基于分數階微分和最優光譜指數的大豆葉面積指數估算
2023-09-23 06:38:50向友珍安嘉琪唐子竣李汪洋史鴻棹
農業機械學報 2023年9期
向友珍 王 辛 安嘉琪 唐子竣 李汪洋 史鴻棹
(1.西北農林科技大學旱區農業水土工程教育部重點實驗室,陜西楊凌 712100;2.西北農林科技大學水利與建筑工程學院,陜西楊凌 712100)
0 引言
大豆是世界農產品貿易中最重要的油脂產品之一,我國的大豆消費市場廣闊,但大豆的自給率卻不到15%,其產量與品質直接影響著我國糧食安全水平[1]。大豆開花期生長狀況對于大豆后續生殖生長與最終產量形成有著重要影響[2]。單位耕地面積上作物葉片總面積與耕地面積之比[3]即為葉面積指數(Leaf area index,LAI),是一種描述植物冠層結構與生長狀況的關鍵植物生理參數[4-5]。科學高效地獲取大豆開花期LAI對開花期大豆的生長狀態評估與產量預測具有重要意義[6-7]。
采用傳統方法對LAI進行直接測定費時、費力、成本較高且具有破壞性與不可恢復性。高光譜遙感農作物生長監測技術因其光譜分辨率高、連續波段多[8]的特點,可對田間作物LAI進行實時、高效測定[9-10]。現有研究大多利用原始冠層高光譜反射率數據進行LAI反演模型構建,但直接采用原始高光譜反射率數據構建的LAI反演模型預測效果并不理想[11]。有學者引入整數階微分變換方法對原始高光譜反射率數據進行處理,在一定程度上消除了光譜數據的背景噪聲,提高了建模精度[12];但也有研究表明1階、2階乃至更高階的整數階微分變換方法忽略了光譜信息的連續性與漸變性[13],在消除背景噪聲的同時也會造成光譜特征的丟失[14]。在土壤含鹽量的反演研究中,已有學者發現相較于整數階微分變換,分數階微分變換處理得到的光譜反射率與鹽分指標具有更強的相關性[15]。作為整數階微分的數學拓展,分數階微分變換可以突出光譜信息的細微變化,增強部分較弱的光譜特征,提高光譜反射率信噪比[16]。
光譜指數是不同敏感波段的線性或非線性組合[17],與單一波段相比,根據綠色植被特有光譜特征選擇的波段構建的高光譜植被指數包含的作物生長信息更為充分[18]。在LAI預測模型構建過程中,適宜的波段組合選擇能有效提高模型精度[19],因此構建高光譜植被指數時的波段優選也是重要的研究內容[20]。傳統光譜指數多采用2個或多個固定波段進行構建,作物種類與生長環境的變化會改變作物的光譜特征,固定波段限制了光譜指數對于光譜信息的充分提取從而影響預測模型的擬合優度[21]。采用相關矩陣法在全部可用波段內篩選與大豆LAI相關性高的波段進行最優光譜指數構建,可有效解決光譜特征易受作物本身生理信息差異影響的問題,顯著促進了光譜信息的利用[22]。高光譜遙感技術對于光譜的劃分更為精細,提供了在所有可用光譜波段范圍內選擇與LAI有強相關性的波段進行最優光譜指數構建的可能。
本文以不同施氮水平與覆膜處理下的開花期大豆LAI為研究對象,對原始高光譜反射率進行0~2階分數階微分變換(步長0.5),采用相關矩陣法在350~1 830 nm波段內篩選與大豆LAI相關性最高的波段構建5組、共計25個最優光譜指數。在此基礎上采用支持向量機(Support vector machine,SVM)、隨機森林(Random forest,RF)、遺傳算法優化的BP神經網絡(BP neural network optimized by genetic algorithm,GA-BP)構建開花期大豆LAI預測模型,并討論不同微分階數與不同機器學習方法的組合對于大豆LAI預測模型精度的影響,以期為更加準確、快速地獲取開花期大豆LAI提供理論參考。
1 材料與方法
1.1 試驗區概況
兩年大豆田間試驗在西北農林科技大學旱區農業水土工程教育部重點實驗室節水灌溉試驗站試驗田(壤土)進行。試驗站坐標:108°24′E、34°20′N(見圖1),海拔524.7 m,屬于暖溫帶季風半濕潤氣候區,降雨集中分布于7—9月,多年平均降水量約580 mm,多年平均溫度約為12.9℃。

圖1 試驗小區布設示意圖
本試驗共設置了4個施氮水平:N1:30 kg/hm2、N2:60 kg/hm2、N3:90 kg/hm2、N4:120 kg/hm2,4種覆蓋處理:SM:秸稈覆蓋、FM:農膜覆蓋、SFM:秸稈+農膜覆蓋、NM無覆蓋處理。秸稈覆蓋量為6 000 kg/hm2,FM與SFM處理采用起壟覆蓋膜側播種方式,于試驗小區內起底兩條寬40 cm、高25 cm的壟,用60 cm寬的地膜覆蓋壟面,大豆播種于膜側5 cm處,行距50 cm。試驗以平作不施氮處理(CK)為對照,各處理隨機排列,兩次重復,試驗小區面積為2.5 m×6 m=15 m2,共計33個小區。試驗用緩釋氮肥(SNF)、鉀肥(K2O,30 kg/hm2)、磷肥(P2O5,30 kg/hm2)作為基肥,在播前一次性施入。試驗用大豆品種為山寧17號,分別于2021年6月17日與2022年6月9日播種,于2021年9月30日與2022年9月28日進行收獲,大豆開花期分別為:2021年7月28日—8月24日與2022年7月23日—8月20日,大豆生育期內未出現明顯病蟲害。
1.2 數據采集
于兩年試驗中大豆開花期(2021年8月5日與2022年8月10日)進行LAI的測定與光譜數據的采集,采集日天氣晴朗,光照穩定,兩年試驗共計獲得LAI與高光譜反射率樣本66組。數據如表1所示。

表1 大豆開花期LAI數據統計
1.2.1大豆冠層高光譜數據采集
分別于2021年8月5日和2022年8月10日10:40—13:00進行試驗小區大豆冠層高光譜反射率數據采集,該時段光照充足,測量光譜信息多,誤差較小。試驗用高光譜測量儀器為美國ASD(Analytical Spectral Devices)公司生產的Field Spec4型可見光/近紅外便攜式地物高光譜儀[23],儀器波段350~1 830 nm,其中,350~1 000 nm光譜分辨率為3 nm,采樣間隔為1.4 nm;1 000~1 830 nm分辨率為10 nm,采樣間隔為2 nm,儀器自動將采樣數據插值為1 nm間隔輸出,視場角25°。
在高光譜數據采集前對光譜儀進行預熱、優化處理并在1 min內完成參考板檢驗和比對,在前一試驗小區高光譜反射率數據采集結束后,后一試驗小區高光譜反射率數據采集開始前進行參考板校正。于每個試驗小區中選取長勢均衡的作物冠層,試驗人員手持光譜傳感器探頭,距作物冠層頂部75 cm垂直向下采集數據,每次共采集記錄10次高光譜反射率數據,依據“3σ”原則[24]剔除異常值后以余下光譜波段反射率的均值作為各小區最終高光譜反射率數據。
1.2.2大豆LAI數據采集
田間大豆LAI實測使用美國LI-COR LAI-2200C型植物冠層分析儀測定。在高光譜反射率數據影像采集的當天進行大豆LAI數據采集。在33個試驗小區內各隨機進行6次大豆LAI數據采集,以其均值作為各試驗小區的實測值。
1.3 光譜數據處理
本研究采用Savitzky-Golay(SG)平滑法對光譜數據進行降噪處理,采用G-L分數階微分(Fractional order differentiation,FOD)算法對高光譜反射率數據進行0~2階(步長0.5)分數階微分變換。G-L FOD算法可將傳統的整數階微分拓展為任意階微分,可以更加充分地解釋數據的細微變化與整體性信息,本試驗中高光譜反射率數據的α階微分公式為[25]
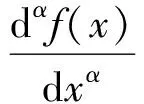
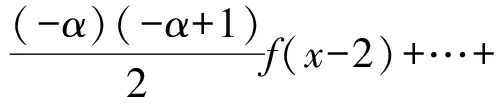

式中x——對應點的值
α——分數階微分階
Г——Gamma函數
n——微分上下限之差,階數為0,則表示未經預處理
光譜數據預處理、植被指數計算均在Matlab 2018中完成,使用Origin 2021進行圖形繪制。
1.4 光譜指數選擇與構建
選取7種光譜指數(表2):比值植被指數(Ratio index,RI)和三角植被指數(Triangular vegetation index,TVI)與植物的葉綠素含量、LAI具有強相關性,但當植被較茂密時其靈敏度會降低[23];改進紅邊比值指數(Modified red edge simple ratio,mSR)與改進紅邊歸一指數(Modified normalized difference index,mNDI)可對葉片的鏡面發射效應進行優化,對于葉片的變化較為敏感;差值植被指數(Difference index,DI)、歸一化植被指數(Normalized difference vegetation index,NDVI)和土壤調節植被指數(Soil-adjusted vegetation index,SAVI)均可反映植物冠層的背景影響并消除部分輻射誤差[26]。
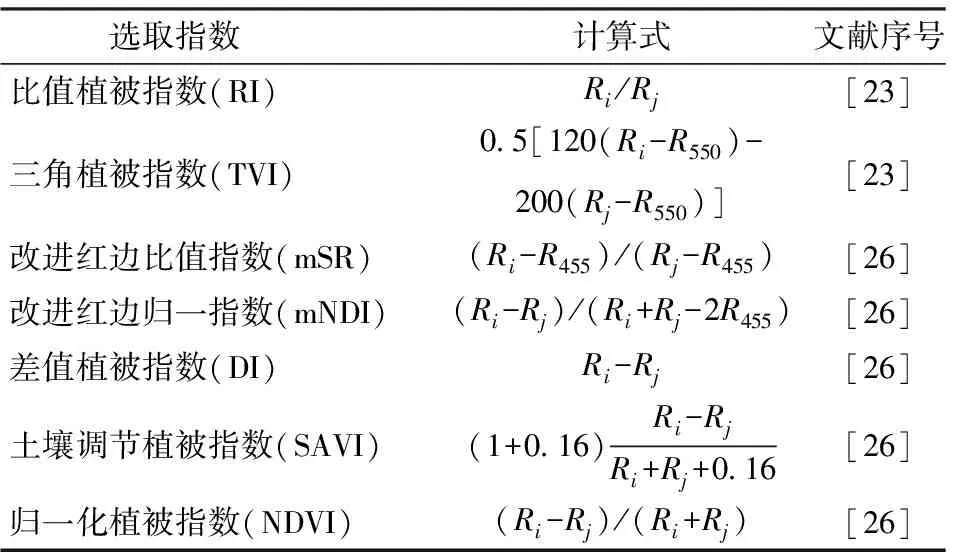
表2 研究選取光譜指數
1.5 模型構建
本研究以構建的不同階最優光譜指數組合作為輸入變量,采用SVM、RF、GA-BP共3種機器學習方法進行建模,對開花期的大豆LAI進行回歸預測,訓練集與驗證集數據比例為2∶1,機器學習模型多次預測擬合結果的平均值作為本試驗中的最終模型擬合結果。
1.5.1支持向量機
支持向量機(SVM)是一種以高斯核和多項式核作為基核函數,采用梯度下降算法進行權重系數優化的二分類機器學習算法[27],具有良好的泛化能力和魯棒性,沒有過擬合缺陷,在模式識別、分類以及小樣本回歸分析中得到了廣泛應用[28]。根據最小交叉驗證誤差的原則,本研究中SVM模型的懲罰系數C與γ分別為20與0.02。
1.5.2隨機森林
隨機森林(RF)是一種基于Bagging模型思想的積分模型。由于其簡單、方便的特點,已廣泛應用于各種回歸和預測問題中。RF模型對每棵樹的結果進行加權平均以達到最終輸出,因此該模型的實現需要構建大量的決策樹,并通過交換和改變協變量來構建一組決策樹以提高預測性能[29-30]。隨機森林需要在放回樣本得到的N個采樣訓練-測試集上訓練N棵決策樹,基于隨機森林模型的回歸,將多棵決策樹的平均預測結果作為最終結果。在決策樹模型內進行訓練-測試時,需要遍歷每個特征和每個方法以有效地確定最優決策樹數量,經過多次訓練與誤差分析,RF模型中的決策樹數量確定為100。
1.5.3遺傳算法優化的BP神經網絡
BP神經網絡(Back propagation neural network)是采用逆向傳播算法進行訓練的一種多層前饋型網絡,本質上是基于梯度下降的一種迭代學習算法,存在易陷入局部極小點、收斂速度慢、接近最優解時可能產生振蕩等缺陷[31]。
遺傳算法(Genetic algorithrn,GA)是以自然選擇和遺傳理論為基礎,將生物進化過程中適者生存原則與群體內部染色體的隨機信息交換機制相結合產生的一種全局尋優搜索算法,它不依賴梯度信息,特別適用于高度非線性、不連續等復雜系統的優化問題,廣泛應用于機器學習、人工神經網絡訓練、模式識別等復雜優化問題[32-33]。遺傳算法可對BP神經網絡的初始權值進行優化,替代梯度下降調節網絡權值和閾值的過程,解決BP算法由于梯度下降引起的難題。本研究采用遺傳算法對BP神經網絡進行優化,遺傳算法的初始種群數量為5,遺傳代數設為50,交叉概率為0.4%,變異概率為0.05%;種群經優化后BP神經網絡輸入層節點個數為5,隱含層節點個數為5,輸出層節點個數為1,最大迭代次數為1 000,訓練目標為1×10-6。
1.6 模型精度驗證
(1)模型評價指標
模型擬合結果采用決定系數(R2)、均方根誤差(RMSE)、標準均方根誤差(NRMSE)與平均相對誤差(MRE)進行評價[34-35],R2越接近1,說明模型的預測精度越高;RMSE與MRE越小,說明模型的性能更穩定,預測結果也更為集中,NRMSE小于10%時,模型的預測值與實測值的一致性表現為極好;NRMSE為10%~20%時,模型的預測值與實測值的一致性表現為較好;NRMSE為20%~30%時,模型的預測值與實測值的一致性表現為一般;NRMSE大于30%時,模型的預測值與實測值的一致性表現為較差。
(2)顯著性檢驗
參考自相關性系數檢驗表,當自由度(即樣本量)為66,相關系數大于0.310,達到極顯著相關水平(P<0.01);當自由度為44,相關系數大于0.376,達到極顯著相關水平(P<0.01);當自由度為22時,相關系數大于0.515,達到極顯著相關水平(P<0.01)。
2 結果與分析
2.1 0~2階微分光譜曲線
本研究采用FOD算法對原始高光譜反射率數據進行0~2階(步長0.5)分數階微分變換處理,圖2為平均后的各階高光譜反射率曲線。大豆原始高光譜反射率曲線呈現出典型的綠色植物反射特征,在綠光波段550 nm左右有1個明顯的反射峰,這是因為植物對于綠光具有較強的反射作用;由于植物對紅光的強吸收性,反射率曲線在紅光波段680 nm左右出現了1個吸收谷;在波段 680~760 nm 光譜反射率急增,出現一段反射陡坡,形成了綠色植被特有的光譜特征——紅邊。由于植被含水率的影響,1 300~1 830 nm光譜反射率快速下降,1 400 nm 左右出現了水汽波段的吸收峰。分數階微分處理可降低光譜反射率噪聲,突出反射率曲線中的細微變化,并保留植物的光譜特征,隨著微分階數增加,各波段對應的光譜反射率漸趨于0,標準差也逐漸減小,紅邊特征波段在各階反射率曲線中均具有較高的反射率。

圖2 0~2階微分光譜反射率曲線
2.2 光譜指數構建與最優光譜指數波段組合提取
為更充分地利用高光譜反射率數據所含信息,選取了7個典型光譜指數。首先對0~2階分數階微分處理后的高光譜反射率的所有波段進行逐波段光譜指數計算,再通過相關矩陣法與大豆LAI進行相關性分析,以最大相關系數所在的i和j波長進行不同階光譜指數構建,并在7個光譜指數中選取與大豆LAI相關性最高的5個指數作為最優光譜指數組合。繪制相關性矩陣圖,如圖3~6所示,從藍到紅表示光譜指數與大豆LAI的相關性由高負相關到高正相關。

圖5 0~2階微分下NDVI、mSR與開花期大豆LAI相關矩陣圖

圖6 0~2階微分下mNDI與開花期大豆LAI相關矩陣圖
圖3~6為經分數階微分處理,0~2階分數階微分高光譜植被指數與大豆LAI的相關矩陣圖,各階光譜指數大豆LAI的相關系數均大于0.310(P≤0.01),達到極顯著相關水平,說明本研究選取的7個光譜指數均可用于預測開花期大豆LAI。0~2 階光譜指數與大豆LAI相關系數的平均值分別0.616、0.657、0.666、0.669、0.658,分數階微分處理后計算得出的最優光譜指數與大豆LAI的相關性與原始光譜指數相比得到顯著提高。1.5階微分處理下,與大豆LAI相關系數最高的是TVI,相關系數為0.755,波長組合坐標為(687 nm,754 nm),各光譜指數與大豆LAI的相關系數由高到低排列為:
TVI、DI、SAVI、RI、NDVI、mNDI、mSR。在上述7個光譜指數中選取5個相關系數最高的光譜指數TVI、DI、SAVI、RI、NDVI作為最優光譜指數組合,其對應波段組合:(687 nm,754 nm)、(687 nm,754 nm)、(728 nm,738 nm)、(687 nm,744 nm)、(620 nm,653 nm)為最優光譜指數波段組合。其余分數階微分最優光譜指數組合與最優光譜指數組合對應波段見表3。

表3 不同微分階數下的最優光譜指數波長組合
2.3 大豆LAI預測模型構建與比較
以提取出的各階最優光譜指數組合作為自變量,以大豆LAI作為響應變量,分別采用SVM、RF、GA-BP構建大豆開花結莢期LAI估算模型,從R2、RMSE、MRE 3方面綜合評定模型精度,不同建模方法對于大豆葉面積的預測結果如表4、圖7所示。

圖7 模型評價結果
結果表明:不同階微分變換處理下大豆LAI估算模型R2從大到小依次為1.5階、2階、1階、0.5階、0階;RMSE、NRMSE與MRE從小到大均依次為:1.5階、2階、1階、0.5階、0階。1.5階微分光譜指數構建的SVM、RF、GA-BP大豆LAI預測模型的驗證集R2分別為:0.776、0.880、0.846,均高于0.515,達到極顯著相關水平,具有良好的線性擬合效果;NRMSE介于10%~20%之間,3種模型的預測值與實測值之間的一致性呈較好水平。同階微分變換處理下,3種建模方法構建的大豆LAI估算模型的建模集與驗證集精度從大到小依次為RF、GA-BP、SVM。各階微分處理下,基于RF構建的大豆LAI預測模型驗證集R2較SVM與GA-BP提高0.047~0.133;NRMSE與MRE分別降低0.704~8.042個百分點與0.781~7.35個百分點。綜上所述,1.5階微分處理與RF方法分別為本研究中的最優微分階數與最優模型構建方法,由此構建的最優大豆LAI估算模型建模集與驗證集的R2為0.890與0.880,RMSE分別為0.348 cm2/cm2與0.320 cm2/cm2,NRMSE分別為11.278%與10.354%,MRE分別為9.795%與9.572%。
3 討論
目前,在利用高光譜反射率數據進行LAI反演模型構建的研究中發現直接運用原始高光譜反射率對于作物LAI進行反演模型構建得到的模型精度往往較差[36]。引入微分變換處理,可以削弱光譜反射率背景噪聲,突出高光譜特征信息,增強高光譜反射率與作物LAI間的相關性進而促進反演模型精度的提升[37-38]。本研究對高光譜反射率數據進行0~2階分數階微分處理(步長0.5)構建大豆LAI反演模型,隨著微分階數的提高,光譜指數與大豆LAI的相關性與模型精度均呈現出先升后降的趨勢,1.5階微分下最優光譜指數與大豆LAI相關性及其構建的預測模型精度均高于1階與2階整數微分。這是因為分數階微分是高光譜反射率整數階微分變換的拓展與延伸,可以提取整數階微分無法表征的漸變性信息[39]。但是隨著微分階數提高,背景噪聲被逐漸削弱,高頻噪聲會被逐漸放大,也減少了反射率數據中的潛在敏感信息,導致了光譜信息信噪比的降低,繼而影響模型精度[40]。本研究發現在全波段范圍內篩選波段構建的最優光譜指數包含了更多與大豆LAI相關的有效信息,且構建的25個0~2階最優光譜指數中的23個指數所對應的波段分布在紅邊或近紅外波段。葉綠素對紅光波段的強吸收和近紅外波段在葉片內部發生的強反射使得紅邊波段成為綠色植物反射率增長最快速也是最能反映植物生長生理特征的重要指示波段,80%以上的植物理化參數都可以從紅邊波段所包含的光譜信息中找到映射[41-42]。分數階微分處理在過濾背景噪聲的同時,也保留了紅邊波段對于植物理化參數的描述能力,因此本研究中各階微分處理下篩選出的與大豆LAI呈極顯著相關關系的波段組合多分布于680~760 nm范圍內,與前人研究結果相符[43]。
本研究以選出的各階最優光譜指數組合作為輸入數據,選用SVM、RF、GA-BP共3種機器學習方法進行LAI預測模型的構建。3種方法中,基于RF方法構建的LAI預測模型精度最高,說明RF提取光譜反射率數據中LAI相關信息的能力更強,這是因為RF算法具有較強的抗干擾與抗過擬合能力,對背景噪聲與異常值的容忍性也更高,更適合解決一些非線性問題[44],陳曉凱等[45]對冬小麥LAI進行反演時也得到了相同的結果。BP神經網絡是一種按誤差逆傳播算法訓練的監督式學習方法,也是當前應用最廣泛的非線性多層前饋網絡模型之一,但神經網絡模型精度也因容易陷入局部極值且收斂速度較慢的缺點[46]受到了限制。遺傳算法可對BP人工神經網絡的初始權值和閾值進行優化,提高網絡的收斂速度與識別精度[47]。本研究中GA-BP模型精度低于RF,可能是因為樣本相對較少但模型訓練次數較高,導致了模型精度與泛化能力的降低[48]。與RF和GA-BP相比,SVM模型對于LAI的預測效果較差,推測是因為SVM抗干擾性較弱且受到核函數與懲罰因子等參數選擇的限制[49]。
當前,利用高光譜數據對作物的LAI、生物量、氮素、葉綠素的模型研究取得了很好的效果,但常用的地面高光譜數據一般只能在地面進行獲取,受限制條件較多。本研究結果表明以1.5階最優光譜指數組合作為輸入變量,采用RF構建LAI預測模型可以得出最佳的擬合精度,今后需要通過不同地區、不同尺度和不同品種類型的試驗對模型進行檢驗和改進,實現模型估測精確性和普適性的有效統一,為使用多光譜和無人機高光譜等多源遙感手段預測多生育期大豆LAI與進一步探索高光譜反射率分數階微分變換提供參考。
4 結論
(1)與原始高光譜反射率數據相比,分數階微分變換后提取出的各階最優光譜指數與大豆LAI的相關性得到顯著提高,1.5階處理下各光譜指數與大豆LAI相關系數的平均值較原始光譜指數提高0.053,其中TVI(687 nm,754 nm)表現出最高的相關性,相關系數為0.755。
(2)當建模方法相同,輸入變量不同時,大豆LAI預測模型的精度從大到小依次為:1.5階、2階、1階、0.5階、原始階位;當輸入變量相同,建模方法變化時,大豆LAI預測模型的精度從大到小依次為:RF、GA-BP、SVM。綜合比較模型的評價指標可知1.5階微分與RF方法分別為本研究中的最優微分階數與最優模型構建方法,由此構建的最優大豆LAI估算模型建模集與驗證集的R2分別為0.890與0.880,RMSE分別為0.348 cm2/cm2與0.320 cm2/cm2,NRMSE分別為11.278%與10.354%,MRE分別為9.795%與9.572%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2022年16期)2022-11-09 23:18:44
中國化肥信息(2022年5期)2022-08-30 01:58:26
今日農業(2021年20期)2021-11-26 01:23:56
今日農業(2021年14期)2021-10-14 08:35:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
下一代英才(酷炫少年)(2018年6期)2018-07-09 03:17:44
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
