結(jié)合先驗(yàn)知識(shí)與深度強(qiáng)化學(xué)習(xí)的機(jī)械臂抓取研究
2023-10-26 06:17:54繆劉洋朱其新丁正凱
西安工程大學(xué)學(xué)報(bào) 2023年4期
繆劉洋,朱其新,丁正凱,王 旭
(1.蘇州科技大學(xué) 電子與信息工程學(xué)院,江蘇 蘇州 215009; 2.蘇州科技大學(xué) 機(jī)械工程學(xué)院/建筑智慧節(jié)能江蘇省重點(diǎn)實(shí)驗(yàn)室/蘇州市共融機(jī)器人技術(shù)重點(diǎn)實(shí)驗(yàn)室,江蘇 蘇州 215009; 3.蘇州科技大學(xué) 電子與信息工程學(xué)院/建筑智慧節(jié)能江蘇省重點(diǎn)實(shí)驗(yàn)室,江蘇 蘇州 215009)
0 引 言
在機(jī)器人領(lǐng)域中,機(jī)械臂的應(yīng)用最為廣泛[1],是自動(dòng)化應(yīng)用中不可或缺的一部分,特別是在搬運(yùn)、分揀、裝配、醫(yī)療等工作場(chǎng)景中扮演著重要的角色。機(jī)械臂不僅提高了作業(yè)安全和產(chǎn)品質(zhì)量,而且降低了生產(chǎn)成本與工作強(qiáng)度[2]。然而,機(jī)械臂通常面向特定的生產(chǎn)線,按照設(shè)定程序完成重復(fù)且技術(shù)含量低的工作[3]。在復(fù)雜的非標(biāo)準(zhǔn)環(huán)境下,如何保證機(jī)械臂準(zhǔn)確高效地完成特定工作依然存在巨大的挑戰(zhàn),雖然國內(nèi)外學(xué)者已經(jīng)提出了使用智能算法對(duì)機(jī)械臂進(jìn)行路徑規(guī)劃[4-5],但是傳統(tǒng)的控制方法在面對(duì)陌生環(huán)境時(shí)仍然存在一定缺陷,例如缺乏自適應(yīng)能力等[6]。
20世紀(jì)五六十年代人工智能興起,為機(jī)械臂的控制策略提供了新思路[7]。不同于傳統(tǒng)的固定命令控制方法[8],強(qiáng)化學(xué)習(xí)與機(jī)械臂技術(shù)相結(jié)合,使機(jī)械臂借助強(qiáng)化學(xué)習(xí)的試錯(cuò)機(jī)制與環(huán)境交互獲取信息[9],從而具有強(qiáng)大的學(xué)習(xí)能力,極大地提高了機(jī)械臂對(duì)陌生環(huán)境和新任務(wù)的適應(yīng)能力。強(qiáng)化學(xué)習(xí)主要用來解決決策問題[10],通過最大化累計(jì)獎(jiǎng)賞方式找到最優(yōu)策略[11]。但在機(jī)械臂行為決策能力的研究中還存在機(jī)械臂數(shù)據(jù)特征提取困難、任務(wù)空間大等問題,DRL為此提供了良好的解決方案。DRL是深度學(xué)習(xí)(deep learning,DL)和強(qiáng)化學(xué)習(xí)(reinforcement learning,RL)的交叉領(lǐng)域,不僅具有DL的線性擬合和特征提取能力[12],還具有RL的決策能力,且在機(jī)械臂控制領(lǐng)域已有大量的研究與應(yīng)用。文獻(xiàn)[13]設(shè)計(jì)了一種具有卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural networks,CNN)的深度Q網(wǎng)絡(luò)(deep Q-network,DQN),以圖片作為輸入學(xué)習(xí)策略,機(jī)械臂在自身環(huán)境與位置未知的情況下,可將小球推入球網(wǎng)。文獻(xiàn)[14]使用深度確定性策略梯度(deep deterministic policy gradient,DDPG)訓(xùn)練機(jī)械臂到達(dá)三維空間內(nèi)的目標(biāo)點(diǎn),同時(shí)設(shè)計(jì)了多種獎(jiǎng)賞函數(shù)對(duì)機(jī)械臂進(jìn)行訓(xùn)練,驗(yàn)證了合理的獎(jiǎng)賞函數(shù)可以加快算法的收斂。文獻(xiàn)[15]使用DDPG訓(xùn)練機(jī)械臂實(shí)現(xiàn)推、抓、扔小球等任務(wù),文中使用事后經(jīng)驗(yàn)回放(hindsight experience replay,HER)算法與DDPG相結(jié)合的方式來處理學(xué)習(xí)過程中獎(jiǎng)賞稀疏的問題。實(shí)驗(yàn)結(jié)果表明,使用HER可以提高簡(jiǎn)單實(shí)驗(yàn)的成功率,但在復(fù)雜任務(wù)中HER的能力有所下降。文獻(xiàn)[16]提出一種位姿最佳算法以降低稀疏獎(jiǎng)賞對(duì)機(jī)械臂訓(xùn)練的影響。文獻(xiàn)[17]對(duì)DDPG做出2點(diǎn)改進(jìn)以加快學(xué)習(xí)速度和提高性能:一是使用非對(duì)稱輸入,其中Actor網(wǎng)絡(luò)使用通過CNN網(wǎng)絡(luò)處理圖像數(shù)據(jù)輸入,而Critic網(wǎng)絡(luò)使用仿真環(huán)境反饋的狀態(tài)(例如物體的位置、機(jī)械臂的關(guān)節(jié)角度等)作為輸入;二是通過增加一組狀態(tài)預(yù)測(cè)網(wǎng)絡(luò)與CNN網(wǎng)絡(luò)并行一起輸入進(jìn)Actor網(wǎng)絡(luò)。
上述內(nèi)容通過DRL方法實(shí)現(xiàn)了機(jī)械臂的自主規(guī)劃與學(xué)習(xí),能夠在未知環(huán)境下完成任務(wù);但是部分研究通過減少機(jī)械臂的關(guān)節(jié)數(shù)量來降低訓(xùn)練難度。因此,在機(jī)械臂使用DRL的學(xué)習(xí)過程中仍存在數(shù)據(jù)采樣效率低、經(jīng)驗(yàn)樣本質(zhì)量低、高維連續(xù)的狀態(tài)-動(dòng)作空間等問題,進(jìn)而導(dǎo)致DRL的獎(jiǎng)賞函數(shù)收斂速度慢、學(xué)習(xí)效率低,直接影響機(jī)械臂的訓(xùn)練效果。目前機(jī)械臂與強(qiáng)化學(xué)習(xí)的結(jié)合主要集中于路徑自主規(guī)劃、目標(biāo)物體抓取等方面。現(xiàn)有研究的抓取目標(biāo)多為球體,機(jī)械臂末端僅需保證夾爪與物體的中心點(diǎn)重合即可,無須考慮抓取時(shí)的姿態(tài)。而在抓取的研究中,多數(shù)僅針對(duì)同一位姿物體分析機(jī)械臂的任務(wù)完成情況,未考慮訓(xùn)練完成后DRL算法在新任務(wù)中的泛化能力。
針對(duì)上述問題,本文以DDPG和Softmax深度雙確定性策略梯度(簡(jiǎn)稱SD3)[18]為原始模型,在原始模型中引入先驗(yàn)知識(shí),并將模型與機(jī)械臂逆運(yùn)動(dòng)學(xué)相結(jié)合對(duì)機(jī)械臂自主抓取的行為決策進(jìn)行訓(xùn)練,以獎(jiǎng)賞函數(shù)的收斂速度和任務(wù)的成功率為指標(biāo)對(duì)原始及引入先驗(yàn)知識(shí)的4種模型性能進(jìn)行比較分析。同時(shí),將訓(xùn)練所得的網(wǎng)絡(luò)參數(shù)進(jìn)行遷移,分析比較引入先驗(yàn)知識(shí)前后算法的泛化能力。為符合實(shí)際,本文使用長(zhǎng)方體作為機(jī)械臂自主抓取對(duì)象,同時(shí)要求夾爪以特定的姿態(tài)執(zhí)行抓取動(dòng)作。
1 相關(guān)知識(shí)
1.1 強(qiáng)化學(xué)習(xí)(RL)
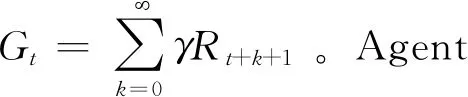
RL算法可依據(jù)有無模型進(jìn)行分類。其中有模型算法需要對(duì)環(huán)境進(jìn)行建模,但模型往往無法充分考慮到現(xiàn)實(shí)環(huán)境中的各種因素總是存在誤差,導(dǎo)致在現(xiàn)實(shí)應(yīng)用中達(dá)不到仿真訓(xùn)練的效果[20],且無法適應(yīng)動(dòng)態(tài)環(huán)境;而無模型RL算法無須對(duì)環(huán)境進(jìn)行精確建模,從而避免上述問題。此外,RL算法還可以按照基于值函數(shù)和基于策略進(jìn)行分類。基于值函數(shù)的RL計(jì)算量大、存在震蕩不收斂的現(xiàn)象[21],在高維連續(xù)動(dòng)作空間中的交互過程難以學(xué)習(xí)最優(yōu)策略。而策略函數(shù)可以針對(duì)連續(xù)動(dòng)作空間直接產(chǎn)生動(dòng)作值,很好地解決連續(xù)動(dòng)作空間問題。針對(duì)上述問題,本文選擇無模型DRL方法進(jìn)行機(jī)械臂自主抓取訓(xùn)練。
1.2 深度確定性策略梯度(DDPG)
文獻(xiàn)[22]基于Actor-Critic(A-C)和DQN的理念架構(gòu)提出DDPG算法解決連續(xù)空間問題。DDPG是一種基于策略的DRL算法,策略π可以描述為一個(gè)包含參數(shù)θ的函數(shù):πθ(s,a)=P[a|s,θ]。對(duì)應(yīng)策略目標(biāo)函數(shù)為:J(θ)=Eπθ[G]。策略目標(biāo)函數(shù)可以通過梯度上升或下降的方法實(shí)現(xiàn)Agent與環(huán)境互動(dòng)過程中的累計(jì)獎(jiǎng)賞最大化。文獻(xiàn)[23]提出策略目標(biāo)函數(shù)的隨機(jī)策略梯度:
?θJ(θ)=Eπθ[?θlnπθ(s,a)Qπθ(s,a)]
(1)
式中:πθ(s,a)為策略函數(shù);Qπθ(s,a)為狀態(tài)價(jià)值函數(shù)。
DDPG包含了Actor和Critic網(wǎng)絡(luò),Actor由在線Actor網(wǎng)絡(luò)μ(s|θμ)和目標(biāo)Actor網(wǎng)絡(luò)μ′(s|θμ′)組成,Critic由在線Critic網(wǎng)絡(luò)Q(s,a|θQ)和目標(biāo)Critic網(wǎng)絡(luò)Q′(s,a|θQ′)組成。其中Actor負(fù)責(zé)與環(huán)境互動(dòng)和生成動(dòng)作,Critic負(fù)責(zé)評(píng)價(jià)Actor并指導(dǎo)后續(xù)動(dòng)作。DDPG中具有經(jīng)驗(yàn)回放機(jī)制,在Agent學(xué)習(xí)過程中通過批量采樣經(jīng)驗(yàn)樣本來更新網(wǎng)絡(luò)參數(shù)。其中在線Actor網(wǎng)絡(luò)根據(jù)在線Critic網(wǎng)絡(luò)輸出的Q值進(jìn)行更新。隨機(jī)策略梯度存在計(jì)算量大等問題,文獻(xiàn)[24]提出了確定性策略梯度,使用確定性策略梯度(deterministic policy gradient,DPG)進(jìn)行網(wǎng)絡(luò)更新,更新梯度為
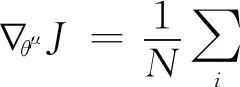
?θμμ(s|θμ)|s=si
(2)
其中Q(s,a|θQ)|s=si,a=μi為在線Critic網(wǎng)絡(luò)在s=si,a=μi狀態(tài)下輸出的Q值,μ(s|θμ)|s=si為在線Actor網(wǎng)絡(luò)在s=si狀態(tài)下輸出的動(dòng)作。
在線Critic網(wǎng)絡(luò)則利用最小化在線Critic網(wǎng)絡(luò)的目標(biāo)與輸出的Q值誤差進(jìn)行更新。定義誤差為損失函數(shù):
式中:yi=ri+1+γQ′(si+1,μ′(si+1|θμ′)|θQ′);Q′(si+1,μ′(si+1|θμ′)|θQ′)為目標(biāo)Critic網(wǎng)絡(luò)輸出的Q值。更新梯度為
?θQQ(s,a|θQ)|s=si,a=μi
(4)
而目標(biāo)Actor網(wǎng)絡(luò)和目標(biāo)Critic網(wǎng)絡(luò)通過滑動(dòng)平均方式進(jìn)行更新,方式如下:
(5)
式中:θQ、θQ′、θμ、θμ′分別為在線Actor、目標(biāo)Actor、在線Critic和目標(biāo)Critic網(wǎng)絡(luò)參數(shù);τ(τ∈(0,1))為學(xué)習(xí)率。
1.3 Softmax深度雙確定性策略梯度
SD3算法在雙延遲DDPG (簡(jiǎn)稱TD3)基礎(chǔ)上使用了雙重Actor網(wǎng)絡(luò)和Critic網(wǎng)絡(luò),同時(shí)引入了Softmax函數(shù)來更新值函數(shù),有效地改善高估和低估偏差對(duì)性能的影響[25]。學(xué)習(xí)過程中,從2組目標(biāo)Critic網(wǎng)絡(luò)選取較小的Q′值并通過Softmax函數(shù)更新在線Critic網(wǎng)絡(luò)參數(shù)。其中連續(xù)動(dòng)作空間的Softmax通過對(duì)Q′值采樣進(jìn)行無偏估計(jì):

2 算法改進(jìn)及實(shí)施
本節(jié)將深入研究算法改進(jìn)和實(shí)施的關(guān)鍵步驟。首先著眼于算法改進(jìn)來提高算法的性能,隨后轉(zhuǎn)向算法實(shí)施,詳細(xì)說明如何將改進(jìn)后的算法應(yīng)用在機(jī)械臂自主行為決策中。
2.1 算法改進(jìn)
在機(jī)械臂自主行為決策過程中,原始DRL模型難以處理高維連續(xù)的狀態(tài)-動(dòng)作空間引起的數(shù)據(jù)采樣效率低及經(jīng)驗(yàn)樣本質(zhì)量低等問題,本文對(duì)算法的改進(jìn)具體如下。
2.1.1 先驗(yàn)知識(shí)
DRL與機(jī)械臂結(jié)合的本質(zhì)是DRL指導(dǎo)機(jī)械臂自主探索和學(xué)習(xí)行為策略。諸多研究表明,機(jī)械臂使用DRL方法解決行為決策問題時(shí),面臨的最大問題為機(jī)械臂高維連續(xù)的動(dòng)作空間導(dǎo)致數(shù)據(jù)采樣效率低和經(jīng)驗(yàn)樣本質(zhì)量低。該問題直接導(dǎo)致訓(xùn)練數(shù)據(jù)不足,使得DRL無法發(fā)揮在特征提取和擬合方面的強(qiáng)大能力[26],最終導(dǎo)致前期學(xué)習(xí)效率低和訓(xùn)練時(shí)間過長(zhǎng)。如果通過增加經(jīng)驗(yàn)池和采樣大小來提高前期學(xué)習(xí)效率,則將導(dǎo)致算力成本增加以及單步學(xué)習(xí)時(shí)間增長(zhǎng)。
針對(duì)上述問題,本文在DRL算法中引入先驗(yàn)知識(shí),即通過專家指導(dǎo)的方式以達(dá)到加快獎(jiǎng)賞函數(shù)收斂速度和減少訓(xùn)練時(shí)長(zhǎng)的目的。本文主要在采樣階段引入先驗(yàn)知識(shí),先驗(yàn)知識(shí)的本質(zhì)為專家經(jīng)驗(yàn)。在原始模型中,使用完全隨機(jī)的方式進(jìn)行采樣,收集的經(jīng)驗(yàn)樣本隨機(jī)性強(qiáng)。雖然該方式可以完全發(fā)揮Agent的探索能力,但是直接導(dǎo)致樣本質(zhì)量不夠好,無法采集到十分有效的樣本,導(dǎo)致數(shù)據(jù)采樣效率低,Agent難以在有限的樣本中學(xué)到好的效果,如此情況下,想要得到良好的訓(xùn)練效果,則需要龐大的樣本數(shù)量,浪費(fèi)大量的算力及時(shí)間成本。在引入先驗(yàn)知識(shí)后,本文在一定概率下使用專家經(jīng)驗(yàn)指導(dǎo)代替完全隨機(jī)進(jìn)行采樣。引入先驗(yàn)知識(shí)的DRL模型如圖1所示。

圖1 引入先驗(yàn)知識(shí)的DRL模型Fig.1 DRL model with the introduction of prior knowledge
圖1中,(s,a)表示當(dāng)前狀態(tài)及當(dāng)前動(dòng)作,(s,a,r,s′)表示當(dāng)前狀態(tài)、當(dāng)前動(dòng)作、獎(jiǎng)賞和下一狀態(tài)。在采樣階段,Agent以一定概率選擇通過先驗(yàn)知識(shí)或隨機(jī)方式作為動(dòng)作輸出,經(jīng)驗(yàn)池溢出后,由Actor網(wǎng)絡(luò)輸出動(dòng)作。采樣前期,以隨機(jī)采樣為主并以低概率伴隨實(shí)施專家指導(dǎo)采樣,隨著采樣數(shù)量增加逐步提高概率直至完成采樣工作。在該方式下,前期大量的隨機(jī)采樣在保證Agent的探索能力同時(shí)避免其陷入局部最優(yōu);后期的專家指導(dǎo)采樣確保經(jīng)驗(yàn)樣本質(zhì)量的同時(shí)保證數(shù)據(jù)的采樣效率。
本文假設(shè)被抓物體相對(duì)于參考坐標(biāo)系的位姿信息T已知,并將T作為先驗(yàn)知識(shí)用于指導(dǎo)Agent采樣。具體實(shí)施如下:在隨機(jī)采樣階段,以概率P進(jìn)行采樣。剩余1-P則通過T對(duì)機(jī)械臂的末端運(yùn)動(dòng)方向以及RG2夾爪的橫滾角、俯仰角、偏航角(roll、pitch、yaw,簡(jiǎn)稱RPY)旋轉(zhuǎn)方向進(jìn)行指導(dǎo),運(yùn)動(dòng)和旋轉(zhuǎn)的幅度在動(dòng)作空間A中隨機(jī)選取。為避免先驗(yàn)知識(shí)限制Agent的探索能力和采樣數(shù)據(jù)的多樣性,同時(shí)保證先驗(yàn)知識(shí)對(duì)Agent的有效指導(dǎo),設(shè)定Pi+1=0.99Pi,P0=0.9,其中i為回合數(shù)。
2.1.2 狀態(tài)-動(dòng)作空間優(yōu)化
為降低狀態(tài)空間和動(dòng)作空間的空間復(fù)雜度,減少計(jì)算量,降低神經(jīng)網(wǎng)絡(luò)的擬合難度,本文將DRL與機(jī)械臂逆運(yùn)動(dòng)學(xué)相結(jié)合。在該方式下,Agent無須同時(shí)觀察機(jī)械臂的關(guān)節(jié)信息并進(jìn)獨(dú)立控制;只需觀察和控制夾爪的位姿,降低狀態(tài)與動(dòng)作空間的維度。Agent在輸出動(dòng)作時(shí),僅需要根據(jù)當(dāng)前狀態(tài)輸出夾爪的位姿,以機(jī)械臂逆向運(yùn)動(dòng)學(xué)(inverse kinematics,IK)的方式,將夾爪的位姿轉(zhuǎn)換為關(guān)節(jié)角度。本文使用六自由度機(jī)械臂作為實(shí)驗(yàn)對(duì)象,其雅克比矩陣存在不可逆的情況,使用偽逆進(jìn)行求解時(shí)在奇異點(diǎn)處難以求解。因此本文使用阻尼最小二乘法進(jìn)行IK求解,在奇異點(diǎn)處仍能穩(wěn)定求解。
2.2 算法實(shí)施
本節(jié)主要介紹引入先驗(yàn)知識(shí)的DRL模型與機(jī)械臂結(jié)合實(shí)現(xiàn)自主行為決策的具體實(shí)施方法。
2.2.1 MDP建模
使用DRL解決機(jī)械臂的自主抓取問題,首先需要將問題建模為MDP。狀態(tài)空間、動(dòng)作空間和獎(jiǎng)賞函數(shù)的定義如下所示。
1) 狀態(tài)空間S。本文設(shè)定Agent在機(jī)械臂每步動(dòng)作上觀測(cè)的狀態(tài)向量st為[px,py,pz,α,β,γ]。其中,[px,py,pz]為夾爪的夾持點(diǎn)相對(duì)于參考坐標(biāo)系的空間位置信息,[α,β,γ]為夾爪相對(duì)于參考坐標(biāo)系的RPY角信息。
在市場(chǎng)經(jīng)濟(jì)中,市場(chǎng)自發(fā)性的市場(chǎng)失靈現(xiàn)象仍然會(huì)不定期的產(chǎn)生,而且本身金融財(cái)務(wù)風(fēng)險(xiǎn)本身就處于較高的位置,而互聯(lián)網(wǎng)金融更是會(huì)加劇財(cái)務(wù)風(fēng)險(xiǎn)暴露的幾率,通過互聯(lián)網(wǎng),金融擴(kuò)張速度同樣大幅增長(zhǎng),而且加上互聯(lián)網(wǎng)具有極強(qiáng)的分散性,能夠十分迅速的將財(cái)務(wù)風(fēng)險(xiǎn)進(jìn)行傳播以及擴(kuò)散,最終給互聯(lián)網(wǎng)金融帶來極大的損失,同時(shí)對(duì)資源配置效率有著極大的影響。所以對(duì)于市場(chǎng)來說,融資交易成本也會(huì)有所降低,另外也將金融市場(chǎng)進(jìn)行完善。但是同樣也增加了財(cái)務(wù)風(fēng)險(xiǎn)誕生的幾率,加強(qiáng)財(cái)務(wù)風(fēng)險(xiǎn)的防范,是互聯(lián)網(wǎng)金融市場(chǎng)穩(wěn)健發(fā)展的重要保障。
2) 動(dòng)作空間A。Agent根據(jù)觀察到的狀態(tài)輸出動(dòng)作向量at=[dx,dy,dz,dα,dβ,dγ],其中,[dx,dy,dz]為RG2夾持點(diǎn)相對(duì)于基坐標(biāo)系在[x,y,z]3個(gè)方向上位移的偏移值,[dα,dβ,dγ]為RG2的RPY角相對(duì)于基坐標(biāo)系在[x,y,z]3個(gè)方向上轉(zhuǎn)動(dòng)的偏移角度,轉(zhuǎn)動(dòng)順序?yàn)閤—y—z。限定夾持點(diǎn)在3個(gè)方向上每次動(dòng)作范圍為[-200 mm,200 mm],夾爪的RPY角轉(zhuǎn)動(dòng)范圍為[-20°,20°]。
3) 獎(jiǎng)賞函數(shù)R。RL的基本思想就是通過最大化獎(jiǎng)賞尋找最優(yōu)策略,獎(jiǎng)賞函數(shù)對(duì)訓(xùn)練速度和學(xué)習(xí)結(jié)果有著非常重要的作用。在機(jī)械臂的自主行為決策訓(xùn)練過程中,易出現(xiàn)獎(jiǎng)賞稀疏問題,該問題會(huì)直接影響?yīng)勝p函數(shù)的收斂和機(jī)械臂的訓(xùn)練效果。合理的獎(jiǎng)賞函數(shù),在一定程度上可以解決獎(jiǎng)賞稀疏的問題。因此本文在機(jī)械臂每進(jìn)行一個(gè)動(dòng)作后給予一個(gè)適當(dāng)?shù)牧⒓椽?jiǎng)賞,具體獎(jiǎng)勵(lì)函數(shù)包含6個(gè)部分。
a) 若機(jī)械臂或夾爪與被抓物體、地面、本身發(fā)生碰撞,則給予r1=-100的負(fù)獎(jiǎng)勵(lì)。
b) 若Agent給定的動(dòng)作超出機(jī)械臂的運(yùn)動(dòng)范圍,則給予r2=-100的負(fù)獎(jiǎng)勵(lì)。
c) 若機(jī)械臂正確完成抓取任務(wù),則給予r3=200的正獎(jiǎng)勵(lì)。
d) 若夾爪夾持點(diǎn)與上一步相比,靠近被抓物體則給予正獎(jiǎng)勵(lì),相反則給予負(fù)獎(jiǎng)勵(lì)。獎(jiǎng)賞函數(shù)r4=ln(dt-dt+1-1),其中dt為第t步夾爪夾持點(diǎn)與被抓物體中心的距離,dt+1為第t+1步時(shí)的距離。
e) 為讓Agent每個(gè)回合使用較少的步數(shù)完成目標(biāo),每個(gè)回合內(nèi)Agent每執(zhí)行一次動(dòng)作給予-1的負(fù)獎(jiǎng)勵(lì),限定每回合最大步數(shù)為50步,超過則立即終止該回合,并給予r5=-50的負(fù)獎(jiǎng)勵(lì)。
f) 抓取時(shí),夾爪在目標(biāo)物體一定范圍內(nèi)時(shí),根據(jù)RPY角的偏差給予一定的負(fù)獎(jiǎng)賞。獎(jiǎng)賞函數(shù)r6=-e|RT-R|-e|PT-P|-e|YT-Y|+3,其中Rt、Pt、Yt分別為第t步夾爪的RPY角,R、P、Y為目標(biāo)物體的RPY角。
綜上,獎(jiǎng)賞函數(shù)為R=r1+r2+r3+r4+r5+r6-1。
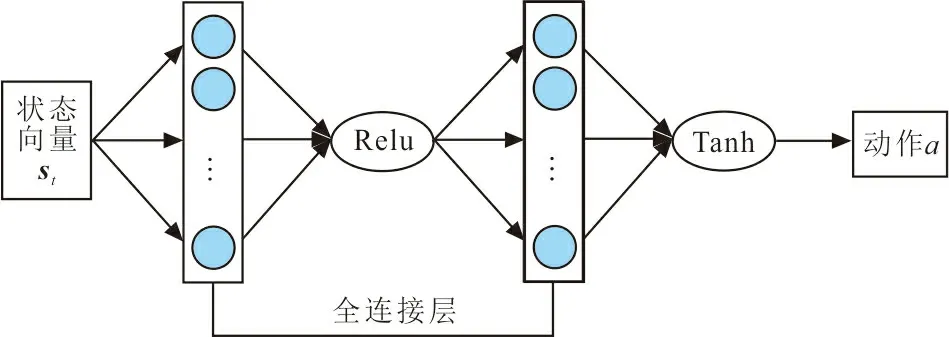
神經(jīng)網(wǎng)絡(luò)在DRL中用來擬合值函數(shù)和特征提取,實(shí)現(xiàn)端到端的學(xué)習(xí)。為保證2種算法對(duì)比的有效性,SD3采用與DDPG一致的網(wǎng)絡(luò)結(jié)構(gòu)與激活函數(shù)。Actor和Critic網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。
(a) Actor網(wǎng)絡(luò)結(jié)構(gòu)
圖2中,2種網(wǎng)絡(luò)均由2層全連接層組成,Actor的激活函數(shù)采用了Relu和Tanh,而Critic的激活函數(shù)則為Relu。所有在線網(wǎng)絡(luò)和目標(biāo)網(wǎng)絡(luò)結(jié)構(gòu)完全一致。Actor網(wǎng)絡(luò)第1層有128個(gè)神經(jīng)元,第2層有64個(gè)神經(jīng)元。Actor網(wǎng)絡(luò)由狀態(tài)向量st經(jīng)過全連接輸入第1層神經(jīng)元,再經(jīng)過Relu函數(shù)輸入到第2層神經(jīng)元,最后通過Tanh函數(shù)輸出動(dòng)作a。Critic網(wǎng)絡(luò)第1層由2組數(shù)量為128的神經(jīng)元組成,第2層由64個(gè)神經(jīng)元組成。Critic網(wǎng)絡(luò)由狀態(tài)向量st和動(dòng)作向量at經(jīng)過全連接輸入第1層的一組神經(jīng)元,然后,將第1層的2組神經(jīng)元進(jìn)行拼接,再經(jīng)過Relu函數(shù)輸入到第2層神經(jīng)元,最后輸出Q值。
2.2.3 超參數(shù)
超參數(shù)在DRL的學(xué)習(xí)過程中也起著至關(guān)重要的作用,合理的參數(shù)設(shè)置可以加快學(xué)習(xí)速度同時(shí)避免Agent陷入局部最優(yōu)。為確保對(duì)比實(shí)驗(yàn)的有效性,SD3與DDPG相同類型參數(shù)設(shè)置同樣的參數(shù)值,通過對(duì)各參數(shù)不斷地測(cè)試與調(diào)整,最終獎(jiǎng)賞折扣因子γ、軟更新學(xué)習(xí)率τ、Actor網(wǎng)絡(luò)學(xué)習(xí)率、Critic網(wǎng)絡(luò)學(xué)習(xí)率、經(jīng)驗(yàn)池大小、采樣大小分別設(shè)置為0.9、0.005、0.001、0.001、50 000、1 024;SD3算法的Q值采樣數(shù)量k設(shè)置為50。
2.2.4 算法流程
DDPG和SD3算法流程主要分為采樣和學(xué)習(xí)兩個(gè)階段。整體算法流程具體如圖3所示。

圖3 算法實(shí)施流程Fig. 3 Algorithm implementation process
圖3中,在采樣階段:首先初始化Actor和Critic網(wǎng)絡(luò)參數(shù),獲取初始狀態(tài);然后根據(jù)概率,從先驗(yàn)知識(shí)或隨機(jī)方式選擇一種輸出動(dòng)作,并獲取下一狀態(tài);最后計(jì)算即時(shí)獎(jiǎng)勵(lì)并存儲(chǔ)經(jīng)驗(yàn)。學(xué)習(xí)階段:Actor網(wǎng)絡(luò)根據(jù)狀態(tài)輸出動(dòng)作,同時(shí)獲取下一狀態(tài);然后計(jì)算計(jì)時(shí)獎(jiǎng)勵(lì)并存儲(chǔ)經(jīng)驗(yàn);最后從經(jīng)驗(yàn)池隨機(jī)選取樣本更新Actor和Critic網(wǎng)絡(luò)參數(shù)。
3 仿真實(shí)驗(yàn)與結(jié)果分析
本文使用CoppeliaSim軟件進(jìn)行仿真實(shí)驗(yàn)。CoppeliaSim是一款專業(yè)的機(jī)器人仿真軟件,具有強(qiáng)大的動(dòng)力學(xué)和運(yùn)動(dòng)學(xué)仿真能力,支持多種物理引擎仿真,同時(shí)還支持C、Matlab、Python等多種編程語言遠(yuǎn)程連接。本文在CoppeliaSim中搭建機(jī)械臂模型,物理引擎為Bullte。使用Python編寫DRL機(jī)械臂控制程序,Actor和Critic神經(jīng)網(wǎng)絡(luò)基于Pytorch框架搭建,通過遠(yuǎn)程應(yīng)用程序編程接口實(shí)現(xiàn)Python與CoppeliaSim通信連接,完成DRL訓(xùn)練CoppeliaSim中機(jī)械臂的自主抓取任務(wù)。
3.1 仿真實(shí)驗(yàn)
本文以一款型號(hào)為“UR5”的六自由度協(xié)作機(jī)械臂作為仿真實(shí)驗(yàn)對(duì)象,機(jī)械臂末端執(zhí)行器為RG2夾爪,UR5的基坐標(biāo)系作為參考坐標(biāo)系,UR5+RG2的D-H參數(shù)如表1所示。

表1 UR5+RG2 D-H參數(shù)表Tab.1 D-H parameter table of UR5+RG2
表1中θi為關(guān)節(jié)轉(zhuǎn)角,di為連桿偏距,ai-1為連桿長(zhǎng)度,αi-1為連桿轉(zhuǎn)角。
為符合實(shí)際工程應(yīng)用情況,將抓取對(duì)象設(shè)置為150 mm×50 mm×30 mm的長(zhǎng)方體。本文使用2種位姿的長(zhǎng)方體進(jìn)行實(shí)驗(yàn),一種用于自主抓取訓(xùn)練,一種用于遷移網(wǎng)絡(luò)參數(shù)后檢驗(yàn)?zāi)P偷姆夯芰ΑF渲?用于訓(xùn)練的長(zhǎng)方體對(duì)于參考坐標(biāo)系的中心坐標(biāo)為[0 mm,800 mm,15 mm],參考坐標(biāo)系的RPY角為[0°,0°,90°]。檢驗(yàn)泛化能力的長(zhǎng)方體中心坐標(biāo)為[10 mm,750 mm,60 mm],RPY角為[45°,0°,90°]。
實(shí)驗(yàn)流程:首先,訓(xùn)練機(jī)械臂對(duì)平放在地面的長(zhǎng)方體抓取;然后,使用本次訓(xùn)練的神經(jīng)網(wǎng)絡(luò)參數(shù)對(duì)不同位姿的同一長(zhǎng)方體進(jìn)行抓取,檢驗(yàn)2種算法的泛化能力;最后,從2次實(shí)驗(yàn)的獎(jiǎng)賞函數(shù)收斂情況和抓取成功率對(duì)2種算法進(jìn)行比較。
3.2 結(jié)果分析
獎(jiǎng)賞函數(shù)收斂情況是評(píng)價(jià)DRL算法有效性的重要指標(biāo)之一。機(jī)械臂自主抓取本質(zhì)上來說是一種行為決策問題,僅從獎(jiǎng)賞函數(shù)的收斂狀況進(jìn)行分析評(píng)價(jià)不具有客觀性。為符合實(shí)際應(yīng)用場(chǎng)景,本文從獎(jiǎng)賞函數(shù)、抓取成功率以及遷移訓(xùn)練所得網(wǎng)絡(luò)參數(shù)對(duì)不同位姿的同一物體抓取情況進(jìn)行對(duì)比分析。抓取成功判斷指標(biāo):夾爪的夾持點(diǎn)與被抓物體的中心點(diǎn)重合(位置誤差≤1 cm),夾爪與物體的RPY角一致,且橫滾角α、俯仰角β、偏航角γ的誤差均小于0.5°。
3.2.1 先驗(yàn)知識(shí)與原始模型比較分析
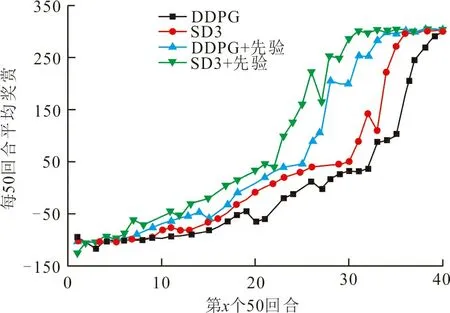
DDPG、SD3算法引入先驗(yàn)知識(shí)前后4種模型的訓(xùn)練結(jié)果如圖4所示,圖4(a)為4種模型獎(jiǎng)賞圖,圖4(b)為4種模型抓取成功率。
(a) 訓(xùn)練獎(jiǎng)賞
從圖4可以看出,所有模型在起始學(xué)習(xí)階段獲得的獎(jiǎng)賞和成功率都很低,但隨著訓(xùn)練回合數(shù)的增加均逐步提高并收斂。根據(jù)本文獎(jiǎng)賞函數(shù)設(shè)定,機(jī)械臂成功完成抓取任務(wù)Agent就會(huì)獲得很大獎(jiǎng)賞,相反任務(wù)失敗或訓(xùn)練步數(shù)超過限制獎(jiǎng)賞則會(huì)很低。比較各模型,引入先驗(yàn)知識(shí)的SD3模型和DDPG模型獎(jiǎng)賞收斂速度較快,分別在1 550和1 700回合時(shí)趨于穩(wěn)定,而SD3和DDPG原始模型分別在1 800和1 950回合左右逐步穩(wěn)定,比原始模型的學(xué)習(xí)效率提升了13.89%、12.82%。在抓取成功率上,引入先驗(yàn)知識(shí)的SD3模型和DDPG模型在2 000回合的成功率達(dá)到27.91%、22.35%,相比原始模型成功率分別提高了16.92%、13.25%。其中引入先驗(yàn)知識(shí)的SD3模型最先成功完成抓取任務(wù),且成功率增長(zhǎng)最快。數(shù)據(jù)趨勢(shì)顯示,隨著訓(xùn)練回合數(shù)的進(jìn)一步增大,成功率同步上升并最終收斂。
從獎(jiǎng)賞的收斂狀況和抓取成功率可以看出DRL算法在引入先驗(yàn)知識(shí)后,可以明顯提升算法性能。這是因?yàn)樵谑褂肈RL解決機(jī)械臂的行為決策問題時(shí),Agent面臨高維連續(xù)的動(dòng)作空間,在采樣階段,如果使用完全隨機(jī)的方式采樣,Agent無法采集到足夠多且有效的數(shù)據(jù)來支撐學(xué)習(xí)階段較好地更新網(wǎng)絡(luò)參數(shù),使得訓(xùn)練時(shí)間漫長(zhǎng)。而在引入先驗(yàn)知識(shí)后,Agent以一定概率通過專家經(jīng)驗(yàn)指導(dǎo)采樣,其余則使用隨機(jī)方式采樣。在這種模式下,Agent不僅可以通過專家經(jīng)驗(yàn)獲得足夠多且有效的數(shù)據(jù),而且隨機(jī)的方式不會(huì)限制Agent的探索能力,以免陷入局部最優(yōu)。所以,引入先驗(yàn)知識(shí)的DRL模型比原始模型的獎(jiǎng)賞和成功率的收斂更快。
3.2.2 遷移模型性能比較分析
抓取不同位姿的物體是機(jī)械臂實(shí)現(xiàn)智能化控制必須解決的難題之一。為驗(yàn)證模型的泛化能力,對(duì)被抓物體更換位姿后,將訓(xùn)練好的網(wǎng)絡(luò)參數(shù)進(jìn)行遷移驗(yàn)證,DDPG、SD3算法引入先驗(yàn)知識(shí)前后4種模型遷移的仿真結(jié)果如圖5所示。

(a) 遷移獎(jiǎng)賞
在學(xué)習(xí)初期,Agent獲得的獎(jiǎng)賞雖然很低,但相比于圖4沒有遷移的模型,圖5的4種模型的獎(jiǎng)賞收斂速度均有明顯提升。圖5中,引入先驗(yàn)知識(shí)后的DRL模型在遷移后仍然保持了訓(xùn)練過程中的優(yōu)勢(shì),在1 000和1 150回合左右已經(jīng)趨于穩(wěn)定,原始模型則在1 300和1 500回合左右開始穩(wěn)定。收斂速度比未進(jìn)行網(wǎng)絡(luò)遷參數(shù)移的模型分別提升了35.48%、32.35%、27.78%和23.08%。引入先驗(yàn)知識(shí)的模型比原始模型學(xué)習(xí)率提升了23.08%、23.33%。同時(shí),從開始到首次成功完成任務(wù)的過程大大縮短,且成功率增長(zhǎng)相對(duì)較快。在2 000回合時(shí),4種模型的成功率達(dá)到49.55%、43.85%、38.85%和32.28%,成功率比未進(jìn)行網(wǎng)絡(luò)參數(shù)遷移的模型分別提升了21.64%、21.5%、27.8%和23.18%。引入先驗(yàn)知識(shí)的模型比原始模型成功率提高了10.7%、11.57%。
本文通過遷移網(wǎng)絡(luò)參數(shù)的方式來抓取不同位姿的物體以驗(yàn)證DRL的泛化能力。從圖4、圖5可以看出,將網(wǎng)絡(luò)參數(shù)遷移后,大大縮減了Agent學(xué)習(xí)的時(shí)間,并且成功率也大幅提升。雖然Agent仍需要一定的學(xué)習(xí)過程,無法直接完成抓取任務(wù),但是學(xué)習(xí)的過程大幅度縮減,而且任務(wù)完成的成功率上升更快。這是因?yàn)樵诰W(wǎng)絡(luò)參數(shù)遷移前獎(jiǎng)賞已經(jīng)收斂,新任務(wù)雖然改變了物體的位姿,但是環(huán)境并沒有太大的變化,網(wǎng)絡(luò)參數(shù)遷移之后,神經(jīng)網(wǎng)絡(luò)已具較強(qiáng)的特征提取和擬合能力。數(shù)據(jù)顯示,與原始模型相比,引入先驗(yàn)知識(shí)的模型泛化能力更強(qiáng)。因?yàn)樵谇耙粋€(gè)任務(wù)中,引入先驗(yàn)知識(shí)的模型收斂較快,在訓(xùn)練后期,神經(jīng)網(wǎng)絡(luò)已經(jīng)趨于穩(wěn)定;而原始模型雖然也已經(jīng)收斂,但是神經(jīng)網(wǎng)絡(luò)的性能相較于引入先驗(yàn)知識(shí)的模型略差,可能陷入局部最優(yōu)。所以在新任務(wù)中,原始模型的收斂速度較慢,成功率較低。同時(shí),引入先驗(yàn)知識(shí)的模型能夠獲得更好的學(xué)習(xí)樣本,在神經(jīng)網(wǎng)絡(luò)有一定擬合能力的情況下,使得該模型的學(xué)習(xí)效率更快,成功率更高,更易達(dá)到最優(yōu)解。
通過引入先驗(yàn)知識(shí),DRL算法表現(xiàn)出明顯的性能提升,與原始模型相比,改進(jìn)后的算法在學(xué)習(xí)效率和成功率方面都表現(xiàn)出顯著提高。尤其是在學(xué)習(xí)效率方面,算法的改進(jìn)加快了深度強(qiáng)化學(xué)習(xí)的訓(xùn)練速度。這不僅有效地降低強(qiáng)化學(xué)習(xí)算法訓(xùn)練所需的時(shí)間和硬件成本,還可以提高算法的應(yīng)用效果。而在成功率方面,成功率的提升也為算法的魯棒性和可靠性提供了有力支撐,改進(jìn)后的算法在執(zhí)行任務(wù)時(shí)具有更好的適應(yīng)性和泛化能力,可以在復(fù)雜多變的環(huán)境下表現(xiàn)出出色的性能,能夠更好地應(yīng)對(duì)各種任務(wù)和環(huán)境的挑戰(zhàn)。因此,引入先驗(yàn)知識(shí)是提高DRL算法性能的一種有效手段,其優(yōu)勢(shì)主要體現(xiàn)在增強(qiáng)了算法的學(xué)習(xí)方式和決策能力,這種優(yōu)勢(shì)不僅延伸了算法的應(yīng)用范圍,也為算法實(shí)現(xiàn)更高的目標(biāo)提供了有力支撐。
4 結(jié) 語
針對(duì)機(jī)械臂與DRL結(jié)合過程中出現(xiàn)的獎(jiǎng)賞函數(shù)收斂速度慢、學(xué)習(xí)時(shí)間長(zhǎng)等問題,提出一種引入先驗(yàn)知識(shí)的DRL模型,以解決Agent采樣過程中的數(shù)據(jù)采樣效率低、經(jīng)驗(yàn)樣本質(zhì)量低的問題,加快獎(jiǎng)賞函數(shù)的收斂速度。將DRL與機(jī)械臂逆運(yùn)動(dòng)學(xué)結(jié)合,處理機(jī)械臂訓(xùn)練過程中高維連續(xù)的狀態(tài)-動(dòng)作空間,降低神經(jīng)網(wǎng)絡(luò)的擬合難度,加快Agent的學(xué)習(xí)速度。經(jīng)過網(wǎng)絡(luò)遷移的實(shí)驗(yàn)驗(yàn)證,先驗(yàn)知識(shí)可提高DRL在實(shí)際應(yīng)用中的魯棒性和可靠性,增強(qiáng)其泛化能力。
實(shí)驗(yàn)結(jié)果表明,與原始模型相比,在DRL算法中引入先驗(yàn)知識(shí)后,新模型在學(xué)習(xí)效率、任務(wù)成功率和泛化能力上有明顯的提升,一定程度上有效地解決了上述問題。本次研究所提出的方案在DRL訓(xùn)練機(jī)械臂的自主行為決策上取得了良好效果,并在UR5機(jī)械臂上得到了較好的驗(yàn)證。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
當(dāng)代工人(2020年8期)2020-05-25 09:07:38
小學(xué)生作文(低年級(jí)適用)(2018年3期)2018-04-17 00:58:35
小溪流(畫刊)(2017年12期)2018-01-10 16:07:29
少年博覽·小學(xué)低年級(jí)(2017年4期)2017-06-09 16:22:28
作文評(píng)點(diǎn)報(bào)·低幼版(2017年7期)2017-03-11 20:49:41
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
科技知識(shí)動(dòng)漫(2016年8期)2016-07-29 20:40:09
