人工智能在自然語言處理中的應用
2023-10-31 06:58:20房偉偉
信息記錄材料 2023年9期
房偉偉,韓 猛
(聊城職業技術學院 山東 聊城 252000)
0 引言
自然語言處理(natural language processing,NLP)是人工智能領域中的一個重要方向,致力于使計算機能夠理解和處理人類語言[1-2]。隨著社交媒體和在線論壇的廣泛應用,大量用戶生成并分享了海量的文本數據,使得暴力言論、仇恨言論等不良信息的傳播成了一個日益嚴重的問題[3-4]。在此情況下,發展有效的自然語言處理技術來自動檢測或過濾暴力言論變得尤為重要。長短期記憶網絡(long short-term memory,LSTM)作為一種重要的深度學習模型,具有良好的序列建模能力,特別適用于處理文本數據[5-6]。其能夠捕捉文本中的長期依賴關系,并具有一定的記憶能力,這使它在自然語言處理任務中表現出色。
本文旨在研究基于LSTM模型的暴力言論檢測系統,提出了一種基于LSTM的架構。通過在網絡文本數據上進行測試,驗證了該架構的有效性和可行性。本文首先對LSTM網絡進行了詳細的介紹,解釋了其結構和工作原理;其次提出了一種基于LSTM的暴力言論檢測架構,該架構利用LSTM網絡對輸入的文本進行建模,并通過訓練從中學習到暴力言論的特征表示;最后,使用網絡爬蟲抓取了大規模的網絡數據,并構建了一個相應的數據集,以評估所提出的架構在實際環境中的性能。
本文的研究成果對于社交媒體平臺、在線論壇以及其他涉及用戶生成文本的應用領域具有重要的實際意義。通過自動化檢測和過濾暴力言論,可以維護網絡空間的安全和健康發展,減少惡意行為對用戶的傷害。同時,本文還為基于深度學習的自然語言處理研究提供了一種新的思路和方法。
1 基于LSTM模型的暴力言論檢測
1.1 LSTM網絡
LSTM是一種具有記憶能力的遞歸神經網絡,被廣泛應用于序列建模任務中。其獨特的結構使其能夠有效地捕捉長期依賴關系,對于處理自然語言處理等序列數據具有重要意義。該網絡包含輸入層、隱藏狀態和輸出層三個基本結構,如圖1所示。
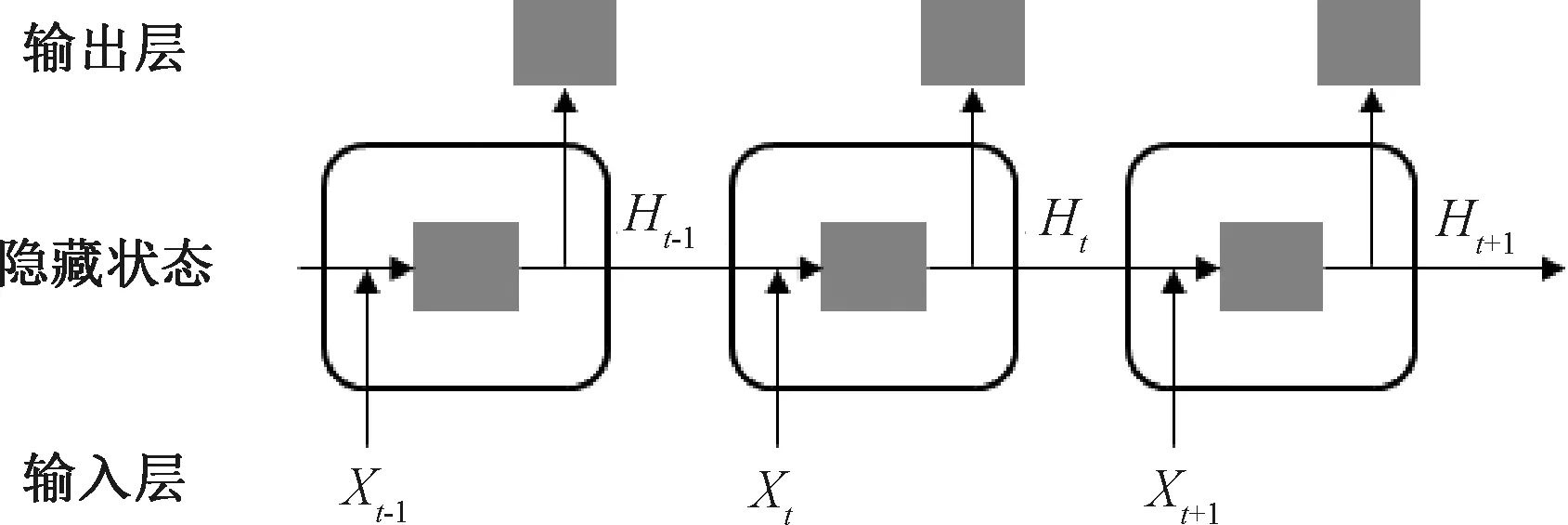
圖1 LSTM的基本結構
LSTM的輸入層接收序列數據,通常是文本、語音或時間序列數據,在每個時間步中,輸入均被表示為向量形式。假設在時間步t時,輸入向量為x(t)∈Rn,其中,n是輸入向量的維度。
LSTM中的隱藏狀態由兩個部分組成,分別是細胞狀態和隱藏狀態。細胞狀態負責存儲和傳遞長期記憶信息,而隱藏狀態負責在網絡中傳遞和共享信息。細胞狀態的更新通過遺忘門、輸入門和輸出門的控制來實現,遺忘門決定了細胞狀態在當前時間步保留多少以前的信息,輸入門決定了當前時間步的輸入信息對細胞狀態的更新程度,輸出門決定了細胞狀態的輸出到隱藏狀態的程度。細胞狀態C(t)的更新方式為式(1)所示:
C(t)=f(t)⊙C(t-1)+i(t)⊙g(t)
(1)
式(1)中,⊙表示逐元素相乘操作,f(t)是遺忘門的輸出,i(t)是輸入門的輸出,g(t)是候選細胞狀態,通過當前輸入和先前隱藏狀態計算得到。隱藏狀態h(t)的計算通過輸出門對細胞狀態進行調整為式(2)所示:
h(t)=o(t)⊙tanh(C(t))
(2)
式(2)中,o(t)是輸出門的輸出,tanh是雙曲正切函數,用于引入非線性變換。
LSTM的輸出層根據具體任務的需求而定。對于分類任務,通常使用softmax激活函數將隱藏狀態映射到預測類別的概率分布。假設有K個類別,LSTM的輸出向量h(t)∈Rm,其中m是隱藏狀態的維度。通過線性變換和softmax激活函數,可以將隱藏狀態映射到K維的預測概率向量y(t)∈RK:
y(t)=softmax(W(h(t))+b)
(3)
式(3)中,W和b分別是可學習的權重和偏差。
1.2 系統架構
基于LSTM的暴力言論檢測架構旨在利用LSTM來自動識別和過濾暴力言論。該架構基于文本輸入,通過LSTM網絡對輸入文本進行建模,并學習到暴力言論的特征表示,如圖2所示。

圖2 基于LSTM的暴力言論檢測架構
(1)輸入層:該架構接收文本作為輸入,通常是用戶生成的文本數據,如社交媒體帖子、評論或論壇發言等。輸入文本經過預處理,轉化為向量表示。
(2)LSTM層:輸入文本的向量表示被饋送到LSTM網絡中。LSTM網絡由多個LSTM單元組成,每個單元負責處理一個時間步的輸入。通過將輸入文本序列逐步輸入LSTM單元,網絡能夠對文本中的上下文信息進行建模,并捕捉長期依賴關系。LSTM單元中的遺忘門、輸入門和輸出門機制對細胞狀態進行更新和調整,從而提供豐富的文本表示。
(3)特征提取:LSTM網絡的隱藏狀態可以看作是對輸入文本的編碼表示。為了從中提取有關暴力言論的特征,可以在LSTM層之后添加一些附加的全連接層或卷積層。這些層可以進一步處理LSTM的隱藏狀態,以捕捉更高級的語義和結構信息。通過特征提取的過程,網絡能夠學習到更具區分性的暴力言論特征表示。
(4)分類器:在特征提取之后,得到的特征向量被輸入到分類器中進行最終的分類判別。分類器可以采用多種算法,例如支持向量機[7-8]或多層感知器[9-10]。本架構采用支持向量機對特征進行分類。
給定一個訓練數據集{xi,yi},其中xi是輸入的特征向量,yi∈{-1,1}表示樣本的類別標簽。支持向量機通過最大化間隔的思想來進行分類,其中間隔定義為超平面到最近的樣本點的距離。支持向量機的分類決策函數可以表示為式(4)所示:
f(x)=sign(wTx+d)
(4)
式(4)中,w是超平面的法向量,d是偏置(偏移)項,sign是符號函數,用于根據函數值的正負來判定樣本的類別。
支持向量機的目標是找到最優的w和d,使得分類決策函數能夠正確地將樣本分為不同的類別,并且間隔最大化。這可以轉化為一個優化問題,即最小化目標函數,同時滿足約束條件。通常使用凸優化方法來求解這個問題。支持向量機的優化問題可以表達為式(5)、式(6)、式(7)所示:
(5)
subject:yi(wTxi+d)≥1-ξi,i=1,2,…,n
(6)
ξi≥0,i=1,2,…,n
(7)
式(5)、式(6)、式(7)中,||w||2是權重向量||w||2的L2范數的平方,C是正則化參數,用于平衡間隔和分類誤差的權衡,ξi是松弛變量,用于處理樣本的不可分性。通過求解上述優化問題,可以得到最優的超平面參數w和d,從而構建支持向量機分類器。
2 實驗與分析
2.1 數據獲取
本研究用網絡爬蟲對微博評論進行爬取,并將部分文本界定為暴力言論。在此過程中,首先選擇Scrapy網絡爬蟲工具[11-12]對微博平臺上的評論進行抓取,通過設置爬蟲的初始鏈接和抓取規則,可以遍歷微博的相關頁面,提取評論數據;在爬取評論數據后,對數據進行預處理和文本清洗,包括去除HTML標簽、特殊字符和表情符號,并進行分詞和去除停用詞等操作,以獲得干凈的文本數據。其次通過將評論數據與相應的標簽關聯,可以建立一個訓練集,這些數據集包含正面樣本(暴力言論)和負面樣本(非暴力言論)。
2.2 模型訓練和測試
在使用數據集對基于LSTM的暴力言論檢測架構進行訓練和測試的階段:
(1)數據集劃分:將準備好的數據集劃分為訓練集和測試集。采用交叉驗證的方法,將數據集分為80%訓練模型,剩下的20%用于評估模型的性能,并確保訓練集和測試集的樣本分布和類別平衡。
(2)構建LSTM模型:基于LSTM的暴力言論檢測架構需要構建一個包含LSTM層、特征提取層和分類器的模型。通過定義合適的網絡結構、層數和節點數,以及選擇合適的激活函數、優化算法和損失函數,建立一個有效的模型。在訓練過程中,需要設置合適的超參數,如學習率、批次大小和迭代次數等。
(3)模型訓練:使用訓練集對LSTM模型進行訓練。將清洗和預處理后的評論文本數據輸入到LSTM模型中,通過反向傳播算法和梯度下降優化算法,更新模型的權重和偏置,以最小化損失函數。訓練過程中,監控模型在訓練集上的損失和性能指標,確保模型能夠逐漸收斂并學習到評論文本的特征表示。
(4)模型評估:在訓練過程完成后,使用測試集對訓練好的模型進行評估。將測試集的評論文本輸入到模型中,通過前向傳播算法獲得預測結果,并將其與真實標簽進行比較。使用評估指標,包括準確率、召回率、F1分數等,來評估模型在暴力言論檢測任務上的性能。
2.3 分析與討論
本研究用準確率、召回率和F1分數對該架構的評估結果如表1所示。

表1 模型評估
對于暴力言論類別,模型正確預測了85個樣本,錯誤預測了15個樣本,總共有100個正樣本。對于非暴力言論類別,模型正確預測了180個樣本,錯誤預測了20個樣本,總共有200個正樣本。通過計算準確率、召回率和F1分數,可以進行數據分析。
準確率表示模型正確預測的樣本占所有預測結果的比例。在該實驗中,暴力言論和非暴力言論類別的準確率分別為0.85和0.9,這意味著模型在預測暴力言論和非暴力言論時分別有85%和90%的準確性;召回率衡量模型對正樣本的識別能力,即模型能夠正確預測多少個正樣本,暴力言論和非暴力言論類別的召回率分別達到了0.85和0.9;暴力言論和非暴力言論類別的F1分數分別達到了0.85和0.9。這表明模型在暴力言論和非暴力言論的預測中有較好的平衡性能。
3 結論
綜上所述,本文開發了一種基于LSTM的暴力言論檢測系統,并對其在自然語言處理中的應用進行了驗證。實驗結果表明,該系統在檢測暴力言論方面具有良好的性能和準確性。通過合理設計和訓練LSTM模型,能夠準確地識別和分類暴力言論,為社交媒體平臺和在線社區提供一種有效的工具來過濾和管理不當言論。然而在進一步研究和應用中仍存在一些挑戰和改進空間:(1)數據集的構建和標定需要更加精細和全面,以提高模型的魯棒性和泛化能力;(2)優化模型的超參數選擇和調整,以進一步提升性能指標的表現。此外,還可以考慮引入更多的特征工程和深度學習模型優化方法,以提高暴力言論檢測的精度和效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
