數字圖書館個性化服務行為信息挖掘系統的設計
2023-10-31 06:58:16蔡瑜婉
信息記錄材料 2023年9期
蔡瑜婉
(永春縣圖書館 福建 泉州 362600)
0 引言
傳統信息挖掘系統的缺陷就是系統響應速度慢,無法實現信息共享,不能夠滿足學生通過數字圖書館個性化服務交互行為對教學資源進行共享。以此,本文設計數字圖書館個性化服務行為信息挖掘系統,通過數據挖掘技術實現個性化交互服務行為信息的二次處理,對數字圖書館個性化交互服務行為信息潛在價值進行挖掘,從而實現高校教育教學的發展。數字圖書館使用信息挖掘技術,能夠提高信息資源組織、使用、集成和加工的效率。信息技術和智能技術的結合,為數字圖書館個性化推薦系統提供支撐。
1 數字圖書館信息挖掘系統的架構
1.1 云服務平臺的基本框架
設計個性化服務行為信息挖掘系統中的云服務平臺框架,要求與圖書館實際情況結合,整合和合理使用圖書館內部資源。云服務能夠將大量的數據提供給系統,使系統穩定地運行。在設計云服務平臺框架的過程中,基于基礎功能設計使圖書館內部資源作為系統設計重點,從而增強框架適應能力,提高擴展性,降低成本。
1.2 信息挖掘系統的架構設計
在個性化服務行為信息挖掘系統架構設計的過程中,將SSH框架作為核心架構。此框架開發周期短、結構簡單、維護方便,在多領域中廣泛使用,圖1為信息挖掘系統的總體架構。

圖1 信息挖掘系統的總體架構
(1)用戶層。使用JSP技術設計個性化服務行為信息挖掘系統架構用戶層,此技術具備高效處理優勢,被廣泛應用在多領域中,能夠實現個性化服務行為信息挖掘系統與用戶的交互邏輯處理。
(2)業務層。為了能夠使個性化服務行為信息挖掘系統穩定地運行,在設計業務層架構的過程中使用SSH框架開發系統業務層,實現系統業務層的層次細化,包括PO層、DAO層、Service層和Web層。利用細化的個性化服務行為信息挖掘系統業務層架構,方便個性化服務行為信息挖掘系統的維護,并且系統開發簡單方便。
(3)數據挖掘層。在設計數據挖掘的過程中,通過數據挖掘工具Weka處理數據,使Weka作為個性化服務行為信息挖掘系統數據挖掘架構核心,與聚類、神經網絡、決策樹分類等算法結合,以此實現個性化服務行為信息挖掘系統數據的規劃處理,使個性化服務行為信息挖掘系統穩定性得到提高。
(4)數據層。主要包括讀者瀏覽信息、借閱信息、圖書信息和個人信息等,該層能夠實現數據存儲。所以,實現圖書館內部數據資源的整合,通過此關系型數據庫存儲數據信息。
2 系統的詳細設計
2.1 數據預處理模塊
將數據處理過程劃分為在線與離線2個部分,利用系統處理之間的合理分配,使推薦速度得到提高[2]。離線設計是針對Web日志中的大規模海量數據信息,通過數據挖掘技術實現數據信息的加工處理,會耗費大量的時間,在線設計能夠處理當前會話用戶的在線推薦引擎問題。
2.1.1 數據準備
離線部分的主要功能就是準備數據,系統后臺存儲大量用戶訪問信息,通過處理之后得出有用的信息。在數據處理過程中,能夠實現用戶訪問信息、屬性信息的處理與過濾,對數據維度的處理過濾能夠促進數據挖掘[3]。數據準備為Web訪問挖掘的基礎工作,也是數據準備核心工作。在數據準備中,要對用戶訪問信息實現處理過濾等操作,具體步驟為:
(1)數據收集。在處理用戶訪問日志數據的過程中,要對客戶端與服務器端的數據信息進行收集。利用客戶端將多站點與單用戶的訪問行為反映出來,在服務器端用戶訪問的瀏覽行為比較模糊,客戶端比較精準;
(2)數據清洗。在收集用戶訪問Web的數據信息之后,要進行清洗與分類,對有價值的信息服務進行挖掘。清洗基于Web的訪問信息數據,實現數據的抽取和刪除,具體包括:①刪除與數據挖掘無關的數據,在用戶訪問Web日志信息中,存在與用戶Web訪問無關的數據,比如圖像文件等,需刪除無關的數據;②在一段時間內解析用戶數據挖掘的信息,合并后得出精準訪問Web數據信息,使數據信息轉化成為其他格式的數據。
(3)用戶識別。通過數據清洗的數據對每個用戶進行識別,有大量識別用戶的方法,比如利用IP地址、用戶注冊、嵌入會話ID等,都具有各自的優缺點。
(4)會話識別。用戶在對Web進行訪問時將此訪問劃分成為多個會話,此時能夠對不同用戶訪問記錄進行區分。針對同個頁面,用戶訪問會話能夠在訪問日志中單獨存儲。針對某用戶訪問時間跨度大的請求,會在用戶訪問某站點時,對不同會話使用時間窗表示。針對某時間窗,設置timeout值。
2.1.2 創建用戶興趣模型庫
(1)創建的意義。數字圖書館為資源信息集合中心,存儲大量資源信息。在用戶海量信息與數據方面,要求讀者尋找信息。另外,此類資源與信息不斷增加,所以要使用相應的措施快速尋找。因此,要求設計用戶興趣模型庫,根據知識模式尋找。
(2)用戶興趣模型庫。針對用戶個性化需求,無法使用統一標準對用戶需求多元素進行衡量,用戶在系統中不僅能夠對Web頁面感興趣,還能夠對圖書感興趣,利用用戶興趣庫衡量其他用戶的個性化需求,實現個性化信息服務設計[4]。數字圖書館為重要數據信息服務部門,假如要為用戶提供個性化信息服務,就要為用戶創建滿足實際用戶需求的興趣模型庫,包括用戶需要的數據和信息。之后通過數據挖掘算法與規則處理Web用戶數據,得到用戶興趣和行為習慣。
2.2 用戶興趣模型庫的生成
數字圖書推薦系統使圖書信息實現數字化,數字圖書館具有大量信息,用戶在海量資源中尋找自己需要的信息不容易。目前,圖書推薦系統要創建圖書資源[5]。此時,應轉變為以讀者用戶的思路創建,用戶興趣模型庫能夠使用戶深層次需求得到滿足,為其提供個性化推薦服務,圖2為用戶興趣模型庫生成流程。
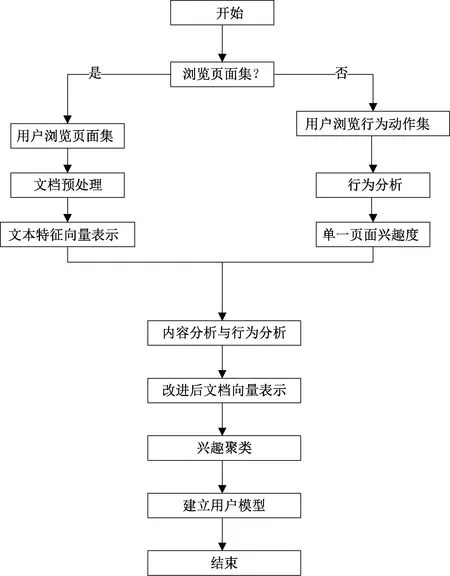
圖2 用戶興趣模型庫生成流程
第一階段為創建用戶興趣描述文檔,得出用戶信息需求,創建用戶興趣描述文檔包括Web瀏覽方式與瀏覽內容;第二階段為根據對象所描述的用戶興趣,關聯資源信息實現用戶興趣信息組織。Web瀏覽內容挖掘能夠分析用戶瀏覽的頁面聚類,創建用戶興趣數據庫模型,分析用戶瀏覽頁面行為。在此過程中,使兩者結合,能夠得出用戶感興趣的主題和感興趣程度,得出帶有加權的向量用戶興趣數據庫模型[6]。
針對用戶來說,分析用戶行為能夠快速得出用戶興趣。用戶瀏覽頁面與站點,在此基礎上會發生很多動作行為,比如用戶訪問頁面時的查詢和標記書簽等動作,還包括訪問頁面時的訪問次數、停留時間、編輯、保存等行為,此瀏覽行為能夠使用戶訪問頁面興趣度得到展現。
2.3 用戶興趣數據庫的更新
讀者在對資源信息進行訪問時,讀者的興趣也會有所改變。興趣變化會影響讀者的興趣領域知識中心,以此使資源信息分類樹節點權值改變,對讀者用戶重新歸類。在整個過程中,節點權值能夠相互鏈接。對于讀者用戶,如果沒有經常訪問就會降低權值,方便使最近訪問的節點在前面。
(1)權值更新。以讀者用戶對于資源信息不同的訪問方式修改資源信息分類樹中的權值,從而識別讀者興趣程度和領域,模型修改方法為式(1):
Newweight=oldWeight+r*t*k/D
(1)
式(1)中的r指的是讀者用戶對于資源信息訪問方式的參數,以方式重要性實現某值的設置,本文使用專家小組指定;t指時間長度;k指文獻資源信息關聯度,取值范圍為0~1;D指調節常量,對不同分類興趣增長速度控制。
(2)權值衰減。用戶興趣數據庫模型會改變讀者的用戶興趣度,讀者如果沒有對某資源信息進行訪問,那么相應的權值也會減少。在此過程中,如果當天訪問和沒有訪問的,就要區別對待,不能夠降低權值。連續沒有訪問天數的節點具有快衰減。那么,在對權值衰減設計的過程中,利用斐波那契數列實現權值衰減模型的設計,通過系統管理員實現興趣衰減的設置。
斐波那契數列為式(2):
fibo[0]=0,fibo[1]=1,fibo[n]=[n-1]+fibo[n-2]
(2)
對權值衰減時,在fibo[i]中的i=0的時候,不會衰減當天訪問節點的權值。如果i越大,表示連續沒有訪問天數比較長,權值衰減比較快。
2.4 智能代理服務
利用智能過濾技術創建數字圖書館個性化推薦服務,以信息共享平臺和智能推薦系統將個性化信息提供給用戶。結合用戶興趣愛好、專業、教育背景等全面分析用戶的知識結構,將信息數據進行智能化過濾,通過大數據挖掘技術分析用戶的興趣習慣,及時推薦給用戶文獻資源。以信息智能化的分類,系統中的用戶需求存在代理動態,根據智能過濾技術使用戶個性化需求得到滿足。
2.5 個性化定制
在用戶需求分析的過程中,個性化定制能夠通過用戶的行為數據模型預測用戶的需求,從而為用戶推送信息服務。此種服務模式要針對用戶個性化需求和自主意愿,利用有效數據集合推算分析和用戶興趣變動,預測用戶可能產生的閱讀行為和習慣,對系統中參數進行調整,并且提供用戶自主選擇功能,根據用戶的需求制定個性化的信息推薦服務[7-9]。通過結合用戶的結構知識和個人興趣,智能化定制館藏數字資源與網絡資源,使用戶個性化信息的獲取更加方便,主要實現代碼如圖3所示。
3 系統的測試
系統的運行環境詳見表1,對數字圖書館個性化交互服務的行為信息挖掘系統進行集成測試,根據測試規定步驟實現測試,對每個模塊之間的協調能力與數據流向進行掌握,測試的步驟詳見圖4。

表1 系統的運行環境
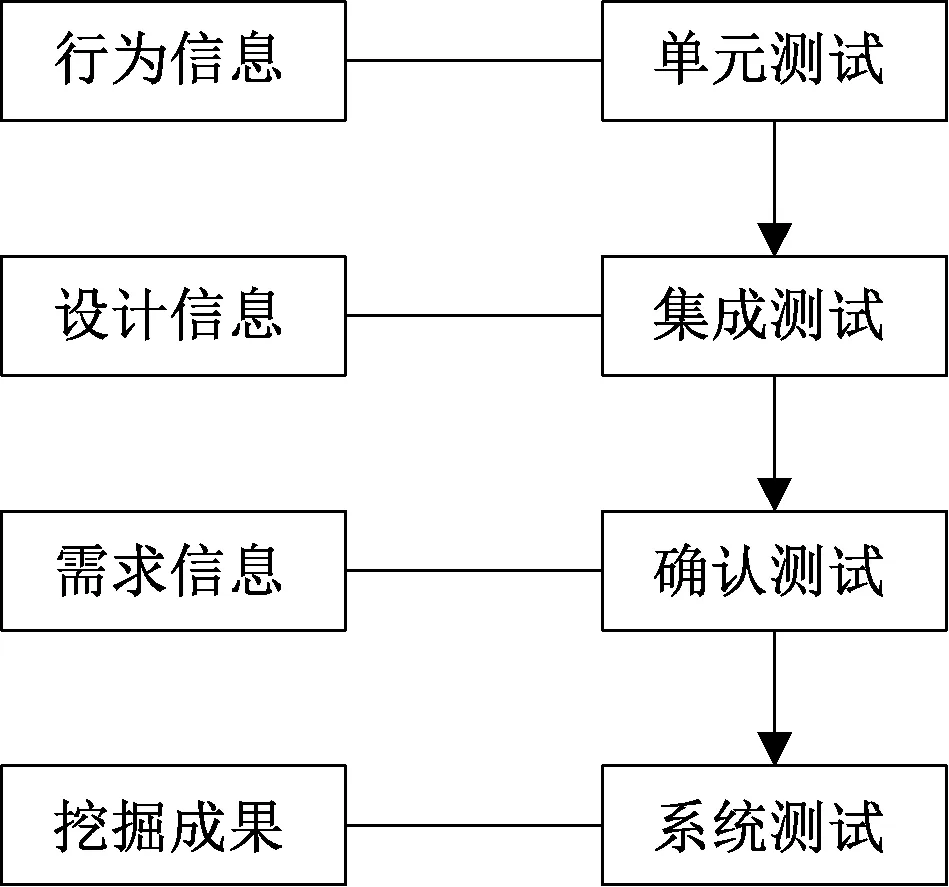
圖4 測試的步驟
通過以上系統測試步驟與運行環境,設置測試次數為50次,以傳統信息挖掘系統對各頁面響應時間進行記錄。表2為頁面響應時間的對比,不同界面系統具有不同的響應時間。傳統信息挖掘系統的登錄界面響應時間比較短,本文系統能夠使進入到系統的速度加快。以此可見,本文信息挖掘系統能夠促進系統響應速度。
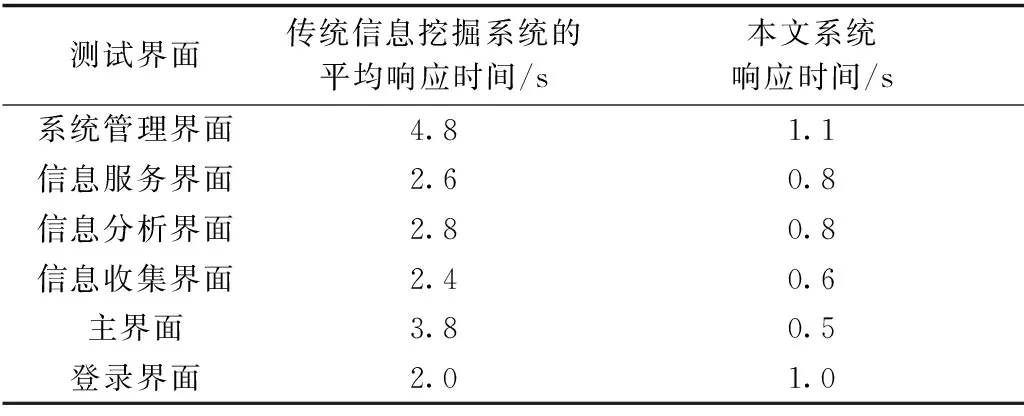
表2 頁面響應時間對比
4 結語
因為圖書館內部的信息比較多,會導致個性化服務行為信息挖掘系統在挖掘信息的時候出現響應速度慢等問題。為了使此問題得到解決,本文設計了個性化服務行為信息挖掘系統,并且對系統開展測試。通過測試結果表明,本文信息挖掘系統的平均響應速度比較快,此研究具有優勢。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
小太陽畫報(2018年1期)2018-05-14 17:19:25
電力與能源(2017年6期)2017-05-14 06:19:37
商用汽車(2016年11期)2016-12-19 01:20:16
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
信息通信技術(2015年6期)2015-12-26 01:16:46
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
創業家(2015年5期)2015-02-27 07:53:25
