基于雙源自適應知識蒸餾的輕量化圖像分類方法
2023-10-26 06:50:30張凱兵馬東佟孟雅蕾
西安工程大學學報 2023年4期
張凱兵,馬東佟,孟雅蕾
(1.西安工程大學 電子信息學院,陜西 西安 710048; 2.西安工程大學 計算機科學學院,陜西 西安 710048)
0 引 言
近年來,隨著深度學習技術(shù)的迅速發(fā)展,計算機視覺領(lǐng)域逐漸得到廣泛應用,同時在圖像分類[1]和識別技術(shù)方面取得了顯著進展。然而,大多數(shù)有關(guān)圖像分類的研究都是基于大型深度神經(jīng)網(wǎng)絡(luò)或其集合上的,模型有數(shù)百萬個參數(shù)。隨著模型參數(shù)量的增加,訓練過程也需要耗費大量的計算資源,導致訓練好的模型難以直接部署到開發(fā)板、移動終端以及可穿戴的嵌入式設(shè)備上,從而影響深度學習模型的實際應用。知識蒸餾[2]作為一種有效的模型輕量化方法,已經(jīng)被廣泛研究并取得了顯著的成果,其成果已應用于各種計算機視覺任務[3-4]。
知識蒸餾指的是將復雜的教師網(wǎng)絡(luò)的知識傳遞給一個輕量化的學生網(wǎng)絡(luò),從而提高學生網(wǎng)絡(luò)的泛化能力和性能。根據(jù)從教師網(wǎng)絡(luò)中所獲取知識的類型,現(xiàn)有的知識蒸餾方法可以分為以下3類:基于軟標簽知識的蒸餾方法、基于特征層知識的蒸餾方法和基于結(jié)構(gòu)化知識的蒸餾方法。基于軟標簽知識的蒸餾方法簡單易懂,主要依賴于教師網(wǎng)絡(luò)最后一層的輸出,通過促使學生網(wǎng)絡(luò)學習教師網(wǎng)絡(luò)的最終預測,從而達到與教師網(wǎng)絡(luò)相近或更優(yōu)的性能。文獻[5]最早提出通過一個溫度系數(shù)對教師網(wǎng)絡(luò)的輸出概率分數(shù)進行軟化,然后作為軟目標來指導學生網(wǎng)絡(luò)。文獻[6]提出了一種教師助教蒸餾方法,首先將助教網(wǎng)絡(luò)作為學生從教師網(wǎng)絡(luò)學習軟標簽知識,然后再指導學生網(wǎng)絡(luò)的訓練。基于特征層知識的蒸餾方法通過對齊教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)中間層的特征,從而使學生網(wǎng)絡(luò)學習到教師網(wǎng)絡(luò)特征層的高級語義信息。文獻[7]提出通過對齊教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)中間層的注意力特征圖來實現(xiàn)知識的遷移;文獻[8]提出最小化教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)之間的激活邊界差異,從而將知識傳遞給學生網(wǎng)絡(luò);文獻[9]分別對教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)的特征進行了空間池化金字塔[10]處理,然后使用L2距離來度量兩者之間的距離。基于軟標簽知識和特征層知識的蒸餾方法都使用教師網(wǎng)絡(luò)中特定層的輸出,而基于結(jié)構(gòu)化知識的蒸餾方法進一步探索不同輸入樣本之間的關(guān)系或者不同層之間的關(guān)系等結(jié)構(gòu)化知識。文獻[11]提出通過模仿教師網(wǎng)絡(luò)生成的解決方案流程矩陣來實施對學生網(wǎng)絡(luò)訓練的指導;文獻[12]提出將不同樣本之間的角度關(guān)系和距離關(guān)系作為知識,使學生網(wǎng)絡(luò)學習到教師網(wǎng)絡(luò)對不同類別樣本豐富的結(jié)構(gòu)化知識。
盡管現(xiàn)有的大多數(shù)知識蒸餾方法取得了一定的研究進展,但仍然存在一些明顯的局限性。一方面,大多數(shù)基于特征層知識的蒸餾方法通過最小化教師特征和學生特征之間的距離來傳遞知識,需要先將教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)的特征變換到同一維度,再進行特征對齊。然而,在特征變換的過程不可避免地會導致信息丟失,同時也增加了計算復雜度。另一方面,基于軟標簽知識的蒸餾方法通過使用一個帶有溫度系數(shù)的softmax層來軟化輸出概率分數(shù),然后將其作為訓練學生網(wǎng)絡(luò)的軟目標。然而,對所有訓練樣本使用恒定的溫度系數(shù)忽略了不同數(shù)據(jù)樣本之間的差異,會限制學生網(wǎng)絡(luò)對教師網(wǎng)絡(luò)軟標簽中有價值信息的學習。
針對以上問題,本文提出了一種新穎的DSAKD方法,從教師網(wǎng)絡(luò)的特征層和軟標簽中獲取雙源類型的知識,從而進一步提高輕量化學生網(wǎng)絡(luò)的性能。首先,對于教師網(wǎng)絡(luò)特征層的知識,提出了一個特征自適應融合模塊分別將教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)中間層不同尺度的特征融合在一起。然后,為了更好地遷移教師網(wǎng)絡(luò)的特征層知識,本文提出了一種特征嵌入對比蒸餾策略,將融合后的教師特征和學生特征投影到統(tǒng)一的嵌入子空間[13]中進行知識遷移。最后,對原有的軟標簽蒸餾方法進行改進,提出了一種自適應溫度蒸餾策略,根據(jù)教師網(wǎng)絡(luò)對每個樣本的預測置信度為所有樣本自適應分配不同的溫度系數(shù),從而為學生網(wǎng)絡(luò)提供更有判別性的軟標簽。
1 DSAKD方法
本文提出的DSAKD方法通過從教師網(wǎng)絡(luò)的特征層和軟標簽中獲取多種類型的知識,并通過構(gòu)造合適的蒸餾損失將知識遷移到學生網(wǎng)絡(luò)中,從而進一步提高輕量化學生網(wǎng)絡(luò)的性能。具體來講,該方法主要由多層特征自適應融合、特征嵌入對比蒸餾和自適應溫度蒸餾3個階段組成,整體框架如圖1所示。
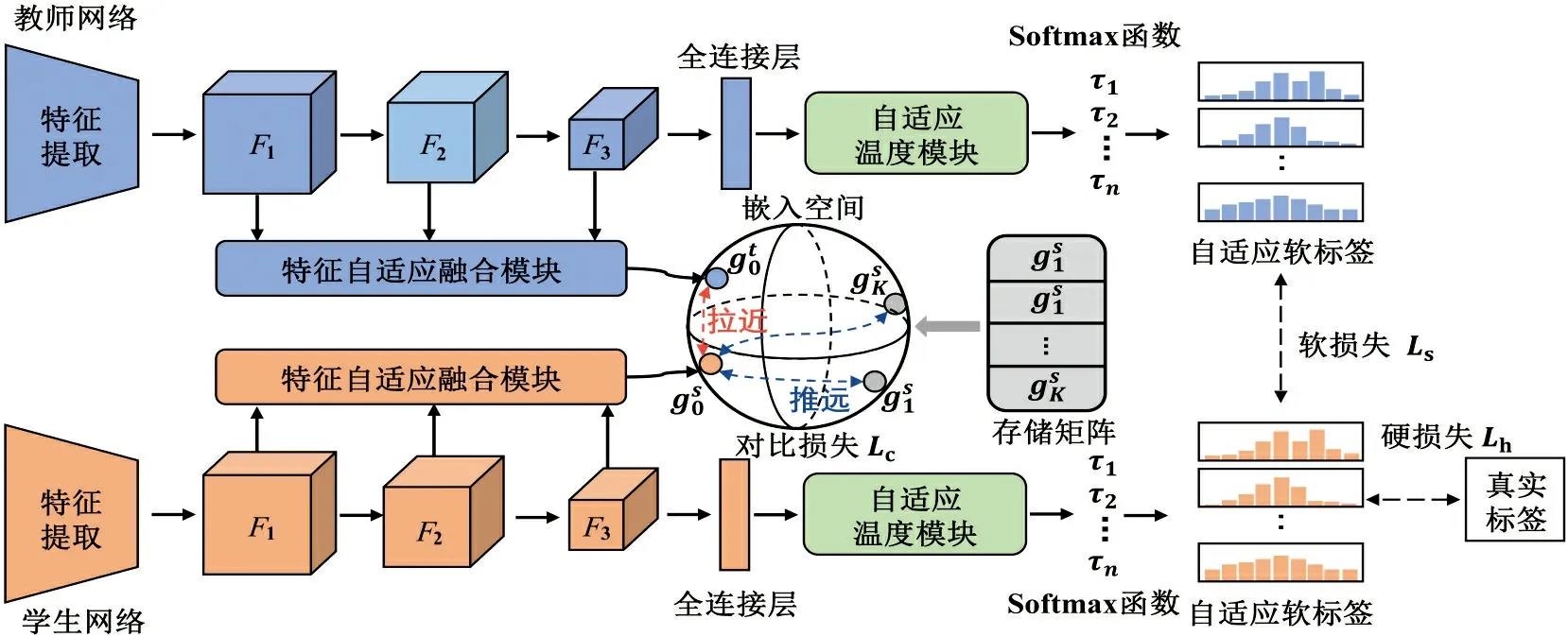
圖1 DSAKD方法總體框架Fig.1 Overall framework of DSAKD method
圖1中,第一階段對教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)的多尺度特征進行自適應融合:對于一張訓練樣本{x0,y0},送入教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)中進行特征提取,分別提取到教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)第k層的特征Fk(k=1,2,3)。然后,將提取到的多尺度特征通過特征自適應融合模塊進行自適應融合,從而得到包含更豐富知識的教師特征和學生特征。
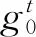
第三階段主要對教師網(wǎng)絡(luò)的軟標簽知識進行學習:通過提出的自適應溫度蒸餾策略對每個樣本自適應地設(shè)置不同的溫度參數(shù),進而從教師網(wǎng)絡(luò)中提取到更有信息量的軟標簽知識。
1.1 特征自適應融合模塊
由于卷積神經(jīng)網(wǎng)絡(luò)不同層次的特征旨在編碼不同類型的信息,網(wǎng)絡(luò)淺層學習到的主要是邊緣和紋理等低級特征,深層學習到的主要是更加抽象的高級語義特征。為了充分利用網(wǎng)絡(luò)提取到的低層紋理特征和高層語義特征信息,同時考慮到兩者之間的互補性,本文采用圖2所示的基于注意力融合的方式對多層特征進行自適應融合[14],得到更有互補性的教師特征對學生網(wǎng)絡(luò)的特征進行指導。

圖2 特征自適應融合模塊Fig.2 The illustration of the feature adaptive fusion module
如圖2所示,本文提出的特征自適應融合模塊主要包含兩步:特征圖調(diào)整和自適應特征融合。將網(wǎng)絡(luò)中間特征層不同尺度的特征表示為Fk(k=1,2,3)(例如,在ResNet網(wǎng)絡(luò)中表示每個殘差塊的輸出),由于淺層特征的特征圖尺寸大,通道數(shù)少,首先采用下采樣策略對淺層特征進行調(diào)整。對于1/2倍的下采樣,使用步長為2的卷積,同時改變淺層特征的特征圖尺寸和通道數(shù);對于1/4倍的下采樣,在上述操作的基礎(chǔ)上,在卷積層之前加入一個步長為2的最大池化層。將調(diào)整到同一尺寸的特征進行自適應融合,計算過程可表示為
(1)

1.2 特征嵌入對比蒸餾模塊

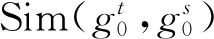

(3)
式中:θ為學生網(wǎng)絡(luò)的參數(shù);τ為溫度系數(shù),控制了模型對負樣本的區(qū)分度;K為負樣本數(shù);M為數(shù)據(jù)集的訓練樣本總數(shù)。
通過特征嵌入對比蒸餾模塊對學生網(wǎng)絡(luò)進行優(yōu)化,進一步擴大了教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)之間的類內(nèi)相似度和類間差異,確保了樣本間結(jié)構(gòu)知識的一致性,使學生網(wǎng)絡(luò)從教師網(wǎng)絡(luò)的特征層中學習到更有價值的知識,從而獲得了性能收益。
如文獻[15]所述,為了確保對比學習的性能,需要大量的負樣本。而一個正樣本對就需要K個負樣本,進行(K+1)次的運算,極大地增加了訓練負擔。為了解決這一問題,本文采用文獻[16]的思想,通過構(gòu)造一個存儲體M∈RN×d來存儲所有訓練樣本的d維嵌入特征,只對每次正向傳播中的正樣本進行更新,從而確保了計算效率。具體來講,當批大小設(shè)置為1時,M的更新遵從下式:
(4)
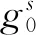
1.3 自適應溫度蒸餾模塊
在原始知識蒸餾框架中,通過使用一個帶有溫度系數(shù)的softmax函數(shù)對教師網(wǎng)絡(luò)的輸出概率分數(shù)進行軟化,然后將其作為訓練學生網(wǎng)絡(luò)的軟目標。此后,這種基于溫度的知識蒸餾策略[17]引起了廣泛研究者的興趣并取得了巨大的成功。然而,最近關(guān)于解耦知識蒸餾的研究發(fā)現(xiàn),知識蒸餾的性能受訓練樣本難度的影響。具體來說,文獻[18]認為高置信度樣本具有大量的有用信息,但這些樣本在原有的軟標簽蒸餾中貢獻卻很小。因此,本文對原有的軟標簽蒸餾方法進行改進,提出了一種自適應溫度蒸餾策略。
知識蒸餾的思想最早是在文獻[5]中提出的,拿一張“貓”圖片舉例,模型輸出它為“狗”的概率比“飛機”的概率要高很多,這些錯誤的概率包含了不同別之間豐富的知識,并揭示了一個模型傾向于怎樣泛化。軟標簽蒸餾方法通過定義一個溫度系數(shù),將大模型的輸出logits轉(zhuǎn)化為軟化的概率預測分數(shù),來監(jiān)督小模型的訓練,這一過程表示為
(5)
其中:zi和vi分別為教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)的logits;τ為溫度系數(shù)。
不同于現(xiàn)有的大多數(shù)知識蒸餾方法使用一個固定的溫度系數(shù)(根據(jù)經(jīng)驗通常設(shè)置為4),本文對原始的軟標簽蒸餾方法進行改進,提出了一種自適應溫度蒸餾方法。具體來講,針對不同的訓練樣本,根據(jù)教師網(wǎng)絡(luò)預測的置信度大小,自適應地給所有訓練樣本分配不同的溫度系數(shù)。對于那些相對難以識別的樣本,當教師網(wǎng)絡(luò)預測的不確定性高時,給予這些樣本較小的溫度系數(shù)來擴大類間差異;對于那些易于學習的樣本,給予它們較大的溫度系數(shù)從而更有效地利用類間信息。本文提出的自適應溫度蒸餾損失如下式所示:
(6)
式中:τi為自適應溫度系數(shù)。τi的計算公式如下:
τi=τmax-(τmax-τmin)·σ(-∑(φ(zi)·
lnφ(zi)))
(7)
式中:σ(·)為tanh激活函數(shù);φ(·)為softmax函數(shù);通過定義τmax和τmin溫度系數(shù)τi限制在一個固定范圍內(nèi)。
通過教師網(wǎng)絡(luò)對每個訓練樣本預測概率的熵值來衡量對該樣本的預測置信度,熵越高說明教師網(wǎng)絡(luò)對該樣本的預測不確定性越高[19],通過式(7)為該樣本分配較小的溫度系數(shù),從而得到更有判別性的軟標簽。
1.4 損失函數(shù)設(shè)計
綜上所述,學生網(wǎng)絡(luò)在特征嵌入對比蒸餾損失、自適應溫度蒸餾損失和真實標簽損失的聯(lián)合指導下進行訓練,進而從教師網(wǎng)絡(luò)的特征層和軟標簽中獲取更有價值的知識,訓練階段總的損失函數(shù)可以表示為
Ltotal=Lcls+λ·Lcon+μ·Latd
(8)
式中:λ和μ分別為對比蒸餾損失和自適應溫度蒸餾損失的權(quán)值系數(shù);Lcls為學生網(wǎng)絡(luò)的分類損失。Lcls的定義如下:
式中:Lce為交叉熵損失;vi為學生網(wǎng)絡(luò)輸出的logits;y為樣本的真實標簽。
1.5 評價指標
本文實驗采用準確率[20](A)對學生網(wǎng)絡(luò)的分類結(jié)果進行評估,計算過程如下:
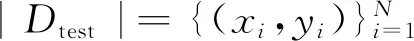
2 實驗結(jié)果與分析
在本節(jié)中,首先對實驗所用到的數(shù)據(jù)集、主干網(wǎng)絡(luò)和參數(shù)設(shè)置進行了介紹,然后分別在3個數(shù)據(jù)集上開展了一系列對比實驗來驗證本文提出的DSAKD方法的有效性,最后進行了模塊的消融實驗并對超參數(shù)進行了分析。
2.1 數(shù)據(jù)集介紹
本文在CIFAR10、CIFAR100和ImageNet 3個基準的圖像分類數(shù)據(jù)集上進行實驗,通過與其他幾種不同的蒸餾算法比較來驗證本文所提出的DSAKD方法的有效性。CIFAR10和CIFAR100數(shù)據(jù)集都是由60 000張32×32大小的彩色圖像組成。其中前者包含10個類別,每個類別有6 000張圖像;而后者包含100個類別,每個類別有600張圖像。CIFAR100數(shù)據(jù)集由于類別數(shù)量更多且每個類別的訓練樣本數(shù)量更少,因此分類難度相對CIFAR10數(shù)據(jù)集更大。除此之外,考慮到CIFAR10和CIFAR100數(shù)據(jù)集都是32×32大小的圖像,并不能代表自然場景中的圖像,本文還在更具有挑戰(zhàn)性的ImageNet數(shù)據(jù)集[21]上進行實驗。該數(shù)據(jù)集共包含128萬張訓練樣本,涵蓋了來自1 000個不同類別的物體和場景,每個類別約有1 000個訓練樣本,并包括50個驗證樣本和100個測試樣本。
2.2 實驗設(shè)置
本文選擇多種不同類型的網(wǎng)絡(luò)作為主干網(wǎng)絡(luò)來開展實驗,包括:ResNet網(wǎng)絡(luò)、VGG網(wǎng)絡(luò)、WideResNet網(wǎng)絡(luò)以及更輕量化的MobileNet網(wǎng)絡(luò)和ShuffleNet網(wǎng)絡(luò),所有的實驗都是在一個深度學習平臺RTX 3090 Ti GPU設(shè)備上執(zhí)行,并在Python 3.7編程環(huán)境中實現(xiàn)。
在訓練過程中,采用一種標準的數(shù)據(jù)增強[22]方案(包括填充、隨機裁剪和水平翻轉(zhuǎn)),對訓練集的圖像進行均值和標準差的標準化處理。對于CIFAR10和CIFAR100數(shù)據(jù)集,為了確保對比實驗的公平性,采用和文獻[23]相同的參數(shù)設(shè)置:共迭代200個訓練輪次,批次大小設(shè)置為128,優(yōu)化器選擇隨機梯度下降法[24],動量為0.9,權(quán)重衰減因子為5.0×10-4,初始學習率為0.1,分別在100、150次迭代下進行0.1倍的衰減。對于ImageNet數(shù)據(jù)集,共迭代100個訓練輪次,批次大小設(shè)置為64,優(yōu)化器同樣選擇隨機梯度下降法SGD,動量為0.9,權(quán)重衰減因子為1.0×10-4,初始學習率為0.1,分別在30、60和80次迭代下進行0.1倍的衰減。
2.3 CIFAR100數(shù)據(jù)集對比實驗
課題組在CIFAR100數(shù)據(jù)集上開展了一系列對比實驗來驗證DSAKD方法的性能優(yōu)勢,包括同構(gòu)網(wǎng)絡(luò)(這里指教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)采用同一類型的網(wǎng)絡(luò))的蒸餾對比實驗以及更有挑戰(zhàn)性的異構(gòu)網(wǎng)絡(luò)(這里指教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)采用不同類型的網(wǎng)絡(luò))上的蒸餾對比實驗。對比方法主要包括:在基于軟標簽的知識蒸餾方法中性能最好的解耦知識蒸餾Decouple KD[18]方法;在基于特征層的知識蒸餾方法中性能最好的知識回顧Review KD[9]蒸餾方法,以及在基于結(jié)構(gòu)化知識蒸餾方法中性能最好的RKD[12]方法。除此之外,考慮到本文的方法主要是在文獻[23]公開的代碼上進行改進的,因此將文獻[23]提出的對比表征蒸餾方法CRD也作為對比方法之一。所有對比實驗的結(jié)果均是在作者提供的公開代碼的推薦參數(shù)配置下實現(xiàn)得到的。
首先,在CIFAR100數(shù)據(jù)集上進行同構(gòu)網(wǎng)絡(luò)對比實驗來評估本文所提DSAKD方法的有效性。為了確保對比實驗的公平性,本文在4種對比方法都采用的3組網(wǎng)絡(luò)上開展對比實驗。3組同構(gòu)網(wǎng)絡(luò)分別為:網(wǎng)絡(luò)1(ResNet110作為教師網(wǎng)絡(luò),ResNet20作為學生網(wǎng)絡(luò)),網(wǎng)絡(luò)2(WRN40-2作為教師網(wǎng)絡(luò),WRN16-2作為學生網(wǎng)絡(luò))和網(wǎng)絡(luò)3(VGG13作為教師網(wǎng)絡(luò),VGG8作為學生網(wǎng)絡(luò))。表1展示了在同構(gòu)網(wǎng)絡(luò)條件下,本文提出的方法和4種對比方法在CIFAR100數(shù)據(jù)集上的Top-1驗證準確率。圖中加粗的字體用于標記最優(yōu)的準確率,而且所有的實驗結(jié)果都是重復5次實驗取的平均值及標準差。
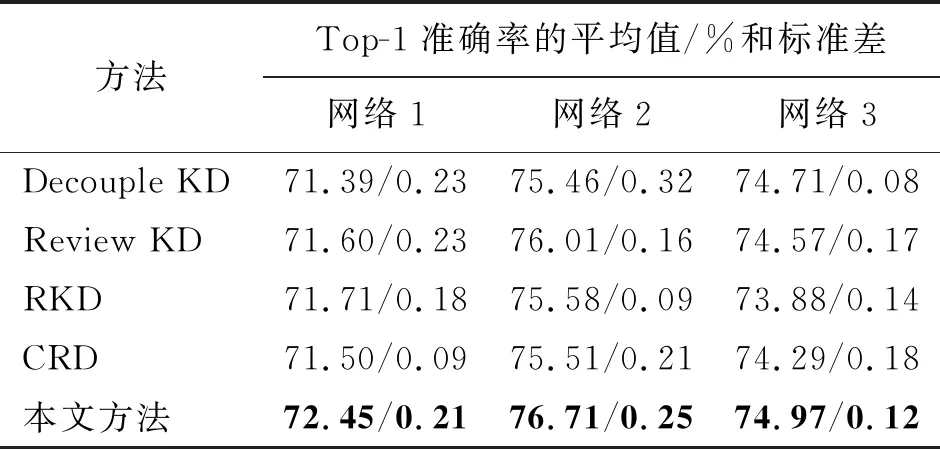
表1 在CIFAR100數(shù)據(jù)集上的同構(gòu)網(wǎng)絡(luò)對比實驗Tab.1 The experimental comparison of peer-architecture distillation on the CIFAR100 dataset
從表1可以看出,與其他4種性能優(yōu)異的蒸餾算法相比,本文提出的方法在3組不同的同構(gòu)網(wǎng)絡(luò)蒸餾實驗中都獲得了最佳的蒸餾性能,顯著地提高了學生網(wǎng)絡(luò)的分類性能。具體來講,基于軟標簽蒸餾的Decouple KD主要是從教師網(wǎng)絡(luò)的軟標簽中獲取知識,經(jīng)過該方法訓練的學生網(wǎng)絡(luò)雖然獲得了性能提升,但是沒有考慮到教師網(wǎng)絡(luò)特征層中豐富的知識。基于結(jié)構(gòu)化蒸餾的RKD方法和基于對比表征蒸餾的CRD都是基于對應層之間進行蒸餾的方法,共同點是讓學生網(wǎng)絡(luò)在訓練前期學習復雜的教師知識,導致經(jīng)過這些方法訓練的學生網(wǎng)絡(luò)提升有限。而Review KD采用一種漸進式融合蒸餾的策略對學生網(wǎng)絡(luò)的特征層進行知識回顧蒸餾,在4種對比方法中取得了最優(yōu)的性能。不同于上述4種對比方法,本文提出的方法從教師網(wǎng)絡(luò)中獲取雙源類型的知識,并通過提出的特征自適應融合策略、特征嵌入對比蒸餾策略和自適應溫度蒸餾策略對學生網(wǎng)絡(luò)進行優(yōu)化,使得學生網(wǎng)絡(luò)能夠從教師網(wǎng)絡(luò)中的特征層和軟標簽中學習到更豐富的知識。與對比方法中性能最好的方法相比,在3組網(wǎng)絡(luò)上的平均驗證準確率提高了0.57%。
為了進一步證明本文所提出方法的有效性和適用性,本文在更具挑戰(zhàn)性的異構(gòu)網(wǎng)絡(luò)上進行了對比實驗。同樣地,選擇4種對比方法都采用的3組異構(gòu)網(wǎng)絡(luò)進行對比,分別為:網(wǎng)絡(luò)a(WRN40-2作為教師網(wǎng)絡(luò),ShuffleNetV1作為學生網(wǎng)絡(luò)),網(wǎng)絡(luò)b(ResNet32×4作為教師網(wǎng)絡(luò),ShuffleNetV2作為學生網(wǎng)絡(luò))和網(wǎng)絡(luò)c(VGG13作為教師網(wǎng)絡(luò),MobileNetV2作為學生網(wǎng)絡(luò))。表2給出了本文方法在3組異構(gòu)網(wǎng)絡(luò)上與其他4種蒸餾算法的對比結(jié)果。
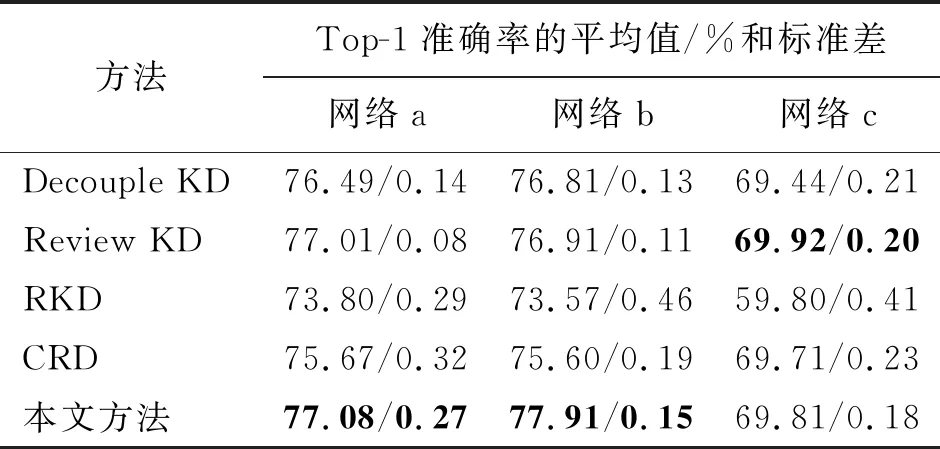
表2 在CIFAR100數(shù)據(jù)集上的異構(gòu)網(wǎng)絡(luò)對比實驗Tab.2 The experimental comparison of cross-architecture distillation on the CIFAR100 dataset
從表2可以看出,本文提出的方法在前2組不同的異構(gòu)網(wǎng)絡(luò)蒸餾實驗中獲得了最佳的蒸餾性能,在最后一組異構(gòu)網(wǎng)絡(luò)蒸餾實驗中獲得了次優(yōu)的性能。總的來說,與對比方法中性能最好的方法相比,在3組網(wǎng)絡(luò)上的平均驗證準確率提高了0.34%。其中,基于結(jié)構(gòu)化蒸餾的RKD方法表現(xiàn)最差,分析原因是異構(gòu)網(wǎng)絡(luò)在結(jié)構(gòu)和特征表示上存在較大的差異,這種差異性導致教師網(wǎng)絡(luò)中的關(guān)系信息無法有效地傳遞給學生網(wǎng)絡(luò)。基于軟標簽蒸餾的方法Decouple KD沒有考慮到教師網(wǎng)絡(luò)特征層的知識,效果提升有限。CRD方法沒有考慮淺層特征的有效知識,從而在更具挑戰(zhàn)性的異構(gòu)網(wǎng)絡(luò)上效果較差。然而,本文提出的方法將教師網(wǎng)絡(luò)的多尺度特征進行自適應融合,并在嵌入空間中通過對比學習進行優(yōu)化,進一步提高了學生網(wǎng)絡(luò)的特征提取能力,使得訓練的學生網(wǎng)絡(luò)在異構(gòu)網(wǎng)絡(luò)上同樣蒸餾效果優(yōu)異。
為了更直觀地展示本文所提方法的有效性,圖3展示了經(jīng)過訓練后學生網(wǎng)絡(luò)和教師網(wǎng)絡(luò)logits的相關(guān)性差異,圖中橫軸和縱軸分別代表教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)的logits,顏色越深表示兩者的差異越大。由于logits是模型輸出的前一步驟,相關(guān)性的降低表明學生網(wǎng)絡(luò)更準確地學習到了教師網(wǎng)絡(luò)的軟標簽知識。因此,這里選擇WRN40-2作為教師網(wǎng)絡(luò),WRN16-2作為學生網(wǎng)絡(luò),與基于軟標簽蒸餾的Decouple KD方法進行對比。
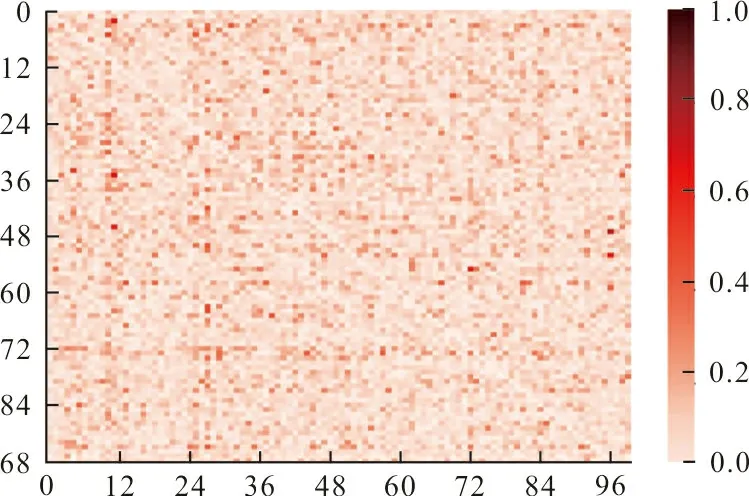
(a) Decouple KD方法
從圖3可以看出,經(jīng)過本文方法訓練的學生網(wǎng)絡(luò)與教師網(wǎng)絡(luò)的logits相關(guān)性差異更小。Decouple KD對所有的訓練樣本設(shè)置同一溫度系數(shù)來得到樣本的軟標簽,沒有考慮不同樣本的差異性,從而導致學生網(wǎng)絡(luò)不能更好地學習和模擬教師網(wǎng)絡(luò)的預測能力。而本文方法通過為所有的訓練樣本分配不同的溫度系數(shù),減小了數(shù)據(jù)集中的難分樣本和噪聲對學生網(wǎng)絡(luò)的干擾,幫助學生網(wǎng)絡(luò)從教師網(wǎng)絡(luò)的特征層和軟標簽中學習到更具魯棒性和判別性的知識,有利于進一步減少教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)之間的logits差異,從而提高了學生網(wǎng)絡(luò)的性能。
2.4 CIFAR10和ImageNet數(shù)據(jù)集泛化性實驗
為了進一步證明本文方法的泛化性能,本文在CIFAR10數(shù)據(jù)集和更具挑戰(zhàn)性的ImageNet數(shù)據(jù)集上開展了對比實驗。表3展示了本文提方法與其他幾種蒸餾方法在CIFAR10數(shù)據(jù)集上取得的Top-1準確率的對比結(jié)果,其中對比方法和網(wǎng)絡(luò)設(shè)置與表1相同。
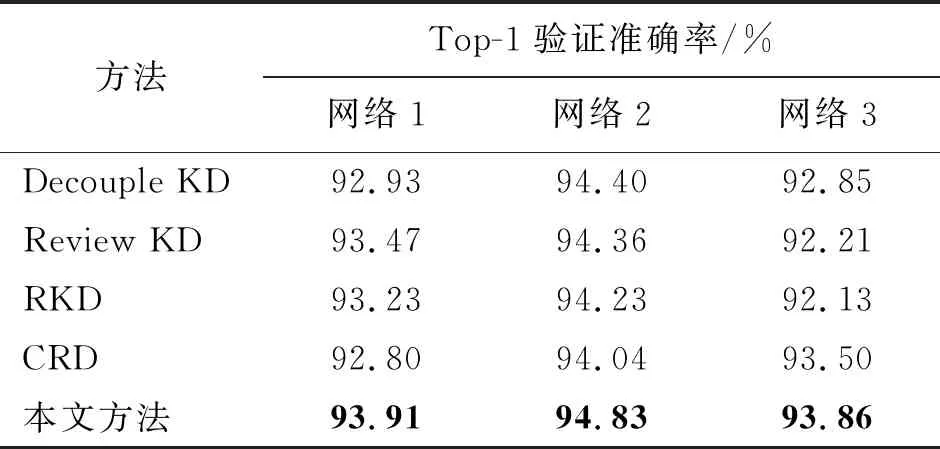
表3 在CIFAR10數(shù)據(jù)集上的對比實驗Tab.3 The experimental comparison on the CIFAR10 dataset
在ImageNet數(shù)據(jù)集上的Top-1準確率和Top-5準確率對比實驗結(jié)果如表4所示。對比方法選擇基于軟標簽蒸餾的開山之作Vanilla KD[5]方法,基于特征層蒸餾的注意力蒸餾方法AT[7],基于結(jié)構(gòu)化蒸餾方法中性能最好的RKD[12]方法以及對比表征蒸餾CRD[23]方法。為了確保對比的公平性,本文對4種方法都采用1組網(wǎng)絡(luò)開展對比實驗,選擇ResNet50作為教師網(wǎng)絡(luò),選擇MobileNetV2作為學生網(wǎng)絡(luò)。
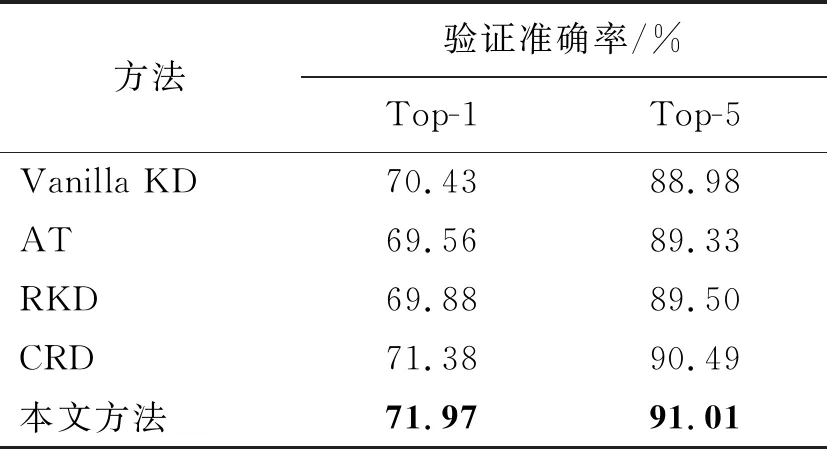
表4 在ImageNet數(shù)據(jù)集上的對比實驗Tab.4 The experimental comparison on the ImageNet dataset
從表3和表4可以看出,本文提出的DSAKD方法在相對簡單的CIFAR10數(shù)據(jù)集和更具挑戰(zhàn)性的ImageNet數(shù)據(jù)集上都取得了優(yōu)異的蒸餾性能。具體來講,在CIFAR10數(shù)據(jù)集上,與對比方法中性能最好的方法相比,在3組網(wǎng)絡(luò)上的平均驗證準確率提高了0.41%。在ImageNet數(shù)據(jù)集上,與對比方法中性能最優(yōu)的CRD方法相比,經(jīng)過DSAKD方法訓練的學生網(wǎng)絡(luò)的Top-1和Top-5識別準確率分別提高了0.59%和0.52%。因此,本文提出的DSAKD方法有著較好的泛化性能,這是因為多層特征自適應融合策略可以幫助學生網(wǎng)絡(luò)獲取更全面的特征表達,而且提出的自適應蒸餾策略針對不同難度的數(shù)據(jù)集可以自適應設(shè)置不同的系數(shù),具有更強的適用性。
2.5 所提模塊的消融實驗
本文提出的模型包含3個主要模塊,即特征自適應融合模塊、嵌入特征對比蒸餾模塊以及溫度自適應蒸餾模塊。本文設(shè)計了消融實驗來進一步驗證各個模塊的有效性,圖4展示了消融實驗的結(jié)果。
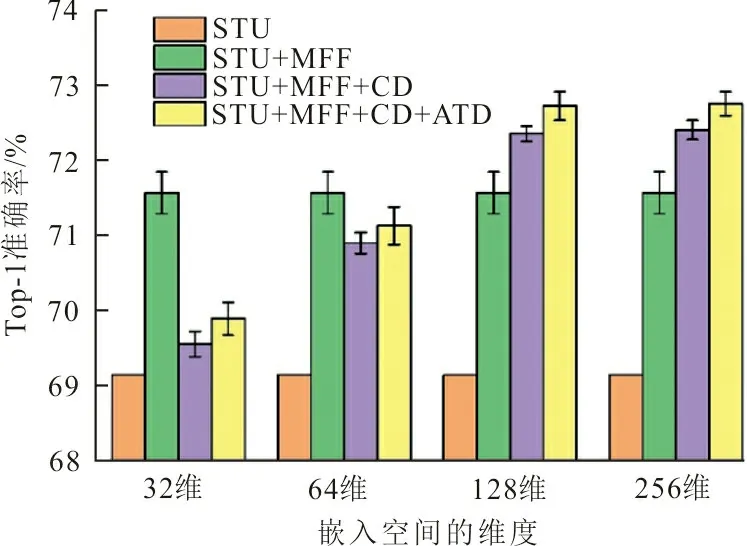
圖4 本文提出的3個模塊的消融實驗Fig.4 The ablation study of the proposed three modules
圖4選擇ResNet56作為教師網(wǎng)絡(luò),ResNet20作為學生網(wǎng)絡(luò),不經(jīng)過任何蒸餾策略訓練的學生網(wǎng)絡(luò)在CIFAR100數(shù)據(jù)集上的平均驗證準確率如橙色柱所示。單獨使用多層特征融合策略,將融合后的特征直接進行匹配,實驗結(jié)果如綠色柱所示。相比于單獨使用學生網(wǎng)絡(luò)進行訓練,經(jīng)過多層特征融合模塊訓練的學生網(wǎng)絡(luò)略微提高了學生網(wǎng)絡(luò)的性能。然后,加入嵌入特征對比蒸餾模塊,將融合后的特征投影到嵌入空間中通過對比學習進行優(yōu)化,結(jié)果如紫色柱所示。最后,驗證提出的自適應溫度蒸餾模塊的作用,在紫色柱的基礎(chǔ)上增加溫度自適應蒸餾模塊后學生網(wǎng)絡(luò)的驗證準確率如黃色柱所示。可以看出加入溫度自適應蒸餾模塊后,網(wǎng)絡(luò)在原有基礎(chǔ)上有了相應的提升。
考慮到嵌入空間的維數(shù)對學生網(wǎng)絡(luò)蒸餾性能的影響,本文在不同維度的嵌入空間進行了對比實驗,見圖4中橫軸所示。考慮到當嵌入空間維度設(shè)置過小時,學生網(wǎng)絡(luò)的性能急劇下降;當維度增加到128后,繼續(xù)增加學生網(wǎng)絡(luò)的性能達到了飽和;當維度設(shè)置為256時,相比于128維,學生網(wǎng)絡(luò)的性能幾乎沒有提升。因此,圖4中僅展示了嵌入空間維度從32維到256維的變化。綜合考慮計算效率和性能增益,本文選擇的最佳的嵌入空間維度為128維。
2.6 參數(shù)分析實驗
學生網(wǎng)絡(luò)在特征嵌入對比蒸餾損失、自適應溫度蒸餾損失和分類損失的聯(lián)合指導下進行訓練,各項損失間的權(quán)值系數(shù)對總損失也有影響,因此本文針對權(quán)值系數(shù)在CIFAR100數(shù)據(jù)集上對學生網(wǎng)絡(luò)性能的影響做了實驗分析。這里選擇WRN40-2作為教師網(wǎng)絡(luò),選擇WRN16-2作為學生網(wǎng)絡(luò),超參數(shù)λ和μ對學生網(wǎng)絡(luò)性能的影響如圖5所示。

圖5 超參數(shù)的參數(shù)分析實驗Fig.5 The parameter analysis experiment with hyperparameters
從圖5可以看出,學生網(wǎng)絡(luò)的性能容易受到權(quán)值系數(shù)λ和μ的影響。當λ和μ的取值較小時,所提出的特征嵌入對比蒸餾損失和自適應溫度蒸餾損失起的作用也較小,導致學生網(wǎng)絡(luò)主要在分類損失的約束下訓練;當λ和μ的取值逐漸增加時,學生網(wǎng)絡(luò)的分類性能隨之增加,一定程度上驗證了本文所提的特征自適應融合模塊、特征嵌入對比蒸餾模塊和自適應溫度蒸餾模塊的有效性;當λ取0.8、μ取1.0時,學生網(wǎng)絡(luò)的性能最優(yōu)。
3 結(jié) 語
本文提出了一種新的雙源自適應知識蒸餾方法,從教師網(wǎng)絡(luò)的特征層和軟標簽中獲取雙源類型的知識,從而進一步提高輕量化學生網(wǎng)絡(luò)的性能。一方面,將教師網(wǎng)絡(luò)和學生網(wǎng)絡(luò)的多尺度特征通過特征自適應融合模塊進行融合,將融合后包含更豐富知識的特征投影到一個嵌入空間中,通過對比學習的思想對學生網(wǎng)絡(luò)進行優(yōu)化,從而提高學生網(wǎng)絡(luò)的特征提取能力;另一方面,本文對原有的軟標簽蒸餾方法進行改進,提出了一種溫度自適應蒸餾策略,根據(jù)教師網(wǎng)絡(luò)對每個樣本的預測置信度為不同的樣本設(shè)置不同的溫度系數(shù),從而將更有判別性的軟標簽知識蒸餾給學生網(wǎng)絡(luò)。在3個基準圖像分類數(shù)據(jù)集上的大量對比實驗結(jié)果表明,本文提出的DSAKD方法在同構(gòu)網(wǎng)絡(luò)和異構(gòu)網(wǎng)絡(luò)蒸餾上都取得了更好的蒸餾效果,進一步提高了輕量化學生網(wǎng)絡(luò)的分類性能。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
