面向多模態(tài)醫(yī)療健康數(shù)據(jù)的知識組織模式研究
2023-10-07 12:09:54葉東宇陳文祺
現(xiàn)代情報 2023年10期
韓 普 葉東宇 陳文祺 顧 亮
(1.南京郵電大學(xué)管理學(xué)院,江蘇 南京 210003;2.江蘇省數(shù)據(jù)工程與知識服務(wù)重點(diǎn)實(shí)驗(yàn)室,江蘇 南京 210023)
以習(xí)近平同志為核心的黨中央始終“把保障人民健康放在優(yōu)先發(fā)展的戰(zhàn)略位置”,黨的二十大報告也提出“推進(jìn)健康中國建設(shè),把保障人民健康放在優(yōu)先發(fā)展的戰(zhàn)略位置”。醫(yī)療健康事關(guān)人民生命健康安全,對經(jīng)驗(yàn)和知識依賴性強(qiáng),需要精準(zhǔn)、全面、高質(zhì)量的知識服務(wù)[1-2]。知識組織是知識服務(wù)的前提和基礎(chǔ)[3-5],醫(yī)療健康數(shù)據(jù)的知識組織水平很大程度上決定了醫(yī)療健康知識服務(wù)的效率和質(zhì)量[1]。
隨著互聯(lián)網(wǎng)和信息技術(shù)的快速發(fā)展,各類醫(yī)療健康活動產(chǎn)生了海量的文本、圖片、視頻和音頻等多模態(tài)數(shù)據(jù)。多模態(tài)數(shù)據(jù)雖然在底層表征上是異構(gòu)的,但是相同實(shí)體的不同模態(tài)數(shù)據(jù)在高層語義上是一致的,表達(dá)相同或相似的語義信息。傳統(tǒng)知識組織體系主要針對單模態(tài)數(shù)據(jù)進(jìn)行知識組織,難以支撐醫(yī)療健康領(lǐng)域多模態(tài)數(shù)據(jù)的語義表示、知識關(guān)聯(lián)和融合,當(dāng)前迫切需要一種更為完善的知識組織方法對類型繁多、專業(yè)性強(qiáng)、分布稀疏的多模態(tài)醫(yī)療健康數(shù)據(jù)進(jìn)行序化和組織。有效的知識組織模式不僅有助于縮小多模態(tài)數(shù)據(jù)間的異構(gòu)鴻溝,獲得更強(qiáng)的語義理解、知識補(bǔ)全和知識推理能力,而且有助于提升多模態(tài)數(shù)據(jù)資源的利用效率和知識服務(wù)水平,從而更好地服務(wù)于“健康中國”國家戰(zhàn)略。
1 相關(guān)研究工作
知識組織概念最早由分類法專家Bliss在1929年首次提出,1964年袁翰青教授在國內(nèi)最早使用了知識組織的表述[6],隨后劉洪波[7]和王知津[8]等國內(nèi)學(xué)者針對知識組織概念、模型、方法和應(yīng)用進(jìn)行了早期的理論和實(shí)踐探索。作為圖情理論和實(shí)踐研究的核心與熱點(diǎn)研究問題,隨著信息技術(shù)不斷發(fā)展,知識組織相關(guān)理論和實(shí)踐都取得了顯著進(jìn)步。尤其是得益于大數(shù)據(jù)和深度學(xué)習(xí)的進(jìn)步,知識組織的理論、方法和技術(shù)研究成為近些年圖書情報學(xué)領(lǐng)域的前沿課題[9-10]。本小節(jié)主要從模態(tài)視角和領(lǐng)域視角對知識組織的最新研究進(jìn)展進(jìn)行梳理。
1.1 面向多模態(tài)數(shù)據(jù)的知識組織
大數(shù)據(jù)時代信息傳播豐富多彩,用戶獲取的信息不僅局限于傳統(tǒng)文本模態(tài),還包含了圖像、音頻和視頻等多模態(tài)數(shù)據(jù)。在此背景下,如何將多模態(tài)數(shù)據(jù)進(jìn)行知識序化形成科學(xué)有效的知識組織體系成為當(dāng)前學(xué)界的關(guān)注熱點(diǎn)[11]。已有研究主要從多模態(tài)知識融合、知識表示和實(shí)踐應(yīng)用方面進(jìn)行了重點(diǎn)關(guān)注。在方法和技術(shù)方面,Wang M等[12]借助維基百科圖像描述中的超鏈接信息關(guān)聯(lián)文本和圖像,以生成多模態(tài)語義關(guān)系。在實(shí)踐應(yīng)用方面,Su J等[13]構(gòu)建了可捕捉文本和圖像語義信息交互的多模態(tài)神經(jīng)機(jī)器翻譯模型;蔣雨肖等[14]利用深度學(xué)習(xí)模型融合文本和圖像的語義特征,進(jìn)而實(shí)現(xiàn)多模態(tài)信息分類。隨著深度學(xué)習(xí)和多模態(tài)學(xué)習(xí)的發(fā)展,多模態(tài)知識圖譜成為知識組織的重要方法和工具[15]。Xia F等[16]在已有醫(yī)學(xué)知識圖譜基礎(chǔ)上,借助圖像檢索構(gòu)建醫(yī)學(xué)多模態(tài)知識圖譜;張瑩瑩等[17]在中文癥狀知識圖譜基礎(chǔ)上,融入圖片以豐富實(shí)體的視覺信息。在數(shù)字人文領(lǐng)域,視覺資源對象語義內(nèi)容豐富[18-19];曾子明等[18]提出一種基于關(guān)聯(lián)數(shù)據(jù)的視覺資源組織方法來揭示知識間內(nèi)在語義關(guān)聯(lián);夏立新等[20]和莊文杰等[21]分別以資源社會化標(biāo)簽和視頻知識元進(jìn)行非遺視覺資源的知識組織;周知等[22]提出了一種4層架構(gòu)的數(shù)字人文圖像資源知識組織模型。
已有研究主要對多模態(tài)知識組織中的相關(guān)方法和技術(shù)進(jìn)行了研究,這些研究大大拓展了多模態(tài)知識組織實(shí)踐的范圍,為多模態(tài)知識組織深入研究奠定了基礎(chǔ)。總體上,相關(guān)研究主要停留在傳統(tǒng)的描述階段,盡管有部分文獻(xiàn)根據(jù)資源特征構(gòu)建了基于關(guān)聯(lián)數(shù)據(jù)的知識組織模型,但主要依賴不同模態(tài)數(shù)據(jù)的元數(shù)據(jù),難以充分利用多模態(tài)數(shù)據(jù)的深層語義信息,多模態(tài)數(shù)據(jù)資源的深度序化和模態(tài)間語義關(guān)聯(lián)迫切需要充分利用多模態(tài)數(shù)據(jù)的固有特征信息進(jìn)行知識組織。
1.2 醫(yī)療健康領(lǐng)域知識組織
隨著知識組織研究的深入以及用戶精準(zhǔn)知識服務(wù)的需求的推動,知識組織正走向領(lǐng)域知識組織時代[5-6]。醫(yī)療健康領(lǐng)域知識專業(yè)性強(qiáng),實(shí)體數(shù)量巨大、更新速度快且實(shí)體間語義關(guān)系非常復(fù)雜[23-24]。已有文獻(xiàn)主要對醫(yī)療健康領(lǐng)域知識組織中的實(shí)體識別、實(shí)體對齊和關(guān)系抽取等關(guān)鍵問題進(jìn)行了研究。在實(shí)體識別方面,Li L等[25]基于注意力機(jī)制與雙向長短期記憶網(wǎng)絡(luò),提出一種改進(jìn)的中文電子病歷實(shí)體識別模型,解決了長文本中遠(yuǎn)距離帶來的信息缺失問題;Ji B等[26]基于多神經(jīng)網(wǎng)絡(luò)協(xié)同合作方法,構(gòu)建了中文醫(yī)學(xué)命名實(shí)體識別模型,并通過遷移學(xué)習(xí)引入非目標(biāo)場景數(shù)據(jù)集提高模型泛化能力。在實(shí)體對齊方面,Hao J等[27]基于本體論、語義網(wǎng)和圖神經(jīng)網(wǎng)絡(luò)提出了一種端到端實(shí)體對齊框架Medeto,有效提高了醫(yī)學(xué)知識庫中本體匹配的準(zhǔn)確率;Su F等[28]采用關(guān)系聚合網(wǎng)絡(luò)提取文本特征,通過輔助信息不參與網(wǎng)絡(luò)反向傳播有效地提高了實(shí)體對抽取的效率。在關(guān)系抽取方面,Alicante A等[29]提出一種無監(jiān)督方法來抽取臨床記錄中的實(shí)體和實(shí)體間關(guān)系;Bai T等[30]設(shè)計了一種基于卷積神經(jīng)網(wǎng)絡(luò)的分段關(guān)注機(jī)制,進(jìn)而抽取中醫(yī)草藥文獻(xiàn)中實(shí)體間的語義關(guān)系。
作為實(shí)現(xiàn)醫(yī)療健康領(lǐng)域知識組織目標(biāo)的最佳途徑之一,知識圖譜能夠以一種便于機(jī)器存儲、識別和理解的方式對數(shù)據(jù)進(jìn)行有效的組織與管理[31],相關(guān)研究近些年受到了學(xué)界的極大關(guān)注[32]。為解決多源健康知識的異構(gòu)問題,馬費(fèi)成等[9]采用五元組形式進(jìn)行健康知識表示。王文韜等[33]基于粒度原理將健康領(lǐng)域知識解構(gòu)成不同知識單元。Warnat H S等[2]利用醫(yī)療健康數(shù)據(jù)和機(jī)器學(xué)習(xí)模型構(gòu)建了疾病分類系統(tǒng)。以醫(yī)學(xué)學(xué)術(shù)文獻(xiàn)為數(shù)據(jù)源,Zhu C等[34]構(gòu)建了疾病知識圖譜,蔡妙芝等[23]采用SPO語義三元組進(jìn)行疾病知識組織。基于尋醫(yī)問藥網(wǎng)結(jié)構(gòu)化信息,武家偉等[35]構(gòu)建了“疾病—癥狀”知識圖譜。陸泉等[36]提出了一個基于擴(kuò)展疾病本體的醫(yī)學(xué)數(shù)據(jù)組織模型,實(shí)現(xiàn)電子病歷大數(shù)據(jù)的知識描述與組織。
綜上所述,現(xiàn)有的醫(yī)療健康知識組織傾向于在單模態(tài)視角下探討不同應(yīng)用場景下的具體問題,部分研究關(guān)注了不同模態(tài)數(shù)據(jù)技術(shù)層面的知識融合,但缺少系統(tǒng)的多模態(tài)知識組織理論架構(gòu)。多模態(tài)醫(yī)療健康數(shù)據(jù)的涌現(xiàn)使跨模態(tài)語義理解與知識組織變得更加迫切,有效的知識組織不僅能夠更全面地揭示不同模態(tài)醫(yī)療健康數(shù)據(jù)之間的語義關(guān)聯(lián),同時也能夠利用多模態(tài)數(shù)據(jù)補(bǔ)全做出更準(zhǔn)確的疾病預(yù)測[37]。本研究將從多模態(tài)和多粒度視角下探究醫(yī)療健康數(shù)據(jù)的知識單元抽取、多模態(tài)知識單元構(gòu)建和多模態(tài)知識圖譜補(bǔ)全等問題,進(jìn)而構(gòu)建醫(yī)療健康領(lǐng)域多模態(tài)知識組織模式,并在醫(yī)療健康知識問答等應(yīng)用場景進(jìn)行分析。
2 面向多模態(tài)醫(yī)療健康數(shù)據(jù)的知識組織模式設(shè)計與技術(shù)分析
多模態(tài)醫(yī)療健康知識組織模式最終是實(shí)現(xiàn)多模態(tài)醫(yī)療健康數(shù)據(jù)的有效組織和應(yīng)用。多模態(tài)醫(yī)療健康知識組織模式的關(guān)鍵步驟是通過醫(yī)療健康數(shù)據(jù)內(nèi)涵特征分析,在已有的醫(yī)療知識圖譜基礎(chǔ)上融入其他模態(tài)信息以補(bǔ)全語義知識,并通過語義關(guān)聯(lián)為用戶提供醫(yī)療健康知識服務(wù)。其中,相較于傳統(tǒng)的知識組織模式,本文的多模態(tài)知識組織模式創(chuàng)新之處在于從醫(yī)療健康數(shù)據(jù)知識單元抽取和多模態(tài)知識單元構(gòu)建方面強(qiáng)化多模態(tài)知識的深度處理與利用。具體如圖1所示。
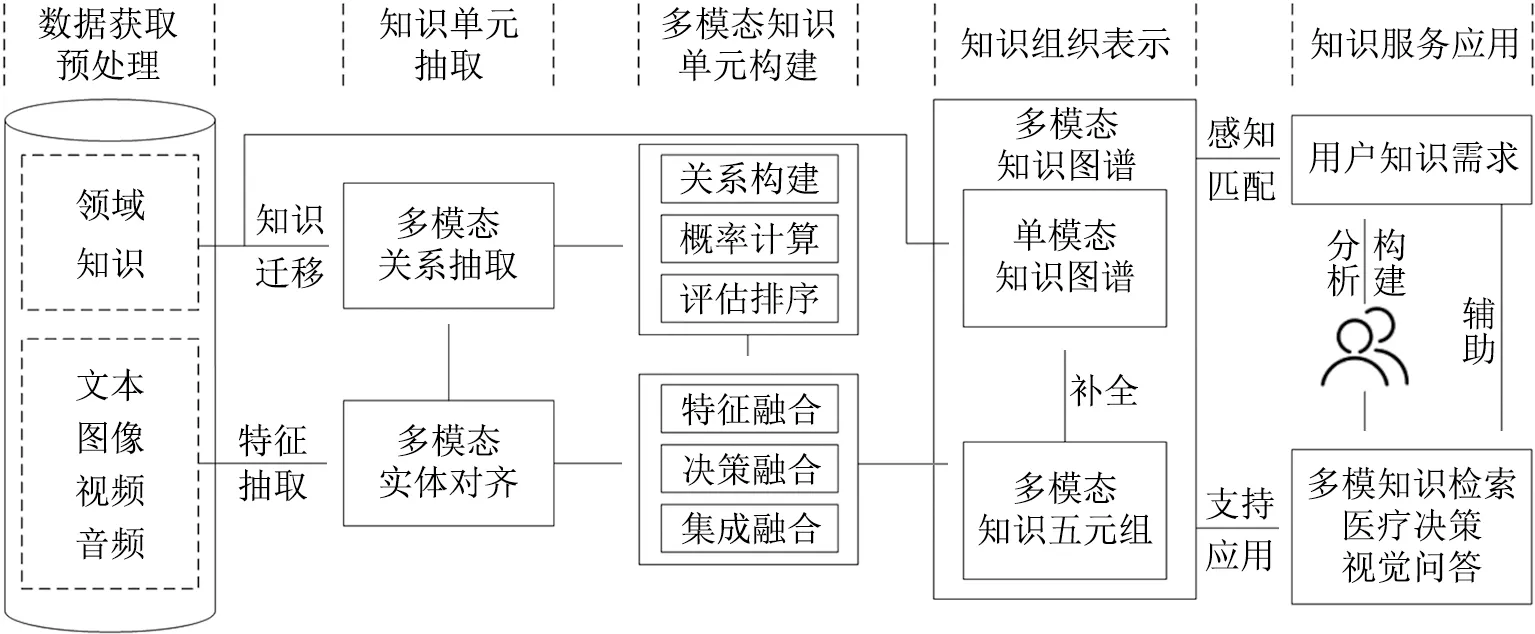
圖1 多模態(tài)醫(yī)療健康數(shù)據(jù)的知識組織模式設(shè)計及應(yīng)用方案
本文以醫(yī)療健康領(lǐng)域電子病歷文本和圖像數(shù)據(jù)為知識組織案例,按照圖1進(jìn)行數(shù)據(jù)獲取及預(yù)處理、知識單元抽取、多模態(tài)知識單元構(gòu)建、多模態(tài)知識組織表示以及知識服務(wù)應(yīng)用的技術(shù)流程論證分析。
2.1 多模態(tài)醫(yī)療健康數(shù)據(jù)的獲取和預(yù)處理
高質(zhì)量的多模態(tài)數(shù)據(jù)集是實(shí)現(xiàn)醫(yī)療健康知識組織的基礎(chǔ),本文的多模態(tài)醫(yī)療健康數(shù)據(jù)來源于醫(yī)療機(jī)構(gòu)、在線健康平臺和醫(yī)學(xué)知識庫,主要包含文本、圖像、音頻和視頻4種模態(tài)數(shù)據(jù)。本研究一方面從合作醫(yī)療機(jī)構(gòu)的臨床電子病歷獲取文本及CT、X光和超聲等醫(yī)學(xué)圖像數(shù)據(jù),并對用戶隱私信息進(jìn)行脫敏處理;另一方面利用爬蟲獲取疾病百科、醫(yī)學(xué)文獻(xiàn)和在線健康平臺的文本及圖像數(shù)據(jù);另外,還通過在線短視頻平臺獲取音視頻模態(tài)數(shù)據(jù)。
盡管可利用的多模態(tài)醫(yī)療健康數(shù)據(jù)較多,但是不同來源的數(shù)據(jù)質(zhì)量參差不齊,尤其是包含大量用戶生成內(nèi)容的在線健康平臺數(shù)據(jù)需要清洗和加工。具體而言,首先通過去重、填補(bǔ)缺失值、處理異常值等方法對多模態(tài)數(shù)據(jù)進(jìn)行預(yù)處理;然后利用YEDDA、CVAT、Praat和VoTT等標(biāo)注工具對文本、圖像、音頻和視頻數(shù)據(jù)進(jìn)行多輪標(biāo)注;接著基于人工隨機(jī)檢查標(biāo)注結(jié)果對多模態(tài)知識實(shí)體及語義關(guān)系標(biāo)注規(guī)范進(jìn)行適時修正;最終通過標(biāo)注一致性檢驗(yàn),獲得高質(zhì)量的多模態(tài)醫(yī)療健康標(biāo)注數(shù)據(jù)集。
2.2 醫(yī)療健康數(shù)據(jù)的知識單元抽取
知識單元是知識的基本組分,對知識序化和知識組織有著極其重要的作用。雖然知識單元的分類標(biāo)準(zhǔn)與表達(dá)形式目前尚未統(tǒng)一,但已有研究多傾向于使用N元組描述知識單元[38]。一方面采用N元組形式可以將知識單元更好地表示為機(jī)器可處理的形式;另一方面可以更方便地實(shí)現(xiàn)知識圖譜的知識補(bǔ)全[39]。基于以上考慮,本文將使用三元組形式表示各模態(tài)醫(yī)療健康數(shù)據(jù)中的知識單元,進(jìn)而為后續(xù)的多模態(tài)知識單元構(gòu)建和知識圖譜補(bǔ)全奠定基礎(chǔ)。本研究中,每個模態(tài)數(shù)據(jù)知識單元定義為實(shí)體與實(shí)體間關(guān)系所構(gòu)成的三元組,因此各模態(tài)數(shù)據(jù)中實(shí)體和實(shí)體間關(guān)系抽取是后續(xù)研究的關(guān)鍵環(huán)節(jié)。
盡管已有研究驗(yàn)證了深度學(xué)習(xí)在實(shí)體識別任務(wù)上的優(yōu)勢,但醫(yī)療健康領(lǐng)域多模態(tài)數(shù)據(jù)具有高度的專業(yè)性,存在不同模態(tài)數(shù)據(jù)均指向同一實(shí)體的現(xiàn)象。如圖2所示,多模態(tài)醫(yī)療健康數(shù)據(jù)中文本描述“腫塊”、音頻數(shù)據(jù)“占位”、醫(yī)學(xué)影像中A區(qū)域和視頻中B部分,雖然描述方式不同,但均表征“腫瘤”疾病這一實(shí)體。此外,醫(yī)療健康領(lǐng)域各實(shí)體間還存在大量的一對多關(guān)系。這些因素給多模態(tài)醫(yī)療健康數(shù)據(jù)的知識單元抽取帶來了很大挑戰(zhàn)。因此,如何解決多模態(tài)數(shù)據(jù)中實(shí)體對齊和關(guān)系抽取是本部分的研究重點(diǎn)。
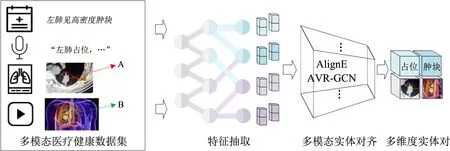
圖2 多模態(tài)醫(yī)療健康數(shù)據(jù)實(shí)體對齊
實(shí)體對齊是判斷不同數(shù)據(jù)源和不同模態(tài)實(shí)體是否為指向同一對象的過程。在已有研究基礎(chǔ)上,本小節(jié)首先利用深度神經(jīng)網(wǎng)絡(luò)對文本、圖像、音頻和視頻數(shù)據(jù)進(jìn)行特征抽取;然后借助AlignE、AVR-GCN和Cross-KG等方法實(shí)現(xiàn)多模態(tài)知識實(shí)體對齊和消融;最終構(gòu)建<腫塊/占位/圖像A/視頻B>的實(shí)體對。
本研究中關(guān)系抽取任務(wù)主要是針對文本模態(tài)數(shù)據(jù)。由于醫(yī)療健康領(lǐng)域?qū)I(yè)性強(qiáng)、實(shí)體表述多樣,實(shí)體間語義關(guān)系復(fù)雜,尤其關(guān)系重疊現(xiàn)象比較常見,如圖3中文本模態(tài)數(shù)據(jù)“左肺見高密度腫塊”中的實(shí)體“腫塊”與“左肺”和“高密度”均存在語義關(guān)系。考慮到傳統(tǒng)聯(lián)合抽取和Pipeline抽取方法難以解決此類問題,本研究采用端到端多模態(tài)生成模型抽取實(shí)體間語義關(guān)系。

圖3 多模態(tài)醫(yī)療健康數(shù)據(jù)中醫(yī)學(xué)實(shí)體關(guān)系抽取模型
在實(shí)體關(guān)系抽取任務(wù)中,首先將文本模態(tài)和圖像模態(tài)數(shù)據(jù)輸入編碼器(Encoder),然后將編碼后的信息輸入到解碼器(Decoder)中進(jìn)行解碼,接著由解碼器生成包含實(shí)體和關(guān)系的序列“腫塊
圖3中,“腫塊
2.3 醫(yī)療健康數(shù)據(jù)的多模態(tài)知識單元構(gòu)建
現(xiàn)有的多模態(tài)知識融合和知識組織研究大多直接將圖片與文本實(shí)體構(gòu)成的知識單元嵌入知識圖譜[17,40]。但知識單元不是獨(dú)立存在的,只有將其置于原始語境下,才能夠最大化地理解知識單元的價值和作用[39]。本研究提出的知識組織模式創(chuàng)新之處在于整合多模態(tài)醫(yī)療健康數(shù)據(jù)以構(gòu)建多模態(tài)知識單元,并在此基礎(chǔ)上實(shí)現(xiàn)醫(yī)療健康知識圖譜的模態(tài)補(bǔ)全,其中多模態(tài)知識單元是在特定語境下對特定知識實(shí)體及其關(guān)系的整合,相較于單模態(tài)的知識單元在內(nèi)容上更加豐富。具體而言,多模態(tài)知識單元構(gòu)建分為知識評估與知識融合兩個步驟。首先,對三元組形式的知識單元進(jìn)行評估以剔除噪聲和無關(guān)信息進(jìn)而得到知識真值;其次,融合知識真值與醫(yī)學(xué)知識庫中的專業(yè)知識得到包含上下文語義信息的多模態(tài)知識單元。本部分以圖4為例,通過知識評估與知識融合生成多模態(tài)知識單元。

圖4 醫(yī)療健康多模態(tài)知識單元構(gòu)建過程
知識評估是通過關(guān)系構(gòu)建、概率計算和評估排序得到多模態(tài)醫(yī)療健康數(shù)據(jù)中知識真值的過程。具體而言,首先基于YOLO和BiLSTM-CRF等算法對圖4中腦膜瘤多模態(tài)數(shù)據(jù)進(jìn)行實(shí)體識別,分別抽取其圖像實(shí)體T1和T2,以及文本實(shí)體“右側(cè)鞍旁”和“形狀規(guī)則占位”;接著通過關(guān)系構(gòu)建枚舉多模態(tài)知識實(shí)體間所有的關(guān)系路徑;然后將每條路徑作為訓(xùn)練專家,通過隨機(jī)游走關(guān)系路徑圖來計算每條關(guān)系路徑終點(diǎn)的概率值[41];最后利用醫(yī)學(xué)知識庫中語義關(guān)系對預(yù)測結(jié)果進(jìn)行排序評估并得到知識真值“<右側(cè)鞍旁,T2,形狀規(guī)則占位>”。
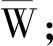
2.4 醫(yī)療健康多模態(tài)知識組織表示
鑒于已有單模態(tài)文本的醫(yī)學(xué)知識圖譜研究已較為成熟[34-35],本研究在文本知識圖譜基礎(chǔ)上進(jìn)行多模態(tài)醫(yī)療健康知識組織表示和補(bǔ)全,該部分工作主要包含多模態(tài)知識五元組構(gòu)建和知識圖譜補(bǔ)全兩部分。五元組構(gòu)建是在各模態(tài)知識單元基礎(chǔ)上,采用五元組形式對多模態(tài)醫(yī)療健康知識進(jìn)行組織,具體以<多模知識單元U,實(shí)體E,關(guān)系R,領(lǐng)域D,參考源S>五元組形式TM進(jìn)行存儲。其中,U包括文本單元UL、圖像單元UP、視頻單元UV和音頻單元UA,E表示實(shí)體集合,R表示實(shí)體間關(guān)系集合,D表示領(lǐng)域集合,S是描述參考源集合,TM=(UL∪UP∪UV∪UA)×E×R×D×S。如圖5所示,首先將包含圖像單元UP和文本單元UL的多模知識單元“神經(jīng)源性腫瘤”存儲在U中;接著將通過實(shí)體識別和關(guān)系抽取的各部分實(shí)體以及實(shí)體間語義關(guān)系集分別存儲在E和R中;最后基于本體知識表示方法,將其他模態(tài)信息存儲在領(lǐng)域D中,將數(shù)據(jù)來源信息存儲在參考源S。

圖5 多模態(tài)醫(yī)療健康知識五元組構(gòu)建(以文本—圖像為例)
知識圖譜補(bǔ)全是指將多模態(tài)知識五元組融入現(xiàn)有單模態(tài)醫(yī)學(xué)知識圖譜。本部分采用語義相似度計算和語義映射的方法將多模態(tài)知識五元組融入現(xiàn)有的知識圖譜,具體包含實(shí)體映射和關(guān)系映射兩部分。如圖6所示,多模態(tài)知識五元組中,實(shí)體E存在文本實(shí)體T1“右下縱膈”和T6“神經(jīng)源性腫瘤”,關(guān)系R中具有T6-T1“發(fā)病部位”和T6-P1“圖片對應(yīng)”;單模態(tài)醫(yī)學(xué)知識圖譜包含實(shí)體“縱膈”和“神經(jīng)源性腫瘤”與表示關(guān)系的三元組“<神經(jīng)源性腫瘤,發(fā)病部位,后縱膈、椎管內(nèi)、腹膜后等>”。實(shí)體映射是將多模態(tài)知識五元組中的文本實(shí)體T1和T6分別同單模態(tài)醫(yī)學(xué)知識圖譜中的實(shí)體1和實(shí)體2建立映射;關(guān)系映射是將關(guān)系“T6-T1”和單模態(tài)醫(yī)學(xué)知識圖譜中關(guān)系1建立映射。由于單模態(tài)醫(yī)學(xué)知識圖譜不存在圖片數(shù)據(jù),因此將“T6-P1”作為關(guān)系2“圖片對應(yīng)”補(bǔ)全到單模態(tài)知識圖譜中,最終以

圖6 多模態(tài)醫(yī)療健康知識補(bǔ)全過程
3 基于多模態(tài)醫(yī)療健康知識圖譜的健康知識服務(wù)
本研究構(gòu)建的多模態(tài)醫(yī)療健康知識組織模式可應(yīng)用于跨模態(tài)知識檢索、視覺問答和輔助決策支持等應(yīng)用場景。本節(jié)以醫(yī)療健康問答系統(tǒng)為實(shí)踐應(yīng)用,驗(yàn)證多模態(tài)知識組織模式在語義消歧和知識補(bǔ)全方面的優(yōu)勢,增強(qiáng)知識服務(wù)的有效性和全面性。
本研究構(gòu)建的醫(yī)療健康知識問答系統(tǒng)主要分為用戶知識需求分析和動態(tài)知識匹配兩部分。知識需求分析通過獲取用戶的基本信息和主題意圖生成用戶知識需求模型。具體而言,首先通過基于規(guī)則和統(tǒng)計的方法獲取用戶基本信息,接著采用主題挖掘抽取用戶請求的主題意圖進(jìn)而構(gòu)建用戶知識需求模型;知識匹配是在多模態(tài)知識圖譜基礎(chǔ)上,利用語義相關(guān)度計算得到與用戶知識需求相關(guān)度高的知識標(biāo)引結(jié)果集,并通過語義關(guān)聯(lián)實(shí)現(xiàn)用戶知識需求與多模態(tài)醫(yī)療健康知識的精準(zhǔn)匹配。
本文以網(wǎng)上問診為例,構(gòu)建基于多模態(tài)知識圖譜的醫(yī)療健康知識問答系統(tǒng),具體如圖7所示。在知識需求分析階段,首先利用多模態(tài)實(shí)體識別、目標(biāo)檢測和關(guān)系抽取等方法獲取用戶提交數(shù)據(jù)的關(guān)鍵信息,然后采用主題挖掘方法對用戶查詢請求的主題意圖進(jìn)行識別,進(jìn)而構(gòu)建用戶知識需求模型。具體地,首先分析和處理用戶提交的數(shù)據(jù),抽取如“疼痛”“不均”“陰影”和醫(yī)學(xué)影像圖中病變部位等關(guān)鍵信息,然后基于主題挖掘算法識別用戶查詢請求的主題意圖并構(gòu)建用戶知識需求模型。在知識匹配階段,首先計算用戶知識需求模型與多模態(tài)醫(yī)療健康知識單元的語義相關(guān)度,得到相關(guān)度較高的知識標(biāo)引結(jié)果集,并利用多模態(tài)實(shí)體的語義關(guān)聯(lián)實(shí)現(xiàn)語義消歧,最終向用戶提供匹配度高的多模態(tài)醫(yī)療健康知識。具體地,通過語義相似度計算得到與用戶知識需求匹配度較高的知識標(biāo)引結(jié)果集“肝膿腫”和“脂肪肝”。實(shí)際情況下,知識標(biāo)引結(jié)果集中相關(guān)概念與用戶知識需求可能存在歧義,這將造成系統(tǒng)推送錯誤信息,如“脂肪肝”的病癥“密度降低”是指全肝密度降低,而用戶知識需求模型中“低密度陰影”則表明病變部位密度較低。因此系統(tǒng)將知識標(biāo)引結(jié)果集與用戶知識需求進(jìn)行多模態(tài)實(shí)體的語義關(guān)聯(lián),計算出用戶知識需求中“低密度”“不均”等實(shí)體與“肝膿腫”中文本和圖像實(shí)體具有最高關(guān)聯(lián)度,進(jìn)而實(shí)現(xiàn)語義消歧,最終系統(tǒng)將可能性最高的結(jié)果“肝膿腫”及相關(guān)信息推送給用戶。

圖7 基于多模態(tài)知識圖譜的醫(yī)療健康問答系統(tǒng)
4 結(jié) 語
隨著信息技術(shù)的發(fā)展和大數(shù)據(jù)時代的到來,醫(yī)療健康領(lǐng)域文本、圖像、視頻數(shù)據(jù)增長迅速,傳統(tǒng)知識組織體系主要針對文本模態(tài)數(shù)據(jù)進(jìn)行知識組織,目前迫切需要一種有效的組織方法對多模態(tài)數(shù)據(jù)進(jìn)行序化整理組織以提升數(shù)據(jù)資源的利用效率,進(jìn)而為用戶提供多維度多樣化知識服務(wù)。本文從多模態(tài)視角,通過分析文本、圖像、音頻和視頻多模態(tài)數(shù)據(jù)的內(nèi)在特性和多模態(tài)數(shù)據(jù)間深層語義關(guān)系,基于多模態(tài)知識圖譜和語義知識組織框架,提出一種面向多模態(tài)醫(yī)療健康數(shù)據(jù)的知識組織模式,重點(diǎn)從多模態(tài)醫(yī)療健康數(shù)據(jù)的獲取和預(yù)處理、醫(yī)療健康數(shù)據(jù)的知識單元抽取、多模態(tài)知識單元構(gòu)建、多模態(tài)知識組織表示和基于多模態(tài)醫(yī)療健康知識圖譜的知識服務(wù)等關(guān)鍵層面分析了具體實(shí)現(xiàn)路徑。本研究一方面推進(jìn)了多模態(tài)知識組織的理論深度;另一方面有助于提升多模態(tài)數(shù)據(jù)資源的利用效率和知識服務(wù)水平,對提升國民健康信息素養(yǎng)和創(chuàng)新知識服務(wù)具有重要的現(xiàn)實(shí)意義。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
湖北經(jīng)濟(jì)學(xué)院學(xué)報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機(jī)學(xué)院學(xué)報(2015年4期)2015-02-28 14:30:00
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
計算物理(2014年2期)2014-03-11 17:01:39
語文知識(2014年1期)2014-02-28 21:59:13
