基于粒子群算法的科技創(chuàng)新數(shù)據(jù)檢索系統(tǒng)設(shè)計(jì)
2023-07-25 09:55:20馬芳平李林郭金婷柳玉蘭徐鐳夢(mèng)
電子設(shè)計(jì)工程 2023年15期
馬芳平,李林,郭金婷,柳玉蘭,徐鐳夢(mèng)
(國(guó)能大渡河流域水電開(kāi)發(fā)有限公司,四川成都 610095)
隨著信息化社會(huì)的進(jìn)步,數(shù)字文獻(xiàn)信息資源的管理和檢索方法有了很大的改進(jìn),但在檢索時(shí)會(huì)出現(xiàn)數(shù)據(jù)檢索不安全、數(shù)據(jù)檢索效率低的問(wèn)題,導(dǎo)致數(shù)據(jù)資源共享出現(xiàn)了嚴(yán)重的“數(shù)據(jù)孤島”情況。因此,建立一套完整的科技創(chuàng)新數(shù)據(jù)檢索體系是十分必要的。有研究人員提出深度學(xué)習(xí)驅(qū)動(dòng)的跨模態(tài)數(shù)據(jù)檢索方法,建立了基于深度學(xué)習(xí)的多模式信息檢索模型,在該模型上,結(jié)合深度學(xué)習(xí)的強(qiáng)大學(xué)習(xí)與表達(dá)能力,采用多標(biāo)記相似度測(cè)量與建模訓(xùn)練技術(shù),實(shí)現(xiàn)科技創(chuàng)新數(shù)據(jù)的檢索[1];還有研究人員提出基于哈希算法的異構(gòu)多模態(tài)數(shù)據(jù)檢索研究方法,通過(guò)對(duì)圖像和文字的語(yǔ)義建模,以保證在模式中的語(yǔ)義一致性。采用CCA 算法融合文字與圖像的語(yǔ)義,產(chǎn)生最大關(guān)聯(lián)矩陣,實(shí)現(xiàn)對(duì)科技創(chuàng)新數(shù)據(jù)的檢索[2]。然而,上述方法受到原始數(shù)據(jù)集冗余信息和噪聲影響,導(dǎo)致檢索結(jié)果不精準(zhǔn)。為此,提出了基于粒子群算法的科技創(chuàng)新數(shù)據(jù)檢索系統(tǒng)設(shè)計(jì)。
1 系統(tǒng)硬件結(jié)構(gòu)設(shè)計(jì)
基于粒子群算法的科技創(chuàng)新數(shù)據(jù)檢索系統(tǒng)硬件結(jié)構(gòu)如圖1 所示。
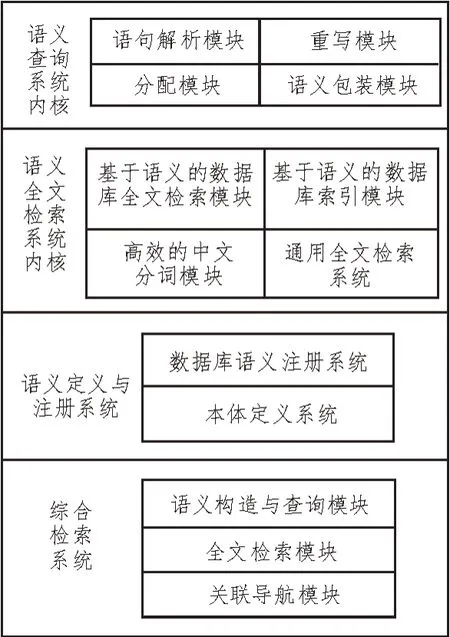
圖1 系統(tǒng)硬件結(jié)構(gòu)
由圖1 可知,該系統(tǒng)硬件結(jié)構(gòu)是由四個(gè)部分組成的,分別是語(yǔ)義查詢(xún)系統(tǒng)內(nèi)核、語(yǔ)義全文檢索系統(tǒng)內(nèi)核、語(yǔ)義定義與注冊(cè)系統(tǒng)、綜合檢索系統(tǒng)。基于本體論的語(yǔ)義搜索可以準(zhǔn)確地對(duì)數(shù)據(jù)進(jìn)行搜索,而基于語(yǔ)義的全文搜索系統(tǒng)則可以為整個(gè)搜索庫(kù)提供一個(gè)具體的關(guān)鍵詞[3]。該結(jié)構(gòu)建立在一個(gè)統(tǒng)一的全文檢索系統(tǒng)之上,包括索引、中文分詞、搜索模式等。以粒子群算法為基礎(chǔ)的綜合檢索系統(tǒng),也能給使用者提供一個(gè)較為便捷的查詢(xún)和展示界面[4]。
1.1 檢索引擎
在檢索服務(wù)器方面,按照所建立的索引庫(kù)及整個(gè)系統(tǒng)的特征進(jìn)行檢索,并給出了相應(yīng)的邏輯結(jié)構(gòu),如圖2 所示。
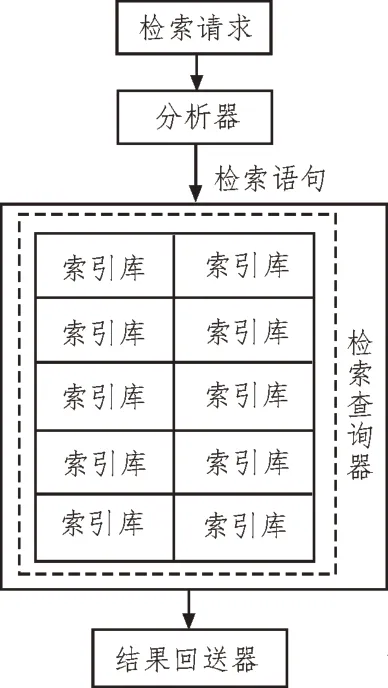
圖2 檢索引擎
在解析過(guò)程中,根據(jù)代理服務(wù)器的查詢(xún)請(qǐng)求,對(duì)查詢(xún)請(qǐng)求進(jìn)行分詞處理,得到一系列關(guān)鍵字,然后根據(jù)這些關(guān)鍵字之間的邏輯關(guān)系,得到一條查詢(xún)語(yǔ)句[5];采用哈希方法,將索引庫(kù)中的索引關(guān)鍵詞指派到各自的檢索查詢(xún)器中,根據(jù)搜索語(yǔ)句的關(guān)鍵詞,在索引庫(kù)中進(jìn)行檢索,產(chǎn)生對(duì)應(yīng)的文檔鏈接,再根據(jù)關(guān)鍵詞之間的邏輯聯(lián)系,將相關(guān)結(jié)果和查詢(xún)的相關(guān)性一同傳送至最后的循環(huán)[6]。
1.2 檢索數(shù)據(jù)存儲(chǔ)模塊
檢索數(shù)據(jù)存儲(chǔ)模塊通過(guò)預(yù)定義的協(xié)作策略,實(shí)現(xiàn)系統(tǒng)各功能模塊的調(diào)用,并進(jìn)行數(shù)據(jù)交互,實(shí)現(xiàn)協(xié)同工作[7]。該模塊所用的工具是一個(gè)動(dòng)態(tài)的數(shù)據(jù)存儲(chǔ)模塊,其結(jié)構(gòu)如圖3 所示。
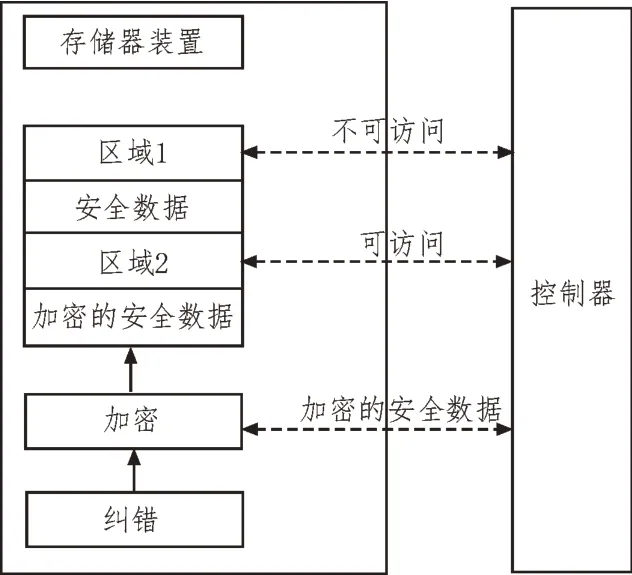
圖3 檢索數(shù)據(jù)存儲(chǔ)模塊
檢索數(shù)據(jù)存儲(chǔ)模塊是可移動(dòng)的,外部硬盤(pán)的引進(jìn)使儲(chǔ)存于存儲(chǔ)器裝置中的主機(jī)裝置變得更小巧、更便于攜帶。該存儲(chǔ)器裝置有兩個(gè)存儲(chǔ)區(qū)域,其中區(qū)域1 用來(lái)記憶儲(chǔ)存資料,外部裝置不可訪(fǎng)問(wèn)該區(qū)域;區(qū)域2 用來(lái)儲(chǔ)存已加密的安全數(shù)據(jù)的,外部裝置可訪(fǎng)問(wèn)該區(qū)域,并且加密的安全數(shù)據(jù)是區(qū)域1 中數(shù)據(jù)的加密版本[8-10]。
1.3 關(guān)聯(lián)導(dǎo)航模塊
關(guān)聯(lián)導(dǎo)航模塊如圖4 所示。
圖4 關(guān)聯(lián)導(dǎo)航模塊
在相關(guān)聯(lián)導(dǎo)航模塊中有3~5 個(gè)關(guān)鍵詞和一個(gè)長(zhǎng)的單詞,通過(guò)首頁(yè)、內(nèi)頁(yè)的宣傳鏈接來(lái)判定這些詞是否為熱門(mén)詞匯[11]。如果導(dǎo)航中的導(dǎo)航模塊以長(zhǎng)字開(kāi)頭,重點(diǎn)突出,且在關(guān)鍵詞排行榜中有更多的內(nèi)頁(yè),那么網(wǎng)站的排名將會(huì)更好,百度主頁(yè)的速度也會(huì)更快,快速提升了科技創(chuàng)新數(shù)據(jù)檢索速度[12]。
2 系統(tǒng)軟件部分設(shè)計(jì)
2.1 基于粒子群算法的數(shù)據(jù)分詞處理
由于詞串是在通道中傳送的,通道中存在噪聲干擾,使詞串失去了邊界標(biāo)志變?yōu)闈h字串。為此,提出了基于粒子群算法的數(shù)據(jù)分詞研究。數(shù)據(jù)分詞流程如圖5 所示。
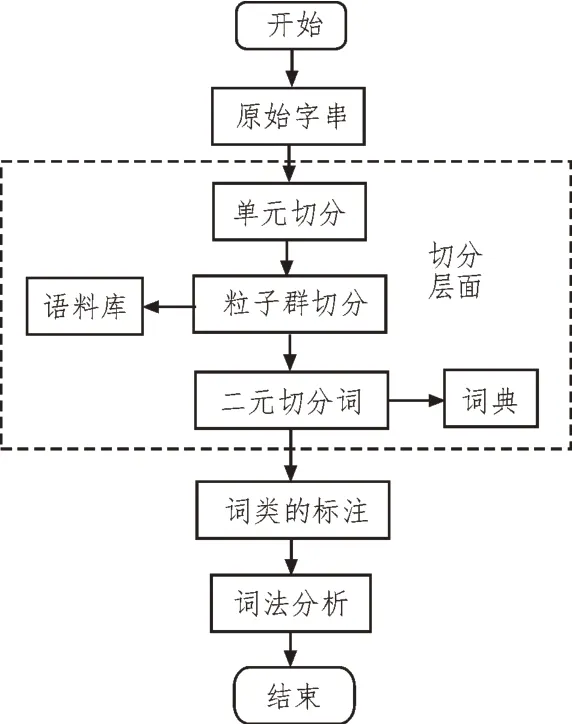
圖5 基于粒子群算法的數(shù)據(jù)分詞流程
在詞典的基礎(chǔ)上,找到所有可能出現(xiàn)的詞,并構(gòu)造一個(gè)有向無(wú)回圈的分詞[13]。每一字與圖表中的一條有向邊對(duì)應(yīng),并將其分配到相應(yīng)的長(zhǎng)度(權(quán)重)。在此基礎(chǔ)上,采用粒子群算法計(jì)算從起始到結(jié)束的最短路徑,并將其輸出作為分詞的結(jié)果[14]。
粒子群求解過(guò)程為:設(shè)粒子群算法的種群規(guī)模為m,連續(xù)演化的時(shí)間為t,該時(shí)間段內(nèi)的活動(dòng)量可表示為:
式中,η(t,ai)表示粒子ai在連續(xù)演化的時(shí)間內(nèi)的適應(yīng)值。
如果粒子在連續(xù)演化時(shí)間內(nèi)被選擇參加飛行,則新的自適應(yīng)分詞表達(dá)式為:
式中,?表示可調(diào)參數(shù)。
當(dāng)粒子活動(dòng)量較小時(shí),新的自適應(yīng)分詞值較小,在隨后的時(shí)間里,優(yōu)先參加飛行,這會(huì)強(qiáng)迫系統(tǒng)的熵值增大[15]。群體中的弱小粒子具有更大的可供選擇的可能性,使得求解空間中的探索區(qū)域和最佳粒子的駐留時(shí)間大大增加,改善算法的局部搜索性能,同時(shí)也避免了大規(guī)模的粒子聚集,保證了群體的多樣性。該方法將待優(yōu)化的各向異性作為最優(yōu)參數(shù),并對(duì)其進(jìn)行了速度、位置的修正,使其在最優(yōu)解空間內(nèi)進(jìn)行最優(yōu)解計(jì)算。
2.2 檢索流程設(shè)計(jì)
綜合上述基于粒子群算法的數(shù)據(jù)分詞處理過(guò)程,設(shè)計(jì)的檢索流程如下所示:
步驟一:以各個(gè)粒子的位置矢量為控制參量,求出各個(gè)粒子的適配值,隨機(jī)地對(duì)粒子的動(dòng)態(tài)和行為進(jìn)行初始化,決定最大可容許的重復(fù)次數(shù),并將鏈接指向網(wǎng)頁(yè)[16]。通過(guò)優(yōu)化二元函數(shù),尋找最優(yōu)粒子并對(duì)其編碼,評(píng)估鏈接最終價(jià)值。按照鏈接價(jià)值依次排序鏈接,并將相應(yīng)的地址存入待搜索隊(duì)列之中,由此確定粒子的最優(yōu)位置。
步驟二:利用數(shù)據(jù)分詞處理結(jié)果完成了對(duì)系統(tǒng)中的所有技術(shù)創(chuàng)新資料的分詞,并在后臺(tái)進(jìn)行;
步驟三:當(dāng)用戶(hù)輸入待檢索的關(guān)鍵詞后,由數(shù)據(jù)分詞處理步驟分詞處理關(guān)鍵詞,由此產(chǎn)生對(duì)應(yīng)的分詞矢量;
步驟四:確定各個(gè)粒子的全局最優(yōu)位置,并對(duì)文檔特征矢量表中的全部記錄進(jìn)行了相關(guān)分析;
步驟五:根據(jù)相關(guān)程度進(jìn)行分類(lèi),最終回歸到相應(yīng)的用戶(hù)文件集中,實(shí)現(xiàn)了數(shù)據(jù)的檢索。
3 實(shí) 驗(yàn)
3.1 科技創(chuàng)新數(shù)據(jù)源導(dǎo)入
由于技術(shù)創(chuàng)新的數(shù)據(jù)來(lái)源是外部資料,因此在進(jìn)行研究時(shí)必須將數(shù)據(jù)來(lái)源的基本參數(shù)引入其中。圖6 中顯示了科技創(chuàng)新數(shù)據(jù)源的輸入過(guò)程。
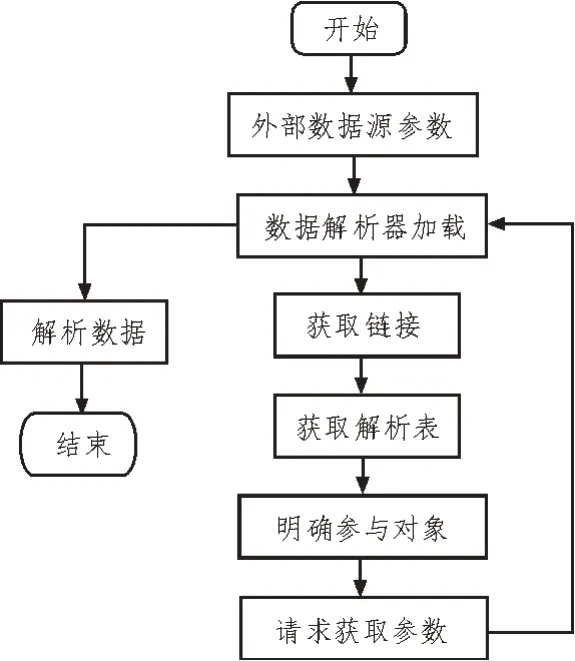
圖6 科技創(chuàng)新數(shù)據(jù)源導(dǎo)入實(shí)現(xiàn)流程
由圖6 可知,在該設(shè)計(jì)模式下,使用者將數(shù)據(jù)來(lái)源的參數(shù)信息填入到視圖層次,并以URL 的形式傳送至模型層。通過(guò)調(diào)用Controller 功能來(lái)獲得URL,將分析結(jié)果作為返回的數(shù)值傳遞到模型層中。模型層根據(jù)返回值的判別結(jié)果,通過(guò)適當(dāng)?shù)募虞d量對(duì)數(shù)據(jù)進(jìn)行分析。
3.2 評(píng)價(jià)標(biāo)準(zhǔn)
采用的評(píng)價(jià)標(biāo)準(zhǔn)是數(shù)據(jù)檢索中的經(jīng)典指標(biāo),即查準(zhǔn)率和查全率,其公式分別為:
3.3 實(shí)驗(yàn)結(jié)果與分析
基于評(píng)價(jià)標(biāo)準(zhǔn),分別使用深度學(xué)習(xí)驅(qū)動(dòng)的跨模態(tài)數(shù)據(jù)檢索、基于哈希算法的異構(gòu)多模態(tài)數(shù)據(jù)檢索和基于粒子群算法的檢索系統(tǒng),對(duì)比分析檢索查準(zhǔn)率和查全率,如圖7 所示。
由圖7 可知,使用深度學(xué)習(xí)驅(qū)動(dòng)的檢索方法查準(zhǔn)率最高為77%,查全率最高為70%;使用基于哈希算法的數(shù)據(jù)檢索方法,查準(zhǔn)率最高為80%,查全率最高為77%;使用基于粒子群算法的檢索系統(tǒng),檢索查準(zhǔn)率和查全率均較高,其中查準(zhǔn)率最高為96%,查全率最高為97%,均高于另兩種方法。這是由于文中設(shè)計(jì)的檢索系統(tǒng),通過(guò)基于粒子群算法的數(shù)據(jù)分詞處理步驟,能夠改善數(shù)據(jù)干擾問(wèn)題,提高查準(zhǔn)率和查全率。
4 結(jié)束語(yǔ)
設(shè)計(jì)的基于粒子群算法的科技創(chuàng)新數(shù)據(jù)檢索系統(tǒng),通過(guò)粒子群算法對(duì)分詞進(jìn)行實(shí)時(shí)加權(quán),通過(guò)在線(xiàn)調(diào)整,使系統(tǒng)具有自適應(yīng)性,使得檢索結(jié)果更加精準(zhǔn)。經(jīng)過(guò)對(duì)上述系統(tǒng)的分析,該系統(tǒng)真正地突破了以往的技術(shù)創(chuàng)新數(shù)據(jù)的限制,實(shí)現(xiàn)了對(duì)中心數(shù)據(jù)庫(kù)數(shù)據(jù)的快速更新。
猜你喜歡
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測(cè)繪(2020年12期)2020-12-29 01:33:58
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
中國(guó)洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
當(dāng)代修辭學(xué)(2011年6期)2011-01-29 02:49:50
