融合注意力機(jī)制的增強(qiáng)受限玻爾茲曼機(jī)驅(qū)動(dòng)的交互式分布估計(jì)算法
2023-10-30 10:13:56孫曉燕鞏敦衛(wèi)
自動(dòng)化學(xué)報(bào) 2023年10期
暴 琳 孫曉燕 鞏敦衛(wèi) 張 勇
近年來(lái),隨著大數(shù)據(jù)、云計(jì)算等技術(shù)的迅猛發(fā)展,信息呈現(xiàn)爆炸式增長(zhǎng),給用戶帶來(lái)新資訊的同時(shí),也增加了用戶篩選有用信息并最終做出決策的難度.個(gè)性化搜索和推薦算法深度而準(zhǔn)確挖掘用戶潛在需求和興趣偏好,向用戶推薦其可能感興趣且滿足用戶需求的項(xiàng)目,進(jìn)而提供高質(zhì)量的個(gè)性化服務(wù)[1-2].然而,互聯(lián)網(wǎng)技術(shù)的發(fā)展以及互聯(lián)網(wǎng)參與人數(shù)的激增,使得各類互聯(lián)網(wǎng)應(yīng)用中聚集了大量用戶生成內(nèi)容(User generated content,UGC),如:用戶評(píng)分、商品類別標(biāo)簽、用戶文本評(píng)論、社交網(wǎng)絡(luò)信息、地理位置信息、圖像或視頻等各種各樣的復(fù)雜數(shù)據(jù),這些信息具有多源異構(gòu)異質(zhì)特性.在個(gè)性化搜索過(guò)程中充分利用多源異構(gòu)UGC 數(shù)據(jù),勢(shì)必將在很大程度上提高個(gè)性化搜索和推薦的綜合性能[3-4].其中,構(gòu)建精確描述用戶個(gè)性化偏好的用戶興趣模型是個(gè)性化搜索問(wèn)題的關(guān)鍵.目前常用的構(gòu)建用戶興趣模型的方法包括貝葉斯模型[5]、多層感知機(jī)[6]、自編碼器[7]、受限玻爾茲曼機(jī)(Restricted Boltzmann machine,RBM)[8]、卷積神經(jīng)網(wǎng)絡(luò)(Convolutional neural network,CNN)[9]等.Kim 等[9]整合了CNN 和概率矩陣分解,提出了卷積矩陣分解(Convolutional matrix factorization,ConvMF)模型.Jin 等[10]通過(guò)元路徑引導(dǎo)鄰域捕獲節(jié)點(diǎn)間的交互模式,提出了高效的端到端基于鄰域的交互模型,用于基于異構(gòu)信息網(wǎng)絡(luò)的推薦.這些方法的成功應(yīng)用展示了綜合考慮多源異構(gòu)信息對(duì)于提高推薦系統(tǒng)和個(gè)性化搜索性能是十分有利的.另外,受到人類視覺(jué)機(jī)理的啟發(fā),基于注意力機(jī)制(Attention mechanism,AM)的神經(jīng)網(wǎng)絡(luò)已成功應(yīng)用于圖像處理、自然語(yǔ)言理解、語(yǔ)音識(shí)別、模式生成等領(lǐng)域[11-12].融合AM 的神經(jīng)網(wǎng)絡(luò)充分利用特征及其重要性程度,使得神經(jīng)網(wǎng)絡(luò)在處理數(shù)據(jù)時(shí)加強(qiáng)重要特征,有利于更有效地進(jìn)行特征提取.Zhou 等[12]提出了基于AM 用戶行為模型處理推薦問(wèn)題.湯文兵等[13]提出了基于注意力機(jī)制的協(xié)同卷積動(dòng)態(tài)推薦網(wǎng)絡(luò),捕捉高階特征交互.Li 等[14]提出了基于時(shí)間間隔感知的自注意力序列推薦算法.這些方法證明了融合AM神經(jīng)網(wǎng)絡(luò)的有效性,加強(qiáng)了重要特征對(duì)應(yīng)用領(lǐng)域的貢獻(xiàn).然而,現(xiàn)有大部分研究工作均假設(shè)所有數(shù)據(jù)已知且充足,模型訓(xùn)練復(fù)雜度較大,且考慮的數(shù)據(jù)類型較單一,面對(duì)高稀疏性數(shù)據(jù)時(shí)通常表現(xiàn)不佳,同時(shí),未考慮用戶興趣偏好的動(dòng)態(tài)變化特性,模型難以隨新增UGC 及時(shí)更新,不適用于實(shí)際應(yīng)用場(chǎng)景中個(gè)性化搜索.
個(gè)性化搜索本質(zhì)上是一類復(fù)雜的定性指標(biāo)優(yōu)化問(wèn)題,也是目前人工智能領(lǐng)域亟待解決的難題.用戶參與進(jìn)化搜索的交互式進(jìn)化計(jì)算(Interactive evolutionary computations,IECs)能夠有效利用用戶對(duì)優(yōu)化問(wèn)題的主觀評(píng)價(jià)和決策,將人類智能評(píng)價(jià)信息與傳統(tǒng)進(jìn)化優(yōu)化算法相結(jié)合,是處理個(gè)性化搜索這類復(fù)雜定性指標(biāo)優(yōu)化問(wèn)題的可行途徑[15-17].Sun 等[15]考慮區(qū)間適應(yīng)值的不確定性,提出了基于代理模型的交互式遺傳算法(Interactive genetic algorithm,IGA),處理復(fù)雜設(shè)計(jì)問(wèn)題.Chen 等[17]利用基于語(yǔ)言模型的編碼,結(jié)合基于Dirichlet 多項(xiàng)式復(fù)合分布的用戶偏好表示和貝葉斯推理機(jī)制,提出了改進(jìn)IEDA 算法.Bao 等[8]充分挖掘用戶隱式偏好信息,構(gòu)建基于RBM 的用戶偏好模型,提出了RBM 模型驅(qū)動(dòng)的交互式分布估計(jì)算法(Interactive estimation of distribution algorithms,IEDA).
這些方法從構(gòu)建用戶偏好代理模型設(shè)計(jì)進(jìn)化優(yōu)化策略的角度處理個(gè)性化搜索問(wèn)題,為進(jìn)化計(jì)算在個(gè)性化搜索和推薦中的應(yīng)用進(jìn)行了嘗試,取得了良好效果.但是,融合多源異構(gòu)UGC 和基于偏好代理模型進(jìn)化計(jì)算(Evolutionary computations,ECs)的相關(guān)研究較少,已有研究也僅僅利用了單一類型UGC信息,此外,沒(méi)有考慮UGC 不同特征信息對(duì)用戶認(rèn)知偏好和ECs 算子的影響.
基于代理模型的進(jìn)化算法在復(fù)雜工程和函數(shù)優(yōu)化中已有較多研究成果,主要利用進(jìn)化過(guò)程中產(chǎn)生的數(shù)據(jù)或者生產(chǎn)實(shí)踐中獲得的數(shù)據(jù),采用機(jī)器學(xué)習(xí)方法等構(gòu)建模型,在進(jìn)化過(guò)程中,利用該模型代替復(fù)雜適應(yīng)度評(píng)價(jià)函數(shù),實(shí)現(xiàn)對(duì)進(jìn)化個(gè)體的適應(yīng)值估計(jì),進(jìn)而提高進(jìn)化優(yōu)化的效率.常用代理模型包括:多項(xiàng)式回歸模型[18]、支持向量機(jī)[19]、神經(jīng)網(wǎng)絡(luò)[20]和克里金模型[21]等.Min 等[22]提出了基于多問(wèn)題代理模型的遷移進(jìn)化多目標(biāo)優(yōu)化算法.Wang 等[23]結(jié)合基于代理模型的低代價(jià)魯棒估計(jì)和時(shí)間消耗的實(shí)際魯棒性測(cè)量,提出了基于圖嵌入的大規(guī)模網(wǎng)絡(luò)代理模型輔助魯棒優(yōu)化算法.Cai 等[24]提出了一種廣義代理模型輔助的進(jìn)化算法處理高維高代價(jià)優(yōu)化問(wèn)題.顯然,已有代理模型均基于數(shù)值型描述的優(yōu)化問(wèn)題,而本文研究面向UGC 的個(gè)性化搜索,需要構(gòu)建用戶偏好代理模型,其處理對(duì)象為文本、類別標(biāo)簽、打分?jǐn)?shù)據(jù)甚至圖像等,傳統(tǒng)代理模型不再適用.
本文考慮深入理解和充分挖掘多源異構(gòu)UGC數(shù)據(jù),利用無(wú)監(jiān)督學(xué)習(xí)RBM 模型強(qiáng)大的表示學(xué)習(xí)能力和AM 在特征選擇方面的突出表現(xiàn),設(shè)計(jì)融合多源異構(gòu)數(shù)據(jù)和AM 的RBM 用戶偏好代理模型,并結(jié)合IECs 進(jìn)化優(yōu)化框架,提出增強(qiáng)RBM 驅(qū)動(dòng)的IEDA,應(yīng)用于個(gè)性化搜索中.充分利用多源異構(gòu)UGC 數(shù)據(jù)包含的文本類信息,包括用戶評(píng)價(jià)和項(xiàng)目類別兩類連續(xù)、離散混合數(shù)據(jù),提取與用戶認(rèn)知偏好高度相關(guān)的特征,獲取表示用戶偏好的注意力權(quán)重,構(gòu)建精準(zhǔn)擬合用戶搜索偏好的基于注意力機(jī)制和RBM 的用戶認(rèn)知偏好模型,實(shí)現(xiàn)多重特征交互,同時(shí)捕捉低階至高階的基于多源異構(gòu)數(shù)據(jù)的用戶偏好特征;在IEDA 框架下,設(shè)計(jì)基于RBM用戶偏好的概率模型,生成含用戶偏好的可行解,同時(shí),設(shè)計(jì)基于RBM 用戶偏好代理模型的進(jìn)化個(gè)體適應(yīng)度估計(jì)函數(shù),為搜索對(duì)象提供量化的評(píng)價(jià)值,部分代替用戶評(píng)價(jià)選擇優(yōu)良個(gè)體,生成用戶可能感興趣的項(xiàng)目推薦列表;考慮用戶偏好的動(dòng)態(tài)演化特性,根據(jù)新增UGC 數(shù)據(jù)和模型管理機(jī)制,動(dòng)態(tài)更新融合多源異構(gòu)數(shù)據(jù)和AM 的RBM 用戶偏好模型,引導(dǎo)個(gè)性化進(jìn)化搜索過(guò)程,以期快速準(zhǔn)確地搜索用戶滿意解,提高個(gè)性化搜索算法的評(píng)分預(yù)測(cè)準(zhǔn)確性和推薦效果.
本文貢獻(xiàn)主要包括3 個(gè)方面:1)針對(duì)含用戶生成內(nèi)容的個(gè)性化搜索問(wèn)題,充分挖掘用戶生成內(nèi)容中的連續(xù)語(yǔ)義特征和離散類別特征,給出基于RBM 的特征融合方法和注意力權(quán)重確定策略,以及融合注意力權(quán)重的RBM 用戶偏好模型構(gòu)建機(jī)制,以擬合用戶興趣偏好的動(dòng)態(tài)變化過(guò)程;2)基于所構(gòu)建RBM 偏好模型,通過(guò)計(jì)算當(dāng)前用戶偏好個(gè)體中決策變量屬性值為1 的概率,建模用戶的興趣選擇傾向,形成IEDA 進(jìn)化個(gè)體生成的采樣概率模型;3)基于RBM 模型參數(shù)確定法則是最小化能量函數(shù)的原則,利用能量函數(shù)構(gòu)建了分布估計(jì)算法(Estimation of distribution algorithm,EDA)進(jìn)化個(gè)體適應(yīng)值評(píng)價(jià)代理模型,進(jìn)而實(shí)現(xiàn)了面向含用戶生成內(nèi)容個(gè)性化進(jìn)化搜索的高效IEDA 算法.
本文后續(xù)內(nèi)容組織如下:第1 節(jié)給出所提算法框架;第2 節(jié)詳細(xì)描述基于注意力機(jī)制和RBM 的用戶認(rèn)知偏好模型構(gòu)建;第3 節(jié)提出基于偏好模型的交互式分布估計(jì)算法;第4 節(jié)給出實(shí)例分析;最后總結(jié)本文工作.
1 算法框架
本文旨在利用UGC 和RBM 建模用戶偏好特征及其動(dòng)態(tài)變化過(guò)程,以交互式進(jìn)化優(yōu)化的方式,準(zhǔn)確刻畫用戶實(shí)時(shí)興趣,抽取用戶行為規(guī)律和發(fā)展動(dòng)態(tài),可望從海量數(shù)據(jù)構(gòu)成的動(dòng)態(tài)演化空間中引導(dǎo)用戶盡快搜索到滿意解,提高面向多源異構(gòu)UGC的個(gè)性化搜索的綜合性能.
所提融合注意力機(jī)制的增強(qiáng)受限玻爾茲曼機(jī)驅(qū)動(dòng)的交互式分布估計(jì)算法(Enhanced restricted Boltzmann machine-driven interactive estimation of distribution algorithms with attention mechanism,AM-ERBM-IEDA)的基本框架如圖1 所示.首先根據(jù)用戶查詢信息,獲得初始物品集合及其UGC 數(shù)據(jù),作為EDA 初始化搜索空間;分別將UGC 的評(píng)價(jià)文本和類別標(biāo)簽送入doc2vec 和multihot 編碼模塊,獲得UGC 數(shù)據(jù)的向量化表示;將量化表示的UGC 作為RBM 偏好模型的輸入,訓(xùn)練該模型;計(jì)算RBM 偏好模型的輸入層分布概率,將其作為EDA種群再生的采樣概率模型;基于RBM 能量函數(shù)定義,構(gòu)建EDA 進(jìn)化個(gè)體(搜索物品)適應(yīng)值代理模型,以估計(jì)個(gè)體適應(yīng)值,實(shí)現(xiàn)選擇操作,將TopN列表提交給用戶評(píng)價(jià),實(shí)現(xiàn)交互過(guò)程;在進(jìn)化過(guò)程中,根據(jù)用戶交互信息和代理模型估計(jì)值管理RBM 模型更新過(guò)程,以跟蹤用戶興趣變化,從而更新采樣概率模型和適應(yīng)值代理模型.循環(huán)上述過(guò)程,直至用戶找到滿意物品.
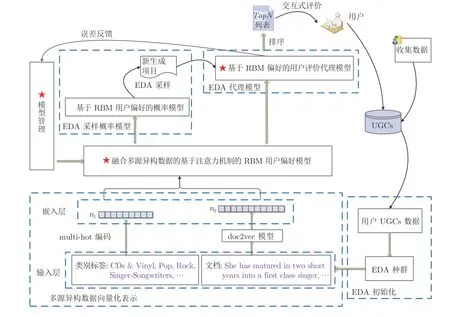
圖1 AM-ERBM-IEDA 算法框架Fig.1 The framework of AM-ERBM-IEDA algorithm
圖1中,“?”標(biāo)記模塊為核心部分,包括:基于注意力機(jī)制和RBM 的用戶認(rèn)知偏好模型構(gòu)建、基于RBM 用戶偏好的交互式分布估計(jì)算法,特別是EDA采樣概率模型計(jì)算,以及EDA 用戶評(píng)價(jià)代理模型和管理.
2 基于注意力機(jī)制和RBM 的用戶認(rèn)知偏好模型構(gòu)建
2.1 面向評(píng)價(jià)和類別UGC 的用戶偏好特征提取
多源異構(gòu)UGC 數(shù)據(jù)中包含豐富的用戶歷史交互行為數(shù)據(jù)(如:用戶對(duì)項(xiàng)目的評(píng)分?jǐn)?shù)據(jù)、用戶對(duì)項(xiàng)目的文本評(píng)論等)、項(xiàng)目?jī)?nèi)容信息(如:項(xiàng)目類別標(biāo)簽等)、用戶之間的社交網(wǎng)絡(luò)關(guān)系等,這些數(shù)據(jù)含有大量用戶顯式和隱式的興趣偏好信息,充分探索和挖掘這些有用信息,建模基于注意力機(jī)制和RBM的用戶認(rèn)知偏好模型,能夠有效提高個(gè)性化搜索算法的性能.該模型包含3 個(gè)模塊:融合多源異構(gòu)數(shù)據(jù)的RBM 注意力權(quán)重生成模塊、注意力層和基于注意力機(jī)制的RBM 模塊,其結(jié)構(gòu)示意圖如圖2所示.
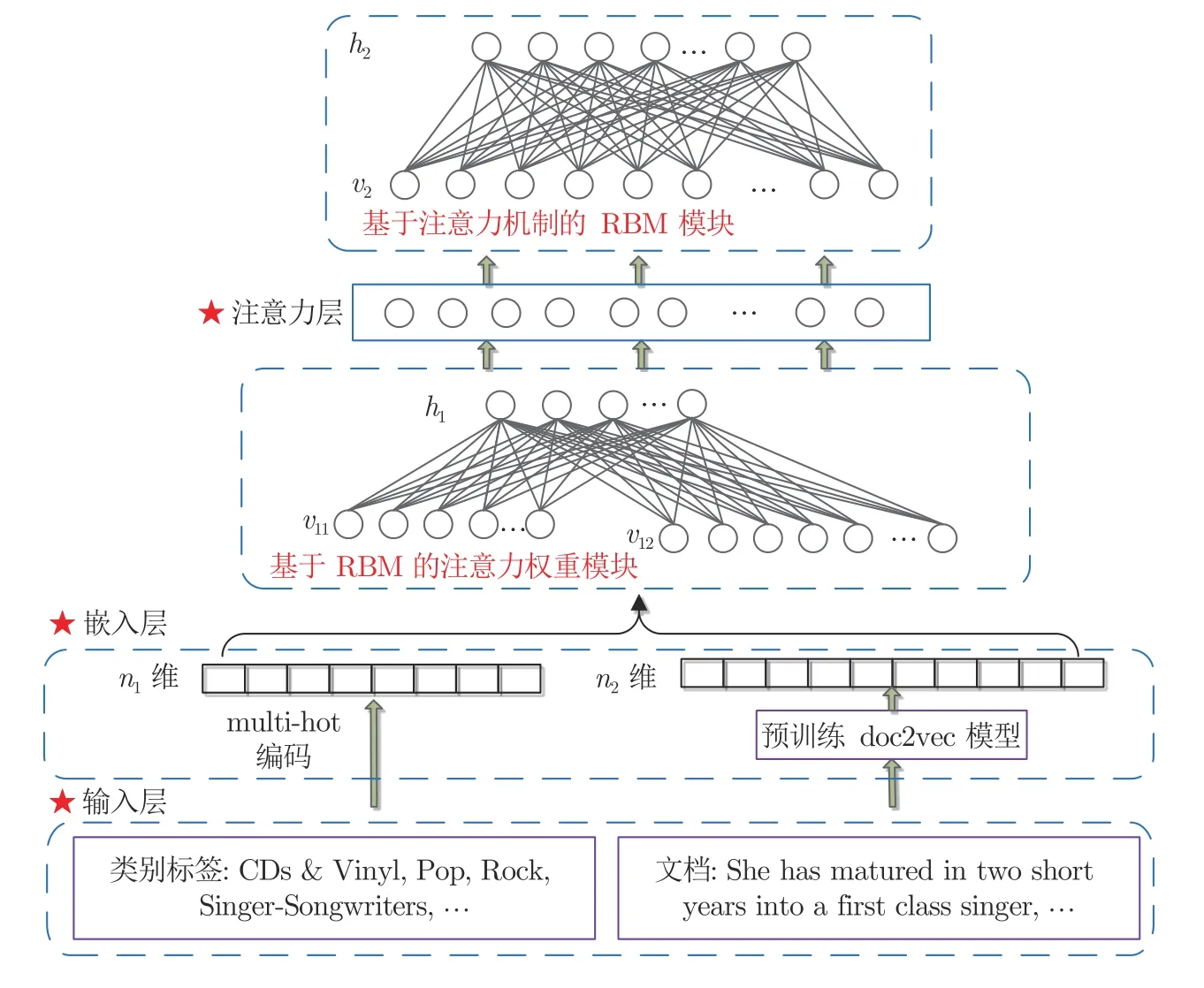
圖2 基于注意力機(jī)制和RBM 的用戶認(rèn)知偏好模型Fig.2 User cognitive preference model based on attention mechanism and RBM
融合多源異構(gòu)數(shù)據(jù)的RBM 注意力權(quán)重生成模型具有兩層網(wǎng)絡(luò)結(jié)構(gòu):v11為第1 組可見(jiàn)層,有n1個(gè)可見(jiàn)單元,表示項(xiàng)目的類別特征;v12為第2 組可見(jiàn)層,有n2個(gè)可見(jiàn)單元,表示用戶對(duì)項(xiàng)目評(píng)論的文本特征;h1為隱層,有m1個(gè)隱單元,表示用戶偏好特征.其中,層間全連接,層內(nèi)無(wú)連接,可見(jiàn)單元和隱單元均為實(shí)數(shù).該模型的輸入數(shù)據(jù)由用戶評(píng)分?jǐn)?shù)據(jù)、項(xiàng)目類別標(biāo)簽和用戶文本評(píng)論構(gòu)成,具體如下:
3)將用戶對(duì)項(xiàng)目的文本評(píng)論進(jìn)行數(shù)據(jù)預(yù)處理,基于數(shù)據(jù)集的語(yǔ)料庫(kù)訓(xùn)練doc2vec 文本向量化表示模型[25],生成用戶文本評(píng)論的向量化表示T=,其中,tij表示用戶ui對(duì)于項(xiàng)目xj的文本評(píng)論的向量化表示.Du中各項(xiàng)目的文本評(píng)論向量化表示Tu,即
由多源異構(gòu)UGC 數(shù)據(jù)整合模型訓(xùn)練數(shù)據(jù),表示為|Du|×n特征向量矩陣Vu,即
根據(jù)訓(xùn)練數(shù)據(jù)集Vu和對(duì)比散度(Contrastive divergence,CD)學(xué)習(xí)算法[26],訓(xùn)練融合多源異構(gòu)數(shù)據(jù)的RBM 注意力權(quán)重生成模型,獲得包含用戶u偏好特征的模型參數(shù),均為實(shí)數(shù).
當(dāng)給定可見(jiàn)單元狀態(tài)時(shí),各隱單元的激活狀態(tài)條件獨(dú)立,第j個(gè)隱單元的激活概率為
其中,ci表示第1 組可見(jiàn)層v11中第i個(gè)可見(jiàn)單元的狀態(tài);ti表示第2 組可見(jiàn)層v12中第i個(gè)可見(jiàn)單元的狀態(tài);表示隱層h1中第j個(gè)隱單元的狀態(tài);表示可見(jiàn)單元i與隱單元j之間的連接權(quán)重;表示第j個(gè)隱單元的偏置;σ(x)=1/(1+exp(-x))是sigmoid 激活函數(shù).
當(dāng)給定隱單元狀態(tài)時(shí),各可見(jiàn)單元的激活狀態(tài)亦條件獨(dú)立,第1 組和第2 組可見(jiàn)層第i個(gè)可見(jiàn)單元的激活概率分別為
模型訓(xùn)練完成后可同時(shí)獲得兩類信息:用戶u對(duì)當(dāng)前待搜索對(duì)象的偏好特征,即隱層輸出;用戶u對(duì)于項(xiàng)目中各決策變量的偏好程度,即輸入層最終獲得的.
2.2 基于注意力機(jī)制的偏好特征集成
考慮用戶歷史行為中不同項(xiàng)目的屬性特征對(duì)評(píng)分預(yù)測(cè)的貢獻(xiàn)的差異性,增加了注意力層,對(duì)用戶的個(gè)性化偏好特征賦予不同權(quán)重,著力分析不同特征間的關(guān)聯(lián)度,以加強(qiáng)重要特征對(duì)評(píng)分預(yù)測(cè)的貢獻(xiàn).
計(jì)算用戶u的注意力權(quán)重atu,即
用戶u偏好的注意力權(quán)重atu刻畫了項(xiàng)目中各決策變量對(duì)于用戶u偏好特征的重要性程度,由此得到優(yōu)勢(shì)群體Du中第i個(gè)項(xiàng)目個(gè)體的編碼表示,即
則Du中所有項(xiàng)目個(gè)體的融合多源異構(gòu)數(shù)據(jù)的基于AM 的向量表示為,即
將Du中的個(gè)體xu再次輸入已訓(xùn)練好的融合多源異構(gòu)數(shù)據(jù)的RBM 注意力權(quán)重生成模型,幫助融合多源異構(gòu)數(shù)據(jù)的基于AM 的RBM 用戶偏好模型將注意力集中于重要的特征,更精細(xì)地表達(dá)當(dāng)前用戶u的偏好特征.由此得到可見(jiàn)單元的輸出,即
其中,softmax(·)函數(shù)保證所有權(quán)重系數(shù)之和為1.函數(shù)衡量了項(xiàng)目個(gè)體xu相對(duì)于用戶偏好特征的注意力權(quán)重系數(shù),計(jì)算式為
進(jìn)一步獲得訓(xùn)練數(shù)據(jù)集Xu中個(gè)體xu的基于AM 的用戶偏好注意力權(quán)重At(xu),即
其中,at(xi)表示Du中項(xiàng)目個(gè)體xi(i=1,2,···,|D|)融合AM 的注意力權(quán)重系數(shù),即
注意力層抽取并融合了用戶對(duì)于個(gè)體決策變量的注意力權(quán)重系數(shù)A(xu),從全局的角度考慮項(xiàng)目各屬性特征對(duì)于用戶偏好的影響,加權(quán)求和獲得融合AM 的注意力權(quán)重系數(shù)的用戶偏好特征向量At(xu),更加關(guān)注對(duì)用戶偏好貢獻(xiàn)大的屬性特征.
2.3 融合高度相關(guān)特征的用戶認(rèn)知偏好模型構(gòu)建
各項(xiàng)目個(gè)體基于AM 的向量表示為At(Xu),由此訓(xùn)練基于AM 的RBM 用戶偏好模型,獲取用戶偏好特征的高階關(guān)系.當(dāng)給定可見(jiàn)單元狀態(tài)時(shí),第j個(gè)隱單元的激活概率為
當(dāng)給定隱單元狀態(tài)時(shí),第i個(gè)可見(jiàn)單元的激活概率為
3 基于偏好模型的交互式分布估計(jì)算法
3.1 分布估計(jì)算法概率更新模型
在IEDA 進(jìn)化優(yōu)化框架下,設(shè)計(jì)基于RBM 用戶偏好的概率模型Pu(x),即
基于RBM 用戶偏好的概率模型Pu(x)通過(guò)計(jì)算當(dāng)前用戶偏好的項(xiàng)目中決策變量屬性值為1 的概率p(xi=1),以概率生成的角度表示用戶對(duì)于項(xiàng)目的偏好,建模用戶興趣選擇傾向.在IEDA 進(jìn)化優(yōu)化過(guò)程中,隨機(jī)采樣概率模型Pu(x),生成包含當(dāng)前用戶偏好的Pop個(gè)新個(gè)體.根據(jù)相似性準(zhǔn)則,將生成的新個(gè)體與搜索空間中的項(xiàng)目進(jìn)行相似性匹配,選擇出相同的項(xiàng)目或者最相似的項(xiàng)目作為可行解,構(gòu)成待推薦項(xiàng)目集合Su.
3.2 基于偏好模型的物品適應(yīng)度函數(shù)
由第2 節(jié)已訓(xùn)練好的融合多源異構(gòu)數(shù)據(jù)的基于AM 的RBM 用戶偏好模型的能量函數(shù)項(xiàng)目x在(x,h2)狀態(tài)下的能量函數(shù)隱式表達(dá)了用戶u對(duì)于項(xiàng)目x的偏好程度,即
3.3 計(jì)算復(fù)雜性分析
本文所提算法的計(jì)算復(fù)雜性由訓(xùn)練用戶文本評(píng)論的doc2vec 向量化表示模型、訓(xùn)練用戶偏好模型和篩選可行解所決定.其中,用戶文本評(píng)論的doc2vec向量化表示模型的訓(xùn)練是離線計(jì)算.訓(xùn)練用戶偏好模型的計(jì)算復(fù)雜性為O(|Du|×(n1+n2)×m);選擇Su個(gè)可行解的時(shí)間花費(fèi)是O(Su×D),D是搜索空間中的項(xiàng)目數(shù)量;計(jì)算Su個(gè)候選項(xiàng)目的個(gè)體適應(yīng)值的時(shí)間花費(fèi)為O(Su).因此,本文所提算法每代總的計(jì)算復(fù)雜性為O(|Du|× (n1+n2)×m+Su×D).
4 實(shí)驗(yàn)結(jié)果與分析
為了驗(yàn)證所提算法的綜合性能,將其應(yīng)用于Amazon[14]的6 個(gè)數(shù)據(jù)集和Yelp 數(shù)據(jù)集,這些數(shù)據(jù)集包括豐富的多源異構(gòu)數(shù)據(jù),如:用戶ID、項(xiàng)目ID、用戶對(duì)項(xiàng)目的1~5 整數(shù)值評(píng)分、項(xiàng)目類別、用戶文本評(píng)論、用戶評(píng)論時(shí)間等信息.數(shù)據(jù)集的統(tǒng)計(jì)信息描述如表1 所示.
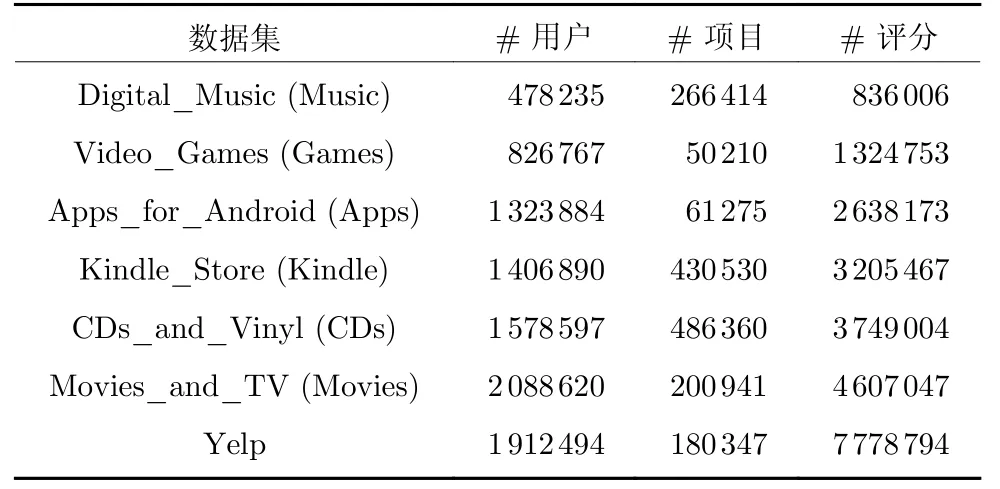
表1 數(shù)據(jù)集統(tǒng)計(jì)信息Table 1 Statistical information of datasets
實(shí)驗(yàn)環(huán)境是Intel Core i5-4590 CPU 3.30 GHz和4 GB RAM,實(shí)驗(yàn)平臺(tái)使用Python 3.6 開(kāi)發(fā).為了客觀比較本文所提算法的性能,選擇Random、Popularity、BPRMF[5]、ConvMF[9]、ATRank[12]、RBMAEDA[20]、DRBM[8]算法進(jìn)行對(duì)比實(shí)驗(yàn)和分析.BPRMF、ConvMF 和ATRank 都是有監(jiān)督學(xué)習(xí)的推薦算法,BPRMF 隱因子數(shù)目為20.RBMAEDA是一種基于無(wú)監(jiān)督學(xué)習(xí)的個(gè)性化搜索算法.實(shí)驗(yàn)中采用以下評(píng)價(jià)指標(biāo):均方根誤差(Root mean square error,RMSE)、命中率(Hit ratio,HR)、平均準(zhǔn)確率(Average precision,AP)、平均準(zhǔn)確率均值(Mean average precision,mAP)[8]和運(yùn)行時(shí)間.
4.1 用戶偏好認(rèn)知模型的可靠性
在數(shù)據(jù)集中隨機(jī)選取10 個(gè)測(cè)試用戶,按用戶評(píng)論時(shí)間順序排列,分別以70%和30%的比例劃分訓(xùn)練數(shù)據(jù)集和測(cè)試數(shù)據(jù)集,使用各種推薦算法為測(cè)試用戶進(jìn)行個(gè)性化搜索實(shí)驗(yàn),各種推薦算法分別獨(dú)立運(yùn)行10 次,記錄相應(yīng)的平均實(shí)驗(yàn)結(jié)果.本文所提算法的實(shí)驗(yàn)參數(shù)如表2 所示.
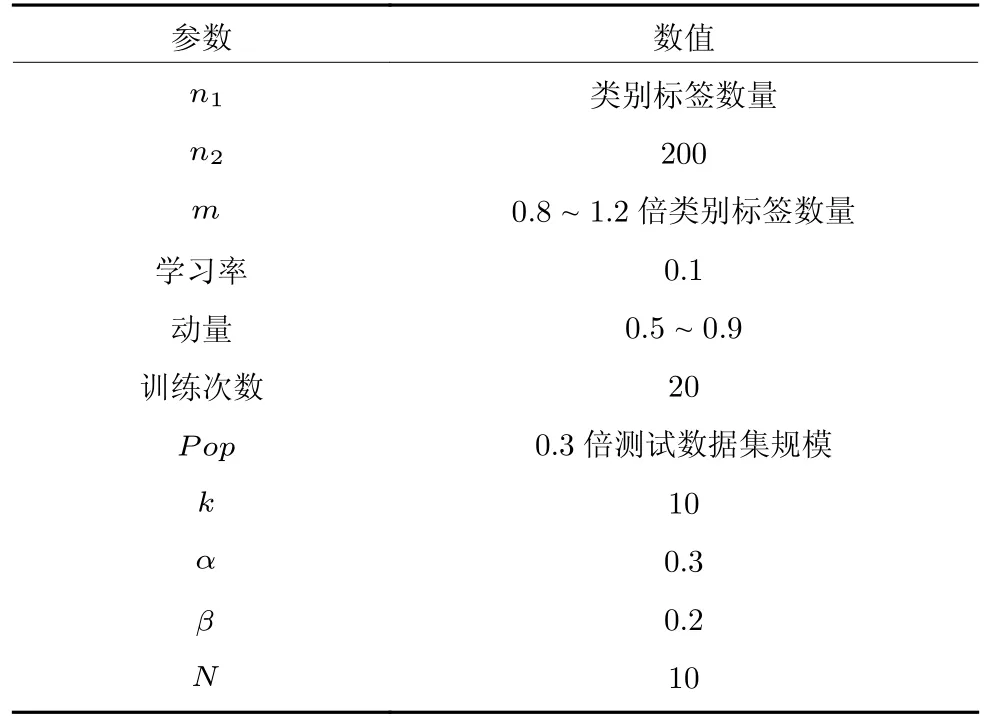
表2 算法的實(shí)驗(yàn)參數(shù)Table 2 Experimental parameters of our algorithm
為了證明本文所提融合多源異構(gòu)數(shù)據(jù)的RBM用戶偏好模型及基于RBM 用戶偏好的代理模型的可行性和有效性,在各種不同領(lǐng)域的數(shù)據(jù)集中進(jìn)行了大量實(shí)驗(yàn).RBM-MsH 算法考慮了各項(xiàng)用戶評(píng)分?jǐn)?shù)據(jù)、類別標(biāo)簽和文本評(píng)論,是沒(méi)有融合AM 的RBM用戶偏好模型算法.融合了AM 和多源異構(gòu)UGC數(shù)據(jù)的增強(qiáng)RBM 的個(gè)性化搜索算法(Integrating attention mechanism into RBM for multi-source heterogeneous UGC),記為AtRBM-MsH.表3 中展示了各算法實(shí)驗(yàn)結(jié)果,最優(yōu)結(jié)果用粗體標(biāo)注.
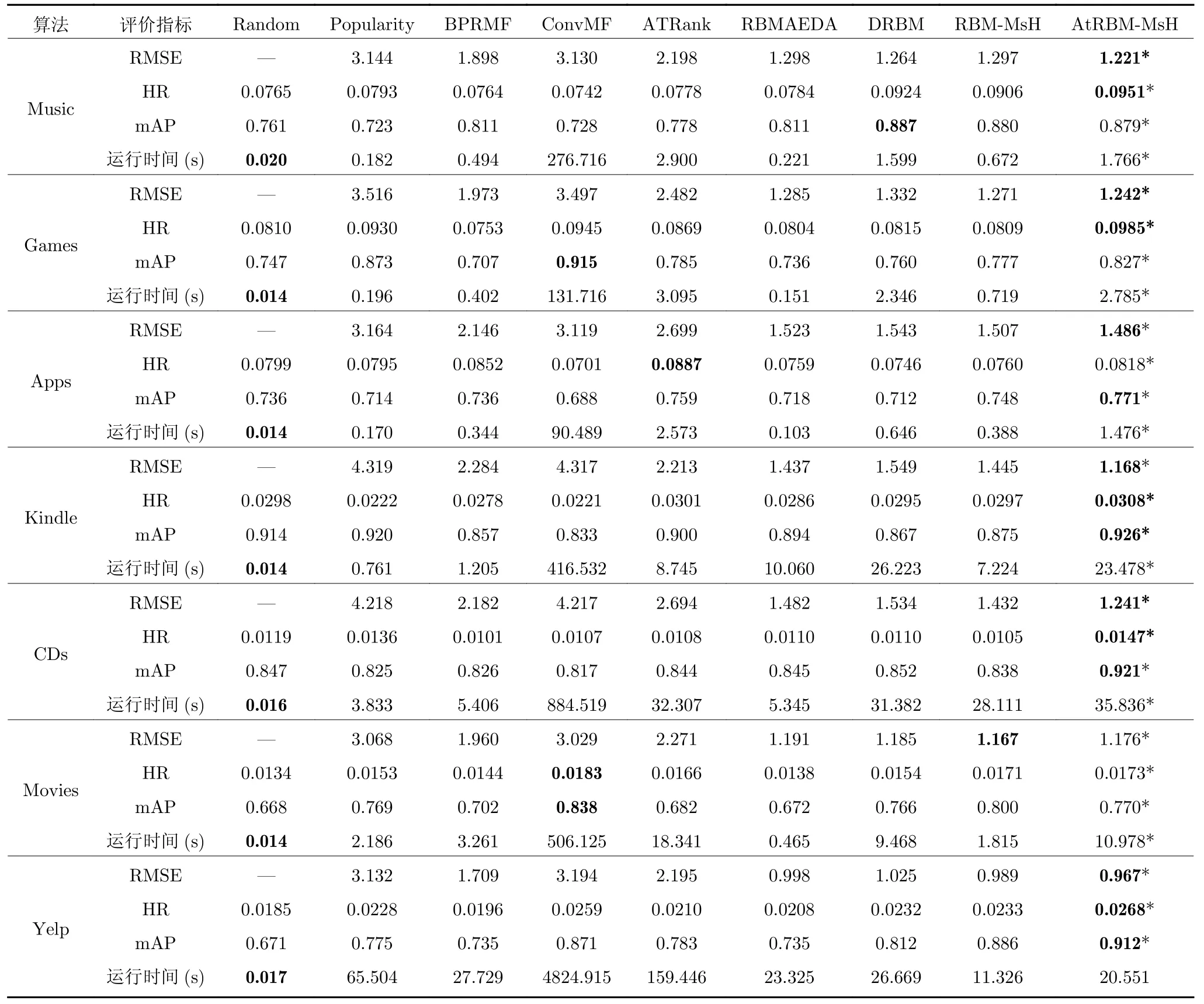
表3 對(duì)比實(shí)驗(yàn)結(jié)果Table 3 Experiments compared with popular recommendation algorithms
實(shí)驗(yàn)中,置信水平0.95 的Mann-Whitney U是一種非參數(shù)檢驗(yàn),用來(lái)展示本文所提算法的顯著性不同,帶有標(biāo)記“*”的數(shù)據(jù)表示該算法與其他算法有顯著性不同.
由表3 可得出以下結(jié)論:
1)在大部分?jǐn)?shù)據(jù)集中,AtRBM-MsH 都取得了最優(yōu)的結(jié)果,如:在Kindle 數(shù)據(jù)集中RMSE 值取得了最優(yōu)1.168,低于ATRank 算法47.22%,而HR和mAP 值取得了0.0308 和0.926,分別高于次優(yōu)ATRank 算法2.33%和2.89%,展示了本文所提算法模型比其他模型具備更強(qiáng)的特征提取能力和表示學(xué)習(xí)能力,進(jìn)行更準(zhǔn)確的評(píng)分預(yù)測(cè)和有效的項(xiàng)目推薦.同樣地,在Yelp 數(shù)據(jù)集中也取得了優(yōu)良的預(yù)測(cè)準(zhǔn)確性和推薦效果.
2)在各數(shù)據(jù)集中,AtRBM-MsH 總體上優(yōu)于BPRMF、ConvMF 和ATRank 這些有監(jiān)督學(xué)習(xí)算法,其中,ConvMF 算法的時(shí)間花費(fèi)巨大,是因?yàn)镃NN 深度學(xué)習(xí)網(wǎng)絡(luò)的運(yùn)算過(guò)程復(fù)雜、訓(xùn)練時(shí)間較長(zhǎng),使得這類基于深度學(xué)習(xí)的推薦算法在所有數(shù)據(jù)集上計(jì)算代價(jià)最高.Random 和Popularity 算法無(wú)法有效獲取用戶的偏好特征,在進(jìn)行推薦時(shí)不具備個(gè)性化特性,總體上的推薦效果不如個(gè)性化搜索算法.Random 算法的時(shí)間花費(fèi)獲得最小值,這是容易理解的.在保證預(yù)測(cè)精度和推薦準(zhǔn)確性的情況下,AtRBM-MsH 利用基于RBM 的個(gè)性化搜索方法極大縮短了構(gòu)建用戶偏好模型的訓(xùn)練時(shí)間,在推薦效果和時(shí)間花費(fèi)上取得了較好的折中效果.
3)在各數(shù)據(jù)集對(duì)比實(shí)驗(yàn)中,AtRBM-MsH 全部?jī)?yōu)于RBMAEDA,這是因?yàn)镽BMAEDA 只考慮了用戶評(píng)分?jǐn)?shù)據(jù)和項(xiàng)目類別標(biāo)簽進(jìn)行個(gè)性化搜索,而AtRBM-MsH 算法綜合考慮了UGC 中的多源異構(gòu)數(shù)據(jù)和影響用戶偏好的決策變量的重要程度,構(gòu)建基于AM 的RBM 用戶偏好模型,更加有利于抽取用戶偏好特征,取得了最優(yōu)的預(yù)測(cè)精度、推薦效果和用戶滿意度.另外,RBM-MsH 雖然考慮了多源異構(gòu)UGC 數(shù)據(jù),但沒(méi)有引入AM,綜合推薦效果優(yōu)于RBMAEDA,但是不如AtRBM-MsH,進(jìn)一步說(shuō)明了融合AM 的有效性.
因此,本文所提算法聯(lián)合多源異構(gòu)UGC 數(shù)據(jù)和AM,深入理解項(xiàng)目類別標(biāo)簽和用戶文本評(píng)論,加強(qiáng)重要特征對(duì)于構(gòu)建用戶偏好模型的貢獻(xiàn),同時(shí),減輕數(shù)據(jù)稀疏對(duì)評(píng)分預(yù)測(cè)的影響,進(jìn)行有效的項(xiàng)目推薦,具備良好的評(píng)分預(yù)測(cè)精確性和項(xiàng)目推薦準(zhǔn)確率.
4.2 基于偏好模型的個(gè)性化搜索有效性
為了充分展示本文所提算法的個(gè)性化搜索和推薦性能,以Kindle_Store 數(shù)據(jù)集中用戶“A13QTZ8-CIMHHG4”為例,篩選當(dāng)前用戶評(píng)分?jǐn)?shù)據(jù)和用戶文本評(píng)論,按時(shí)間順序排列截取前 #% 為訓(xùn)練數(shù)據(jù)集,后(100 -#)%為測(cè)試數(shù)據(jù)集,測(cè)試在不同的數(shù)據(jù)集稀疏度情況下用戶進(jìn)行個(gè)性化搜索.表4 是測(cè)試用戶的個(gè)性化搜索實(shí)驗(yàn)結(jié)果.
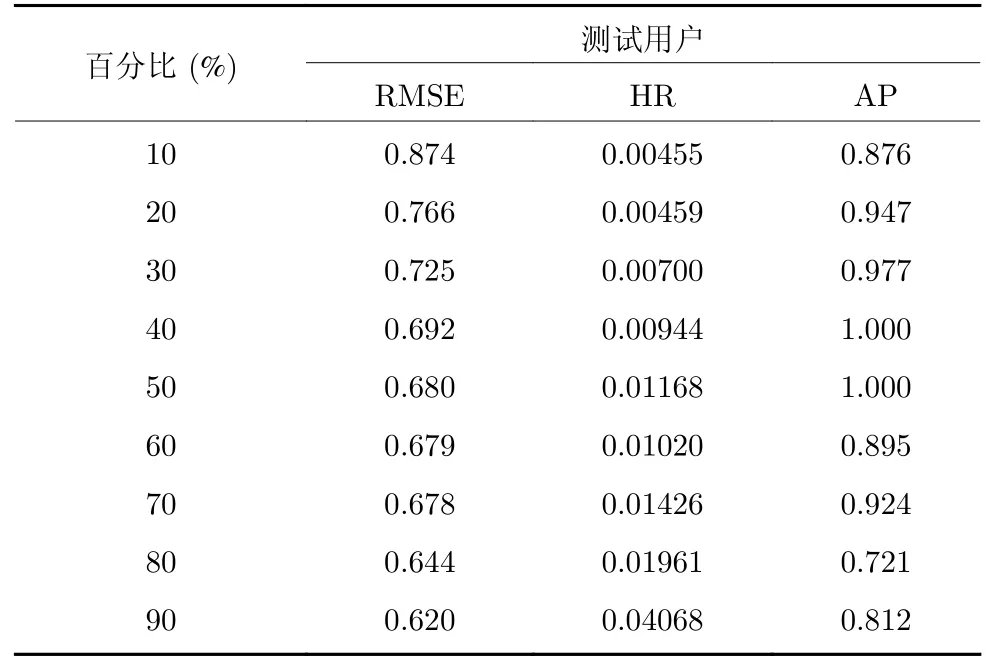
表4 測(cè)試用戶個(gè)性化搜索實(shí)驗(yàn)結(jié)果Table 4 Experimental results of a test user
實(shí)驗(yàn)結(jié)果表明,在數(shù)據(jù)稠密度只有30%時(shí),At-RBM-MsH 也達(dá)到了很好的預(yù)測(cè)精度和推薦準(zhǔn)確性,幾乎是把用戶喜歡的項(xiàng)目都排在了TopN項(xiàng)目推薦列表的前面,具備更好的用戶滿意度和用戶體驗(yàn).隨著數(shù)據(jù)集中稠密度的逐漸增大,AtRBMMsH 的預(yù)測(cè)精度和推薦準(zhǔn)確性也在不斷提高,說(shuō)明當(dāng)數(shù)據(jù)稠密時(shí)有用信息逐漸增加,有利于融合多源異構(gòu)數(shù)據(jù)的RBM 用戶偏好模型抽取當(dāng)前用戶偏好特征,為個(gè)性化搜索算法提供了有效的用戶偏好策略引導(dǎo).
圖3是以圖形形式展示測(cè)試用戶分別利用RBMAEDA、DRBM、RBM-MsH 和AtRBM-MsH 算法進(jìn)行個(gè)性化搜索的實(shí)驗(yàn)結(jié)果.
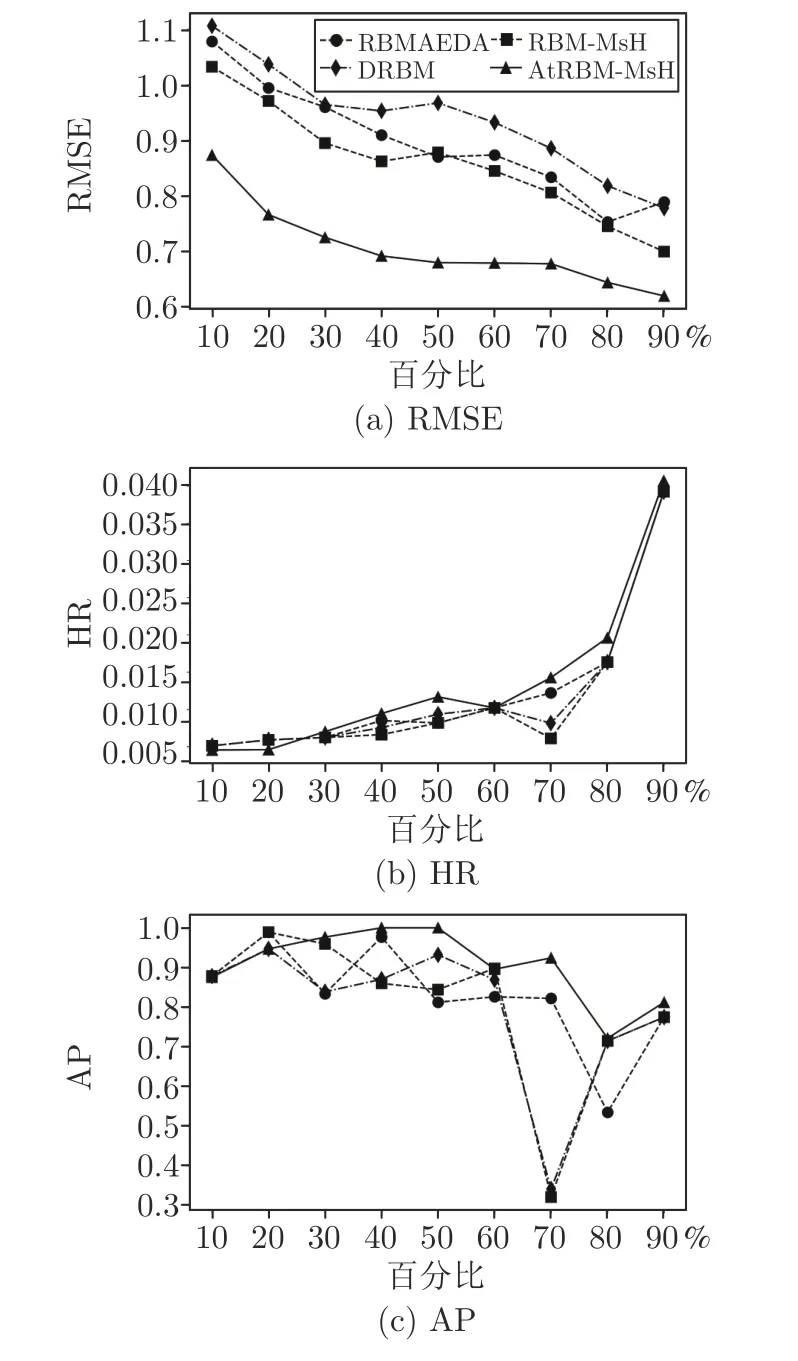
圖3 測(cè)試用戶個(gè)性化搜索實(shí)驗(yàn)Fig.3 Experimental results of a test user
從圖3 可以看出,用戶對(duì)于項(xiàng)目的文本評(píng)論包含了較多的用戶偏好信息,融合多源異構(gòu)數(shù)據(jù)的RBM-MsH 優(yōu)于只考慮項(xiàng)目類別標(biāo)簽的RBMAEDA和DRBM,而AtRBM-MsH 能夠充分整合多源異構(gòu)UGC 數(shù)據(jù)和AM,有效抽取用戶偏好,獲得了優(yōu)良的綜合性能.
為了進(jìn)一步展示本文提出的AtRBM-MsH 輔助的IEDA (AtRBM-MsH assisted IEDA,At-RIEDA-MsH)算法的綜合性能,在CDs_and_Vinyl 數(shù)據(jù)集隨機(jī)選擇某用戶,將未結(jié)合IEDA 框架的AtRBM-MsH 算法與AtRIEDA-MsH 算法進(jìn)行了對(duì)比實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如圖4 所示.
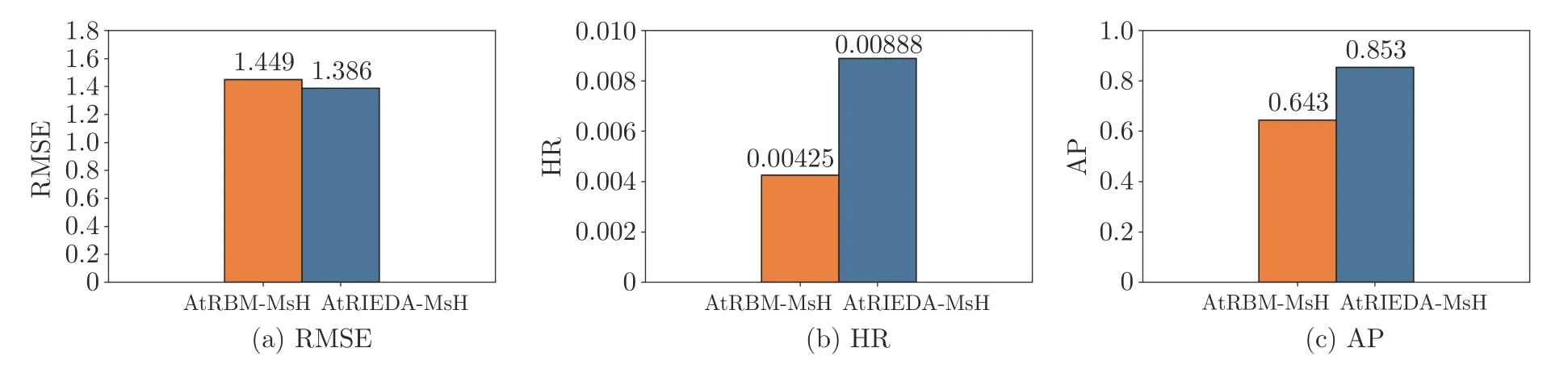
圖4 CDs_and_Vinyl 數(shù)據(jù)集測(cè)試用戶個(gè)性化搜索實(shí)驗(yàn)Fig.4 Experimental results of a test user on CDs_and_Vinyl
從圖4 中可以看出,AtRIEDA-MsH 優(yōu)于At-RBM-MsH,其RMSE 值降低了4.35%,HR 和AP分別提高了108.94%和32.66%,展示了在IEDA框架下充分利用多源異構(gòu)UGC 數(shù)據(jù),融合AM 構(gòu)建增強(qiáng)的基于RBM 用戶偏好模型,抽取用戶偏好特征,引導(dǎo)用戶進(jìn)行個(gè)性化搜索是可行且有效的.
4.3 基于交互式分布估計(jì)算法的UGC 搜索的有效性
在實(shí)驗(yàn)中,隨機(jī)選擇某用戶參與交互式個(gè)性化搜索過(guò)程,前50%作為訓(xùn)練數(shù)據(jù)集,其中,前20%作為初始的歷史交互數(shù)據(jù),后30% 數(shù)據(jù)分割為10 份,作為每次迭代的新增UGC,剩余50%作為個(gè)性化搜索的可行解搜索空間,模擬用戶的交互式個(gè)性化搜索的動(dòng)態(tài)過(guò)程,展示本文所提算法的可行性、有效性和適應(yīng)能力.將本文所提算法與5 種IECs:傳統(tǒng)IEDA、RBM 輔助的IGA (RBM assisted IGA,RBMIGA)、RBMAEDA[20]、DRBMIEDA[8]、RBM-MsH 輔助的IEDA (RBM-MsH assisted IEDA,RIEDA-MsH)算法進(jìn)行對(duì)比實(shí)驗(yàn),其中,IEDA 作為基線算法,RBMIGA 是IGA 框架下的基于RBM 個(gè)性化搜索算法.各算法進(jìn)行10 代優(yōu)化搜索,給出10 次評(píng)分預(yù)測(cè)和項(xiàng)目推薦,同時(shí),各算法獨(dú)立運(yùn)行10 次,計(jì)算平均評(píng)價(jià)指標(biāo)評(píng)估算法的綜合性能.實(shí)驗(yàn)結(jié)果如表5 所示,其中最優(yōu)解用粗體表示.
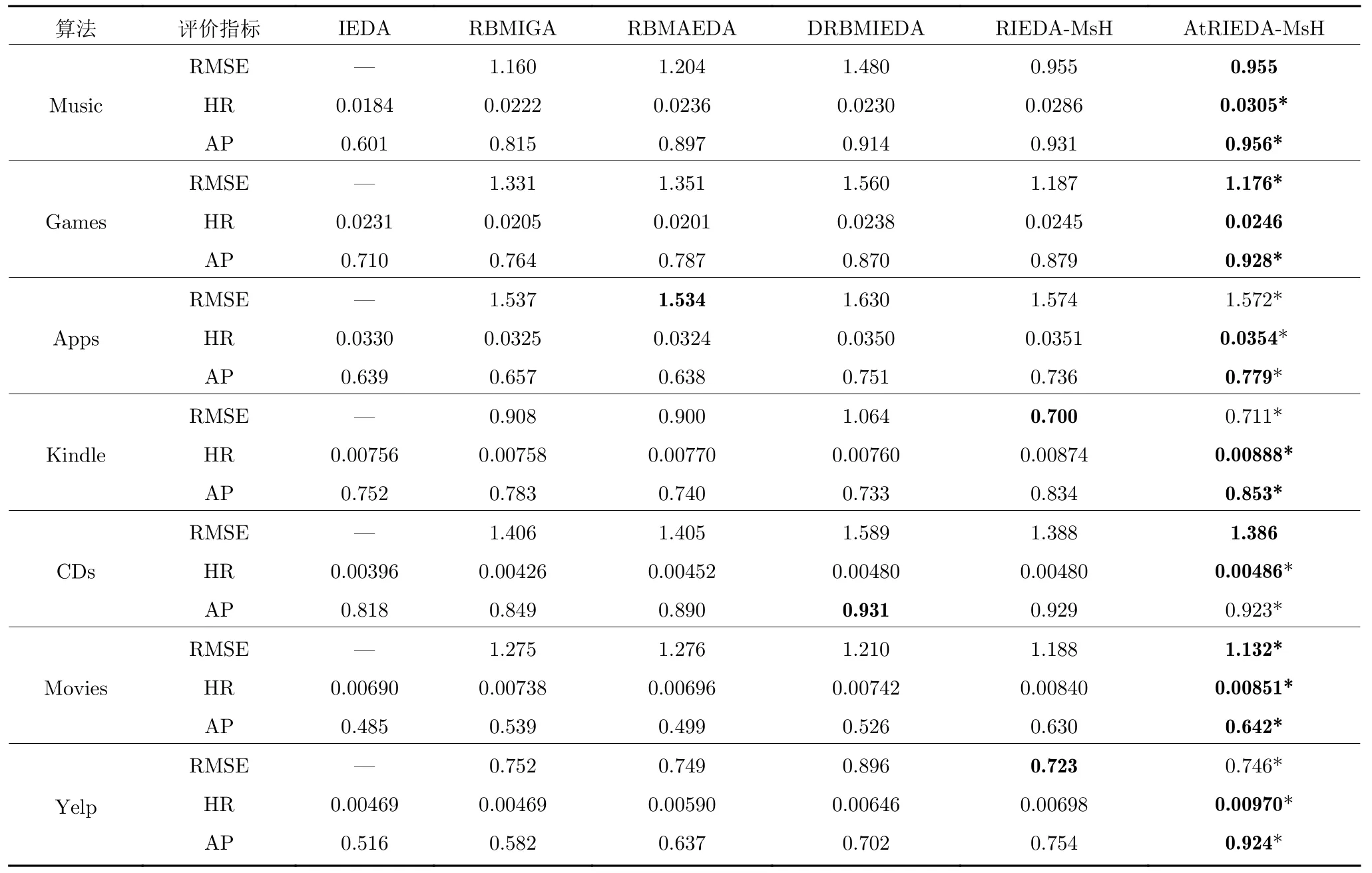
表5 對(duì)比實(shí)驗(yàn)結(jié)果Table 5 Comparison of experimental results
在表5 中,標(biāo)記“*”表示根據(jù)置信水平0.95 的Mann-Whitney U 非參數(shù)檢驗(yàn)算法顯著區(qū)別于其他算法.另外,由于在IEDA 算法中沒(méi)有構(gòu)造代理模型預(yù)測(cè)用戶對(duì)于項(xiàng)目的評(píng)分,所以IEDA 算法沒(méi)有RMSE 值.由表5 可得出以下結(jié)論:
1)在各數(shù)據(jù)集中,AtRIEDA-MsH 取得了最優(yōu)效果,如:在Music 數(shù)據(jù)集中AtRIEDA-MsH 平均RMSE 值獲得了最優(yōu)值0.955,HR 和AP 值分別為0.0305 和0.956,高于次優(yōu)RIEDA-MsH 算法6.64%和2.69%.在Yelp 數(shù)據(jù)集中也獲得了類似的實(shí)驗(yàn)結(jié)果.雖然在部分?jǐn)?shù)據(jù)集中一些評(píng)價(jià)指標(biāo)沒(méi)有取得最優(yōu)值,但是綜合比較獲得了最優(yōu)綜合性能.AtRIEDA-MsH 是在RBMAEDA 中融合了用戶文本評(píng)論和AM,更有利于構(gòu)建高效的用戶偏好模型、EDA 概率模型和用戶評(píng)價(jià)代理模型,提高了評(píng)分預(yù)測(cè)能力和推薦準(zhǔn)確性.
2)在各數(shù)據(jù)集對(duì)比實(shí)驗(yàn)中,RBMAEDA 優(yōu)于RBMIGA,RBMIGA 優(yōu)于IEDA,RIEDA-MsH 優(yōu)于RBMAEDA,說(shuō)明用戶文本評(píng)論相比較項(xiàng)目類別標(biāo)簽包含了更多的用戶偏好信息,幫助RIEDAMsH 算法提高了評(píng)分預(yù)測(cè)能力和推薦準(zhǔn)確性.更進(jìn)一步,AtRIEDA-MsH 算法考慮多源異構(gòu)UGC 數(shù)據(jù),利用基于注意力機(jī)制RBM 模型構(gòu)建用戶偏好模型,引導(dǎo)個(gè)性化搜索,取得了最優(yōu)的預(yù)測(cè)準(zhǔn)確性和綜合搜索效果.
為了進(jìn)一步展示本文所提算法的優(yōu)越性能,以圖形的形式動(dòng)態(tài)展示Music 和Games 數(shù)據(jù)集中用戶的個(gè)性化搜索過(guò)程,如圖5 和圖6 所示.
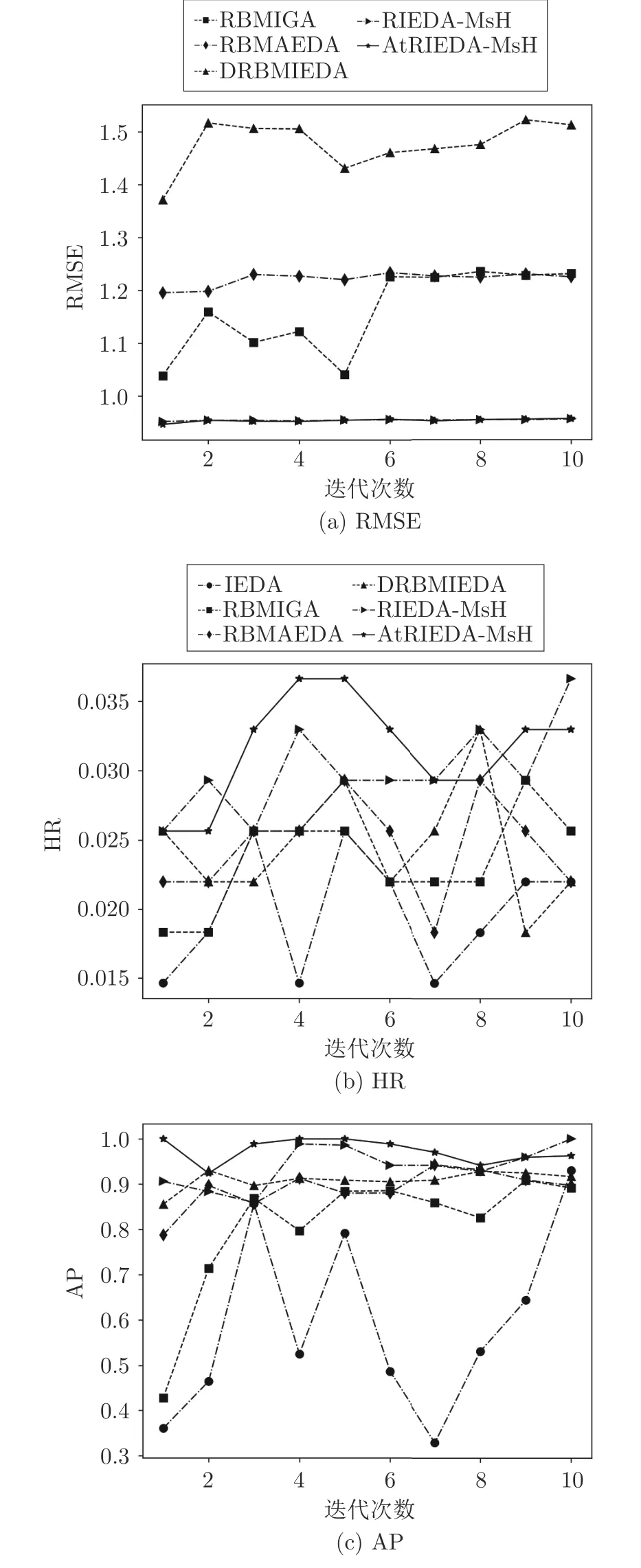
圖5 Music 數(shù)據(jù)集某用戶個(gè)性化搜索實(shí)驗(yàn)Fig.5 Experimental results of a test user on Music
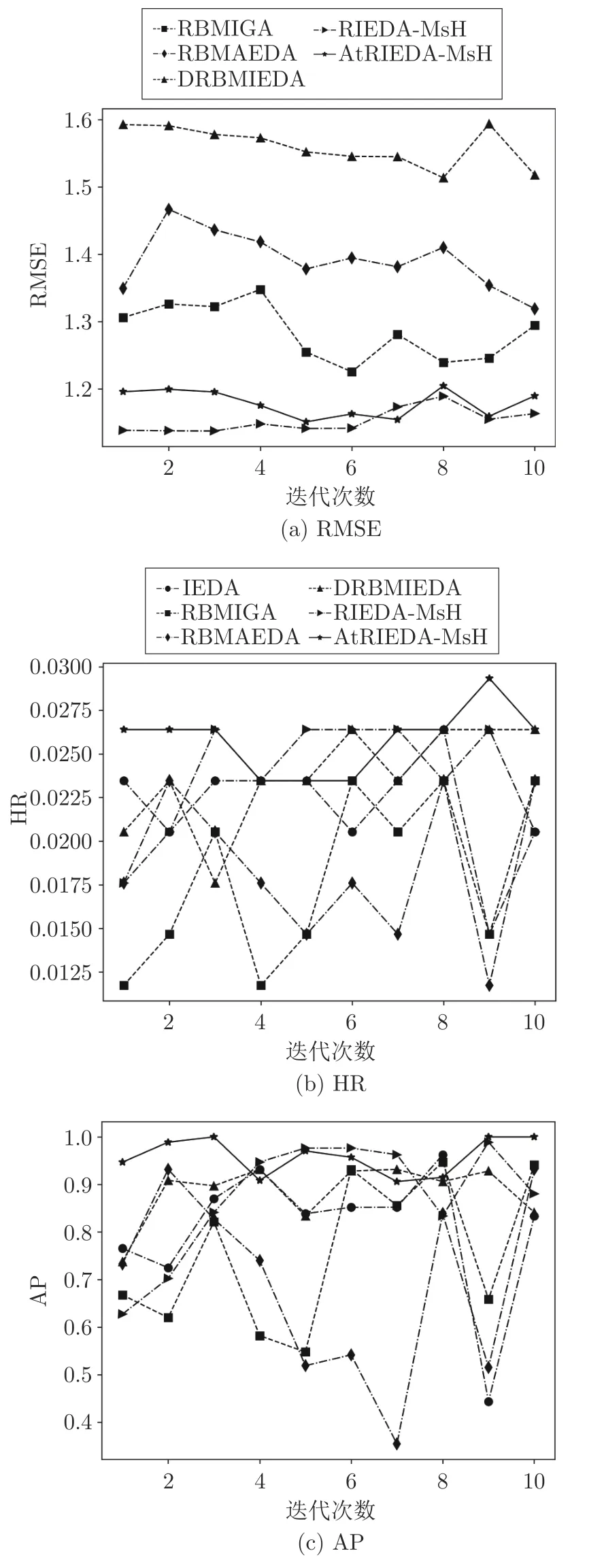
圖6 Games 數(shù)據(jù)集某用戶個(gè)性化搜索實(shí)驗(yàn)Fig.6 Experimental results of a test user on Games
從圖中可以看出,大部分情況下藍(lán)色線代表AtRIEDA-MsH 和紅色線代表的RIEDA-MsH 算法的RMSE 值低于其他對(duì)比算法,而HR 和AP 優(yōu)于其他算法,說(shuō)明本文所提出的算法能夠較好地抽取用戶偏好特征,動(dòng)態(tài)跟蹤用戶偏好,為當(dāng)前用戶進(jìn)行有效的個(gè)性化推薦,取得了較好的預(yù)測(cè)精確性和推薦準(zhǔn)確率,改善了用戶體驗(yàn)和滿意度.
5 結(jié)束語(yǔ)
針對(duì)如何在大數(shù)據(jù)環(huán)境下充分有效利用多源異構(gòu)UGC 數(shù)據(jù),本文提出了融合多源異構(gòu)數(shù)據(jù)的增強(qiáng)RBM 驅(qū)動(dòng)的IEDA,并將其應(yīng)用于個(gè)性化搜索這類復(fù)雜定性指標(biāo)優(yōu)化問(wèn)題中.利用多源異構(gòu)UGC數(shù)據(jù),構(gòu)建融合多源異構(gòu)數(shù)據(jù)的基于注意力機(jī)制的RBM 用戶偏好模型,幫助用戶偏好模型將關(guān)注點(diǎn)聚焦于屬性信息的重要特征,有效抽取用戶偏好特征,動(dòng)態(tài)跟蹤用戶興趣和偏好.同時(shí),以創(chuàng)造良好的用戶體驗(yàn)和平臺(tái)效益為目標(biāo),在IEDA 框架下構(gòu)建用戶與個(gè)性化搜索算法的交互式過(guò)程,設(shè)計(jì)了相應(yīng)的進(jìn)化優(yōu)化策略,通過(guò)用戶偏好模型所獲得的用戶認(rèn)知經(jīng)驗(yàn)和興趣偏好動(dòng)態(tài)引導(dǎo)當(dāng)前用戶逐漸搜尋到滿意解,從而有效解決了個(gè)性化搜索問(wèn)題.在今后的研究工作中,擬將進(jìn)一步有效利用圖像、視頻等信息,研究融合動(dòng)態(tài)群體智能IECs 的個(gè)性化搜索算法及其應(yīng)用,提供智能化、專屬化的用戶服務(wù)體驗(yàn).
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
