基于Lucene 的校園中文問答采集平臺檢索技術研究與實現
2023-11-04 18:14:22吳志霞葉根梅
通化師范學院學報 2023年10期
關鍵詞:校園
吳志霞,葉根梅,甘 麗
隨著信息技術的發展,通過搜索引擎查詢問題答案已成為日常生活中一種普遍現象.問答系統(Question Answering System,QAS)[1]作為信息檢索系統的一種,是一種在檢索技術上發展的、可以給用戶一定反饋的系統.創建服務于校園的問答系統,需要先采集服務于校園領域的問答集,然后運用問答集進行訓練生成訓練模型.為采集校園問答集,需要開發采集問答的平臺.在設計實現問答采集平臺過程中,設計開發者必須考慮為平臺提供問題的檢索服務.傳統的問題檢索大多基于關系數據庫的關鍵字查詢,檢索方式比較單一,隨著數據量的增多,檢索效率也會降低.Lucene 是一種性能優異的開源全文搜索框架,利用它可以方便地定制符合自身需求的搜索引擎.本文采用Lucene 的中文分詞、倒排索引、結果相關度排序、高亮等關鍵技術,設計并實現了服務于某高校基于Web 應用的校園中文問答采集平臺,采用MySQL 關系數據庫存儲的14 萬條問答記錄驗證了檢索的準確性和高效性[2-6].
1 開發實例及數據表介紹
1.1 開發實例介紹
校園中文問答采集平臺基于Web 開發模式,采用Spring+SpringMVC+MyBatis 框架技術實現.開發實例提供問答樣本數據集采集模塊、問答樣本數據集管理模塊、文本制度文件導入模塊、問答樣本數據集輸出模塊和智能應答五個模塊.其中,需要運用Lucene 搜索架構,實現問答采集平臺的問句檢索.
1.2 校園問答采集系統相關數據表介紹
運用Lucene 搜索架構實現問答采集平臺,利用四張數據表存儲通過平臺導入的校園規章制度文件數據,以及針對這些規章制度文件采集到的問答集.
(1)規章制度文件表(subject).用來存儲導入的規章制度文件主題信息,主要包括id、導入的制度文件主題描述、順序編號等信息.具體描述如表1 所示.

表1 規章制度文件表(subject)
(2)章節表(chapterTitle).用來存放導入的制度文件的章節名稱.主要包括id、導入的制度文件章節名稱、順序編號、章節歸屬的規章制度文件id 和創建時間等信息.具體描述如表2 所示.
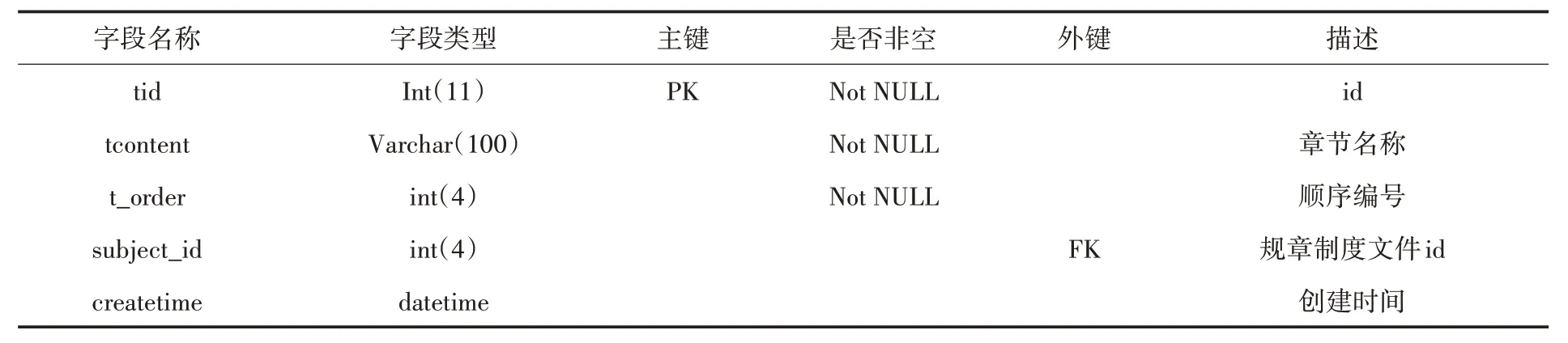
表2 章節表(chapterTitle)
(3)條例表(rules).用來存放具體的條例,主要包括id、導入的制度文件條例標題、條例內容、順序編號、章節歸屬的規章制度文件id、條例歸屬的章節id 和創建時間等信息.具體描述如表3 所示.

表3 條例表(rules)
(4)問答表(qanswer).用來存放采集到的問答樣本數據,主要包括qid、問題、答案、參考信息文本塊、問題歸屬的條例id、問題歸屬的規章制度文件id、問題歸屬的章節id、創建人、創建時間、第一審核人、審核時間、審核級別、第二審核人、審核時間、審核級別、核定級別和狀態等信息.具體描述如表4 所示.

表4 問答表(qanswer)
2 采用Lucene 搜索架構實現問答采集平臺數據檢索
2.1 Lucene 簡介
Lucene 是一種運用Java 語言編寫的開源全文搜索框架,屬于Apache 軟件基金會Jakarta項目組下的子項目.Lucene 作為一個搜索工具包,提供了完整的查詢引擎、搜索引擎和某些語言的分析引擎.開發人員可以利用其強大的索引和搜索功能為目標系統添加信息檢索功能[3].
2.2 基于Lucene 搜索架構實現平臺數據檢索基本流程
基于Lucene 實現平臺數據檢索流程如圖1 所示.第一步,搜集數據.數據可以是文件系統、手工輸入、網絡上的數據和數據庫中的數據;第二步,通過數據創建索引;第三步,用戶輸入要查詢的關鍵字;第四步,通過關鍵字創建查詢器;第五步,根據查詢器到索引里獲取數據;最后,把查詢結果展示給用戶.

圖1 基于Lucene 實現平臺數據檢索流程圖
2.3 基于Lucene 搜索架構實現問答采集平臺問題候選問句的檢索
基于Lucene 實現通過問答采集平臺輸入要查詢的問題并得到多個候選問答集,根據問題得到候選問題集的檢索程序流程圖如圖2 所示.獲取用戶輸入的針對問題需要查詢的關鍵字;準備中文分詞器,調用業務邏輯中的方法獲取數據庫中所有的問答對數據;運用中文分詞器與問答對數據創建索引;依據中文分詞器和針對“問題”的字段去創建查詢器;執行搜索;由指定的界面展示查詢出來的候選問題集和對應的答案,得到的候選問題都標有相應的匹配得分,匹配得分越高顯示越靠前.

圖2 候選問題集的檢索程序流程圖
運用中文分詞器與問答對數據創建索引的核心代碼如下:


在“創建索引”的代碼塊中,應用程序把每一條數據記錄都轉換成一個文檔(Document),并寫入索引文件中.用戶輸入查詢關鍵字,執行搜索的程序流程如圖3 所示.創建IndexReader 類型的對象reader;基于reader 創建搜索器;指定每頁要顯示多少條數據;執行搜索,得到數組,返回的數組類型為ScoreDoc;運用搜索器、數組、查詢器和中文分詞器,返回符合條件的查詢結果.

圖3 執行搜索程序流程圖
2.4 運行效果
用戶在本文中的搜索引擎輸入查詢關鍵字,搜索結果如圖4 所示.分值表示當前行的匹配度得分,得分越高在問答集列表中越靠前顯示.為提升用戶的使用體驗,應用程序中關鍵字都進行了突出標識,在圖4 中用黑框標識出突出的字體.
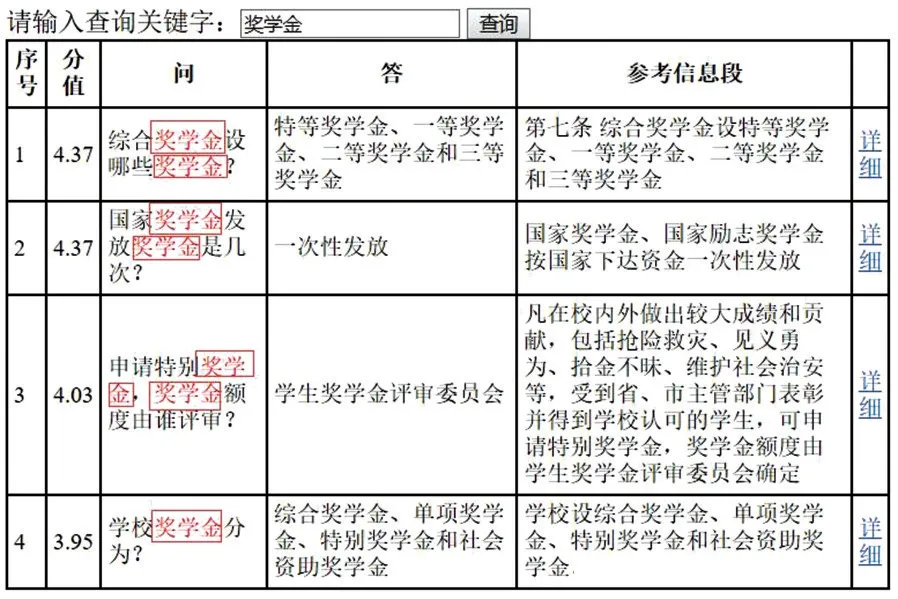
圖4 搜索結果
2.5 平臺檢索對比實驗
數據檢索主要考慮檢索的效率與檢索的準確性.本文對比了基于Lucene 的全文檢索和基于MySQL 數據庫表“SELECT * FROM qanswer WHERE qname LIKE %檢索詞%”方式的模糊查詢檢索功能.文中選取了不同詞長的8 個具有代表性的檢索詞,對MySQL 數據表中的14 萬條問答記錄分別采用這兩種方法進行搜索,比較其搜索效率和準確度.實驗結果如表5 所示.

表5 基于Lucene 的檢索與模糊檢索結果對比
對比基于Lucene 的檢索和MySQL 數據庫表的模糊查詢,兩者在檢索效率和數量方面都存在差異.采用倒排索引技術的Lucene 檢索框架,檢索效率更高.在檢索結果數量方面,Lucene 匹配以詞元為單位,會進行分詞,導致Lucene 檢索普遍比模糊查詢的結果數量多.例如,搜索“公益活動”,使用Lucene 檢索能夠切分出“公益”和“活動”兩個詞元,所以能夠匹配“公益活動”“公益”和“活動”等多條記錄,而MySQL 模糊查詢無法搜索出這些結果.
3 結語
在傳統的應用軟件中,對數據的搜索大多采用關系數據表的模糊查詢方式,每次查詢請求,需要遍歷數據表中的全部記錄.本文將開源Lucene 搜索架構運用到校園中文問答采集平臺,能夠快速檢索到數據,對數據進行相關度排序,并提供突出顯示,讓用戶體驗得到提升,為數據檢索提供了一種實踐思路.
猜你喜歡
兒童故事畫報(2019年2期)2019-01-22 20:01:06
兒童故事畫報(2019年1期)2019-01-18 00:40:46
兒童故事畫報(2018年12期)2018-12-20 23:14:52
兒童故事畫報(2018年11期)2018-11-15 23:48:04
兒童故事畫報(2018年10期)2018-10-24 21:22:06
兒童故事畫報(2018年9期)2018-10-23 19:25:02
兒童故事畫報(2018年7期)2018-10-23 19:24:54
南方周末(2018-06-28)2018-06-28 08:11:04
琴童(2017年3期)2017-04-05 14:49:04
小天使·二年級語數英綜合(2017年3期)2017-04-01 17:17:48
