基于注意力機制的文本挖掘深度混合推薦模型
2023-10-16 12:33:42陳增照
華中師范大學(xué)學(xué)報(自然科學(xué)版) 2023年5期
張 婧, 陳增照, 段 超, 王 虎
(1.江漢大學(xué)教育學(xué)院, 武漢 430065; 2.華中師范大學(xué)人工智能教育學(xué)部, 武漢 430079;3.浙江師范大學(xué)浙江省智能教育技術(shù)與應(yīng)用重點實驗室, 浙江 金華 321004)
手機等移動設(shè)備的普及使人們的日常生活更加依賴移動服務(wù),人們從移動設(shè)備中獲取業(yè)務(wù)信息、產(chǎn)品信息、促銷信息和推薦信息.移動服務(wù)的重要應(yīng)用是視頻推薦[1].推薦算法作為信息過濾的重要手段,旨在為用戶推薦個性化、小規(guī)模的信息集合以解決“信息過載”和“信息迷航”等問題[2],已在電子商務(wù)、社交平臺、新聞、電影、音樂等眾多應(yīng)用服務(wù)[3]中得到初步應(yīng)用.協(xié)同過濾是目前應(yīng)用最廣泛的一種推薦算法[4],它首先分析歷史行為數(shù)據(jù)生成與當(dāng)前用戶行為興趣最相近的用戶群,再將該用戶群當(dāng)前的喜好推薦給當(dāng)前用戶.
協(xié)同過濾不依賴于物品和用戶本身的特征,具有領(lǐng)域無關(guān)的特性,但該方法易遭受冷啟動和數(shù)據(jù)稀疏問題[5].為緩解這兩類問題的影響,研究者往往將用戶或者物品的輔助信息應(yīng)用到協(xié)同過濾中以提高推薦的準確性[6-7].現(xiàn)有研究中用到的輔助信息主要包括社會網(wǎng)絡(luò)、用戶和項目的屬性和上下文信息等,在文件形式上則包括文本、圖片、視頻、音頻等多種類型,其中使用最多的是文本信息.
近年來,由于深度學(xué)習(xí)在特征提取方面以及注意力機制在特征選擇方面的突出表現(xiàn),越來越多的研究使用融合注意力機制的深度學(xué)習(xí)模型挖掘輔助信息的潛藏因子以生成有效的表示形式.如卷積神經(jīng)網(wǎng)絡(luò)與概率矩陣分解相結(jié)合的模型[8](convolutional matrix factorization,ConvMF),堆疊式降噪自編碼器與概率矩陣分解相結(jié)合的模型[9](a variant of stacked denoising autoencoder, aSDAE),以及將卷積神經(jīng)網(wǎng)絡(luò)和自編碼器相結(jié)合的模型[10](a probabilistic model of hybrid deep collaborative filtering,PHD).最近注意力機制在自然語言處理領(lǐng)域表現(xiàn)突出,Wang等[11]將注意力機制與長短時記憶網(wǎng)絡(luò)(long short-term memory,LSTM)相結(jié)合進行語義關(guān)系抽取.基于注意力的模型[12](dual attention-based,D-Attn),通過使用局部和全局注意力機制和卷積神經(jīng)網(wǎng)絡(luò)提取文本信息的特征做評分預(yù)測.自編碼器與注意力機制相結(jié)合的模型[13]CATA++(collaborative dual attentive autoencoder,CATA++),提高了科技論文推薦的準確率.谷歌提出的Transformer[14]是基于注意力的機器翻譯架構(gòu),它是一個混合神經(jīng)網(wǎng)絡(luò),具有前饋層和自注意層,其研究首次提出了多頭注意力機制,將多個自注意力連接起來,同時通過降低維度減少計算消耗,并且能夠捕捉長距離單詞之間的相關(guān)性.
本文提出了一種融合多頭注意力機制的卷積矩陣分解模型(multi-head attention convolutional matrix factorization,MACMF).該模型將描述項目的文本信息轉(zhuǎn)化為詞向量,經(jīng)過預(yù)訓(xùn)練的詞向量完成初始化,在卷積神經(jīng)網(wǎng)絡(luò)的嵌入層和卷積層之間加入多頭注意力機制,提取項目的潛在因子,再結(jié)合概率矩陣分解做評分預(yù)測.
本文的主要貢獻包括以下三個方面.首先,將多頭注意力機制融入卷積神經(jīng)網(wǎng)絡(luò),優(yōu)化了ConvMF模型,利用超參數(shù)平衡上下文信息和評分信息,減少了數(shù)據(jù)稀疏帶來的不利影響.其次,優(yōu)化了卷積神經(jīng)網(wǎng)絡(luò)模型.在卷積層中增加長度為1的卷積核,有利于提取單一詞特征,在池化層中采用k-max-pooling技術(shù),減少信息丟失.最后,在ML-100k、ML-1m、ML-10m、Amazon四個公開數(shù)據(jù)集上的大量實驗表明,與所有基線模型相比,其結(jié)果均能取得更好的效果.
1 相關(guān)工作
本節(jié)深入分析與本研究相關(guān)的研究有兩條線,第一條是基于深度學(xué)習(xí)的推薦模型,第二條是融合注意力機制的推薦模型.
1.1 基于深度學(xué)習(xí)的推薦模型
近年來,深度學(xué)習(xí)在語音識別,圖像處理和自然語言處理(natural language processing,NLP)領(lǐng)域受到了極大的關(guān)注[15].深度學(xué)習(xí)技術(shù)已成為人工智能領(lǐng)域和推薦系統(tǒng)的研究前沿.深度學(xué)習(xí)具有非線性變換、表征學(xué)習(xí)、序列建模、靈活性等特點,基于深度學(xué)習(xí)的推薦系統(tǒng)可以分為兩大類:集成模型和神經(jīng)網(wǎng)絡(luò)模型[16].集成模型又分為兩種類型:1)將深度學(xué)習(xí)與傳統(tǒng)推薦模型集成在一起,并且僅依靠深度學(xué)習(xí)模型進行推薦;2)將深度學(xué)習(xí)模型與傳統(tǒng)推薦模型集成在一起,試圖以一種或多種方式將深度學(xué)習(xí)方法與傳統(tǒng)推薦技術(shù)相結(jié)合.按照所采用的深度學(xué)習(xí)技術(shù)的類型, 將神經(jīng)網(wǎng)絡(luò)模型分為兩類:使用單一深度學(xué)習(xí)技術(shù)的模型和深度復(fù)合模型.在單一深度學(xué)習(xí)技術(shù)中,分為八個子類:基于MLP、AE、CNN、RNN、RBM、NADE、AM、AN和DRL的推薦系統(tǒng)[17].深度學(xué)習(xí)技術(shù)的使用提高了推薦模型的適用性,例如多層感知機可以有效地對用戶和項目之間的非線性交互進行建模[18],CNN能夠從異類提取局部和全局表示[19].深度復(fù)合模型的動機在于,不同的深度學(xué)習(xí)技術(shù)可以互相補充,并能夠提供更強大的混合模型[16].
1.2 融合注意力機制的推薦模型
注意力機制的思想是由人類的視覺系統(tǒng)以及人的眼睛如何關(guān)注和集中于圖像的特定部分或者句子中的特定單詞所激發(fā)的[13].它的核心邏輯是從關(guān)注全部到關(guān)注重點,并非所有的輸入信息都同等重要,只有一小部分信息對模型起關(guān)鍵作用,深度學(xué)習(xí)中的注意力可以簡單地描述為權(quán)重向量,用來顯示輸入元素的重要性.注意力機制最早使用在圖像分類任務(wù)中[20],當(dāng)看一張圖片時,一般不會關(guān)注圖片的全部內(nèi)容,而是將注意力集中在圖片的部分焦點上.后來研究者將其引入自然語言處理領(lǐng)域,成功提升了機器翻譯的性能.目前,在不同的推薦任務(wù)中也使用了注意力機制[21-22].例如MPCN[21]結(jié)合評論級和文本級信息解決文檔級問題,通過利用指針網(wǎng)絡(luò)挑出重要的評論從而用來建模當(dāng)前的用戶項目矩陣.此外,NAIS[22]使用注意力網(wǎng)絡(luò)區(qū)分用戶配置文件中的項目,這些項目在模型預(yù)測中具有更大的影響力.
2 多頭注意力卷積矩陣分解模型
本節(jié)將對MACMF的原理和主要模塊進行詳細介紹.首先介紹概率矩陣分解模型,描述了組合概率矩陣分解和融合注意力機制的卷積神經(jīng)網(wǎng)絡(luò)的主要思想.接下來,給出了融合注意力機制的卷積神經(jīng)網(wǎng)絡(luò)的詳細架構(gòu),說明了MACMF模型可以通過分析項目描述文檔產(chǎn)生項目的潛在因子.最后,描述了優(yōu)化MACMF模型的方法.
2.1 MACMF概率模型
本研究在ConvMF模型結(jié)構(gòu)圖的基礎(chǔ)上改進得到圖1 所示的MACMF模型結(jié)構(gòu),該模型在卷積神經(jīng)網(wǎng)絡(luò)的嵌入層和卷積層之間加入多頭注意力機制,將融合多頭注意力機制的卷積神經(jīng)網(wǎng)絡(luò)模型(multi-head attention convolutional neural network,MACNN)集成到概率矩陣分解(probabilistic matrix factorization,PMF)中.
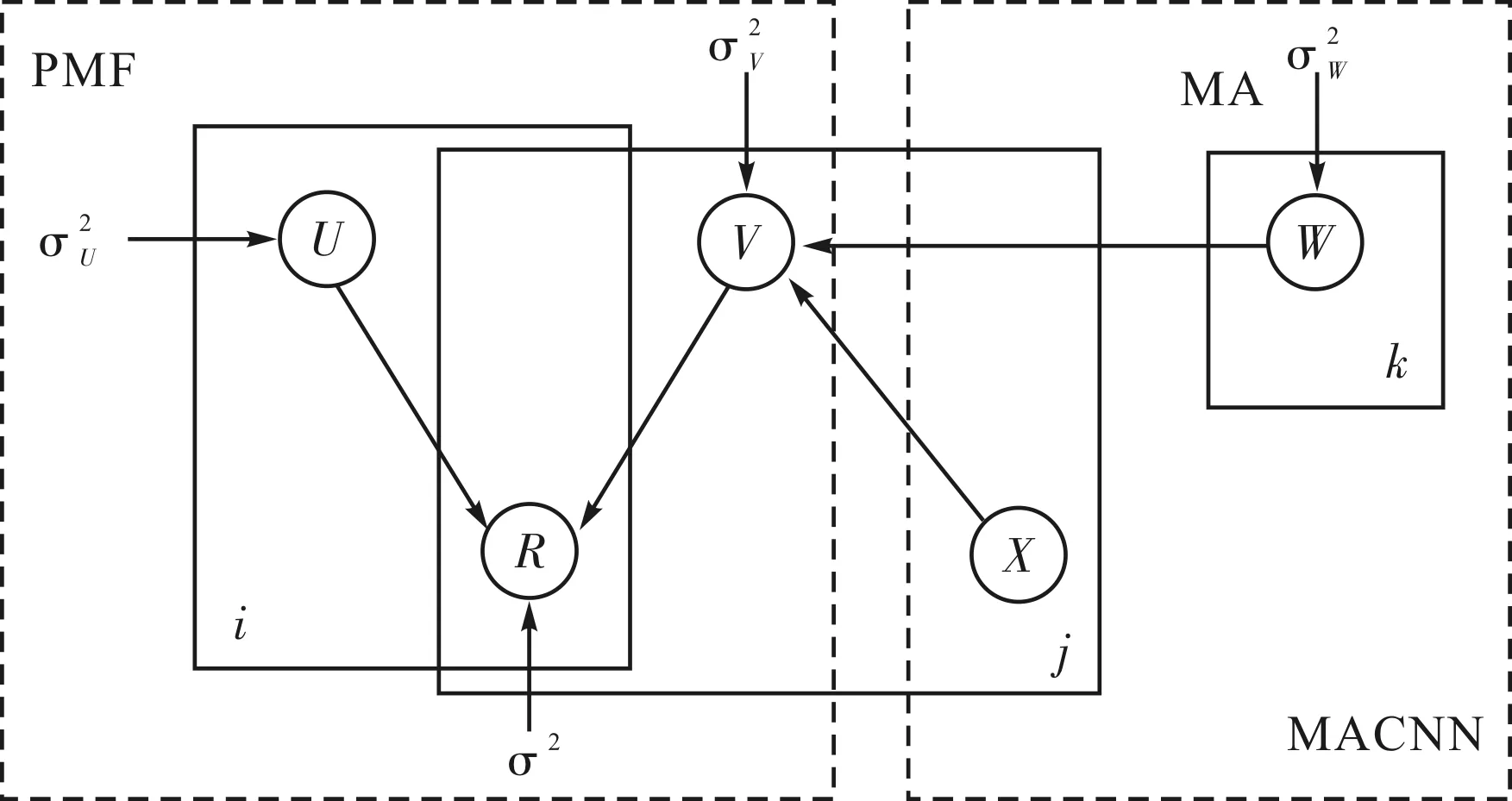
圖1 MACMF模型結(jié)構(gòu)Fig.1 MACMF model structure
假設(shè)有N個用戶和M個項目,目標是找到用戶和項目的潛在因子,將它們的乘積重構(gòu)評分矩陣.
p(R∣U,V,σ2)=∏∏N(Rij∣Ui,Vj,σ2),
(1)
其中,N是均值為μ、方差為σ2的零高斯正態(tài)分布的概率密度函數(shù).作為用戶潛在模型的生產(chǎn)模型,將零均值的球面高斯先驗放在方差為σ2的用戶的潛在因子上.
圖1中U為用戶的潛在因子,V為項目的潛在因子,R為評分矩陣,Xj表示項目j的描述文檔,W為內(nèi)部權(quán)重.從MACNN模型獲得的文檔潛在向量用作高斯分布的均值,項目的高斯噪聲用作高斯分布的方差,這是MACNN和PMF之間的橋梁,有助于將文本特征與評分矩陣組合在一起分析.
2.2 融合多頭注意力的MACMF
本研究中的MACNN體系結(jié)構(gòu)是在卷積神經(jīng)網(wǎng)絡(luò)的嵌入層和卷積層之間加入多頭注意力機制,目的是從電影的描述文檔信息中獲取項目的潛在因子.該體系結(jié)構(gòu)包含五層:1) 嵌入層;2) 多頭注意力層;3) 卷積層;4) 池化層;5) 輸出層.
嵌入層是根據(jù)單詞的長度將原始文檔轉(zhuǎn)換成數(shù)字矩陣,然后輸出到下一層.如果有一個單詞,通過將文檔中單詞的嵌入向量進行級聯(lián)對文檔進行矩陣表示.然后,通過優(yōu)化過程進一步訓(xùn)練詞向量.
多頭注意力層選擇重要特征.多頭注意力機制首先將向量信息經(jīng)過一個線性變換,然后將其輸入到縮放點積注意力中,總計做h次,每一次算一個頭,頭之間參數(shù)不共享,然后將h次的縮放點積注意力結(jié)果進行拼接,最后進行一次線性變換得到的值作為多頭注意力的結(jié)果.
(2)
MultiHead(Q,K,V)=
Concat(head1,…,headh)WO.
(3)
公式表明多頭注意力的不同之處在于進行h次計算而不僅僅算一次,這樣的優(yōu)點是可以允許模型在不同的表示子空間里學(xué)習(xí)相關(guān)的有用信息[23].
卷積層提取上下文特征.由于文檔在上下文信息的本質(zhì)上與信號處理或計算機視覺不同,因此使用NLP中的特定卷積架構(gòu)正確提取文檔特征.在卷積層中,采用窗口大小分別為1、3、5、7的一維卷積核對詞向量矩陣進行上下文特征提取.
池化層不僅從卷積層中提取代表性特征,而且還通過構(gòu)建固定長度特征向量的合并操作處理可變長度的文檔.在池化層中,采用k-max-pooling技術(shù)提取代表性特征.k-max-pooling認為每一塊不只一個點重要,前幾個點可能都比較重要,所以在每一個pooling塊中取前k大的值.
(4)
在輸出層,通過轉(zhuǎn)換從上一層獲得的高級功能以用于特定任務(wù).為推薦任務(wù)投影了用戶和項目的潛在因子的K維空間,最終通過使用常規(guī)的非線性投影生成文檔的潛在向量.
2.3 最大后驗估計優(yōu)化方法
為了優(yōu)化模型,例如用戶的潛在因子和項目的潛在因子,MACNN的權(quán)重和偏差參數(shù),使用最大后驗估計優(yōu)化變量U、V和W,操作如下:
(5)
通過對式(5)等號兩邊取負對數(shù),將其重構(gòu)為最小化損失函數(shù)L.
我家住在三樓,樓層并不算高,不知何故,一氣上樓,竟累得我氣喘吁吁的,躺在床上,休息了半個多小時,也硬是沒有歇過來。
L(U,V,W)=
(6)
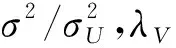
采用坐標下降法最小化L,在固定其余變量的同時迭代優(yōu)化潛在變量,式(6)為關(guān)于U的二次函數(shù),同時暫時假定V和W為常數(shù),可以通過Ui微分求損失函數(shù)L.對V采取同樣的操作得到如下表示,ui←(VIiVT+λUIK)-1VRi,
(7)
vj←(UIjUT+λVIK)-1(URj+λVMACNNW(Xj) ),
(8)
其中,Ii、Ij、IK為單位對角矩陣,λU和λV為平衡參數(shù).式(8)顯示了文檔潛在向量MACNN(即MACNNW(Xj))通過λV更新vj作為平衡參數(shù)的效果.
然而,無法像處理U和V那樣更新W,因為W和MACNN體系結(jié)構(gòu)中的非線性相關(guān).眾所周知,當(dāng)U和V暫時恒定時,損失函數(shù)L可以解釋為L2的正則項加權(quán)平方誤差函數(shù).得到ε(W)如下式,
(9)
同樣的,使用在神經(jīng)網(wǎng)絡(luò)中通用的反向傳播算法求得公式(10),優(yōu)化W直至收斂或者達到預(yù)定義的迭代次數(shù)為止.
?wkε(W)=
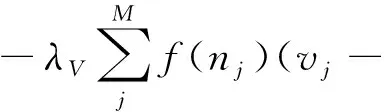
(10)
通過優(yōu)化U、V、W,最終可以得到預(yù)測的用戶對項目的未知評分信息.
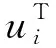
(11)
其中,Vj=MACNNW(Xj)+εj.算法流程圖如下所示.

算法1 MACMF算法輸入:用戶項目評分矩陣R,電影簡介信息X.目標:優(yōu)化潛在因子U、V和W1:隨機初始化U和W2: for j ≤M do3: 通過vj ←MACNNW (Xj )初始化V4:end for5:重復(fù)6:for i≤N do 更新 ui←(VIi VT+λU IK )-1VRi end for for j ≤M do 更新 vj←(UIj UT+λV IK )-1(URj+λV MACNNW (Xj ) ) end for 重復(fù) for j ≤M do wk ε(W)=-λV Mjf(nj )(vjwk MACNNW (Xj ) )+λW wk end for 直到收斂直到滿足早期停止使用驗證集.
3 實驗結(jié)果與分析
本節(jié)使用來自不同領(lǐng)域的四個數(shù)據(jù)集評估MACMF模型的性能,并將MACMF模型與五個經(jīng)典的基線算法進行比較,同時分析不同超參數(shù)對本文提出的MACMF模型的實驗結(jié)果的影響.
3.1 數(shù)據(jù)集及其預(yù)處理
為評估MACMF方法的效果,在MovieLens[24]和Amazon[25]兩個公開數(shù)據(jù)集上進行測試.原始的MovieLens數(shù)據(jù)集包含72 000個用戶,10 681部電影和10 000 054個評分數(shù)據(jù),評分范圍為1到5分.本實驗采用它的三個子集,分別為ML-100k,ML-1m和ML-10m.為了將用戶的評分數(shù)據(jù)和相應(yīng)的評論數(shù)據(jù)關(guān)聯(lián),從IMDB網(wǎng)站上收集了相關(guān)電影的簡介信息.Amazon數(shù)據(jù)集既包含用戶的評分,又包含評論信息.兩個數(shù)據(jù)集都非常稀疏.
為進行公平的比較,采用與文獻[8]相同的方式對原始數(shù)據(jù)集做了預(yù)處理工作:刪除了MovieLens中沒有包含電影簡介信息的項目,并刪除Amazon數(shù)據(jù)集中評分低于3項的用戶.經(jīng)過預(yù)處理之后的數(shù)據(jù)集信息如表1所示.對于文本信息,通過以下步驟進行預(yù)處理:將原始文檔的最大長度設(shè)置為300,去掉停用詞;計算每個詞的TF-IDF值作為特征值,刪除文檔頻率高于0.5的詞;最后選擇前8 000個詞作為詞匯表.在對文本進行處理時,采用預(yù)訓(xùn)練的詞嵌入模型Glove轉(zhuǎn)化為300維詞向量,生成300×300的詞向量矩陣作為卷積神經(jīng)網(wǎng)絡(luò)的輸入.
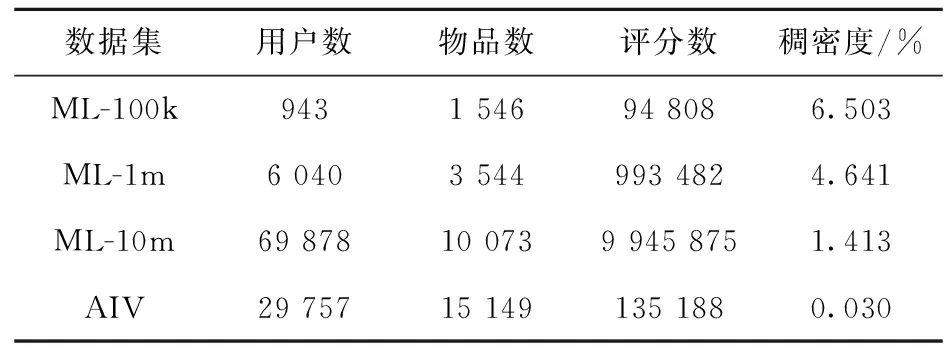
表1 四個經(jīng)過預(yù)處理的數(shù)據(jù)集統(tǒng)計結(jié)果
3.2 對比模型及軟硬件環(huán)境
為評估模型的性能,選擇五種經(jīng)典模型作為基線算法.
PMF[26]:概率矩陣分解是一種通用的基線方法,它可以根據(jù)用戶和項目的潛在特征預(yù)測用戶評分.潛在特征代表用戶的不同興趣點.這種方法的前提假設(shè)是用戶和項目的評分都服從高斯分布.
CTR[27]:協(xié)作主題回歸是一個緊密耦合的模型,該模型將協(xié)同過濾PMF和潛在狄利克雷分配(Latent Dirichlet Allocation,LDA)相結(jié)合.該模型嘗試將評分和文本信息結(jié)合預(yù)測評分.
CDL[28]:協(xié)作深度學(xué)習(xí)是一種新提出的深度貝葉斯模型,該模型使用精心設(shè)計的深度學(xué)習(xí)模型堆疊式降噪自編碼器預(yù)測評分,試圖從輔助信息中提取用戶的偏好.
ConvMF[8]:卷積矩陣分解是最新的上下文感知推薦模型之一,該模型將卷積神經(jīng)網(wǎng)絡(luò)集成到PMF中,學(xué)習(xí)文檔上下文的文本特征.
ConvMF+[8]:此方法是在ConvMF的方法的基礎(chǔ)上通過使用預(yù)訓(xùn)練的詞嵌入模型Glove擴展應(yīng)用.
本實驗軟件環(huán)境為集成開發(fā)平臺PyCharm Community Edition 2020.1.1 x64,Python 3.7,Keras 2.3.1.硬件環(huán)境為Intel Core i7 4790K 4.00 GHz CPU,GeForce GTX 1080 GPU、32GB內(nèi)存和1T存儲空間.
3.3 評價指標
推薦系統(tǒng)的評價指標通常分為三類[29]:1) 預(yù)測準確性指標(例如RMSE和MAE),主要用于評估推薦系統(tǒng)預(yù)測評分的準確性;2) 分類準確性度量(例如Precision和Recall),用于測量推薦系統(tǒng)做出正確決策的頻率;3) 排名準確性度量(例如DCG和MAP),評估由推薦系統(tǒng)執(zhí)行的項目排名的正確性.本文的目標是做評分預(yù)測,因此采用RMSE和MAE作為評價指標.通常RMSE和MAE可以表示如下:
(12)
(13)

3.3 實驗結(jié)果
表2展示了MACMF和五個基線算法的總體評分預(yù)測誤差.表中長短期記憶網(wǎng)絡(luò)矩陣分解(long short-term memory matrix factorization,LSTMMF)是將所提MACMF模型中的CNN部分替換為LSTM所得到的實驗結(jié)果.其中,最后一行表示本文模型相對于基線算法在每組數(shù)據(jù)集中最佳結(jié)果(粗體標識基線模型的最優(yōu)效果,下劃線標識每組數(shù)據(jù)集的最佳效果)的提升,分別2.07%、1.12%、0.79%和2.68%.表明多頭注意力機制在卷積層之前選擇了對推薦結(jié)果有影響的重要特征.可見,對于四組數(shù)據(jù)集,MACMF均能達到最好的RMSE值.
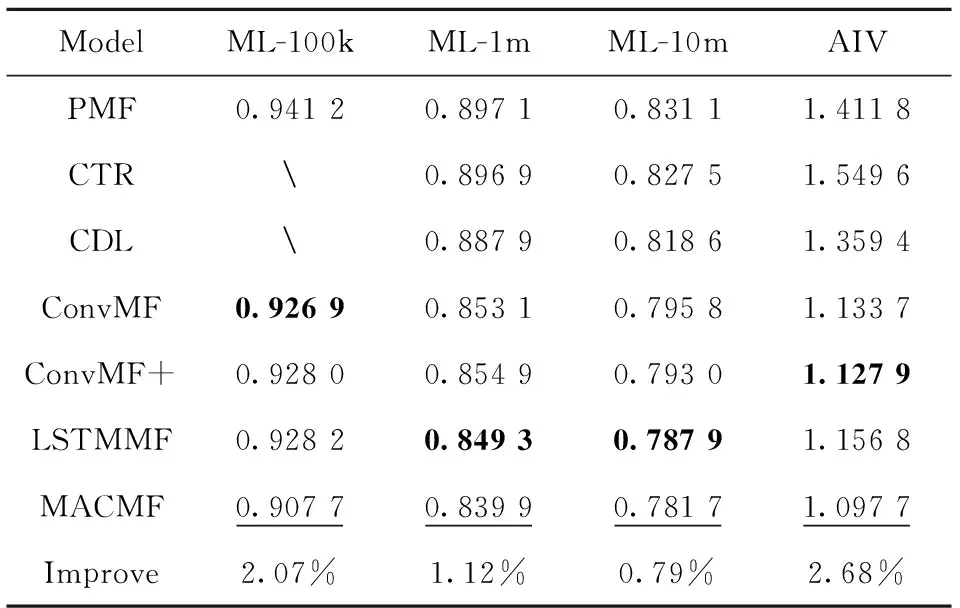
表2 四個數(shù)據(jù)集上的評價結(jié)果
表3給出了在不同λu和λv組合值下,RMSE和MAE的變化情況.實驗結(jié)果表明,(λu,λv)在ML-100k、ML-1m、ML-10m和AIV上分別取(2,50)、(2,210)、(8,50)、(1,40)時,MACMF模型能取得最好的結(jié)果,說明合適的λu和λv組合可以有效地平衡評分信息和物品描述文檔信息,從而降低MACMF模型的RMSE和MAE值.
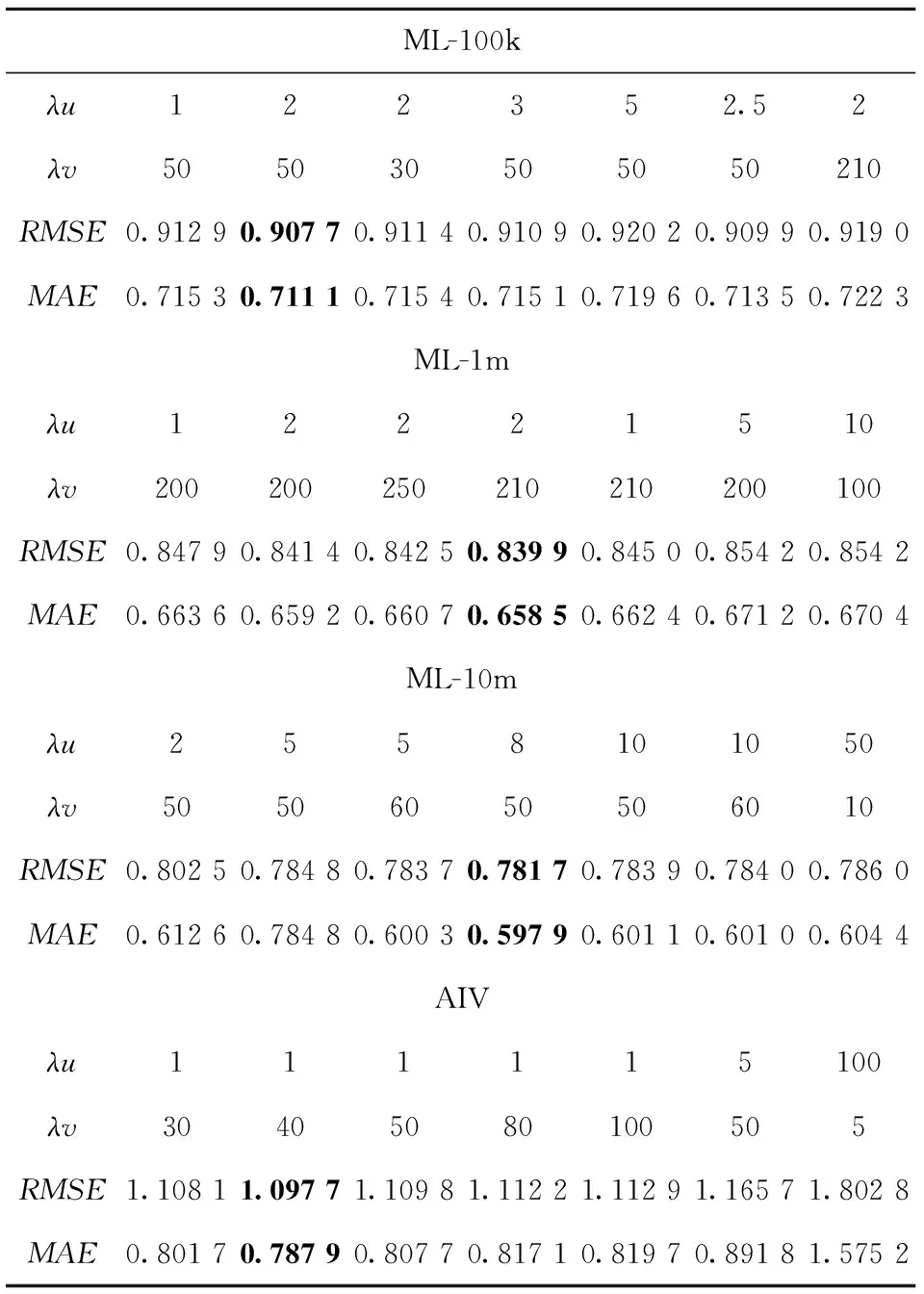
表3 λu和 λv 在四個數(shù)據(jù)集上對RMSE和MAE的結(jié)果影響
此外,還研究了訓(xùn)練數(shù)據(jù)的比例如何影響模型性能.將ML-1m數(shù)據(jù)集的密度從20%提高到80%,相應(yīng)的RMSE結(jié)果如圖2所示.從中可看出,MACMF模型始終表現(xiàn)最佳,而且ConvMF是次佳的.隨著訓(xùn)練數(shù)據(jù)比例的增加,所有方法的RMSE均逐漸下降,這與研究的預(yù)判相同,即隨著訓(xùn)練數(shù)據(jù)增加,模型的性能也隨之提高.
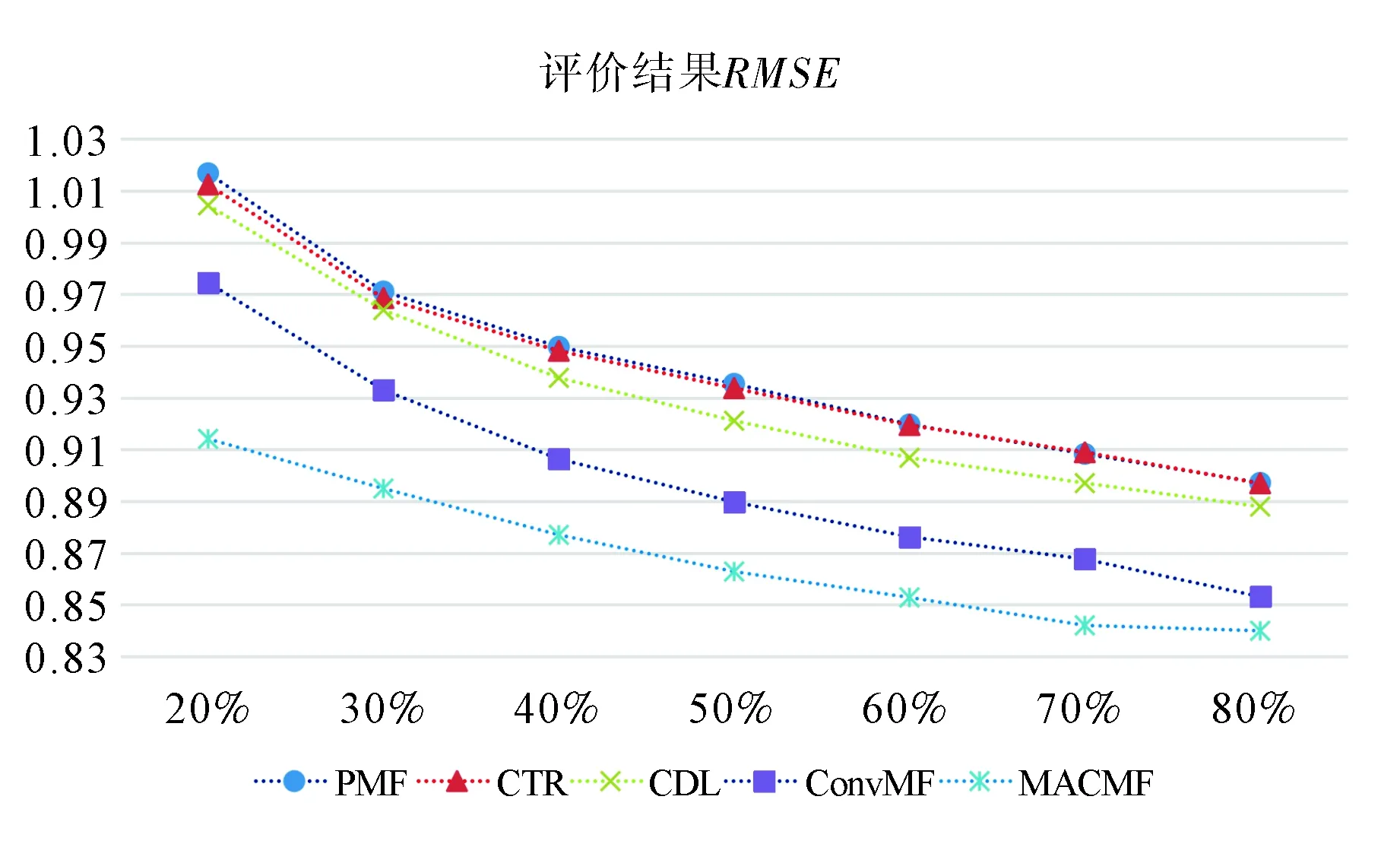
圖2 調(diào)整不同訓(xùn)練數(shù)據(jù)的百分比對評價結(jié)果的影響Fig.2 Effect of adjusting percentages of different training data on evaluation results
多頭的本質(zhì)是多個獨立的注意力計算,作為一個集成作用,防止過擬合,同文獻[14]中輸入序列是完全一樣的;Q、K、V通過線性轉(zhuǎn)換,每個注意力機制的函數(shù)只負責(zé)最終輸出序列中一個子空間,而且相互獨立.深度學(xué)習(xí)技術(shù)的超參數(shù)眾多,不同的超參數(shù)組合對實驗結(jié)果產(chǎn)生極其重大的影響,本實驗通過大量的實驗得出了MACMF模型的最佳組合結(jié)果.
4 結(jié)論及展望
本文提出融合注意力機制的深度卷積神經(jīng)網(wǎng)絡(luò)模型MACMF,通過將多頭注意力機制的卷積神經(jīng)網(wǎng)絡(luò)巧妙地融合到PMF框架中,多頭注意力機制在CNN的嵌入層和卷積層之間,增強了CNN模型的特征選擇和提取能力,有效防止過擬合,通過大量參數(shù)的調(diào)整使得模型達到了最佳性能.并通過多組實驗分析了實驗的具體參數(shù)對實驗結(jié)果的影響,特別是通過利用LSTM與PMF融合的LSTMMF模型的對比結(jié)果,檢驗了本文提出的MACMF模型的有效性.大量實驗結(jié)果表明,MACMF可以從文本上下文中提取更多的物品潛在因子,從而提高模型的性能.
雖然本文所提模型取得了較好的效果,但是未來還存在繼續(xù)改進的可能性.主要表現(xiàn)在如下幾個方面,第一是評論文本特征提取有巨大的發(fā)展空間,隨著人工智能在自然語言處理領(lǐng)域取得的不斷突破,將有更高效更精準的評論文本特征提取模型產(chǎn)生,可以為基于評論文本的深度推薦系統(tǒng)獲得更大的發(fā)展空間,取得更好的效果.第二是用戶、項目以及用戶-項目上下文信息紛繁復(fù)雜,呈現(xiàn)多源異構(gòu)性,如何從這些海量的輔助信息中提取對推薦結(jié)果產(chǎn)生影響的因子是未來的重要研究方向.例如模型中沒有考慮對用戶輔助信息的特征挖掘、對用戶進行畫像、利用用戶的相關(guān)信息提取用戶的潛在因子,預(yù)測可以進一步提升模型的準確率,為線上用戶提供更加個性化的視頻資源推薦服務(wù).第三是海量特征提取后的特征融合以及時間因素對特征的影響.當(dāng)提取出多源異構(gòu)輔助信息后,調(diào)節(jié)各種輔助信息之間的作用大小是重要的研究點.用戶的興趣偏好存在動態(tài)性,會隨著時間不斷發(fā)生變化,如何提取用戶的動態(tài)偏好特征也是下一步的研究難點.總而言之,利用物聯(lián)網(wǎng)技術(shù)全方位采集數(shù)據(jù),然后通過大數(shù)據(jù)和人工智能技術(shù)從海量數(shù)據(jù)中挖掘影響推薦結(jié)果的影響因素是進一步研究的熱點.
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
