一種基于LSTM的中醫藥數據增強方法
2023-11-22 06:03:25柳鵬熊旺平晏燕
現代信息科技 2023年19期
柳鵬 熊旺平 晏燕

摘? 要:中醫藥數據在許多領域中具有廣泛的應用,但由于數據缺乏,導致中醫藥領域的發展受到限制。因此,文章提出了一種基于LSTM的中醫藥數據增強方法,以生成更多的中醫藥數據,以提高中醫藥領域的應用價值。研究從已有的中醫藥數據中構建了一個基于LSTM的生成模型,并通過實驗驗證了該方法的有效性。實驗結果表明,基于LSTM的中醫藥數據增強方法可以生成與真實數據相似的數據,從而可以為中醫藥領域的研究和應用提供更多的數據資源。
關鍵詞:中醫藥數據增強;LSTM;生成模型;數據資源
中圖分類號:TP18;TP391.1? 文獻標識碼:A? 文章編號:2096-4706(2023)19-0117-06
A Chinese Medicine Data Enhancement Method Based on LSTM
LIU Peng1, XIONG Wangping1, YAN Yan2
(1.College of Computer, Jiangxi University of Chinese Medicine, Nanchang? 330004, China;
2.Fengcheng People's Hospital of Jiangxi Province, Yichun? 331100, China)
Abstract: TCM data has a wide range of applications in many fields, but the lack of data has led to the development limitation of the TCM field. Therefore, this paper proposes a TCM data enhancement method based on LSTM to generate more TCM data in order to improve the application value in the field of TCM. In this research, a generation model based on LSTM is constructed from existing TCM data, and the effectiveness of the method is verified through experiments. The experimental results show that the TCM data enhancement method based on LSTM can generate data similar to the real data, and thus can provide more data resources for research and application in the field of TCM.
Keywords: Traditional Chinese Medicine data enhancement; LSTM; generative model; data resource
0? 引? 言
隨著科技的不斷發展,深度學習已經成為一種熱門的研究方向。在醫學領域,深度學習已經被廣泛應用于醫療影像分析、疾病診斷和治療等方面。然而,在中醫藥領域,由于數據的質量和數量限制,深度學習的應用仍然面臨許多挑戰。
在中醫藥領域,數據增強[1]是一種解決數據不足問題的有效方法。數據增強可以通過對原始數據進行多種方式的擴充來生成新的數據集,從而提高模型的泛化能力和魯棒性[2]。本文探討了一種基于LSTM的中醫藥數據增強方法。
長短期記憶網絡(LSTM)是一種常用的循環神經網絡[3],它能夠有效地處理序列數據。本文的方法是利用LSTM模型來生成新的中醫藥數據,具體來說,是將已有的中醫藥數據作為輸入序列,通過訓練LSTM模型來生成新的中醫藥數據。通過這種方法,可以有效地擴充原始數據集,從而提高模型的表現。
本文的主要貢獻如下:首先,本文提出了一種基于LSTM的中醫藥數據增強方法,可以有效地擴充中醫藥數據集;其次,對比了使用增強數據和不使用增強數據的模型性能,證明了數據增強的有效性;最后,還對LSTM模型進行了深入的分析,探討了其在中醫藥數據增強中的應用。
本文的組織結構如下:第二部分介紹了相關工作,包括數據增強和LSTM模型;第三部分詳細描述了本文提出的基于LSTM的中醫藥數據增強方法;第四部分通過實驗驗證了本文的方法的有效性;最后,本文在第五部分進行了總結和展望。
1? 相關工作
本文提出了一種基于LSTM的中醫藥數據增強方法。在相關工作部分,本文將介紹一些與本文相關的研究工作,包括數據增強和LSTM模型的應用。
數據增強是一種常用的解決數據不足問題的方法。在圖像領域,數據增強的方法包括隨機旋轉、隨機縮放、隨機裁剪等[4]。在自然語言處理領域,數據增強的方法包括詞向量替換、句子重構等[5]。在醫學領域,數據增強的方法包括對醫療影像進行旋轉、鏡像等操作[6]。這些方法都可以有效地擴充數據集,提高模型的泛化能力和魯棒性。
LSTM是一種常用的循環神經網絡,它能夠有效地處理序列數據。在自然語言處理領域,LSTM模型已經被廣泛應用于語言模型、機器翻譯和情感分析等方面[7]。在醫學領域,LSTM模型也被用于疾病預測和藥物發現等任務中[8]。
在中醫藥領域,也有一些相關的研究工作。例如,劉金壘等人[9]通過挖掘中醫藥領域的知識圖譜,構建了一個中醫藥知識圖譜庫,以幫助醫生和研究人員更好地理解中醫藥知識。此外,蘆霞[10]將深度學習應用于中藥配方的研究,通過建立中藥配方的預測模型,來預測其功效和治療效果。
然而,在中醫藥數據增強方面,尚未有太多的研究。因此,本文提出的基于LSTM的中醫藥數據增強方法具有一定的創新性和實用性。通過擴充中醫藥數據集,本文可以更好地應用深度學習模型來解決中醫藥領域中的問題,為中醫藥研究和臨床實踐提供更好的支持。
2? LSTM模型的構造
2.1? 數據集和數據預處理
在采集數據的過程中可能會出現錯誤,這會使得部分數據缺失。缺失數據會影響模型的預測,因此必須對缺失數據進行處理。本文采用上一個時間表和下一個時間表相同時間段的數據的均值來填補缺失值。
由于原始輸入數據的不同特征所用的評價指標的量綱不同,會影響數據分析的最終結果。為了消除這種指標間的量綱影響,將原始數據進行標準化[11]。經過標準化處理后,各指標將處于同一數量級。同時,標準化有助于提高神經網絡的訓練速度以及提高模型的精度。本文采用最大最小標準化方法(Min-Max Normalization)又稱離差標準化[12],將數據映射到[0,1]之間,轉換函數如式(1)所示:
其中xmin表示該血藥濃度特征數據中的最小值;xmax表示該特征數據的最大值;xn表示將要歸一化的值; 表示經過歸一化之后的值。
2.2? 長短期記憶網絡
本文中提出的基于LSTM的中醫藥數據增強方法,主要包括以下幾個步驟:數據預處理、LSTM模型構造、數據增強和模型訓練。
在LSTM模型構造中,本文采用了經典的LSTM結構,用于處理中醫藥序列數據。LSTM模型由多個LSTM層和一個全連接層組成,其中每個LSTM層包括多個LSTM單元。每個LSTM單元包含一個輸入門、一個遺忘門和一個輸出門,用于控制輸入數據的流動和記憶數據的存儲。LSTM的內部結構模型如圖1所示。
式(2)中:Gt表示通過遺忘門后的信息,σ()表示sigmoid激活函數,ωf表示遺忘門中輸入的特征向量的權重矩陣,[ht-1,xt]表示由兩個向量拼接成的新向量,xt表示當前的輸入向量,ht-1表示上一次的輸出向量,bf表示遺忘門的偏置值。式(3)中:ωi表示輸入門中輸入的特征向量的權重矩陣,bi表示輸入門的偏置值。式(4)中? 表示需要更新的信息,Ct表示輸入門更新后的信息。式(5)表示t時刻的輸出,并作為歷史信息被保留。式(6)表示最終輸出的表達式,輸出整個LSTM模型的最終結果。
在模型的輸出層,本文采用了Softmax函數,將模型輸出的結果轉化為概率分布。模型的損失函數采用交叉熵損失函數[13],用于衡量模型的預測結果與真實結果之間的差異。模型的訓練使用反向傳播算法進行優化,更新模型的參數以最小化損失函數。
值得注意的是,為了防止模型過擬合,本文在模型中加入了dropout[14]和正則化[15]等技術。dropout技術可以隨機丟棄一部分神經元,防止模型對某些特征的過度依賴。而正則化技術則可以限制模型的參數大小,防止模型過度復雜。
3? 實驗結果與分析
3.1? 實驗數據介紹
本文使用的數據是大承氣湯血藥濃度實驗數據和UCI數據集中的Tetuan City power consumption和AirQualityUCI。大承氣湯血藥濃度數據來源于江西中醫藥大學中醫病因生物學重點實驗室。
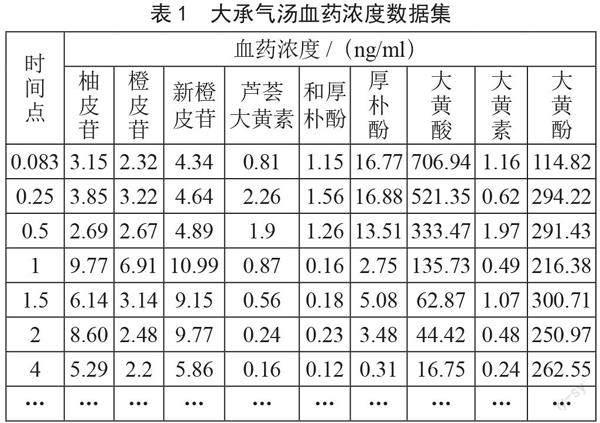
大承氣湯血藥濃度實驗數據包含6組大的時間序列樣本,每組樣本包含12個時間點,總共72條樣本。每個時間點有9個成分的血藥濃度,分別是柚皮苷、橙皮苷、新橙皮苷、蘆薈大黃素、和厚樸酚、厚樸酚、大黃酸、大黃素和大黃酚,大承氣湯血藥濃度的部分實驗數據集如表1所示。
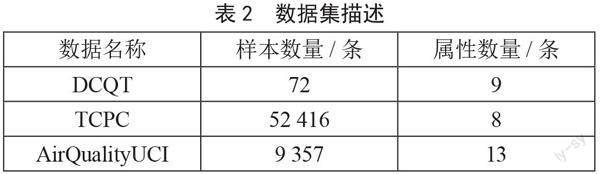
UCI數據選取Tetuan City power consumption (TCPC)和AirQualityUCI,樣本量分別為9 357和52 416條,UCI數據集的詳細描述見http://archive.ics.uci.edu/ml/。數據集的具體描述如表2所示。
3.2? 評價方法介紹
在本文中使用的評價指標為:均方根誤差(RMSE),平均絕對誤差(MAE),均方對數誤差(MSLE)。各指標的計算方法如式(7)~(9):
在上述的三個式子中:n表示所有訓練樣本的數量,yl表示待預測數據的真實結果, 表示模型輸出的預測結果,RMSE,MAE和MSLE表示模型的預測結果與真實結果之間的誤差,誤差越小,模型的精度也越高。
3.3? 實驗環境
本文所提出的LSTM數據增強模型是在Windows 10操作系統上進行的實驗,設備的內存為32 GB,處理器為Intel Core i7-9700K CPU @ 3.60 GHz 3.60 GHz,GPU為Nvidia GeForce GTX 1660 Ti 6GB GDDR6。本文使用的編程語言版本為Python 3.7.10,運行框架及版本為TensorFlow 2.5.0和Keras 2.4.3。
3.4? 模型有效性
為了驗證LSTM模型的有效性,本文將LSTM分別跟PLS,XGBoost和RNN進行比較,結果通過評價指標RMSE,MAE和MSLE來評估,RMSE,MAE和MSLE的值越小,模型的精度越高。實驗結果如表3所示。
根據表3的實驗結果可知,在預測三個數據集的四個模型中,LSTM的擬合效果最好,在三個數據集中的平均RMSE(12.49)、MAE(8.12)、MSLE(0.51)最小,而XGBoost模型的平均RMSE(15.87)、MAE(10.79)、MSLE(0.73)在三個數據集中的擬合結果最差。
大承氣湯實驗數據屬于小樣本數據,在實驗中,LSTM的RMSE小于XGBoost、RNN和PLS。四個模型的RMSE分別為13.08、12.52、11.34和11.28。LSTM的MAE小于XGBoost、RNN和PLS。四個模型的MAE分別為8.89、7.23、7.46和6.73。LSTM的MSLE小于XGBoost、RNN和PLS。四個模型的MSLE分別為0.43、0.26、0.15和0.11。從結果來看,LSTM模型比PLS和XGBoost模型的預測效果好,說明LSTM也可以很好地處理小樣本數據。
在UCI數據中,AirQualityUCI數據集屬于中等數據量樣本,Tetuan City power consumption數據集屬于大數據量樣本。在各類數據量中,LSTM的效果都是最好的,在AirQualityUCI數據集中,RMSE分別為13.66、12.56、12.40和11.34,MAE分別為8.45、
8.88、8.51和7.98,MSLE分別為0.86、0.79、0.78和0.64。在Tetuan City power consumption數據集中,RMSE分別為20.88、21.66、17.09和14.84,MAE分別為15.02、16.48、11.26和10.64,MSLE分別為0.92、0.82、0.8和0.78。結果表明,LSTM無論在大承氣湯數據集中還是UCI數據集中,預測的準確率都是最高的,在預測效果方面優于其他模型。
為了更直觀地顯示實驗結果,分別繪制圖表以體現均方根誤差(RMSE),平均絕對誤差(MAE),均方對數誤差(MSLE)的波動情況。由于各個數據集的RMSE、MAE和MSLE的數量級不同,為了方便比較各數據集在不同方法上的RMSE、MAE和MSLE的波動情況,將實驗結果數據按照RMSE、MAE和MSLE分別繪制出圖2、圖3和圖4。
在本文中,從表2中可以知道,TCPC屬于大型數據集,AirQualityUCI屬于中型數據集,而DCQT屬于小型數據集。從實驗結果來看,本文提到的方法在這三類數據上都有較好的表現,而從圖2、圖3和圖4可以直觀地看出LSTM在各項指標中效果相比XGBoost、RNN以及PLS都有明顯的提升。
3.5? 數據增強
本文的數據是時間序列的,訓練模型的方式是通過輸入一行起始時間的血藥濃度數據來預測下一個時間點的血藥濃度數據,直到完成12個時間點的預測。因此,本文實現數據增強的方法是將多個起始時間的數據批量輸入模型,起始時間的數據來自原始數據。為了避免數據過擬合,輸入的數據將添加一個噪音,噪音的范圍限制在原值的15%的大小,原始數據添加噪聲后變為一個新的值。新的數據經過模型處理后,可以獲得增強數據。
例如從大乘氣湯的數據集中隨機挑選5組數據,在圖表中展示如圖5所示。
選取每組數據的第一行屬性值并添加隨機噪音,然后經過LSTM模型處理后,可以得到新的增強數據。例如使用圖5中的5組數據進行數據增強,如果模型對數據進行6次預測(每次預測的數據添加的噪音是隨機的),可以得到6倍于原始數據的數據量,實驗結果如圖6所示。
通過圖5和圖6的對比,可以看出模型生成的新樣本與原始樣本都處在一個相似的規律和范圍內。說明模型能實現對原始數據的數據增強。
實驗結果表明,LSTM模型可以有效地對中醫藥數據進行增強,并可以在不增加數據采集和標注成本的情況下提高預測模型的精度。通過使用LSTM模型生成合成數據,可以擴展原始數據集的規模,并使預測模型更好地捕捉數據的特征。此外,與其他模型相比,LSTM在預測性能方面表現出更好的結果,特別是在處理序列數據的長期依賴關系方面。
4? 結? 論
本研究使用LSTM模型進行中醫藥數據增強,并通過與其他模型的對比,證明了該方法能夠有效提高預測模型的性能。結果表明,LSTM模型生成的合成數據可以增加數據集的規模,并提高模型的精度,同時避免了增加數據采集和標注成本的問題。本文還將LSTM模型與其他模型進行了比較,包括XGBoost、RNN和PLS,并在RMSE、MAE和MSLE等指標上進行了評估。實驗結果表明,LSTM模型在預測中醫藥數據方面表現優異。這表明,對于序列數據這種類型的預測任務,LSTM模型可以更好地處理長期依賴關系,從而提高預測精度。
本文提出了一種有效的中醫藥數據增強方法,證明了LSTM模型在這種方法中的有效性。此外,通過與其他模型的對比,還證明了LSTM模型在序列數據預測任務中的優越性。這些結果對于中醫藥數據的分析和預測具有實際意義,并對其他序列數據的分析和預測也具有參考價值。
參考文獻:
[1] 宋輝,苑龍祥,郭雙權.基于數據增強和特征注意力機制的灰狼優化算法-優化殘差神經網絡變壓器故障診斷方法 [J/OL].現代電力:1-9(2023-02-27).https://www.cnki.net/KCMS/detail/detail.aspx?dbcode=CAPJ&dbname=CAPJLAST&filename=XDDL20230223002&v=MjQ0NjRaT3NOWXdrN3ZCQVM2amg0VEF6bHEyQTBmTFQ3UjdxZFpPWm5GQzNsVmIvQUlscz1QU25QWXJHNEhOTE1yWTFH.
[2] 曹鋼鋼,王幫海,宋雨.結合數據增強的跨模態行人重識別輕量網絡 [J/OL].計算機工程與應用:1-11(2023-02-16).http://kns.cnki.net/kcms/detail/11.2127.tp.20230214.1543.064.html.
[3] 宋剛,張云峰,包芳勛,等.基于粒子群優化LSTM的股票預測模型 [J].北京航空航天大學學報,2019,45(12):2533-2542.
[4] 李陽,高軾奇.基于數據增強及注意力機制的肺結節檢測系統 [J].北京郵電大學學報,2022,45(4):25-30.
[5] 黃國棟,徐久珺,馬傳香.基于BERT-Encoder和數據增強的語法糾錯模型 [J/OL].湖北大學學報:自然科學版:1-7(2023-03-03).http://kns.cnki.net/kcms/detail/42.1212.N.20230302.
1647.004.html.
[6] 曾子明,張瑜.基于數據增強和多任務學習的突發公共衛生事件謠言識別研究 [J/OL].數據分析與知識發現:1-16(2023-02-10).http://kns.cnki.net/kcms/detail/10.1478.g2.20230208.
1132.001.html.
[7] 孔繁鈺,陳綱.基于改進雙向LSTM的評教文本情感分析 [J].計算機工程與設計,2022,43(12):3580-3587.
[8] 秦佳杰,陳聰,關靜,等.基于滯后效應的多變量LSTM模型對兒童呼吸道疾病就診人數的預測 [J].中華疾病控制雜志,2022,26(9):1057-1064+1116.
[9] 劉金壘,惠小珊,張振鵬,等.基于中醫診療指南的冠心病知識圖譜構建 [J].中國實驗方劑學雜志,2023,29(7):208-215.
[10] 蘆霞.基于神經網絡的感冒中藥配方模型建立和性能考察 [D].南昌:華東交通大學,2011.
[11] 董雪情,荊瀾濤,田瑞,等.基于LSTM模型的變壓器頂層油溫預測方法 [J].電力學報,2023,38(1):38-45.
[12] WU T,LIU C C,HE C. Prediction of Regional Temperature Change Trend Based on LSTM Algorithm [C]//2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC). Chongqing:IEEE,2020,1:62-66.
[13] HUANG H H,WANG T Y,LIU J,et al. Predicting Urban Rail Traffic Passenger Flow Based on LSTM [C]//2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC).Chengdu:IEEE,2019:616-620.
[14] 于家斌,尚方方,王小藝,等.基于遺傳算法改進的一階滯后濾波和長短期記憶網絡的藍藻水華預測方法 [J].計算機應用,2018,38(7):2119-2123+2135.
[15] AKITA R,YOSHIHARA A,MATSUBARA T,et al. Deep Learning for Stock Prediction Using Numerical and Textual Information [C]//2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS).Okayama:IEEE,2016:1-6.
作者簡介:柳鵬(1995—),男,漢族,江西宜春人,碩士研究生在讀,研究方向:醫藥數據挖掘;熊旺平(1982—),男,漢族,江西豐城人,教授,博士,研究方向:數據挖掘;晏燕(1986—),女,漢族,江西豐城人,主管護師,碩士,研究方向:醫藥信息學。
收稿日期:2023-03-09
基金項目:國家自然科學基金(61762051);國家自然科學基金(82160955);國家自然科學基金(82274680)
