,t時間步的解碼器使用上下文向量c、隱狀態(tài)h′和上一時間步的輸出y計算得到當(dāng)前時間步的輸出y。帶有注意力機制的RNN模型和注意力機制模型分別如圖2a、b所示。
從圖2可知,上下文向量c可以關(guān)注到輸入中最相關(guān)的部分,也就是“注意力”[10],c的計算式如下:
其中,α是解碼器在計算第t個預(yù)測輸出值y時,分配給編碼器第i個隱狀態(tài)h的注意力權(quán)重系數(shù)。α計算方式有很多種,不同的計算方式代表不同的Attention模型,常見的計算模型主要有加性模型、點積模型、縮放點積模型和雙線性模型4種。
Attention模型的計算步驟如下。
其中,函數(shù)f可以是任意的非線性函數(shù),如tanh、ReLU等。
f. 根據(jù)當(dāng)前時刻解碼器的隱狀態(tài)h′、上一時刻解碼器的輸出y和當(dāng)前時刻的上下文向量c,計算當(dāng)前的輸出y:
其中,g為計算當(dāng)前時刻輸出y的函數(shù),在Attention模型中,g通常是一個全連接神經(jīng)網(wǎng)絡(luò)。
g. 重復(fù)步驟c,直到得到第m時間步的輸出序列y。
2 實驗?zāi)P?/p>
2.1 SQL注入過程
SQL注入按注入類型可分為數(shù)字型注入、字符型注入和搜索型注入[11],其中以數(shù)字型注入和字符型注入居多,也更容易被攻擊者發(fā)現(xiàn)和利用。在WEB程序中,攻擊者的目的只有一個,即構(gòu)造非法輸入,繞過程序限制,把非法SQL命令帶入后臺執(zhí)行,利用數(shù)據(jù)庫的特性獲取更多的信息或更大的權(quán)限。
從攻擊者的攻擊順序看,一次完整的攻擊包括了尋找注入點、判斷注入點的注入類型、獲取目標(biāo)數(shù)據(jù)庫信息和操作目標(biāo)數(shù)據(jù)庫4個階段[12],以字符型注入為例,其攻擊流程如圖3所示。
尋找注入點。可能的注入點一般存在于登錄頁面、查找數(shù)據(jù)頁面或添加數(shù)據(jù)頁面等用戶可以訪問數(shù)據(jù)庫數(shù)據(jù)的地方。最常用的尋找SQL注入點的方法就是尋找形如“http://www.xxx.xx/?id=XX”的鏈接,其中“XX”可能是數(shù)字,也可能是字符串。
注入點注入類型判斷。注入點注入類型常見的主要有數(shù)字型注入類型和字符型注入類型,現(xiàn)以字符型注入類型為例進(jìn)行說明,其判斷流程如圖4所示。
由圖4可知,字符型注入點類型的判斷主要分為3步,分別是加引號、加“and 1=2”和“and 1=1”,加引號是為了判斷注入點的是單引號字符、雙引號字符還是其他字符類型,加“and 1=2”和“and 1=1”是為了判斷SQL指令是否會帶入后臺數(shù)據(jù)進(jìn)行執(zhí)行,只有“and 1=1”回顯正常、“and 1=2”回顯異常才是存在注入漏洞。在使用后兩種方法判斷注入類型時,還需要用到SQL中的注釋,以閉合name=XX后面的單引號(也有可能是雙引號或其他)。MySQL中有3種形式的注釋符,分別是?? (后面有一個空格)注釋符、#注釋符和/**/注釋符。滿足以上3點的注入點,基本可以認(rèn)定其注入類型為字符型注入。
獲取數(shù)據(jù)庫信息。找到注入點并判斷注入點的類型后,就可以構(gòu)造SQL語句進(jìn)行數(shù)據(jù)庫信息的獲取,在獲取數(shù)據(jù)庫信息的過程中,可以使用聯(lián)合查詢獲取WEB應(yīng)用程序可回顯的顯示位,然后使用database()、version()等特殊函數(shù)獲取數(shù)據(jù)庫的信息,使用information.schema等特殊庫獲取數(shù)據(jù)庫名,然后就可以獲取到數(shù)據(jù)庫中的表、表中的字段等信息。
操作數(shù)據(jù)庫。當(dāng)獲得數(shù)據(jù)庫中管理員的用戶名和密碼后,攻擊者可以在該階段執(zhí)行一些數(shù)據(jù)庫操作,如修改數(shù)據(jù)庫中特定表的數(shù)據(jù)、用戶的權(quán)限、添加一些非法用戶甚至可以導(dǎo)出數(shù)據(jù)庫信息或是刪除數(shù)據(jù)庫數(shù)據(jù)等。
2.2 數(shù)據(jù)收集及預(yù)處理
網(wǎng)上現(xiàn)存的SQL注入樣本數(shù)量較少,筆者前期從相關(guān)文獻(xiàn)中收集了約4 000條正樣本語句用于實驗,這些樣本數(shù)據(jù)由于數(shù)量太少,SQL注入種類覆蓋不全面,導(dǎo)致模型不能提取到完整的SQL注入特征。為了提高模型的精度和抗干擾能力,又通過數(shù)據(jù)倉庫、基于攻擊樹的SQL攻擊語句(正樣本)生成方法及在SQLI?Lab上運行SQLmap和tamper腳本收集并篩選出23 000條SQL注入樣本數(shù)據(jù),收集到的數(shù)據(jù)涵蓋了布爾盲注、時間盲注、報錯注入、聯(lián)合查詢注入、堆查詢注入及寬字節(jié)注入等常見的SQL注入類別。加上前期工作采集的數(shù)據(jù),共計收集到了27 000條數(shù)據(jù)用于實驗,其中正樣本15 000條,負(fù)樣本12 000條,正負(fù)樣本的比例為5∶4。收集到的數(shù)據(jù)中存在一些經(jīng)過編碼的文本和很多無意義的符號,數(shù)據(jù)預(yù)處理階段主要是將經(jīng)過編碼的文本解碼為UTF?8編碼,并對數(shù)據(jù)集進(jìn)行規(guī)范化處理和數(shù)據(jù)清洗,方便后面的分詞和詞嵌入。文本中存在的解碼前后的SQL語句對應(yīng)形式見表1。
SQL語句解碼后,還需要對數(shù)據(jù)集進(jìn)行泛化處理,得到清潔的數(shù)據(jù),盡可能地減少噪聲數(shù)據(jù)對模型的影響,泛化處理主要步驟如下:
a. 將樣本數(shù)據(jù)全部轉(zhuǎn)換為小寫;
b. 去掉樣本數(shù)據(jù)中的域名、協(xié)議及端口等字段,只留下URL中的數(shù)據(jù)荷載部分;
c. 將十六進(jìn)制數(shù)字泛化為0x00,其他數(shù)字泛化為0;
d. 將時間、日期泛化為固定字符串“dtime”。
2.3 詞嵌入與數(shù)據(jù)集
實驗中使用RoBERTa進(jìn)行詞嵌入訓(xùn)練,BERT(Bidirectional Encoder Represe?ntation from Transformers)是一種預(yù)訓(xùn)練語言模型,克服了以往單詞被表示成唯一索引值,或使用神經(jīng)網(wǎng)絡(luò)模型生成詞嵌入存在的一些缺點,RoBERTTa會根據(jù)上下文的不同動態(tài)地生成單詞的表示形式,而不是固定不變的。例如在SQL注入樣本集中,有如下兩個樣本:
負(fù)樣本? ?select * from users where username=xxx and pwd=xxx
正樣本? ?username=xxx union select 1,2,group_concat(concat_ws(‘0x7e,username,password))from security.users ?這里如果使用神經(jīng)網(wǎng)絡(luò)模型(如word2vec)正樣本和負(fù)樣本中的“select”都會被表示成相同的詞嵌入,而使用RoBERTa模型進(jìn)行詞嵌入,每個SQL語句中的“select”將生成不同的詞向量,除了捕獲諸如多義詞之類的明顯差異外,上下文不同的單詞嵌入還能捕獲其他形式的信息,這些信息可產(chǎn)生更準(zhǔn)確的特征表示,從而帶來更好的模型性能。
在進(jìn)行詞嵌入前還需要對語料進(jìn)行分詞,分詞使用正則表達(dá)式對文本進(jìn)行分割,并保留所有形如?? 、、”、(及??后的空格等在內(nèi)的所有特殊字符,在分詞之后為了讓RoBERTa識別出句子的范圍和方便分類還需要在句子的前后分別插入和標(biāo)識。為了防止后續(xù)數(shù)據(jù)集中出現(xiàn)新的特征詞和統(tǒng)一SQL句子的長度,還需要在分詞后的語料中添加
通過分詞過程,整個SQL數(shù)據(jù)集中99%以上的SQL語句長度都在150個單詞范圍內(nèi),各段語句長度占比如圖5所示。
由圖5可知,SQL注入數(shù)據(jù)集中僅有0.32%的語句在分詞后長度超過150,因此在制作數(shù)據(jù)集時,對每個SQL語句進(jìn)行截斷和填充處理,不足150詞長度的使用
2.4 模型搭建及注入檢測
實驗?zāi)P褪腔谧⒁饬C制的BiLSTM神經(jīng)網(wǎng)絡(luò)模型——Att?BiLSTM,編碼器和解碼器均采用了BiLSTM[13],BiLSTM是RNN的一種,由前向LSTM和后向LSTM結(jié)合而成[14,15],能夠較好地捕捉到較長距離的依賴關(guān)系,不但能編碼從前到后的信息,還能編碼從后到前的信息,對處理時序數(shù)據(jù)具有很好的效果。
Att?BiLSTM模型如圖6所示,實驗中使用了RoBERTa進(jìn)行詞嵌入,詞嵌入后的SQL文本向量在BiLSTM表示的編碼器層中訓(xùn)練得到SQL文本特征向量的隱狀態(tài),該隱狀態(tài)和解碼器中的第t個時間步的隱狀態(tài)在Attention層中計算得到第t個時間步的上下文向量(在訓(xùn)練初期,編碼器中的第1個時間步的隱狀態(tài)是隨機初始化的),最后把具有上下文信息的上下文向量和解碼器層的隱狀態(tài)在解碼器BiLSTM中融合后,送入全連接層即可得到模型的輸出。
模型中采用了RoBERTa詞嵌入和Attention機制,在詞嵌入表征能力提升的同時,也考慮了序列中不同元素的重要程度,有效提升了模型的預(yù)測精度。
3 實驗效果
實驗從27 000條訓(xùn)練數(shù)據(jù)集中,按照8∶2的比例抽取訓(xùn)練集和測試集,具體的訓(xùn)練數(shù)據(jù)分布見表2。
3.1 評價指標(biāo)
為了驗證模型的檢測能力,筆者使用預(yù)測準(zhǔn)確率(Accuracy)、精確率(Precision)、召回率(Recall)和F1值4個常用指標(biāo)進(jìn)行模型性能評估。這些指標(biāo)可以通過表3所示的混淆矩陣計算得到。
Accuracy表示的是正確分類的樣本占總樣本的比例:
Precision表示的是模型預(yù)測為正樣本中,實際也為正樣本所占的比例:
Recall表示的是所有正樣本中,模型預(yù)測為正樣本所占的比例:
F1是精確率和召回率的調(diào)和平均數(shù),用于評估模型的質(zhì)量,結(jié)果越接近1說明模型越好:
3.2 實驗結(jié)果及分析
在表2所示的數(shù)據(jù)集下,使用Adam優(yōu)化器進(jìn)行迭代學(xué)習(xí),經(jīng)過5萬次的迭代訓(xùn)練,其各項性能指標(biāo)如圖7所示。
從圖7中可以看出,模型的收斂速度很快,大約迭代到4 000次左右時,模型的各項指標(biāo)就已接近99%。在后面的迭代訓(xùn)練中,召回率、精確率和F1值都有略微的波動,但波動幅度很小,其精度都能維持在99.5%左右。
在SQL注入檢測中,召回率比精確率更為重要,其反映的是SQL注入樣本中被模型識別為正樣本和數(shù)據(jù)集中正樣本的比值,這個比值越高,就說明模型對正樣本的檢測精度越高,也更能反映模型的優(yōu)劣。因為在SQL注入檢測中,模型將正樣本錯分為負(fù)樣本比將負(fù)樣本錯分為正樣本所帶來的損失更為嚴(yán)重。由式(6)可知,召回率越高,則將正樣本預(yù)測為負(fù)樣本的概率越低,即模型對正樣本的區(qū)分能力越強。從圖7a可知,模型的召回率總是優(yōu)于精確率的,并且召回率和精確率的精度都很高,說明模型對正負(fù)樣本的區(qū)分度都很好,并不會嚴(yán)重偏向正樣本或負(fù)樣本。
準(zhǔn)確率能衡量一個模型對新樣本(也就是測試樣本)的識別能力,準(zhǔn)確率越高,說明模型將樣本分類正確的數(shù)目越多,從圖7b可以看出,模型的準(zhǔn)確率為99.58%左右,對未知數(shù)據(jù)具有較好的檢測能力。
3.3 實驗對比
筆者使用表2數(shù)據(jù)集,在Python環(huán)境下和LSTM、BiLSTM、RNN、BiRNN、GRU、BiGRU進(jìn)行對比,對比結(jié)果見表3。
同樣的環(huán)境和參數(shù)配置下,筆者所使用的Att?BiLSTM具有最好的召回率和分類準(zhǔn)確率,RNN和BiRNN的效果最差。由表3可知,雖然GRU和BiGRU在精確率方面都優(yōu)于Att?BiLSTM,但Att?BiLSTM的召回率更高,達(dá)到了99.64%,分類準(zhǔn)確率也高于GRU和BiGRU,且在SQL注入檢測中更關(guān)注召回率,因為召回率更能反映SQL檢測模型對正樣本的識別能力。從這方面看,Att?BiLSTM模型能夠更精確地檢測出SQL注入語句,有效防御SQL注入攻擊。
4 結(jié)束語
筆者提出的Att?BiLSTM模型,是一種基于注意力機制的BiLSTM SQL注入檢測模型,并結(jié)合自然語言處理技術(shù)和RoBERTa模型對SQL語料進(jìn)行分詞和詞嵌入,改善了SQL注入語句中的詞向量表征,同時在模型中引入了注意力機制,使模型更能關(guān)注到SQL注入中的攻擊特征,減少噪聲數(shù)據(jù)的影響,并據(jù)此提高模型分類檢測的準(zhǔn)確率,降低誤報率。從實驗結(jié)果可知,引入注意力機制的Att?BiLSTM檢測模型識別準(zhǔn)確率和召回率都有明顯提高,其分類準(zhǔn)確率為99.58%,召回率為99.64%。未來工作中將對二階SQL注入開展進(jìn)一步的研究。
參 考 文 獻(xiàn)
[1] 翟寶峰.SQL注入攻擊的分析與防范[J].遼寧工業(yè)大學(xué)學(xué)報(自然科學(xué)版),2021,41(3):141-143;147.
[2] GUO Q Q,ZHANG H X.Technology System for Security Protection of Critical Information Infrastructures[J].Netinfo Security,2020,20(11):1-9.
[3] MUHAMMAD R,BASHIR R,HABIB S,et al.Detection and Prevention of SQL Injection Attack by Dynamic Analyzer and Testing Model[J].International? Journal of Advanced Computer Science and Applications,2017,8(8):209-211.
[4] LI Q,WANG F,WANG J F,et al.LSTM based SQL injection detection met?hod for intelligent transportation system[J].IEEE Transactions on Vehicular Technology,2019,68(5):4182-4191.
[5] FAROOQ U.Ensemble Machine Learning Approaches for Detection of SQL Injection Attack[J].Tehni?ki Glasnik,2021,15(1):112-120.
[6] XIE X,REN C H,F(xiàn)U Y S,et al.SQL Injection Detection for Web Applications Based on Elastic?Pooling CNN[J].IEEE Access,2019,7:151475-151481.
[7] 王華鋒,王久陽.一種基于Roberta的中文實體關(guān)系聯(lián)合抽取模型[J].北方工業(yè)大學(xué)學(xué)報,2020,32(2):90-98.
[8] SHERSTINSKY A.Fundamentals of recurrent neural network (RNN) and long short?term memory (LSTM) network[J].Physica D:Nonlinear Phenomena,2020,404:132306.
[9] 周飛燕,金林鵬,董軍.卷積神經(jīng)網(wǎng)絡(luò)研究綜述[J].計算機學(xué)報,2017,40(6):1229-1251.
[10] 任歡,王旭光.注意力機制綜述[J].計算機應(yīng)用,2021,41(S1):1-6.
[11] 趙少飛,楊帆,田國敏.基于網(wǎng)站系統(tǒng)的SQL注入解析[J].網(wǎng)絡(luò)安全技術(shù)與應(yīng)用,2019(11):28-29.
[12] 郭春,蔡文艷,申國偉,等.基于關(guān)鍵載荷截取的SQL注入攻擊檢測方法[J].信息網(wǎng)絡(luò)安全,2021,21(7):43-53.
[13] 阮進(jìn)軍,楊萍.基于Att?CN?BiLSTM模型的中文新聞文本分類[J].通化師范學(xué)院學(xué)報,2022,43(12):65-70.
[14] HOCHREITER S,SCHMIDHUBER J.Long short?term memory[J].Neural Computation,1997,9(8):1735-1780.
[15] YU Y,SI X,HU C,et al.A review of recurrent neural networks:LSTM cells and network architectures[J].Neural computation,2019,31(7):1235-1270.
(收稿日期:2022-08-17,修回日期:2023-04-11)
Attention Mechanism and BiLSTM Application in SQL Injection Detection
MENG Shun?jian, LI Ya, WANG Hai?rui, ZHU Gui?fu, WANG Qing?yu
(Faculty of Information Engineering and Automation , Kunming University of Science and Technology)
Abstract? ?Aiming at the poor detection efficiency and accuracy of SQL injection detection methods, a detection method based on attention mechanisms Att?BiLSTM model was proposed. Firstly, having the collected dataset preprocessed before having it embedded in the word using RoBERTa so as to obtain the language representation that incorporating contextural information; and then, having the encoded word vector trained in the two?way long?short?term memory network based on the attention mechanism to obtain the correlation between the data, including the characteristic representation of ignoring irrelevant noise information and focusing on theimportant information; and finally, having the output which incorporating attention information classified or backpropaged to the training layer to update parameters. Experimental results show that, the SQL injection detection model(Att?BiLSTM) based on attention mechanism effectively improves the detection accuracy by 99.58% and a recall rate of 99.64%; compared with the original BiLSTM, the accuracy and recall rate are increased by 0.52% and 0.28%, respectively, and compared with BiRNN, the accuracy and recall rate are increased by 6.18% and 6.91%, respectively.
Key words? ?SQL injection detection, deep learning, BiLSTM, attention mechanism
猜你喜歡
中國教育技術(shù)裝備(2016年19期)2016-12-27 19:23:52
中國遠(yuǎn)程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿(mào)工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導(dǎo)刊(2016年9期)2016-11-07 22:20:49
