配網重過載預警及配網容量規劃研究
2023-08-14 02:21:08趙婷婷
通信電源技術 2023年10期
趙婷婷
(國網山西省電力公司 運城供電公司,山西 運城 044000)
0 引 言
在開展影響配變重過載現象的相關研究中,通過對配電網歷史運行數據、配電網停電搶修工單、變壓器負荷數據以及氣象數據等數據進行分析可以看出,以多源異構數據為基礎進行數據挖掘,可以有效提高對配網重過載相關的特征指標集的分析[1,2]。在此基礎上,通過構建針對配網負載情況的分級預測框架,不僅可以實現對配網重過載風險的短期預警,提升迎峰度夏的預警能力,而且能識別出空載、輕載線路,為后期容量規劃提供解決思路[3]。因此,從配電網實際出發,整合配電網多源異構數據,對配網重過載預警和容量規劃技術進行深入研究十分必要[4]。
現階段,在具體的配網重過載預警及配網容量規劃過程中,由于影響停電的許多因素難以以數據值的形式呈現和獲取,導致特征指標體系的建立面臨著一定的困難,使得預警方法無法全面考慮所有的影響因素[5]。此外,在對配網容量進行規劃時,也需要充分考慮城鎮用電空心化問題,既要避免重過載導致的容量不足,又要關注由于輕載或空載帶來的容量過剩問題[6]。只有這樣才能切實提升配網的供電能力和經濟效益。
針對此,本文提出配網重過載預警及配網容量規劃研究,通過構建配網負載情況分級預測模型對配網重過載情況作出及時預警,同時結合實際需求對配網容量進行合理規劃。
1 配網重過載預警及配網容量規劃設計
1.1 歷史數據的配網重過載預警
為了提高預警效果的可靠性,本文采用K-means聚類的方式對配網的基礎運行數據進行處理[7]。基于K-means 聚類的停電數據集采樣方法的算法流程如下。
步驟1:對原始配變數據集進行數據預處理,包括基于K-最近鄰算法(K-Nearest Neighbor,KNN)的缺失值處理和基于STL-ESD 算法的異常值處理,然后進行特征選擇后得到帶有停電(記y=1)和不停電(記y=0)標簽的特征數據集D,計算公式為
步驟2:將特征數據集D進行切分,選取其中的80%為訓練數據集D1,20%為測試數據集D2。
步驟3:對訓練數據集D1中的不停電數據集T0進行聚類,隨機選取k個聚類質心點為μ1,μ2,…,μk∈Rn。
步驟4:對于(xi,yi)∈T0,計算所屬簇,則有
步驟5:對于每一個簇j,重新計算該簇的質心為
步驟6:計算簇心的最大移動距離,具體的計算方式可以表示為
若d>ε,更新μj′=μj,跳到步驟7 執行。
步驟7:對上述聚類結果的每一簇按照比例進行隨機欠采樣,最終得到平衡訓練結果。當實際的實施配網運行數據大于平衡訓練結果時,則進行預警。
通過這樣的方式,對配網中重過載情況作出及時響應。
1.2 配網容量規劃
在上述基礎上,本文采用AdaBoost 算法實現對配網不同饋線對應容量的規劃。在具體的實施過程中,將加權后的全部數據樣本對下一個弱分類器進行訓練,直到迭代終止,最后根據某種組合方法對所有的弱分類器進行組合,并用測試數據進行驗證,具體的實現過程如下。
步驟1:輸入訓練數據集。
步驟2:假設數據集中每個樣本的權值開始都是均勻的,則各個樣本初始權值wli的計算方式可以表示為
步驟3:設定最大迭代次數(即最大線性組合弱分類器個數)為T,那么則有t=1,2,…,T。
步驟4:訓練第t個弱分類器時,第i個樣本的權重為wti,訓練得到的基分類器表示為Gt(x)。
步驟5:計算數據集D在Gt(x)上的分類誤差率,具體可以表示為
式中:εt為分類誤差率;I為指示函數。
步驟6:將Gt(x)的分類誤差率εt與指定的閾值比較,閾值設置為0.5。當εt的取值范圍為(0,0.5)時,表示分類器的分類效果比隨機分類要好,則執行步驟7;當εt的取值范圍大于等于0.5 時,表示分類器的分類效果比隨機分類還要差,那么需要進行下一輪迭代;當εt的取值結果為0 時,即樣本全部正確分類。
步驟7:根據分類誤差率εt計算基分類器Gt(x)的權值,具體的計算方式可以表示為
式中:權值αt為四基分類器Gt(x)線性組合中的權值系數,該系數反映的是該基分類器在最終的強分類器中的重要程度。因此,當基分類器Gt(x)分類的誤差εt越小時,它在最終分類器中越重要,對應輸出最終分類器,也就是配網容量可以表示為
按照這樣的配網容量規劃方式,確保各饋線對應的輸出滿足實際負荷需求。
2 測試與分析
2.1 測試環境
在測試階段,本文以10 kV 配電網作為測試環境,其連接方式為三端柔性多狀態開關(Flexible Multi-State Switch,FMSS)連接,對應的拓撲結構設置情況如圖1 所示。
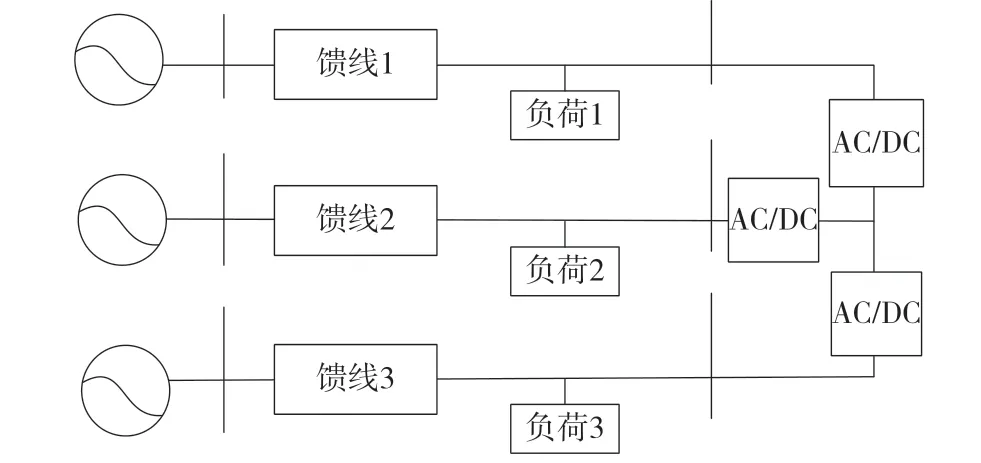
圖1 測試配網的拓撲結構
結合圖1 可以看出,測試配網環境中共包括3條饋線,其中饋線1 的負荷承載能力為4.0 MW,饋線2 的負荷承載能力為9.0 MW,饋線3 的負荷承載能力為8.0 MW。在此基礎上,本文構建了不同的用電場景展開測試,具體如表1 所示。
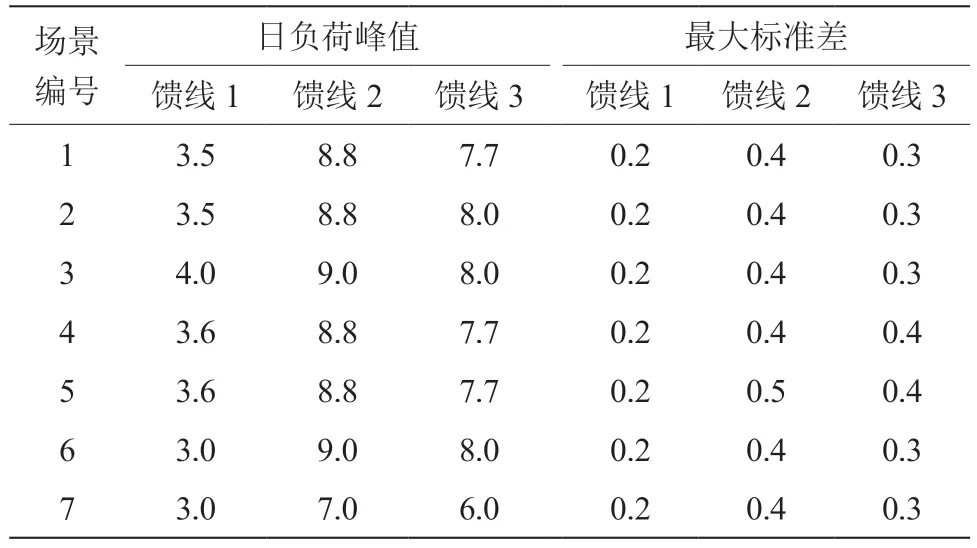
表1 測試場景設置 單位:MW
按照表1 所示的方式,設置7 種不同的測試場景,同時采用本文設計的配網重過載預警及配網容量規劃方法展開測試分析。為了提高測試結果的分析價值,分別采用營配大數據融合預警與規劃方法以及多參數分析的預警與規劃方法作為對照組,開展對比測試。
2.2 測試結果與分析
在對測試結果進行分析的階段,利用線路掉閘率作為評價指標,對不同方法的重過載預警效果進行分析,得到的數據結果如表2 所示。
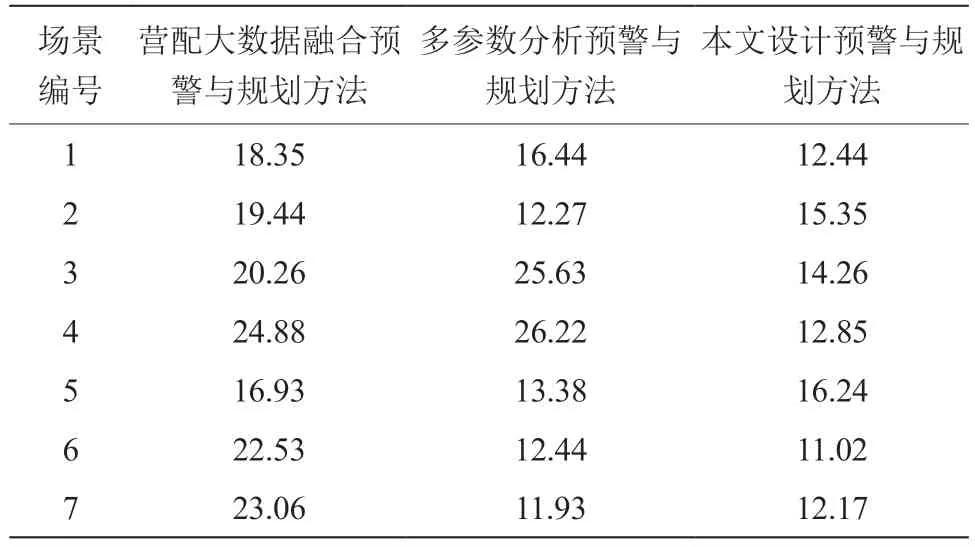
表2 不同方法線路掉閘率統計表 單位:%
結合表2 所示的測試結果可以看出,在3 種不同方法的測試結果中,對應的線路掉閘率存在較為明顯的差異。其中,在營配大數據融合預警與規劃方法中,不同場景下的線路掉閘率穩定在15.0%~25.0%,最大值達到了24.88%。在多參數分析預警與規劃方法中,不同場景下的線路掉閘率出現了較為明顯的波動,最小值僅為11.93%,最大值達到了26.22%。相比之下,在本文設計的預警與規劃方法中,不同場景下的線路掉閘率穩定在20.0%以下,最大值僅為16.24%。測試結果表明,本文設計方法可以實現對重過載情況的有效預警,在降低線路掉閘率方面具有良好的實際應用價值。
在此基礎上,對不同方法對應的配網容量規劃效果進行分析,具體的評價指標為各饋線的日期望缺供電量,得到的數據結果如表3 所示。
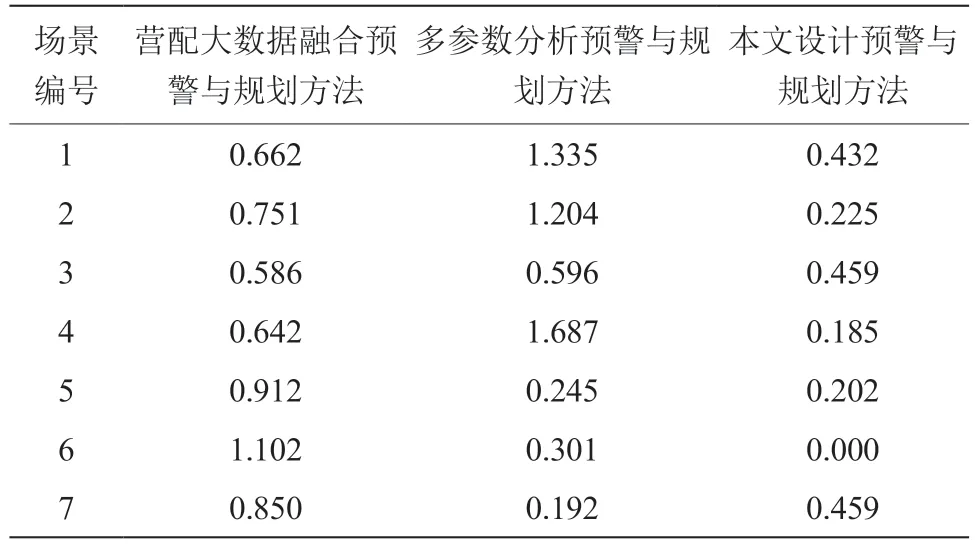
表3 不同方法下線路的日期望缺供電量 (單位:MW·h)
結合表3 中的測試結果可以看出,在3 種方法的測試中,線路整體的日期望缺供電量均穩定在2.0 MW·h 以內,但是具體數值仍存在一定的差異。其中,營配大數據融合預警與規劃方法對應的線路日期望缺供電量基本穩定在1.100 ~0.600 MW·h,最大值達到了1.102 MW·h;多參數分析預警與規劃方法對應的線路日期望缺供電量與掉閘率表現出了相同的發展趨勢,波動較為明顯,最小值僅為0.192 MW·h,最大值達到了1.687 MW·h。相比之下,本文設計預警與規劃方法對應的線路日期望缺供電量始終在0.50 MW·h 以下,最大值僅為0.459 MW·h。測試結果表明,本文設計方法可以實現對配網容量的合理規劃,在降低線路日期望缺供電量方面具有良好的實際應用價值。
3 結 論
在對配網進行規劃管理的過程中,如何實現對電源布點、道路建設、市政規劃、用電負荷分布情況的協同考慮,保障配網容量規劃結果的合理性是亟待解決的問題之一。本文提出配網重過載預警及配網容量規劃研究,大大提高了配網供電的可靠性,對應的應急響應能力也得到了進一步提升。希望通過本文的研究可以為客戶服務水平提供技術保障和支持。
猜你喜歡
公民與法治(2020年11期)2020-07-25 02:02:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中國衛生(2016年2期)2016-11-12 13:22:16
華東科技(2016年10期)2016-11-11 06:17:41
Coco薇(2016年2期)2016-03-22 02:42:52
中國工程咨詢(2016年4期)2016-02-14 07:28:28
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
