面向微服務的制造執行系統關鍵技術研究*
2023-09-18 08:42:16李亞杰李昭楠
制造技術與機床 2023年9期
李亞杰 李昭楠
(河南科技大學機電工程學院,河南 洛陽 471003)
隨著智能制造研究與應用的不斷深入,制造執行系統作為連接企業計劃層與控制層的紐帶,在企業智能制造體系架構中的作用也顯得更加重要。為了得到最好的應用效果,制造執行系統需要根據企業制造車間的個性化需求進行定制。隨著客戶個性化定制需求的不斷增加,企業的生產組織模式、管理流程與生產過程也呈現出多樣化、動態多變的特點,因此要求制造執行系統具有更加敏捷、靈活的動態配置與重構能力。
傳統的MES 系統大多采用單體架構,系統功能之間耦合程度高,隨著企業需求的不斷變化,系統規模與復雜度不斷增加,造成系統可擴展性差、變更周期長、成本高,在企業需求變更出現后難以快速對系統進行重構,造成企業現狀與系統功能之間的脫節,影響系統的應用效果,甚至造成系統實施的失敗。為了改善制造執行系統的可重構性,文獻[1]提出了面向生產過程云服務的制造執行系統,采用面向服務的技術架構(service oriented architecture,SOA),將復雜的車間管理業務定義為松散耦合的服務組件,便于車間業務流程進行靈活、動態的配置與重構。文獻[2]基于可重構流程模型和組件技術建立了可重構MES 流程模型,以提高MES 系統流程的可重構能力。文獻[3]提出了一種面向MES 生命周期的模型驅動定制化方法來進行MES 系統的自動生成和持續改進,降低MES 實施和重構的復雜性。文獻[4]針對具有高度自動化水平的制造系統提出了一種MES 定制化方法,將可變性指數作為評價生產系統有效性的參數來驅動MES 模型進行調整。文獻[5]從底層的體系結構入手,建立了支持網絡化制造的數控車間可插拔制造執行系統。文獻[6]提出一種制造執行系統集成可重構的框架,并分別從業務實體、業務邏輯和系統間集成層研究了集成可重構實現方法。文獻[7]針對制造執行系統擴展性問題,建立了基于工廠方法模式的可擴展MES 系統體系結構。以上研究為提高MES 的可重構性和可擴展性提供了解決思路,但仍無法從根本上避免采用單體架構造成的系統復雜度高、維護成本高、交付周期長等問題[8]。
微服務架構將大型軟件系統拆分為多個可獨立運行的服務,拆分后的微服務可以獨立進行開發、測試、部署、重構,很大程度地降低了系統的耦合性[9],基于微服務架構的系統具有開發周期短、擴展性與復用性更好的優點[10],微服務架構的這種特性使其在系統開發中被廣泛接受和應用[11-13]。因此,本文開展了面向微服務的制造執行系統研究,建立了面向微服務的制造執行系統架構,并提出了基于用例-數據訪問關系模型的制造執行系統微服務劃分方法,將用例和數據之間的訪問關系作為微服務劃分的依據,將制造執行系統劃分為多個相互獨立的微服務,便于在不影響系統運行的條件下進行系統功能的重構,以提高系統持續滿足車間業務需求變化的能力,進而提升系統的應用效果和車間管理效率。
1 基于微服務的制造執行系統架構
基于微服務的制造執行系統架構如圖1 所示。主要包括平臺層、數據層、服務層、接口層、應用層和展示層。
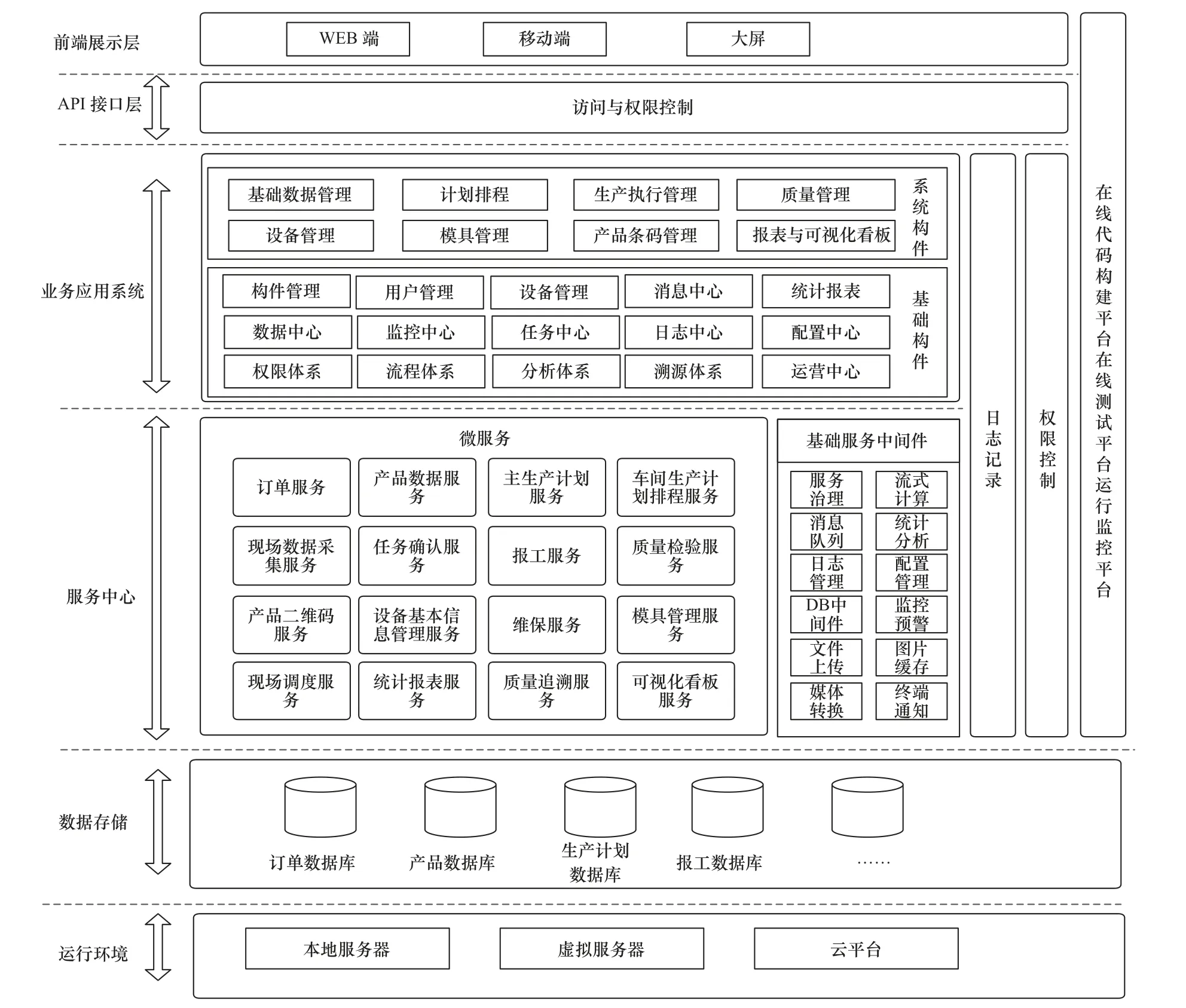
圖1 基于微服務的MES 系統架構
(1)展示層:展示層是MES 與用戶進行交互的前端,主要負責接收用戶的輸入和操作指令,并將系統的運行結果展示給用戶。
(2)應用層:應用層是系統提供給用戶的功能,在應用層按照用戶的業務流程將微服務封裝為MES 的各個功能,在展示層接收到用戶的輸入和操作指令后通過調用應用層的功能實現對于不同業務的處理。
(3)接口層:接口層負責連接應用層和服務層,根據應用層中用戶選擇的不同操作通過接口調用對應的微服務進行處理,并將處理結果返回給應用層。
(4)服務層:服務層中封裝了系統中包含的微服務,用戶的業務邏輯主要反映在服務層中,負責按照用戶指令進行數據查詢與邏輯運算,并反饋處理結果,是系統的核心層。
(5)數據層:數據層中包含系統運行所需的數據庫,為系統運行提供數據存儲服務。
(6)平臺層:平臺層中包含系統運行所需的服務器、操作系統、數據庫系統等軟硬件條件。
在MES 的多層架構中,應用層實現對用戶業務流程的封裝和處理,服務層負責對數據的邏輯運算,接口層負責應用層和服務層之間的數據通信,通過這種分層劃分解除業務流程和數據處理邏輯之間的耦合關系,當業務流程或業務邏輯發生變化時,只需要對應的重構業務層或服務層中受到影響的部分,不會對其他部分產生影響,降低系統重構的技術復雜度,便于對系統進行維護。
系統數據庫分為業務系統構建數據庫(圖2)和業務數據庫(圖3)兩部分。應用層的業務應用系統由各個微服務組合而成,它們之間的組成關系存儲在業務系統構建數據庫中,包括業務系統屬性表和微服務表。業務系統屬性表中存儲各業務系統的信息,包括業務系統編號、業務系統名稱和業務系統描述等。微服務表中存儲系統各個微服務的信息,包括微服務編號、微服務名稱、端口號和微服務描述等,微服務和業務系統之間的組成關系體現在這兩張表的主外鍵關系上。

圖2 業務系統構建數據庫

圖3 業務數據庫
業務數據庫中存儲業務執行過程中產生的數據。為了保證系統微服務的獨立性,每個微服務在業務數據庫中都對應于一個單獨的數據庫。例如在圖3 中,將業務數據拆分為設備與派工、計劃管理、現場管理等數據庫供對應的微服務調用。
2 領域場景驅動的制造執行系統微服務劃分技術
對于采用微服務架構的系統來說,微服務的粒度劃分是否合適是最關鍵的因素之一[9],微服務粒度決定了系統微服務之間相互調用和通信的復雜度。目前大多數系統在進行微服務劃分時依賴架構設計者的個人經驗[14],受主觀因素影響較大,并且面對大型系統時,微服務拆分效果較低且粒度劃分合理性無法保證。
領域驅動設計倡導按照業務領域進行系統微服務劃分,不同的業務領域之間使用獨立的數據模型。制造執行系統作為一種數據庫系統,其系統業務的實現最終都是圍繞數據庫實現的。在制造執行系統的系統設計階段,用例圖反映用戶能夠在系統中完成的操作,數據庫結構模型反映用戶執行業務過程中涉及的各類數據,通過對用例圖和數據庫表結構進行分析,能夠得到系統的業務邏輯以及相互之間的數據調用關系。用例與數據表之間的關聯關系對應于系統中的業務邏輯、功能與微服務之間的關系,對其進行分析之后能夠得到系統的微服務劃分結果。因此,本文建立了基于用例圖和數據庫表結構的MES 系統微服務劃分方法,劃分流程如圖4 所示。
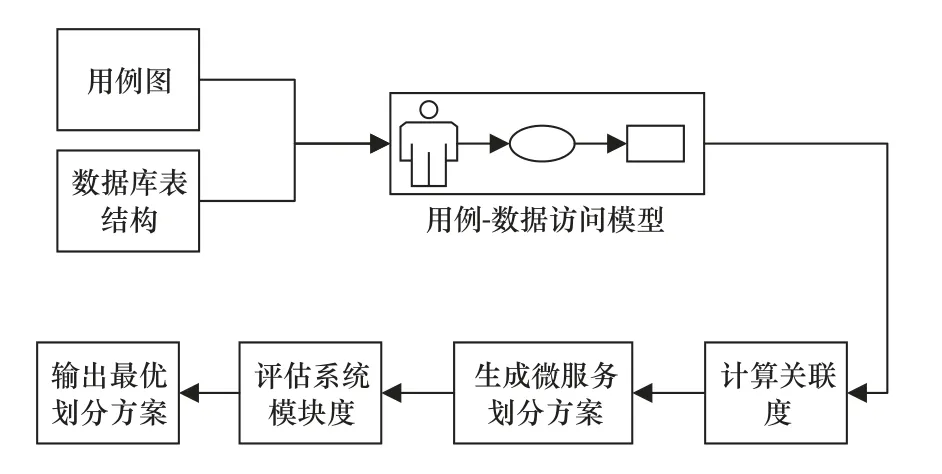
圖4 微服務劃分流程
步驟1:對用戶進行調研,建立系統用例圖和數據庫表結構。
步驟2:分析用例和數據表之間的數據調用關系,建立用例數據訪問模型。在系統中,當不同的用例操作同一個數據表時,雖然操作的類型與數據屬性不同,但在最終實現時僅體現在前后端的接口程序中,對系統微服務的劃分沒有影響,因此本文在建立用例-數據訪問模型時僅考慮用例對數據表的調用,不考慮數據表具體屬性的調用。
步驟3:根據用例對數據表的數據調用類型,計算用例和數據表之間、數據表和數據表之間的關聯關系。
步驟4:利用GN 算法生成微服務方案。
步驟5:評估微服務劃分方案對應的MES 系統模塊度,輸出劃分方案。
2.1 建立用例-數據訪問模型
解析用例與數據表之間的訪問關系,建立三元組W=(U,E,R),其中U 表示與數據表有關聯關系的用例集合,E為數據表集合,R為用例-數據關系集合,例如Rm=(Ui,Ej,create)表示用例Ui和數據Ej存在名為create的調用關系。用例-數據訪問模型如圖5 所示,例如,對于用例U1和數據表E1之間通過一條邊相連,這條邊記為E1=(U1,E1,Delete)。
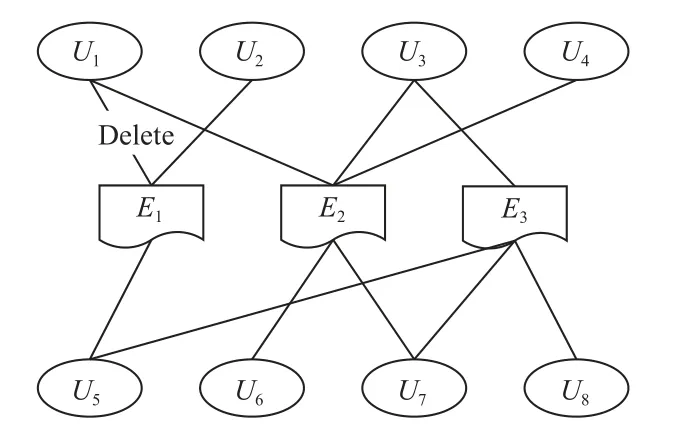
圖5 用例-數據訪問模型
建模過程如下:
步驟1:分析用例-數據關系圖中的特征,建立數據表集合E 與用例集合U,每個用例與數據表都是模型中的節點。
步驟2:分析用例與數據表之間的調用關系與類型,對于每個用例,確定進行業務操作時與之關聯的所有數據表,生成用例及與之關聯數據表的邊。
步驟3:依據節點與邊的關聯建立映射。對于圖5 中任一邊,由該邊連接的兩個節點作為此邊的關聯映射。
2.2 計算數據關聯度
在用例-數據表關系圖模型中數據表之間沒有直接相連的邊,但數據表能夠被不同用例通過訪問調用進行關聯,數據關聯度體現在用例與數據表的調用關系上。當數據表被一個用例同時調用時,表示這些數據表之間的關聯度較高,會同時被操作,因此,在進行微服務劃分時,關聯度高的數據表更應該被劃分到同一個微服務中以提高微服務之間的獨立性,降低微服務之間的調用頻率,降低系統的數據耦合程度和復雜度。
設用例-數據訪問模型中共包含n個用例,m個數據表,Counti代表操作數據表Ei的用例數量,Countij代表同時操作數據表Ei和Ej的用例數量,則數據表Ei和Ej的關聯度Sij等于Countij除以分別操作Ei和Ej的用例數量之和,即:
按照上述公式計算可得E中m個數據表兩兩之間的關聯度,表現為一個m×m的關聯度矩陣S,矩陣中第i行第j列的元素表示數據表Ei和Ej之間的關聯度Sij,由上述公式可知Sij=Sji,矩陣對角線上的元素取值為0,表示當i=j,即Ei和Ej為同一個數據表時關聯度為0。
2.3 微服務劃分
矩陣S反映了用例-數據表關系圖中的數據表之間的關聯度,用例-數據訪問模型中的R反映了用例與數據之間的關聯關系權重,本文采用Girvan-Newman(G-N)算法對用例和數據表進行聚類,通過聚類運算后,具有更高關聯度的用例和數據表會被聚到一個微服務中。G-N 算法的流程如下。
步驟1:根據用例-數據訪問模型和關聯矩陣S構建無向圖T,T 的頂點為集合U 中的用例和集合E 中的數據表,當Tij=0 時表示頂點i和j之間沒有邊相連,當Tij=a時表示頂點i和j之間有一條權重為a的邊相連。對于連接用例和數據表的邊,其權重根據用例與數據表的訪問關系類型確定,用例對于數據的操作包括創建(Create)、修改(Update)、查詢(Query)、刪除(Delete)4 種,對應業務執行過程中對于數據庫操作的4 種形式,創建代表該用例執行過程中會生成一條或多條數據,修改表明用例執行過程中會對數據表的某些屬性進行修改,查詢表明用例執行過程中需要查詢數據表的某些屬性,刪除表明用例執行過程中會刪除一條或多條數據。為了區分這4 種關系所反映的用例與數據表之間的關聯程度,按照這4 種關系對數據的影響,為其賦予不同的權重值,分別為創建1、修改0.75、刪除0.5、查詢0.25。對于連接數據表的邊,其權重為關聯矩陣中對應數據表之間的關聯度值。
步驟2:計算所有邊的邊介數,用邊介數除以對應邊的權重得到邊權比,找到邊權比最大的邊將其移除。
式中:Cij表示頂點i和j之間的邊介數,αij表示連接頂點i和j的邊的權重。
步驟3:保存劃分結果,并計算模塊度Q,模塊度的計算方法見式(4)。
式中:eii表示社區i中所有邊的權重與整個圖中所有邊權重的比值,ai表示與社區i頂點相連的所有邊的權重與整個圖中連接所有頂點的邊的權重之間的比值。
步驟4:重復步驟2、3 直至所有的邊都被移除,輸出模塊度最高的劃分方案。
算法的核心代碼如下:
3 應用實例
某軸承制造企業采用面向訂單制造的管理模式,目前的生產管理采用人工和紙質文件管理的方式進行,生產計劃采用紙質計劃文件下達,每天由統計員統計現場完工情況,并逐級向上反饋,計劃的變更由計劃員口頭通知,生產管理的規范性較差,生產計劃的科學性不強,現場生產狀態反饋不及時,難以實時、準確地獲取訂單的生產情況,延遲交付時有發生。在此情況下,企業開展了制造執行系統建設,通過調研分析,建立了圖6 所示的用例-數據訪問關系圖(計劃和現場管理部分)。
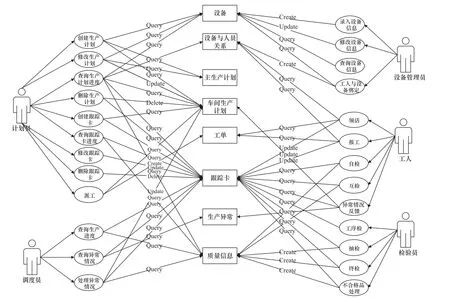
圖6 用例-數據訪問關系圖
根據用例與數據表之間的關系,計算數據表之間的關聯度,建立關聯度矩陣:
算法的模塊度迭代過程如圖7 所示,算法輸出結果見表1。

表1 微服務劃分結果

圖7 模塊度迭代曲線
根據算法計算結果,可將圖6 劃分為3 個微服務。至此,基于系統設計階段建立的用例圖和數據表結構,通過用例-數據訪問關系驅動的劃分方法獲得了模塊度最高的MES 系統微服務劃分結果,可以為開發人員進行微服務劃分提供參考。
4 結語
通過建立基于微服務的多層制造執行系統架構,降低制造執行系統的耦合性和復雜度,便于對系統進行維護。通過領域場景驅動的微服務劃分技術,利用用例-數據表訪問關系圖進行分析,得到系統數據表之間的關聯度,利用G-N 算法進行微服務劃分,得到模塊度最高的系統微服務劃分方案,解決傳統單體架構帶來的重構和擴展困難的問題,提高制造執行系統的可重構性和可維護性,為制造執行系統快速響應業務重構需求變化提供支撐。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
家庭影院技術(2017年9期)2017-09-26 03:41:45
商周刊(2017年9期)2017-08-22 02:57:56
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
