融合注意力機制的電力集控安全隱患實體識別模型研究
2023-11-01 02:01:48張滈辰屈紅軍牛雪瑩耿琴蘭
自動化儀表 2023年10期
張滈辰,屈紅軍,牛雪瑩,耿琴蘭
(青海省電力公司科研綜合樓,青海 西寧 810000)
0 引言
當前,安全隱患記錄表是以自然語言的形式記錄的。由于電力安全隱患文本包含了大量的電力專業詞匯、數值符號、特殊符號、縮略詞等信息,導致實體邊界難以界定。由于電力領域數據集較少,導致傳統實體識別模型在識別電力領域實體時準確率較低。
傳統的實體識別模型主要有基于規則模板-字典的實體識別方法[1]、隱馬爾可夫實體識別模型[2]、條件隨機場(conditional random field,CRF)[3]模型等。雖然上述模型可以進行實體識別任務,但仍需要利用專家經驗對數據進行標注處理,再進行實體識別,存在工作量大、適用范圍小的缺點[4-5]。為了減少專家標注的工作量并實現自動提取文本特征的目標,需將深度學習應用在電力領域的實體識別中。文獻[6]利用循環神經網絡(recurrent neural network,RNN)對序列文本進行處理并提取文本特征,但RNN模型在處理長序列文本時容易出現梯度消失的問題。文獻[7]和文獻[8]在雙向長短時記憶(bidirectional long short-term memory,BiLSTM)網絡模型的基礎上加入反向,對文本進行雙向特征提取。文獻[9]在BiLSTM模型的基礎上加入CRF,通過CRF模型獲取最優標注序列。文獻[10]通過加入注意力機制增加重要信息的權重,進一步提高了實體識別的效果。為了進一步提高實體識別的準確率,研究人員提出文本預訓練模型以提高文本的向量化水平。文獻[11]利用Word2vec中的詞袋模型,通過上下文將字映射為向量,并對字之間的關系進行表示。但是其未考慮到上下文語義,導致特征提取效果不佳。文獻[12]提出了基于Transformer的雙向編碼器表示(bidirectional encoder representation from Transformer,BERT) 語言表征模型,將多個Transformer編碼器串聯以動態生成字向量。
綜上所述,為了有效識別電力安全隱患實體信息,本文從嵌入表示和特征提取兩方面入手,提出了1種融合注意力機制與BERT-BiLSTM-CRF的電力集控安全隱患實體識別模型。本文首先將預訓練完成的電力 BERT 作為語義信息編碼層,在上下文語義的基礎上對電力安全隱患文本進行嵌入向量表示;再將向量化表示的隱患文本送入 BiLSTM層,并引入注意力機制使模型關注重點部分,輸出實體信息標簽概率;最后在 CRF 層以句子為單位輸出全局最優標簽序列。
1 電力安全隱患數據特點
電力安全隱患實體識別是對電力安全隱患中的隱患位置、隱患名稱、隱患屬性、機構名稱、日期時間、專有名詞等進行識別,并在此基礎上對安全隱患實體信息進行分析和挖掘。這可為相似設備的檢修提供歷史經驗,同時為電力集控智能決策提供數據基礎。電力安全隱患文本特點如下。
①電力安全隱患文本中包含大量的安全隱患實體,例如工作人員記錄安全隱患時需要記錄時間、發現人、隱患的位置、名稱和安全隱患的程度等信息。這些信息都是以自然語言的形式記錄的,計算機難以準確識別[13]。
②電力安全隱患信息主要包括隱患設備信息、隱患設備名稱、隱患設備狀態、隱患設備參數、隱患位置、隱患名稱、隱患屬性、機構名稱、日期時間、專有名詞等。
③電力安全隱患文本用語的有關規范中,國家電網大多以縮略的形式對電力專業名詞進行記錄,存在領域詞匯多、線路名詞多、縮略詞多的特點。
本文將電力安全隱患實體識別任務轉換為序列標簽標注任務,以實現安全隱患實體信息的抽取與分類。根據電力領域專家的意見,標簽標注采用BIO標注機制。B標注為首位字符。I標注為中位字符。O標注為其他字符。在電力生產安全隱患實體識別任務中,標注機制如表1所示[14]。
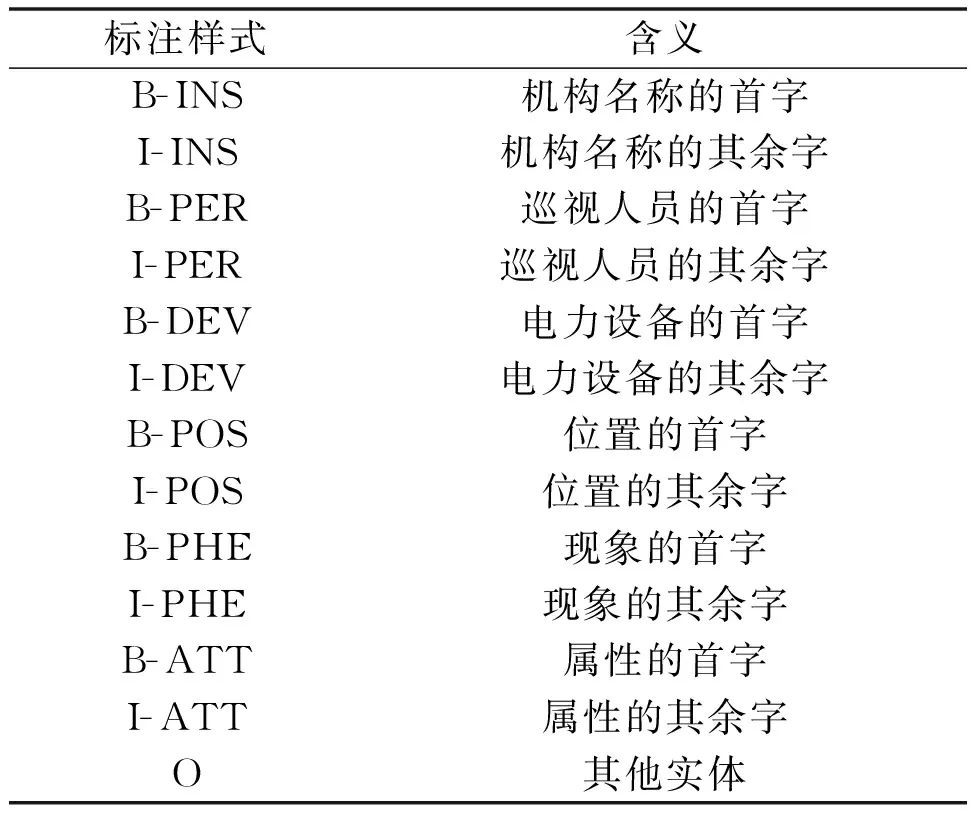
表1 標注機制Tab.1 Labeling mechanism
2 故障文本實體識別算法與流程
所提融合注意力機制與BERT-BiLSTM-CRF的電力集控安全隱患實體識別模型主要包括3個部分,分別為BERT 語義編碼嵌入層、BiLSTM形式-注意力層、CRF層。模型首先將電力安全隱患文本以句子形式送入BERT語義編碼嵌入層,獲得融合全局和上下文語義的電力安全隱患特征向量;再將電力安全隱患特征向量輸入BiLSTM 層獲得實體信息標簽概率,并在此基礎上引入注意力機制增加重要部分的權重;最后利用 CRF 層對標簽序列進行打分,以輸出最優標簽序列。模型整體架構如圖1所示。
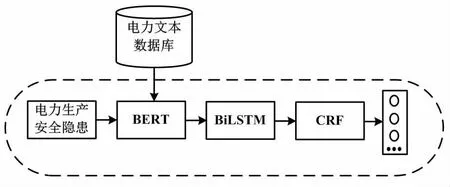
圖1 模型整體架構Fig.1 Overall structure of the model
2.1 BERT預訓練過程
傳統的編碼表示模型只能從字符層面對文本進行特征提取和編碼表示,容易造成上下文語義的丟失。BERT模型將1段輸入文本轉化為1組表示向量。其中,每個表示向量對應于輸入文本的每個切分單元(詞或字),并且每個向量都融合了句子層面的上下文本信息,從而提升下游實體識別的準確率。
①字符層面的掩碼預測過程 。
BERT模型的掩碼語言模型(mask language model,MLM)訓練過程中需要隨機遮掩15%的輸入字符。被遮掩處理的字符有 80%的概率被替換為[MASK]符號、10% 的概率被替換為無關字符以增加訓練時的噪聲、 10%的概率保持原字符不變。利用BERT模型可以預測那些被遮掩的字符[15]。BERT 層編碼過程如圖2所示。
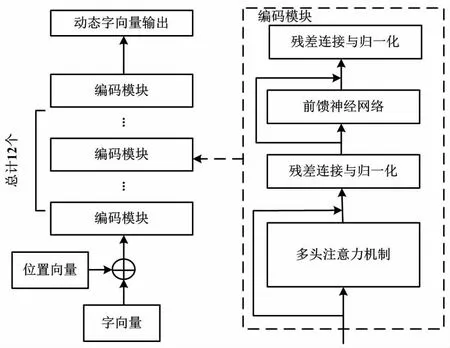
圖2 BERT 層編碼過程Fig.2 BERT layer coding process
由圖2可知,BERT模型根據上下文語義和全局語義對輸入字符進行向量化嵌入表示,并將結果與實際字符進行誤差分析,從而利用反向傳播調整模型參數。與傳統的向量表示模型相比,BERT模型可以整合全局和上下文語義信息,在更好地利用文本信息的基礎上提高實體識別任務的準確率。
②句子層面的上下句關系判斷過程。
在句子層面,BERT 通過判斷2個句子是否為上下文關系來優化模型參數[16]。在訓練時樣本序列的開頭加入標識符“CLS”,2個句子的間隔處加入分隔符[SEP]。將句子輸入到BERT中可實現語序先后的判斷。與傳統的向量表示模型相比,BERT模型實現了句子級別的電力安全隱患文本特征提取,以達到模型參數優化的目的。這使得 BERT 能夠理解輸入文本(句子)的整體含義,提升了實體識別的準確率。
③BERT 層編碼過程。
本文將電力安全隱患文本切分后輸入BERT層進行動態字向量編碼,在考慮周圍字符的搭配情況的前提下使每類特征表示為獨立的特征向量。通過特征向量的求和得到綜合特征向量作為下個編碼模塊的初始輸入。串聯的多層編碼模塊可自動提取安全隱患文本中的不同語言特征。編碼模塊的輸出為含有上下文語義信息的電力安全隱患文本的向量化表示。
隨著BERT模型網絡層數的增加,訓練誤差周期性擴大,而神經網絡準確率逐漸下降。通過加入殘差連接使輸出更敏感、網絡優化更容易、訓練速度更快。殘差連接直接連接低層表示和高層表示的特性,并通過邊界填充保證正特性傳輸的一致。
殘差連接中的第一層表達式如式(1)所示。
bi1=f(w1bi:i+t-1+c1)
(1)
式中:c1為偏置項;f為非線性函數;bi為偏置向量。
殘差連接中的第二層表達式如式(2)所示。
bi2=f(w2bi1:i1+t-1+c2)
(2)
式中:c2為偏置項。
殘差連接優化之后,結合快速連接和逐元素添加相關操作,得到殘差連接的輸出向量a。其中,多次拼接殘差連接的表達式如式(3)所示。
b=bi,1+bi,2
(3)
式中:b為特征向量。
2.2 雙向RNN
普通RNN模型通過隱含層逐層進行信息傳遞,但傳遞中會存在梯度消失的問題[17]。長短時記憶(long short-term memory,LSTM)在RNN模型的基礎上加入門控機制,利用遺忘門選擇性遺忘不重要的信息,解決了RNN模型在處理長序列文本時的梯度消失問題。為了獲得電力安全隱患文本的雙向語義特征,本文提出了通過LSTM進行語句的正向和反向特征獲取。
BiLSTM結構如圖3所示。
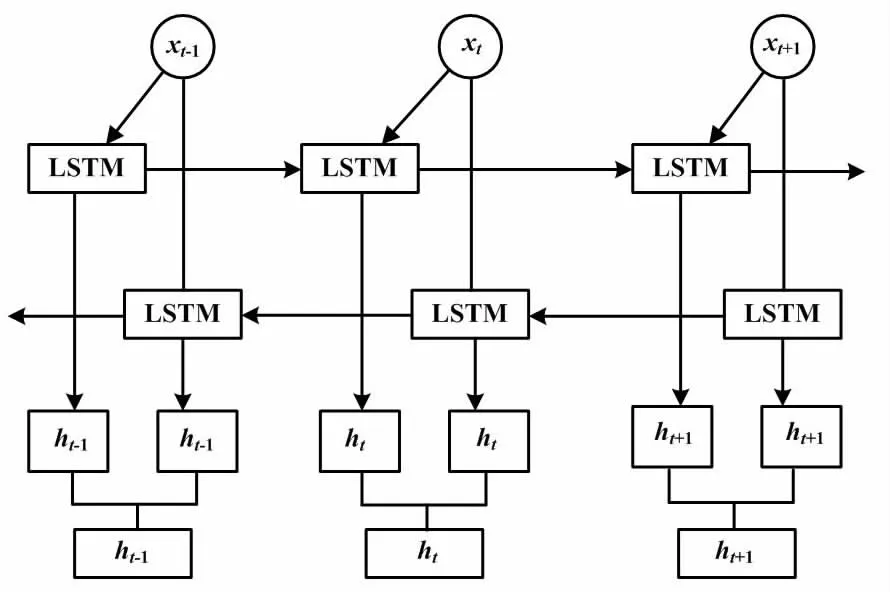
圖3 BiLSTM結構Fig.3 Structure of BiLSTMl
BiLSTM在t時刻的狀態更新計算過程如式(4)~式(8)所示。
(4)
式中:sigmoid為激活函數;w為LSTM權重;u為輸入向量x的權重矩陣。
(5)
(6)
(7)
式中: tanh為激活函數;Ct為模型在t時刻的輸入。
(8)
電力安全隱患文本在經過BERT層和BiLSTM層后,字符具有相同的權重。不重要的部分會影響語義的識別,進而導致電力安全隱患實體標簽信息錯誤。注意力機制通過計算詞與詞之間的關聯程度,以及對編碼層信息進行整合將重要信息賦予較大的權重,從而更好地獲取語義信息。注意力計算函數計算向量之間相關性的得分函數。其定義如式(9)所示。
(9)
式中:Yi為BiLSTM 層輸出的特征序列;bij為文檔中 詞語之間的相關性概率分布。
(10)
式中:wi和wJ分別為電力安全隱患文本中的第i個詞和第j個詞;N為安全隱患文本中詞的個數;f(wi,wJ)為采用詞wi與詞wJ的關聯得分;f(wi,wk)為詞wi與隱患文本中其他詞wk的關聯得分。
注意力機制通過學習隱患文本特征的動態變化規律和文本間的相關性,利用映射加權和學習參數矩陣賦予BiLSTM層輸出的電力安全隱患文本標簽序列不同權重,在保障文本語義獲取的同時降低不重要信息的影響。
2.3 CRF層
本文利用CRF模型約束輸出之間的關系,對電力安全隱患文本序列的標注進行打分約束以獲得全局最優標注結果。打分如式(11)所示。
(11)
式中:Ayi-1yi為電力安全隱患中同標簽之間轉移的分數值;Pi,yi為電力安全隱患中yi標簽的得分;n為電力安全隱患字符總數。
CRF層對每個可能的標注序列進行打分,并根據得分找到標簽的最優標注序列。CRF標注過程如圖4所示。
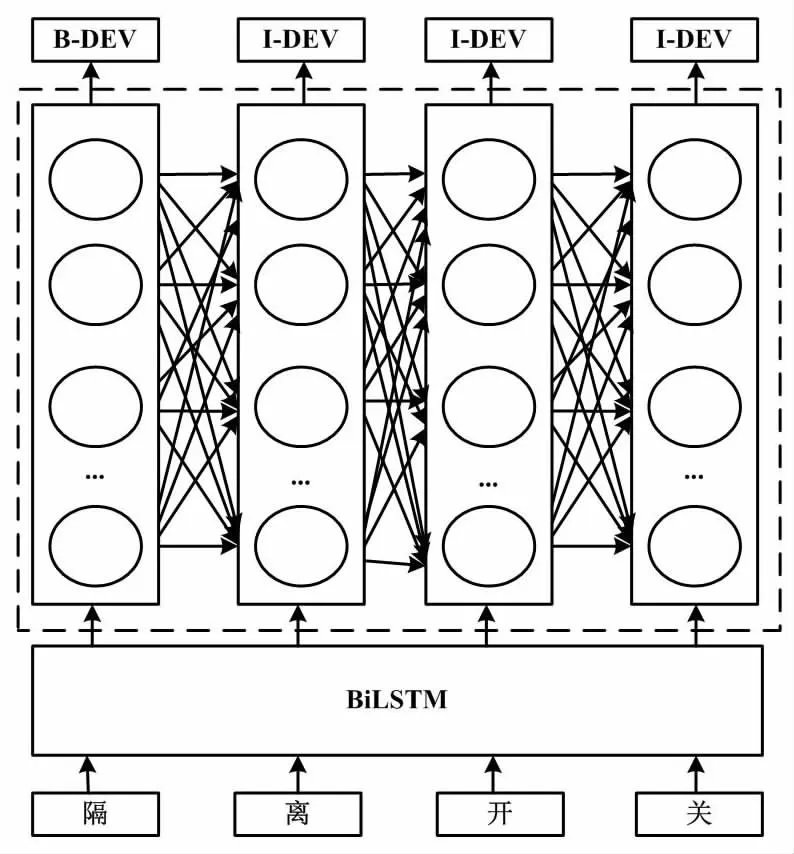
圖4 CRF標注過程Fig.4 CRF labeling process
3 試驗分析
部分隱患數據如表2所示。

表2 部分隱患數據Tab.2 Partial hidden danger datas
為驗證電力生產安全隱患實體識別模型的有效性,本文選取了某省級電力公司2019年至2021年電力集控平臺收錄的電力安全隱患文本信息,整合隱患排查表的隱患內容,構建電力生產安全隱患數據集。數據集包含3 847個隱患實體、8種隱患關系類型。通過構建訓練集和測試集,采用K折交叉驗證模型的性能。本文借鑒相關資料,采用Adam優化器,將batch_size設定為32,并通過調整優化器的學習率最終確定學習率為0.01、Dropout為0.5、試驗框架為tensorflow2.5。 精確率(precision,P)指本身為正的樣本中實際為正例的比例。正樣本的區分能力越強,則P越高。
(12)
式中:M為樣本為正,預測為正;N為樣本為正,預測為負。
召回率(recall,R)表示樣本中本身為正且預測正確的比重。正樣本識別能力越強,則R越高。
(13)
式中:T為樣本為負,預測為負。
F值(f-measure,F)為準確率和召回率的加權調和平均值,反映模型的真實性能。
(14)
通過與其他實體識別模型進行對比分析,驗證所提模型的有效性。模型性能對比如表3所示。
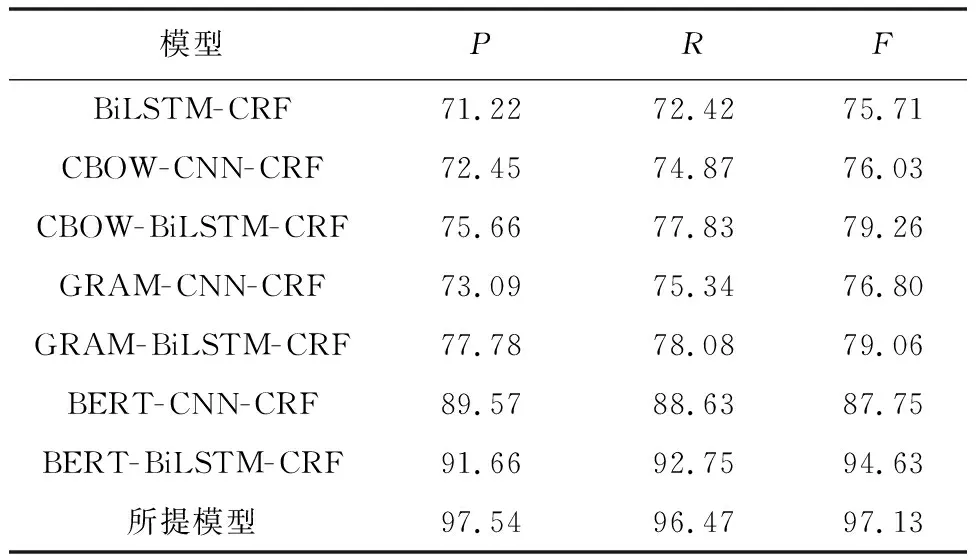
表3 模型性能對比Tab.3 Comparison of model performances /%
從表2中可以看出,相比其他傳統實體識別模型,所提模型在電力安全隱患文本上進行實體識別時總體效果要高5%~21%。由表2可知,向量嵌入表示模型中BERT模型性能優于連續詞袋(continuous bag of words,CBOW)模型與skip-gram。這是因為BERT模型可以有效獲取上下文語義,并在此基礎上對文本進行字符級和句子級的向量化表示,可以解決CBOW與 skip-gram模型的語義丟失和窗口過小的問題,避免了誤差累積。另一方面,利用BiLSTM來獲取文本的前后語義,并利用門控機制的遺忘門對不重要的信息進行遺忘,可以側重距離較近的語義信息,更適合解析安全隱患文本中的實體信息。通過加入注意力機制可以整合BiLSTM層輸出信息,并將重要信息賦予較大的權重,利用注意力機制讓更重要的特征占據更大的權重,從而更好的獲取語義信息。在電力安全隱患文本最佳標注序列判定中,CRF模型與隱馬爾可夫模型(hidden Markov model,HMM)相比,利用歸一化因子對隱患文本序列進行約束,可以減少偏置的發生,具有更好的識別效果。試驗結果也證實了所提模型的有效性和可行性。
融合注意力機制與BERT-BiLSTM-CRF模型對電力生產安全隱患的各類別實體識別對比如表4所示。
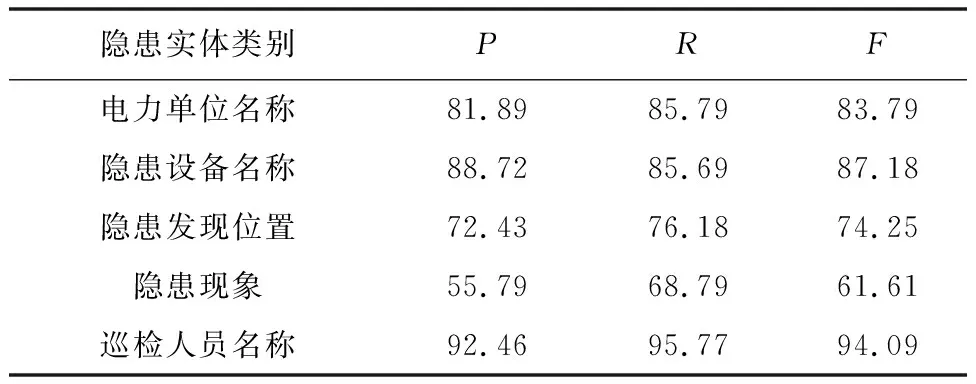
表4 各類別實體識別對比Tab.4 Comparison of entity identification by calegories /%
由表4可知,所提模型對巡檢人員名稱識別效果最佳。這是因為巡檢人員名稱具有較多的訓練數據且實體邊界明顯。而隱患發現位置實體識別較差。因為這類實體大多由縮略詞、符號構成,需要根據上下文語義進行識別,導致識別準確率較低。
4 結論
本文根據電力安全隱患文本的特點提出了融合注意力機制與BERT-BiLSTM-CRF的電力集控安全隱患實體識別模型。該模型可以對電力集控平臺中儲存的電力安全隱患文本進行實體識別。本文進行了以下研究:①使用BERT模型在獲取上下文語義的同時將輸入的隱患文本向量化;②利用 BiLSTM +注意力機制+ CRF層獲取電力安全隱患的最佳標注序列,加入注意力機制將電力文本的上下文語義信息進行融合。本文以電力集控平臺儲存的電力安全隱患文本作為試驗數據。所提模型與傳統模型相比總體效果提升了5%~21%,證實了所提模型的有效性。后續研究將進一步提高復雜電力安全隱患實體的識別能力。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
外語學刊(2011年1期)2011-01-22 03:38:33
