基于PON 接入系統的網絡質差分析方法的研究
2023-10-05 08:10:48鄭航飛張顯峰周成龍
電子設計工程 2023年19期
鄭航飛,張顯峰,周成龍
(1.武漢郵電科學研究院,湖北武漢 430073;2.烽火通信科技股份有限公司,湖北武漢 430073)
隨著通信技術的發展,網絡已經自然而深刻地融入人類的日常生活和工作。人們希望借助于網絡,隨時隨地通過語音、圖像以及視頻等多種方式進行靈活通信。隨著網絡的普及性越來越高,網絡的用戶群體也在逐漸擴大,這些用戶群體對網絡使用過程中的滿意度是很重要的。因此對網絡中的數據流量進行分析也成了至關重要的一個環節。
傳統的網絡流量分類都是通過傳輸層的端口號進行區分不同的業務,但是隨著網絡的不斷發展,網絡中的業務急速增長,傳統的網絡流量分類已經滿足不了移動互聯網中大量業務的解析,進而有了深度報文檢測技術,這種技術能夠更深層次地對報文進行解析,從而能夠更精確地對網絡中的數據流量進行識別分類。但是,深度報文分析能做到的只是對網絡流量進行識別,無法對識別到的數據流量進行分析計算。
該文基于PON 接入系統,提出了一種網絡質差分析方法,該方法與傳統報文檢測方法不同的是,在網絡流量經過OLT(光線路終端)時,對現網中的網絡流量進行動態分析,通過特征庫將網絡中的流量分為視頻流量、線上辦公流量、游戲流量、在線教育流量等,進一步對這些數據流量進行計算,從而精確地得出相關的網絡問題[1-4]。
1 架構設計
質差分析方法架構圖如圖1 所示,系統部署在OLT 上,用戶上網的網絡流量會經過OLT 的主控盤交換芯片的鏡像功能進行鏡像,將所有的網絡流量鏡像到網絡資源板卡。

圖1 質差分析方法架構設計圖
在網絡質差分析設備的底層收包,采用了DPDK(Data Plane Development Kit)架構,DPDK 的主要職責是管理網卡,將網卡收到的數據包進行處理。在傳統的網絡協議棧中,網絡報文會通過網卡接收和發送,傳統的報文接收發送都需要向CPU 發送中斷,而且每次中斷都需要保存、恢復處理器狀態,同時運行中斷程序,這樣的操作會消耗大量的時間,對于這樣數據量大、高性能的方法,處理速度將會成為整個方法的性能瓶頸。因此,在底層收包的處理上選用了DPDK,其采用輪詢模式驅動的方式直接操作網卡的接收和發送隊列,將報文直接拷貝到用戶內存空間[5-9]。
在DPDK 收包處理之后,原始的數據報文會進入到網絡流量質差分析方法中進行深度報文分析以及相關網絡指標的計算,在程序運行的過程中,會將計算的結果上報到主控盤的CPU,然后輸出計算的結果。
2 方法模塊
方法模塊圖如圖2 所示,首先在現網中獲取到一些應用的域名,然后將這些域名手動配置進特征庫,在DPDK 做了收包處理以后,首先會結合配置的特征庫對該數據流進行識別,在將數據流進行了初步識別之后,將收到的數據包進行深度報文解析,根據不同報文的端口、標識號不同等特點,進行不同的解析。解析部分分為DNS 報文解析以及MAC 地址同步。在將數據報文深度解析得到需要的數據之后,就進入到最重要的網絡KPI計算部分,該部分用到了一些現階段比較優秀的算法,根據特征庫配置的應用來進行計算[10-11],然后將分析計算出來的數據存放在共享內存中,最后將計算結果上報到主控盤。
2.1 報文解析
2.1.1 MAC地址同步
整個網絡流量分析方法部署在OLT,OLT 的主控盤會定時向網絡流量分析資源板卡發送MAC 地址同步報文,這種報文采用的是UDP 報文格式。在OLT 上進行組包時,只打包了OLT 下所掛的ONU(光網絡單元)的基本信息,如OLT 的IP 地址,ONU 的MAC地址,所屬的OLT編號、槽位號以及VLAN號等。
在DPDK 收包處理以后,報文解析模塊會收到原始報文,在經過深度報文分析,可以解析獲得OLT封裝在報文中的ONU 信息。
2.1.2 DNS解析
DNS 解析是很重要的一個部分,在這個部分,DNS 解析模塊同樣能收到網絡中的原始報文,在這個模塊會根據DNS 報文的特點,逐層解包。根據數據報文的格式,在收到報文后,先將報文中的以太頭剝離,獲取到數據報文中的源Mac 地址和目的Mac地址,同時還將獲取數據包的類型。DNS 數據報文屬于UDP 數據報文的一種,因此在進行DNS 解析時,會優先過濾掉其他類型的報文,提高后續的處理效率。
在經過多次剝離報文后,DNS 數據報文中攜帶的DNS 信息會暴露出來,然后將報文中的數據解析出來。主要需要獲取的指標有該DNS 交互的ONU的MAC 地址、域名、IP 地址列表以及響應時間。在獲取到ONU 的MAC 地址后,根據上述的MAC 地址同步獲取到ONU 信息,并更新DNS 信息,將DNS 信息與對應的ONU 信息綁定。完成了DNS 解析后,將解析所獲取的IP 地址列表回填到特征庫。
2.2 流處理
與傳統的深度報文檢測不同的是流處理,對網絡指標進行計算。流處理階段將計算現網中的用戶在對不同的應用進行訪問時,所產生的不同的丟包、時延、抖動等指標。
在這個模塊中,根據不同的協議類型在網絡中傳輸的特點,分別計算丟包、時延、抖動。在收到數據報文以后,會初步將報文分為TCP、UDP、ICMP 三種報文。在分包處理時,由于TCP 傳輸會進行三次握手,并且有報文順序等特點,所以這里只對正常報文之間的時延以及抖動進行計算,將其他的重傳報文、亂序報文不作計算時延抖動的處理,而這些重傳亂序報文將會進行丟包計算的處理。而對所有的UDP、ICMP 報文都只計算時延與抖動[12]。
2.2.1 時延、抖動計算
在計算算法方面,三種報文對于時延抖動的計算采用的是一種計算方法。主要計算的指標有平均往返時延(rtt_mean)、平均往返時延抖動(rtt_jitter)以及TCP 數據流的超時重傳時間(Retrans_rto)。當數據經過報文解析的數據報文進入到流處理模塊時,首先在提前創建好的數據流中查詢這個數據報文的上一個符合要求的數據報文進行計算,這里先計算出兩個報文之間的采樣時間,即往返時間(SampleRTT),如果在數據流中沒有找到符合要求的數據報文,那么當前處理的這個數據報文將繼續掛在數據流尾部供下面到來的數據報文進行計算。
計算表達式如下[13]:
1)平均往返時延:
2)平均往返時延抖動:
3)采用滾動迭代的方法對兩種參數進行計算,初始時,rtt_mean=SampleRTT,后續每計算出一次SampleRTT 就更新得出一次rtt_mean,直到統計周期結束,得出最終rtt_mean。對于抖動,同樣也是采用滾動迭代的方式進行計算,初始時,rtt_jitter=1/2 SampleRTT,后續每計算出一次SampleRTT 就更新一次,直到最終計算出rtt_jitter。
對于TCP 數據報文,還會存在重傳超時時間,對于重傳超時時間,計算表達式如下:
根據RFC6289,并經過多次測試計算,在參數α取1/8,β取1/4,μ取1,γ取4 時,計算結果最佳。
2.2.2 丟包計算
從數據報文的特點出發,主要計算TCP 數據報文的丟包率。根據現網中數據流的方向可以初步將網絡流量分成上下行,如果收到的數據報文的目的MAC 地址為網絡側的MAC 地址,則判斷為上行數據報文,如果收到的數據報文源MAC 地址為網絡側的MAC 地址,則判斷為下行數據報文。
其次,對于網絡故障定位功能來說,僅做上下行判斷的準確性遠遠不夠,因此,除了判斷上下行之外,還對丟包做了更加精確的定位處理。以監測點為基準,除了將數據報文分為上下行外,還在上下行的基礎上將數據報文分為網絡側和用戶側,網絡側數據報文即監測點到服務器之間的數據報文,用戶側數據報文即監測點到客戶端之間的數據報文。從而可以將數據報文更精確地分為上行用戶側數據報文、上行網絡側數據報文、下行用戶側數據報文、下行網絡側數據報文。因此,基于監測點,丟包可以分為上行用戶側丟包、上行網絡側丟包、下行用戶側丟包、下行網絡側丟包。
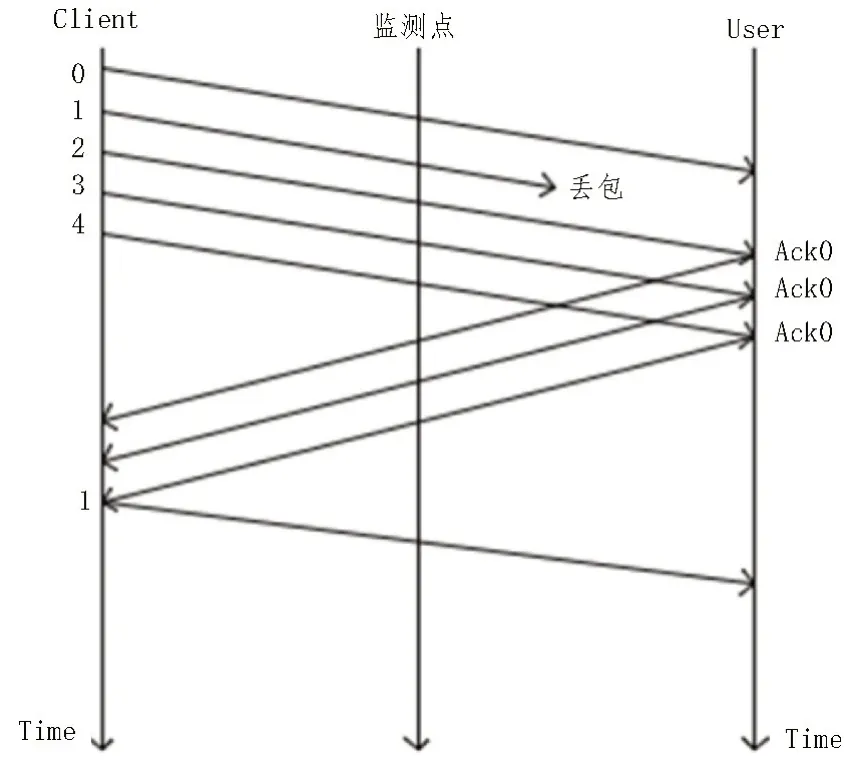
下行數據丟包分為下行網絡側丟包和下行用戶側丟包,即發送端為Client 端時,發送的報文丟失,為下行數據丟包。下行網絡側丟包如圖3 所示,當1 號報文發生下行網絡側丟包時,User 端會在未收到1號報文的情況下,會持續向服務器發送0 號報文的Ack 報文,Client 端在持續收到三個0 號報文的Ack報文后,重新發送1 號數據報文,此時,設置的監測點上就會檢測到1 號報文的重傳報文。下行用戶側丟包如圖4 所示,1 號報文在監測點與User 端發生了丟失,此時監測點能檢測到一次1 號數據報文,但是User 端還是會向Client 端發送0 號數據報文的Ack報文,Client 繼而重發1 號數據報文,那么在監測點就能再次檢測到1 號數據報文。
同理,上行數據丟包也分為上行網絡側丟包和上行用戶側丟包,即發送端為User 端時,發送的報文丟失,為下行數據丟包[14-15]。
根據TCP 數據報文存在IP 首部ID 號(ID(i))、TCP報文首部序號(seq(i))以及超時重傳,基于方法中對于各種丟包的定義,在判定TCP 報文是否發生丟包之前,先定義如下表達式[16]:
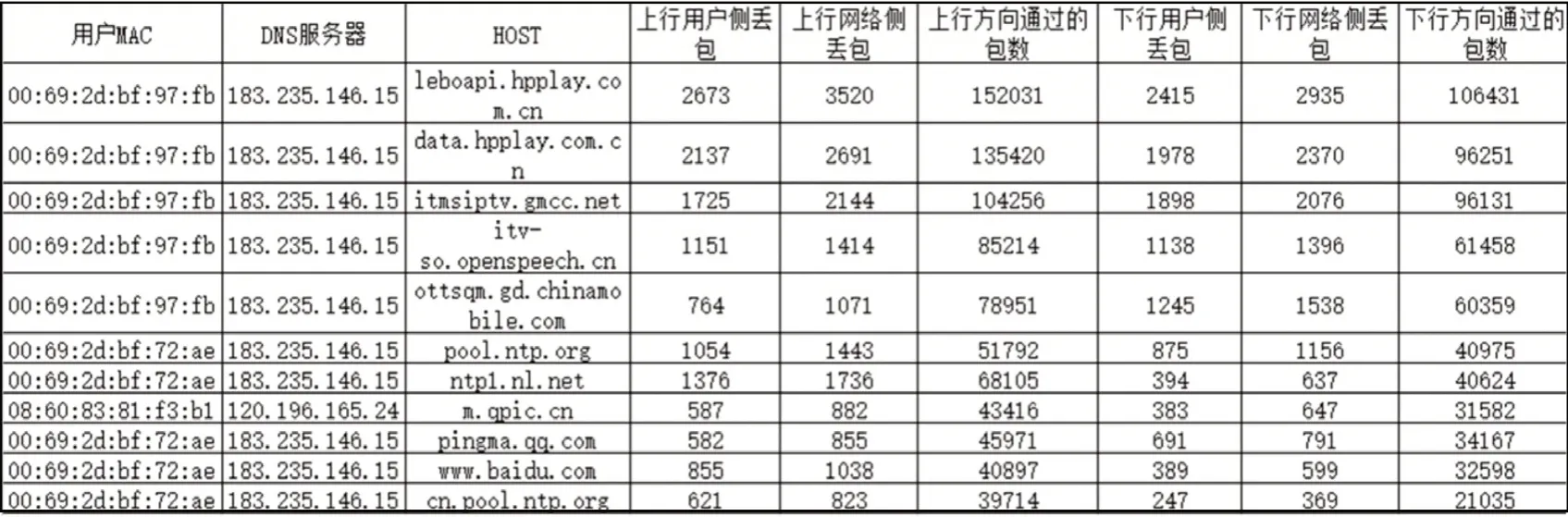
①seq(i) 圖3 下行網絡側丟包 圖4 下行用戶側丟包 ②seq(i)=seq(j) ③T(i,j)>Retrans_rto(Retrans_rto 為上述重傳超時時間,T(i,j)為兩個數據報文之間的時間間隔) ④ID(i)-ID(j)>=3(ID為對應報文IP 首部的ID號) 如果當前處理的數據報文使表達式①and{③or④}為真時,那么對于上行數據報文來說就是產生上行用戶側丟包,對于下行數據報文來說就是產生了下行網絡側丟包。如果當前處理的數據報文使表達式②and{③or④}為真時,對于上行就是產生上行網絡側丟包,對于下行就是產生下行用戶側丟包。 實驗環境主要依賴于OLT,實驗拓撲環境如圖5 所示,首先搭建模擬現網中的上網環境,在網關下面連接OLT,在OLT 下面連接多個ONU,然后在每個ONU 下面掛多個終端進行上網,產生上網流量,然后將檢測點設置到OLT 上,使用OLT 的鏡像功能,將OLT 正常的上網流量全部鏡像到質差分析系統上,然后DPDK 進行收包處理,之后開始對這些數據流量進行分析。 圖5 實驗拓撲環境 網絡流量質差分析方法基于上述網絡拓撲進行了實際的測試,在對數據流量進行了初步的識別之后,統計并列舉出訪問域名的一些識別信息,如圖6所示。 結果顯示,該網絡流量質差分析方法能將從OLT 經過的網絡流量進行識別分類,每個域名會對應多個IP 地址,同時這種方法可以統計訪問該域名的次數以及成功的次數與未響應的次數,然后對每一種應用的數據流進行時延、抖動計算。并對這些流量進行TCP 的丟包、重傳的計算,部分結果數據如圖7 所示。 在將數據流初步識別之后,將每一種應用的數據流進行分類,然后根據分類后的數據流進行計算,最后得出訪問不同的應用時,網絡出現的丟包、時延、抖動等參數指標。 基于PON 接入系統,該文提出了一種網絡流量質差分析方法,對現網中的數據流量進行質差分析,能將網絡流量根據業務類型進行分類,該方法在對數據報文識別分類的基礎上能計算出這些數據流量的時延、抖動、丟包等網絡性能參數,并能定位到出現網絡故障的地方。同時用到了幾種參數的計算算法,這些算法能夠很好地解決在計算時延、抖動、丟包等方面的問題。 盡管該方法能夠識別出現網中大部分類型的流量,但是還存在許多不足,比如目前只支持IPv4 數據報文的解析與識別,暫不支持IPv6 的數據報文進行識別。同時,參數計算準確率還有待提高。在后續,將針對IPv6 業務進行完善,并改進計算算法,以提高參數計算的準確率。 圖6 流量識別信息截圖(部分) 圖7 流量KPI計算結果截圖(部分)
3 實驗結果分析
3.1 實驗拓撲環境

3.2 實驗結果數據分析
4 結束語