基于通道注意力機制的室內場景深度圖補全
2023-08-30 22:09:27任瀚實周志宇孫樹森
浙江理工大學學報 2023年5期
關鍵詞:深度學習
任瀚實 周志宇 孫樹森
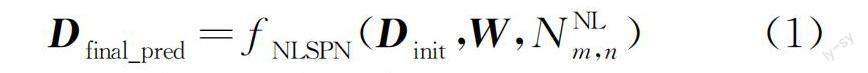
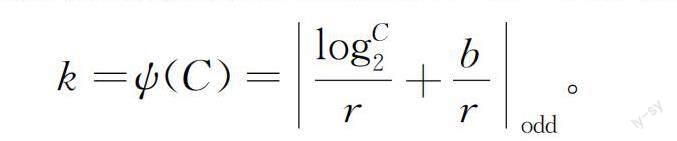

摘 要: 在深度相機獲取的室內場景深度圖中,部分像素點缺失深度信息;為補全深度信息,設計了端對端的場景深度圖補全網絡,在此基礎上提出了一種基于通道注意力機制的室內場景深度圖補全方法。該方法將場景彩色圖與缺失部分深度信息的場景深度圖作為場景深度圖補全網絡的輸入,首先提取場景彩色圖和深度圖的聯合特征,并根據通道注意力機制將提取到的聯合特征進行解碼,得到初始預測深度圖;然后借助非局部區域上的傳播算法逐步優化場景深度的預測信息,得到完整的場景深度圖;最后在Matterport3D等數據集上進行實驗,并將該方法與典型方法進行比較分析。實驗結果表明,該方法融合了場景彩色圖和深度圖特征信息,通過注意力機制提高了深度圖補全網絡的性能,有效補全了深度相機拍攝室內場景時缺失的深度信息。
關鍵詞:深度圖;深度補全;深度學習;注意力機制;室內場景
中圖分類號:TP391.41;TP183
文獻標志碼:A
文章編號:1673-3851 (2023) 05-0344-09
引文格式:任瀚實,周志宇,孫樹森. 基于通道注意力機制的室內場景深度圖補全[J]. 浙江理工大學學報(自然科學),2023,49(3):344-352.
Reference Format: REN? Hanshi,ZHOU? Zhiyu,SUN Shusen. Depth map completion for indoor scenes based on the channel attention mechanism[J]. Journal of Zhejiang Sci-Tech University,2023,49(3):344-352.
Depth map completion for indoor scenes based on the channel attention mechanism
REN Hanshia, ZHOU Zhiyua, SUN Shusenb
(a.School of Information Science and Technology; b.School of Computer Science and Technology, Zhejiang Sci-Tech University, Hangzhou 310018, China)
Abstract: When the depth camera scans the indoor scene, the depth information of some pixels is missing. To solve this problem, we proposed a depth map completion method for indoor scenes based on a channel attention mechanism and an end-to-end scene depth map completion network. With the scene color map and incomplete scene depth map as input, the network first extracted the scene color map features and depth map features, and decoded the extracted combined features based on the channel attention mechanism to obtain the initially predicted depth map. Then the predicted scene depth information was gradually optimized with the help of non-local spatial propagation algorithm to finally obtain the complete scene depth map. Finally, the proposed method was compared with typical methods using datasets such as Matterport3D. Experimental results show that this method, integrating the feature information of the scene color map and the depth map, improves the performance of depth map completion network through the attention mechanism, and effectively complements the lack of depth information when shooting indoor scenes by depth camera.
Key words:depth image; depth completion; deep learning; attention mechanism; indoor scene
0 引 言
目前,場景深度圖在自動駕駛[1]、場景重建[2]以及增強現實[3]等領域有著廣泛應用。雖然深度傳感器技術已經有了很大發展,但Microsoft Kinect、Intel Real Sense、Google Tango等商品級RGB-D相機,在拍攝場景過亮、物體表面過于光滑、相機與物體之間距離過遠或過近等情況下采集到的深度圖像會缺失部分像素點的深度數據。深度數據缺失會對自動駕駛、三維重建、目標檢測等計算機視覺任務造成不利影響,因此深度圖補全研究非常必要。
本文研究商品級相機拍攝的室內場景RGB-D圖像深度數據補全的問題。深度圖補全任務可以歸結為一個密集標記問題,因此針對密集標記問題的方法也可以用于深度圖補全任務[4]。帶有跳躍連接的編碼器-解碼器結構[4]已廣泛用于解決語義分割等密集標記問題。例如,Senushkin等[4]提出了一種網絡,該網絡由編碼器-解碼器和一個輕量級細化網絡組成,在Matterport3D數據集上取得了最佳效果。此外,解決深度圖補全任務的另一種思路是利用傳播算法,通過觀測到的深度數據補全深度圖。例如,Park等[5]提出了一種網絡,采用傳播算法,利用非局部區域內相關性較強的像素的深度數據來補全深度圖,有效避免了局部區域中無關像素的影響。
單目圖像的深度估計是計算機視覺領域中一個重要問題。早期的深度估計方法主要通過人工調整模型、表面和法線[6-7]、單目紋理圖或失焦特性[8]等實現;最近的研究主要結合多尺度信息來預測像素級深度[9-10],這可以通過多種方式實現,如融合網絡架構中不同層對應的特征映射再使用降維回歸。上述方法只適用于估計商品RGB-D相機所拍攝的深度圖,但不適用于商品級相機拍攝的室內場景RGB-D圖像深度圖補全的問題。由于這些RGB-D圖像通常缺失部分深度信息,僅在原始深度上訓練不能很好地補全缺失的深度圖,所以本文采用融合彩色圖和深度圖的方法來提升深度圖補全任務效果。
早期的深度圖補全任務一般通過基于壓縮感知或濾波器的方法實現。Uhrig等[11]提出了一種基于卷積神經網絡的深度圖補全方法,通過彩色圖像引導對基于卷積神經網絡的深度圖補全方法進行了改進。Chen等[12]提出了一種基于連續卷積的2D-3D融合網絡結構。Li等[13]采用多尺度級聯沙漏結構進行深度圖補全。鄭柏倫等[14]使用三分支的多尺度特征融合網絡融合彩色圖像特征和深度圖像特征,進行深度圖補全。除了利用彩色圖像引導,最近提出的一些方法還使用表面法線和物體邊界信息來輔助解決深度圖補全任務[15-16]。以上相關算法都屬于監督學習,此外處理深度圖補全任務也可以使用自監督算法或無監督算法[17-18]。上述大部分工作都是基于室外場景的稀疏深度的Lidar數據,并在KITTI數據集上驗證;另一部分工作針對的是Kinect傳感器獲取的半密集深度數據。最近,Zhang等[19]引入了用于室內深度圖補全任務的大型RGB-D數據集Matterport3D,使用預先訓練好的神經網絡進行法線估計以及邊界檢測,再對得到的法向量和邊界進行全局優化。雖然該方法在Matterport3D數據集上取得良好效果,但其網絡的復雜性限制了該方法的實際應用。Huang等[20]提出的方法在Matterport3D數據集上首次超過原始結果。與Zhang等[19]的研究相似,他們提出的方法也涉及復雜的圖像預處理并通過多階段處理實現;雖然它不依賴于預先訓練的骨干網絡,但使用了在外部數據上訓練過的深度神經網絡。Senushki等[4]提出的編解碼網絡訓練的模型在Matterport3D數據集上表現最佳。該模型僅需要輸入室內場景彩色圖和不完整的深度圖,而不需要法線信息和邊界等附加信息,通過編碼器進行特征提取后即可利用輕量級的細化網絡完成深度圖補全任務。
直接進行深度圖補全的算法已經具有良好表現;使用彩色圖引導稀疏深度圖進行傳播,并通過稀疏的深度圖獲得深度信息預測,是另一種完成深度圖補全任務的有效途徑。空間傳播算法從大規模數據中學習特定的親和力,可應用于包括深度圖補全和語義分割在內的計算機視覺任務。最初的空間傳播算法通過線性相關的傳播模型設計,只針對某像素與其在某個方向上(上、下、左、右)鄰近的3個像素,沒有考慮與該像素相關的所有像素。Cheng等[21]提出的卷積空間傳播網絡(Convolutional spatial propagation network,CSPN)克服了這一局限。CSPN可以預測局部區域內相鄰點的相關性,同時更新所有像素的局部上下文信息以提高效率。然而CSPN依賴于固定區域內的相鄰像素之間的關系,這些固定區域內的相鄰像素本身可能來自不同的物體。因此這樣的傳播方式會因不相關像素導致深度值混合,也限制了圖像中上下文相關信息(即非局部上下文信息)的應用。最近,已有一些研究對非局部上下文信息的應用進行了探索[22-24]。Wang等[25]提出了一種帶有非局部塊的深度神經網絡;非局部塊由兩兩像素間的親和力計算模塊和特征處理模塊組成,通過將非局部塊嵌入已有的深度網絡進行視頻分類和圖像識別任務。Park等[5]在此基礎上提出了一種非局部區域空間傳播網絡(Non-local spatial propagation network,NLSPN),進一步優化了深度圖補全網絡。NLSPN計算每個像素的非局部區域內像素間的親和力,通過深度神經網絡得到初始深度圖以及置信度圖;結合像素間的親和力關系和置信度,在預測的非局部區域中對初始預測深度圖進行迭代傳播精化。該網絡有效避免了固定區域內不相關像素在傳播過程中可能造成的混合深度問題,但在深度邊界處的混合深度問題仍未能完全解決。
針對深度相機獲取的室內場景深度圖,為補全部分像素點缺失的深度信息,本文提出了一種深度圖補全方法,設計了一種基于通道注意力(Efficient channel attention,ECA)機制的融合彩色圖與深度圖特征的深度圖補全網絡。該補全網絡采用編解碼器結構,編碼器由多個卷積層和通道注意力機制模塊組成,對深度圖及其對應的彩色圖進行多尺度特征提取,在此基礎上通過傳播算法得到深度補全圖像。本文提出的深度圖補全網絡融合了彩色圖與深度圖的特征,并且不需要預先提取法線、邊界檢測等額外信息,降低了網絡的結構復雜性,在Matterport3D和NYUv2數據集上取得了較好效果。
1 方法設計
本文提出的深度圖補全方法可分為兩步:第一步,使用編解碼結構獲得初始深度預測圖,通過編碼器學習室內場景彩色圖中大量的特征信息,并與室內場景深度圖的特征進行融合,以獲取豐富圖像特征;通過解碼器使用多個反卷積操作實現初步補全。第二步,在非局部區域上使用傳播算法,細化上一步得到的深度預測圖。
1.1 深度圖補全網絡
本文提出的深度圖補全網絡采用端對端的卷積神經網絡,結合了通道注意力機制和空間傳播算法。采用通道注意力機制可以使深度神經網絡更加關注關鍵信息。在提取特征圖時融合了彩色圖以及深度圖信息,能有效地獲得信息豐富的特征圖,加強彩色圖在補全分支上的引導作用。特征圖提取采用基于ResNet的深度卷積神經網絡,并加入了通道注意力機制模塊,以獲得不同大小的特征圖;在特征圖逐步變小的同時增加了特征圖的數量,保證了網絡結構的有效性。
本文設計的網絡結構如圖1所示。該絡采用編碼器-解碼器結構,包含兩部分:彩色圖-深度圖特征提取模塊和深度圖補全模塊。彩色圖-深度圖特征提取模塊通過多個卷積層和通道注意力機制模塊實現對彩色圖和深度圖融合特征提取,以獲取豐富的特征圖關鍵信息,從而為深度圖補全模塊作準備。在深度圖和彩色圖特征提取階段,先對彩色圖和深度圖分別通過Conv1進行一次卷積,將二者結果融合,再使用兩個通道注意力模塊。深度圖補全模塊采用4個反卷積層,然后分成3個分支,得到初始深度預測圖Dinit、親和矩陣W以及非局部區域NNLm,n。通過非局部區域傳播算法,最終得到深度預測圖Dfinal_pred,即:
其中:fNLSPN()表示初始深度預測圖Dinit和最終補全的深度圖像Dfinal_pred之間根據非局部區域NNLm,n和親和矩陣W傳播的映射函數。
通過彩色圖-深度圖特征提取模塊對深度圖和其對應的彩色圖進行特征提取。本文直接將未經處理的深度圖和彩色圖作為網絡的輸入。先分別使用一個3×3的卷積層得到一個32通道的彩色圖特征圖Fc和一個16通道的深度圖特征圖Fd,將二者結合為一個48通道的特征圖F2,再經過多個3×3的卷積層進行多尺度提取,對其中第一步和最后一步得到的特征圖Fi,即F2、F4使用通道注意力模塊[26],即:
其中:Icolor表示場景彩色圖;Ddepth為場景深度圖;σ表示激活函數Relu;*表示卷積操作,W表示卷積的權重;b1、b2均為偏置向量;Fc和Fd分別為經過1層卷積后得到的彩色特征圖和深度特征圖,fECA()表示通道注意力機制。其中,通道注意力機制模塊沒有過分增加模型的復雜度,但可以顯著提升補全效果。通道注意力機制的作用原理見1.2節。
在進行深度圖補全時,使用4個卷積核為3×3,步長為2的反卷積層進行解碼。分3個分支得到初始深度預測圖Dinit、親和矩陣W以及非局部區域NNLm,n,使用初始深度預測圖Dinit利用非局部區域傳播算法對相關區域NNLm,n中的像素點進行傳播賦值,其中相關區域NNLm,n表示為:
傳播算法能使場景內物體前景與背景有效分開,有利于深度圖像信息的補全。非局部區域傳播算法的實現過程見1.3節。
1.2 通道注意力機制模塊
為了獲得具有更多有效信息的深度特征圖,將彩色圖-深度圖特征提取模塊得到的多個特征圖輸入通道注意力機制模塊,對第一步提取特征得到的特征圖和最后一個卷積提取特征得到的特征圖輸入通道注意力機制模塊,深度圖像補全的效果可以得到顯著提升。通道注意力機制模塊示意圖如圖2所示。本文在編碼器融合彩色圖和深度圖之后,對其進行多次卷積操作,獲得特征圖Fi,并對得到的特征圖Fi先使用全局平均池化層,再利用自適應的卷積核為k的1維卷積,以捕捉各個通道之間的交互關系,最后得到Fi,ECA。通道注意力機制模塊可以在不做降維操作的情況下,以較小的參數量來提升卷積神經網絡的性能。
通道注意力機制模塊的輸入為卷積模塊提取出的特征圖Fi,經過操作得到包含更多有效信息的特征圖Fi,ECA。
本文使用矩陣Wk來學習通道注意力,
其中:w是可學習的參數。對于每個通道yi本文只計算它與其相鄰的k個通道之間的關系,yi的權重ωi表示為:
其中:Ωki表示與yi相鄰的一組通道,yji表示第j個與yi相鄰的通道。
以上權重計算方式可以通過1維卷積來實現,即:
其中:Conv1Dk( )表示卷積核為k的1維卷積。使用1維卷積時,通道維度C與卷積核k之間存在一個線性映射關系,C=r×k-b;為了減小線性函數作為特征關系式所帶來的局限性,而且一般通道維度C通常為2的冪次方,因此本文將線性函數φ(k)=r×k-b擴展為非線性函數,即:
C=φ(k)=2(r×k-b)。
所以,根據給定的特征圖通道數C,k可以表示為:
其中:|x|odd表示最接近x的奇數。本文使用r=2、b=1時的通道注意力機制模塊;當輸入的特征為F2時,此時自適應的一維卷積核大小為3,如圖2所示。
1.3 非局部區域傳播算法
為了進一步細化初步得到的補全深度圖,本文對初步獲得的深度圖使用非局部區域傳播算法進行細化處理。傳播算法的原理是用具有相似性的相鄰觀測像素來估計其他深度值缺失的像素,并細化可信度較低區域的深度值。空間傳播算法已經被用于各種計算機視覺應用中的關鍵模塊,在深度圖補全任務中優勢更為明顯,比直接回歸算法更優越[8,25]。空間傳播算法和卷積空間傳播算法可以把可信度高的區域信息通過數據間的親和度依賴有效傳播到可信度較低的區域。但是這兩種算法會受到局部區域的限制,局部區域像素的深度分布不均,可能導致前景和背景的深度值混合。所以,本文采用非局部區域傳播算法[6]改善前背景處深度值混合的問題。
本文定義非局部區域如式(2)所示,其中:I和D分別為彩色圖像和深度圖像,fφ()表示非局部區域預測網絡,p、q為實數(可以為分數)。在此區域中,使用親和力和置信度的聯合學習,增強相關像素的影響,同時抑制不相關像素的影響。fφ()網絡采用可形變卷積[27]實現。
NLSPN模塊的輸入為初始預測圖Dinit、像素間的親和矩陣和原始深度圖的置信度圖。置信度圖含有原始深度圖中每個像素的置信度,每個像素的置信度取值范圍為[0,1]。本文將置信度和親和矩陣相結合,進行歸一化得到親和矩陣W,即:
其中:ci,j表示在(i,j)處像素的置信度,取值范圍為[0,1];w^i,jm,n表示位于(i,j)處像素未經歸一化的初始親和度;γ表示可學習的歸一化參數,γmin和γmax是根據經驗設置的最小值和最大值;tanh函數的使用能夠減少歸一化過程中的偏差。
因此,最后輸出結果為:
Dfinal_pred=fNLSPNDinit,W,NNLm,n。
1.4 損失函數
總損失可以寫為:
其中:D(v)表示最終補全得到的深度圖中像素v處的深度值;Dgt(v)表示場景真實深度圖中像素v處深度值;Dinit(v)表示初始深度預測圖中像素v處深度值;V表示場景真實深度圖中有效像素;|V|表示有效像素的數量。
本文在總損失中加入了Lssim損失,以獲得更高質量、結構更完整深度圖補全圖。Lssim為結構相似性(Structural similarity,SSIM)損失[21],根據結構信息的退化程度來衡量補全質量。Lssim越小,補全后深度圖的結構與場景真實深度圖結構越相似。
2 結果與討論
本文提出的深度圖補全網絡使用Pytorch框架搭建訓練模型,GPU使用NVIDIA GeForce RTX 3060,內存為12 GiB。訓練數據集使用Matterport3D數據集[19]和NYUv2數據集。在Matterport3D數據集上只有極少方法能取得較優的深度圖補全效果,NYUv2數據集是深度圖像補全任務的常用數據集。
Matterport3D數據集[19]由真實的傳感器數據以及從官方重構網格獲取到的真實深度數據組成。本文的訓練集使用其中一個子集,約2358張圖像,對圖像做預處理,將其縮小至320×240。本文訓練模型時使用50個Epoch,使用另一子集約864張圖像作為測試集,并與典型算法進行比較分析。NYUv2數據集由Kinect傳感器捕獲的464個室內場景的彩色圖和深度圖像組成。對于訓練數據,本文使用了官方訓練分割的一個約50 kib的圖像子集,每張圖像縮小到320×240,然后使用304×228中心裁剪。與文獻[5, 20]類似,本文從密集深度圖像中隨機采樣500個深度像素,并將其與對應的彩色圖像聯合作為網絡輸入。訓練模型時同樣使用50個Epoch,使用官方分割出的654張圖像測試集進行評估和可視化比較。
2.1 評估指標
本文的室內場景補全任務的驗證方式與文獻[4-5, 19-20]類似。本文采用均方根誤差、平均絕對誤差以及精確度對本文的網絡進行評估,這些指標在室內場景深度圖補全任務的評估中被廣泛認可。均方根誤差和平均絕對誤差直接測量絕對深度精度。均方根誤差對異常深度值更為敏感,所以均方根誤差通常被視作模型評估的主要指標。另外,精確度δt表示相對誤差小于閾值t的預測像素所占的百分比。δt也可以被理解為深度圖補全任務的精度,精度越高說明最終預測的深度圖與場景真實深度值越接近,補全效果就越好。本文計算了t取1.25、1.252、1.253時的δt值。
均方根誤差ERMS的計算公式為:
平均絕對誤差EMA的計算公式為:
δt的計算公式為:
其中:t∈{1.25,1.252,1.253},v∈V。
2.2 實驗結果對比分析
為了驗證本文提出的深度圖像補全網絡的性能,選取Zhang等[19]、Huang等[20]、Senushkin等[4]、Park等[5]等4種較為典型的方法進行實驗對比。Zhang等[19]首次使用深度神經網絡用于深度圖補全任務,并制作了Matterport3D數據集。Huang等[20]在Zhang[19]基礎上在深度網絡中加入了自注意力機制,實現在Matterport3D數據集上更優的補全深度圖。而Senushkin等[4]提出的方法訓練出的DmLrn模型在Matterport3D數據集上取得最佳表現,Park等[5]提出的方法則在NYUv2數據集上取得最佳表現。本文采用均方根誤差、平均絕對誤差以及精確度作為深度圖補全網絡性能指標,誤差越小、精度越高說明補全效果越好。
由表1和表2給出的深度圖補全誤差統計數據可知,DmLrn[4]和本文方法均能夠在不使用法線、物體邊緣預測的情況下取得了較優結果。與Zhang等[19]、Huang等[20]、Senushkin等[4]方法相比,本文方法具有更好的補全結果。在Matterport3D數據集上,本文網絡均方根誤差為0.309,較該數據集上最優模型DmLrn[4]相比降低了0.652,準確度在閾值為1.25時精度提升11%,在閾值為1.252時精度提升6.9%,在閾值為1.253時精度提升2.5%;在NYUv2數據集上,本文提出的方法與該數據集上的最優模型指標上基本相同。本文方法在編碼器的特征提取階段加入了通道注意力機制模塊,在網絡訓練過程中充分學到了場景的上下文信息,從而提升深度圖補全網絡的性能。本文方法在Matterport3D數據集上取得了更優性能,表明本文方法在前、背景相差較大的大規模室內場景深度圖補全方面有較大優勢。
圖3為本文方法與Senushkin等[4]、Huang等[20]方法在Matterport3D數據集上的深度圖補全效果。從圖3可以看出,本文方法能在保證圖像結構信息的基礎上達到更優精度,DmLrn[4]在邊緣處明顯出現深度值混合的現象。本文的方法能夠很好地將前景和背景分開,使得補全后的物體邊緣更為清晰。圖4為本文方法與Park等[5]、Senushkin等[4]方法在NYUv2數據集上的深度圖補全效果。從圖4可以看出,本文方法物體邊緣以及總體補全效果均表現良好,補全后的深度圖像具有清晰的邊界。綜上所述,本文提出的深度圖補全網絡在不同數據集上均取得較好效果。
3 結 語
本文提出了一種基于注意力機制的場景深度圖補全的方法。在場景彩色圖像引導下,編碼器融合場景彩色圖和深度圖特征信息,在特征提取過程中使用注意力機制使網絡更加關注補全任務所需要的區域,在深度圖像補全任務中取得更高的準確度。實驗表明,該方法可以較好地補全室內場景深度圖中的缺失信息。
為了進一步改善深度圖像補全的質量,后續研究可考慮將場景彩色圖中的幾何結構信息融入場景深度圖補全網絡,以提升補全后深度圖像的邊緣準確度。
參考文獻:
[1]Fu C, Mertz C, Dolan J M. LIDAR and monocular camera fusion: On-road depth completion for autonomous driving[C]//2019 IEEE Intelligent Transportation Systems Conference (ITSC). Auckland, New Zealand. IEEE, 2019: 273-278.
[2]梅峰,劉京,李淳秡,等.基于RGB-D深度相機的室內場景重建[J].中國圖象圖形學報,2015,20(10):1366-1373.
[3]Ping J M, Thomas B H, Baumeister J, et al. Effects of shading model and opacity on depth perception in optical see-through augmented reality[J]. Journal of the Society for Information Display, 2020, 28(11): 892-904.
[4]Senushkin D, Romanov M, Belikov I, et al. Decoder modulation for indoor depth completion[C]//2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). New York: ACM, 2021: 2181-2188.
[5]Park J, Joo K, Hu Z, et al. Non-local spatial propagation network for depth completion[C]//16th European Conference on Computer Vision-ECCV 2020. Glasgow, UK. Cham: Springer, 2020: 120-136.
[6]沙浩,劉越,王涌天, 等.基于二維圖像和三維幾何約束神經網絡的單目室內深度估計方法[J].光學學報,2022,42(19):47-57.
[7]江俊君,李震宇,劉賢明.基于深度學習的單目深度估計方法綜述[J].計算機學報,2022,45(6):1276-1307.
[8]周萌,黃章進.基于失焦模糊特性的焦點堆棧深度估計方法[J/OL].計算機應用.(2023-02-17)[2023-03-03].http://kns.cnki.net/kcms/detail/51.1307.TP.20230217.1018.004.html.
[9]Xu D, Wang W, Tang H, et al. Structured attention guided convolutional neural fields for monocular depth estimation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. June 18-23, 2018, Salt Lake City, UT, USA. IEEE, 2018: 3917-3925.
[10]白宇,梁曉玉,安勝彪.深度學習的2D-3D融合深度補全綜述[J/OL].計算機工程與應用. (2023-03-01)[2023-03-03]. http://kns.cnki.net/kcms/detail/11.2127.TP.20230228.1040.006.html.
[11]Uhrig J, Schneider N, Schneider L, et al. Sparsity invariant CNNs[C]//2017 International Conference on 3D Vision (3DV). October 10-12, 2017, Qingdao, China. IEEE, 2018: 11-20.
[12]Chen Y, Yang B, Liang M, et al. Learning joint 2D-3D representations for depth completion[C]// 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South). IEEE, 2019: 10022-10031.
[13]Li A, Yuan Z J, Ling Y G, et al. A multi-scale guided cascade hourglass network for depth completion[C]//2020 IEEE Winter Conference on Applications of Computer Vision (WACV). March 1-5, 2020, Snowmass, CO, USA. IEEE, 2020: 32-40.
[14]鄭柏倫,冼楚華,張東九.融合RGB圖像特征的多尺度深度圖像補全方法[J]. 計算機輔助設計與圖形學學報, 2021, 33(9): 1407-1417.
[15]Qiu J X, Cui Z P, Zhang Y D, et al. DeepLiDAR: deep surface normal guided depth prediction for outdoor scene from sparse LiDAR data and single color image[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). June 15-20, 2019, Long Beach, CA, USA. IEEE, 2020: 3308-3317.
[16]Xu Y, Zhu X G, Shi J P, et al. Depth completion from sparse LiDAR data with depth-normal constraints[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South). IEEE, 2020: 2811-2820.
[17]Song Z B, Lu J F, Yao Y Z, et al. Self-supervised depth completion from direct visual-LiDAR odometry in autonomous driving[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(8): 11654-11665.
[18]Choi J, Jung D, Lee Y H, et al. SelfDeco: self-supervised monocular depth completion in challenging indoor environments[C]//2021 IEEE International Conference on Robotics and Automation (ICRA). Xi'an, China. IEEE, 2021: 467-474.
[19]Zhang Y, Funkhouser T. Deep depth completion of a single RGB-D image[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA. IEEE, 2018: 175-185.
[20]Huang Y K, Wu T H, Liu Y C, et al. Indoor depth completion with boundary consistency and self-attention[C]//2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW). Seoul, Korea (South). IEEE, 2020: 1070-1078.
[21]Cheng X J, Wang P, Yang R G. Depth estimation via affinity learned with convolutional spatial propagation network[C]//15th European Conference on Computer Vision-ECCV 2020. Munich, Germany. Cham: Springer, 2018: 108-125.
[22]楊宇翔,曹旗,高明煜, 等.基于多階段多尺度彩色圖像引導的道路場景深度圖像補全[J].電子與信息學報,2022,44(11):3951-3959.
[23]盧宏濤,羅沐昆.基于深度學習的計算機視覺研究新進展[J].數據采集與處理,2022,37(2): 247-278.
[24]Shim G, Park J, Kweon I S. Robust reference-based super-resolution with similarity-aware deformable convolution[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). June 13-19, 2020, Seattle, WA, USA. IEEE, 2020: 8422-8431.
[25]Wang X L, Girshick R, Gupta A, et al. Non-local neural networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA. IEEE, 2018: 7794-7803.
[26]Wang Q L, Wu B G, Zhu P F, et al. ECA-net: efficient channel attention for deep convolutional neural networks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). June 13-19, 2020, Seattle, WA, USA. IEEE, 2020: 11531-11539.
[27]Zhu X Z, Hu H, Lin S, et al. Deformable ConvNets V2: more deformable, better results[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). June 15-20, 2019, Long Beach, CA, USA. IEEE, 2020: 9300-9308.
(責任編輯:康 鋒)
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
