基于端到端深度學習的藏語語音識別研究
2023-11-14 08:05:38高耀榮邊巴旺堆
現代計算機 2023年17期
高耀榮,邊巴旺堆
(西藏大學信息科學技術學院,拉薩 850000)
0 引言
全球現有語言數量約為7000 種,大多數自動語音識別工作處理的是擁有大型語料庫的語言,如普通話、英語和日語等。而對于小語種,如藏語,使用人數相比大語種要少,若使用基于傳統語音識別方法如DNN-HMM[1],則需準備發音詞典且對藏語有深入了解,因此也導致了藏語語音識別的處理工作所需門檻更高[2]。在藏語語系中分衛藏方言、安多方言、康巴方言,三者有共性也有區別,其中衛藏方言主要在西藏中部人口最密集的地方使用,因此本文選用衛藏方言作為研究對象。
傳統語音識別系統要求聲學模型、語言模型和發音字典。而如今藏語信息處理在進行現代化變遷[3-4]。近年來,端到端網絡[5]的出現降低了實現語音識別的前期準備門檻,其由編碼器和解碼器構成,編碼器相當于特征提取器,解碼器基于編碼器搜索最優解,只需準備語音和文本,即可實現語音到文本的直接轉換。此外,端到端網絡提供了更廣泛的建模單元選擇,也據此提出了很多端到端模型,如鏈接時序分類技術[6]、基于注意力的LAS[7](Listen, Attend and Spell)模型。
不同的端到端網絡各有優缺點,本文通過聯合基于鏈接時序分類(connectionist temporal classification,CTC)和注意力機制(Attention)模型,以此融合了CTC 自動對齊和Attention[8]建立上下文聯系的優點,引入聯合參數λ對CTC 和Attention 分配不同的權重。并且以Transformer作為編碼器提取全局特征。因此,本文建立Transformer-CTC/Attention 模型應用于藏語語音識別。
1 基于藏文特點的語音建模
藏文作為拼音文字,由30 個輔音字母和4個元音字母組合而成。類似中文,一個藏文字通常為一個音節,而每個音節之間由音節符“?”來分割。藏文一個音節的結構分七部分,分別包括前加字、上加字、輔音、下加字、元音、后加字和再后加字,最基礎的結構只有輔音,而最復雜的結構如圖1所示。
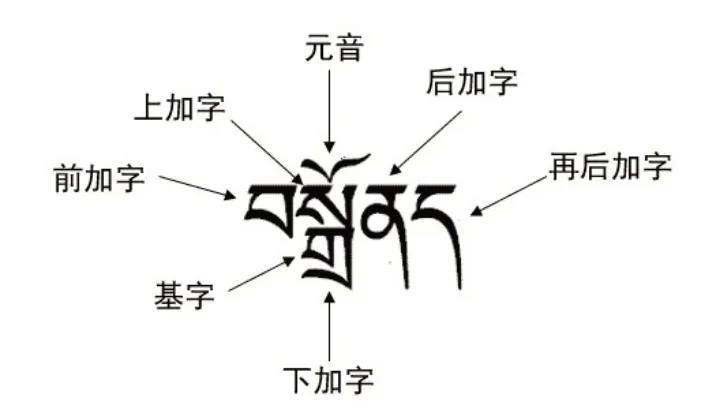
圖1 藏文結構
語音識別的建模單位的選取需要與發音結構相聯系,傳統藏語語音識別以音素為建模單元,并需準備音素與文字轉換關系的發音字典。如今隨著算力和深度網絡學習能力的提升,已無需選擇較小建模單位如音素,Zhou 等[9]探究了五種不同建模單位(音素、音節、詞、子詞和漢字)對普通話語音識別的效果,實驗結果表明基于漢字的模型效果最好,由于藏文字通常為一個音節的特點,即一個藏文字可看成是一個發音單元,所以本文選取以字為識別單位。如這一句???????????????????????(扎西德勒)識別順序則為“???”“?????”“?????”“??????”,此種方式對應著以字為識別單位的中文語音識別[9]或以單詞為識別單位的英語語音識別,并都得到優秀的識別率。
2 Transformer模型
Transformer[10]由Decoder 和Encoder 組成,即編碼器-解碼器。其中在每個Decoder 和Encoder 中采用Attention 機制,加強了信息的關聯性,給更重要的信息更多關注度。其中,多頭注意力機制可以無需考慮距離關注輸入序列不同位置之間的關系,可以更容易獲取全局信息,在語義特征提取能力和長距離特征捕捉能力方面優于傳統的LSTM模型[11]。
Transformer 也被廣泛應用于語音識別領域,2018 年,Dong 等[12]就首次把Transformer 模型應用于ASR 中,而Huang 等[13]通過限制自注意力的學習范圍研究流式的Transformer 語音識別網絡,流式語音識別是語音數據實時傳入而識別文本結果實時輸出,對比非流式語音識別需要更快的解碼速度。Transformer 結構如圖2 所示,Transformer 包含多組的Encoder 和Decoder,每個Encoder 包含三層,分別是self-Attention、Layer Norm 和Feed Forward;而Decoder 的Attention 則為兩級,第一級self-Attention 的輸入信息來自前一層Decoder 的輸出結果,第二級Encoder-Decoder Attention 的輸入信息來自前一層Decoder 和Encoder 的輸出結果,從而結合輸入和輸出的信息。其輸入信息來自整個結構,可以建立輸入語音特征和識別結果之間的序列對應關系,所以本質上還是端到端的結構。
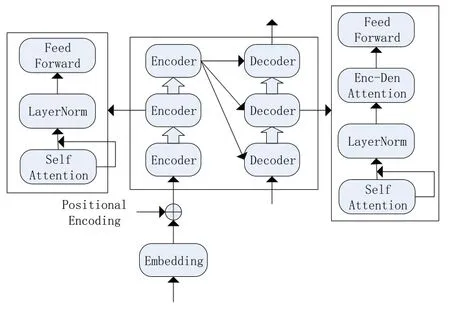
圖2 Transformer結構

圖3 CTC結構
2.1 Positiioonnaall Encooddiinngg
圖2 中Positional Encoding 即位置編碼,由于Transformer 引入了self-Attention 機制,self-Attention 對輸入的token 無法分辨信息的相對位置信息,則需給輸入的位置作標記。在本文輸入語音之前,學習語音特征的位置信息,并疊加到輸入Embedding中,該位置信息的獲取是獨立的,不需要依賴前后遞歸或卷積操作。位置編碼的公式為
其中:PE是語音的位置向量,pos為每個輸入語音的實際位置,i表示是第幾個元素,dmodel是語音向量的維度,sin 和cos 交替編碼位置,既保存語音實際位置信息也可得到語音的相對位置信息。
2.2 self-Attennttiioonn
Transformer 的核心是self-Attention,注意力函數相當于通過一組鍵值對將查詢的向量映射到輸出,并通過加權和得到輸出。我們將查詢、鍵和值分別表示為Q,K和V,self-Attention 具體公式如下:
其中:dk是矩陣K的列數,在原始實現的基礎上,通過Scale 操作對QKT除以dk開平方,以避免值過大導致softmax函數梯度很小、很難優化。經過注意力函數的輸出結果Z的每一行Zi表示一個位置的結果,這個位置對應輸入語音特征序列X的某一幀Xi,且這個位置輸出結果還包含了其他幀Xj的信息,公式如下:
由上述公式可知,輸出結果包含了句子上下信息,即不僅關注當前語音的幀,也能獲取語音前后其他幀的信息,這些信息的重要性通過Attention 機制調節。在此基礎上引入多頭注意力(Multihead Attention)機制,即可取多組的Q、K和V進行計算。
3 CTC/Attention模型
3.1 鏈接時序分類
輸入的語音序列存在靜音、重復的情況,因此一般語音序列是比實際文本序列要長的。而鏈接時序分類(CTC)可以實現自動對齊輸出標簽和輸入序列,不需要像DNN-HMM[1]那樣需要對齊標注。CTC 假定輸入符號是相互獨立的,輸出序列X和輸出序列Y是按時間順序單調對齊,在輸入序列X={x1,x2,…,xT}和輸出序列Y={y1,y2,…,yT}之間建立了多對一的鏈接,然后通過動態規劃來解決序列對齊問題,從而實現語音和文本的匹配。
CTC 引入空白標簽“blank”表示靜音的情況,即輸出序列Y′=Y∪{“blank”},把出現此情況的標簽替換為“blank”,而在識別的最后則需要刪去空白標簽。假設建模單元序列為Q,CTC 的識別目標是讓輸入序列X和輸出序列Y吻合,即式(4)的概率P(Y|X)盡可能大,CTC 損失公式(5)盡可能小,其中的P(Q|X)相當于聲學模型,描述了語音與建模單元的關系。
3.2 注意力機制
基于Attention 的Encoder-Decoder,可以看成是端到端架構的改進版,在Encoder和Decoder之間通過Attention 機制銜接,使得Decoder 的輸出與Encoder有了注意力權重,結構如圖4所示。
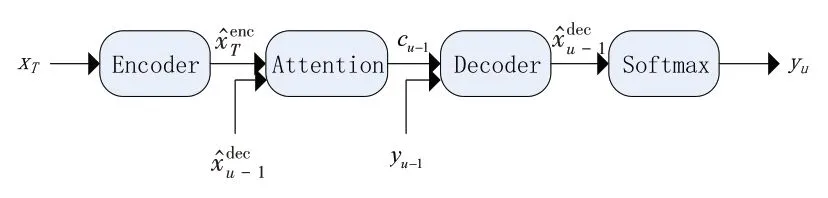
圖4 Attention結構
本文Attention 的Encoder 為Transformer,Transformer 的輸出作為Attention 的輸入,即Transformer 相當于是聲學模型提取語音特征。而Attention 的Decoder 結構設定為LSTM,最后的輸出為將LSTM 隱藏層的當前狀態hu通過Softmax 函數得到。因此,最終輸出是計算預測標簽和輸入序列的概率分布,相當于是語言模型。
網絡中Attention 機制的輸入是Encoder 的輸出序列,通過公式計算注意力權重建立輸出序列和輸入序列的對齊關系。
其中,αu-1,t是注意力權重,公式如下:
其中,eu-1,t表示解碼器輸出與編碼器輸出的原始注意力分數。
3.3 聯合CTC/Attennttiioonn
CTC 可以實現對齊輸入序列和輸出標簽,但是若建模單元為互相獨立,沒有考慮到標簽之間的組合關系,即沒有語言模型,則會導致識別準確率不高。而Attention 機制通過注意力權重建立標簽各種組合的可能性,但輸出序列和輸入序列不一定按順序嚴格對齊。因此,將CTC 和Attention 結合起來構建聯合CTC/Attention模型,Attention 融入CTC 自動對齊的優點,可以避免解碼時對齊過于隨機,提高識別率。
根據端到端結構,先提取語音Fbank 特征向量作為編碼器Transformer 的輸入,CTC 和Attention 共為解碼器,編碼器的輸出被二者共享,最后通過聯合解碼輸出,具體結構如圖5所示。CTC/Attention 模型的訓練是多任務學習,模型的損失其實就是CTC loss 和Attention loss 的加權求和,引入λ為聯合參數取值范圍為[0,1],損失計算公式如下:
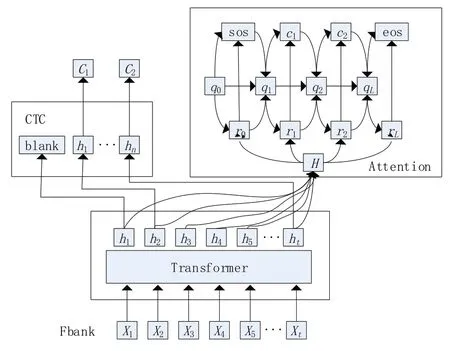
圖5 Transformer-CTC/Attention 模型
4 實驗結果且分析
4.1 實驗參數
對語音使用kaldi 工具提取80 維的Fbank 特征作為模型輸入,窗長為25 ms,窗移為10 ms。其中每幀添加0.1的隨機噪聲系數。
本文Transformer 的多頭注意力頭數為4 個,encoder 塊有12 個,decoder 塊有6 個,每個塊的參數獨立,采用ReLU作為激活函數,dropout系數為0.1。使用自適應矩估計Adam 優化器,既能適應稀疏梯度,又能緩解梯度震蕩。采用warmup steps 為5000 的warmup lr 學習策略訓練,設定學習率為0.002,訓練160輪。
4.2 數據集與評價指標
為驗證模型的有效性,實驗選取Zhao 等[14]公開的包含30 小時的衛藏藏語語音數據集TIBMD@MUC。語音為16 KHz 的WAV 格式,訓練集和測試集分別為27 小時和3 小時。基于前文所訴的建模單元選取方法,對此數據集藏語文本進行處理,得到2857 個建模單元,其中
本次藏語語音識別任務以詞識錯率(word error rate,WER)[15]作為評價標準,其中S代表替換的字數量,D代表刪除的字數量,I代表插入的字數量,N代表總的字數量。WER值越小越好。具體公式如下:
4.3 實驗結果及分析
為驗證聯合CTC/Attention 的有效性,先研究CTC 和Attention 分別在藏語語音識別的效果,設置λ= 1 和λ= 0 分別表示Transformer-CTC 和Transformer-Attention 模型。為探究不同聯合參數λ的效果,預先設置CTC/Attention 模型的聯合訓練參數λ為0.3、0.5 和0.7,三個值作對比分析,經過實驗結果分析決定再增添訓練參數λ= 0.8作對比,最終實驗結果見表1。
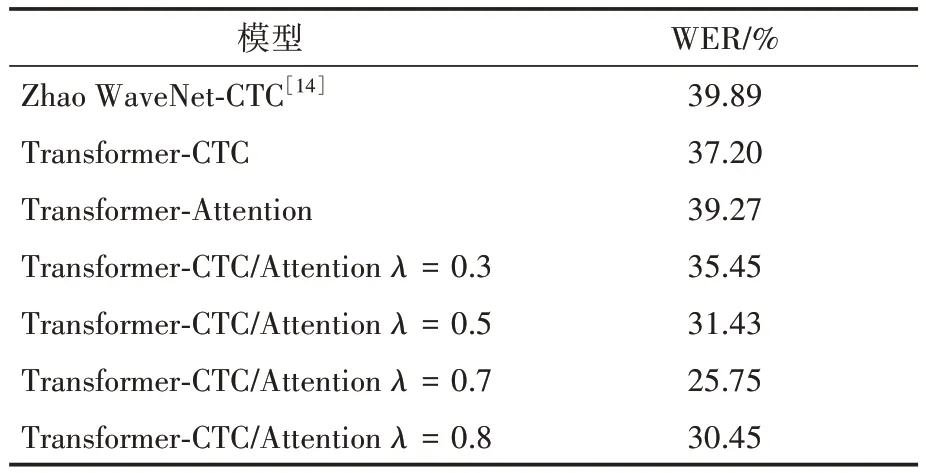
表1 語音識別結果
實驗結果表明,相對于單獨以CTC 或Attention作為解碼器,聯合CTC/Attention 模型應用在藏語語音識別中的識錯率都有不同程度的降低,且都優于Zhao等[14]的WaveNet-CTC實驗結果。這是因為Transformer 是基于Attention,而WaveNet 是基于CNN,因此以Transformer 作為聲學模型可以更好地提取長序列輸入的全局特征和上下文依賴。
圖6 和圖7 分別表示CTC、Attention 和聯合模型CTC/Attention 的損失曲線圖。由圖6 可知,在藏語語音識別中,Attention 損失相對CTC 更小,且下降得更快。圖7 結果表明,聯合參數λ越大,即CTC 占比越大,則損失越大且收斂速度更慢。然而結合表1 實驗結果,當λ= 0.7 的時候,相對其他聯合參數識別結果更好,這是因為當給予CTC 更大的權重時,有助于CTC 階段對齊更準確,而即使因此減少了Attention 的權重,由于Attention 收斂得很快,在足夠的訓練次數上對Attention本身性能影響不大。
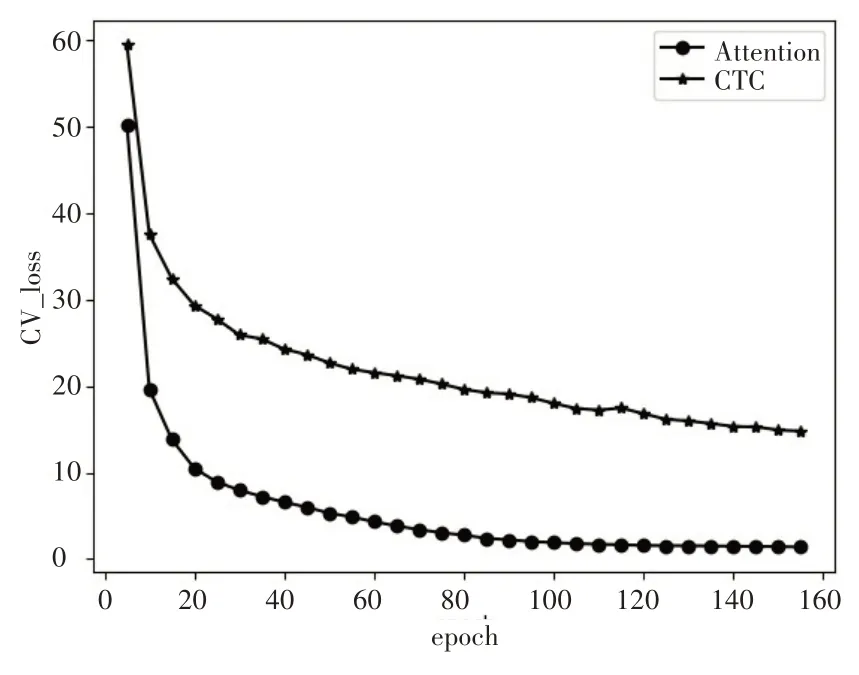
圖6 CTC、Attention訓練損失
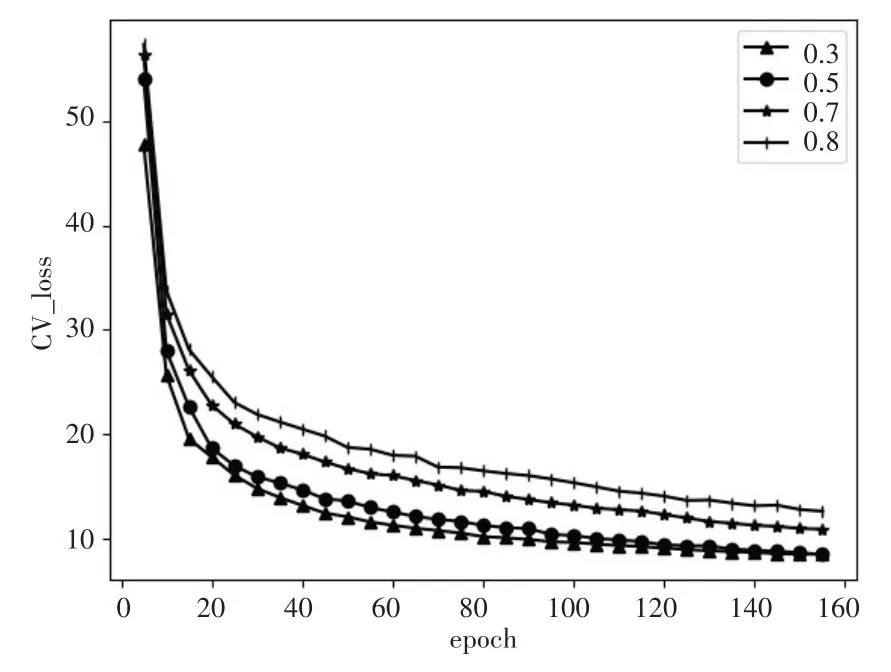
圖7 CTC/Attention訓練損失
5 結語
藏語語音識別是尊重民族文化,促進民族團結的重要任務。本文構建Transformer-CTC/Attention 端到端模型對藏語語音識別進行研究。使用藏字作為識別單位,在Zhao等[14]的藏語語音數據集上取得更低的識錯率。證明以藏字為識別單位和端到端網絡對藏語語音識別的可行性,驗證了Transformer-CTC/Attention優于WaveNet-CTC網絡,探究了不同的聯合參數λ對藏語語音識別的效果。藏語語音識別目前遇到最大的困難還是未有更大型專業的藏語語音公開數據集,基于此問題,未來的研究方向可以引入遷移學習和無監督學習,從而拓寬學習范圍。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
