MMRGait-1.0:多視角多穿著條件下的雷達時頻譜圖步態識別數據集
2023-09-15 01:37:48陳曉陽薛世鯤
雷達學報 2023年4期
關鍵詞:特征
杜 蘭 陳曉陽 石 鈺 薛世鯤 解 蒙
(西安電子科技大學雷達信號處理國家重點實驗室 西安 710071)
1 引言
步態識別是一種新興的生物識別技術,旨在通過人體行走特點的不同對人體的身份進行識別[1]。相比于指紋識別、虹膜識別等傳統的生物識別技術,步態識別具有非合作、遠距離、不易偽裝等優點,可用于智能門禁、安防監控、刑偵監測等領域,具有十分廣闊的應用前景[2]。
近年來,由于深度學習的成熟發展和大量光學步態識別數據集的支撐,基于光學傳感器的步態識別方法相關研究取得了有效的進展。然而,光學傳感器易受天氣和光線條件影響,且采集的圖像或視頻存在隱私泄露的風險。與光學傳感器相比,雷達通過發射電磁波的方式來探測和感知目標,可以有效防止隱私泄露,同時雷達可以在不同的天氣和光線條件下工作,具有較強的環境魯棒性[3]。因此,基于雷達的步態識別方法具有非常高的實際應用價值,目前已受到廣泛關注[4-8]。
人在行走時,人體各個部位的微運動會在雷達回波信號上引起頻率調制產生微多普勒信號[9]。由于每個人行走的姿態、方式不同,微多普勒信號中包含的步態信息也會有所差異。對微多普勒信號進行時頻分析得到的時頻譜圖能夠反映人體豐富的步態微多普勒信息,因此利用時頻譜圖進行步態識別是一種十分有前景的處理方法。傳統的基于雷達的步態識別方法通常使用手動提取特征的方式進行識別,識別過程一般分為兩步:(1)從時頻譜圖中提取軀干和四肢運動周期、多普勒展寬等特征;(2)將提取到的特征輸入到支持向量機、決策樹等傳統分類器完成識別。然而,此類方法非常依賴先驗知識,計算復雜度較高且泛化性較差,通常難以獲得滿意的識別效果[10]。
近年來,深度學習技術在基于雷達的步態識別領域逐漸興起,與傳統的基于手動提取特征的方法相比,基于深度學習的方法可以自動地從時頻譜圖中提取具有鑒別力的步態特征,識別性能得到了極大的提升[11,12]。目前已有許多學者對基于時頻譜圖的步態識別問題展開了相關研究,南京航空航天大學的Cao等人[4]首次提出了一種基于AlexNet卷積神經網絡的步態識別方法,在采集的20人數據集上達到了較好的識別效果。意大利貝內文托大學的Addabbo等人[11]利用時序卷積神經網絡對步態時序信息進行建模,并在采集的5人數據集上驗證了所提方法的有效性。Doherty等人[12]使用空間注意力和通道注意力機制增強特征表示以獲取更具判別力的步態特征,所提方法在39人數據集上達到了較高的識別性能。天津大學的Lang等人[5]設計了一種動作分類與步態識別的多任務模型,并在采集的15人數據集上驗證了模型的有效性。Yang等人[13]使用多尺度特征融合策略融合了網絡不同層提取到的步態信息,在15人的數據集上達到了較高的識別準確率。復旦大學的Xia等人[14]使用Inception模塊以及殘差模塊搭建了識別網絡,并取得了較好的識別效果。上述工作證明了深度學習技術應用于雷達步態識別領域的可行性,推動了雷達在步態識別領域的發展。然而,上述研究僅局限于分類任務,即訓練集和測試集中人的身份必須一致,無法對訓練集中未出現的身份進行有效識別,這限制了基于雷達的步態識別在真實世界中的應用。
在真實世界中,步態識別通常被認為是一項檢索任務[15],即給定一個查詢樣本,步態識別模型需要從步態樣本庫中檢索出與查詢樣本匹配度最高的樣本并賦予身份標簽。與基于分類任務的步態識別方法相比,基于檢索任務的步態識別方法具有以下特點:(1)檢索任務不要求訓練集和測試集中人員的身份相同,因此離線訓練的步態識別系統可以直接部署到新場景中;(2)當新身份的人出現時,只需要更新樣本庫而無需重新訓練模型。
基于檢索任務的步態識別模型通過對比不同樣本在特征空間中距離的遠近來衡量樣本之間的匹配度,距離越近則樣本之間的匹配度越高。檢索任務模型的訓練需要足夠多身份數目的樣本支撐,以保證模型能夠學習到將相同身份樣本之間的距離拉近、不同身份樣本之間的距離拉遠的能力,使相同身份樣本之間的匹配度最高。同時,在基于檢索任務的步態識別中,訓練集和測試集中人的身份通常是不相同的,這對數據集中人的身份數目提出了更高的要求。然而,現有基于雷達的步態識別研究大多使用私有時頻譜圖數據集進行實驗,這些數據集中人員的數目通常較少,無法滿足檢索任務對數據量的需求。由于數據采集的時間成本和人力成本較大,目前暫時沒有人員數目充足的雷達時頻譜圖步態識別數據集公開,因此基于檢索任務的雷達步態識別仍然是一個亟待研究的領域。
為了填補基于檢索任務的雷達時頻譜圖步態識別數據集的空缺,并為相關研究提供數據支撐,本文公開了一個121人的大型雷達步態識別時頻譜圖數據集。考慮到毫米波雷達具有較高的分辨率以及較低的功耗,且容易在實際應用中部署,本文選擇毫米波雷達作為傳感器來獲取步態數據。同時考慮到在真實世界中,不同的行走視角[16]以及不同的穿著條件[17]會導致人體微多普勒特征的變化繼而影響到步態識別模型的性能,因此,我們采集的數據包含了受試者在多種穿著條件下沿雷達不同視角行走的情況。此外,本文提出一種基于檢索任務的雷達步態識別方法,并在公布數據集上評估了在多視角、跨視角以及相同穿著條件、跨穿著條件下的識別性能,實驗結果可以作為基準性能指標,該數據集已可通過《雷達學報》官網的相關鏈接(https://radars.ac.cn/web/data/getData?newsColumnId=c 2cae1d9-521f-444e-ad1e-f009bf7b9acc)免費下載使用,供更多學者在此數據集上開展進一步研究。
2 MMRGait-1.0數據集信息
2.1 毫米波雷達簡介
本文使用德州儀器(Texas Instruments,TI)開發的77 GHz調頻連續波(Frequency-Modulated Continuous-Wave,FMCW)雷達AWR 1843[18]采集原始的人體雷達回波數據。該雷達采用低功耗的COMS工藝,以較小的尺寸實現了極高的集成度,同時該雷達擁有3個發射天線和4個接收天線,在方位維和俯仰維上具有一定的角度分辨率,雷達天線陣列分布如圖1所示。

圖1 毫米波雷達天線陣列分布圖Fig.1 Antenna array distribution of millimeter-wave radar
毫米波雷達的天線配置為1發4收,雷達發射波形為線性調頻連續波,其中單個線性調頻信號又被稱為Chirp信號。發射波形的具體參數配置如表1所示。在此配置下,該雷達可以達到0.097 m/s的速度分辨率,較高的速度分辨率容易獲取豐富的人體步態信息。
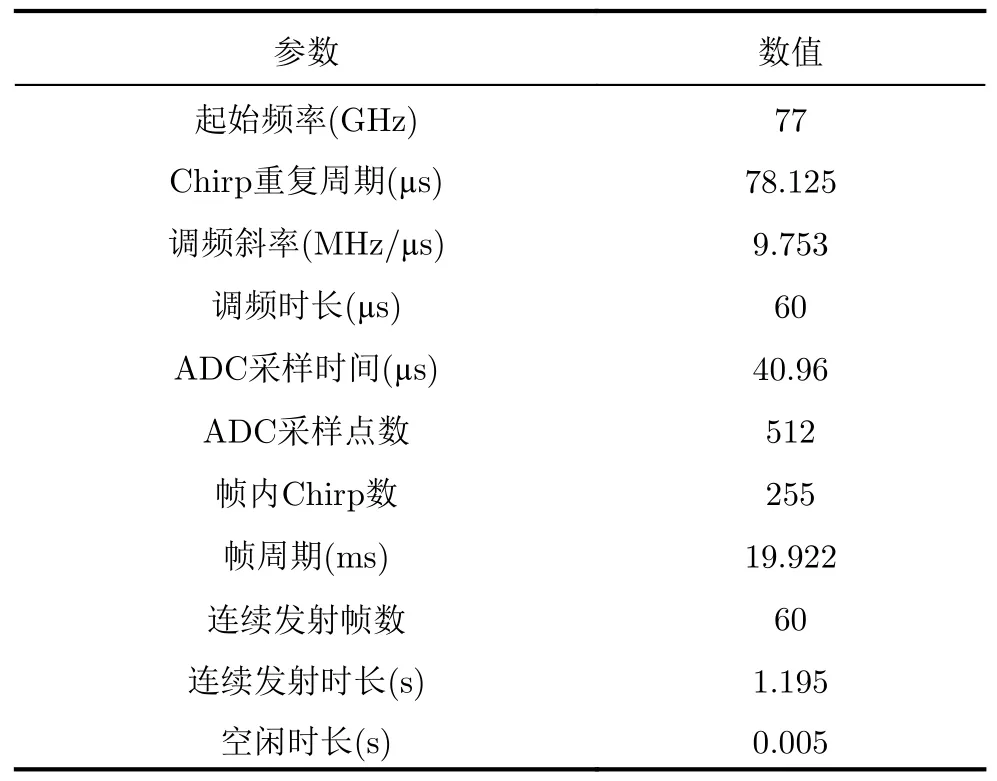
表1 雷達發射波形參數配置Tab.1 Parameter configurations of the radar transmitting waveform
2.2 數據采集設置
步態數據的采集平臺和室內采集場景如圖2所示,圖2(a)所示毫米波雷達用于采集步態數據,光學相機用于記錄采集場景。本數據集中共包含121位受試者的步態數據,其中,男性72人,年齡21~26歲,身高163~187 cm,體重55~100 kg;女性49人,年齡21~27歲,身高在155~176 cm,體重在40~67 kg。本文采集了受試者在3種穿著條件下沿8個不同視角行走的數據,行走視角示意圖如圖3所示。我們規定行走軌跡與雷達法線方向的夾角為行走視角,8個視角分別為0o,30o,45o,60o,90o,300o,315o,330o。圖4展示了3種穿著條件的示例,3種穿著條件分別為正常穿著、穿大衣和挎包。正常穿著行走時,人體的各個部位正常運動且沒有被物體遮擋;挎包行走時,一只手需要扶包,有一條胳膊無法正常擺動;穿大衣行走時,大腿上半部分被遮擋,且大衣的下擺有無規則擺動。

圖2 數據采集平臺和室內采集場景Fig.2 Data collection platform and indoor collection scene
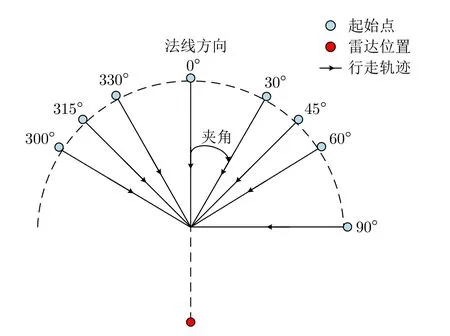
圖3 行走視角示意圖Fig.3 The view of walking

圖4 3種穿著條件示例Fig.4 Examples of three wearing conditions
本數據集中每位受試者共采集80組數據,每組數據時長為2.4 s。具體來說,8個行走視角每個視角各采集10組,其中,6組為正常穿著,2組為穿大衣,2組為挎包。121位受試者共采集9680組數據。
2.3 信號處理流程
本文使用1發4收的天線配置采集數據,因此每組數據包含4個通道的原始雷達回波信號,對雷達回波信號進行信號處理可以得到時頻譜圖,具體的信號處理流程如圖5所示。首先我們將4個通道的雷達回波信號進行非相干積累,其次對積累后的信號進行距離維快速傅里葉變換(Fast Fourier Transform,FFT)得到時間-距離圖,然后使用高通濾波器濾除靜止雜波,最后選取時間-距離圖中人體行走時所在的距離單元(0~9.375 m),對每個距離單元的信號進行短時傅里葉變換(Short-Time Fourier Transform,STFT)并求和得到最終的時頻譜圖,時頻譜圖可以反映人體目標各個散射點能量強度和頻率隨時間變化的過程[19]。

圖5 信號處理流程Fig.5 Signal processing flow
短時傅里葉變換是一種常用的時頻分析方法,其通過滑動窗口的方式對時間窗內的信號做FFT得到時頻譜圖,對信號s(t)做短時傅里葉變換的表達式如下:
其中,h(·)表示信號的漢明窗(Hamming)窗函數,t表示時間維,ω表示頻率維。根據經驗,本文將短時傅里葉變換的采樣點數設置為512,漢明窗窗長設置為0.047 s,滑窗的重疊率設置為80%。圖6展示了同一人在3種穿著條件下沿8個視角行走的2.4 s時頻譜圖,橫坐標表示時間,為直觀展示人體的行走速度,將縱坐標的頻率轉換為速度,速度范圍為-6.23~3.12 m/s。當穿著條件相同時,不同行走視角的時頻譜圖反映的微多普勒信息有所差異,視角從0o變換到90o的過程中,時頻譜圖中速度維的延展逐漸變小,微多普勒信息逐漸變少。當行走視角相同時,不相同穿著條件下的時頻譜圖也有所不同:挎包行走時,由于一條胳膊無法正常擺動,其時頻譜圖相較于正常穿著的時頻譜圖缺失了部分微多普勒信息。穿大衣時,由于大腿上半部分被遮擋,且大衣下擺的不規則擺動會對回波信號產生額外的頻率調制,因此穿大衣行走的時頻譜圖相較于正常穿著行走的時頻譜圖也會有所差異。
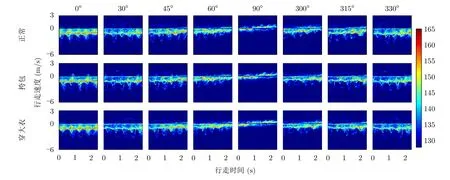
圖6 8種行走視角、3種穿著條件下的時頻譜圖Fig.6 Time-frequency spectrograms for eight walking views and three wearing conditions
2.4 數據集格式
本數據集包含時頻譜圖的矩陣和圖片兩種格式的數據,為方便數據集的使用,我們對數據進行了統一的命名,格式為AAA-BB-CC-DDD,其中,AAA表示受試者的ID,取值范圍為001~121;BB表示3種穿著條件,分別為NM(正常)、BG(挎包)、CT(穿大衣);CC表示在BB穿著條件下采集的第CC組數據。在NM條件下采集6組數據,因此CC取值范圍為01~06,在BG條件下采集2組數據,CC取值為01,02,在CT條件下采集2組數據,CC取值為01,02;DDD表示行走的視角,分別為000,030,045,060,090,300,315,330。矩陣數據的后綴為“.mat”,每個矩陣的大小為192×246,總樣本數為9680。圖片數據的后綴為“.jpg”,每張圖片的尺寸為477像素×429像素,總樣本數為9680。以矩陣格式的數據為例,具體的數據集結構如圖7所示。
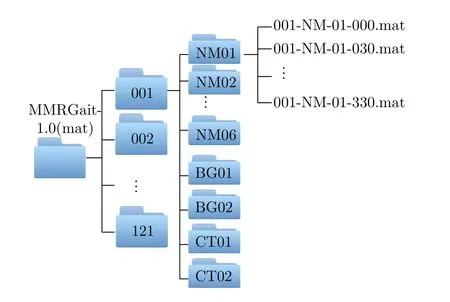
圖7 具體數據集結構示意圖Fig.7 Structure of the dataset
3 基于檢索任務的雷達步態識別方法
現有的大多數雷達步態識別方法僅局限于分類任務,只能對訓練集中出現過的身份進行識別,新身份的樣本會被錯誤判斷為訓練集中的某一個身份,因此這種基于分類任務的雷達步態識別方法在實際應用場景中十分受限。相較于基于分類任務的雷達步態識別方法,基于檢索任務的雷達步態識別方法更適用于實際應用場景,其流程如圖8所示,檢索任務遵循“受試者獨立”準則,即測試集中人員身份未在訓練集中出現,測試集中樣本的身份均為“新身份”[2]。在特征提取模型的訓練階段,需要身份數目足夠多的樣本支撐,使模型能夠學習到將相同身份樣本之間的距離拉近、不同身份樣本之間的距離推遠的能力。在測試階段,測試集被進一步分為查詢樣本與樣本庫,其中,查詢樣本為待識別身份的樣本,樣本庫中的樣本為身份已知的模板樣本。將給定查詢樣本與樣本庫中所有樣本分別輸入到特征提取模型中得到各自的特征,計算該查詢樣本特征與樣本庫中所有樣本特征之間的距離,將樣本庫中與查詢樣本特征距離最近的樣本的身份賦予該查詢樣本,不同樣本在特征空間中距離的遠近可以衡量樣本之間的匹配度,距離越近則樣本之間的匹配度越高。
基于檢索任務的步態識別方法可以應用到門禁系統、犯罪追蹤等領域,以公司的門禁系統為例,步態識別系統需要事先采集該公司所有員工的步態數據作為樣本庫,每當員工進入公司時,步態識別系統會采集員工此時的步態數據作為查詢樣本,只有從樣本庫中檢索出該查詢樣本的身份時,門禁才會放行。本文提出一種基于檢索任務的雷達步態識別網絡模型。此外,為充分挖掘時頻譜圖中不同時間尺度的微多普勒信息,本文提出了一種長短時特征提取模塊。下面將詳細介紹本文提出的步態識別網絡模型。
3.1 總體框架
本文提出的步態識別網絡模型總體框架如圖9所示,該模型以ResNet18[20]為主干特征提取網絡,為獲得更大尺寸的特征圖,本文去掉了原始Res-Net18網絡中第一個殘差模塊之前的最大池化層。此外,使用空間注意力模塊、長短時特征提取模塊以及多尺度特征融合模塊獲取具有判別力的步態特征,最后使用度量學習中的三元損失[21]對網絡進行優化。該網絡以時頻譜圖作為輸入,時頻譜圖表示為x ∈RB×C×D×T,其中,B表示網絡訓練一次所用的時頻譜圖數量;C表示時頻譜圖的通道數,其大小取決于輸入格式,當時頻譜圖的輸入格式為RGB圖片時,通道數為3,當輸入格式為矩陣時,通道數為1;D表示時頻譜圖的頻率維;T表示時頻譜圖的時間維。輸入時頻譜圖首先經過一層卷積核大小為7 ×7的 卷積層得到特征圖然后再經過4個殘差模塊Conv Block得到4個不同尺度的特征圖其中,C0,C1,C2,C3和C4分別表示不同尺度的特征圖的通道數,每個特征圖中不同的通道代表不同的特征。接下來使用空間注意力模塊對不同尺度的特征圖進行空間位置加權,然后使用長短時特征提取模塊提取特征圖中不同時間尺度的步態特征,最后使用多尺度特征融合模塊將不同尺度的特征進行融合,并使用融合后的特征計算三元損失來優化網絡。下面將詳細介紹各個模塊。
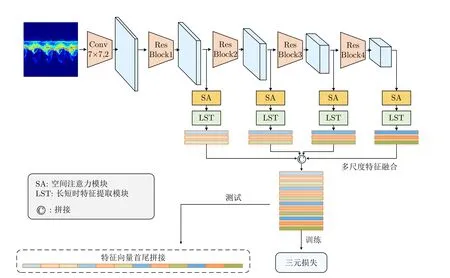
圖9 基于檢索任務的特征提取網絡模型結構框圖Fig.9 Framework for feature extraction network model based on retrieval task
3.2 模塊介紹
3.2.1 空間注意力模塊
時頻譜圖中除了存在人體運動產生的微多普勒信息之外,通常還存在背景噪聲以及未濾除干凈的靜止雜波,對于步態識別任務來說,我們希望網絡能夠充分地提取人體的微多普勒特征,并且抑制背景噪聲和靜止雜波等無關特征的提取。此外,人體不同部位的微多普勒特征對最終識別的貢獻程度也有所差異,因此我們也希望網絡能夠關注更具判別力的微多普勒特征。注意力機制的目的是按照特征的重要程度對特征進行加權,使網絡重點關注重要特征而抑制無關特征。本文使用CBAM[22]中的空間注意力模塊對時頻譜圖中不同空間位置的特征按重要程度進行加權。空間注意力圖的計算流程如圖10所示。
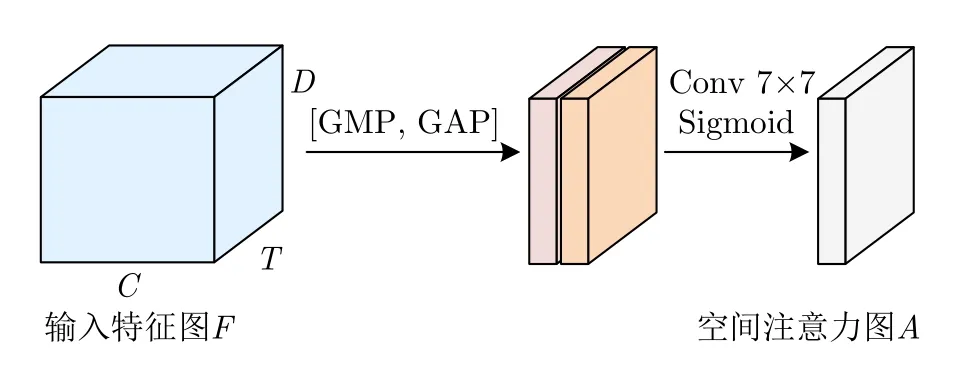
圖10 空間注意力圖計算流程Fig.10 Spatial attention map calculation process
其中,σ表示Sigmoid激活函數,GMP表示全局最大池化,GAP表示全局平均池化,f7×7表示卷積核大小為7 ×7的卷積層。
最后,將空間注意力圖A(Fi)與 輸入特征圖Fi相乘即可得到空間位置加權的特征圖
3.2.2 長短時特征提取模塊
步態時頻譜圖能夠反映人行走時各個身體部位散射點的能量強度以及多普勒頻率隨時間變化的過程。從時頻譜圖不同長度的時間段中提取的特征反映的步態信息有所差異,對于一張具有完整步態周期的2.4 s時頻譜圖來說,對整個2.4 s的時頻譜圖進行特征提取,得到的是長時的“全局”特征;而對時頻譜圖某一時間段(例如0~0.3 s)進行特征提取,得到的則是短時的“局部”特征。“全局”特征能夠反映整個步態周期內的信息,“局部”特征則反映了某一時間段內細粒度的步態信息,充分利用“局部”特征和“全局”特征能夠提高步態特征的豐富性。
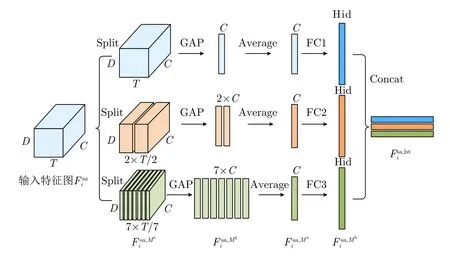
圖11 長短時特征提取模塊計算流程Fig.11 Long-short time feature extraction module calculation process
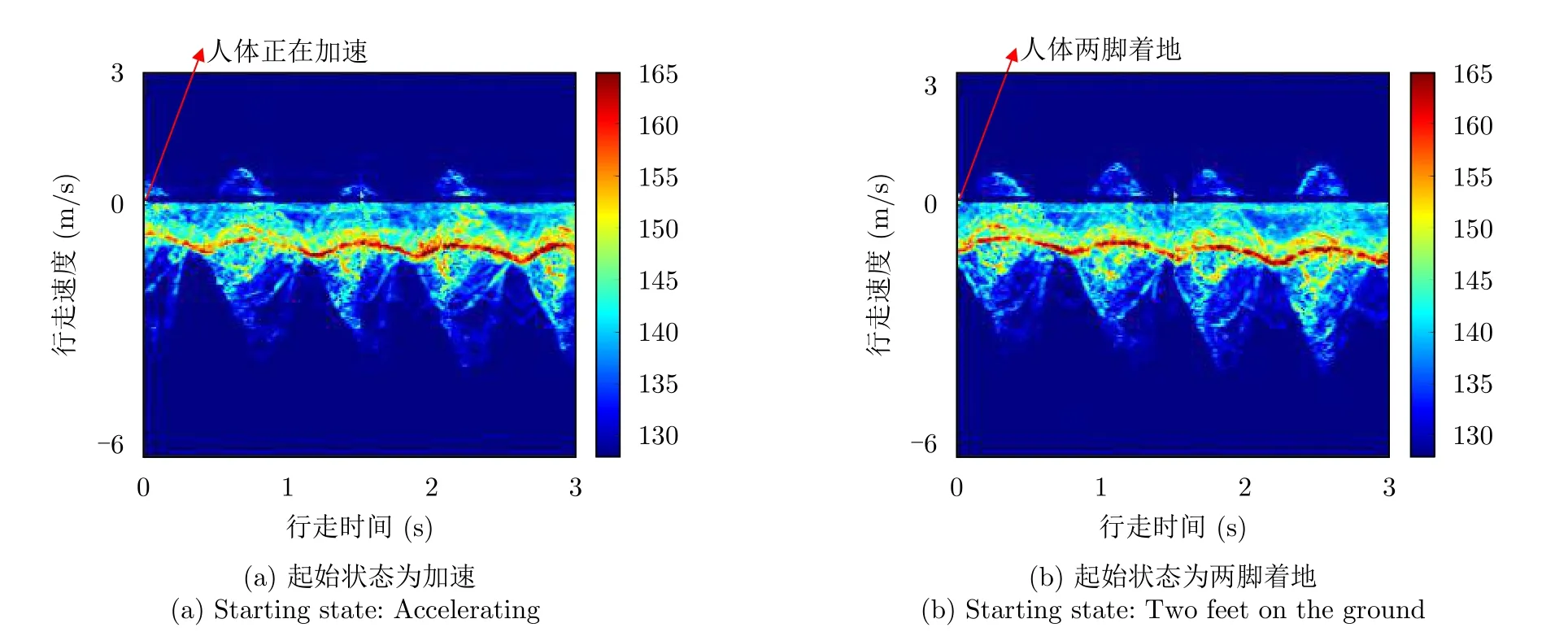
圖12 同一人不同起始狀態下行走的兩組時頻譜圖數據Fig.12 Two sets of time-spectrogram data of walking in different starting states
3.2.3 多尺度特征融合模塊
將4個殘差模塊提取到的特征圖依次輸入到空間注意力模塊、長短時特征提取模塊中,得到4組不同尺度的步態特征由于卷積神經網絡中不同層的感受野大小不同,網絡不同層提取的步態特征中包含的信息也有所差異。淺層網絡的感受野較小,提取到的步態特征中蘊含更多細粒度的信息,如時頻譜圖的輪廓、紋理、邊緣信息等。深層網絡的感受野較大,提取到的步態特征中蘊含豐富的語義信息。為充分利用網絡不同層提取到的有價值信息,本文使用拼接操作將4組不同尺度的步態特征進行融合,拼接過程如下所示:
3.3 訓練與測試
3.3.1 訓練
本文使用度量學習中的三元損失訓練網絡,該損失的目的是在特征空間中將相同身份樣本之間的距離拉近,不同身份樣本之間的距離拉遠。對每批訓練樣本計算三元損失,具體計算公式如下:
其中,H表示一批訓練樣本中身份的數目,K表示每個身份擁有的訓練樣本數目,D(·)表示歐氏距離,Dp表示第i個身份的樣本a與相同身份的樣本p構成的正樣本對在特征空間中的歐氏距離,Dn表示第i個身份的樣本a與第j個身份的樣本n構成的負樣本對在特征空間中的歐氏距離,m為控制正樣本對與負樣本對之間距離的閾值參數。
3.3.2 測試
測試時,給定查詢樣本q,目的是從樣本庫G={gi|i=1,2,...,N}(gi為樣本庫中的樣本,N為樣本數)中檢索出與該查詢樣本相同身份的樣本。具體測試過程為:
4 實驗與分析
4.1 實驗設置
本文使用圖片格式的時頻譜圖數據集進行實驗,我們將采集的121人中前74人的數據作為訓練集,其余47人的數據作為測試集。輸入網絡的時頻譜圖時長為2.4 s,尺寸大小為224像素×224像素。網絡第1個卷積層以及后續4個殘差模塊輸出特征圖的通道數C0,C1,C2,C3,C4分別為32,64,128,256,512。長短時特征提取模塊中使用3種分割方式將特征圖分成1,2,7份,全連接層FC輸出特征向量的維度Hid為512。一批訓練樣本中身份的數目P為2,每個身份擁有的訓練樣本數目K為4,三元損失中閾值參數m設置為0.2。使用AdamW優化算法訓練網絡,其中初始學習率lr設置為0.0005,權重衰減項weight_decay設置為0.0001。訓練迭代次數為400000次,每次迭代后使用OneCycleLR策略對學習率進行調整。我們在Pytorch框架上完成網絡的搭建,并使用NVIDIA GeForce GTX 2080Ti顯卡對網絡進行訓練。
4.2 評價準則
在測試階段,我們將測試集劃分成查詢樣本和樣本庫,以評估模型在多視角、跨視角以及多穿著條件、跨穿著條件下的識別性能。本文將多視角、跨視角、相同穿著條件、跨穿著條件下的識別準確度作為評價準則,4種準則的具體定義如下:
(1) 多視角條件下的識別準確度
給定某個視角的查詢樣本,樣本庫中包含查詢樣本視角在內的8個視角,計算給定視角的查詢樣本在多視角樣本庫中進行身份檢索的Rank-1準確度。例如當查詢樣本的視角為0o時,樣本庫中樣本的視角為0o,30o,45o,60o,90o,300o,315o,330o,計算0o查詢樣本在多視角樣本庫中進行身份檢索的Rank-1準確度,該Rank-1準確度即為0o查詢樣本在多視角條件下的識別準確度。
(2) 跨視角條件下的識別準確度
給定某個視角的查詢樣本,共有7個單視角樣本庫,每個樣本庫中包含除查詢樣本視角之外的某個單一視角,分別計算給定視角的查詢樣本在單視角樣本庫中進行身份檢索的Rank-1準確度,將計算得到的7個Rank-1準確度取平均作為給定視角的查詢樣本在跨視角條件下的識別準確度。例如當查詢樣本的視角為0o時,分別計算0o查詢樣本在單視角樣本庫中進行身份檢索的Rank-1準確度,并將7個單視角Rank-1準確度取平均作為0o查詢樣本在跨視角條件下的識別準確度。
(3) 相同穿著條件下的識別準確度
給定某個穿著條件的查詢樣本,樣本庫中樣本的穿著條件與查詢樣本的相同,計算給定穿著條件的查詢樣本在相同穿著條件的樣本庫中進行身份檢索的Rank-1準確度,該Rank-1準確度即為相同穿著條件下的識別準確度。
(4) 跨穿著條件下的識別準確度
給定某個穿著條件的查詢樣本,樣本庫中樣本的穿著條件與查詢樣本的不同,計算給定穿著條件的查詢樣本在不同穿著條件的樣本庫中進行身份檢索的Rank-1準確度,該Rank-1準確度即為跨穿著條件下的識別準確度。
4.3 實驗結果與分析
由于目前沒有針對雷達時頻譜圖的基于檢索任務的步態識別方法,我們對比了幾種基于分類任務的步態識別方法,并將這些方法中的分類損失替換為三元損失以完成檢索任務。也就是說可以認為這些方法都是已有的針對雷達時頻譜圖的基于分類任務的步態識別方法的變形,我們已經將這些方法的分類網絡改成了檢索網絡,做的是檢索任務的識別實驗。其中,方法1[12]在VGG-16網絡[25]中嵌入了注意力機制以獲取更具判別力的步態特征,方法2[5]在自建網絡中嵌入了殘差模塊以及密集模塊,方法3[13]使用了多尺度特征融合策略以融合網絡不同層提取的信息,方法4[14]使用Inception模塊以及殘差模塊搭建了一個輕量級網絡,方法5[11]使用時序卷積神經網絡對時頻譜圖中的時序信息進行建模。
如2.5節所述,每位受試者共采集了10組數據,其中正常穿著的6組數據表示為NM01-06,挎包的2組數據表示為BG01-02,穿大衣的2組數據表示為CT01-02。本文實驗中將NM05-06、BG01-02以及CT01-02分別作為查詢樣本,將NM01-04作為樣本庫。查詢樣本NM05-06在樣本庫NM01-04中進行身份檢索可以評估相同穿著條件下的識別性能,查詢樣本BG01-02和CT01-02在樣本庫NM01-04中進行身份檢索可以評估跨穿著條件下的識別性能。
表2給出了不同方法在多視角、相同穿著條件下和多視角、跨穿著條件下的識別結果,從表2可以看出,當查詢樣本為正常穿著NM(相同穿著條件)以及挎包BG、穿大衣CT(跨穿著條件)時,本文方法的識別性能均優于其他方法,這是因為方法1到方法4沒有利用到時頻譜圖中的時序信息,方法5對全局時序信息進行了建模,但對局部時序特征的挖掘不足,而本文方法針對時頻譜圖的時序特性設計了長短時特征提取模塊,該模塊首先將時頻譜圖的特征圖沿時間維分割成不同的份數,以提取不同時間尺度的步態特征,最后將從整張特征圖中提取到的全局時序特征與從分割后的特征圖中提取到的多粒度局部時序特征進行融合,以獲得更加豐富的步態特征表示。同時,本文使用了多尺度特征融合策略,可以充分利用淺層特征圖中的局部、細粒度信息以及深層特征圖中的全局、粗粒度信息。雖然本文方法取得了不錯的識別效果,但是在跨穿著條件下的識別準確度相較于相同穿著條件仍然有一定程度的下降,從表2可以看出,查詢樣本為BG時的準確度相較于NM時下降13.23%,查詢樣本為CT時的準確度相較于NM時下降15.27%。這是因為挎包和穿大衣行走時人體的步態微多普勒特征與正常行走時相比有所差異,因此在跨穿著條件下網絡的識別性能會有所下降。
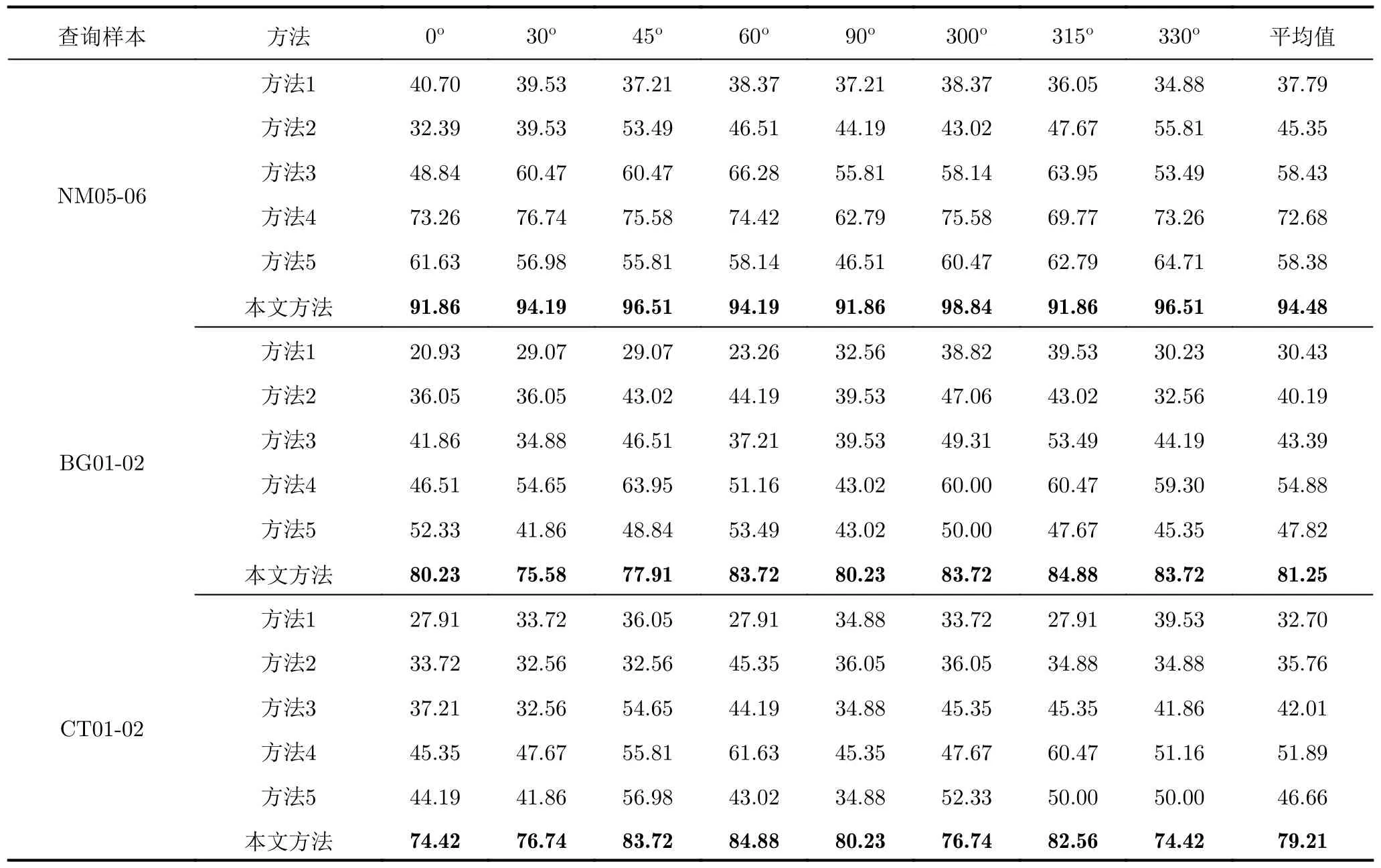
表2 不同步態識別方法在多視角條件下的識別準確度(%)Tab.2 Recognition accuracy of different gait recognition methods in multi-view conditions (%)
表3給出了不同方法在跨視角、相同穿著條件下和跨視角、跨穿著條件下的識別結果,從表3可以看出,所有方法在跨視角條件下的識別準確度相較于多視角條件下的識別準確度均有大幅下降。這是因為雷達獲取的是向視線方向投影的微多普勒信息,具有較強的方位敏感性,當一個人的行走視角發生變化時,時頻譜圖反映的微多普勒信息也會隨之變化,因此在跨視角條件下的識別性能較差。但本文方法較這些方法在跨視角條件下還是能夠在一定程度上提升識別性能的。
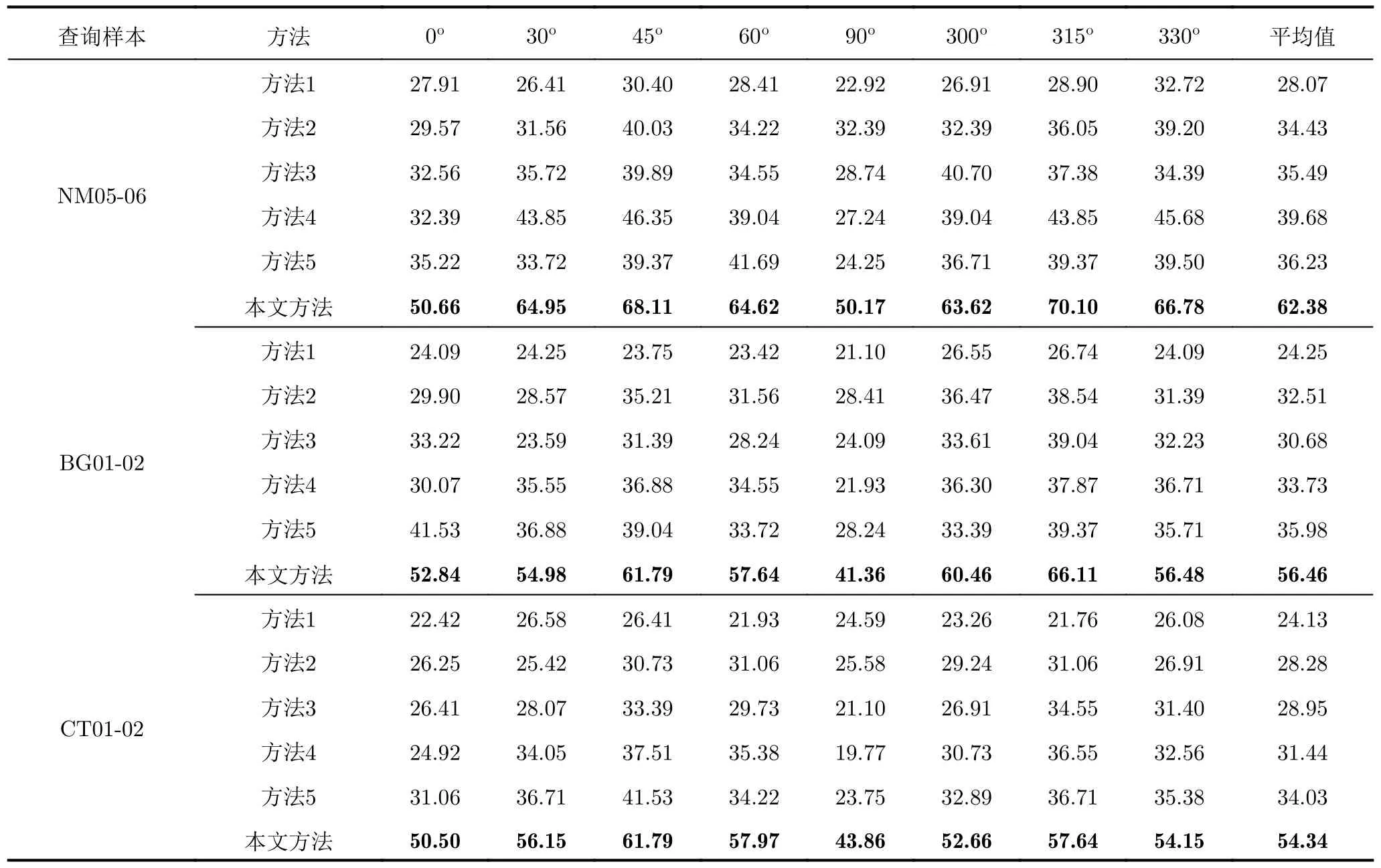
表3 不同步態識別方法在跨視角條件下的識別準確度(%)Tab.3 Recognition accuracy of different gait recognition methods in cross-view conditions (%)
此外,我們計算了不同方法的模型復雜度,其中輸入時頻譜圖的格式為224像素×224像素的3通道RGB圖片。表4展示了不同方法的模型復雜度,由表4可知,本文方法的計算量大于其他方法,參數量比方法1小,比其他方法大。說明我們針對檢索任務設計合適的模塊來提升模型識別率的同時,也在一定程度上增加了模型的復雜度,因此后續需要進一步研究一些輕量級架構以提高模型的識別效率。
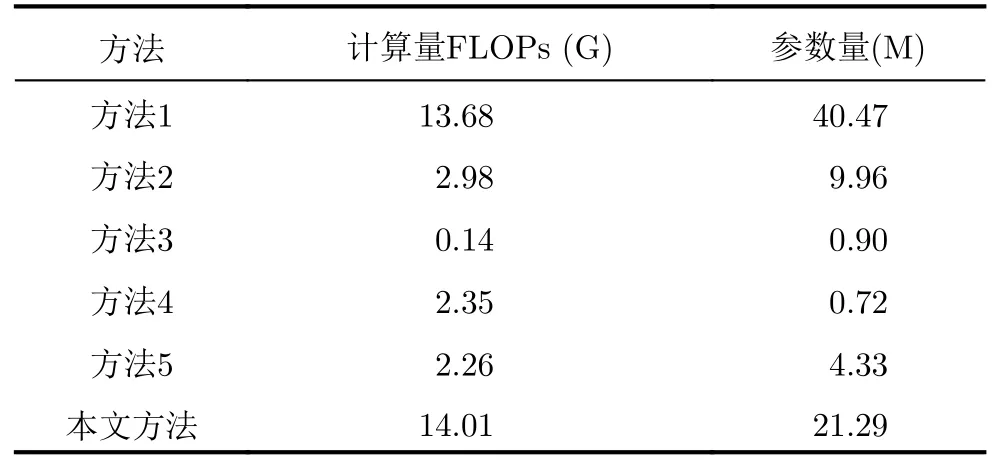
表4 不同步態識別方法的模型復雜度Tab.4 Model complexity of different gait recognition methods
4.4 消融實驗
我們進行了一系列消融實驗以評估所提網絡模型中空間注意力模塊、長短時特征提取模塊以及多尺度特征融合模塊的有效性。表5給出了在多視角條件下進行消融實驗的結果。
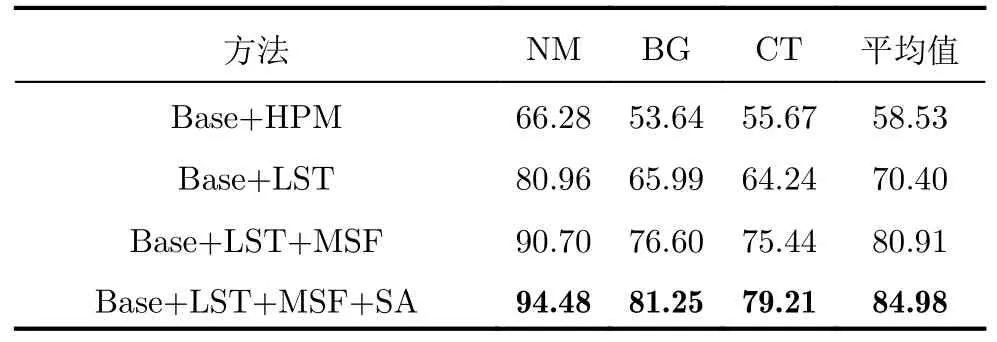
表5 消融實驗識別準確度(%)Tab.5 Recognition accuracy of ablation studies (%)
表5中Base表示ResNet18主干特征提取網絡,LST表示長短時特征提取模塊,HPM表示文獻[26]提出的水平金字塔映射模塊,與本文所提的LST相比,HPM缺少向量取平均的操作,MSF表示多尺度特征融合模塊,SA表示空間注意力模塊。相較于Base+HPM,Base+LST的識別準確度提高了11.87%,這是因為LST中向量取平均操作聚合了分割后各個部分的特征,有效緩解了時頻譜圖中起始狀態不對齊對識別性能的影響。與Base+LST相比,Base+LST+MSF的識別準確率提高了10.51%,證明了多尺度特征融合模塊可以聚合網絡不同層提取到的有價值步態信息。Base+LST+MS+SA為本文方法,其在Base+LST+MSF的基礎上增加了空間注意力模塊,識別準確率提高了4.07%,證明了對時頻譜圖中空間位置進行加權可以提高步態特征的鑒別性。上述消融實驗證明了本文方法中各個模塊的合理性與有效性。
5 結語
本文公開了一個大型的雷達時頻譜圖步態識別數據集,填補了基于檢索任務的雷達步態識別數據集的空缺,同時為相關研究提供了數據支撐。本文使用毫米波雷達采集了121位受試者在3種穿著條件下沿雷達8個不同視角行走的時頻譜圖數據,每位受試者在每個行走視角下各采集10組,其中6組為正常穿著,2組為穿大衣,2組為挎包。同時,本文提出了一種基于檢索任務的毫米波雷達步態識別網絡模型,并在公布數據集上進行了相關實驗,實驗結果證明了所提模型的有效性。此外,跨視角和跨穿著條件下的步態識別是一項非常有挑戰性的工作,本文所提模型的實驗結果可以作為基準性能指標,方便后續相關工作者在此基礎上開展進一步研究。
本文公布的數據集仍然存在一些不足需要改進,由于本文使用1發4收的毫米波雷達天線配置采集數據,雷達的方位維分辨率較低并且沒有俯仰維分辨能力,在步態識別時無法利用人體的空間位置信息以及形狀信息。后續考慮使用具有較高方位維和俯仰維分辨率的雷達采集人體步態數據,生成時頻譜圖、點云等形式的數據,以充分利用人體的微多普勒信息、形狀信息和空間位置信息等進行步態識別。此外,本數據集的采集場景較為單一、背景較為干凈,后續我們會進一步開展復雜場景中的步態識別研究。
附錄
MMRGait-1.0:多視角多穿著條件下的雷達時頻譜圖步態識別數據集(MMRGait-1.0)依托《雷達學報》官方網站發布,數據及使用說明已上傳至學報網站“MMRGait-1.0:多視角多穿著條件下的雷達時頻譜圖步態識別數據集”頁面(附圖1),網址: https://radars.ac.cn/web/data/getData?newsColumnId=c2cae1d9-521f-444e-ad1e-f009bf7b9acc.

附圖1 MMRGait-1.0:多視角多穿著條件下的雷達時頻譜圖步態識別數據集發布網頁App.Fig.1 Release webpage of MMRGait-1.0: A radar time-frequency spectrogram dataset for gait recognition under multi-view and multi-wearing conditions dataset
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
