基于樸素貝葉斯的學術論文推薦算法研究
2023-11-27 13:19:52嚴海兵朱振剛
蘇州科技大學學報(自然科學版) 2023年4期
關鍵詞:用戶
嚴海兵,周 剛,朱振剛,楊 萌
(1.蘇州科技大學 圖書館,江蘇 蘇州 215009;2.蘇州科技大學 機械工程學院,江蘇 蘇州 215009)
學術論文是對某個科學領域中的學術問題進行研究后表述科學研究成果的文章,其主體是期刊論文,是數字圖書館中交流最為活躍的部分。
國內外主流的數字圖書館檢索平臺收錄的論文數量都達到了千萬篇的級別,雖然可以在檢索詞層次幫助用戶獲得信息資源,但其智能化程度較低,無法在知識層面描述用戶的興趣和需求,導致檢索到的信息資源空間較大,用戶從這些海量信息中獲取符合自己興趣和需求的信息困難,信息過載。因此,數字圖書館迫切需要針對目標用戶興趣和需求的推送服務,即智慧化的“信息找人”推送服務。孕育于數據挖掘、知識發現、機器學習技術的推薦系統研究應運而生,優秀的學術論文推薦系統是數字圖書館智慧化的迫切需求。
1 學術論文推薦算法研究現狀
推薦系統是一種智能個性化信息服務系統,可借助用戶對資源的興趣和需求建立用戶信息模型、資源信息模型,并根據模型通過一定的智能推薦策略實現有針對性的個性化資源信息定制[1]。當前應用于學術論文推薦的主流推薦系統算法基本都是基于內容推薦算法[2]和協同過濾推薦算法[3]的改進算法。例如:王嫣然等人的一種基于內容過濾的科技文獻推薦算法,針對科技文獻建立文本特征向量模型,利用TF-IDF 計算特征關鍵詞對文獻的權重,然后使用余弦值計算用戶已訪問的文獻與未訪問文獻的特征向量的相似度,為用戶進行文獻資源推薦[4],這是經典的基于內容推薦的研究算法。馬鑫等的融合類目偏好和數據場聚類的協同過濾推薦算法研究,該算法引入類目偏好和語義偏好的概念,利用類目偏好比對高維用戶—項目矩陣進行降維,然后利用協同過濾進行文獻推薦[5]。宋楚平提出使用中圖法圖書二級分類類目代替圖書本身,優化了用戶對圖書的評價矩陣,再用協同過濾推薦圖書[6]。Noor Ifa da 等提出利用用戶借閱記錄和圖書的關鍵詞發生概率建立概率關鍵詞模型,再用協同過濾推薦圖書[7]。這些都是在經典的協同過濾推薦算法的基礎上提出的改進推薦算法。
主流推薦算法優點很多,但應用于主體是學術論文的數字圖書館存在一定的不足。基于內容推薦算法中用戶模型完全基于歷史記錄中的用戶興趣和需求,難以發現用戶潛在興趣和需求。推薦的結果會聚集在用戶過去的項目類別上,如果用戶不主動關注其他類型的項目,算法很難為用戶推薦多樣性的結果,也無法挖掘用戶深層次的潛在興趣和需求[8]。隨著時間的推移,用戶的研究課題發生變化,對學術論文的興趣和需求也將發生改變。科學技術日新月異,新技術、新發現、新思想層出不窮,基于歷史訪問記錄的內容推薦不符合學術論文推薦的基本要求。
協同過濾推薦算法能夠滿足用戶對學術論文新動態推薦的需求,能有效地提高檢索效果和效率,因此,應用于論文推薦系統的研究較多[9]。在應用中,它存在的不足是冷啟動和稀疏矩陣問題:冷啟動問題,因推薦系統是基于其他用戶的行為而做出的,在系統運行初期,由于缺乏足夠的數據記錄,無法完成協同推薦;稀疏矩陣問題,是由于系統中用戶數量和項目量的巨大,用戶對項目的評價有限,據此建立的相似性矩陣稀疏,也無法完成協同推薦。數字圖書館學術論文更新量大,錄入的期刊論文月更新量就達萬篇,這些都會觸發協同過濾推薦算法的冷啟動和稀疏矩陣問題。為此多數學者都是圍繞彌補冷啟動和稀疏矩陣問題,提出其改進算法。
面對學術論文數量達到千萬篇級別的數字圖書館,推薦算法的效率是非常重要的。基于內容推薦算法需要用文本特征向量模型表示每篇論文,且兩兩比較相似度,依據相似度推薦;協同過濾推薦算法冷啟動和稀疏矩陣問題影響推薦算法的效率和效果,改進算法提升了效率,但其計算模式沒有發生根本的變化,需要建立用戶對論文的評價矩陣,計算用戶與用戶的相似度,依據相似用戶推薦。該文研究通過預估用戶訪問學術論文的概率大小進行系統推薦,嘗試從另一個角度解決學術論文推薦的算法。
2 樸素貝葉斯算法(Native Bayes)
貝葉斯理論是一種用事件發生的先驗概率和已知信息概率推測后驗概率的數理統計方法,被廣泛應用于機器學習的自動分類中。樸素貝葉斯算法是在貝葉斯理論的基礎上進行了簡化,即假定給定樣本的分類屬性之間相互條件獨立[10]。雖然這個簡化方式在一定程度上降低了貝葉斯分類算法的分類效果,但是在實際的應用場景中,極大地簡化了貝葉斯算法的復雜性,并且實際應用效果較好[11]。
樸素貝葉斯算法先計算各個樣本的先驗概率,再利用貝葉斯公式計算各樣本屬于每一個類的后驗概率[12]。算法高效穩定,多應用于數據分類分析,如楊曉花等利用貝葉斯算法對圖書館書目進行自動分類[13];丁童心等利用樸素貝葉斯算法進行人臉表情分類識別[14]。
樸素貝葉斯算法應用于文本分類時,算法的目的是為樣本文本內容匹配最有可能的類別,就是分配文本到后驗概率最大的類別中[15]。文中的研究是改進樸素貝葉斯算法應用到學術論文推薦中,推薦算法的目的是尋找學術論文內容匹配最符合目標用戶的興趣和需求,即推薦論文中后驗概率最大的,最符合目標用戶的,這里不同的目標用戶可以類比作不同的類別容器。
樸素貝葉斯算法在學術論文推薦的工作過程可描述如下:
(1)為每個論文樣本F 建立一個n 維特征向量F={w1,w2,…,wn},利用特征向量描述論文內容;
(2)計算后驗概率P(U|F),U 為目標用戶的需求論文集合;
(3)重復(1)(2),尋找P(U|F)值最大的前m 個樣本論文{F1,F2,…,Fm}推薦給目標用戶U。
根據貝葉斯公式
設其中P(F)、P(U)對于所有論文、用戶均相同,因此只需要尋求計算P(F|U)最大值即可。用戶需求論文集合的先驗概率,這里假設特征屬性w1,w2,…,wn不存在依賴關系,其取值是相互獨立的,其中P(wi|U)可以依據用戶學術畫像特征詞計算得到。
3 用戶學術畫像(User Academic Profile)
用戶畫像是指根據用戶的屬性、用戶的偏好、用戶的行為等信息抽象出來的標簽化用戶模型[16]。用戶畫像有多重維度的刻畫,不同的應用場景有不同的標簽化模型[17]。在數字圖書館推薦系統中,用戶畫像側重于學術畫像,可依據用戶學術研究所屬學科領域以及用戶在系統中歷史訪問行為的數據中挖掘而來。數據分為顯式的和隱式的,顯式的是用戶根據調查主動填寫的,如用戶的學科專業、所屬領域、研究方向等;隱式的是根據用戶訪問行為和用戶顯示信息關聯挖掘的,如用戶曾下載過的學術論文、用戶曾發表的學術論文等。
3.1 特征詞來源
在該文研究中,筆者力圖用描述用戶興趣和需求的特征詞來標簽化用戶學術畫像,這些特征詞來源如圖1 所示。顯式中學術前沿的特征詞可以來自大數據的分析、行業領域專家推薦的研究熱點詞;研究方向的特征詞來源于用戶的自定義。隱式中的特征詞都來自不同的學術論文,瀏覽過的、下載過的、發表過的,這些表示用戶專注的學術研究。提取的特征詞來源于描述論文內容特征的標題、文摘和關鍵詞,通過分詞技術抽取能描述論文內容有實際意義的詞,去除不能表述實際意義的虛詞、通用詞等停用詞[18]。
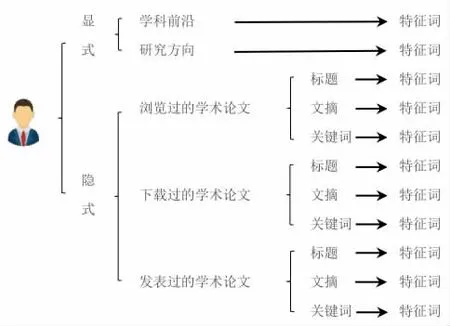
圖1 用戶學術畫像
3.2 特征詞加權計算
特征詞來源于用戶感興趣的學術論文,多篇論文中都涉及相同特征詞,說明用戶對這一領域關注多,興趣度大。用戶的興趣點、研究方向隨著時間會有所變化,因此提取特征詞的論文發表的時間應該在加權中有所反映。一篇學術論文可用字典數據結構表示為F={‘w1’:k,‘w2’:k,…,‘wn’:k},鍵w 為特征詞,值k 為其權重,k 的初始值為decay(x)。其中Nowyear()為當前年,Pubyear()為論文發表年,論文發表時間x=Nowyear()-Pubyear(),decay(x)是自定義的時間衰減函數。
經過多次測試比較,最終自定義的時間衰減函數是y=decay(x)=1/e0.2x,x≥0,如圖2 所示。
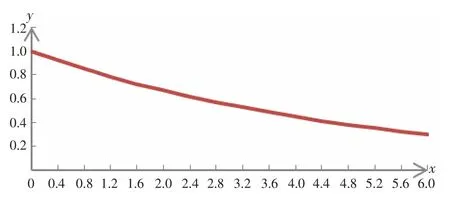
圖2 時間衰減函數y=decay(x)
該函數較好地模擬了特征詞的出現隨著時間的流逝,對用戶的影響力不斷衰減,權值從1 趨近于0。
基于加權特征詞字典的用戶學術畫像建立流程如下:(1)初始化用戶字典U={‘ws’:1,‘wt’:1},ws、wt來源于學科前沿和研究方向的系列特征詞,初始權值為1。(2)循環歸并用戶畫像,歸并學術論文字典于用戶字典U=U∪F,F={‘w1’:k,‘w2’:k,…,‘wn’:k},即U={w:U[w]+F[w] for w in U if w in F},U 和F 中相同特征詞w的權值相加生成U={‘w1’:k1,‘w2’:k2,…,‘wn’:kn}。
4 基于樸素貝葉斯的學術論文推薦算法(Native Bayes Filtering,NBF)
該推薦算法是有監督學習的機器學習算法,算法流程如圖3 所示。用戶曾發表的論文、瀏覽的論文、下載的論文都是已知用戶感興趣和需求的內容,在推薦的論文中用戶依據興趣和需求對部分論文瀏覽或下載,相當于對這些被推薦的論文進行了推薦效果的正向評價。這些論文集作為用戶畫像的來源,同時也是學習算法的數據訓練集,通過每次用戶的評價,用戶學術畫像的系數會發生調整,以此提升算法的推薦效果。
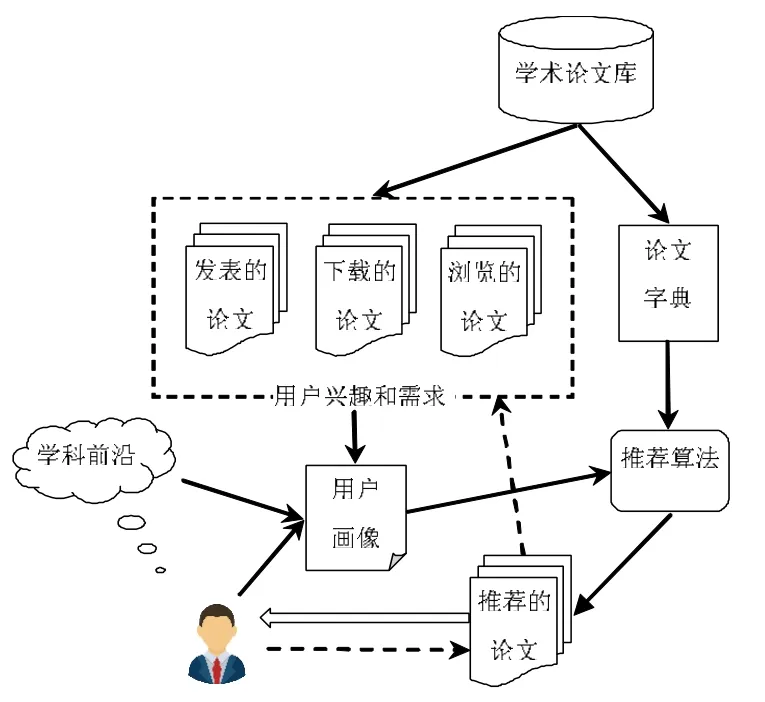
圖3 基于樸素貝葉斯的學術論文推薦算法推薦流程
根據上文3.2 中所述的用戶學術畫像特征詞加權計算,U={‘w1’:k1,‘w2’:k2,…,‘wn’:kn},得出P(wi|U)=,wi∈U。根據上文2.1 中的推理,論文推薦度←P(F|U)←P(F|U)=,wi∈F。對于所有特征詞w,當?w∈F 且w?U 時,P(w|U)→0。
根據表1 的計算過程,用戶A 的學術畫像U={‘智慧圖書館’:5.8,‘協同過濾’:3.4,‘內容推薦’:3.6,‘人工智能’:1,‘個性化’:2.27,‘情景感知’:2,‘知識圖譜’:0.67},因此,P(‘智慧圖書館’|U)=0.31,P(‘協同過濾’|U)=0.18,P(‘內容推薦’|U)=0.19,P(‘人工智能’|U)=0.05,P(‘個性化’|U)=0.12,P(‘情景感知’|U)=0.11,P(‘知識圖譜’|U)=0.04。
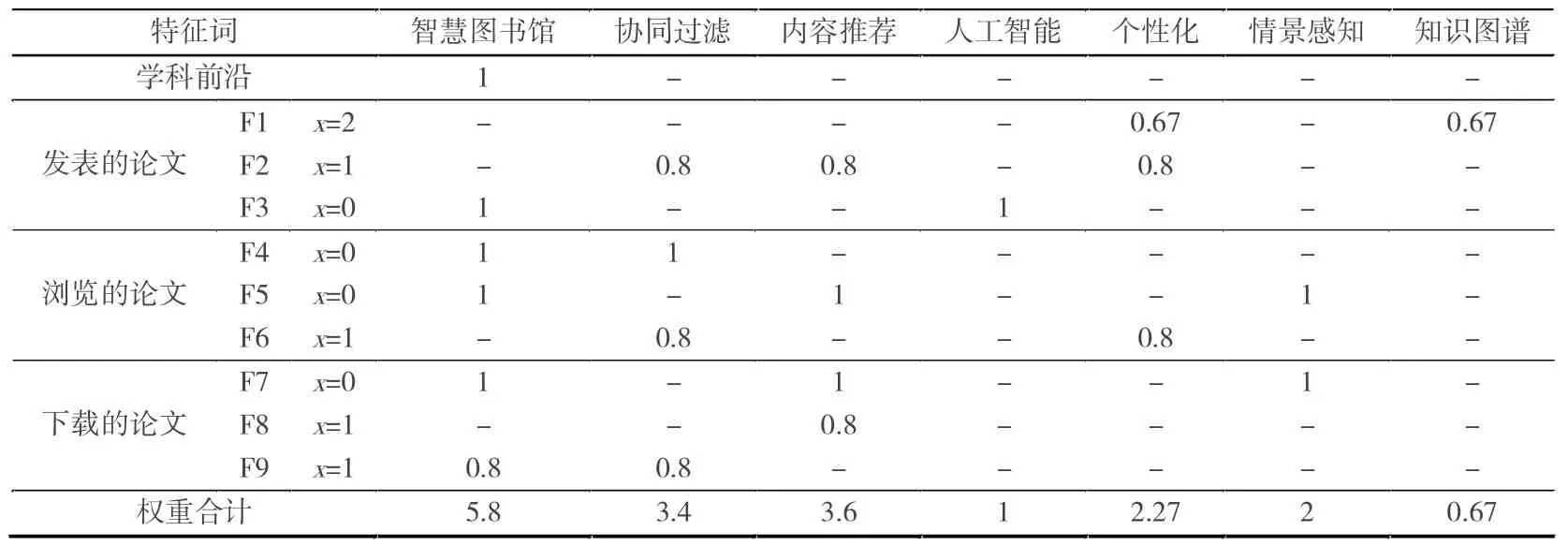
表1 用戶A 學術畫像特征詞加權計算過程
通過分詞技術,每篇學術論文對應一個特征詞字典,比對用戶學術畫像中出現的特征詞的先驗概率可以計算P(F|U)值。表2 為簡化的論文推薦度計算過程,F11-F15 為5 篇學術論文,用特征詞字典表示,其中w為論文中出現而用戶學術畫像中未出現的任意特征詞,P(w|U)→0,為便于比較和計算,統一設定P(w|U)=0.01。通過推薦度的計算,論文的推薦順序為:F12>F11>F13>F15>F14。

表2 論文推薦度計算
5 實證分析
為了驗證文中NBF 推薦算法的有效性,從萬方數據數據庫中獲取相關期刊論文的數據。實驗測試算法中選取論文特征詞數量M 與描述用戶學術畫像特征詞數量N 的最優取值。推薦的學術論文是否滿足用戶的興趣和需求以用戶是否瀏覽、下載過為依據;瀏覽、下載過的論文被補充進描述用戶學術畫像。最后在相同的實驗環境及數據條件下,對文中的NBF 推薦算法與傳統的基于內容推薦算法(CBF)、協同過濾推薦算法(CF)進行實驗測試,比較3 種推薦算法的查準率P、召回率R、F1值及運行時間等評價指標。
5.1 數據來源
選取包含篇名、文摘、關鍵詞的論文數據1 000 條,涉及學科有環境科學、材料科學、計算機科學、電子信息、土木工程、機械工程、數學、物理、化學、生物,每個學科相關論文100 篇。選取測試用戶20 人,每一學科涉及2 人,其中10 人有已發表論文,包含于選取數據中1 篇到5 篇不等。
5.2 實驗過程
在Win dows 系統環境下使用Python3.5 對文本數據進行分析,使用jieba 庫進行中文分詞,去停用詞,計算每篇論文的特征詞權重,篩選出權重較大的前M 個特征詞,形成特征詞字典,表示對應論文。根據測試用戶所屬學科專業和已發表的論文,初始化用戶學術畫像。在模擬環境下,測試用戶瀏覽、下載論文,系統算法反饋推薦的論文,用戶再根據推薦論文,選取需求的論文瀏覽、下載評估推薦的準確性。算法通過這樣的多次學習訓練,一次次地加權計算出描述用戶的特征詞,選取權重較大的N 個特征詞,建立字典描述用戶學術畫像。
5.2.1 實驗1 不同特征向量維度下的算法平均推薦準確率
實驗確定M、N 特征詞數量。令M=5,改變N 的取值,測試結果如圖4 所示,隨著N 值的增大,平均推薦準確率逐漸提高,到達30 后趨于平穩,因此取N=30,繼續M 值的測試。
隨后,令N=30,改變M 的取值,測試結果如圖5 所示,隨著M 值的增大,平均推薦準確率逐漸提高,到達35 后趨于平穩。因此取M=35 為最優解。
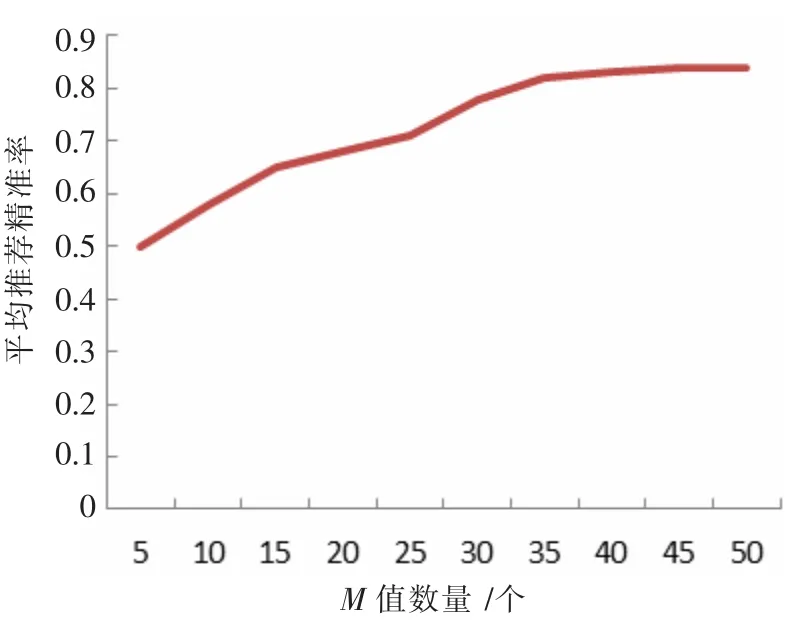
圖5 N=30 時平均推薦準確率趨勢圖
通過實驗確定N 值和M 值,確定用戶畫像特征詞和學術論文特征詞向量的最優維度。取N=30、M=35 個經驗最優值,是為了下一步NBF、CBF、CF 的比較測試。
5.2.2 實驗2 文獻檢索基本性能指標比較測試
取N=30、M=35,測試文中的NBF 推薦算法隨著推薦論文數量從20 至60 每次增加5 的不同情況下的查準率P、召回率R、F1值及運行時間的變化情況。在相同的模擬實驗環境下,引入CBF、CF 推薦算法進行測試,作為性能參照。其中CBF、CF利用TF-IDF 計算特征關鍵詞對論文的權重,使用余弦值計算兩個特征詞向量的相似度,為用戶進行資源推薦。
如圖6 所示三種推薦算法隨著推薦論文數量的增加,查準率P 都有所下降。NBF 和CBF 算法在推薦論文50 篇內,性能接近,50 篇后NBF 趨于平穩,較優。CF 算法在推薦中遇到了冷啟動問題,在模擬測試中性能較差。
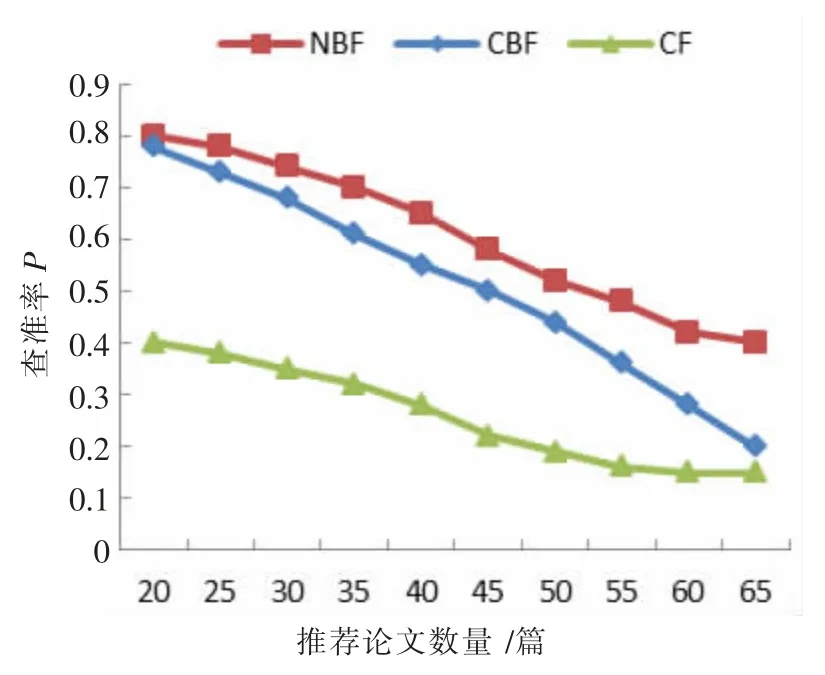
圖6 三種推薦算法隨推薦論文數量查準率變化圖
如圖7 所示三種推薦算法隨推薦論文數量的增加召回率變化趨勢。NBF 推薦算法明顯好于CBF 和CF算法。CF 依然在推薦中遇到了冷啟動問題。
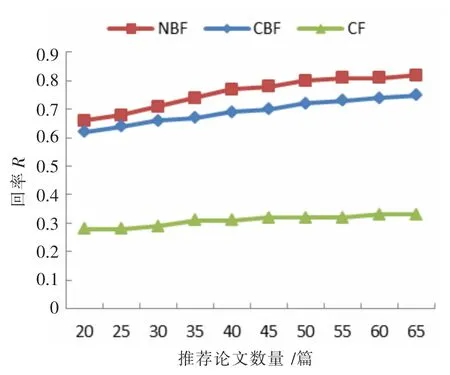
圖7 三種推薦算法隨推薦論文數量召回率變化圖
F1值是同時兼顧推薦算法的查準率和召回率的重要性能指標,可以根據公式F1=(2PR)/(P+R)進行計算,如圖8 所示。NBF 僅在推薦20~25 篇論文時與CBF 相當,其他推薦數量時,均優于CBF 和CF 算法。
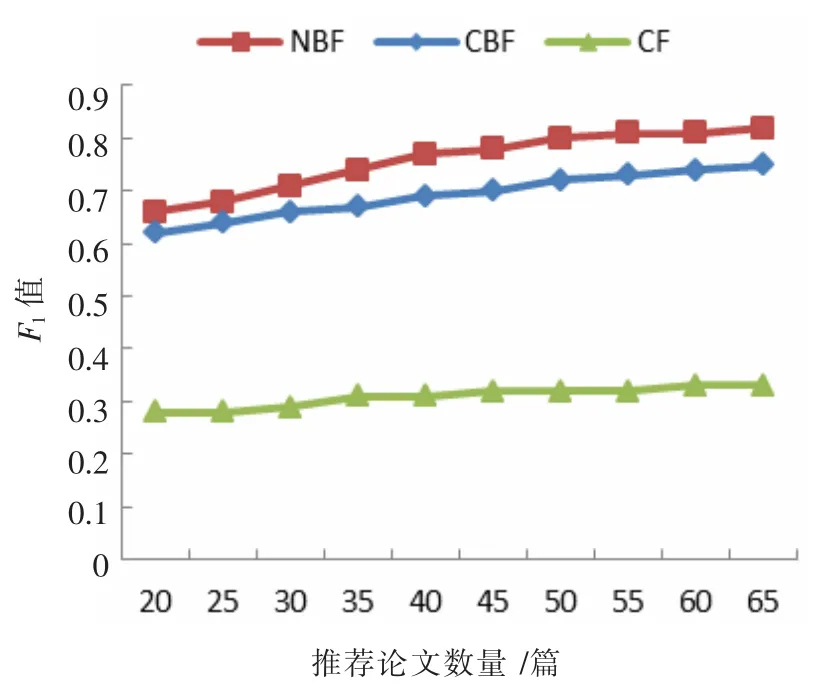
圖8 三種推薦算法隨推薦論文數量F1 值變化圖
5.2.3 實驗3 推薦算法運行時間比較測試
在相同的運行環境下,三種推薦算法隨著推薦論文數量的增加,運行時間的變化如圖9 所示。NBF 算法平均運行時間為4.9 s,CBF 算法平均運行時間為6.9 s,NBF 比CBF 運行效率提高了29%。CF 算法因為測試用戶數量少,影響了實驗效果。
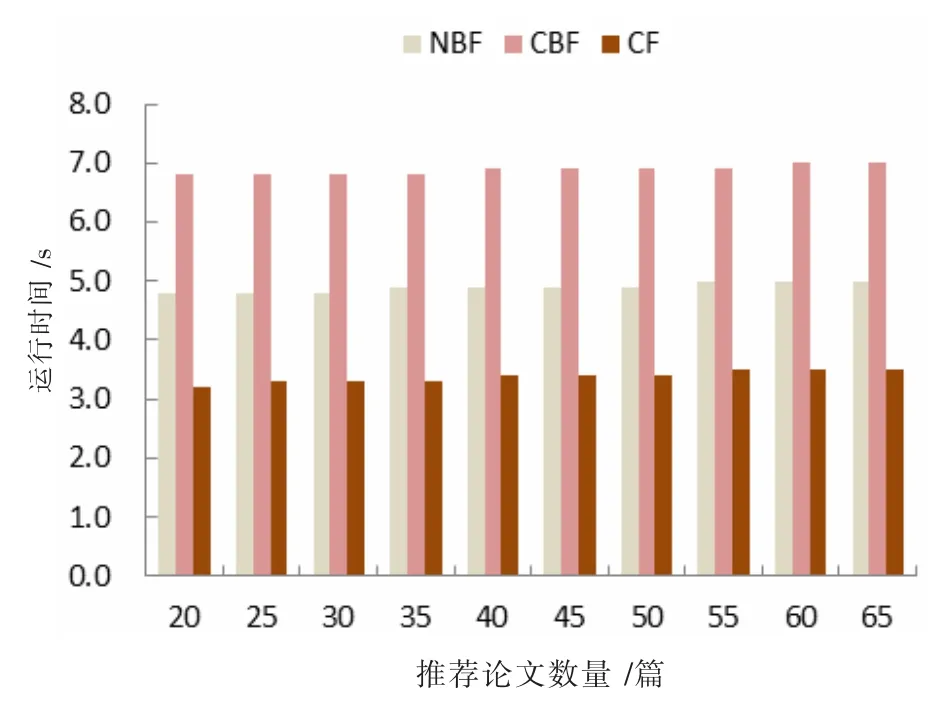
圖9 三種推薦算法隨推薦論文數量運行時間變化圖
實驗結果表明當N=30、M=35 時,文中研究的NBF 算法在測試指標查準率P、召回率R、F1值、運行時間方面明顯優于CBF、CF 算法。實驗中CF 算法使用的是基礎的協同過濾算法,沒有消除CF 算法中固有的冷啟動問題等不足,因此這里的CF 算法表現較差。該實驗不能表示其他學者的CF 改進算法的測試結果。
6 結語
學術論文是國家地區科學研究、高等教育的重要文獻保障資源,如何提升學術論文的有效利用率是圖書情報學研究撬動科研能力提升的杠桿。學術論文有其自身的特點:學科專業性強,內容分類細,月更新量大,同時學術論文還是數字圖書館的主體,其主流數字圖書館檢索平臺收錄的論文數量多達千萬篇[19]。在海量的資源中,基于用戶學術畫像,推薦用戶有效論文極其重要。基于樸素貝葉斯的學術論文推薦算法NBF,是依據貝葉斯分類算法提出并改進的,在模擬測試的環境中性能優于主流CBF、CF 推薦算法,在實際應用中具有一定的價值。文中的研究是從預估用戶訪問學術論文的概率入手思考推薦算法的,可以為圖書館個性化推薦服務提供了新的思路。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
