融合外部知識的生成式實體關系聯合抽取方法
2023-08-15 02:02:10祝振赫
計算機技術與發展 2023年8期
祝振赫,武 虹,高 潔,周 玉
(1.中國科學院大學 人工智能學院,北京 100049;2.中國科協創新戰略研究院,北京 100038;3.中國科學院自動化研究所 模式識別國家重點實驗室,北京 100190;4.北京中科凡語科技有限公司 凡語AI研究院,北京 100190)
0 引 言
隨著互聯網、大數據和知識圖譜等技術的發展,各行各業都在構建自己的知識庫,以便為下游的問答、摘要等應用提供知識的支持。文本作為重要的信息載體,包含了大量豐富的知識,如百科介紹、醫院病例、企業標書等,都包含了豐富的內容,具有重要的應用價值。但由于沒有統一規范化的寫作標準,導致內容形式多種多樣且多為非結構化或半結構化文本,為整理統計的工作帶來很大的挑戰,并難以直接應用于下游任務中。如何從這類非結構化文本中獲取蘊含的知識成為了一項重要的研究課題。信息抽取(Information Extraction,IE)是自然語言處理領域中一個非常重要的任務。該任務主要是從非結構化或半結構化文本中抽取出用戶所需要的信息,如命名實體、實體關系及事件等,并以結構化的形式輸出,以便于支持下游任務的應用[1]。
關系抽取(Relation Extraction,RE)作為信息抽取的主要子任務之一,主要目標是從非結構化文本中抽取出有關的兩個實體及實體間的關系,構成關系三元組的結構化形式。通常形式化描述為
基于傳統的機器學習的關系抽取方法主要通過領域專家制定實體關系范式,通過統計和規則等方法進行抽取。Miller等人[3]通過訓練增強解析樹來表示句子的語義信息,再對不同關系類型設計模式匹配規則來進行抽取。Zelenko等人[4]用核函數及支持向量機的方法進行關系抽取。傳統的關系抽取方法具有準確率高的優點,當文本滿足規則條件后,就能夠抽取出想要的信息。但傳統的關系抽取方法依賴人工設計特征和抽取規則,需要大量成本,并難以覆蓋所有情況,因此該方法的泛化能力較差。
隨著深度學習的興起,大量的深度學習方法被應用到了關系抽取中。許多經典的關系抽取方法都是使用監督學習來獲得較好的性能表現,因為監督學習能夠更有效地讓模型抽取到特征,從而提高準確率和召回率。但是在一些特定領域,由于難以獲取大規模標注數據,導致監督學習的成本大大增加,在應用中通常使用基于啟發式規則的無監督方法和遠程監督等半監督方法。
網絡中的文本形式多樣,許多的半結構化文本都包含著一定的實體和關系的知識。如百科類網頁大多都詳細介紹了一個實體的信息,通常都包含關于該實體的一段描述及其基本信息表。基本信息表一般被稱為Infobox,其中包含了許多和該實體有關的屬性和其他實體。這種半結構化文本也經常作為構建知識圖譜和遠程監督實體關系抽取數據集的直接數據來源[5]。許多基于遠程監督的實體關系抽取方法都通過Infobox構建的知識圖譜來實現。如百度百科“戰狼”頁面的基本信息中的句子“《戰狼》是由吳京執導的現代軍事戰爭片,該片由吳京、余男、倪大紅、斯科特·阿金斯、周曉鷗等主演”,可以和Infobox中的“導演:吳京”條目構成一個實體關系抽取任務的標簽數據,原句的一個實體關系元組為<戰狼,導演,吳京>。像這種從表格文本以及通過句法規則獲取的實體關系三元組都包含了一定的內在知識,如何利用這些內在知識對于實體關系聯合抽取十分重要。
該文提出一種基于深度學習的融合外部知識的生成式實體關系聯合抽取方法,對于一些難以獲取大規模標注數據的特定領域,通過在訓練時引入一些典型規則所抽取的結果作為額外知識幫助模型從文本中抽取到更準確全面的信息。模型采用多編碼器框架,采用知識自注意力機制對外部知識進行編碼。在解碼過程中,采用跨知識注意力方法,融合知識編碼器的隱層向量得到解碼隱層狀態,進而生成實體和關系序列。實驗結果表明,所提方法能夠通過融合外部知識,提升實體關系三元組的準確率,尤其提升模型在標注數據稀缺場景下的抽取準確率。
1 相關工作
關系抽取任務從領域上可分為限定域關系抽取和開放域關系抽取,其區別在于是否對關系類別進行制定。限定域關系抽取需要事先確定關系類別,而開放域關系抽取的關系直接從原文本中抽取獲得。限定域關系抽取的優勢是所抽取的關系明確,但是無法抽取到所制定關系類別以外的關系。開放域關系抽取能夠抽取到更多的關系類別,但經常會抽取到不準確或無意義的關系。
基于深度學習的關系抽取方法主要分為流水線(Pipeline)式抽取方法和聯合(Joint)式抽取方法兩種。流水線式方法一般是先對文本進行命名實體識別,找出文本中所有的命名實體,然后再將這些命名實體兩兩配對進行關系分類。這種流水線抽取方法通常用于限定域關系抽取,其關系預測階段是一個多分類任務,所以無法抽取到定義好的關系以外的其他關系。并且由于分成了兩個任務,在實體識別時往往會依賴其他自然語言處理工具,從而導致誤差傳播的問題,對模型性能會造成一定的影響。當時普遍認為流水線抽取方法不如聯合抽取方法好,但Zhong等人[6]在流水線模型的基礎上使用了一種簡單的方法就達到了當時的最好性能。他們在實體識別結束后對原句進行重構,將抽取到的頭尾實體及其類別信息加入到句子當中,然后進行關系分類的判別。可見在關系抽取時引入額外信息有助于模型的學習。聯合抽取方法是同時完成實體和實體間關系的抽取任務,通過利用實體和關系的關聯信息來提高模型性能[7]。Wei等人[8]用多任務學習的方式,讓實體和關系共享一個編碼器(Encoder),再由兩個解碼器(Decoder)分別解碼得到實體和關系。Zheng等人[9]將實體關系聯合抽取任務轉換為序列標注任務,使用BIO(B-begin,I-inside,O-outside)序列標注的方法對三元組進行整體建模,通過端到端模型對句子進行編碼后預測每個單詞所屬標簽類別,將臨近的頭尾實體及關系合并為需要抽取的三元組,取得了不錯效果。但這種序列標注的方法無法處理實體嵌套的問題。Li等人[10]則是將聯合關系抽取任務轉換成多輪問答任務,通過在輸入中加入問題來引入實體關系信息,再由模型預測出答案,即文本中能夠作為答案片段的起始結束位置。Cui等人[11]采用序列到序列(Sequence-to-Sequence,Seq2Seq)模型,將實體關系標記作為單詞加入詞典,通過編碼器對文本進行編碼,再由解碼器直接解碼輸出帶有實體關系標記的三元組文本序列。
該文提出一種基于Seq2Seq的融合知識的多源關系抽取方法,通過引入規則抽取的三元組作為額外提示信息,幫助模型從文本中抽取出更準確全面的實體關系三元組。該方法能夠有效利用規則知識,對于領域的遷移性較強,對于缺乏標注數據的領域,只需要利用簡單的領域知識來制定一些典型規則進行抽取,抽取結果即可作為額外知識輔助模型,從而達到比直接使用Seq2Seq模型和單靠規則抽取都要好的效果,減少了人工定制復雜規則的成本。
2 關系抽取方法
2.1 問題描述
采用類似Cui等人[11]的方法,輸入為一段文本和使用規則抽取出的關系元組文本,關系元組通過表示實體和關系的特殊字符進行標記后拼接成字符串,比如“ ”。模型通過對文本和關系元組信息進行預測得到的所有可能三元組,并以相同方式將所有預測關系三元組進行拼接作為一個字符串輸出。
2.2 整體架構
該文所面對的從網頁文本中抽取所有可能實體關系這一任務的整體架構如圖1所示。輸入為來自網頁的原始文本,通過預處理操作去除非正文等噪聲信息,得到純文本后使用基于領域知識制定的簡單規則對文本進行關系抽取,得到后續作為提示信息的三元組,并用特殊字符標識拼接為字符序列。然后用編碼器-解碼器模型對文本和根據規則抽取得到的三元組字符串進行預測,輸出所有可能關系元組構成的字符序列。
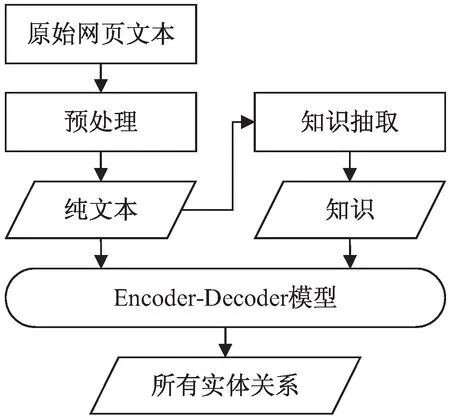
圖1 多源關系抽取方法整體架構
2.3 外部知識抽取
對于百科類的文本使用Infobox等結構化文本匹配和基于依存句法分析的模式匹配規則進行抽取。利用哈工大語言技術平臺(Language Technology Platform,LTP)對文本進行依存句法分析,然后選取Jia等人[12]提出的依存語義范式進行關系抽取。對于類似企業標書等特殊文體的文本,則依據領域知識采用正則表達式、關鍵字匹配以及表格解析等方法進行抽取。將得到的實體對及實體間關系用特殊字符標記后組成一個形如“ ”的字符串。其中“”中間的為頭實體,“”中間的是尾實體,“”之間的是頭尾實體間關系。
該文將上述方法抽取得到的實體關系元組信息作為每個句子的局部知識,利用知識編碼器學習背后的模式、規則等全局知識來指導模型抽取,從而提高實體關系聯合抽取的準確率。
2.4 模型結構
基礎模型選用的是經典的Seq2Seq模型Transformer[13],在其原有架構上進行改動,以引入額外知識。在其原有編碼器的基礎上再增加一個知識編碼器,同樣使用自注意力機制對引入的知識進行編碼,從而獲得文本中的局部知識信息。將文本編碼和知識編碼一同送入解碼器中。在解碼器增加一個解碼知識的注意力層,用于解碼出更類似引入知識的三元組,從而達到對知識的學習。模型結構如圖2所示。

圖2 多源關系抽取模型結構
2.4.1 知識提取器
面對特定領域的具體任務,首先利用相關領域知識構建一個知識提取器,作為該領域全局知識。知識提取器通過使用規則從文本中抽取實體關系元組以及根據表格信息匹配對應句子等方法獲取和該句子有關的局部知識,作為輸入模型的額外知識信息。
2.4.2 文本編碼器
輸入為句子X=(x1,x2,…,xn),通過詞嵌入和位置編碼操作后得到句子嵌入EX=(ex1,ex2,…,exn)。輸入文本編碼器后得到輸入句子的上下文向量HX=(hx1,hx2,…,hxn)
HX=TextEncoder(EX)
(1)
2.4.3 知識編碼器
對知識提取器得到的和句子相關的知識進行特殊標記處理拼接后形成知識序列K=(k1,k2,…,km),通過詞嵌入和位置編碼操作得到知識嵌入EK=(ek1,ek2,…,ekm)。輸入知識編碼器后得到知識的上下文向量HK=(hk1,hk2,…,hkm)
HK=KnowledgeEncoder(EK)
(2)
2.4.4 解碼器
在解碼階段首先將目標三元組序列T=(t1,t2,…,ts)作為解碼器的輸入,同樣經過詞嵌入和位置編碼后得到目標元組序列嵌入ET=(et1,et2,…,ets)。在注意力層將ET經過自注意力機制得到的目標序列隱層狀態HT先后與HX和HK計算交叉注意力,得到融合知識后的解碼器輸出的隱層狀態HO。
HT=SelfAttention(ET)
(3)
HTX=CrossAttention(HT,HX)
(4)
HO=CrossAttention(HK,HTX)
(5)
其中,HTX為解碼器輸入的上下文向量和編碼器輸入的三元組上下文向量做交叉注意力所得到的包含目標三元組和輸入三元組注意力的上下文向量。
將HO經過線形層和softmax計算得到輸出單詞的概率P:
P=softmax(WlHO)
(6)
其中,Wl為線性層的權重矩陣。
最后根據詞表輸出生成的序列Y=(y1,y2,…,yn)。
2.5 訓練方式
首先使用純文本和所有抽取出的實體關系三元組作為編碼器和解碼器的輸入單獨訓練一個Transformer模型并在訓練好之后將各層參數固定。再用純文本和部分抽取實體作為模型編碼器輸入,所有實體關系三元組作為解碼器輸入進行訓練,訓練過程中僅更新知識編碼器以及目標三元組和知識交叉注意力模塊的參數。
2.6 目標函數
目標函數如公式(7)所示,根據給定輸入句子X、外部知識K以及用標注數據訓練得到的Transformer參數θX來生成目標序列Y,采用最大似然估計,提升真實樣本Y的似然概率。
(7)
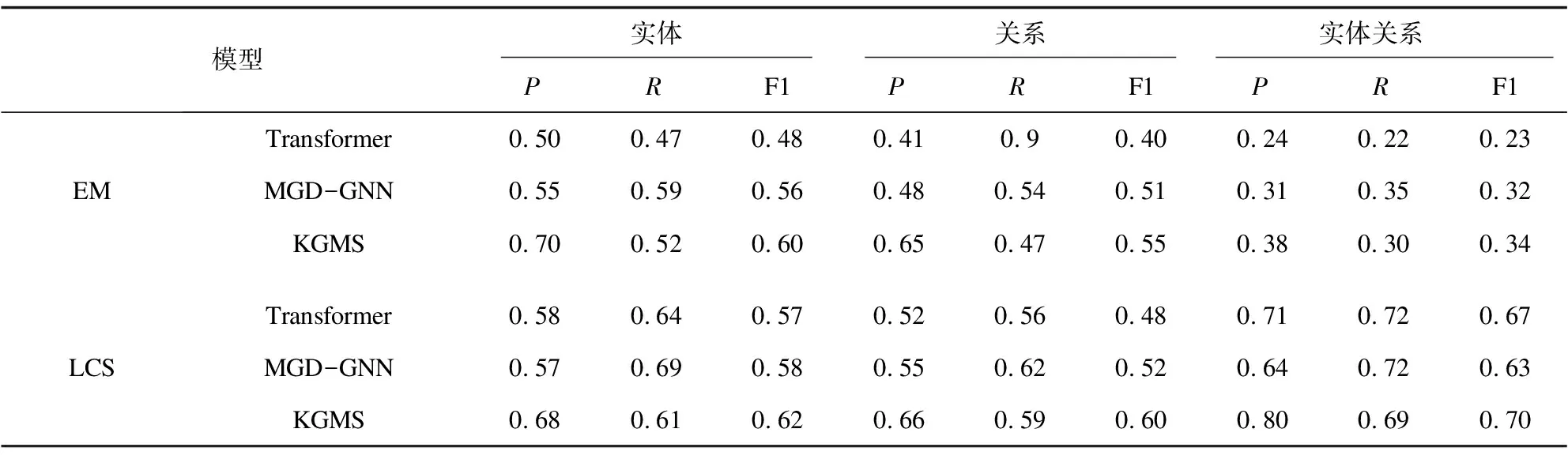
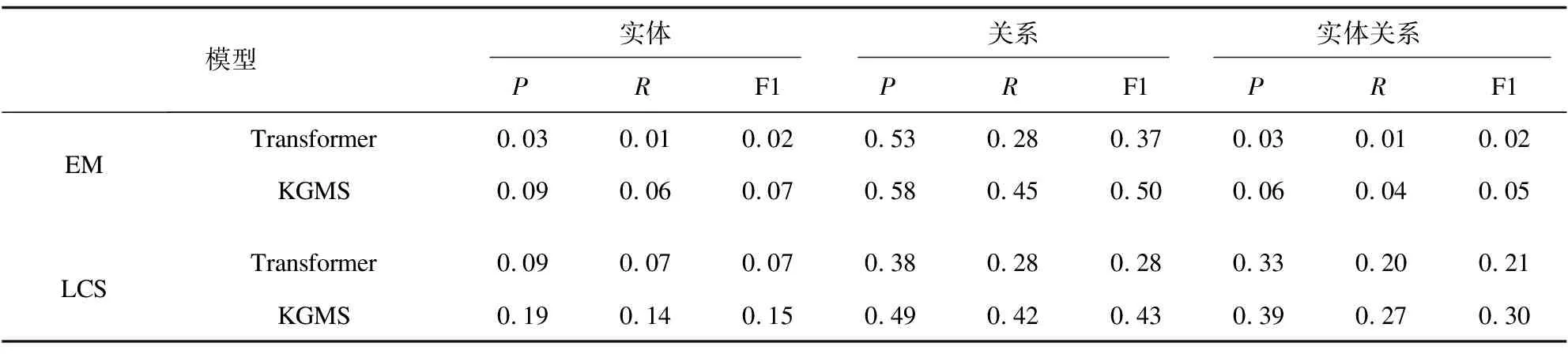
其中,θK為知識編碼器和知識交叉注意力層的參數。θx為其余參數,D={(X,Y)}表示監督數據集,其中X為句子序列,Y為實體-關系序列,K為全局知識圖譜,Kx為與句子相關的局部知識圖譜。M為實體-關系序列Y的字符個數。y Seq2Seq模型的一個優點是比較靈活,能夠通過對生成序列進行特殊構造來完成多種不同的任務。因此,該文分別在開放域和限定域兩個數據集上進行實驗。 實驗所使用的兩個數據集,一個是通用百科領域的數據集SpanSAOKE,由Lyu等[14]制作,處理后包含26 481個中文句子以及53 774個實體關系三元組。其數據來源為百度發布的符號輔助開放知識表達(Symbolic Aided Open Knowledge Expression,SAOKE)[15]數據集。該數據集是中文開放域信息抽取的大規模句子級數據集,其中每個句子都是人工標記的,并采用統一的知識表示格式來表達句子中所包含的事實。 另一個是采招網(https://www.bidcenter.com.cn/)上的標書網頁文本共獲取了20 951篇,經過去除HTML標簽、JavaScript、CSS等代碼文本以及特殊符號等數據清洗處理后得到僅包含正文的標書文本。根據需求及對標書格式的認知制定一系列規則對標書內容進行抽取,實體類別包括招標方名稱、供應商名稱、招標代理機構名稱、預算金額、產品名稱等24種類別。按模型設定的256最大文本長度進行切分后得到總計71 695份原文本和事實元組的句對。將數據集劃分為訓練集、驗證集和測試集,見表1。 表1 數據集統計信息 其中,SpanSAOKE為開放域關系抽取數據集,不限制關系類別,關系均從原文中抽取得到。Bid-Docs為爬取的標書文本數據集。訓練集和驗證集為通過復雜的網頁爬取規則進行自動化標注,測試集為自動標注后進行人工校驗得到。由于該數據集比較特殊,以標書本身為頭實體,只抽取關系和對應尾實體,因此標注時使用特殊字符“”標注關系,“”標注尾實體。 實驗使用F1值作為評價指標并采用涂飛明等人[16]在實驗中所用的兩種計算方式,一個是完全匹配(Exact Match,EM),對于抽取出的關系三元組,只有當預測的頭實體、尾實體及實體間關系完全和標準答案相同時才算是一個正確的抽取結果。另一個是最長公共子串(Longest Common Substring,LCS),下面為具體計算方法: 考慮到模型生成多個三元組的數量和順序不固定,因此先對答案和預測結果的三元組序列按三元組拆分后進行排序。對于答案中的每一個三元組,使用LCS長度在預測結果中找到其關聯性最高的三元組,找到的所有三元組按答案順序拼接,預測中多余的三元組直接按原順序拼接在后面,形成和答案最相近的序列。然后以新得到的序列和標準答案三元組序列求出二者的最長公共子串LCS,然后用LCS的長度作為預測正確的序列長度,分別與預測結果序列長度和標準答案序列長度計算精確率P和召回率R,最后利用公式(8)計算F1值。這兩種計算方法分別反映了模型預測結果的精確匹配度和模糊匹配度。在計算LCS時去掉了“”等用于表示頭尾實體及關系的特殊符號。 (8) 使用EM指標時的精確率P和召回率R的計算公式分別為: (9) (10) 其中,TC為預測正確的三元組數量,TP為預測三元組總數量,TG為標準答案三元組總數量。 使用LCS指標時的精確率P和召回率R的計算公式分別為: (11) (12) 其中,LLCS為預測結果序列和標準答案序列的LCS的長度,LP為預測序列長度,LG為標準答案序列長度。 操作系統是Ubuntu16.04.7,編程語言為Python3.7,深度學習框架為Pytorch1.8.1,句子最大長度設定為256,知識編碼器以及知識交叉注意力層和Transformer的編碼器及解碼器一樣為6層,多頭注意力的頭數為8個。 融合知識的關系抽取方法在SpanSAOKE和從網頁獲取的標書文本兩個數據集上的實驗結果分別如表2和表3所示,其中Transformer為基于注意力機制的Seq2Seq模型,使用自注意力機制的編碼器對輸入文本進行編碼,再通過自回歸的解碼器解碼出目標序列。MGD-GNN[14]是一個基于字符級的流水線式開放域關系抽取模型,通過構建單詞和字符之間的依賴關系圖來引入依存句法信息以及分詞信息,利用圖神經網絡對其進行編碼得到最終每個字符的表示,然后分別預測每個連續字符子序列為關系的概率,最后為每個得到的關系預測其對應的頭尾實體。KGMS為文中模型。由于標書數據集比較特殊,只抽取關系和尾實體的二元組,因此現有關系抽取方法不太適用,故只和未融合知識的Transformer進行比較。 表2 SpanSAOKE實驗結果 表3 標書文本實驗結果 在SpanSAOKE數據集上,相比之下MGD-GNN因為是對句子的每個連續字符子序列進行預測,所以抽取到了最多的關系元組,具有最高的召回率。但其預測正確的元組數量沒有KGMS所抽取的多,并且對于沒有完全匹配的關系元組,KGMS也得到了更接近答案的結果。由此可見,KGMS在抽取時參考了輸入元組所包含的規則信息,使得抽取更具有針對性,從而提高了完全匹配的精確率和召回率。 在標書文本上,KGMS在引入知識信息后性能有所提升,但整體表現都不好,分析可能是因為網頁標書格式比較多樣,且有一些表格,導致爬取后的數據十分雜亂,且難以通過預處理進行修整。由于標書文本形式比較特殊,默認將標書題目作為所有要抽取的關系元組的頭實體,在抽取時僅抽取定義的關系及對應尾實體。很多時候定義的關系并未出現在原文中,需要模型根據上下文來判斷實體所屬類型,而上下文信息又往往比較零碎,嚴重影響了模型的特征提取。 Text:網游公司的地推人員通常分為兩類:一類是正式招聘,多為大學生; Gold:<地推人員,分為,兩類><一類,是,正式招聘><地推人員,多為,大學生> Pattern Matching:<地推人員,多為,大學生><網游公司地推人員,分為,兩類> Transformer:<網游公司的地推人員,通常分為,兩類><一類,是,正式招聘><多,為,大學生> MGD-GNN:<網游公司的地推人員,通常分為,兩類><一類,是,正式招聘><網游公司的地推人員,多為,大學生> KGMS:<地推人員,多為,大學生><地推人員,分為,兩類><網游公司推司,分為,兩類> 如上所示,相比之下Transformer和MGD-GNN所抽取的實體都包含了修飾語,而從標準答案來看顯然是不希望修飾語出現的。Pattern Matching為通過規則獲取的作為額外知識的三元組。其中包含了有修飾語和無修飾語的實體,使得KGMS在引入知識后嘗試將兩種類型都抽取出來。但由于Pattern Matching沒有關于“一類是正式招聘”,從而導致KGMS忽略了這部分。由此可說明引入的知識對實體關系抽取有比較大的影響,可以通過對額外知識的設計,引入更多更符合需求的知識來對模型的抽取行為進行引導,從而提升模型的性能。 該文提出了一種融合外部知識的實體關系聯合抽取方法,采用多編碼和知識注意力機制,將句法結構和結構化信息等外部知識融入編碼解碼框架的模型來生成實體和關系序列,從而提高模型的準確率。實驗結果顯示,在開放域和限定域的數據集上的表現均有所提升,可以提升抽取準確率。對于一些標注數據稀缺場景是有效的提升方法,同時規則的制定可以讓模型更好地具有領域適應性。在今后的工作中將使用預訓練模型作為基礎模型,并構建更完善的數據集來探究該方法。3 實驗部分
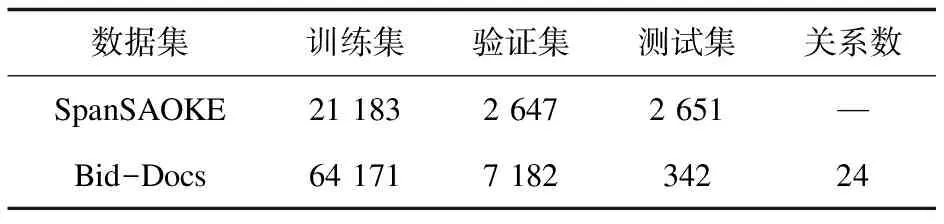
3.1 數據集
3.2 評價指標
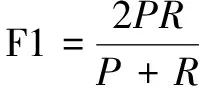
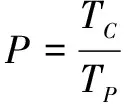
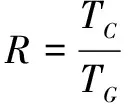
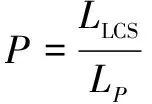
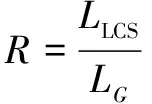
3.3 實驗環境及參數設置
3.4 實驗結果
3.5 實例分析
4 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
