增強局部上下文監督信息的麥苗計數方法
2023-07-31 08:06:44申華磊麻巧迎鄭國清臧賀藏
農業機械學報 2023年7期
申華磊 張 潔 劉 棟,2 麻巧迎,2 鄭國清 臧賀藏
(1.河南師范大學計算機與信息工程學院, 新鄉 453007; 2.河南省教育人工智能與個性化學習重點實驗室, 新鄉 453007;3.河南省農業科學院農業經濟與信息研究所, 鄭州 450002; 4.農業農村部黃淮海智慧農業技術重點實驗室, 鄭州 450002)
0 引言
小麥是我國重要的糧食作物,保持小麥的持續高產對維護我國糧食安全具有重要意義[1]。在小麥生長過程中,麥苗株數是制約產量的關鍵因素,麥苗過于稀疏或稠密極大地影響小麥產量。因此,及時準確地統計麥苗株數將為后續的出苗率估算、產量預測和籽粒品質評估等生產環節提供重要科學依據[2]。
傳統的麥苗計數工作主要依賴于人工在田間進行數苗,存在經濟成本高、勞動力消耗大和計數效率低等問題,并且計數結果易受主觀因素影響。隨著深度學習的發展,使用深度神經網絡進行目標對象自動計數正成為新的研究熱點。與人工數苗方法相比,使用深度神經網絡對采集到的麥苗圖像進行分析,進而自動檢測麥苗株數,可打破時空限制和對農業專家的依賴,提高勞動效率。
已有學者使用深度學習技術對細胞[3]、人群[4-6]、豬只[7-9]和麥穗[10-12]等目標對象進行計數。這些方法可被分為兩類:基于目標檢測的方法和基于密度圖回歸的方法。基于目標檢測的方法主要使用YOLO、SSD和Faster R-CNN等檢測器對圖像中的目標對象進行檢測[13-15],之后得到目標對象的數目。這類方法不僅可以提供目標對象的計數結果,還可以通過邊框提供目標對象的位置信息。然而,這類方法在訓練階段需要標注大量的目標對象邊框作為標簽[16];麥苗細小且相互之間存在遮擋、重疊和扭曲等現象,使得麥苗邊框標注費時費力。同時,根據麥苗點標注結果自動生成偽框圖的方法容易出錯,并需要手動進行后處理。基于密度圖回歸的方法[17-21]對目標對象使用點標注生成密度圖,以作為模型的學習目標,之后對模型預測出的密度圖求積分得到目標對象的計數值。目前,具有代表性的方法有CSRNet[22]、CANet[23]、SCAR[24]、BL[25]和DM-Count[26]等。CSRNet使用空洞卷積以提高擁擠場景下的計數精度。CANet組合多個不同大小感受野獲得的特征以自適應地對不同尺度的上下文信息進行編碼。SCAR引入注意力機制以獲取像素和人群上下文之間的關聯信息。BL使用貝葉斯損失函數,從點標注構建密度貢獻概率模型以彌補密度圖的不足。DM-Count將分布匹配用于計數任務,并設計了新的優化策略以度量真實值與預測值之間的相似性。總體而言,這類方法的麥苗標注成本不高,但不能標識出麥苗的準確位置。這不利于種植規劃和良田培育等下游任務;且易受透視圖失真的影響,導致模型的魯棒性不強。
SONG等[27]提出的P2PNet為目標對象計數提供了新的解決方案。P2PNet直接將點標注結果作為學習目標,之后預測出所有目標對象的點坐標,從而得到計數結果。與上述兩類計數方法相比,P2PNet不需要對訓練樣本中的目標對象進行框標注,也不需要通過點標注生成偽密度圖或偽框圖間接得到學習目標。這不僅顯著降低了訓練樣本的標注成本,還減少了間接生成學習目標導致的模型計數性能下降的風險。并且,P2PNet可明確標識出目標對象的位置,更能滿足下游任務的應用需求。由以上分析可知,P2PNet更適于復雜場景下的麥苗計數。
但是,P2PNet直接用于麥苗計數的性能較差。一方面,麥田中的枯葉、不同光照角度導致麥苗圖像出現不同方向和尺寸的陰影,為計數模型帶來干擾噪聲,嚴重影響P2PNet的性能。另一方面,麥田中土塊對麥苗的遮擋以及麥苗生長稠密時葉片間的重疊,導致P2PNet的誤判。
農業專家對麥苗人工計數時,對于不易判別的困難樣本,通常根據麥苗的局部根莖信息、葉片發育的全局信息判斷麥苗為一株還是多株。受此啟發,本文對P2PNet進行改進,提出增強局部上下文監督信息的麥苗計數模型P2P_Seg。首先,引入局部分割分支改進網絡結構,以增強麥苗的局部上下文監督信息,引導網絡的注意力到麥苗根莖部區域,并減弱上述雜物、光照和土塊等帶來的噪聲。之后,設計逐元素點乘機制融合分割分支提取到的麥苗局部根莖信息與基礎網絡提取到的葉片發育全局信息,以模仿農業專家結合麥苗的根莖信息和葉片發育的全局信息應對遮擋和重疊造成的計數困難。最后,將融合后的特征信息通過點回歸分支和分類分支以預測麥苗的位置與株數。
1 研究區概況與數據
1.1 研究區概況
實驗地位于河南省現代農業研究開發基地的小麥實驗區,地處北緯35°00′28″,東經113°41′48″,海拔為97 m。實驗采用完全隨機區組設計,播種日期為2021年10月15日,共有400個小區,每個小區面積為36 m2。
1.2 研究數據
研究數據主要通過數據采集、預處理、圖像標注和數據集劃分4個步驟獲取。研究數據的主要制作流程如圖1所示。

圖1 研究數據制作流程圖
1.2.1數據采集
使用型號為HONOR 20 PRO的智能手機采集數據,相機分辨率為4 800萬像素,傳感器類型為BSI CMOS,光圈f/2.2。拍攝時間為2021年11月,小麥正處于苗期。主要對使用1 m×1 m紅色矩形框標出的目標計數區域進行采樣,共采集到317幅麥苗圖像,分辨率為4 000像素×3 000像素。剔除畫質模糊或存在嚴重遮擋的圖像,共篩選出295幅圖像作為最初實驗圖像。
1.2.2數據預處理
數據預處理的目的是對紅色矩形框外的非目標計數區域進行黑色填充和冗余剔除,其流程如圖2所示。為避免非目標區域麥苗對計數結果的影響,使用預處理工具對非目標區域進行黑色填充。為避免后續用于數據增強的隨機裁剪操作可能得到大面積的非目標計數區域,從而干擾目標區域的計數結果,對非目標區域進行最大程度的冗余剔除。經過以上兩個步驟,得到本文的最終實驗圖像。

圖2 麥苗圖像預處理步驟
1.2.3圖像標注
麥苗形態細小且易出現遮擋、重疊等現象,這使得基于框標注的方法非常困難,因此采用成本較低、方便快捷的點標注方法。一個點標注表示對應麥苗在圖像中的點坐標。采用WANG等[28]開發的標注工具進行數據集標注。該標注工具不僅能夠對圖像進行分塊標記,而且可對分塊區域進行隨機縮放。對于麥苗圖像中較為稠密、遮擋和重疊較為嚴重的區域,使用該工具對其放大再進行標注,有效地提高了標注速度與質量。標注區域為特征相對明顯的麥苗根莖部,便于后續網絡的訓練。
使用上述方法對295幅圖像進行點標注,共標注32 237株麥苗。其中,單幅圖像總標記點的最大值為321,最小值為18;平均每幅麥苗圖像約標記109株麥苗。不同密度等級的麥苗標注圖像如圖3所示。

圖3 不同密度等級的麥苗標注圖像
1.2.4數據集劃分
經過標注可得到295幅最終實驗圖像及對應的標注點,它們共同構成麥苗數據集。接著,按照比例6∶1∶3將麥苗數據集隨機劃分為訓練集、驗證集和測試集。其中訓練集、驗證集和測試集分別含有177、29、89幅麥苗圖像。麥苗數據集劃分結果如表1所示。
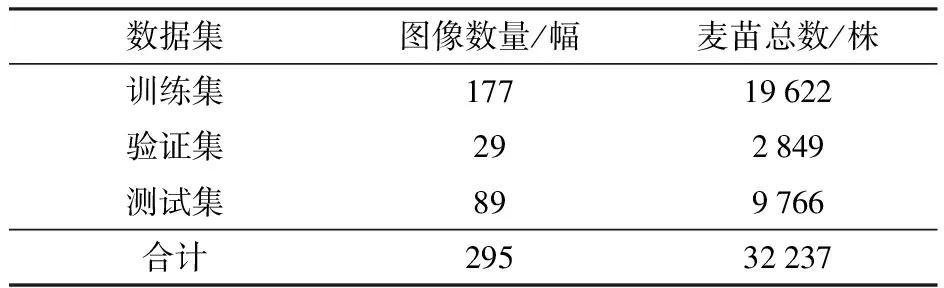
表1 麥苗數據集劃分結果
2 研究方法
2.1 P2PNet
P2PNet為目標計數提供了新的解決方案,是一個基于點標注的計數模型,以點的形式標注出目標對象的位置坐標,然后直接把標注結果作為模型的學習目標。P2PNet以VGG16_bn[29]為骨干網絡,提取目標對象的全局特征;之后將全局特征同時送入點回歸分支和分類分支以分別生成目標對象的候選點和每個候選點對應的置信度分數;最后根據分類結果從候選點中篩選出目標對象的位置坐標。位置坐標的總數即為目標對象的計數結果。
2.2 P2P_Seg整體框架
為減少光照、遮擋和重疊等因素對麥苗計數的影響,本文對P2PNet進行改進,引入麥苗局部分割分支以增強麥苗局部上下文監督信息,提出增強局部上下文監督信息的麥苗計數模型P2P_Seg。其網絡架構如圖4所示。首先,基礎網絡提取麥苗圖像的全局特征,得到全局特征圖F0。其次,麥苗局部分割分支生成局部特征圖F1,以提取麥苗局部上下文監督信息。然后,特征融合模塊的逐元素點乘機制融合麥苗的全局信息與局部上下文信息,生成融合后的特征圖F2。最后,通過點回歸分支與分類分支分別預測出麥苗的候選點位置坐標及其對應的置信度分數。

圖4 P2P_Seg模型整體框架
上述基礎網絡、點回歸分支與分類分支繼承自P2PNet。與P2PNet不同,為融合麥苗的局部根莖信息和全局葉片發育信息,以對抗光照、遮擋和重疊等因素的干擾,P2P_Seg從基礎網絡得到全局特征圖F0后,并未將其直接送入點回歸分支和分類分支,而是引入麥苗局部分割分支以提取麥苗局部特征圖F1。將F0與F1融合后得到的特征圖F2作為點回歸分支與分類分支的輸入,預測候選點位置坐標及其對應的置信度分數。
2.3 麥苗局部分割分支
麥苗局部分割分支旨在提取麥苗根莖部的局部上下文監督信息,具有2個用途:①集中模型的注意力到點標注的麥苗根莖部目標區域,忽略光照導致的陰影和田間枯葉等噪聲的干擾。②當麥苗標注點位置被土塊等雜物遮擋時,可以提供更多的上下文參考信息,提高模型的計數精度。麥苗局部分割分支包含的關鍵技術有麥苗局部分割圖生成和麥苗局部特征提取模塊設計。
2.3.1麥苗局部分割圖
麥苗局部分割圖是由點標注結果生成的體現麥苗局部上下文監督信息的圖像。該分割圖是麥苗局部分割分支的學習目標。麥苗局部分割分支使得計數網絡在將點標注作為學習對象的基礎上,又同時利用麥苗局部分割圖提取出麥苗局部上下文信息。這對計數網絡起到更強的監督作用。
麥苗局部分割圖是二值圖像,圖像上每個像素的值為0或1。值為0的區域為非麥苗根莖部目標區域;值為1的區域為本文所關注的麥苗根莖部目標區域,即局部上下文監督信息區域。給定一幅帶有N個點標注的麥苗圖像,點標注的位置在麥苗的根莖處,用P={pi|i∈{1,2,…,N}}表示該圖像內所有麥苗的點標注坐標,其中pi=(xi,yi)表示第i株麥苗的坐標。分別生成N個以pi為圓心、σ為半徑的圓域;圓域內的像素值為1、圓域外的像素值為0,從而得到麥苗局部分割圖G。圓域半徑σ決定了每株麥苗的根莖部目標區域的大小。SHI等[30]通過將圖像分割成局部區域塊,提出了核估計器σpi,以估計目標對象的尺寸。原始的核估計器σpi未考慮麥苗在整體圖像上的分布,可能會得到過大或過小的麥苗根莖部目標區域,如圖5a所示。過大的麥苗根莖部目標區域會引入額外的噪聲,過小的麥苗根莖部目標區域不能充分表示上下文信息。因此,本文在原始核估計器σpi的基礎上,考慮麥苗的整體分布,對所有點標注對應的核估計器σpi求平均,得到了更適合估計麥苗根莖部目標區域大小的圓域半徑σ,從而得到如圖5b所示的麥苗分割圖。上述麥苗局部分割圖G和圓域半徑σ的生成過程為
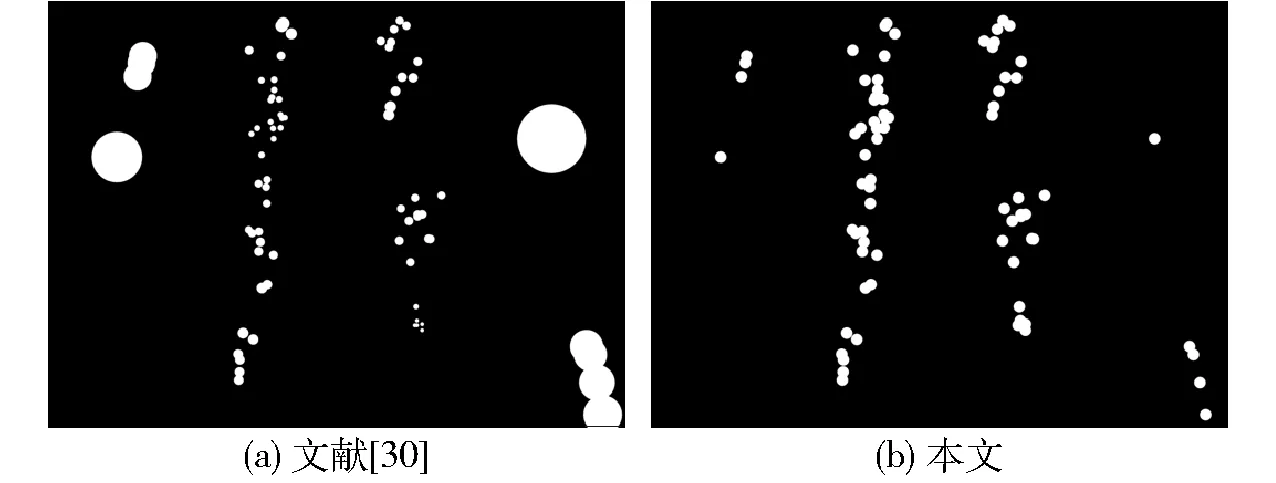
圖5 不同方法生成麥苗的局部分割圖
(1)
(2)
式中p——麥苗局部分割圖中的像素位置
pi——第i株麥苗的坐標
‖p-pi‖——p與pi間的歐氏距離
2.3.2麥苗局部特征提取模塊
麥苗局部特征提取模塊是麥苗局部分割分支的重要組成部分,旨在生成局部特征圖F1。本文設計的麥苗局部特征提取模塊如圖6所示,主要由降維卷積單元和卷積層組成。
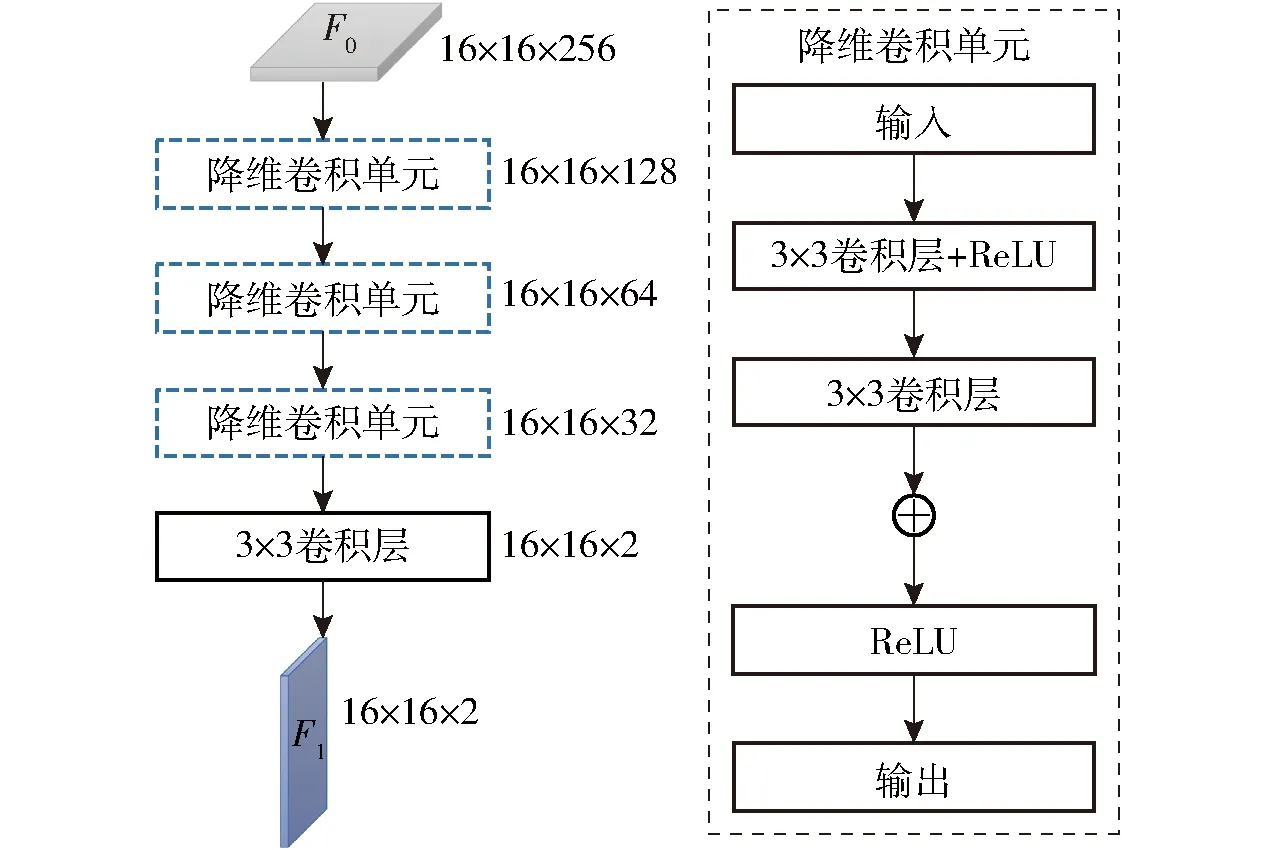
圖6 局部特征提取模塊
降維卷積單元的作用是在不改變輸入特征圖尺寸的前提下將其通道數減半,由連續2個3×3卷積層與ReLU激活函數交替組成。其中,第1個3×3卷積層將輸入特征圖的通道數減半;第2個3×3卷積層繼續提取深層特征,不改變特征圖的尺寸。為了提高網絡模型的非線性表達能力,每層卷積之后采用ReLU函數進行非線性激活。同時,在兩個卷積層之間使用殘差連接以對抗梯度消失。
麥苗局部特征提取模塊的輸入為16×16×256的全局特征圖F0。首先,F0經過連續3次的降維卷積單元,其尺寸依次變為16×16×128、16×16×64、16×16×32。接著,保持F0的尺寸不變,使用3×3卷積層將其通道數變為2,分別對應麥苗根莖部和非麥苗根莖部的特征圖。這兩個特征圖拼接在一起,得到尺寸為16×16×2的局部特征圖F1。F1表征麥苗根莖部的高層語義信息,也是本文強調的麥苗局部上下文監督信息。
局部特征圖F1的生成過程為
F1=f1(f(F0))
(3)
式中f(·)——連續3次的降維卷積單元操作
f1(·)——卷積函數
預測分割圖FG的生成過程為
FG=f1(f2(F1))
(4)
式中f2(·)——上采樣函數
如圖4所示,局部特征圖F1的作用有兩個:F1用來與全局特征圖F0進行融合,進而實現麥苗局部上下文監督信息與全局信息的融合;F1依次經過8倍最近鄰插值法上采樣、3×3卷積層生成預測分割圖FG,從而在網絡訓練階段實現對麥苗局部分割分支的優化。上采樣使得預測分割圖FG的尺寸與麥苗局部分割圖的尺寸保持一致;3×3卷積層平滑上采樣產生的噪聲,以得到數學性質更穩定的特征表達。
2.4 特征融合模塊
本文設計的特征融合模塊如圖7所示。首先,將尺寸為16×16×2的局部特征圖F1送入一個softmax層,得到兩個尺寸為16×16的張量。每個張量的元素值被歸一化到[0,1],表示對應每個像素被網絡判定為麥苗根莖部和非根莖部兩個類別的概率。其次,對表征局部上下文監督信息的麥苗根莖部特征張量執行repeat操作、復制256次,得到尺寸為16×16×256的新特征圖。最后,將新特征圖與全局特征圖F0逐元素點乘,得到融合后的特征圖F2。F2融合了麥苗的局部根莖信息與全局特征信息,進一步增強網絡對麥苗的識別能力,從而有效提高麥苗計數的準確率。
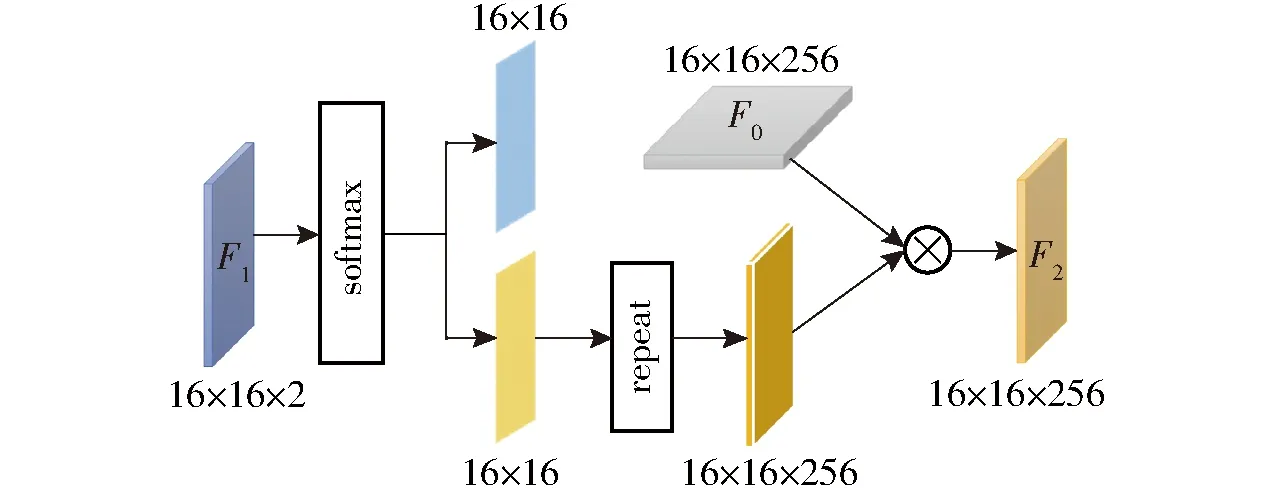
圖7 特征融合模塊
2.5 損失函數
如圖4所示,為了更充分地訓練P2P_Seg,分別對點回歸分支、分類分支和麥苗局部分割分支設計了LP、LCE、LG損失函數。
點回歸分支預測出M個候選點坐標,分類分支生成M個對應的置信度分數。在訓練階段,首先使用SONG等[27]提出的一對一匹配策略對網絡生成的候選點坐標與標注點坐標進行一對一匹配。與標注點坐標匹配成功的N個候選點坐標即為預測的麥苗位置坐標。它們對應的置信度分數標簽為1;剩余候選點坐標被分類為背景點,這些背景點對應的置信度分數標簽為0。這N個麥苗預測坐標與真實標注點坐標之間的距離越小越好,因此使用歐氏距離優化點回歸分支。分類分支則使用交叉熵損失函數(Cross entropy loss function,CE)進行優化。點回歸分支的損失函數LP和分類分支的損失函數LCE分別表示為
(5)
(6)
y——類別標簽,取0或1
分割分支生成的預測分割圖FG是像素級二分類結果。為緩解前景類與背景類之間存在的樣本不平衡問題,減少對計數精度的影響,本文引入SHI等[30]提出的逐像素加權焦點損失LG,即
(7)
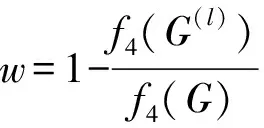
(8)
式中w——權重
l——通道對應的索引值,取0或1
G(l)——標簽分割圖中上標為l的通道形成的張量
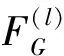
f3(·)——對張量的所有元素值求算術平均函數
γ——超參數,根據焦點損失(focal loss)[31]的推薦設置為2
f4(·)——對張量的所有元素值求和函數
組合上述點回歸分支、分類分支和麥苗局部分割分支的損失函數,得到總損失函數L為
L=LCE+λ1LP+λ2LG
(9)
式中λ1——超參數,取0.002
λ2——超參數,取0.005
3 實驗與結果分析
3.1 實驗設置
實驗使用的計算機配置為Intel(R)Core(TM)i7-10600 CPU@2.90 GHz;GPU為NVIDIA GeForce RTX3090,顯存容量為24 GB。實驗使用PyTorch作為深度學習框架,設置訓練批次為8、訓練輪數為1 000、學習率為0.000 1,采用Adam算法進行優化。基礎網絡在ImageNet上進行了預訓練,其訓練學習率設置為0.000 01。采用隨機裁剪和隨機旋轉對訓練樣本進行數據增強,每幅圖像被隨機裁剪為4份,每份尺寸為128像素×128像素。隨后,對裁剪后的圖像進行概率為0.5的隨機旋轉。
3.2 評價指標
使用平均絕對誤差(Mean absolute error, MAE)和均方根誤差(Root mean square error, RMSE)評價模型的性能。MAE用來衡量網絡的計數準確率;其值越小,表明麥苗株數的預測值越接近真實值。RMSE用來衡量網絡的穩定性;其值越小,表示網絡的穩定性越強、魯棒性越好。
3.3 麥苗根莖部區域的影響
為評估不同麥苗根莖部區域對麥苗計數結果的影響,對比本文提出的圓域半徑σ生成方法和SHI等[30]提出的核估計器σpi生成方法所得到的不同麥苗局部分割圖對P2P_Seg計數性能的影響。實驗結果如表2所示。

表2 不同麥苗局部分割圖對P2P_Seg的影響
由表2可知,使用本文的麥苗局部分割圖作為麥苗局部分割分支的學習目標時,可得到更準確的計數效果。這說明本文提出的圓域半徑σ生成方法能得到尺寸更為合理的麥苗根莖部目標區域,從而使得P2P_Seg的計數性能更好。
3.4 與其他方法對比
為進一步驗證P2P_Seg的性能,在自建麥苗數據集上與CSRNet、CANet、SCAR、BL、DM-Count和P2PNet進行對比實驗。其中,前5種方法為基于密度圖的計數方法,P2PNet為基于點標注的計數方法。如表3所示,P2P_Seg的MAE為5.86,RMSE為7.68,與P2PNet相比分別降低0.74、1.78。同時,與其他計數方法相比,P2P_Seg的兩種計數誤差亦最小。這說明增強局部上下文監督信息可以提高P2P_Seg對麥苗的識別能力,從而顯著提高計數精度。
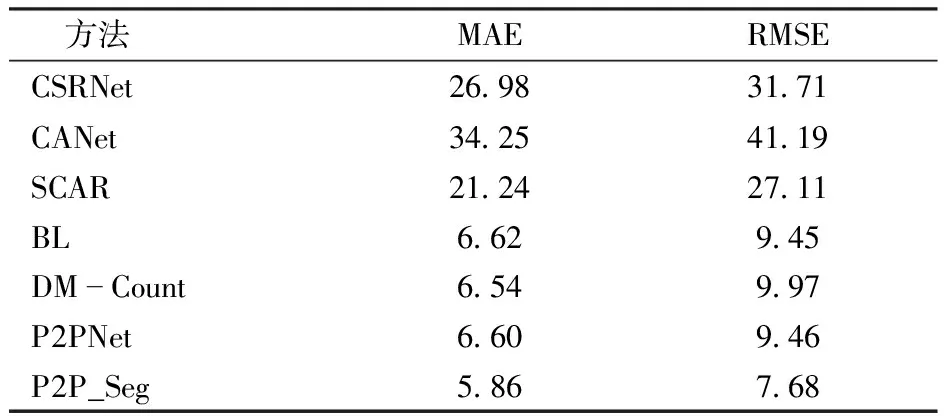
表3 在麥苗數據集上不同方法實驗結果對比
圖8展示了上述網絡在部分測試樣例上的可視化結果。圖8a為點標注的結果,直接作為P2PNet與P2P_Seg的真實值。圖8b為由點標注生成的密度圖像,作為基于密度圖計數方法的真實值。圖8c~8i分別為CSRNet、CANet、SCAR、BL、DM-Count、P2PNet、P2P_Seg的計數結果,通過密度圖進行可視化展示;密度圖的顏色越深,說明麥苗密度越大。這些基于密度圖方法的計數準確率不高,生成的密度圖不能直接標識出麥苗的位置,無法為下游任務提供更多的支撐信息。最后兩列分別為P2PNet和P2P_Seg的預測結果,這些結果均為更加直觀的麥苗坐標。由于P2P_Seg引入了局部分割分支以增強局部上下文監督信息,在對受遮擋、重疊和光照等因素影響的麥苗圖像計數時,其預測值更接近真實值,計數誤差更小。從頂部第1行到底部第6行,圖像中麥苗逐漸由稀疏變得稠密,并且圖像中存在枯葉、光照導致的陰影等噪聲,給現有的計數網絡識別帶來了不小的挑戰。但是,本文提出的P2P_Seg通過增強局部上下文監督信息,將注意力集中在麥苗根莖部,使其盡可能忽略其他噪聲,從而顯著提高了麥苗計數的準確率。同時,在處理不同稠密程度的麥苗圖像時,P2P_Seg皆取得最好的計數結果,表現出更好的泛化性能。
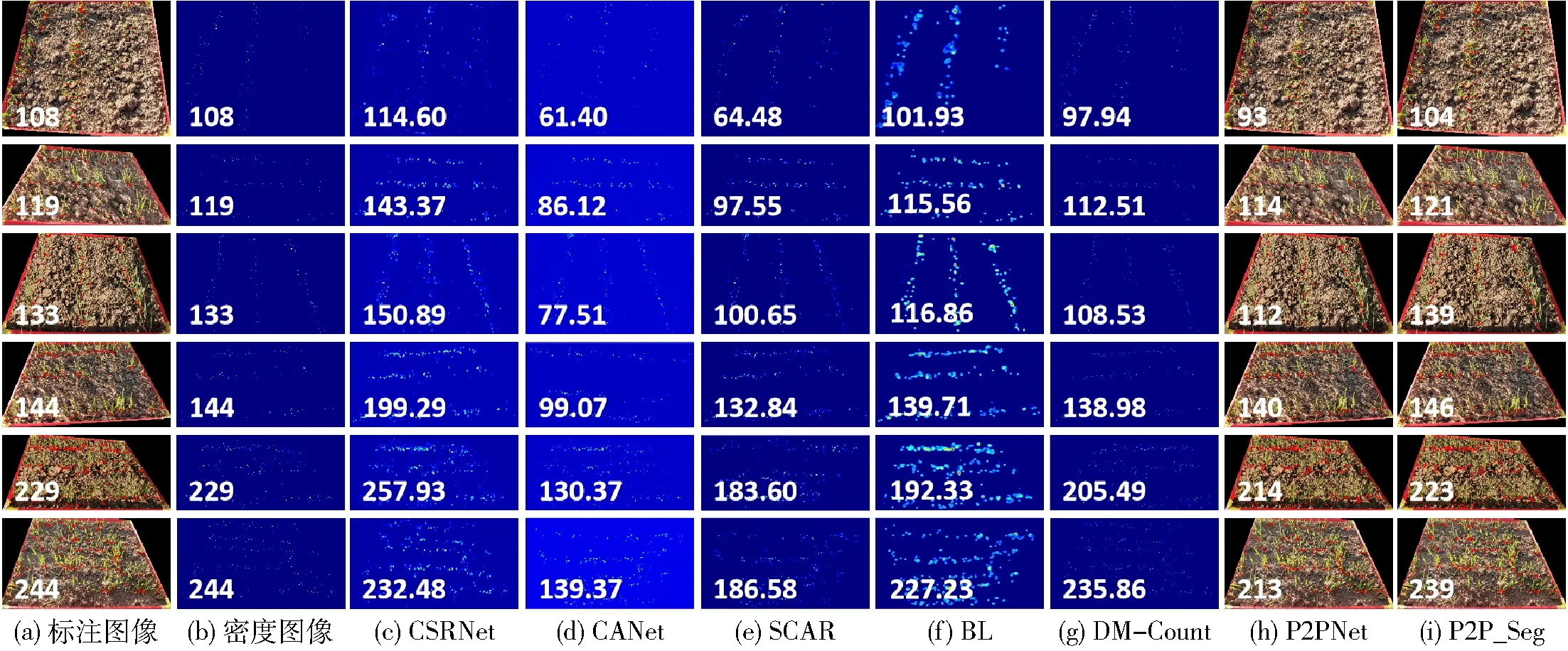
圖8 不同方法計數結果可視化圖
3.5 應用測試分析
為測試本文提出的P2P_Seg在實際大田環境下開展麥苗自動計數的性能,將訓練好的模型在實際獲取的89幅大田圖像上進行麥苗計數。表 4列出了部分大田圖像上的計數結果。這些圖像按照麥苗密度等級分為3類:密度偏小、密度中等和密度偏大。其中,圖像1~5為密度偏小麥苗圖像,圖像6~10為密度中等麥苗圖像,圖像11~15為密度偏大麥苗圖像。從表4中可以看出,P2P_Seg在所有密度等級大田麥苗圖像上都取得了最好的計數結果。
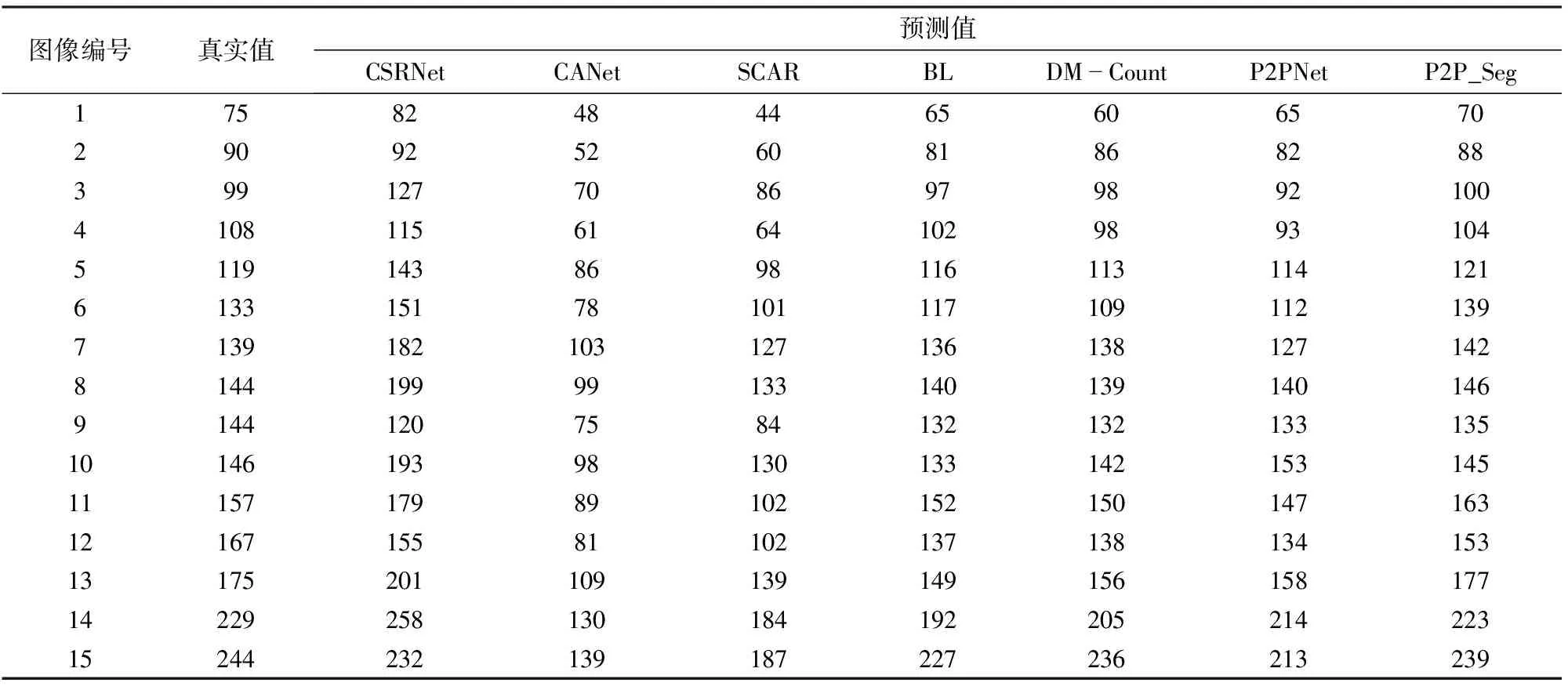
表4 部分大田圖像上不同方法麥苗計數結果對比
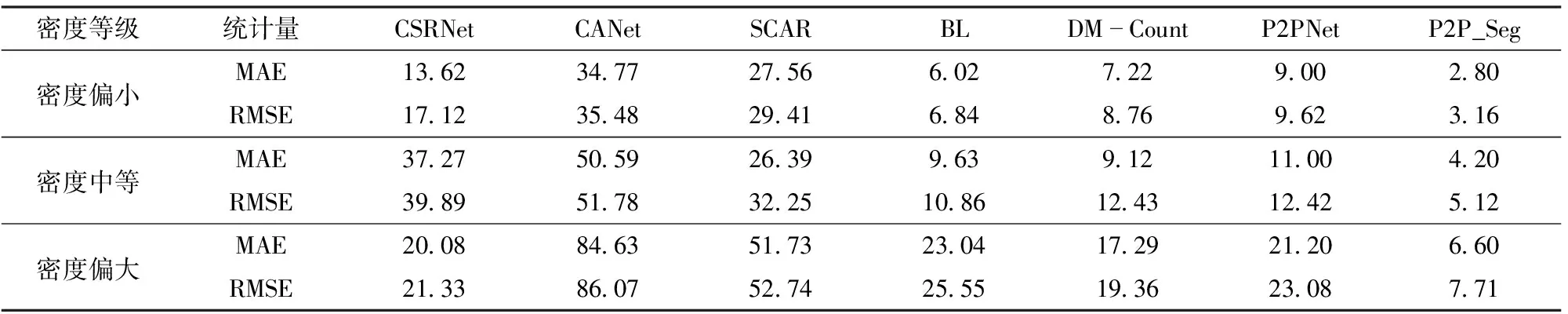
表5 不同密度等級麥苗圖像計數結果對比
表 5使用MAE和RMSE對這些計數結果進行統計對比。在密度偏小大田麥苗圖像上,P2P_Seg的MAE和RMSE分別為2.80和3.16,在所有方法中最好。在密度中等大田麥苗圖像上,P2P_Seg的MAE和RMSE分別為4.20和5.12,在所有方法中最好。在密度偏大大田麥苗圖像上,P2P_Seg的MAE和RMSE分別為6.60和7.71,在所有方法中最好。
3.6 誤計數和漏計數情況分析
受成像角度、麥苗密度和雜物遮擋等因素的影響,P2P_Seg的計數結果存在誤計數和漏計數的情況。圖9展示了這些情況,其中誤計數區域用矩形標識、漏計數區域用橢圓標識。
誤計數的主要原因包括成像角度不佳、麥苗相互遮擋和雜物遮擋等。如圖9a所示,因為成像方向與麥苗所在行平行,出現較嚴重的麥苗相互遮擋,從而出現誤計數(圖9a的區域①、②),盡管該區域的麥苗密度偏小。隨著麥苗稠密程度增加,麥苗相互遮擋變得嚴重,這會導致誤計數,如圖9b的區域⑤和圖9c的區域⑤所示。此外,雜物遮擋致使麥苗根莖部未完全展露也會出現誤計數(圖9d的區域④)。
漏計數的主要原因包括麥苗相互遮擋、雜物遮擋和苗株細弱等。麥苗相互遮擋導致的漏計數現象較為普遍,如圖9b的區域①、②、⑥、⑦、⑧和圖9c的區域①、②、③、④、⑥所示。同時,雜物遮擋導致的麥苗根莖部未完全展現(圖9d的區域①)或發育遲緩導致的苗株細弱(圖9d的區域③)也會引起漏計數。
4 結論
(1)針對光照、遮擋和重疊等因素導致的現有計數模型性能受限問題,提出增強局部上下文監督信息的麥苗計數模型P2P_Seg。該模型在P2PNet的基礎上引入麥苗局部分割分支以獲取更多的麥苗局部上下文監督信息,并使用逐元素點乘機制融合局部上下文監督信息與基礎網絡提取的全局信息。對網絡結構的改進和專門設計的特征融合策略提高了模型的特征提取能力,增強了模型對光照、遮擋和重疊等因素的對抗能力,提高了模型的魯棒性,顯著減少了模型對麥苗的誤計和漏計。
(2)在自建麥苗數據集上,與其他主流計數方法進行了對比實驗。結果表明,P2P_Seg的MAE為5.86,RMSE為7.68;與P2PNet相比,分別降低0.74和1.78。同時,與其他計數方法相比,P2P_Seg的兩種計數誤差亦最小,計數性能最好。
(3)在實際大田環境下進行的麥苗自動計數測試表明,P2P_Seg在密度偏小、密度中等和密度偏大3種等級的大田麥苗圖像上都取得了最好的計數結果。P2P_Seg能夠更準確地預測出麥苗的株數,可有效緩解傳統人工數苗費時費力的問題。同時,P2P_Seg還能預測出麥苗的位置,為種植規劃和良田培育等下游任務提供有效支撐信息,更有助于實際農業生產。
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
中華手工(2017年2期)2017-06-06 23:00:31
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
中外會展(2014年4期)2014-11-27 07:46:46
民生周刊(2012年10期)2012-10-14 09:06:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
