基于數據挖掘與機器學習技術的低滲儲層產量預測
2023-09-23 11:01:48廖璐璐李根生曾義金宋先知高啟超周珺
長江大學學報(自科版) 2023年5期
廖璐璐,李根生,曾義金,宋先知,高啟超,周珺
1.中國石油大學(北京)石油工程學院,北京 102249
2.中國石化石油工程技術研究院有限公司,北京 102206
低滲儲層是非常規油氣儲層的重要組成部分,其在全球石油天然氣供應中的地位日益凸顯。隨著我國油氣能源需求的不斷增加,提升儲量潛力巨大的低滲儲層產量對于保障我國經濟發展和能源安全保障至關重要。然而,低滲儲層的區域延展性大、油氣生產效率低,以及鉆井和儲層改造作業頻繁等特點使得多年在常規油氣藏生產作業中所總結出的知識體系與開發方式不能很好的應用于此。另一方面,我國石油公司在海外新區的勘探開發過程中缺乏實踐經驗。因此,借助以大數據和機器學習為代表的AI技術將是快速掌握儲層數據信息、提升認知水平、高效制定工程措施,并實現致密儲層降本增效開發的重要契機。
油氣田的生產預測至關重要,需要包括地質學家、油藏工程師、采油師和鉆完井工程師等多個石油領域專家們的分工合作。好的生產預測需要專業、高效和緊密的團隊合作,每個領域的專家在一個項目的分析預測過程中不僅各有分工,且存在時間上的先后順序。針對油氣藏產量預測,前人進行了多方面的探索并得到了許多切實可行的方法,比如通過遞減分析和典型曲線分析方法[1];利用二元非線性或多元線性回歸出經驗公式[2];或者使用計算科學技術進行綜合油藏數值模擬[3]。區別于常規油氣藏,低滲油氣藏開發的成功與工程優化和合同期內的高效開發更加息息相關。因此,一個快速有效的、綜合了地理/油藏/工程參數的產量預測模型非常關鍵。
隨著數據量的爆炸式增長、計算資源的日益豐富以及數學算法的不斷改善,以數據驅動、機器學習技術等為代表的現代數據科學為傳統石油與天然氣行業提供了技術變革的可能性。許多國家(國際石油公司)都在此投入了大量的精力,希望發現新技術可以提高、改善甚至取代傳統的工業工藝流程。非常規頁巖儲層開發中產生的大量生產、物性和工程參數為數據挖掘的應用提供了可能性[4]。加拿大非常規油氣藏資源豐富、布井密度高,可以提供充足的機器學習樣本。一些經典的方法如利用基于圖形辨識的人工神經網絡方法預測獨立變量的變化值大小[5-7];利用基于因變量與多元自變量的多元線性回歸方法預測產能[8-12];利用變量結構回歸(非線性)方法自動識別模型結構等[13-14];利用支持向量機(SVM)預測巖石物性和提高油藏組分模型的運行效率[15-16];基于隨機變量自由組合等原理,利用隨機森林(RF)回歸方法和梯度提升機方法(XGboost)通過疊加效果較差的初始預測模型最終建立集合優化模型等[17-19]。
基于此,筆者提出了利用大數據挖掘和機器學習技術來解決中石化海外作業者項目中產量的快速預測和工程參數的綜合評估問題。該研究收集了來自加拿大Cardium致密儲層-Pembina油田的1 200多口油井數據:利用敏感性測試確定了與產量相關的主控因素,在該基礎上建立多維數據庫,并為之后的機器學習模型建立打下基礎。根據敏感性分析結果,篩選出10種與Cardium低滲儲層累計產量最為相關的影響參數。通過測試基于不同機器學習技術的預測模型,隨機森林算法以其最低誤差值、穩定的輸出和優異的預測精度脫穎而出。這種以機器學習技術為基礎創建的預測流程在時效性和準確度上均具備優勢(精度可達85%),可以為現場壓裂施工設計優化提供可靠的保障。
1 預測流程
流程分為4個步驟:①針對研究目標區域建立包含樣本、協變量和標簽值的數據集合;②利用皮爾遜相關系數找尋主控因素和標簽函數的關鍵節點時間;③建立多種機器學習模型,如梯度提升機(XGboost)、隨機森林(RF)、支持向量(SVM)和神經網絡等,并計算預測模型精度;④利用k-Fold交叉驗證方法進一步提升優選機器學習模型的預測精度,如圖1所示。

圖1 基于數據挖掘與機器學習技術的低滲儲層產量預測流程
2 案例概述和數據庫
以加拿大阿爾伯塔省的Cardium致密儲層為研究案例。Cardium致密儲層向東延伸至阿爾伯塔省邊界以東約200 km處。厚度從位于西部邊界150 m到平原地區的不足50 m不等。Cardium致密儲層深度從1 200~2 700 m不等。研究目標位于Range 09-13 &Township45-49區塊,寬約50 km,長50 km,平均儲層厚度10~20 m。根據預測方法步驟①,將研究區域內的1 286口井經過一系列除雜、清洗和篩選,得到可用的數據樣本井為612個,每個樣本中包含50種協變量(井位/巖性/工程參數)與5組標簽值(3、6、9、12、18和36個月累計產量)。
2.1 主控因素排名
根據預測方法步驟②篩選了10種與標簽值相關系數最高的協變量:分別是井位坐標、資源密度、垂直深度、水平井段長度、總壓裂段級數、總泵入支撐劑量、單位泵入液量、加砂濃度、排量和有無泥隔層;相較于前人研究的標簽參數僅局限在一個固定值上,選取了不同時間節點上的5個累計產量值,由此發現10個主控因素中的6種鉆完井工程參數的相關系數存在拐點,即存在時間軸上的系數相關最大值。以水平井長度段為例,如圖2(a)所示,不同時間節點上的累計產量值與其相關系數略有不同,計算值在12個月累計產量的分析中達到峰值,其他幾個工程參數表現出相類似的特點,如圖2(b)所示,判斷“到底利用哪個時間節點為最終標簽值”做好了數學理論基礎依據。
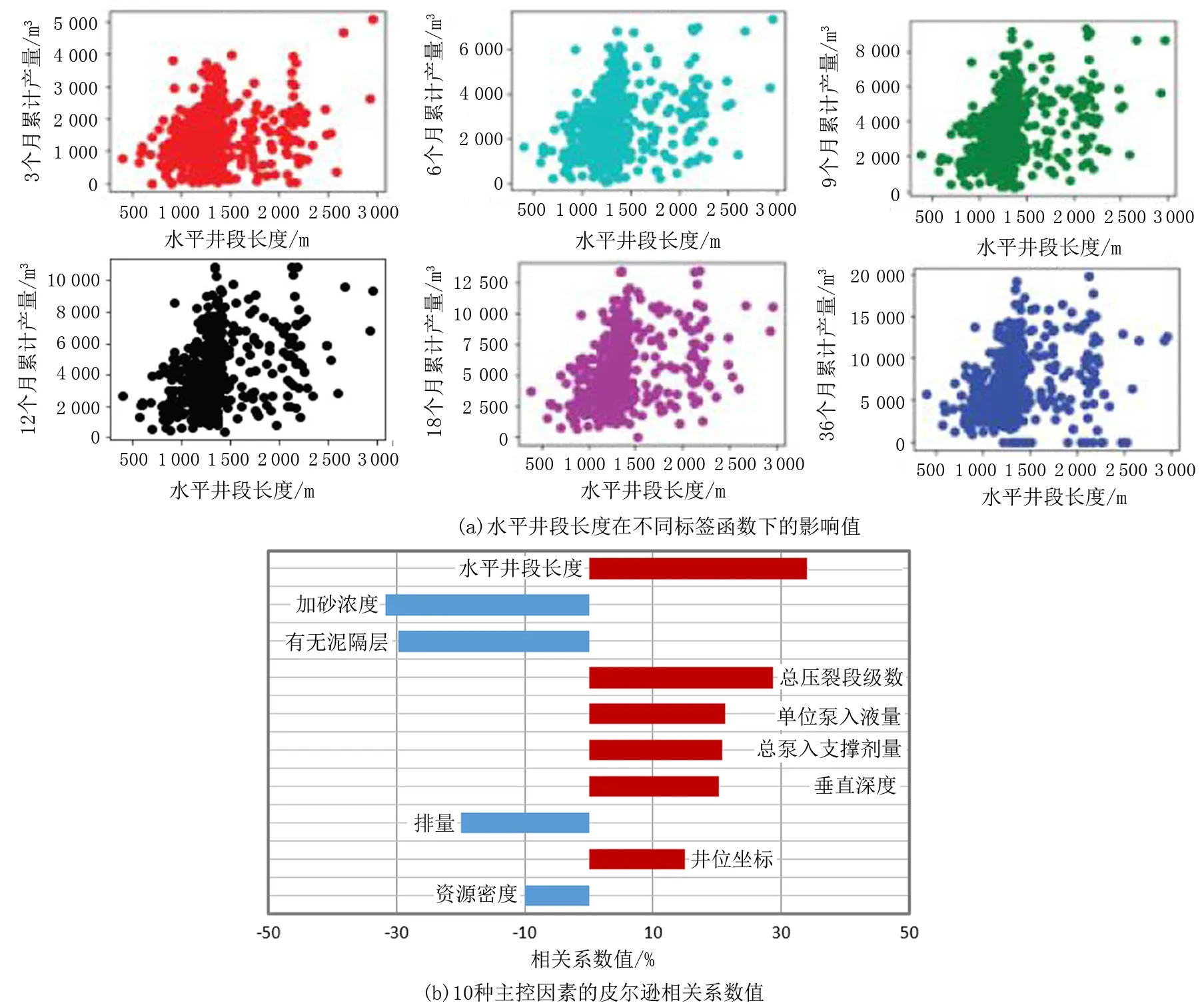
圖2 主控因素篩選
2.2 優選算法
嘗試了多種機器學習模型,結果表明隨機森林算法在同等條件下所得到的誤差值最低,擁有最好的表現。圖3(a)為決策樹的邏輯表達,圖3(b)為隨機森林的邏輯表達。
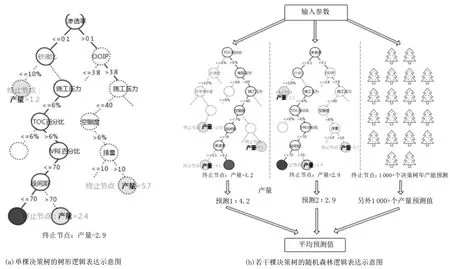
圖3 算法優選
前文提到的運算條件指的是數據庫總樣本量、訓練集/測試集比例、協變量值、標簽值和驗證方法等,如表1所示,該模型建立涉及到的總數據量為3萬多個,協變量包括27個工程參數與23個非工程參數,標簽值的最終選擇為12個月累計產量,驗證方法為10-Fold交叉驗證方法,最終的預測精度到達85%以上。對比不同的運算條件可以看出:①總樣本數量的增加可以顯著減低誤差率;②訓練集/測試集比例控制在80∶20~90∶10的區間比較合適,比例過大或過小可能造成過擬合和欠擬合;③協變量數量一定的情況下,標簽值選擇累計產量為12個月的預測誤差值越低,這也與之前皮爾遜相關系數的分析相一致;④k-Fold交叉驗證方法可以提高預測精度和穩定性。
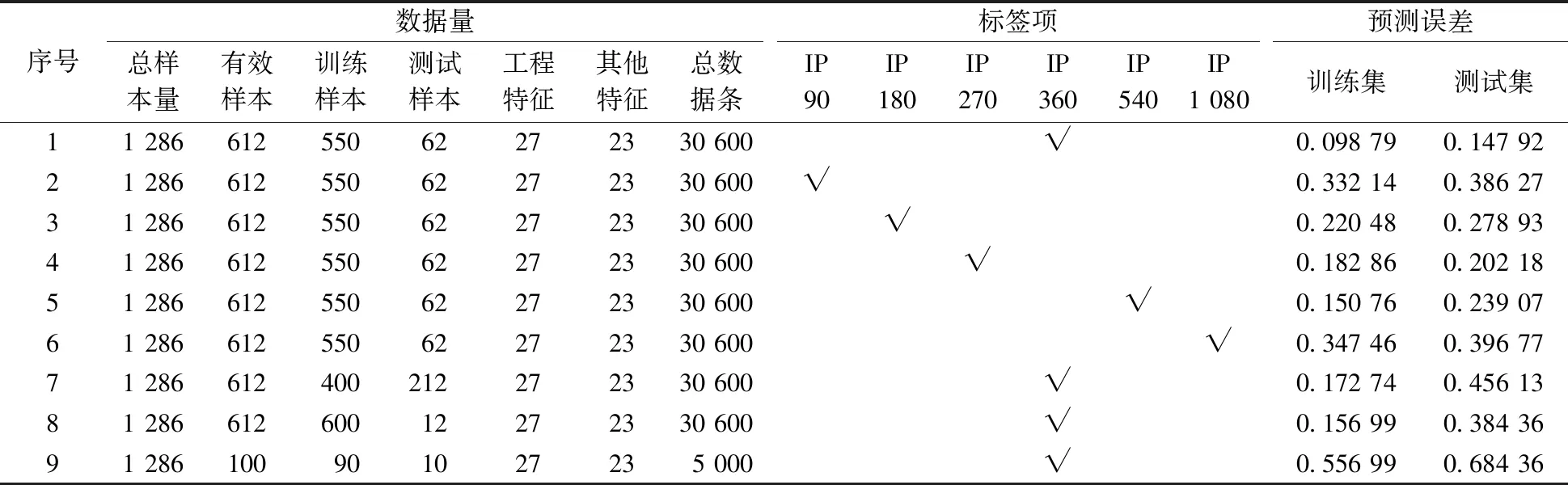
表1 隨機森林結果展示
2.3 現場施工參數優化
在油藏地質相似的情況下,認為優選6個工程主控因素將會對Cardium致密儲層開發產生積極的作用,研究的最后一項內容則圍繞著如何利用數據挖掘解決工程參數優化問題。首先對全區的620口井進行了分類:類Ⅰ為RT-全區,包含全部井的樣本(地質油藏條件良莠不齊,水力壓裂技術方案多樣);類Ⅱ為RT-對比區(該處地質油藏條件較差,未采用改良水力壓裂技術);類Ⅲ為RT-西南角(該處地質油藏條件最差,但采用了改良的水力壓裂技術),并對此3類的3個月、6個月、9個月、12個月和36個月的平均累計產量進行了對比。需要注意的是類Ⅱ為未來布井的研究區域,分區和具體產值如表2所示。
對比類Ⅰ與類Ⅱ可以看出,在12個月前,RT-西南角的水平井的產量表現更為優異。在地質油藏條件更差的前提下,說明了類Ⅱ儲層改造的效果很好,12個月后,地質油藏因素與產量的相關性增強,產量開始更多的受到儲層本身性質的影響。12個月產量兩類產值持平,而到36個月時全區平均累計產量比西南角僅高出了500 m3左右。另外,12個月這個轉折節點也與之前皮爾遜相關系數值的拐點相一致,相互印證。
對比類Ⅰ與類Ⅱ說明,RT-西南角相較于油藏地質同等或稍好的RT-對比區有更高的平均累計產量,并且一直領先。從3個月到36個月累計產量,差值分別為338.02、655.67、822.40、909.42和1 258.18 m3,增速逐漸變緩。綜上所述,對比研究的儲層改造工藝有很大提高和優化的空間,36個月產值提高可達到25%以上,如圖4所示。

圖4 RT全區、RT-對比區和RT-西南區在不同 時間上的平均產值對比
研究相應總結與歸納了該6項工程主控參數在類Ⅰ、類Ⅱ和類Ⅲ的數學統計值。以尋求產量差異的工程因素差別,在不同的分區下,施工數據存在個性差別,可以通過對比區(需改進區域)與西南角的工程參數的統計值的對比,為對比區的新井鉆完井工程參數設計提供參考意見。水平井段長度方面,類Ⅱ的平均值為1 158.0 m,比類Ⅰ和類Ⅲ的均值小15%~16%,并且全區范圍內的長度最小值出現在類Ⅱ,最大值出現在類Ⅲ;壓裂級數方面,類Ⅱ的平均值為18.5級,比類Ⅰ和類Ⅲ的均值小5%~12%,并且全區范圍內的長度最小值出現在類Ⅱ,最大值出現在類Ⅲ;每米加砂量方面,類Ⅱ的平均值為361.3 kg/m,比類Ⅰ和類Ⅲ的均值高13%~7%,對比各項統計結果為3種類型中的最高值;每米加液量方面,類Ⅱ的平均值為3.6 m3/m,與類Ⅰ持平,比類Ⅲ高出19%;加砂質量濃度方面,類Ⅱ的平均值為481.0 kg/m3,與類Ⅰ持平,比類Ⅲ高出18%;排量方面,類Ⅱ的平均值為7.8 m3/min,與類Ⅰ和類Ⅲ幾乎持平(見表3)。
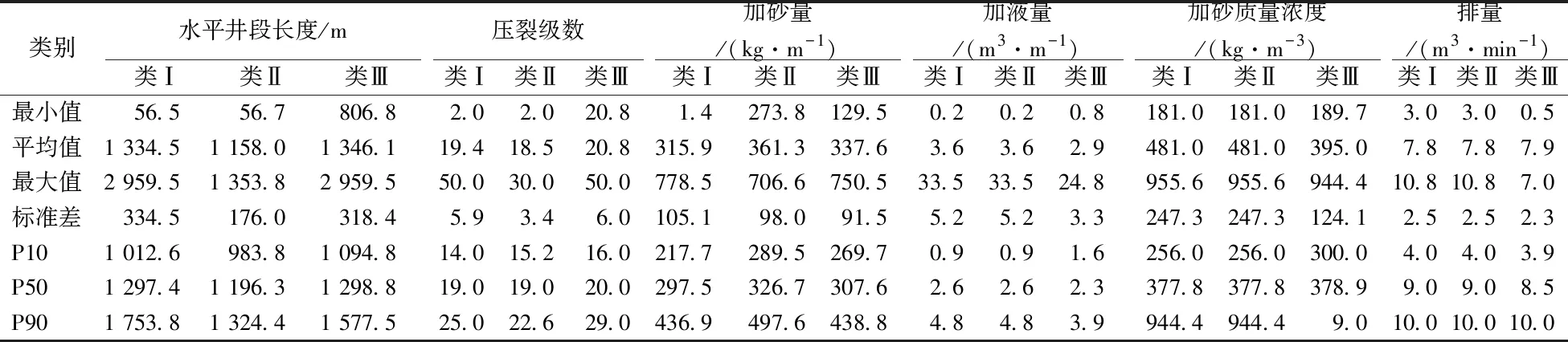
表3 Cardium致密儲層水平井-關鍵完井參數統計表
最終依據皮爾遜相關系數、累計產量對比和不同工程參數的統計情況,基于宏觀統計提出對比區域新井的施工改進方案:在原有的基礎上將水平井段增加15%~20%;壓裂級數相應增加10%~15%,即在原有的段間距基礎上保持不變甚至略微加大;每米加砂量和每米加液量保持不變或略微減少;加砂質量濃度在原有基礎上減少10%~15%;排量在原有基礎上減少5%~10%。采用該改良工程施工方案,并通過本文提到的優化隨機森林方法可以預測對比區的12個月或36個月累計產量,結果相較于研究區域的歷史平均產量提高15%~20%。考慮到壓裂技術水平井段長度、級數和壓裂規模等費用的增加,初步計算了基于數據挖掘和機器學習技術改良鉆完井參數后的單井創收值,如表4所示。36個月累計提高產量為7185.85桶,考慮桶油操作成本為9.8美元/桶,36個月累計創收43.12萬美元,年增收利潤約為5.5萬美金/井。

表4 Cardium致密儲層水平井-采用優化鉆完井參數后的年創收效益
3 結論
從大數據的角度出發,在Cardium致密儲層建立了地理/物性/工程與生產數據的機器學習模型。完成了該儲層600多口水平井的單因素敏感分析,篩選了主控因素,建立并優選了機器學習預測模型,優化后的精度可以達到85%以上。該研究為Cardium致密儲層提供了一套切實可行的集數據庫建立、主控因素篩選和機器學習方法建立優化等一體的產量預測方法,進而可以更加快速合理地評估儲層和降低開發成本。
1)利用皮爾遜相關性分析,在50種協變量中甄選了10個主控因素,分別是井位坐標、資源密度、垂直深度、水平井段長度、總壓裂段級數、總泵入支撐劑量、單位泵入液量、加砂濃度、排量和有無泥隔層。參數不僅僅局限在一個固定值上,而是找到了不同時間節點上的5個累計生產產量值,并利用相關值的拐點找到時間軸上的系數最相關值。
2)眾多模型中隨機森林的預測模型具有最低的誤差值,預測精度可以達到85%以上。中小型數據庫中可以利用k-Fold交叉驗證方法來提升模型預測精度和預測穩定性。
3)訓練集/測試集比例控制在80∶20~90∶10的區間比較合適,比例過大或過小可能造成過擬合和欠擬合,另外,通過降低葉子節點維數也可以解決過度擬合的問題。
4)結合皮爾遜相關性研究,Cardium致密儲層前12個月累計產量與工程參數更相關,而之后則逐漸受到地質油藏條件的影響。西南角在相同甚至更差的地質油藏情況下,仍然可以通過增加水平井段長度、每米加砂量、每米加液量和減少加砂質量濃度來提高產量。預計在目標區域,通過基于數據挖掘與機器學期技術優化后的鉆完井參數將為目標區域創造5~6萬美元/井的增收效益。
猜你喜歡
礦山安全信息(2022年40期)2022-04-07 02:16:52
當代水產(2021年10期)2021-12-05 16:31:48
大眾投資指南(2021年35期)2021-02-16 01:06:26
今日農業(2020年20期)2020-11-26 06:09:10
聚氯乙烯(2018年9期)2018-02-18 01:11:34
電力與能源(2017年6期)2017-05-14 06:19:37
太空探索(2016年6期)2016-07-10 12:09:06
信息通信技術(2015年6期)2015-12-26 01:16:46
筑路機械與施工機械化(2015年11期)2015-07-01 16:28:43
筑路機械與施工機械化(2015年8期)2015-01-11 09:24:54
