基于全局時空注意力機制和PCA_3DNet的動作識別方法
2023-08-30 05:15:48田秋紅張元奎潘豪李賽偉施之翔
浙江理工大學學報 2023年5期
田秋紅 張元奎 潘豪 李賽偉 施之翔


摘 要: 針對基于3D卷積神經網絡的動作識別方法存在參數量過大、無法捕捉時空特征的全局依賴關系等問題,提出了一種基于全局時空注意力機制(Global spatiotemporal attention mechanism,GSTAM)和PCA_3DNet的動作識別方法。該方法引入偽3D卷積結構減少網絡參數,在偽3D卷積結構中嵌入通道注意力機制(Channel attention mechanism,CAM)來增強通道特征,并采用全局時空注意力機制來捕捉特征信息的全局依賴關系,加強時空特征的表征能力,從而提高動作識別的準確率。該方法在兩個公開數據集UCF101和HMDB51上的識別準確率分別為93.5%和70.5%,模型參數量為13.46 Mi,浮點運算量為8.73 Gi;在準確率、參數量和計算量上的綜合表現優于現有的傳統方法和深度學習方法。實驗結果表明該方法能夠獲取豐富的時空特征信息,有效提升動作識別的性能。
關鍵詞:全局時空注意力機制;PCA_3DNet;通道注意力機制;時空特征;動作識別
中圖分類號:TP391
文獻標志碼:A
文章編號:1673-3851 (2023) 05-0310-08
引文格式:田秋紅,張元奎,潘豪,等. 基于全局時空注意力機制和PCA_3DNet的動作識別方法[J]. 浙江理工大學學報(自然科學),2023,49(3):310-317.
Reference Format: TIAN? Qiuhong,ZHANG? Yuankui,PAN? Hao,et al. Action recognition method based on global spatiotemporal attention mechanism and PCA_3DNet[J]. Journal of Zhejiang Sci-Tech University,2023,49(3):310-317.
Action recognition method based on global spatiotemporal attention mechanism and PCA_3DNet
TIAN Qiuhong, ZHANG Yuankui, PAN Hao, LI Saiwei, SHI Zhixiang
(School of Computer Science and Technology, Zhejiang Sci-TechUniversity, Hangzhou 310018, China)
Abstract: In view of the fact that the action recognition method based on three-dimensional (3D) convolutional neural network has the problems of too many parameters and cannot capture the global dependence of spatiotemporal features, an action recognition method based on global spatiotemporal attention mechanism (GSTAM) and PCA_3DNet is proposed. In this method, the pseudo 3D convolution structure is introduced to reduce network parameters, the channel attention mechanism (CAM) is embedded in the pseudo 3D convolution structure to enhance the channel features, and the GSTAM is adopted to capture the global dependence of feature information and strengthen the representation ability of spatiotemporal features, so as to improve the accuracy of action recognition. The recognition accuracy of this method on two public datasets UCF101 and HMDB51 is 93.5% and 70.5%, respectively, the amount of model parameters is 13.46 Mi, and the floating point of operations is 8.73 Gi. The comprehensive performance in accuracy, parameters and computation outperforms the existing traditional methods and deep learning methods. The experimental results show that the method can obtain abundant spatiotemporal feature information and effectively improve the performance of action recognition.
Key words:global spatiotemporal attention mechanism; PCA_3DNet; channel attention mechanism; spatiotemporal feature; action recognition
0 引 言
動作識別在智能視頻監控[1]、運動分析、智能人機交互等領域有著廣泛的應用前景[2],已經逐漸成為一個非常熱門且具有挑戰性的研究方向。目前動作識別方法主要分為傳統動作識別方法和基于深度學習的動作識別方法[3]。傳統動作識別方法主要通過手工提取視頻動作的運動特征。Wang等[4]提出密集軌跡(Dense trajectories, DT)算法來獲取視頻動作的運動軌跡,提取方向梯度直方圖(Histogram of oriented gradient, HOG)[5]、光流方向直方圖(Histograms of oriented optical flow, HOF)[6]特征。許培振等[7]對DT算法進行改進,提出了改進的密集軌跡(Improved dense trajectories, IDT)算法,該算法通過加速穩健特征(Speeded-up robust features, SURF)匹配算法來獲取視頻幀之間的光流特征。Patel等[8]利用運動目標檢測和分割,提取出運動對象的HOG特征,并融合速度、位移及區域特征來表征動作。Xia等[9]對IDT的光流軌跡算法進行了擴展,設計了一種多特征融合的描述子表示動作。傳統動作識別方法的局限在于動作識別的準確率較低,手工提取特征不夠充分,并且計算成本較大。
隨著深度學習技術的迅速發展,越來越多的研究人員利用卷積神經網絡[10]自動提取圖像特征。Simonyan等[11]提出了一種雙流動作識別網絡,該網絡通過空間流網絡和時間流網絡來提取外觀特征和運動特征,但是該網絡主要考慮外觀和短期運動,不利于建模時間跨度較大的視頻任務。Wang等[12]提出了一種時間分段網絡(Temporal segment networks, TSN)來彌補雙流網絡中建模長時間視頻動作的不足;Wang等[13]又對TSN網絡進行了改進,提出了一種能夠捕獲多尺度時間信息的時間差異網絡(Temporal difference networks,TDN)。雖然上述方法[11-13]能夠提取出視頻中動作的時間特征和空間特征,但是這些方法在時空特征提取上是相互獨立的。Tran等[14]使用三維卷積網絡(Convolutional 3d networks,C3D)來直接學習視頻中動作的時空特征。Carreira等[15]將InceptionV1網絡中所有二維(Two-dimensional, 2D)卷積全部膨脹成三維(Three-dimensional, 3D)卷積,提出了膨脹三維卷積網絡(Inflated 3d convolution networks, I3D)。Hara等[16]將3D卷積應用到殘差網絡上,提出了三維殘差網絡。Qiu等[17]提出了一種偽三維卷積網絡(Pseudo-3D convolution networks, P3D),該網絡通過偽3D卷積結構來擬合3D卷積,從而緩解了3D卷積導致模型參數量過大的問題,并且實驗驗證了偽3D卷積結構的有效性。上述研究人員采用了多種3D卷積神經網絡用于動作識別,但是在使用3D卷積進行特征提取的過程中,無法區分關鍵動作特征和背景特征,且在卷積過程當中無法獲取特征的全局依賴關系。
注意力機制被引入卷積神經網絡之后能夠顯著提升網絡的性能,使得網絡關注圖像中關鍵的信息,抑制無關信息[18]。Wang等[19]將一種殘差注意網絡應用于圖像分類任務上,并取得較好的分類效果。Jaderberg等[20]提出了一種空間注意力機制,將原始圖像的空間信息轉換到另一個空間,保留其關鍵信息,結果表明該方法能夠有效提高模型性能。Hu等[21]提出了一種通道注意力模型SeNet,通過對輸入特征圖的通道賦予不同的注意力權重來學習不同通道特征的重要性。Woo等[22]結合上述兩個方法提出了一種卷積塊注意力模型(Convolution block attention module, CBAM),該模型由通道注意力模塊和空間注意力模塊構成。Lei等[23]提出了一種通道式時間注意力網絡,該網絡通過通道注意力來強調每一幀的細粒度信息特征,且實驗證明了該注意力可以提升網絡模型的表達能力。雖然上述研究方法在動作識別的任務中取得了一定的效果,但是仍然沒有考慮到時空特征的全局依賴關系。
本文針對動作識別方法中存在的特征提取不充分、參數量過多、無法捕獲時空特征的全局依賴關系等問題,提出了一種基于全局時空注意力機制和PCA_3DNet的動作識別方法。為了減少模型的參數量,本文引入偽3D卷積結構代替3D卷積結構,采用串聯1×1×3卷積和3×3×1卷積的方式來擬合3×3×3卷積,以減少參數量;為了充分利用動作特征的通道信息,將通道注意力機制嵌入偽3D卷積結構中,實現通道特征信息的增強,并設計了PCA_3DNet網絡模型作為特征提取網絡;加強時空特征的表征能力,將全局時空注意力機制加入PCA_3DNet網絡中,對時空特征的全局依賴關系進行建模,以提高視頻動作特征的提取能力。
1 方法設計
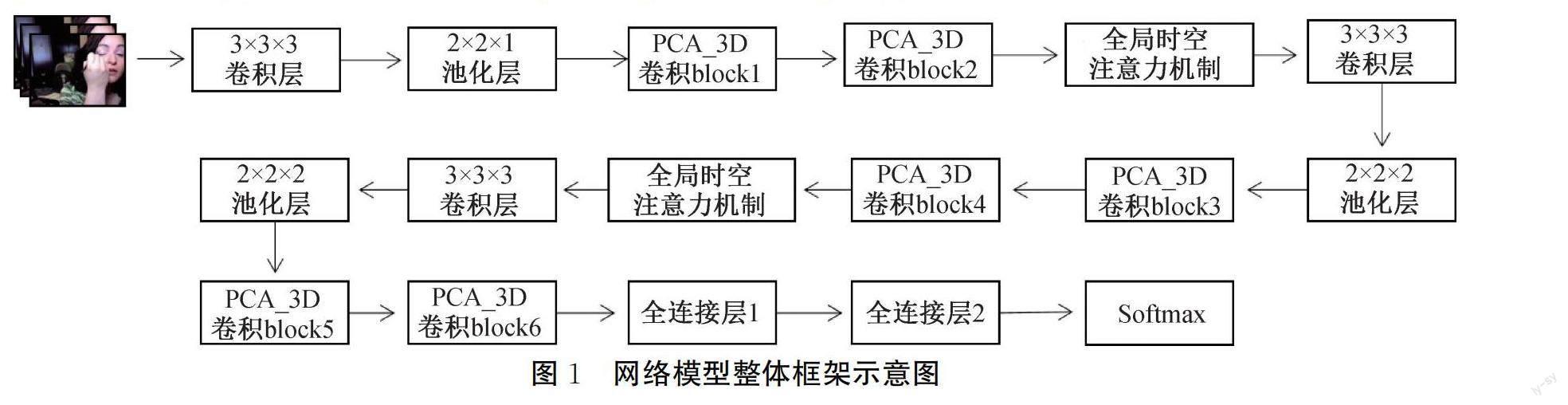
本文設計了一種基于全局時空注意力機制和PCA_3DNet的動作識別網絡模型,該模型整體框架示意圖如圖1所示。首先采用稀疏采樣的方法提取視頻幀序列作為模型的輸入;然后通過PCA_3D卷積block提取視頻動作特征,并加入全局時空注意力機制學習時空特征的全局依賴關系,使模型提取到更豐富的動作特征;最后使用Softmax層實現動作識別。
1.1 PCA_3DNet
本文通過PCA_3D卷積block構建了特征提取網絡——PCA_3DNet,其包含6個PCA_3D卷積block,PCA_3D卷積block結構示意圖如圖2所示。
首先基于3D卷積層對輸入特征X∈RH×W×T×C提取時空特征,其中:H、W、T和C分別表示特征圖的高度、寬度、時間深度和通道數。在PCA_3D卷積block中,通過偽3D卷積結構[17](偽3D卷積結構由1×1×3卷積層和3×3×1卷積層構成)來模擬3×3×3卷積提取時空特征,以減少參數量。3D卷積層參數量的計算公式為:(kh×kw×kt×nic+1)×noc,其中:kh、kw、kt為3D卷積核在高、寬、時間三個維度的大小,nic為輸入特征圖的通道數量,noc為3D卷積核的數量。其次,本文在PCA_3D卷積blcok中嵌入通道注意力機制(Channel attention mechanism,CAM)模塊,該模塊針對輸入特征X的通道關系進行建模,能夠獲取特征的通道信息權重分布,加強有用通道特征,抑制無關通道特征,從而增強PCA_3D卷積block的特征提取能力。最后利用特征融合層將1×1×1卷積層的輸出特征和CAM模塊的輸出特征相融合,得到PCA_3D卷積block的輸出特征X′。其中在PCA_3D卷積block中嵌入的通道注意力機制結構示意圖如圖3所示。
CAM模塊首先利用特征線性轉換層將輸入特征X∈RH×W×T×C轉換成UC∈RH×W×T×C;其次基于全局平均池化操作和全局最大池化操作將UC∈RH×W×T×C壓縮為UGAP∈R1×1×1×C和UGMP∈R1×1×1×C,生成兩個不同的通道特征描述符UGAP和UGMP。通道特征描述符UGAP和UGMP對輸入特征的全局像素進行計算,因此UGAP和UGMP具有全局時空特征的感受野。上述計算過程可用式(1)—(3)表示:
UC=Tran(X) ???(1)
其中:Tran( )表示在輸入特征X上的相應通道上進行1×1×1卷積線性轉換;GAP()表示全局平均池化操作,GMP()表示全局最大池化操作;UC表示經過1×1×1卷積層線性轉換后的輸出特征;i、j、k分別表示在特征圖UC中H、W、T維度上的位置。
為了學習更為豐富的通道特征,本文選擇使用特征融合層來融合兩個通道特征描述符UGAP和UGMP,生成混合通道特征描述符UMix∈R1×1×1×C;隨后將混合通道特征描述符UMix輸入到MLP(多層感知機),并經過Sigmoid和Reshape操作生成通道特征相關性描述符SC∈R1×1×1×C;最后,將通道特征相關性描述符SC和特征UC逐通道相乘,得到通道注意力特征FC∈RH×W×T×C。上述計算過程可用式(4)—(6)表示:
其中:FC是CAM模塊的輸出特征,U表示矩陣相乘,σ表示sigmoid函數操作,⊕表示特征融合操作。
1.2 全局時空注意力機制模塊
在3D卷積過程中,輸出特征的目標特征,是由輸入特征和卷積核在感受野范圍內進行局部內積運算得到,所以3D卷積在特征提取的過程中僅僅考慮到了輸入特征的局部信息。3D卷積過程示意圖如圖4所示。
圖4中輸出特征的目標特征僅僅作用于輸入特征的局部區域,然而對于輸入數據是視頻幀序列,目標特征不僅僅依賴于輸入特征中的局部特征信息,還可能依賴于其他時空特征信息。因此本文提出了全局時空注意力機制(Global spatiotemporal attention mechanism, GSTAM)模塊,該模塊通過計算當前特征位置和其他時空特征位置的相關性來捕獲時空特征之間的全局依賴關系,全局時空注意力機制結構示意圖如圖5所示。
GSTAM模塊首先將輸入特征X∈RH×W×T×C分別經過3個1×1×1卷積,得到X1、X2、X3∈RH×W×T×C。其次,將特征圖X2和特征圖X3輸入多尺度池化層,多尺度池化層結構示意圖如圖6所示,通過多尺度池化層對X2、X3進行降采樣操作,得到XMP2、XMP3∈RH1×W1×T1×C,其中:H1、W1、T1分別表示特征圖的高度、寬度和時間深度。然后對特征圖X1、XMP2、XMP3進行矩陣變換得到XR1∈RN×C(N=H×W×T)、XR2∈RC×S(S=H1×W1×T1)、XR3∈RS×C(S=H1×W1×T1);將XR1和XR2進行矩陣相乘計算當前特征位置和其他特征之間的相關性,并通過Softmax函數生成全局時空注意力權重系數XS∈RN×S。在得到全局時空注意力權重系數后,將其和XR3進行逐元素相乘得到包含注意力的特征圖XA∈RN×C,之后將XA進行通道重塑后和輸入特征X進行殘差連接,得到GSTAM模塊的輸出特征F∈RH×W×T×C。
多尺度池化層結構由池化核大小分別為2、4、8的最大池化層組成,通過多尺度池化層結構能夠從多維度壓縮特征,提取出不同尺度的池化特征,使得網絡能夠學習到不同尺度下的特征信息,并且多尺度池化層結構降低了GSTAM模塊中特征圖的大小,從而減少了矩陣相乘產生的較大計算量。
2 實驗與結果分析
本文在UCF101和HMDB51這兩個具有挑戰性的動作識別數據集上測試本文提出的方法,并且從不同的角度來驗證本文提出方法的有效性和可行性。
2.1 數據集
UCF101數據集:該數據集是一個真實動作視頻集,該數據集包含101類動作,一共有13320個視頻片段,每個類別的視頻動作分為25組,每組包含4~7個視頻動作,視頻類別主要分類5類,分別是人與物體交互、人體動作、人與人交互、樂器演奏、體育運動[24]。部分示例視頻截圖如圖7所示。
HMDB51數據集:該數據集包含了51類動作,共有6849個視頻片段。視頻類別主要分為面部動作、面部操作、身體動作、交互動作、人體動作等5類,如抽煙、拍手、打球、擁抱等動作,該數據集的視頻大多來源于電影剪輯片段,小部分來源于YouTube等視頻網站,像素較低[25]。部分示例視頻截圖如圖8所示。
2.2 實驗過程
本文實驗基于Python3.7、Tensorflow2.0、Keras2.0實現,選擇稀疏采樣的方法從視頻片段中提取視頻幀作為模型的輸入,在UCF101數據集上分別選取8、12、16幀視頻幀作為模型輸入進行了實驗,實驗結果如表1所示。根據實驗確定本文網絡模型輸入大小設置為112×112×16×3,采用Adam()優化器學習網絡參數,batch大小設置為16,初始學習率設置為0.001,權重衰減設置為0.005,防止過擬合添加的Dropout層的失活率設置為0.5,模型訓練迭代次數達到150次后終止訓練。
2.3 消融實驗
為了驗證在PCA_3D卷積block中嵌入的CAM模塊和在PCA_3DNet中添加的GSTAM模塊的可行性和有效性,本文在UCF101數據集上進行了消融實驗。
本文分別使用P3D卷積結構搭建的Baseline模型、Baseline+CAM(PCA_3DNet)模型、Baseline+GSTAM模型、Baseline+CAM+GSTAM(本文方法)在UCF101數據集上進行實驗。實驗結果見圖9。從圖9(a)中可以看出,當本文分別在Baseline模型的基礎上添加CAM模塊、GSTAM模塊后,模型的準確率都比Baseline模型高,說明CAM模塊和GSTAM模塊可以增強模型的特征提取能力,提升模型性能。當本文將CAM模塊和GSTAM模塊都添加到Baseline模型當中,本文方法的準確率比Baseline模型、Baseline+CAM模型和Baseline+GSTAM模型都高,說明加入CAM模塊和GSTAM模塊后,本文方法可以提取到更加豐富的特征,使得網絡模型的性能顯著提升。從圖9(b)中可以看出,在前30次迭代的時候,各組實驗模型的損失值都下降最快;在迭代到100次以后,各組實驗模型的損失值都趨于穩定,而本文所采取的Baseline+CAM+GSTAM模型的波動性最小,損失值更加穩定。實驗結果表明:CAM模塊能夠有效增強通道特征,GSTAM模塊能夠學習時空特征的全局依賴關系,添加兩個模塊能夠增強模型的特征提取能力,有效提升網絡模型的識別準確率。
本文同時在參數量和浮點運算量(Floating point operations, FLOPs)方面來評估CAM模塊和GSTAM模塊的有效性,其中FLOPs可以表示為計算量,用于衡量模型方法的復雜度。實驗結果見表2。從表2中可以看出,Baseline模型的浮點運算量為8.53 Gi,參數量為13.19 Mi。在分別添加了CAM模塊和GSTAM模塊后,模型的浮點運算量的增量以及參數量的增量非常少,但是準確率上的提升較為明顯,意味著本文以較小的內存代價、計算量代價換取了準確率較大的提升,并且本文方法的浮點運算量的增量為0.20 Gi,參數量的增量為0.27 Mi,準確率卻提升了5.96%。實驗結果表明:本文提出的CAM模塊以及GSTAM模塊可行并且有效,能夠提升模型的性能且花費的計算成本較低。
2.4 方法對比
為了驗證本文方法的可行性,本文將本文方法與主流方法在UCF101數據集和HMDB51數據集上進行對比實驗,實驗結果見表3所示。從表3中可以看出,在UCF101數據集上,除了I3D(Two-Stream)[15]和TSN(RGB+Flow)[12]外,本文方法和其他方法相比都顯示出了優勢。而I3D(Two-Stream)模型和TSN(RGB+Flow)模型都需要進行光流的計算,這會增加模型的計算的復雜度,并且影響模型的實時性能。在HMDB51數據集上,本文方法和其他方法相比,本文方法準確率最高,性能表現最佳。實驗結果表明:本文方法在不同的數據集上都具備較高的準確率,模型泛化能力強,魯棒性高。
此外,本文方法的準確率比C3D模型高了7.7%;與P3D模型相比提高了4.9%;與Two-Stream模型相比提高了5.5%。雖然I3D(Two-Stream)模型和TSN(RGB+Flow)模型在UCF101數據集上的準確率比本文方法高0.2%和0.7%,但是這兩種方法引入了雙流結構并將光流數據作為輸入,而本文方法僅需RGB數據作為輸入,減少了光流數據的計算成本。
為了進一步驗證本文方法的有效性,本文和主流方法在浮點運算量和參數量上進行了對比實驗,實驗結果見表4。從表3—表4中可以看出,雖然I3D(Two-Stream)在準確率上面比本文方法高0.2%,但是該模型是直接將Inception V1中的2D卷積膨脹成3D卷積,從而在參數量方面遠遠超過本文方法,說明該模型需要耗費更多的內存代價;TSN(RGB+Flow)模型雖然在UCF10數據集準確率比本文方法高0.7%,但是該方法的浮點運算量為16 Gi,約是本文方法的兩倍,并且TSN模型在使用RGB數據作為輸入的時候,準確率比本文方法低8.4%。本文方法與C3D模型和P3D模型相比,參數量約為C3D模型的1/6、P3D模型的1/5。在浮點運算量方面,本文方法的浮點運算量較小,說明本文方法的模型復雜度低,和其他方法相比,本文方法也具備優勢。實驗結果表明本文方法在模型準確率、模型參數量、模型計算量等方面取得了較好的平衡,在具有較低的參數量和計算量的同時能夠擁有較高的準確率。
3 結 論
本文提出了一種基于全局時空注意力機制和PCA_3DNet的動作識別方法。該方法通過搭建PCA_3DNet作為主干特征提取網絡,并且利用其內部的PCA_3D卷積block結構來減少網絡參數以及增強通道特征信息;通過全局時空注意力機制模塊可以獲取特征的全局依賴關系,進一步提升特征提取效率,從而提高動作識別的準確率。本文方法在UCF101和HMDB51公開數據集上進行了實驗,識別準確率分別為93.5%和70.5%,參數量為13.46 Mi,浮點運算量為8.73 Gi;消融實驗證明了本文方法能夠提取到更加豐富的時空特征,在動作識別任務中可以實現更好的性能;對比實驗證明了本文方法的準確率較高,參數量和計算量較少且具有較高的魯棒性。目前本文在公開的動作數據集上進行實驗,后續將采集實際場景下的動作視頻數據集,并對現有方法的網絡結構進行優化,以適用于實時場景下的動作識別任務。
參考文獻:
[1]Ben Mabrouk A, Zagrouba E. Abnormal behavior recognition for intelligent video surveillance systems[J]. Expert Systems with Applications: An International Journal, 2018, 91(C):480-491.
[2]Wang L, Huynh D Q, Koniusz P. A comparative review of recent kinect-based action recognition algorithms[J]. IEEE Transactions on Image Processing: a Publication of the IEEE Signal Processing Society, 2020, 29: 15-28.
[3]盧修生,姚鴻勛. 視頻中動作識別任務綜述[J]. 智能計算機與應用, 2020, 10(3): 406-411.
[4]Wang H, Klser A, Schmid C, et al. Action recognition by dense trajectories[C]∥CVPR. Colorado Springs, CO, USA. IEEE, 2011: 3169-3176.
[5]Klaeser A, Marszaek M, Schmid C. A spatio-temporal descriptor based on 3D-gradients[C]∥BMVC 2008-19th British Machine Vision Conference. Leeds. British Machine Vision Association, 2008: 1-10.
[6]Brox T, Malik J. Large displacement optical flow: descriptor matching in variational motion estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(3): 500-513.
[7]許培振, 余志斌, 金煒東, 等. 基于提高的稠密軌跡人體行為識別[J]. 系統仿真學報, 2017, 29(9): 2053-2058.
[8]Patel C I, Labana D, Pandya S, et al. Histogram of oriented gradient-based fusion of features for human action recognition in action video sequences[J]. Sensors, 2020, 20(24):7299.
[9]Xia L M, Ma W T. Human action recognition using high-order feature of optical flows[J]. The Journal of Supercomputing, 2021, 77(12): 14230-14251.
[10]Heslinga F G, Pluim J P W, Dashtbozorg B, et al. Approximation of a pipeline of unsupervised retina image analysis methods with a CNN[C]∥Medical Imaging 2019: Image Processing. San Diego, USA. SPIE, 2019, 10949: 416-422.
[11]Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[C]∥Proceedings of the 27th International Conference on Neural Information Processing Systems. New York. ACM, 2014: 568-576.
[12]Wang L M, Xiong Y J, Wang Z, et al. Temporal segment networks for action recognition in videos[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(11): 2740-2755.
[13]Wang L M, Tong Z, Ji B, et al. TDN: temporal difference networks for efficient action recognition[C]∥2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA. IEEE, 2021: 1895-1904.
[14]Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3D convolutional networks[C]∥2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile. IEEE, 2016: 4489-4497.
[15]Carreira J, Zisserman A. Quo vadis, action recognition? A new model and the kinetics dataset[C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 4724-4733.
[16]Hara K, Kataoka H, Satoh Y. Learning spatio-temporal features with 3d residual networks for action recognition [EB/OL].(2017-08-25)[2022-10-10].https:∥arxiv.org/abs/1708.07632.
[17]Qiu Z F, Yao T, Mei T. Learning spatio-temporal representation with pseudo-3D residual networks[C]∥2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy. IEEE, 2017: 5534-5542.
[18]張聰聰, 何寧, 孫琪翔,等. 基于注意力機制的3D DenseNet人體動作識別方法[J].計算機工程,2021,47(11):313-320.
[19]Wang F, Jiang M Q, Qian C, et al. Residual attention network for image classification[C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA. IEEE, 2017: 6450-6458.
[20]Jaderberg M, Simonyan K, Zisserman A, et al. Spatial transformer networks[EB/OL]. (2015-06-05)[2022-10-10]. https:∥arxiv.org/abs/1506.02025.
[21]Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]∥2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA. IEEE, 2018: 7132-7141.
[22]Woo S, Park J, Lee J Y, et al. CBAM: Convolutional block attention module[C]∥Proceedings of the European conference on computer vision (ECCV). Cham: Springer International Publishing, 2018: 3-19.
[23]Lei J J, Jia Y L, Peng B, et al. Channel-wise temporal attention network for video action recognition[C]∥2019 IEEE International Conference on Multimedia and Expo (ICME). Shanghai, China. IEEE, 2019: 562-567.
[24]Soomro K, Zamir A R, Shah M. A dataset of 101 human action classes from videos in the wild[EB/OL]. (2012-12-03)[2022-10-10]. https:∥arxiv.org/abs/1212.0402.
[25]Wishart D S, Tzur D, Knox C, et al. HMDB: the human metabolome database[J]. Nucleic Acids Research, 2007, 35(suppl_1): D521-D526.
[26]Liu K, Liu W, Gan C, et al. T-C3D: Temporal convolutional 3D network for real-time action recognition[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, 32(1):7138-7145.
[27]Wang L M, Li W, Li W, et al. Appearance-and-relation networks for video classification[C]∥2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA. IEEE, 2018: 1430-1439.
[28]Hara K, Kataoka H, Satoh Y. Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet? [C]∥2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA. IEEE, 2018: 6546-6555.
[29]Xu J, Song R, Wei H L, et al. A fast human action recognition network based on spatio-temporal features[J]. Neurocomputing, 2021, 441: 350-358.
(責任編輯:康 鋒)
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
