基于預訓練模型與記憶卷積網絡的立場檢測研究
2023-08-15 02:02:14周浩軒王國權
計算機技術與發展 2023年8期
陳 珂,周浩軒,王國權
(1.廣東石油化工學院 計算機學院,廣東 茂名 525000;2.東莞長城開發科技有限公司,廣東 東莞 523000)
0 引 言
立場分析用于挖掘文本對特定話題、對象的支持、反對、中立立場,它和情感分析有相似的地方。但是由于人們有時會采用反諷、對比等修辭手法來表達觀點,正、負面情感文本有可能表達同一種立場,而現行的情感分析方法采用機器學習的特征詞提取方法進行識別,在針對隱晦和不敏感文本無法準確進行識別。由此,該文提出一種基于深度學習的立場分析方法。
立場分析通常采用預訓練來解決數據匱乏的問題。在針對SemEval-2016任務6中,Augenstein[1]采用skip-gram和LSTM(BiLSTM)分析推特立場,所得的F1值為58%。Zarrella[2]使用了skip-gram結合RNN模型,平均F1值為67.8%。周艷芳[3]在針對NLPCC-2016任務4中提出基于遷移學習的字、詞特征混合立場分析方法,F1值達到72.2%。胡瑞雪[4]提出基于BERT-LSTMCNN的立場分析方法,所得F1值可達87%。
受到胡瑞雪[4]的BERT-LSTMCNN模型啟發,該文對LSTM和CNN部分采用并行輸入輸出,提高立場分析的準確率,同時采用了多模型對比實驗方法驗證該模型的高效性。
1 基于深度學習的立場分析
深度學習方法的特點在于提取特征上實現自動化[5],在許多領域取得了較好的效果,文本立場分析任務上也涌現出越來越多的深度學習方法。
在卷積神經網絡的立場分析方法上,Yuki等人[6]采用CNN模型通過自動檢測主題詞和有效詞來檢測立場。Wei等人[7]通過建立一個二分類的訓練數據集,然后修改歸一化層來執行三分類檢測Twitter文本立場。Yaakov等人[8]則是提出了基于有限數量特征的立場分類任務實現。
在長短時記憶神經網絡的立場分析方法上,岳重陽[9]提出了基于注意力的雙向長短時神經網絡。Kuntal等人[10]提出了一種基于LSTM的兩階段模型T-PAN。
王安君等人[11]在基于深度學習的分類框架上,為了將話題信息結合進來,提出了BERT-Condition-CNN模型。Sun等人[12]提出使用一個共享的長短時記憶網絡(Long Short-Term Memory,LSTM)層來學習立場和情感信息之間的深層共享表示,然后將共享的表示信息進行疊加,將情感檢測的隱含層輸出作為立場分析的附加輸入進行聯合學習,利用情感信息來促進立場分析的效果。
2 模型介紹
在針對NLPCC2016立場分析任務上,受到胡瑞雪[4]模型的啟發,該文提出了基于BERT-LSTMCNN的并行輸入輸出模型。通過BERT語言預訓練模型對輸入的字建模,生成詞嵌入向量,再分別輸入LSTM和CNN網絡,得到全局特征向量和局部特征向量,然后將其拼接,最后使用softmax函數進行分類。模型架構如圖1所示。
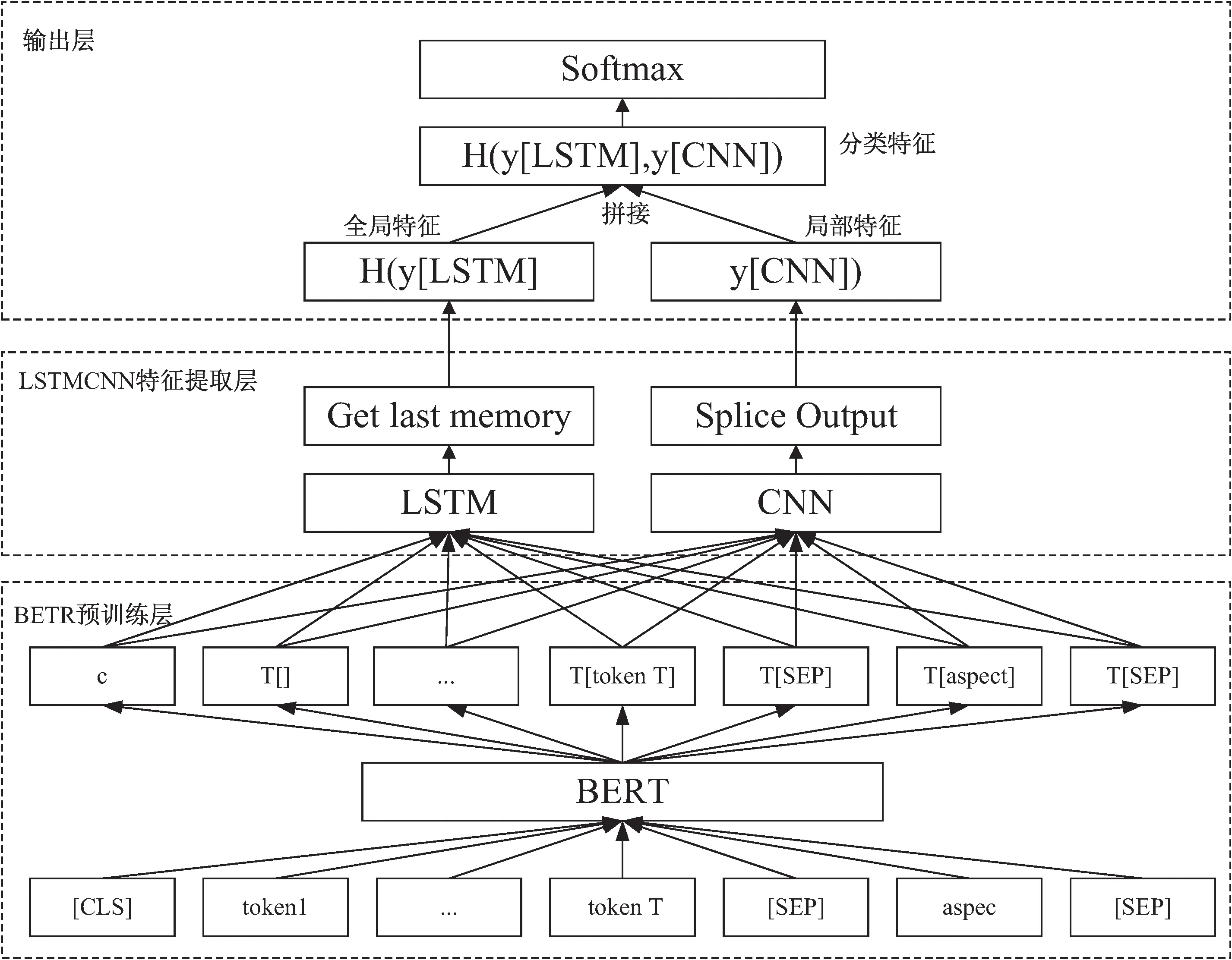
圖1 BERT-并行LSTMCNN網絡模型
2.1 BERT預訓練
BERT的核心是雙向的Transformer模型,具有可變數量的編碼層和自注意力模型。當BERT模型進行預訓練形成語言表示模型后,只需對模型進行遷移學習網絡訓練,即可應用于下游特定性語言處理任務,對于字級、句級、句子對級的自然語言處理任務均使用。
模型在輸入層采用多層相加輸入的方式,其中就有Token嵌入層、Segment嵌入層和Position嵌入層[13]。Token嵌入層是為了將字詞映射為實際有值的向量;Segment嵌入層采用將實際值賦值給第一個句子中所有的字詞,另一個實際值則賦值給了第二個句子中所有字詞,目的是為了形成句子對;Position嵌入層會將字詞中兩個句子的中間位置變為位置向量,以便后續更好地進行運算。
預訓練主要有兩個任務,分別是掩碼語言模型(MLM)和下一句預測(NSP)。MLM任務使用了Mask(面具)對15%已分類的單詞進行屏蔽,然后通過BERT模型進行預測,并且在最終的損失函數計算被遮蓋住的標記。該任務的目的是關注預料集中的每個詞語,從而得到更準確的上下文語義信息。
NSP的目的是讓模型理解句子間的關聯性,可在任何一個級別語料庫進行訓練,對句子對A和B,B有一半的概率是緊隨A的實際下一句(IsNext),另一半概率則是語料庫中的隨機句子(NotNext)。將這個句子對拼接時在句首添加標識[CLS],A、B間則用標識[SEP]分隔開,并對[CLS]做二分類任務。
2.2 LSTM與CNN的融合應用
LSTM模型是通過在RNN模型的隱藏層中加入了細胞記憶單元結構,進一步使得LSTM模型具有學習到長期以來信息的能力,用于全局信息的提取;CNN作為一種前饋神經網絡模型,采用了使卷積層和池化層交替堆疊的方式實現卷積的功能,其核心在于卷積層對于數據局部特征的提取[14]。
在LSTM和CNN的特征提取層中,令得到的向量H分別輸入到LSTM和CNN神經網絡中,在LSTM網絡之后接入一個激活層,在得到激活層輸出的最后一個狀態時可以輸出得到向量yLSTM。在CNN中,是由一個卷積層、一個激活層和一個最大池化層組成,再對CNN網絡進行多卷積核的輸出進一步合并處理得到yCNN。
將LSTM與CNN融合使用可以同時利用LSTM提取全局特征與CNN識別局部特征的能力。Pedro M.Sosa[15]在對推特文本立場分析實驗中,發現使用CNN-LSTM模型時,比CNN模型提高3%,而針對LSTM模型,則是降低了3.5%。在另外一組實驗中,使用LSTM-CNN模型比使用CNN模型的對照組提高8.5%,和LSTM模型相比,則提高2.7%,CNN和CNNLSTM模型性能表現差且需要更多的輪數(EPOCH)去提升模型效能以及減少過擬合。
所以,在該實驗的基礎上,該文采用并行的LSTMCNN結構,同時利用LSTM提取全局的文本特征和CNN網絡挖掘文本局部關聯性的能力,以達到優良的輸出效果。
3 數據預處理
3.1 中文文本數據預處理
大量的研究數據表明,數據預處理對于分類是否高效起著決定性的作用,訓練模型的魯棒性也會因數據預處理而產生相應改變,分類結果準確性也會因此改變[16]。
在數據預處理方面,首先是標注文本立場,針對小規模樣本,采用的訓練集、測試集和驗證集的最佳比例標準為0.6∶0.2∶0.2,采用jieba庫進行分詞,并對停止詞、低頻詞以及非正式文本進行刪除,減少噪聲干擾,以達到簡化操作的效果。
3.2 最優字個數維度判定算法
最優字個數維度算法目的在于計算BERT模型的最優輸入序列長度,以緩解文本數據稀疏造成誤差的問題。
在最優字個數維度判定算法中,中文文本總是以正整數的方式出現,在維度上也是有限的,而變量的取值為離散型的自然數,公式如式(1)和式(2)所示。
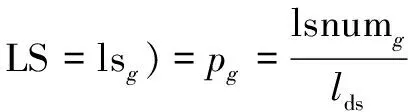
(MIN(ls)≤g≤MAX(ls))
(1)
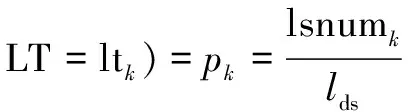
(MIN(lt)≤k≤MAX(lt))
(2)
式中,文本長度的分布概率記為P(LS),話題長度分布概率記為P(LT)。對此定義lsnumg為文本條數,數據集總條數為lds,所取比值即為文本長度分布概率,在表示范圍中,MIN(ls)為最小文本長度,MAX(ls)為最大文本長度,長度分布概率同上。
相對的,文本長度概率函數F(LS)和話題長度概率函數F(LT)公式如下:
(3)
(4)
式(3)表示當前文本長度取(lsa,lsb]時的概率,所計算出的概率是關于話題長度的函數,稱為分布函數;式(4)則表示話題長度取(lta,ltb]時的概率[17]。
4 實驗分析
4.1 實驗數據
實驗采用了NLPCC2016的中文微博文本立場檢測任務的數據集。所用到的微博話題如表1所示,所取字數均值為5到8,所取數據集標注方式和開源數據集均相同,評論文本采集于新浪微博,總計訓練集數據為3 000條,驗證集與測試集分別為1 000條。
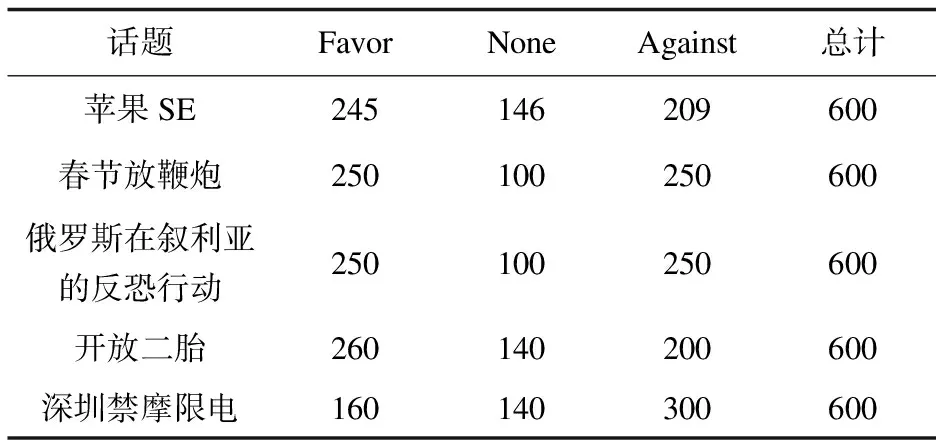
表1 話題數據集統計數據
可以看出,所取得的五個話題的數據體現了開源數據集的相關特性,并且在數據中不僅僅有鮮明的表達立場的評論,也存在隱晦或未直接表達的評論[18]。
4.2 實驗內容
為了對比本次實驗中所提模型的性能,設立對照實驗組,分別設計以下模型:
(1)CNN模型:輸入層128維,學習率1e-5,丟棄率為0.5,批處理參數(batch_size)為32,輪數(EPOCH)為10。
(2)LSTM模型:隱藏層為128維,其余參數設置同上。
(3)LSTMCNN模型:先接入LSTM進行全局特征提取,再將結果接入CNN進行局部特征提取,參數設置同上。
(4)CNNLSTM模型:先接入CNN進行局部特征提取,再將結果接入LSTM進行全局特征提取,參數設置同上。
(5)BERT預訓練+LSTMCNN神經網絡:采用BERT-Base,Chinese語言模型,批處理參數(batch_size)設置為32,Token序列的最大長度為128,輪數(EPOCH)為10。
本次實驗中,評價模型的性能指標如下:
(1)準確率:
(5)
其中,TP表示正例,FP表示偽正例,準確率表示預測正例中真正正例的比例。
(2)召回率:
(6)
其中,TP表示正例,FN表示偽反例,召回率表示預測正例占全部正樣本的比例。
(3)F1-評測值:
(7)
本次實驗的系統環境是Windows10,編程語言為python3.6,采用了谷歌發布的BERT中文預訓練模型“BERT-Base,Chinese”,CPU為Intel(R)Core(TM)i7-10875H,GPU為GeForce GTX 1070,實驗平臺Keras版本為2.6.0,TensorFlow版本為2.6.2。
4.3 實驗結果與分析
對上述話題和文本數據進行最優字個數維度判定算法處理,對5個目標話題和對應文本進行計算,分別提取出話題長度、話題最優長度、評論文本最長長度和評論文本的最優長度,得出的結果如表2所示。
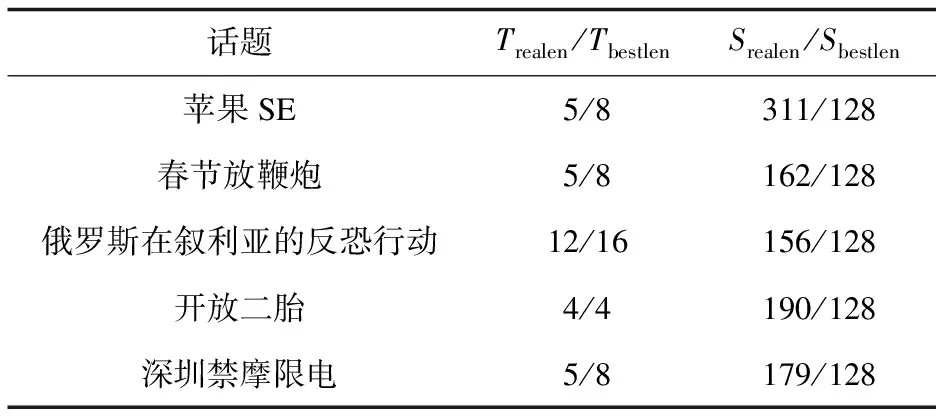
表2 話題和文本的字維度大小
由表2可以得知,當目標話題字維度和評論文本字維度均取到2的n次方倍時,所得數據有且可為最佳,因此,在BERT預訓練過程中,輸入作為2的n次方倍時,進一步處理及計算特征表征時,效果較為優秀,同時對后續準確率提升較為顯著[19]。
使用BERT+全連接神經網絡驗證字維度大小對立場檢測的影響。在文中分別對不同話題進行分析,在特征表征上選取原始BERT預訓練語言模型訓練。特征抽取上,選擇全連接層進行提取,實驗方面,分別對五個話題和相關評論進行訓練,結果如表3、圖2所示,評價指標為式(7)中的F1(Avg)。

表3 字個數維度不同時對立場檢測的影響
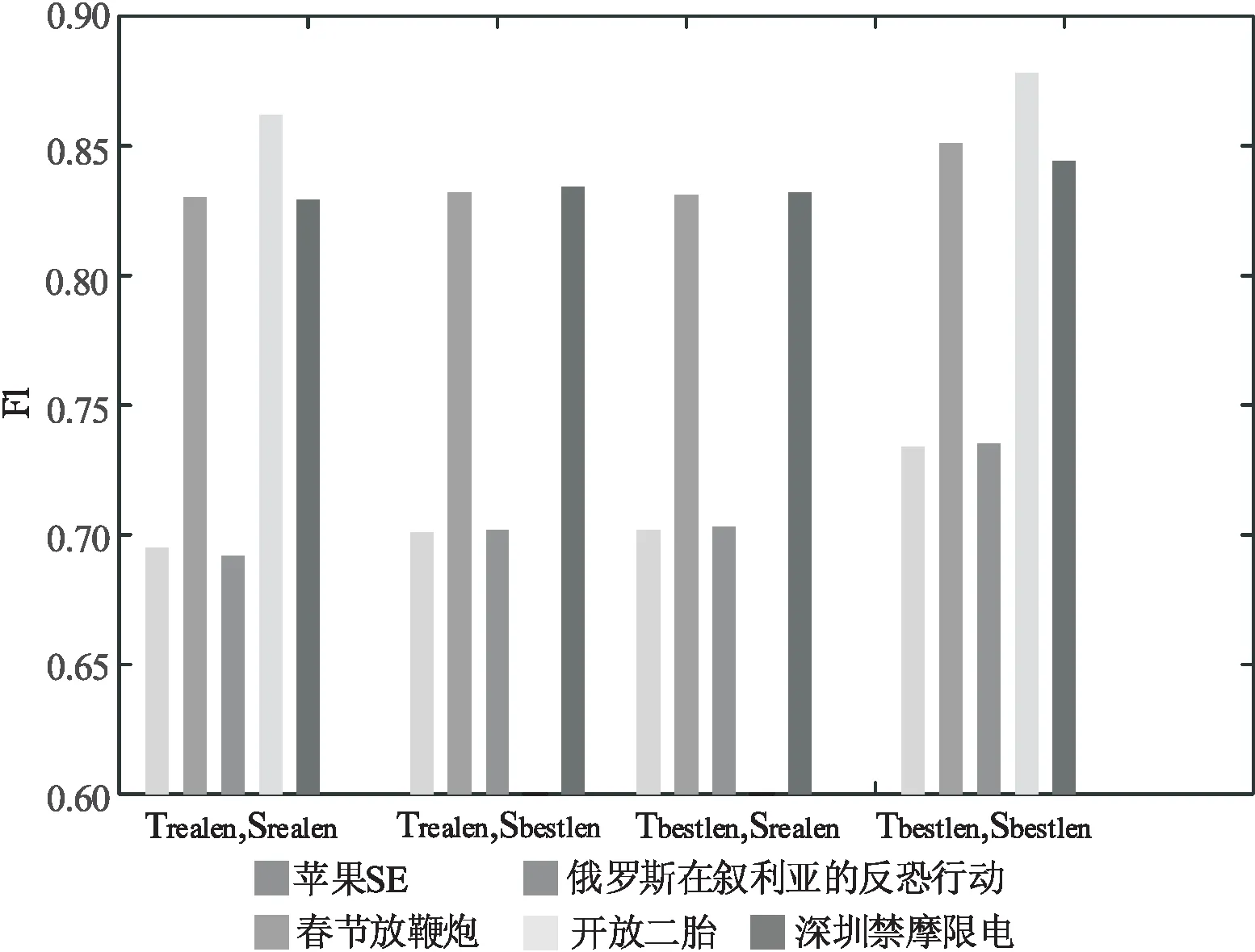
圖2 字個數維度不同時對立場檢測的影響
如表3所示,當目標話題和評論文本字個數維度均取最佳時[20],F1值約比其他情況高3%, 同時,當目標話題文本字個數維度取到4時,可以得到最佳性能。
Tbestlen,Sbestlen表示目標話題的最優字個數維度和微博文本最優字個數維度的組合,當話題和文本都是最佳字數時效果最佳。
使用提出的實驗模型對話題文本都使用最優字個數進行立場分析,首先對不使用BERT模型進行預訓練的相關神經網絡模型進行實驗,驗證CNN、LSTM、CNNLSTM、LSTMCNN模型的F1值與EPOCH輪數分析圖,如圖3所示,數據如表4所示。
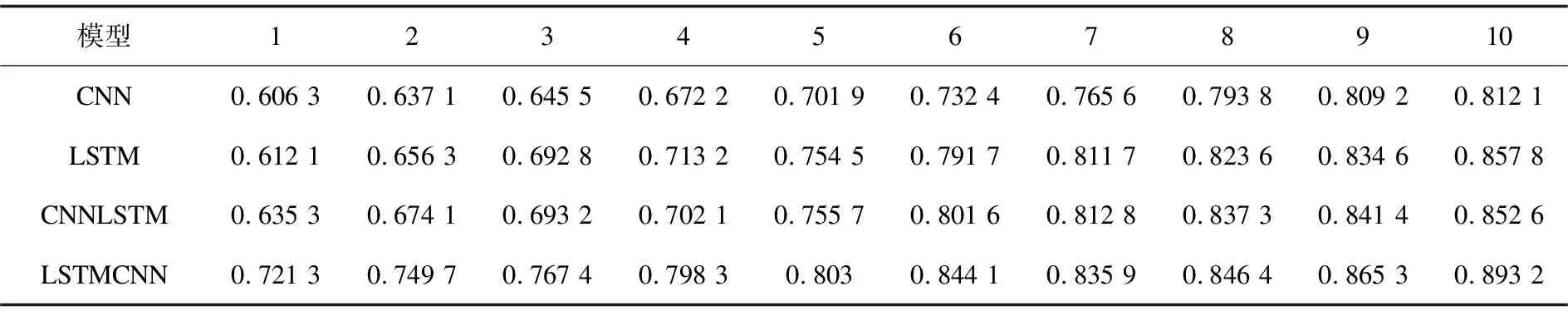
表4 CNN、LSTM、CNNLSTM、LSTMCNN模型的F1值數據
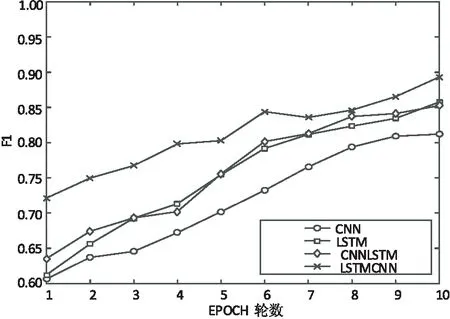
圖3 部分實驗模型的F1值
由圖3可以看出,在CNN、LSTM、CNNLSTM、LSTMCNN模型中,所得結果的帶“*”曲線始終領先,故在該次實驗中,可以證明LSTMCNN領先于其他三個模型。
其次,在不使用BERT模型進行預訓練下即對表4中的最優模型和所提模型進行分析,驗證LSTMCNN、BERT-LSTMCNN模型的F1值與EPOCH輪數分析圖,如圖4所示,數據如表5所示。

表5 LSTMCNN、BERT-LSTMCNN模型的F1值數據
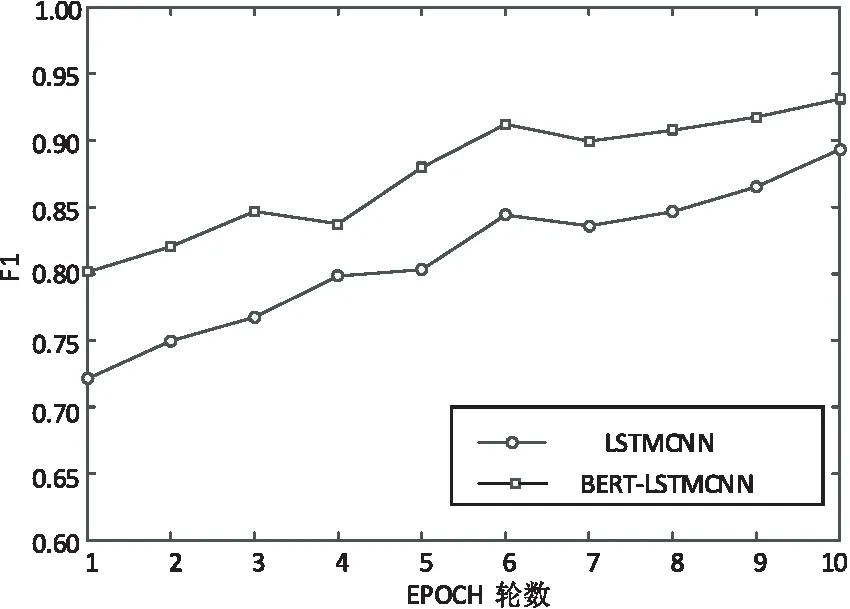
圖4 LSTMCNN、BERT-LSTMCNN模型的F1
在LSTMCNN和BERT-LSTMCNN圖表中可以看出,經過BERT預訓練后對該數據集的立場檢測任務有明顯的提高,平均相對沒有經過BERT預訓練的LSTMCNN神經網絡模型提高約8%。
在采用了BERT模型進行預訓練后,相對于普通模型,BERT模型在學習率的提升上較為顯著,該模型所具備的“微調”的優勢相對更為顯著[21],對自我的輸出及后接模型的自我學習機制有較大的提升,接下來將用實驗結果來進一步闡述,所得數據如表6所示。
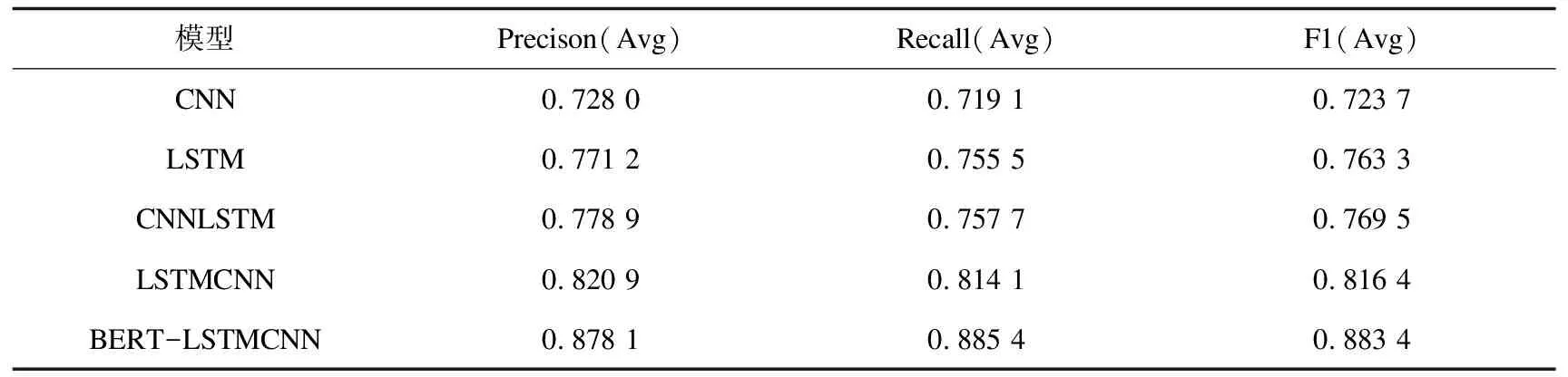
表6 實驗結果
從表6中分析可知,當同等參數設置下,BERT-LSTMCNN模型性能是最佳的,所得F1值約為88.3%。由實驗數據可以看出,結合LSTM和CNN模型均能提升模型性能,其中,LSTMCNN優于CNNLSTM,并且,加入BERT模型進行預訓練對F1值提高較為顯著,提升約7%。
同時,對比現有模型,所提模型相對周艷芳[3]所提出的基于遷移學習的字、詞特征混合立場分析方法,F1值高出約16%,相對胡瑞雪[4]提出的基于BERT與串行LSTMCNN模型的立場分析方法,F1值高出約1%,因此,所提模型具有更優越的性能。
5 結束語
立場分析作為情感分析領域的一個新興方向,在文本分類任務中,主要做自動分析在線評論對于目標話題支持與否的態度。該文結合了微博文本立場分析任務,通過利用相關算法及建立相關模型進行了詳細的研究工作。
在實驗中可以得出結論,當目標話題最優字數維度和文本最優字數維度相結合時,對于后續的預訓練有顯著的提高效果;使用BERT預訓練模型及并行輸入輸出的記憶卷積網絡,相對于其他模型有更好的效能。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年18期)2018-11-14 01:48:06
山東工業技術(2016年15期)2016-12-01 05:31:22
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
小學教學參考(2015年20期)2016-01-15 08:44:38
