基于高光譜技術的黑果腺肋花楸成熟度判別及多酚含量檢測模型構(gòu)建
2023-08-15 01:10:28南希駿周泉城李婭婕厲佳怡王紅磊徐文慧劉依諾倪乙丹郭婷婷盛桂華
食品工業(yè)科技 2023年15期
關鍵詞:模型
南希駿,周泉城,李婭婕,厲佳怡,王紅磊,徐文慧,劉依諾,倪乙丹,郭婷婷,嵇 威,盛桂華
(山東理工大學農(nóng)業(yè)工程與食品科學學院食品科學系,山東淄博 255049)
黑果腺肋花楸(Aronia melanocarpa,AM,簡稱黑果)果實含有豐富的營養(yǎng)物質(zhì),是多酚含量最高的植物之一[1]。黑果多酚可以清除自由基、減少脂質(zhì)過氧化并增強抗氧化酶活力等,具有抗炎、抗癌、降血糖、降血壓、調(diào)節(jié)心血管疾病以及改善腸道菌群[2?7]等作用。近年來,黑果的營養(yǎng)價值與功能性得到越來越多的認可,市場需求不斷擴大。而黑果多酚含量是評價黑果品質(zhì)的關鍵。黑果的成熟度判別,可以快速的識別黑果所處時期的成熟度,可為黑果的適時采摘提供依據(jù),并可以結(jié)合黑果多酚含量檢測結(jié)果,為黑果產(chǎn)品生產(chǎn)提供優(yōu)質(zhì)原料和數(shù)據(jù)支持。但是黑果成熟度判別方法報道較少,且傳統(tǒng)的破壞性檢測黑果多酚的福林酚法[8]耗時費力,滿足不了快速檢測的需求,因此,建立一種高效、快速、可靠且對黑果后續(xù)的生產(chǎn)及加工影響小的判別和檢測方法對黑果相關產(chǎn)業(yè)的發(fā)展具有重要意義。
近年來,具有實時監(jiān)測能力的無損光學技術引起了人們的興趣,高光譜成像(Hyperspectral imaging,HSI)技術可以獲得樣品的全部光譜信息,并與圖像信息相結(jié)合,可以判別外部特征和測定內(nèi)部成分[9],具有快速、無損、識別精度高等諸多優(yōu)點。國內(nèi)外許多學者利用HSI 技術對果蔬的成熟度判別進行了研究,李軍宇等[10]通過HSI 技術結(jié)合可溶性固形物和硬度值建立了不同成熟度李果實的偏最小二乘法(Partial least square,PLS)判別模型,準確度達91.25%,證明利用HSI 技術對不同成熟度李果實進行判別是可行的。國內(nèi)外許多學者還利用HSI 技術對果蔬內(nèi)部品質(zhì)方面進行了檢測研究,楊曉玉等[11]使用化學方法測定了靈武長棗維生素C 含量,并與高光譜信息結(jié)合,建立了支持向量機(Support vector machine,SVM)高光譜檢測模型,可以滿足HSI 技術對靈武長棗維生素C 含量的無損檢測。Yang 等[12]采用化學方法提取并測定荔枝果皮花青素含量,利用HSI 技術并采用徑向基函數(shù)神經(jīng)網(wǎng)絡算法與花青素含量建立融合模型,并進行了可視化,可以顯示荔枝果皮內(nèi)花青素的分布。以上研究表明,HSI 技術在果蔬快速、無損成熟度判別及內(nèi)部品質(zhì)檢測方面具有一定的研究基礎和廣闊的應用前景。目前,關于黑果的成熟度判別以及黑果多酚的無損快速檢測的研究未見報道,這限制了黑果的高值化應用及黑果多酚的功能性開發(fā)。
基于上,本研究擬利用高光譜成像技術對黑果進行掃描得到光譜數(shù)據(jù),并采樣化學法測定其多酚含量,將光譜信息與多酚含量數(shù)據(jù)通過Unscrambler X進行預處理及建立模型,采用MATLAB 提取特征波長并優(yōu)化模型,構(gòu)建基于高光譜的黑果成熟度判別以及多酚含量檢測的最優(yōu)模型,以達到對黑果的成熟度判別以及多酚含量無損檢測的目的,從而為黑果的適時采摘、品質(zhì)評價及相關產(chǎn)品的深度開發(fā)和高值化應用提供理論基礎和技術支持,促進黑果產(chǎn)業(yè)的發(fā)展。
1 材料與方法
1.1 材料與儀器
富康源1 號黑果腺肋花楸果實 由山東省淄博市林業(yè)保護發(fā)展中心種植并提供;沒食子酸標準品、乙醇、鹽酸等其它常用試劑 購自上海愛純生物科技有限公司。
HSI-eswir-400-2500 高光譜農(nóng)業(yè)物料分選儀五鈴光學股份有限公司;UV759CRT 型掃描型紫外可見分光光度計 青島聚創(chuàng)環(huán)保集團有限公司;AL-1D4 精密分析天平 梅特勒-托利多儀器(上海)有限公司;TDL-40B 低速離心機 上海安亭科學儀器廠。
1.2 實驗方法
1.2.1 黑果的采集 根據(jù)文獻報道,黑果進入成熟期后,隨著成熟度的增加,其果實從紅色變?yōu)樽仙罱K變?yōu)楹谏喾雍恳搽S著成熟度的變化發(fā)生改變[13?14]。山東省淄博市林業(yè)保護發(fā)展中心種植的黑果,7 月下旬開始變紅,8 月上旬變?yōu)樽仙? 月中旬逐漸由紫色變?yōu)楹谏R虼耍x擇2018 年8 月5 日~9 月4 日期間,每天采摘黑果果實,采摘后的果實立即用自封袋封閉,在?40 ℃冰箱中冷凍保存,用于化學法多酚含量測定和高光譜信息采集,以監(jiān)測多酚含量隨成熟度變化的變化規(guī)律,并建立基于高光譜的黑果成熟度判別以及多酚含量檢測模型。
1.2.2 多酚含量測試
1.2.2.1 黑果多酚的提取 參考叢龍嬌等[15]的方法并稍加修改。將黑果置于烘箱中60 ℃下烘干至恒重,用研缽研磨,加入65.00%乙醇—2.00%鹽酸加速研磨,黑果與65.00%乙醇—2.00%鹽酸料液比為1:50 g/mL。在設定溫度40 ℃、超聲功率500 W 超聲波條件下提取多酚類物質(zhì)60 min。3000 r/min 下離心10 min,取上清液貯藏備用。
1.2.2.2 總酚含量的測定 多酚標準曲線的測定采用福林酚比色法,參考叢龍嬌等[15]的方法并稍加修改。紫外分光光度計765 nm 下測定溶液的吸光度。得到線性回歸方程:y=0.008x+0.0025,回歸系數(shù):R2=0.9954。取黑果多酚提取液代替沒食子酸標準溶液,測定其在765 nm 下吸光度,重復三次。
1.2.3 黑果高光譜信息采集 采用HSI 系統(tǒng)(見圖1)對黑果進行光譜信息采集。

圖1 感興趣區(qū)域采集Fig.1 Area of interest acquisition
在進行實驗前,高光譜系統(tǒng)需先預熱半小時。由于光照分布不均勻以及存在暗電流噪音,所以在要對采集的光譜信息進行黑白標定[16]。
式中:R 為經(jīng)過校正后的光譜圖像;Iλ為直接由高光譜采集設備獲取的漫反射光譜圖像;Bλ為關閉光源擰緊鏡頭蓋后采集的暗參考圖像;Wλ為采集的標準白板的漫反射圖像。
樣品掃描時,確定最佳曝光時間2.9 ms,平臺位移速度15.34 mm·s?1,焦距30.7 mm,相機分辨率384×288,光入射角度45°[17]。采集到光譜信息后,利用ENVI 4.8 軟件在原始數(shù)據(jù)中選取1521 像素矩形感興趣區(qū)域(見圖1),獲得原始光譜信息。
1.2.4 模型建立及評價
1.2.4.1 判別模型的建立 判別分析模型參考李佛琳等[18]的方法,使用SPSS 23 中Discriminate 程序運算。首先對原始數(shù)據(jù)進行剔除異常值和預處理,選擇最佳的預處理下光譜數(shù)據(jù),用光譜-理化值共生距(Sample set partitioning based on joint x-y distance,SPXY)法進行樣本劃分,用競爭性自適應重加權算法(Competitive adaptive reweighted sampling,CARS)和無信息變量消除法(Uninformative variable elimination,UVE)提取特征波長,根據(jù)標準成熟度級別組成的校正集樣本光譜數(shù)據(jù)分別建立高光譜—黑果成熟度PLS 判別模型和高光譜—黑果成熟度SVM判別模型,再以此判斷需預測的樣本成熟度級別。選擇效果最好的PLS 模型和SVM 模型,運用Fisher判別法,根據(jù)建立的判別方程對光譜數(shù)據(jù)做逐一回代重判別,校驗方程精度。
1.2.4.2 多酚-高光譜模型的建立及可視化 同“1.2.4.1”,原始數(shù)據(jù)經(jīng)剔除異常值、預處理、SPXY法樣本劃分后,采用CARS 和UVE 法提取特征波長,分別構(gòu)建特征波長與多酚含量、全波長與多酚含量的PLS 檢測模型和SVM 檢測模型,最終建立檢測模型并進行驗證[11]。
比較建立的檢測模型,選擇最適合的預測模型來可視化黑果多酚含量[19]。具體來說,將每個像素的光譜輸入到所建立的模型中,預測該特定點的多酚含量,對高光譜圖像中的所有像素重復這一過程。其中背景分割采用閾值為0.2。用不同的顏色顯示不同的預測多酚值,生成偽彩色圖像。所得到的圖有助于可視化單個樣本內(nèi)和樣本間多酚空間分布的差異。MATLAB 2018a 用于可視化任務。
1.2.4.3 模型評價指標 模型的可靠性和精度可以通過一些參數(shù)指標進行評價[20]。在本研究中,模型的評價指標選擇建模集決定系數(shù)(Rc2)和預測集決定系數(shù)(Rp2),建模集均方根誤差(Root mean squared error of calibration,RMSEC)和預測集均方根誤差(Root mean squared error of prediction,RMSEP)來進行分析定量。計算公式分別如下所示:
建模集決定系數(shù):
式中:nc為建模集樣本數(shù)量;為第i 個樣本的預測值;yi為第i 個樣本的實測值;為建模集樣本的平均值。
預測集決定系數(shù):
式中:np為預測集樣本數(shù)量;為第i 個樣本的預測值;yi為第i 個樣本的實測值;為建模集樣本的平均值。
建模集均方根誤差:
式中:nc為建模集樣本數(shù)量;為第i 個樣本的預測值;yi為第i 個樣本的實測值。
預測集均方根誤差:
式中:np為預測集樣本數(shù)量;為第i 個樣本的預測值;yi為第i 個樣本的實測值。
1.3 數(shù)據(jù)處理
高光譜圖像處理軟件為ENVI 5.3,剔除異常值、SPXY 樣本劃分、提取特征波長、可視化軟件為MATLAB 2018a,預處理及建模軟件為The Unscrambler X 10.4,軟件繪圖軟件為Origin 2018 9.5。
2 結(jié)果與分析
2.1 黑果果實多酚含量變化規(guī)律
8 月5 日~9 月4 日,每天隨機采摘黑果果實并測量其多酚含量,根據(jù)果實顏色和測得的多酚含量,分析多酚含量變化規(guī)律,對其成熟度劃分級別,見表1 和圖2。
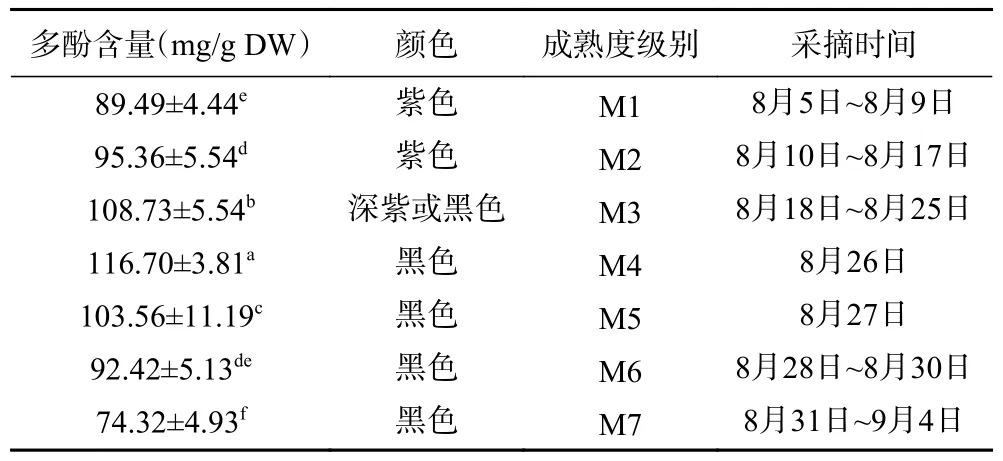
表1 黑果多酚含量變化規(guī)律及成熟度劃分Table 1 Variation of polyphenol content and division of maturity in AM

圖2 M1 至M7 成熟度級別的黑果Fig.2 AM at maturity level M1 to M7
有研究表明,黑果在較為溫暖的長江流域里下河地區(qū)成熟時期為八月初[13],而在較為寒冷的東北、遼西等地黑果成熟時期為九月初[14]。目前沒有關于魯中地區(qū)黑果成熟期以及營養(yǎng)成分含量隨時間變化規(guī)律的報道。理論上黃河流域的魯中地區(qū)黑果成熟時期應為八月中旬到八月底。從表1 可以看出,魯中地區(qū)的淄博,從8 月初到9 月初,黑果多酚含量呈現(xiàn)先增高后減少的趨勢,進入8 月下旬后,黑果多酚含量最高,達到100 mg/g 以上,符合我們對魯中地區(qū)黑果成熟時期的預判。
值得注意的是,進入8 月下旬后,黑果多酚含量變化比較大,本研究中,黑果多酚8 月26 日達到峰值、116.7±3.81 mg/g DW,之后多酚含量開始下降,8 月31日~9 月4 日的黑果多酚含量降到了74.32±4.93 mg/g DW,因此為提高黑果的收獲質(zhì)量,整個8 月下旬,應緊密監(jiān)測其多酚含量,適時采收。
2.2 高光譜檢測
采用HSI 系統(tǒng)對98 個黑果進行光譜信息采集,利用ENVI 4.8 軟件在原始數(shù)據(jù)中選取1521 像素矩形感興趣區(qū)域,未經(jīng)預處理的原始光譜如圖3 所示,為了消除噪音的影響[17],選取1000~2200 nm 的光譜區(qū)間進行分析[21?22]。

圖3 光譜反射曲線Fig.3 Spectral reflection curve
2.3 判別模型的建立
2.3.1 剔除異常值 蒙特卡洛交叉驗證法可以挑選可能存在異常的值并進行選擇性剔除,通過計算得到效果更佳的模型[11]。具體操作如下:將采集后的光譜值與黑果成熟度級別進行分析建模,交互驗證誤差均方根(Root mean square error of cross validation,RMSECV)最小的即為最佳主成分數(shù);通過蒙特卡洛交叉驗證法后得到各樣本的預測誤差均值和預測誤差標準差并繪制散點圖。如圖4 所示,以預測誤差均值和預測誤差標準差的平均值的2.50 倍為界限(圖中虛線),超出界限即為可能存在異常的值。將每個可能存在異常的值刪除并建模,R2增大即判定為異常值并剔除,R2減小即不是異常值并保留。

圖4 蒙特卡洛檢測Fig.4 Monte Carlo detection
如圖4 所示,預測誤差標準差和預測誤差均值超出界限值的需要依次剔除。剔除異常值2、12、59、66、70 號樣本剔除后,R2從0.8686 升高至0.8974,因此判定為異常值并剔除。67、91 號樣本不是異常值。
2.3.2 SPXY 樣本劃分 SPXY 法按3:1 將樣本分為校正集和預測集(見表2)。

表2 不同預處理方法的黑果成熟度PLS 模型Table 2 PLS models for maturity of AM based on different pretreatment methods
在對黑果的成熟度級別進行分類判別前,首先分別給每一成熟度級別的樣本假設一個值作為判別標志,分別將M1、M2、M3、M4、M5、M6、M7 成熟度級別黑果賦值為1、2、3、4、5、6、7,然后建立PLS判別模型。
PLS 是比較常用的化學計量學方法,可以用于定性分析和定量分析。采用Unscrambler X10.1 軟件建立PLS 模型。由于建立的判別模型在進行分類判別時,其模型預測類別值非整數(shù),所以在判斷類別時設定一個閾值,認為預測類別值與假設類別值之間的差值大于等于0.5 的樣本認定為非此類別樣本[21]。本研究中設定黑果的M1 級別的正確預測類別值在0.5~1.5 之間,M2 級別的正確預測類別值在1.5~2.5之間,M3 級別的正確預測類別值在2.5~3.5 之間,M4 級別的正確預測類別值在3.5~4.5 之間,M5 級別的正確預測類別值在4.5~5.5 之間,M6 級別的正確預測類別值在5.5~6.5 之間,M7 級別的正確預測類別值在6.5~7.5 之間。
2.3.3 原光譜與預處理光譜的PLS 模型比較 建立未經(jīng)過光譜預處理和經(jīng)預處理后的黑果成熟度PLS 模型并進行綜合比較。如表2 所示,與其他預處理建立的模型相比,經(jīng)過多元散射校正(Multiple scattering correction,MSC)預處理后的模型RMSECV最低,為0.7360;R2最高,為0.8977。說明經(jīng)MSC 預處理后建立的判別模型最穩(wěn)定,效果最好。因此選用經(jīng)MSC 預處理后所得到的光譜數(shù)據(jù)進行后續(xù)的研究分析。
2.3.4 提取特征波長
2.3.4.1 CARS 由于CARS 的隨機性和不確定性,因此經(jīng)過50 次試驗選取波長數(shù)量較少的,RMSECV最低的特征波長[23]。如圖5 所示,圖5a 為波長數(shù)量的變化趨勢:隨著試驗次數(shù)的增加,波長變量逐漸減少;圖5b 為迭代次數(shù)與RMSECV 之間的關系,RMSECV 在32 處達到最低后逐漸升高,說明選擇過程剔除了與黑果成熟度檢測有關的重要變量;圖5c 為參與PLS 建模的特征波長的回歸系數(shù)值,其中“*”對應位置為32 次的采樣。選擇RMSECV 值最低的為最佳的迭代次數(shù),即第32 次。第32 次采樣所得特征波長為55、104、109、156、173、194、195、202 nm 共11 個光譜波長,占總光譜波長的5.44%。

圖5 CARS 篩選過程Fig.5 CARS screening process
2.3.4.2 UVE 無信息變量消除方法的參數(shù)設置為隨機噪聲矩陣的變量數(shù)為202 個,與建模的光譜波長變量數(shù)一致,提取的最大主成分數(shù)為7。如圖6 所示,豎虛線左側(cè)為真實的波長變量,右側(cè)為隨機噪聲變量;兩水平虛線為UVE 穩(wěn)定性的閾值,虛線之外的為要提取的特征波長,提取38、39、40、41、42、43、44、45、46、55、56、57、58、59、107、108、109、111、122、123、200、201 nm 共22 個波長,占總光譜波長的10.89%。
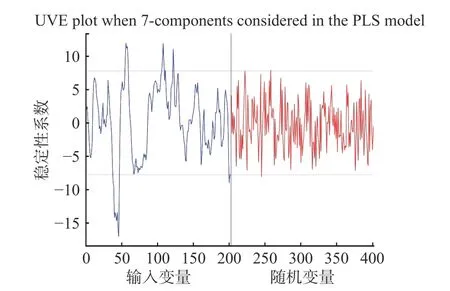
圖6 UVE-PLS 模型的穩(wěn)定性分布曲線Fig.6 Stability distribution curve of UVE-PLS model
2.3.5 PLS 模型和SVM 模型建立及驗證
2.3.5.1 PLS 模型建立及驗證 建立CARS、UVE和FS 的PLS 模型,并進行驗證。如表3 所示,將各模型進行比較,其中CARS-PLS 的RMSECV 最小,為0.6221,Rc2和Rp2最大,分別為0.9233 和0.9169,具有最好的校正性能和交互驗證性能。因此,CARSPLS 模型為最優(yōu)的PLS 模型,模型預測理論上最準確。

表3 黑果成熟度級別的PLS 模型Table 3 PLS models for maturity level of AM
2.3.5.2 SVM 模型建立及驗證 SVM 模型建立及驗證如表4 所示,其中UVE-SVM 的RMSECV 最小,為0.6233,Rc2最大,為0.9712,校正效果和交互驗證效果較好。因此,UVE-SVM 模型為最優(yōu)的SVM 模型,模型預測理論上最準確。

表4 黑果成熟度級別的SVM 模型Table 4 SVM models for maturity level of AM
綜上所述,CARS-PLS 與UVE-SVM 模型校正效果和交互驗證效果較好,因此對CARS-PLS 與UVESVM 模型進行判別分析。
2.3.6 CARS-PLS 判別結(jié)果 由表5 可知,PLS 判別模型在校正集中誤判樣本數(shù)為10,識別率為85.71%;在預測集中誤判樣本數(shù)為4,識別率為82.61%,綜合識別率為84.95%。
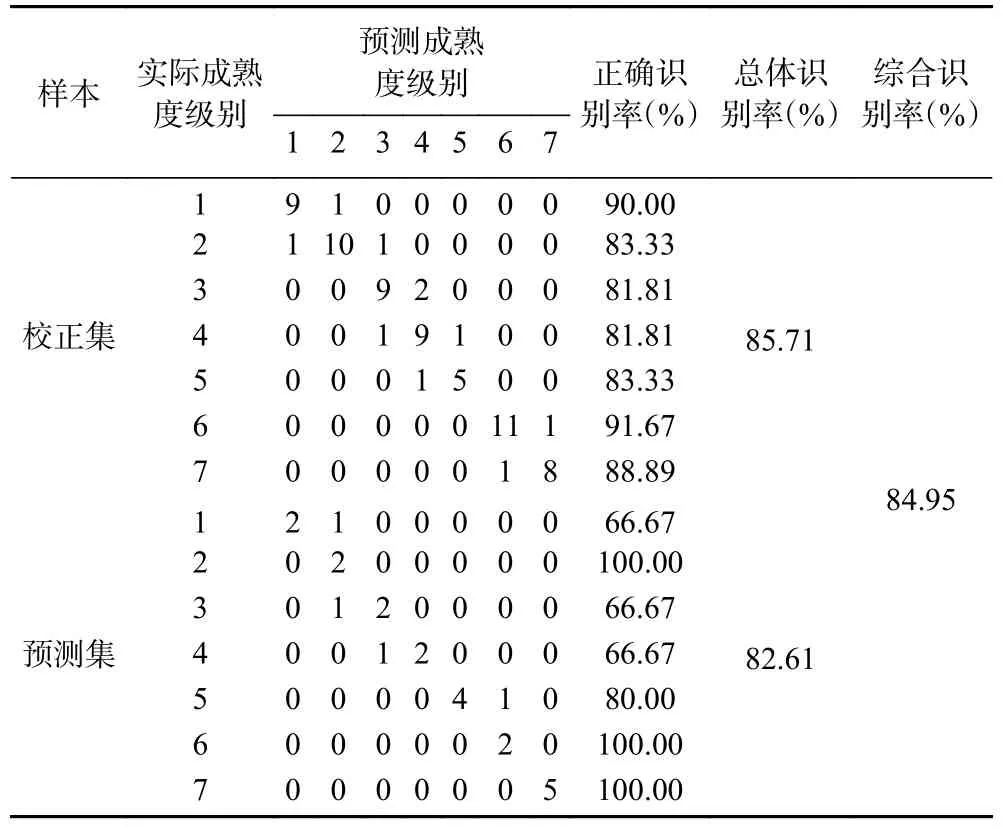
表5 CARS-PLS 模型判別結(jié)果Table 5 The discrimination results of CARS-PLS model
2.3.7 UVE-SVM 判別結(jié)果 結(jié)果如表6 所示,SVM判別模型在校正集中誤判樣本數(shù)為4 個,識別率為94.28%;在預測集中誤判樣本數(shù)為1 個,識別率為95.65%,綜合識別率為94.62%。相較于CARS-PLS判別模型,UVE-SVM 判別模型效果更好,綜合識別率更高。

表6 UVE-SVM 模型判別結(jié)果Table 6 The discrimination results of UVE-SVM model
黑果的成熟度判別模型研究較少,本研究建立的UVE-SVM 黑果成熟度判別模型綜合識別率為94.62%,Rc2和Rp2分別為0.9712 和0.9708。李鑫等[24]建立的基于高光譜成像技術的煙葉田間成熟度的SVM 判別模型的總和識別率在87.19%~93.13%之間。相較于李鑫等建立的預測模型,該模型具有更好的判別效果。
2.3.8 SVM 模型的驗證 將七個成熟度級別的黑果混合后隨機選取20 個進行模型的驗證,選取結(jié)果為M1 級別3 個樣本,M2 級別2 個樣本,M3 級別2 個樣本,M4 級別2 個樣本,M5 級別4 個樣本,M6 級別2個樣本,M7 級別5 個樣本。將黑果的光譜值代入上述的UVE-SVM 模型,得到的黑果成熟度級別的預測值,并與實際級別構(gòu)建的散點圖(圖7),R2=0.9793,判別結(jié)果為20 個樣本結(jié)果正確率均為100.00%。結(jié)果表明該UVE-SVM 模型具有良好的預測性能。

圖7 黑果成熟度級別的SVM 判別模型的實測級別和預測級別散點圖Fig.7 Scatter plots of the measured level and predicted level of the SVM discriminant model for AM maturity level
2.4 多酚-高光譜建模
2.4.1 蒙特卡洛法剔除異常值 如圖8 所示,預測誤差標準差和預測誤差均值超出界限值的需要依次剔除。剔除異常值2、59、66、91 號樣本剔除后,Rc2從0.7686 升高至0.7845,因此判定為異常值并剔除。12、67 號樣本不是異常值。

圖8 蒙特卡洛檢測Fig.8 Monte Carlo detection
2.4.2 SPXY 樣本劃分 采用蒙特卡洛交叉驗證法剔除異常值后,采用SPXY 法按3:1 的比例將黑果多酚含量樣本進行劃分,并分別計算校正集、預測集多酚含量的最大值、最小值、平均值和標準偏差,結(jié)果如表7 所示。

表7 SPXY 法樣本劃分Table 7 Sample division by SPXY method
2.4.3 原光譜與預處理光譜的PLS 模型比較 建立未經(jīng)過光譜預處理和經(jīng)預處理后的黑果成熟度PLS 模型并進行綜合比較。如表8 所示,與其他預處理建立的模型相比,經(jīng)過中值濾波(Median Filter)預處理后的模型RMSECV 最低,為14.4182;R2較高,為0.7832。說明經(jīng)Median Filter 預處理后建立的黑果多酚含量模型最穩(wěn)定,效果最好。因此選用經(jīng)Median Filter 預處理后所得到的光譜數(shù)據(jù)進行后續(xù)的研究分析。
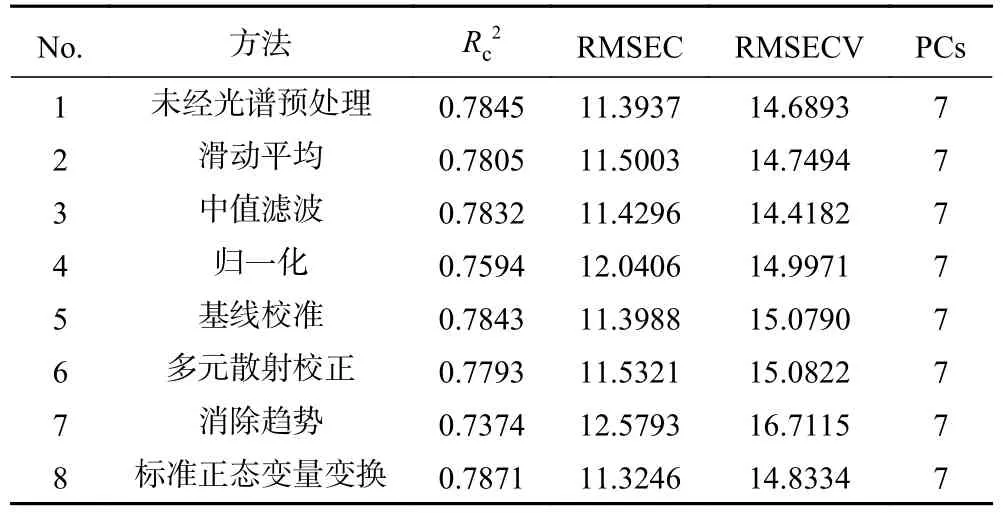
表8 不同預處理方法建立的PLS 預測模型Table 8 PLS models established by different pretreatment methods
2.4.4 特征波長的選取
2.4.4.1 競爭性自適應加權算法 如圖9 所示,圖9 a 為波長數(shù)量的變化趨勢:隨著試驗次數(shù)的增加,波長變量逐漸減少;圖9b 為迭代次數(shù)與RMSECV之間的關系,RMSECV 在19 處達到最低后逐漸升高,說明選擇過程剔除了與黑果多酚含量檢測有關的重要變量;圖9c 為參與PLS 建模的特征波長的回歸系數(shù)值,其中“*”對應位置為19 次的采樣。選擇RMSECV 值最低的為最佳的迭代次數(shù),即第19 次。第19 次采樣所得的特征波長為2、25、26、27、39、61、62、63、64、84、85、87、89、90、93、94、95、96、97、98、100、101、102、105、129、130、133、136、138、140、145、161、163、165、167、175、191 nm共37 個光譜波長,占總光譜波長的18.32%。
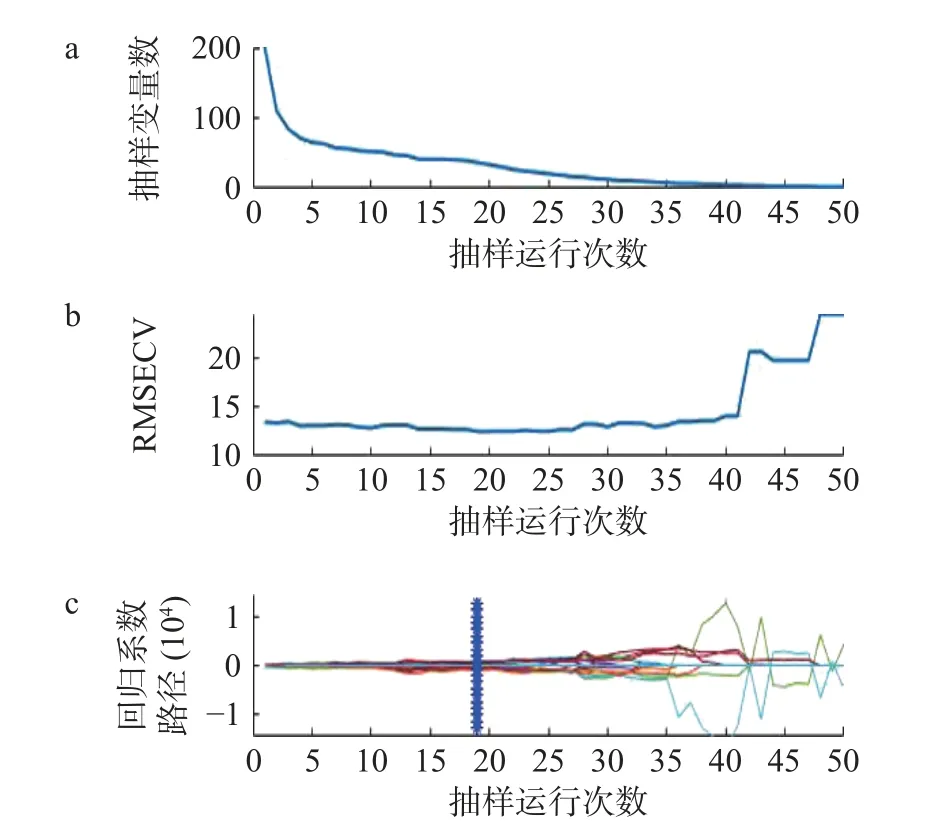
圖9 CARS 篩選過程Fig.9 CARS screening process
2.4.4.2 UVE 無信息變量消除方法的參數(shù)設置為隨機噪聲矩陣的變量數(shù)為202 個,與建模的光譜波長變量數(shù)一致,提取的最大主成分數(shù)為7。如圖10所示,豎虛線左側(cè)為真實的波長變量,右側(cè)為隨機噪聲變量;兩水平虛線為UVE 穩(wěn)定性的閾值,虛線之外的為要提取的特征波長,提取1、2、3、5、6、7、18、19、23、24、25、26、27、28、29、59、60、61、62、63、64、65、66、67、68、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、101、102、103、104、105、106、107、108、109、110、111、128、129、130、131、132、133、134、135、136、137、138、139、140、141、142 nm共75 個波長,占總光譜波長的37.13%。

圖10 UVE 模型的穩(wěn)定性分布曲線Fig.10 stability distribution curve of UVE model
2.4.5 PLS 模型建立及驗證 建立CARS、UVE 和FS 的PLS 模型,并進行驗證。如表9 所示,CARS-PLS的RMSECV 最小,為13.4552,Rc2和Rp2最大,分別為0.7997 和0.7496,校正效果和交互驗證效果較好。因此,CARS-PLS 模型為最優(yōu)模型,理論上模型預測最準確。

表9 黑果多酚含量的PLS 模型Table 9 PLS models for polyphenol content of AM
2.4.6 SVM 模型建立 建立CARS、UVE 和FS 的SVM 模型,并進行驗證。如表10 所示,CARS-SVM的RMSECV 最小,為16.4224;Rc2和Rp2最高,分別為0.8331 和0.7377,即校正效果和交互驗證效果較好。因此,CARS-SVM 模型為最優(yōu)模型,理論上模型預測最準確。

表10 黑果多酚含量的SVM 模型Table 10 SVM models for polyphenol content of AM
黑果多酚含量預測模型的相關研究較少,本研究建立的CARS-SVM 模型Rc2均高于其他模型的Rc2,為0.8331。張驍?shù)萚25]建立的水稻籽粒直鏈淀粉含量高光譜預測模型Rc2為0.74。李宗飛等[26]建立的甜菜葉片全氮含量高光譜預測模型Rc2為0.747,相較于張驍、李宗飛等建立的預測模型,本研究建立的模型具有更好的校正性能。
2.4.7 SVM 模型的驗證 隨機選取不同成熟度級別的20 個黑果驗證模型,將黑果的光譜值代入上述的CARS-SVM 模型,得到的黑果多酚含量的預測值,并與實際值構(gòu)建的散點圖(圖11),R2=0.8389,結(jié)果表明該CARS-SVM 模型具有較好的預測性能。

圖11 黑果多酚含量的SVM 模型的實測值和預測值的散點圖Fig.11 Scatter plot of measured and predicted values of SVM model for polyphenol content in AM
2.4.8 黑果多酚含量可視化模型 高光譜圖像經(jīng)校正后,提取黑果樣本上每一像素點對應的光譜信息,用已建立的黑果多酚含量高光譜模型可有效預測各像素點的多酚含量[27]。以像素點空間位置及對應多酚含量繪制了偽彩色圖像,如圖12 所示,隨機選取七個成熟度級別的黑果,得到顏色鮮明、可視化的偽彩色黑果多酚含量分布圖像。分布圖上黑果的背景為深藍色,多酚含量顯示為零;顏色越紅表示多酚含量越高[28]。如圖所示,各級別的黑果多酚含量比較均勻,內(nèi)部深藍色點可能是黑果籽,研究結(jié)果與前文測得的多酚含量一致,證明了采用高光譜圖像信息建立黑果多酚含量可視化模型是可行的。

圖12 黑果多酚含量空間分布圖Fig.12 Spatial distribution for polyphenols of AM
3 結(jié)論
本研究對魯中地區(qū)黑果進入成熟期后,多酚含量隨時間和成熟度的變化規(guī)律進行了研究,發(fā)現(xiàn)魯中地方黑果成熟期在8 月下旬,多酚含量達到峰值。構(gòu)建了基于高光譜的黑果成熟度判別以及多酚含量檢測的最優(yōu)模型:黑果成熟度判別模型,效果最好的為MSC 預處理下的UVE-SVM 模型,綜合識別率為94.62%,Rc2為0.9712,根據(jù)該模型驗證的準確度為100%;多酚含量模型,效果最好的為Median Filter 預處理下的CARS-SVM 模型,Rc2為0.8331。特征波長的提取及建模對光譜進行了降維,簡化了數(shù)據(jù)量。此外,本研究還表明黑果多酚含量的可視化是可行的。
本研究為黑果的適時采摘、品質(zhì)評價及相關產(chǎn)品的深度開發(fā)和高值化應用提供理論基礎和技術支持,拓展了黑果無損檢測技術,為HSI 技術在漿果領域的應用提供了理論基礎。對促進黑果產(chǎn)業(yè)的發(fā)展有一定的意義。目前,國內(nèi)外對黑果多酚的功能特性已經(jīng)有了較多的應用和研究,但是檢測方法較為落后。后續(xù)研究可以圍繞黑果多酚中花青素、類黃酮和酚酸等單體多酚以及原花青素等復合多酚的高光譜檢測模型的構(gòu)建。此外,可視化可以實現(xiàn)智慧化采摘果蔬,符合未來智能化發(fā)展的趨勢,而國內(nèi)外對果蔬的可視化研究也較少,后續(xù)研究可以圍繞此研究方面進行。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
