注意力機制融合前端網絡中間層的語聲情感識別
2023-09-20 06:50:18朱應俊周文君馬建敏
應用聲學 2023年5期
朱應俊 周文君 朱 川 馬建敏
(復旦大學航空航天系 上海 200433)
0 引言
語聲情感識別(Speech emotion recognition,SER)已在娛樂產品的情感交互、遠程教育的情感反饋、智能座艙的情緒監測中得到廣泛應用。在應用中,通過建立語聲信號的聲學特征與情感的映射關系,對語聲的情感進行分類。基于單一特征的SER 模型因受到特征信息量不足的制約而影響識別準確率。隨著對語聲情感特征研究的逐步深入,通過對多種語聲特征進行融合以消除特征中的冗余信息并提升識別準確率的方法受到越來越多的關注,已形成了特征級、中間層級、決策級等融合方式。
對語聲情感特征進行特征級的融合可以在增加信息量并提高識別準確率的同時有效減小特征維度。Liu等[1]使用基于相關性分析和Fisher 準則的特征選擇方法,去除來自同一聲源且具有較高相關性的冗余特征。Cao等[2]也提出了基于Spearman 相關性分析和隨機森林特征選擇的方法提取相關性最弱的特征以進行融合。基于網絡中間層進行的融合則利用神經網絡將原始特征轉化為高維特征表達,以獲取不同模態數據在高維空間的融合表示。Cao等[3]在話語級別的情感識別中使用門控記憶單元(Gated memory unit,GMU)來獲取語聲信號的靜態與動態特征融合后的情感中間表示。Zhang等[4]提出了基于塊的時間池化策略用于融合多個預訓練的卷積神經網絡(Convolutional neural network,CNN)模型學習到的片段級情感特征,得到固定長度的話語級情感特征。語聲特征的融合還可基于多個模型在其輸出階段進行決策級融合以集成其情感分類結果[5]。Noh等[6]使用基于驗證準確度的指數加權平均法則組成了分級投票決策器對多個CNN 模型的決策結果進行融合。Yao等[7]使用基于置信度的決策級融合整合了在多任務學習中獲得的循環神經網絡(Recurrent neural network,RNN)、CNN 和深度神經網絡(Deep neural network,DNN)。
注意力機制可用于自動計算輸入數據對輸出數據的貢獻大小,近年來也在語聲識別相關領域得到了較多運用。Bahdanau等[8]將注意力機制應用于RNN 和n-gram 語言模型,建立了端到端的序列模型。Mirsamadi等[9]將基于局部注意力機制的加權時間池化策略用于RNN 模型,以學習與情感相關的短時幀級特征。Kwon[10]使用特殊的擴張CNN 從輸入的過渡語聲情感特征中提取空間信息并生成空間注意力圖以對特征進行加權。
在已有對語聲特征融合及注意力機制在SER任務中應用研究的基礎上,通過對語聲信號進行預加重和分幀加窗等處理,得到基于譜特征和時序特征的前端網絡,利用壓縮-激勵(Squeeze-andexcitation,SE)通道注意力機制對前端網絡中間層進行融合,有效利用不同前端網絡在SER 任務中的優勢提高情感識別準確率。通過在漢語情感數據集中的對比實驗,對前端網絡選擇的合理性和SE 通道注意力機制用于對前端網絡中間層進行融合的有效性進行驗證。
1 SER模型
本文判斷語聲信號情感類別的SER 模型如圖1所示,該模型由3個模塊組成:前端網絡模塊、注意力機制融合模塊和后端網絡分類模塊。前端網絡模塊對輸入的語聲信號進行預加重和分幀加窗等處理后,提取梅爾倒譜系數(Mel-frequency cepstral coefficients,MFCC)和逆梅爾倒譜系數(Inverted MFCC,IMFCC)作為譜特征,把譜特征輸入到二維卷積神經網絡(Two dimensional CNN,2D-CNN)得到MFCC 2D-CNN 和IMFCC 2D-CNN;提取散射卷積網絡系數(Scattering convolution network coefficients,SCNC)作為時序特征,把時序特征輸入到長短期記憶網絡(Long-short term memory,LSTM)中得到SCNC LSTM。注意力機制融合模塊引入SE 通道注意力機制,將MFCC 2D-CNN、IMFCC 2D-CNN 和SCNC LSTM 前端網絡中提取的中間層進行加權融合得到融合深度特征(Fusion deep feature,FDF)。后端分類模塊基于DNN構建分類器,依據輸入的FDF映射輸出情感分類結果。
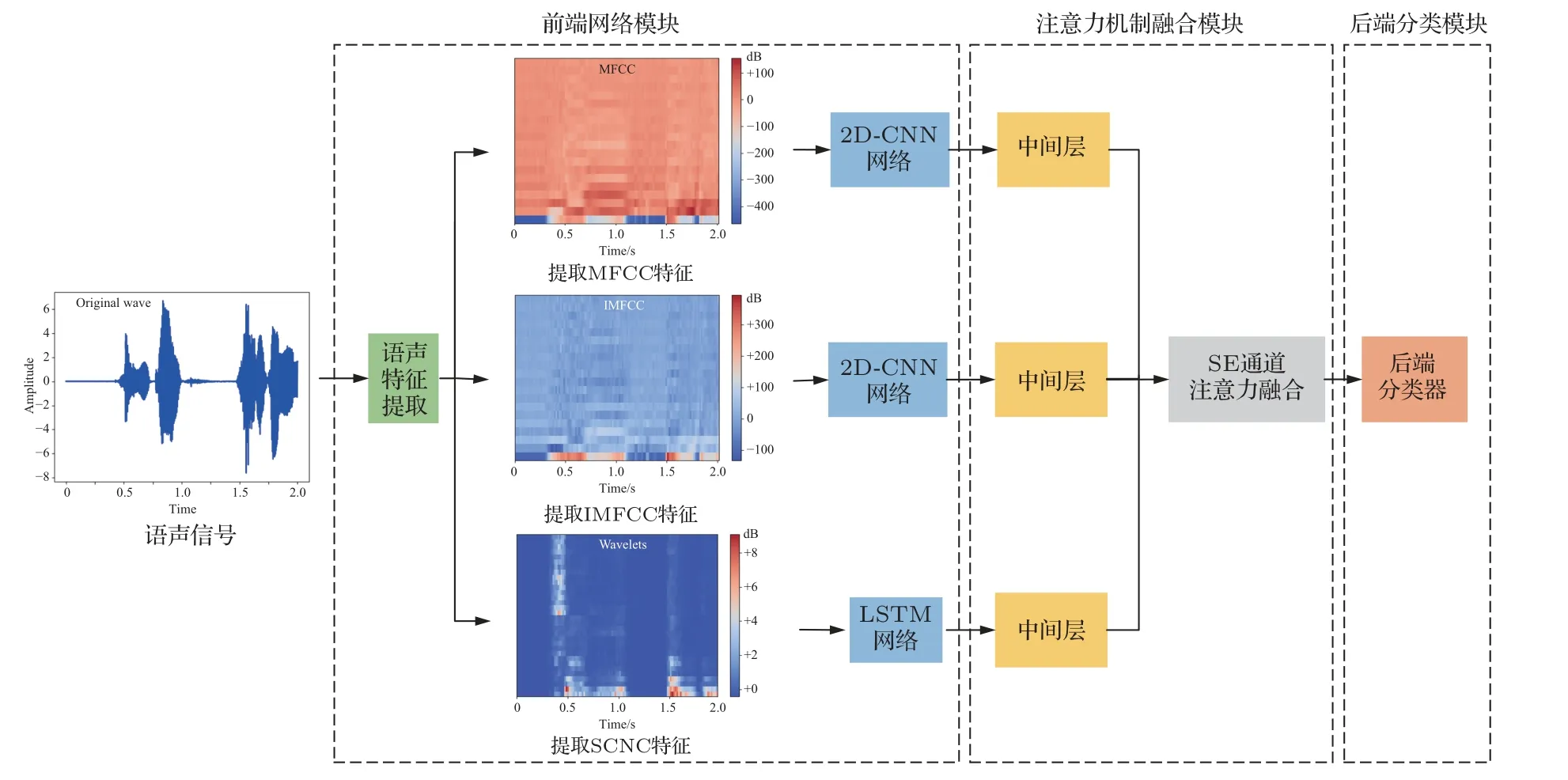
圖1 SER 模型結構Fig.1 Structure of SER model
1.1 基 于MFCC 和IMFCC 特 征 的2D-CNN前端網絡
MFCC 和IMFCC譜特征中不同頻譜區間的頻譜能量分布體現著不同情感狀態下的聲道形狀和發聲狀態[11],其中計算MFCC 特征時使用的Mel三角濾波器模擬了人耳聽覺的非線性機制,更加關注于語聲信號的低頻部分而對中高頻的變化不夠敏感[12];IMFCC特征則通過IMel 濾波器在高頻區域分布更加密集來獲取更多高頻信息[13]。Hz 頻率與Mel 頻率及IMel 頻率之間的定量關系可分別表示為[14]
其中,f表示Hz 頻率,fMel和fIMel分別為Mel 頻率及IMel頻率。
將語聲信號的功率譜通過Mel 及IMel 三角濾波器,并將對數能量帶入離散余弦變換(Discrete cosine transform,DCT)以消除相關性,可計算得到語聲信號的MFCC 系數及IMFCC 系數。還引入其一階二階差分項作為動態特征以體現語聲情感的時域連續性[15]。特征差分項dt的實現如下:
其中,ct表示MFCC或IMFCC倒譜系數,st表示一階導數的時間差。將一階差分結果重復帶入即可得到二階差分,最終可計算得到帶有差分項的MFCC及IMFCC特征。
為了利用CNN 在提取特征矩陣的局部空間相關性信息方面的優勢[16],本文搭建了改進Alexnet的2D-CNN,網絡結構簡圖如圖2 所示,網絡卷積部分的結構參數如表1 所示。卷積層使用了ReLU 激活函數,并進行了L2 正則化,正則化參數為0.02。在完成卷積運算后,使用扁平化層(Flatten)對卷積特征進行降維,輸入到節點數分別為2048 和512的兩層全連接層對特征進行整合,并由6 個節點的Softmax 分類層得到情感分類結果。將MFCC和IMFCC特征分別輸入2D-CNN 訓練得到MFCC 2D-CNN前端網絡和IMFCC 2D-CNN前端網絡。
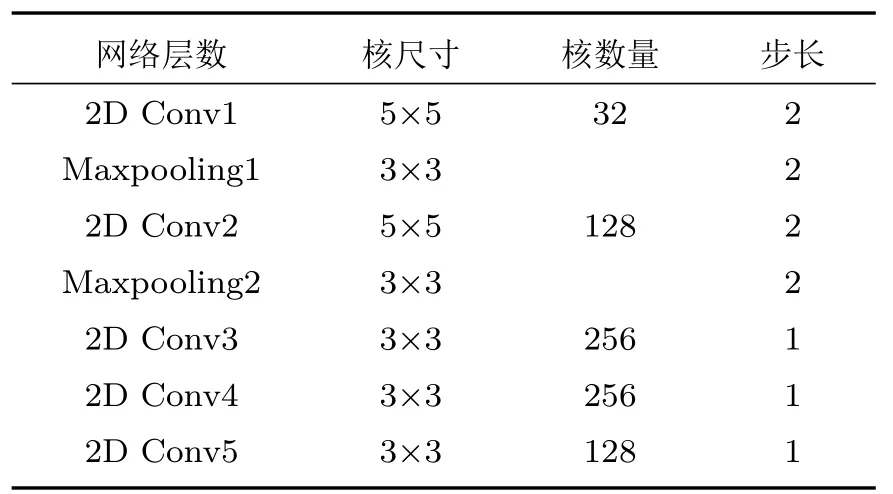
表1 2D-CNN 前端網絡卷積層參數Table 1 Parameters of convolutional layers in 2D-CNN front-end network
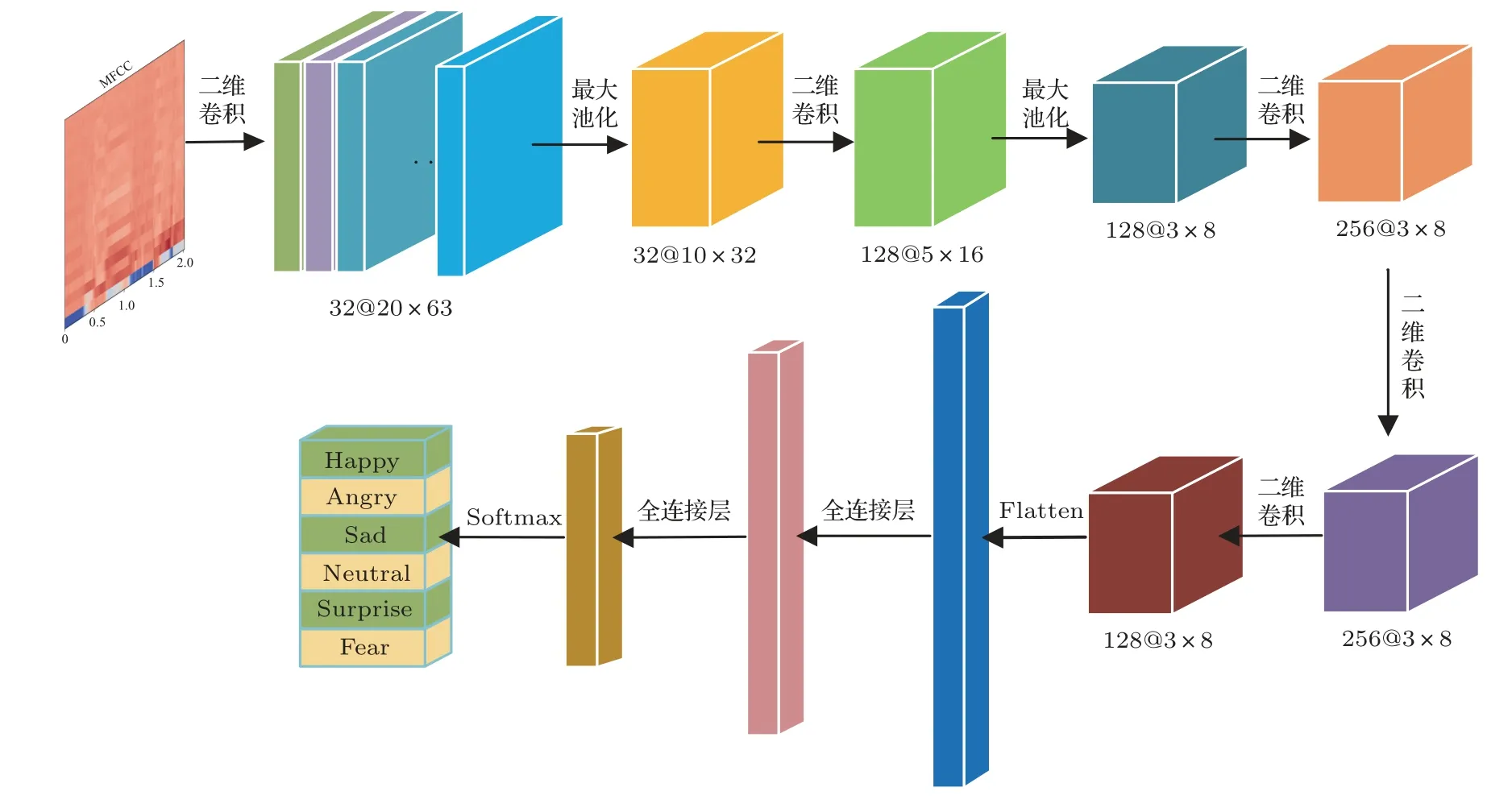
圖2 基于MFCC 與IMFCC 的2D-CNN 前端網絡結構Fig.2 2D-CNN front-end network structure based on MFCC and IMFCC
在反向傳播過程中,為了應對由樣本量過少及訓練數據分布不均衡導致的網絡性能下降的問題,本文引入了Focal loss損失函數[17],通過給難分類樣本(Hard example)較大的權重,給易分類樣本(Easy example)較小的權重,來放大難分類樣本的損失并抑制易分類樣本的損失,從而使網絡聚焦于難分類樣本的學習,提高分類準確率。Focal loss 損失函數Lfl的計算如下:
其中,pt表示分類器預測的概率值,γ為權重放大因子,αt是類別權重。為了增大2D-CNN 前端網絡對難分類樣本的權重,將γ取為4,因為數據集中各類情感樣本數目相同,將αt設置為1。
1.2 基于SCNC特征的LSTM前端網絡
本文引入了由不變散射卷積網絡(Invariant scattering convolution network,ISCN)自動提取的SCNC 特征[18]作為時序特征。將語聲幀視作短時平穩信號,輸入由多層小波散射變換與取模算子級聯得到的ISCN 中,提取其散射系數作為SCNC 特征,該特征能夠最小化信號的平移和形變的影響,具有較強的變形穩定性,且保留用于分類的高頻信息,故在網絡中間層對特征進行融合時能夠維持分類魯棒性[19]。
對語聲信號進行的小波變換可表示為{x ?ψλ}λ,其中指數λ=2-jr給出了帶通濾波器ψλ的頻率位置,?表示卷積運算,對于語聲信號僅計算λ在r ∈[0,π)范圍內所對應的路徑。沿路徑p=(λ1,λ2,···,λm) 迭代進行小波變換和取模運算可求得小波變換系數:
其中,對于每條路徑p,S[p]x(u)是窗口位置u的函數,將式(5)代入其中即可得到計算m階加窗散射系數的公式如下:
為了提高特征的高頻分辨率,將分幀加窗后的語聲片段輸入由5 層小波變換和取模算子級聯得到的ISCN 中,以提取網絡的加窗散射系數作為SCNC特征。
LSTM 相較于CNN 可以更好地處理時間序列的任務,同時LSTM 解決了RNN 的長時依賴問題[20],并避免了反向傳播過程中的梯度消失[21]。本文搭建了基于SCNC 特征的LSTM 前端網絡,網絡由LSTM 層和3 層全連接層組成,為對應每幀語聲提取到的32維的SCNC特征,LSTM層設置了32個節點,每個節點通過126 個時間步進行更新[22]。單個節點的結構如圖3所示。
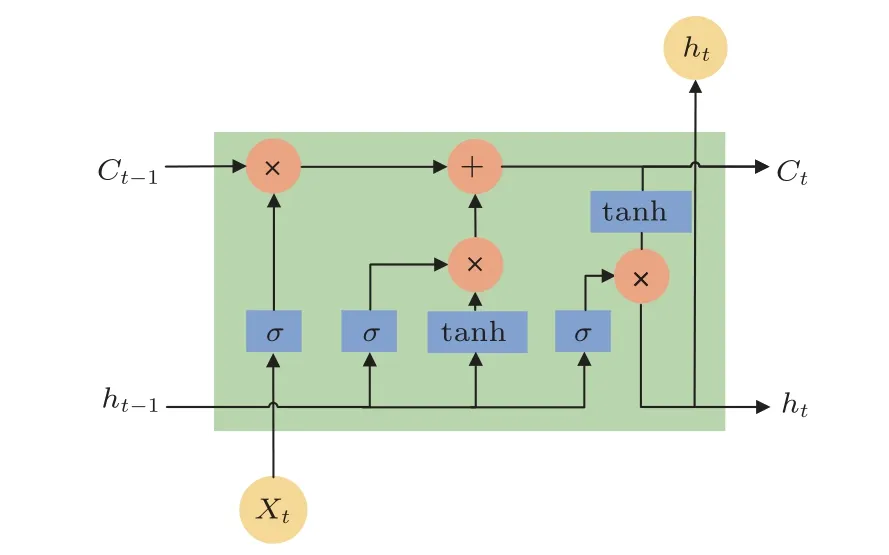
圖3 單個LSTM 節點的內部結構Fig.3 Internal structure of LSTM node
在LSTM 節點中,Xt表示SCNC 特征沿時間軸的輸入,Ct表示由當前輸入產生的細胞待更新的狀態,由輸入門it和遺忘門ft決定當前細胞狀態要如何更新,細胞狀態的迭代公式為
ht表示當前節點輸出的隱藏狀態,由輸出門ot和當前細胞狀態計算得到,使用tanh 函數作為激活函數,其計算如下:
將LSTM 網絡層輸出的全部隱藏狀態H使用Flatten 層降維后輸入到節點數分別為1024 和256的全連接層進行特征整合,激活函數為ReLU 函數,全連接層后使用了Dropout 函數以抑制過擬合,Dropout 率為0.3,并由6 個節點的Softmax 分類層得到情感分類結果。將SCNC特征輸入LSTM以訓練得到SCNC LSTM 前端網絡。
1.3 基于SE通道注意力機制的網絡中間層融合
在SER 任 務 中,MFCC 2D-CNN 和IMFCC 2D-CNN 前端網絡更加關注譜特征中的語聲能量信息,而SCNC LSTM 前端網絡則側重于語聲的時序性信息。為了發揮兩類網絡的優勢,本文將前端網絡模型視作特征提取器,分別提取了MFCC 2D-CNN 與IMFCC 2D-CNN 前端網絡最后一層卷積層的輸出,提取了SCNC LSTM 前端網絡的隱藏狀態H。前端網絡的中間層深度特征作為話語級的特征表示,由于不同網絡中的深度特征對情感分類的貢獻程度不同,本文引入SE 通道注意力機制,利用SE Block對各前端網絡中間層權重進行調整[23],融合過程如圖4所示。
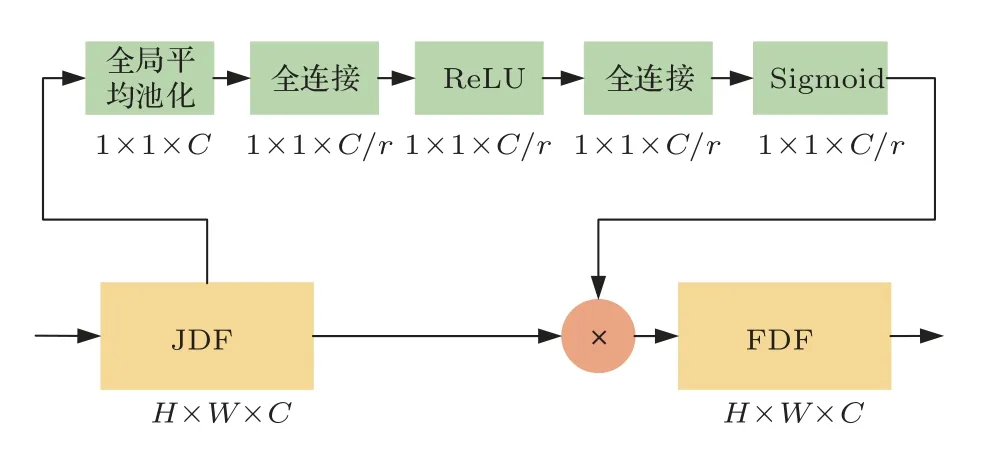
圖4 SE 通道注意力機制融合過程Fig.4 SE channel attention mechanism workflow
SE 通道注意力機制的實現通過兩步完成。第一步為Squeeze 操作,對應于圖4 中的全局平均池化,其實現如下:
其中,壓縮函數Fsq在特征維度上對中間層矩陣uc進行壓縮降維,將H ×W ×C的多通道特征降為1×1×C的C維向量,以表征網絡中間層的全局信息。第二步的Excitation 操作對全局平均池化后生成的zc依次進行了全連接、ReLU 激活、全連接、Sigmoid 激活,得到代表各通道重要性的權重矩陣,其表達式為
其中,δ為線性激活函數,W1與W2為兩個全連接層,σ為Sigmoid激活函數。
將Excitation 操作后求得的權重矩陣s與前端網絡中間層矩陣相乘可得到FDF矩陣,從而實現由多通道的聯合深度特征(Joint deep feature,JDF)向FDF的轉變。
1.4 DNN后端分類器
利用SE 通道注意力機制融合前端網絡中間層得到了FDF矩陣作為話語級的情感特征,輸入基于DNN的后端網絡分類器進行SER,網絡共有5 層全連接層,節點數分別為2048、512、256、64,激活函數均為ReLU 函數,最后由Softmax 分類層輸出得到多分類預測矩陣,取概率最大的一類作為最終的情感預測結果。在網絡中使用了Dropout 來抑制過擬合,其中Dropout 率為0.2。為了研究基于SE 通道注意力機制的網絡中間層融合方式對每一類情感的識別效果,將DNN 后端網絡的分類結果基于混淆矩陣進行輸出表示。
2 實驗與結果分析
實驗部分首先通過消融實驗對語聲特征的維度選擇及前端網絡設計的合理性進行了驗證,其次通過與前端融合和中間層非計權融合的對比實驗驗證了SE 通道注意力機制用于網絡中間層融合的有效性,最后通過與參考文獻中融合方式的對比實驗對基于SE 通道注意力機制的網絡融合方式在SER任務中的準確率與時間復雜度進行了分析。
2.1 實驗平臺與數據集
實驗選用的CPU 型號為11th Gen Intel Core i5-11400,搭配4666 MHz 頻率的雙通道DDR4 內存,容量共32 GB,用于深度學習加速的GPU 型號為NVIDIA GeForce RTX3060,顯存容量為12 GB,開發使用的語言版本為Python 3.8.3,使用的深度學習框架為Tensorflow 2.4.0。
本文實驗基于中國科學院自動化研究所錄制的漢語情感語料庫的部分數據進行,該數據子集包含了來自4 位說話者的1200 條語聲,其情感傾向包括生氣(Anger)、悲傷(Sad)、害怕(Fear)、開心(Happy)、中性(Neutral)、驚訝(Surprise),語聲的采樣率為16000 Hz。實驗中,將語聲片段的時長統一為2 s 共32000個采樣點,對其進行加窗分幀操作后可得到126 個語聲幀。求得各語聲特征維度如表2所示。
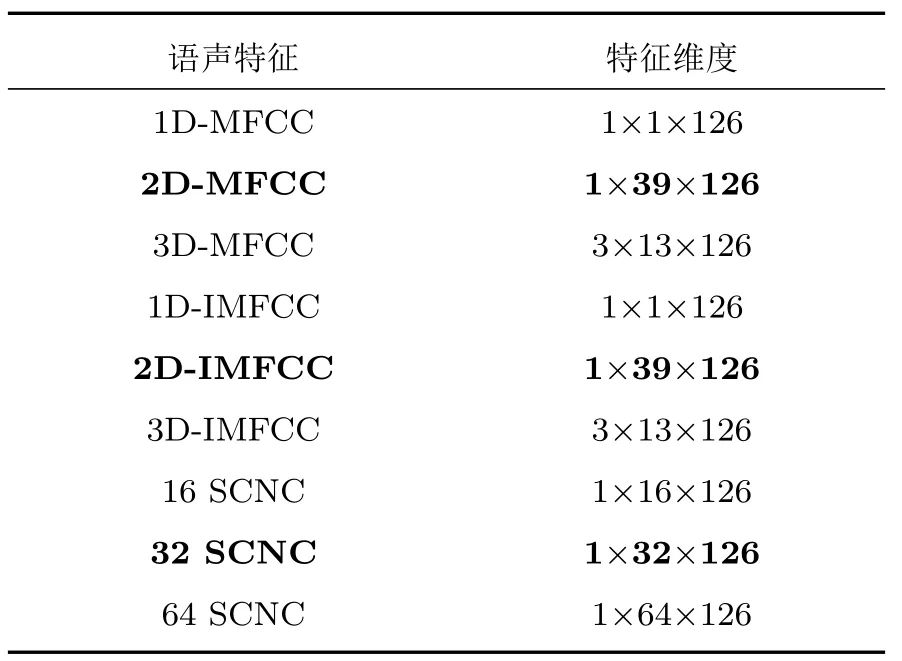
表2 語聲特征及維度Table 2 Speech features and its dimension
2.2 實驗設置
為消除數據集劃分方式對網絡性能的影響,將中國科學院自動化研究所語聲情感數據集進行隨機排序,并按照80%、10%、10%的比例劃分為訓練集、驗證集和測試集。取五折交叉驗證后的各情感平均分類準確率(Average ACC)和宏F1 得分(Macro-F1 Score)作為網絡性能的評價指標。
為驗證前端網絡設置及對應特征維度選擇的合理性,實驗分別對比了:(1) 基于一維譜特征1D-MFCC 與1D-IMFCC 的1D CNN前端網絡。(2) 基于三維譜特征3D-MFCC 與3D-IMFCC 的3D-CNN前端網絡。(3)使用平均池化(Ave-pool)層的2D-CNN前端網絡。(4) 基于16維與64維SCNC特征的LSTM 前端網絡。(5) 基于32維SCNC特征的2D-CNN前端網絡。為驗證在網絡中間層進行融合相較于特征級融合的優勢,實驗對比了兩類前端融合方式:(1) 前端特征級注意力機制融合。(2) 前端特征級非計權融合。除此之外,還比較了對網絡中間層進行非計權融合后的網絡性能。
為了進一步驗證SE 通道注意力機制用于網絡中間層融合的適用性,還和文獻[2]中基于隨機森林特征選擇算法的前端融合、文獻[3]中基于GMU 的分層網絡中間層融合和文獻[7]中基于置信度的后端融合方式進行了比較分析,并取預測測試集的總耗時作為時間復雜度指標進行討論。
2.3 實驗結果與討論
不同維度語聲特征在對應前端網絡中的分類結果如表3 中所示。由表3 可知基于二維MFCC特征的2D-CNN 前端網絡相較于基于一維及三維MFCC 特征的前端網絡取得了更高的平均準確率和宏F1 得分;基于二維IMFCC 特征的2D-CNN 前端網絡亦優于基于一維與三維IMFCC 特征的前端網絡;且最大池化在2D-CNN 前端網絡中的效果好于平均池化。對比16 維與64 維的SCNC 特征可知,基于32 維SCNC 特征的LSTM 前端網絡性能更好,且優于基于SCNC特征的2D-CNN前端網絡。
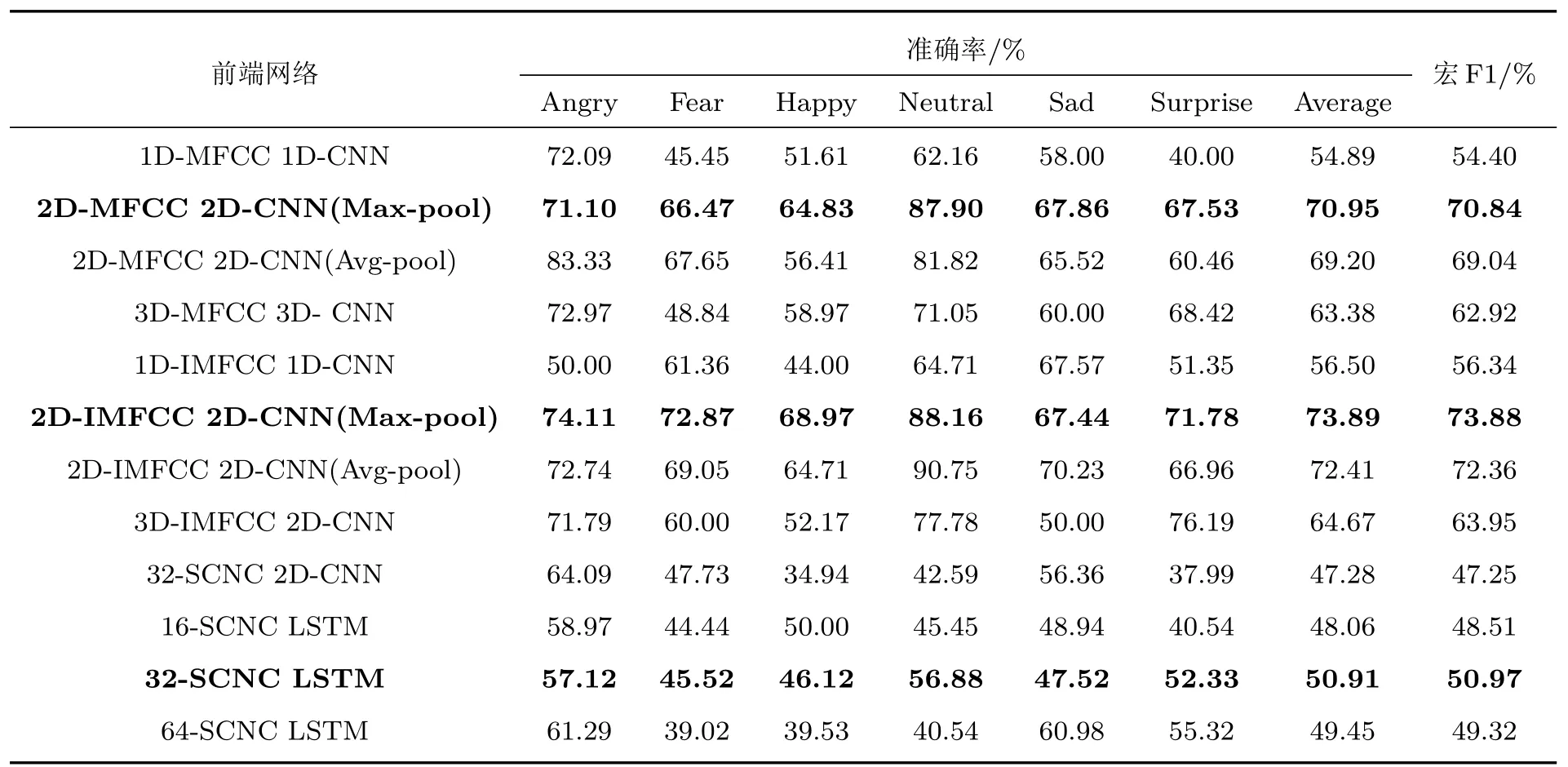
表3 三類語聲特征在不同前端網絡中的分類結果Table 3 Classification results of three SER features in different front-end networks
分析可知,對于二維MFCC 和IMFCC 特征,2D-CNN 前端網絡可有效利用特征矩陣中的頻譜能量信息進行分類。而最大池化相較于平均池化,對特征矩陣中的紋理信息更加敏感,更有利于對區分性信息的提取。對于SCNC 特征,LSTM 前端網絡能夠更好地學習序列中的時間相關性,由5 層ISCN提取的32維SCNC 特征則可較好地保留用于分類的高頻信息。
將本文所選的3 類前端網絡的分類結果表示為混淆矩陣,如圖5 所示,其中對角線數據表示網絡對每類情感的識別準確率。觀察混淆矩陣可知,3 類前端網絡對“中性(Neutral)”與“憤怒(Angry)”兩類情感的識別準確率顯著高于其余情感類別。
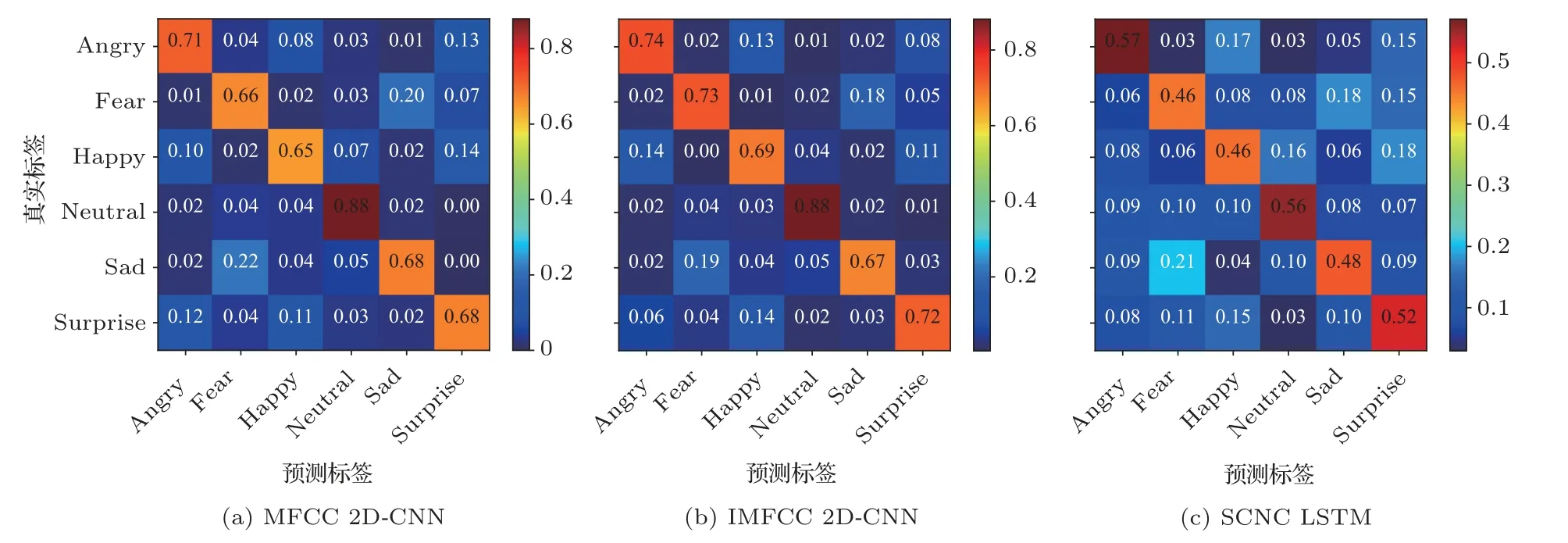
圖5 三類前端網絡的分類混淆矩陣Fig.5 Confusion matrix for three front-end networks
基于SE 通道注意力機制的網絡中間層融合方式對比前端融合方式與中間層非計權融合方式的情感分類結果如表4 所示,觀察可知,前端特征級的拼接融合或注意力機制融合相較于單一特征僅能使情感分類的平均準確率小幅提升,這證明了前端融合特征泛化能力有限,無法充分利用多種語聲特征的優勢。而基于網絡中間層進行非計權拼接融合后的準確率相較于特征級融合有了顯著提高,但其表現依舊差于采用SE 通道注意力機制的融合方式。這證明了基于網絡中間層進行的融合優于特征級的融合,也進一步驗證了基于SE 通道注意力機制進行融合的有效性。不同融合方式取得的分類混淆矩陣分別如圖6 所示,觀察可知后端分類網絡均在“中性”情感上取得了最高的識別準確率,這也證明了前端網絡在某一類情感識別中的優勢在融合后可以得到保留。
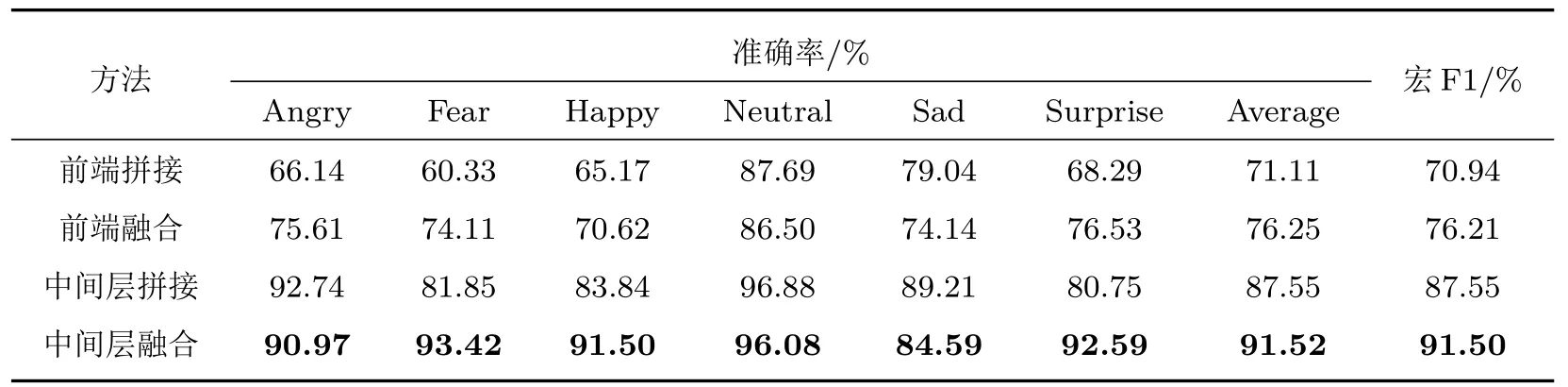
表4 不同網絡融合方式的對比實驗結果Table 4 Comparative test results of different network fusion methods
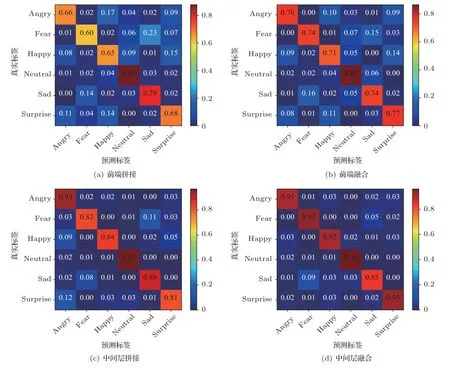
圖6 不同網絡融合方式的分類混淆矩陣Fig.6 Confusion matrix for different network fusion methods
文獻[2–3,7]中不同階段的融合方式在測試集上的平均準確率和預測耗時如表5 所示。觀察數據可知,基于隨機森林特征選擇算法的特征融合方式[2]所用預測時間最短,這也體現了傳統機器學習方法在預測效率上的優勢。基于置信度的后端決策級融合方式[7]在使用多類語聲特征獲得較高的準確率的同時耗費了最長的預測時間。而基于GMU的網絡中間層融合方式[3]對動靜態譜特征進行融合則可兼顧識別效率與準確率。本文相較于融合方式[3]在譜特征的基礎上增加了時序特征,使用SE通道注意力機制用于網絡中間層融合,平均準確率提高了5.39%,預測耗時則僅增加0.015 s。對比實驗證明了本文基于通道注意力機制的融合網絡用于SER 任務時,通過對多種語聲特征和分類網絡的有效利用,可以實現更高的平均識別準確率。
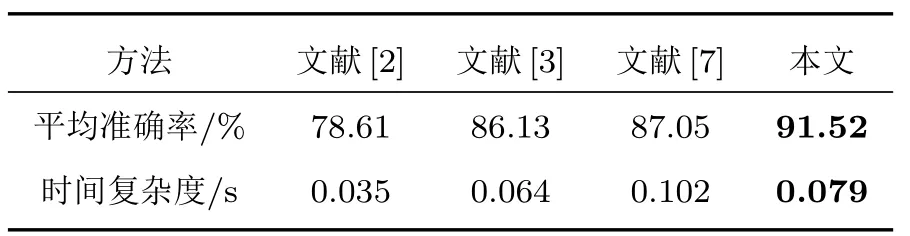
表5 融合方式的準確率與復雜度對比Table 5 Accuracy and complexity comparison
3 結論
本文把SE 通道注意力機制用于對基于譜特征的和時序特征的前端網絡的中間層融合,并進行了實驗驗證。實驗結果表明,多特征分類相較于單一特征分類在情感識別準確率上具有明顯的優勢;中間層融合的多特征融合方式優于前端特征級的融合方式;利用SE 通道注意力機制對前端網絡中間層進行融合,能有效利用不同前端網絡在SER 任務中的優勢提高情感識別準確率。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
文苑(2018年21期)2018-11-09 01:23:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
