基于Lasso特征選擇乳腺癌二分類算法研究
2023-08-04 07:21:12辛瑞昊
吉林化工學院學報 2023年1期
馮 欣,張 航,辛瑞昊
(1.吉林化工學院 理學院,吉林 吉林 132022;2.吉林化工學院 信息與控制工程學院,吉林 吉林 132022)
乳腺癌[1](Breast cancer)是一種新發數高的一種疾病,已然成為一種噩夢。因此,研究乳腺癌發病機理,降低乳腺癌死亡率,提高乳腺癌預后效果迫在眉睫,這也是現在醫療領域所面臨的一個巨大挑戰。
在目前研究中,已經有很多學者針對乳腺癌分類提出自己的模型去展開研究。王冬[2]等人針對乳腺癌分類診斷提出了一種基于人工魚群優化的隨機森林模型,其最終準確率能達到97.48%。章飛[3]等人針對女性乳房造影圖片的特征提取數據集進行分類診斷,使用多種機器學習算法建立分類模型對比。Lahoura[4]等人針對乳腺癌分類診斷問題提出一種基于云計算的無監督極限學習機(ELM)乳腺癌遠程診斷系統,診斷準確率達到98.68%。Wang[5]等人將ELM與卷積神經網絡(CNN)相結合針對乳腺癌分類問題進行檢測,其實驗結果效果良好。因此對乳腺癌的分類研究已然成為現在的一個研究趨勢。
本研究利用乳腺癌公開數據集,針對不平衡數據采用隨機過采樣算法,特征選擇采用了Least absolute shrinkage and selection operator(Lasso)回歸算法[6]與序列前向選擇算法。最后使用多種分類器的準確率對本研究提出的算法進行一定的評估,同時對最優臨床特征進行可視化分析,本研究將為乳腺癌的診斷研究提供一定的參考。
1 特征選擇模型及方法
1.1 Lasso回歸模型
Lasso回歸[7-9]是一種壓縮估計,該模型因為懲罰項而更加精練,它的另一個優勢在于子集收縮的同時保留了回歸系數的壓縮。在考慮一般線性問題的時候,線性函數矩陣優化目標為
(1)
其中β表示估計參數向量;y表示觀測向量;X表示變量矩陣值;觀測值是由變量值計算得到的。
Lasso的優化目標為
(2)
Lasso回歸是在線性回歸的基礎之上添加了正則化得到的,見公式(2)。由于Lasso回歸能夠將一些回歸系數歸零,這樣可以有效地解決各特征之間的多重共線性困擾,這將成為本研究中特征選擇的一個新方法。
1.2 SFS模型
序列前向選擇[10-11](SFS,Sequential Forward Selection)是一種搜索策略算法。主要思想為從空集Y0開始,每次選擇一個特征x加入最新的特征子集Y中,可以保障特征函數最優。其算法步驟如下:
1.建立空的特征子集Y0={?};
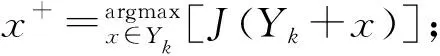
3.更新目前最優特征子集:Yk+1=Yk+x+,k=k+1;
4.轉到第2步。
1.3 評價指標
機器學習中的預測結果一般分為如下幾種結果,見表1。其中True Positive(TP):把正樣本預測為正。True Negative(TN):把負樣本預測為負。False Positive(FP):把負樣本預測為正。False Negative(FN):把正樣本預測為負。本研究的評價指標準確率[12-13](ACC),它的求解公式為
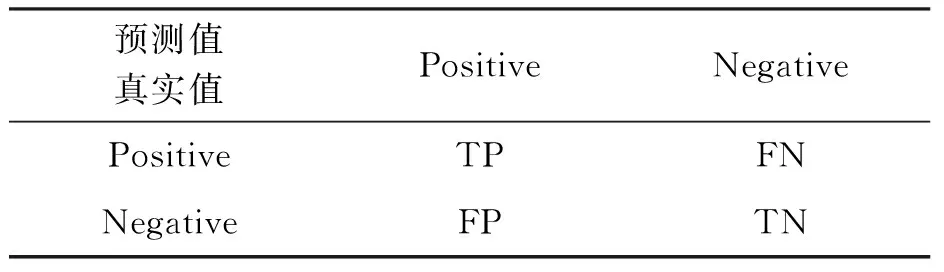
表1 分類預測結果
(3)
通過上述評價指標來評判模型是否合理,以及模型結果是否符合預期結果。
2 基于不平衡數據集分類模型構建
本研究實驗流程見圖1。首先對原始數據集進行標準差標準化處理方法,針對平衡數據集采用的隨機過采樣[14]方法。接下來是特征選擇這塊,使用Lasso回歸算法做初步的特征選擇,使用五倍交叉驗證取五次回歸系數不為0交集特征做接下來的實驗。接下來使用基于隨機森林(RF)的序列前向選擇算法,經過分類器取最優ACC結果。最終將得到的最優臨床特征進行多方面的可視化分析,具體情況見下述章節。
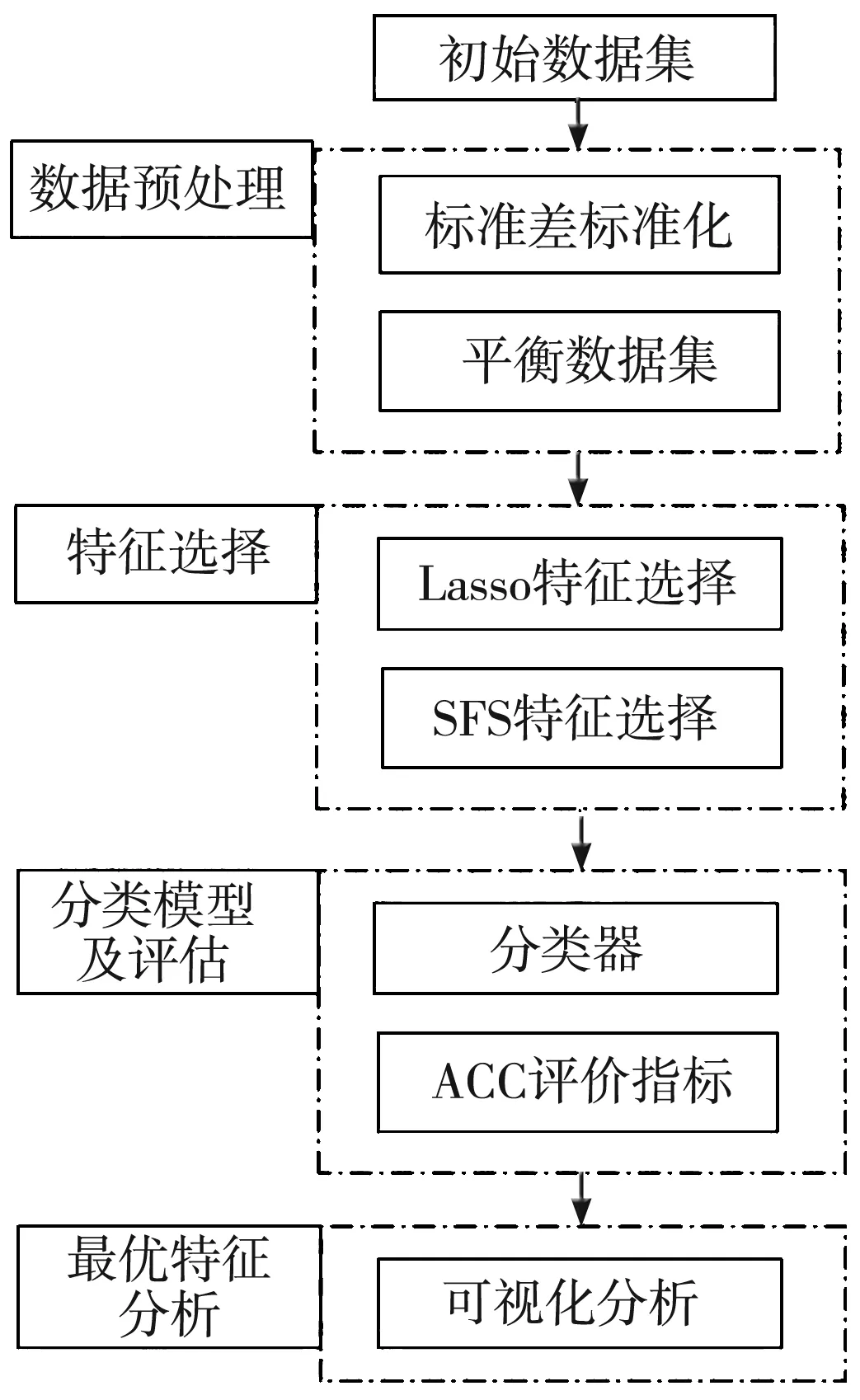
圖1 實驗流程圖
3 實驗結果與分析
3.1 數據集介紹
本研究使用威斯康星州的乳腺癌公開數據集[2]進行實驗,該數據集有357例輕度患者,212例重度患者。數據集中含有32個屬性,其中含有30個特征。數據集根據平均值、標準誤差以及最值將細胞核分為三組,數據集特征介紹見表2。
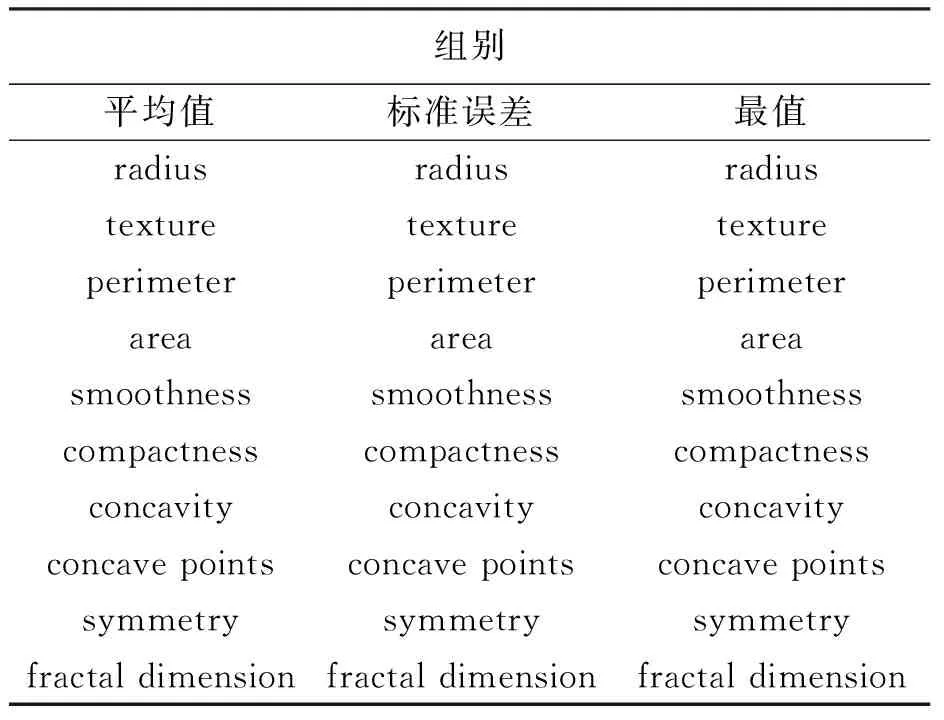
表2 數據集特征介紹
3.2 實驗結果
利用第2節中所述算法對乳腺癌診斷分類進行測試。首先利用標準差標準化處理完數據集之后,使用隨機過采樣算法進行數據集的平衡,平衡后的樣本個數見表3。接下來運用Lasso特征選擇算法,運用五倍交叉驗證取回歸系數不為0的特征的交集,特征由原始30個變成8個,進行接下來的實驗。
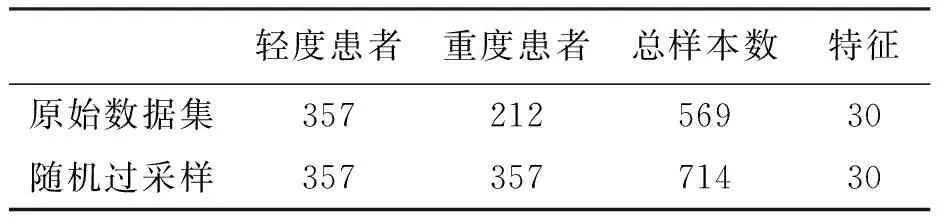
表3 數據預處理:隨機過采樣算法平衡數據集
第二步特征選擇算法使用了SFS算法,此算法結合隨機森林分類器對其進行最優特征子集評估,本研究從8個特征依次往下遞減,去尋找最優特征子集區間。為了保證實驗的穩定性,在進行分類診斷準確率評估的時候結合了十倍交叉驗證,其評價結果見表4。表4中出現的分類器依次為:支持向量機(Support Vector Machine,SVM[15])、K鄰近法[16](K-Nearest Neighbor,KNN)、決策樹(Decision Tree,DT)、樸素貝葉斯(Naive Bayes,NB)、隨機森林(Random forest,RF)、線性判別分析(Linear Discriminant Analysis,LDA)、自適應提升算法(Adaptive Boosting,AdaBoost)和極限梯度提升算法(Extreme Gradient Boosting,XBG)。根據表4得到最優特征子集以及最適用模型的分類器,最優特征子集將用于下一步分析。由表4可知,最優特征子集的特征個數為6個的時候最好,并且最優的是隨機森林分類器。最優6個特征為:平均半徑(radius mean)、平均周長(perimeter mean)、平均區域(area mean)、區域(area se)、最差周長(perimeter worst)和最差對稱性(symmetry worst)。接下來探究了6個特征對乳腺癌輕度患者與重度患者的顯著差異性,見3.3節。
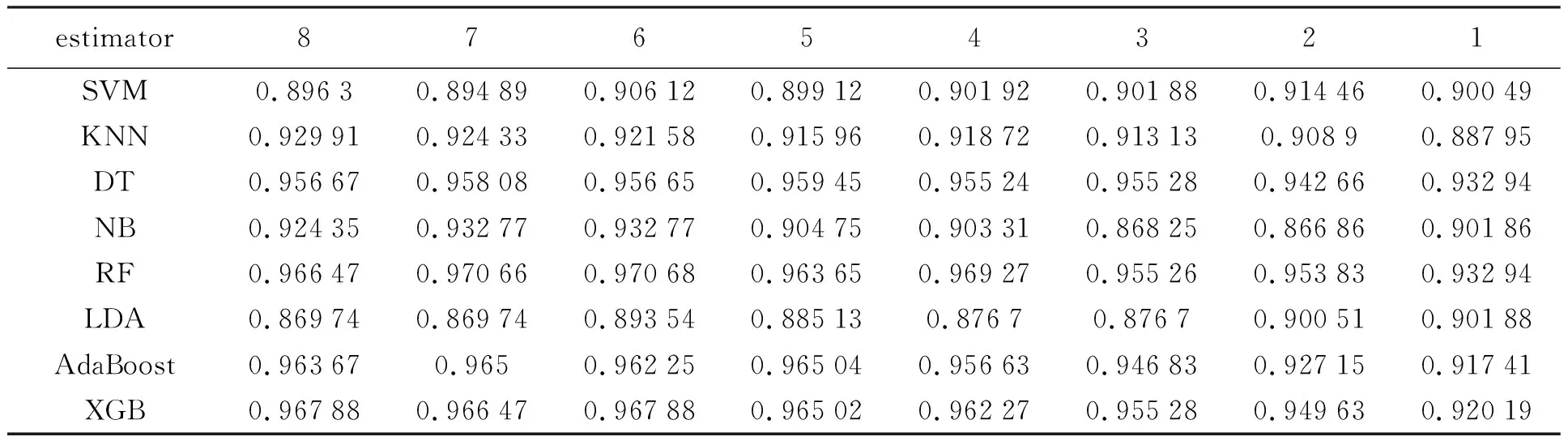
表4 UCI乳腺癌二分類實驗結果
3.3 臨床特征可視化分析
本研究針對實驗最優特征子集進行單個特征分析,為了證實特征對于區分不同程度的患者樣本的效性,從最優的6個臨床特征的數據分布情況(箱線圖)、對應的student-t檢驗[17](Student's t test,T-test)的p-value[18]值以及主成分分析[19-20](Principal Component Analysis,PCA)后的降維圖等不同角度來進行驗證。見圖2,本研究通過箱線圖將最優的6個臨床特征進行數據集的分布顯示,通過不同顏色表明不同程度的患者類型,其中黑色表示重度患者,白色表示輕度患者,從圖2中可見,單個特征的數據集在區分二分類問題上有一定的區分度。圖3是介紹了每個特征的p-value值,一般p-value值小于0.05可以證明該特征在不同分類上具有顯著差異性。由于本實驗中得到的p-value值太小,為了能可視化出來,使用了“-log10(p-value)”函數(此函數為單調遞減函數)進行了變化,同時使用“-log10(0.05)”進行對比(此函數為p-value=0.5),最終結果對比見圖3,可視化圖形很好地展示6個特征的單獨p-value值均小于0.05,為顯著差性特征。PCA降維一般用于提取數據的主要特征分量,在維度壓縮的同時盡可能保留更多的變量。

圖2 特征箱線圖分布情況
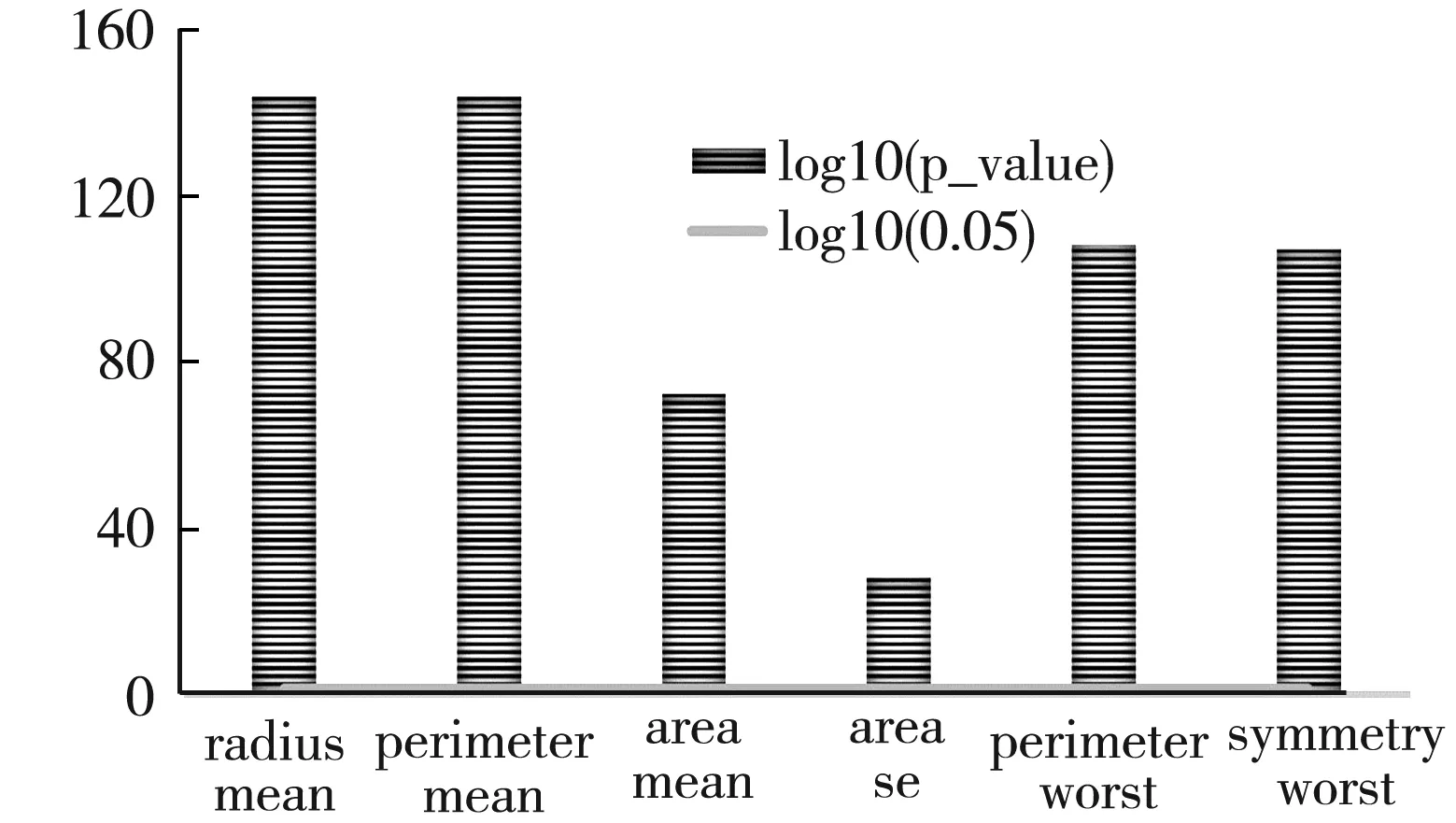
圖3 特征T-test的p_value比較
本研究將針對上述6個特征進行降維分析,進一步通過可視化驗證最優特征區分重度與輕度患者的優越性。側重于三維可視化,所以特征也是壓縮到3個。如圖4所示,三維坐標分別表示壓縮后的三個特征值,能夠很好地看見不同類別的樣本經過PCA降維分析之后比較容易辨別。此處可視化展示將從另外的角度說明最優特征子集對于數據集的分類效果比較好。
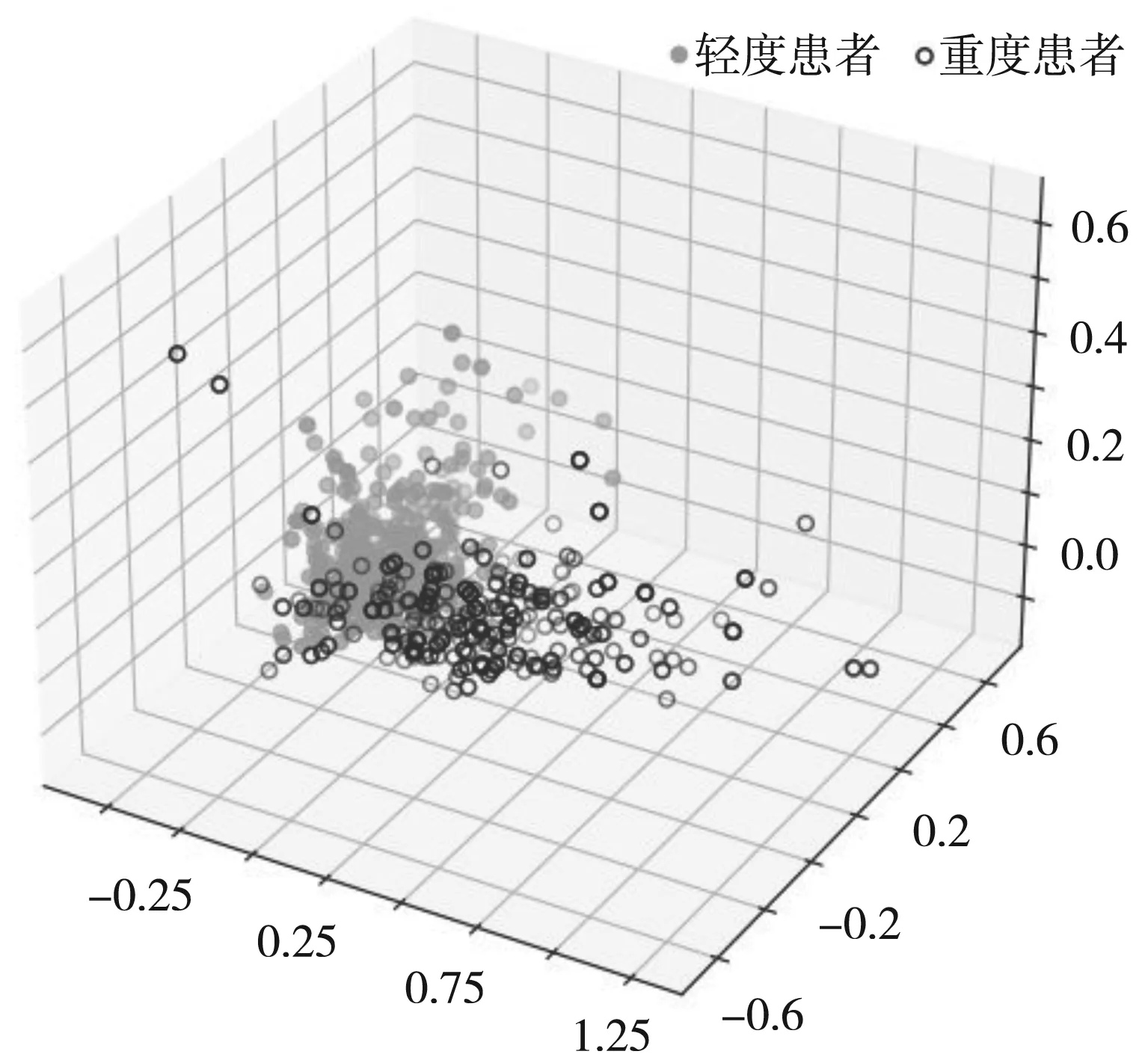
圖4 PCA降維的3D圖
3.4 SEER數據庫驗證
為了證實本研究提出算法的優越性,繼而針對SEER(The Surveillance,Epidemiology,and End Results)[21]數據庫(https://seer.cancer.gov/)中乳腺癌數據集進行了進一步驗證。本研究選擇了最近的時間年份(2015年)診斷數據進行實驗探究,根據臨床常用字段加上意義取舍。最終保留下來17 636個樣本,其中2 623個死亡樣本,15 013個存活樣本數據,特征為:種族(Race recode)、性別(Sex)、原發灶部位(Primary Site)、組織學類型(Histologic Type ICD-O-3)、雙側/單側(Laterality)、腫瘤大小(CS tumor size)、腫瘤進入程度(CS extension)、淋巴結情況(CS lymph nodes)、轉移部位(CS mets at dx)、生存時間月份(Survival months)和是否有多原發癌(First malignant primary indicator)11個特征。經過對原始數據集的數據進行標準差標準化與隨機過采樣的數據預處理階段,接下來運用Lasso特征選擇算法,運用五倍交叉驗證取回歸系數不為0的特征的交集,特征由原始11個變成10個,進行SFS算法,特征從10個依次遞減,至于找到最優特征子集。結合分類器最終得到以下評價結果見表5,根據表格中內容可知,最優特征子集的特征個數為6個的時候最好,并且最優的是隨機森林分類器。如圖5所示為了使實驗結果更好地展示出來,橫坐標表示最優特征組合個數,縱坐標表示該子集下的分類準確度,結合不同分類器找到最優結果是隨機森林分類器,準確度達到97.24%,為臨床醫療診斷提供了理論支持。根據上述實驗最終得到的6個特征為:Race recode、Primary Site、Laterality、CS tumor size、Survival months和First malignant primary indicator。上述特征組成的子集對區分乳腺癌的生存與死亡分類有顯著差異性。
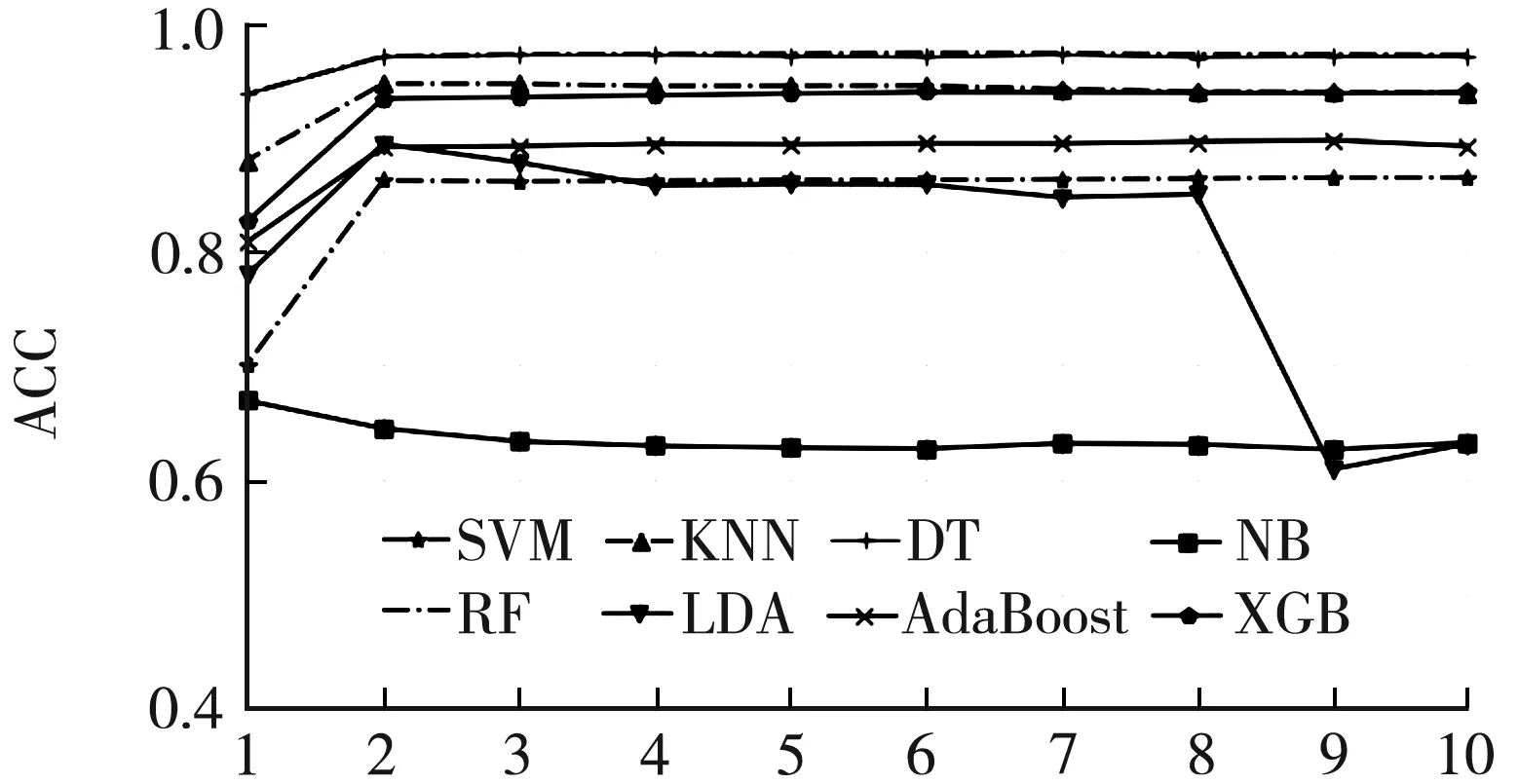
number圖5 不同分類器二分類準確度
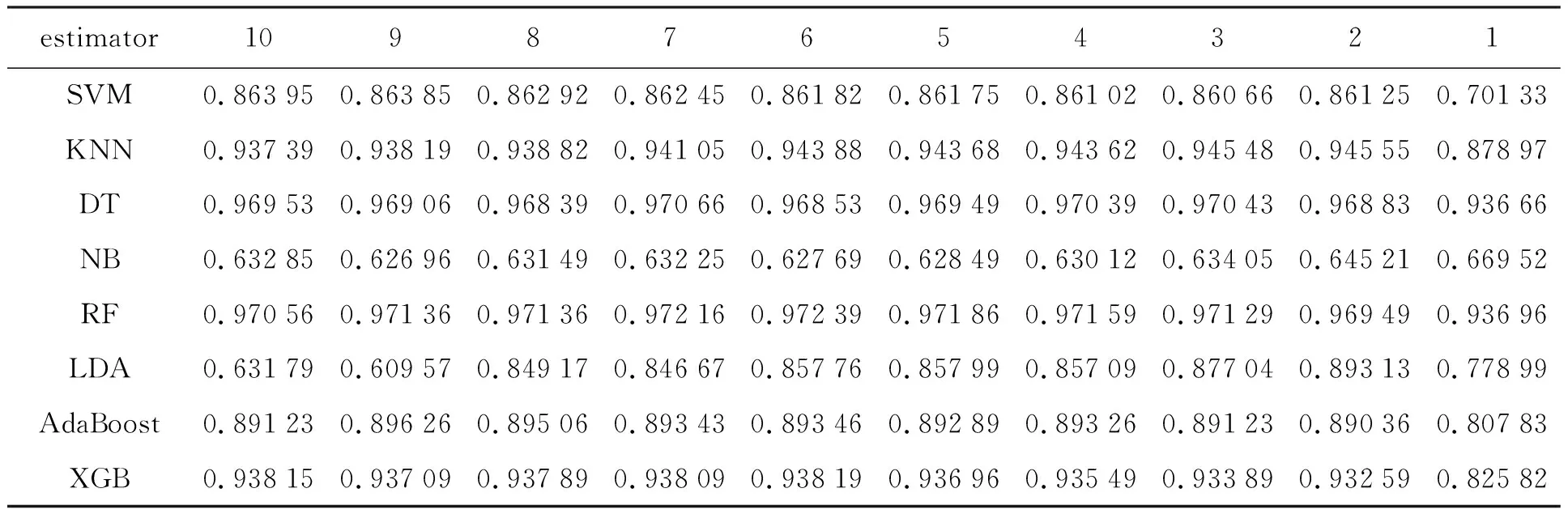
表5 SRRE乳腺癌二分類實驗結果
4 結 論
本研究針對威斯康星州的乳腺癌數據集,平衡數據后,提出Lasso回歸與SFS相結合算法進行特征選擇步驟,從而減少對冗余臨床特征的研究,結合8種分類器進行模型最終評價,為乳腺癌分類診斷提供新的探究思路。通過數據可視化展示出最優特征子集的乳腺癌分類效果圖,為醫療大數據行業的臨床研究提供了理論支撐。為了驗證本研究算法的優越性,利用SEER數據庫中的乳腺癌數據集進行驗證,通過本文的算法的驗證,從最初的11個特征篩選到最后的6個特征,實驗結果表明乳腺癌的分類準確率達到97.24%。本研究提出的方法模型在威斯康星州的乳腺癌公開數據集和SEER數據庫乳腺癌數據集中體現比較好,但未在其他疾病的數據集中探究,這將成為未來的研究重點。
猜你喜歡
中老年保健(2022年6期)2022-08-19 01:41:48
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中國生殖健康(2019年2期)2019-08-23 08:11:42
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2019年6期)2019-01-06 09:20:12
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
祝您健康(2018年5期)2018-05-16 17:10:16
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
