異策略深度強化學習中的經驗回放研究綜述
2023-11-28 18:48:14胡子劍高曉光萬開方張樂天汪強龍NERETINEvgeny
自動化學報 2023年11期
胡子劍 高曉光 萬開方 張樂天 汪強龍 NERETIN Evgeny
強化學習(Reinforcement learning,RL)的來源通常被認為是心理學中的行為主義理論,即有機體能獲得最大利益的習慣性行為是在環境給予的獎勵或懲罰的不斷刺激下,逐步形成的對刺激的預期.直到20 世紀末,RL 才開始得到研究者們的重視并迅速發展,并被認為是設計智能體的核心技術之一[1-2].
RL 通過 “試錯”(Trail-and-error)[2]的方式與環境進行交互并獲得獎勵,并依據獎勵不斷調整智能體的行為策略.這種符合人類的經驗性思維與直覺推理的一般決策過程使得其在人工智能領域得到了廣泛的應用[3].隨著應用環境復雜程度的不斷提升,“維度災難”[4]限制了RL 的進一步發展.為了更好地表征復雜任務場景中高維度的狀態空間,谷歌人工智能團隊Deepmind 創新性地將深度學習(Deep learning,DL)與RL 相結合,提出了人工智能領域的一個新的研究熱點 ——深度強化學習(Deep reinforcement learning,DRL)[5].DRL 同時具備了DL 的特征感知能力和RL 的決策能力,能夠學習大規模輸入數據的抽象表征,并以此表征為依據進行自我激勵,優化解決問題的策略[6].目前,DRL 這種端對端(End-to-end)的學習方式已經在游戲博弈[5,7-9]、機器人控制[10-12]、自動駕駛[13-15]、金融貿易[16-18]、醫療保健[19-20]等多個領域取得了顯著的進展,其訓練的智能體的表現已經接近甚至超越了人類水平.
不同于監督學習和無監督學習,RL 通過智能體與環境的不斷交互來對環境進行探索進而獲得經驗(樣本),并根據所獲得的經驗對智能體的策略不斷更新,最終找到一個適應環境的最優策略.由于RL 在學習過程中沒有固定的數據集,其需要智能體消耗大量的時間成本來獲取交互經驗.在一些復雜的環境尤其是現實環境中(例如自動駕駛)會承擔很多的風險與代價.除此之外,損耗、響應時延等問題也會使得智能體能夠收集的經驗數量是有限的.如何合理利用有限的經驗來訓練出策略盡可能好的智能體已然成為國內外研究者的一個關注重點.
經驗回放(Experience replay,ER)是一種存儲過去的連續經驗并對其進行采樣以重復使用進而更新智能體行動策略的技術,其概念于1992 年被Lin 等[21]率先提出.2015 年,隨著深度Q 網絡算法(Deep Q-network,DQN)[5]的提出,經驗回放被證明在DRL 的突破性成功中發揮了重要的作用.這一新的研究熱點迅速吸引了大量研究者的關注,到目前為止,經驗回放已成為提高異策略DRL 算法穩定性和收斂速度的一種主要技術.在現有文獻中,還沒有研究嘗試將DRL 中的經驗回放算法進行分類和總結.本綜述以RL 的基本理論為出發點,首先介紹了RL 的基本概念.隨后對RL 算法依據行為策略與目標策略的一致性進行了分類,并對其中異策略DRL 的典型算法進行了介紹.然后結合近年來公開文獻詳細梳理了國內外成熟的異策略DRL 中的經驗回放方法,并將其分為兩個大類,即經驗利用和經驗增廣.最后,對異策略DRL 中的經驗回放方法進行了總結與展望.
1 深度強化學習理論基礎
1.1 強化學習
RL 是一個學習如何將環境狀態映射到智能體的行為以最大化累積回報的過程[2].其中智能體與環境的交互過程如圖1 所示,在每一個時間步,智能體首先對環境進行觀測,隨后根據觀測結果依照自身策略選擇要采取的動作并執行.該動作會使得環境的狀態發生轉移,并且環境會根據這一動作的優劣對智能體進行獎勵或懲罰.智能體不斷重復這個過程,直至達到設定的終止狀態,結束這一回合的迭代.
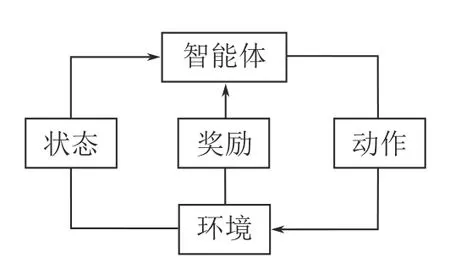
圖1 強化學習過程Fig.1 The process of reinforcement learning
馬爾科夫決策過程(Markov decision process,MDP)為RL 提供了一個簡單易行的框架,幾乎所有的RL 問題都可以被建模成MDP.MDP 通常由四元組 (S,A,P,R)表示,其中: 1)S是環境中智能體所有能夠到達的狀態的集合;2)A代表智能體在環境中所有能夠選擇的動作的集合;3)P是智能體在狀態s下執行動作a并到達狀態s′的概率,其中a∈A并且s,s′∈S;4)R代表智能體在狀態s下執行動作a所獲得的獎勵.
在RL 中,策略π是從狀態空間到動作空間的映射:π:S→A.π中的一個元素π(a|s)代表智能體在狀態s下選擇動作a的概率.依據該策略,智能體能夠獲得累計獎勵Rt.對于一個在T時間步終止的回合,在任意時間步t時的累計獎勵Rt的定義如下
其中,r(·)是獎勵函數,γ∈[0,1] 是一個折扣系數,來決定未來獎勵對累計獎勵的影響,γ的引入使得距離當前狀態越遠的獎勵,對當前的累計獎勵的影響越小.
定義智能體在狀態s下執行動作a并遵循策略π一直到回合結束所獲得的累計獎勵的數學期望為狀態–動作值函數Qπ(s,a)
當遵循最優策略π*時,狀態–動作值函數達到最大值
最優狀態–動作值函數Q*(s,a)滿足具有遞歸屬性的貝爾曼方程[22]
持續地迭代公式(4)使狀態–動作值函數最終收斂即可獲得解決該RL 問題的最優策略
1.2 強化學習算法
1.2.1 強化學習算法分類
RL 中通常包含兩種策略,分別稱為行為策略(Behavior policy)和目標策略(Target policy).行為策略是智能體在與環境交互過程中用來選擇動作的策略,即在智能體訓練過程中使用的策略.而目標策略是指智能體在行為策略產生的經驗中不斷學習、優化時所采用的動作選擇策略.
如圖2 所示,根據算法中的行為策略和目標策略是否相同可以將RL 算法分為兩類,同策略強化學習(On-policy RL)和異策略強化學習(Off-policy RL).
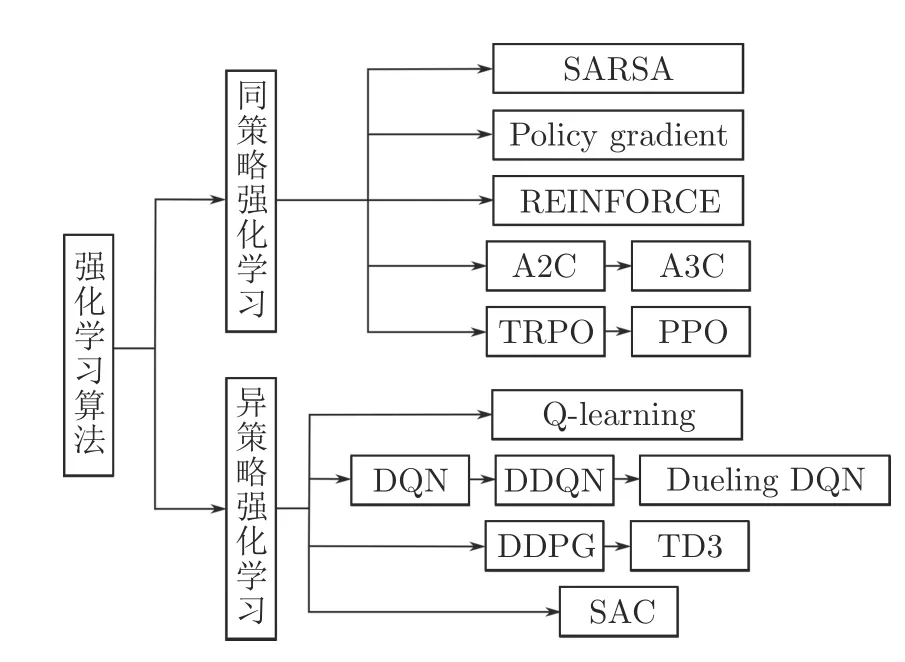
圖2 強化學習算法分類Fig.2 The classification of reinforcement learning algorithms
屬于同策略RL 的算法主要有SARSA[23]、Policy gradient[24]、REINFORCE[25]、基于演員–評論家(Actor-critic,AC)架構的優勢演員–評論家(Advantage AC,A2C)[26]、異步優勢演員–評論家(Asynchronous A2C,A3C)[27]、信賴域策略優化(Trust region policy optimization,TRPO)[28]、近端策略優化(Proximal policy optimization,PPO)[29]等算法.異策略RL 主要包含Q-learning[30]、DQN[5]及其一些改進算法[31-32]、確定策略梯度的深度確定性策略梯度(Deep deterministic policy gradient,DDPG)[33]和改進后的雙延遲深度確定性策略梯度(Twin delayed DDPG,TD3)[34]、隨機策略梯度的柔性演員–評論家(Soft AC,SAC)[35]等算法.
以同策略RL 和異策略RL 的經典算法SARSA和Q-learning 為例,其狀態–動作值函數的更新方式分別如下式所示
二者的區別在于,在Q-learning 中,行為策略采用ε-greedy 策略進行動作選擇來完成智能體與環境的交互過程,在Q 值更新時,目標策略并不關心下一時間步所采取的動作a′,而是貪婪地使用下一時間步中最大的Q 值來更新當前時間步的Q 值.而在SARSA 算法中,智能體交互過程和Q 值更新過程中的動作選擇策略均采用的是ε-greedy 策略.
同策略RL 通常在每一時間步都對目標策略進行實時更新,而異策略RL 通常設計經驗池來對行為策略產生的交互經驗進行存儲,以便智能體對其采樣和學習,從而實現對目標策略的不斷更新.二者各自的主要優勢如表1 所示.
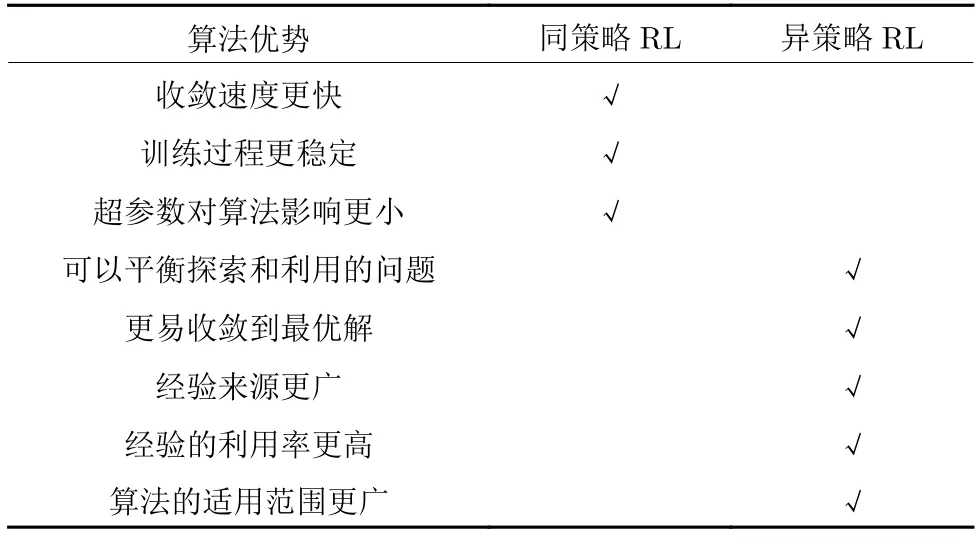
表1 同策略與異策略算法的優勢對比Table 1 Comparison of advantages of on-policy and off-policy algorithms
1.2.2 異策略強化學習
為了擴大RL 算法的使用范圍,Mnih 等[5]將卷積神經網絡與Q-learning 相結合,提出了基于值函數的DQN 算法.DQN 主要有以下兩個特點:
1)使用兩個獨立的網絡
如圖3 所示,DQN 有兩個超參數相同的深度神經網絡,分別叫做估計網絡(Eval net)和目標網絡(Target net).參數為θQ的估計網絡的輸出為估計Q 值Q(si,ai|θQ),用來近似表示狀態–動作值函數,而參數為的目標網絡的輸出則為通過結合獎勵值ri來計算目標Q 值yi
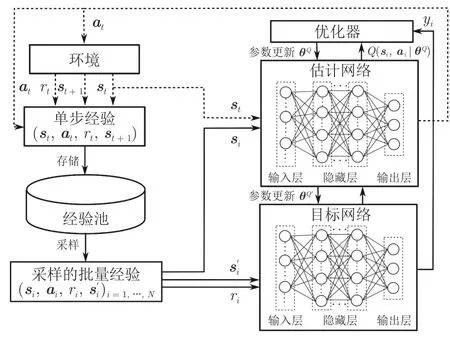
圖3 DQN 算法框架Fig.3 The framework of DQN algorithm
DQN 通過最小化估計Q 值與目標Q 值之間的均方誤差來更新估計網絡的參數
其中,N為采樣的經驗數.
每隔一定的迭代次數,就將估計網絡的參數θQ直接復制到目標網絡.DQN 的這種網絡結構降低了目標網絡與估計網絡之間的相關性,從而提升了算法的穩定性.
2)引入經驗回放機制
為了消除經驗之間的相關性,使用于訓練的經驗滿足獨立同分布,DQN 首次引入經驗回放機制并設計了一個經驗池來存儲和管理經驗.在每一個時間步,將智能體與環境的交互經驗(si,ai,ri,si+1)暫存到經驗池中.在訓練過程中采取隨機抽樣的方法從經驗池批量選擇經驗來對估計網絡的參數進行更新,從而實現了對過往經驗的充分利用,進一步提升了算法的性能.
然而由于神經網絡估計的Q 值會在某些時候產生正向或負向的誤差,而根據DQN 的更新方式(式(8)),這些誤差會不斷地向正向累積從而產生狀態–動作值函數過高估計的問題.為了解決這個問題,Hasselt 等[31]提出了深度雙Q 網絡(Double DQN,DDQN).不同于DQN 只使用目標網絡來計算目標Q 值,DDQN 將動作選擇與策略評估分離開來,首先使用估計網絡選擇最優的動作,隨后使用目標網絡對該動作進行評估.DDQN 的網絡結構和參數更新方式均與DQN 完全相同,而其目標Q 值的計算方式有所改變
這種通過利用兩個網絡來計算目標Q 值的方式使得即便其中某一網絡的某個動作存在嚴重的過估計,而由于另一網絡的存在,該動作最終使用的Q 值也不會被過高估計.實驗表明,DDQN 能夠對Q 值進行更為準確的估計,在多種應用場景中都可以獲得更為穩定有效的策略.
在很多場景中,Q 值只受當前狀態影響,智能體所采取的動作對其影響不大.基于這種現象,Wang等[32]提出了競爭深度Q 網絡(Dueling DQN).與DQN 不同的是,在Dueling DQN 中經過卷積神經網絡處理的特征被分別輸入到兩個不同的全連接網絡中,即值函數網絡V(si|θ,β)和優勢函數網絡A(si,ai|θ,α),其中θ是共用的卷積神經網絡部分的參數,β和α分別為值函數網絡和優勢函數網絡對應全連接層的參數.將兩個網絡的輸出進行合并得到
然而按以上優勢函數構造的Q 函數會導致解不唯一的問題,在實際使用時,一般通過將動作優勢函數值減去當前狀態下所有優勢函數的平均值來提高訓練過程的穩定性
除了上述較為經典的DDQN、Dueling DQN算法,還有很多研究嘗試對DQN 從訓練算法、網絡結構和學習機制等不同方面進行改進,例如分布式DQN (Distributional DQN)[36]、深度循環Q 網絡(Deep recurrent Q-network,DRQN)[37]、噪聲DQN (Noisy DQN)[38]、Rainbow[39]等.劉建偉等[40]對這些DQN 的改進算法進行了詳細的分析和討論.
DQN 一類的基于值函數的算法通過對狀態–動作值函數的近似表達來進行學習,并且在處理離散動作空間問題時取得了不錯的效果.然而當問題擴展到連續動作空間時,貪婪策略需要在每一個時間步進行優化,這種優化的速度太慢且無法應用于大型無約束的函數優化器[33].而基于策略梯度的算法直接將策略近似,因此可以很好地在連續空間中對動作進行搜索.基于策略梯度的算法通常分為兩種: 輸出動作為狀態映射a=μθ(s)的確定策略梯度算法和輸出動作為概率分布a~πθ(s)的隨機策略梯度算法.二者的策略梯度分別為
其中,ρπ和ρμ是狀態的采樣空間,而πθ是動作的采樣空間.
Lillicrap 等[33]提出了一種基于演員–評論家架構的DRL 方法DDPG,該方法在求解具有連續動作空間的MDP 時取得了良好的效果.演員網絡用于確定智能體選擇動作的概率,而評論家網絡用于根據環境狀態對智能體選擇的動作進行評估.如圖4所示,與DQN 的網絡結構相同,DDPG 的演員和評論家網絡都包含兩個結構相同的估計網絡和目標網絡.
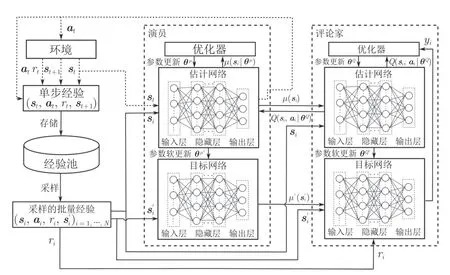
圖4 DDPG 算法框架Fig.4 The framework of DDPG algorithm
DDPG 加入了一個獨立噪聲Nt來增加智能體探索過程的隨機性
在DDPG 的基礎上,Fujimoto 等[34]提出了一種新的基于策略的算法TD3,該算法已被證明是目前最先進的DRL 算法之一.TD3 算法主要做了以下三個改進來提升DDPG 算法的性能.
1)利用雙網絡結構來避免過估計: TD3 具有兩套評論家網絡來分別計算并選擇其中較小的作為目標,因此式(17)、式 (18)分別為
2)延遲更新演員網絡來增加穩定性: 不同于DDPG 算法的同步更新演員和評論家網絡參數,TD3算法讓評論家網絡的更新頻率稍高于演員網絡,以此來提高演員網絡的穩定性.
3)添加動作噪聲來平滑目標策略: 為了使學習到的策略更加平滑和穩定,TD3 加入了一個動作噪聲ε~clip(N(0,),-l,l)來使得在計算Q 值時動作能夠在一定范圍內隨機變化
TD3 的網絡參數的更新方式則與DDPG 保持一致,采用軟更新的方法
其中,τ∈[0,1] 決定了每次更新的幅度.
不同于確定策略梯度,隨機策略梯度能夠使智能體在相同的狀態下按照概率分布選取不同的動作.最為廣泛使用的異策略RL 算法就是引入了熵(Entropy)的概念的SAC 算法.
熵是對一個隨機變量的隨機程度大小的度量.對于一個隨機變量X,假設其概率密度為p,即p(xi)是隨機變量X為xi的概率,那么它的熵就被定義為
在RL 中常用H(π(·|s))來表示策略π在狀態s下的隨機程度.最大熵強化學習(Maximum entropy RL),就是在RL 的目標中加入熵的正則項來最大化累計獎勵,同時使策略更加隨機
其中,α是控制熵的重要程度的正則化系數.
相較于傳統的RL,熵的正則化增加了最大熵RL 算法的探索程度,α越大,算法的探索性就越強,策略學習的速度也就越快,陷入局部最優解的可能性也就越小.
SAC 算法由Haarnoja 等[35]在2018 年首次提出,使用隨機策略來實現連續控制,隨后他們又在文獻[41]中基于Q-learning 舍棄了值函數的應用,還將熵的權重α設計為可自動調整的參數來提高訓練的穩定性.與TD3 算法相同,SAC 算法也使用了雙評論家的網絡結構(包含參數為θ1,θ2的估計網絡和對應參數為的目標網絡).與TD3 算法不同的是,由于只包含一個參數為θ的演員網絡,SAC算法在計算Q 值時僅通過演員網絡πθ來根據狀態進行動作選擇ai~πθ(·|si).因此,式(21)變為
由于在連續動作空間的環境中,SAC 算法演員網絡輸出的動作是對高斯分布采樣得到的,需要使用重參數化技巧(Reparameterization trick)[42]來使得動作采樣的過程可導,從而方便策略梯度的計算
其中,μθ(s)和σθ(s)分別為在狀態s下多次選擇動作的均值和標準差.隨后使用損失函數Lπ(θ)來對演員網絡進行更新
對于評論家網絡的目標網絡,SAC 也同樣使用軟更新的方式來更新其參數.
2 經驗回放機制
如圖5 中的外部循環所示,在異策略RL 算法中,經驗回放通常是通過設計一個經驗池來對智能體與環境的交互經驗進行暫存,以便智能體從中選擇合適的經驗來學習更新自身的行動策略.經驗池通常是一個固定大小的先進先出(First in first out,FIFO)的緩沖區,其中包含智能體收集的最新的部分經驗.這種緩沖區為DRL 帶來了兩個優點: 1)均勻采樣打破了連續經驗之間的相關性,提高了算法的穩定性;2)大容量緩沖區確保了從長期經驗中學習的可能性,從而避免了 “災難性遺忘”[5]現象的發生.
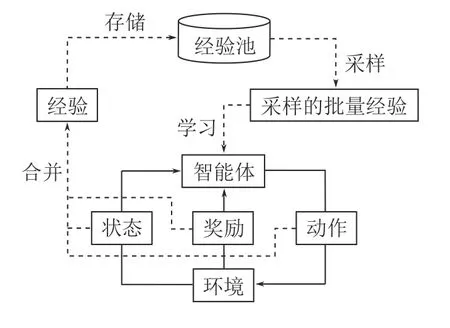
圖5 異策略RL 的經驗回放流程Fig.5 The experience replay process of off-policy RL
作為一種獨立于RL 循環之外的即插即用的模塊,經驗回放已經被廣泛應用于各種領域來提升異策略RL 算法的效果.如圖6 所示,本節將經驗回放算法分為經驗利用和經驗增廣兩大類,來對目前較為成熟的經驗回放領域的相關研究進行詳細介紹.
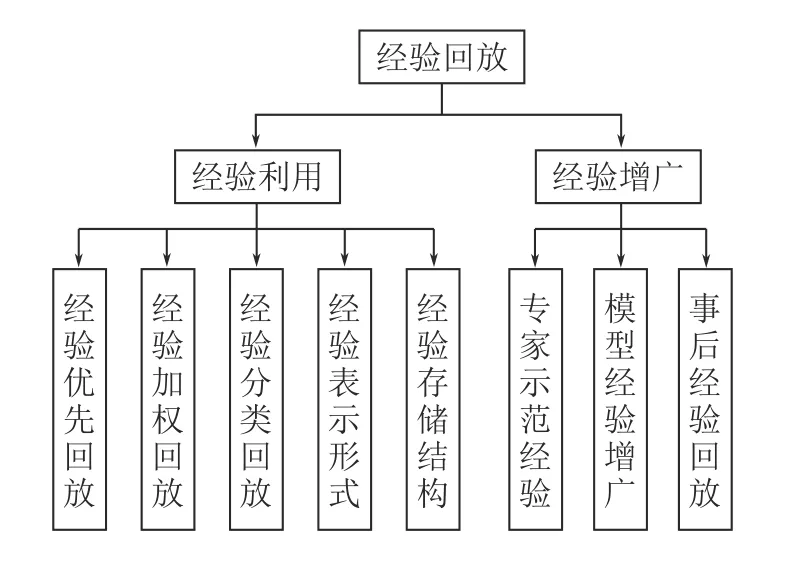
圖6 經驗回放分類Fig.6 The classification of experience replay
2.1 經驗利用
2.1.1 經驗優先回放
經驗利用的最基本思路就是調整被學習的經驗的順序,即通過設計一些采樣算法來優先選擇更適合當前網絡收斂的經驗進行學習.
2016 年,Schaul 等[43]首次提出了優先經驗回放算法(Prioritized experience replay,PER),根據所存儲經驗各自的時間差分誤差(Temporal difference error,TD error)的大小來賦予其不同的優先級,使得TD error 更大的經驗能夠獲得更大的采樣概率.對于一條經驗ei,其采樣概率計算如下
其中,δi為TD error,ε是一個正向的常數,來保證TD error 接近零的經驗也有被采樣到的可能.除此之外,PER 還設計了一個名為 “sum tree”的數據結構來保證經驗存儲和優先性采樣的高效性.實驗表明,結合了PER 后的DQN 算法在收斂效率上取得大幅提高,在49 個Atari 游戲中有41 個的表現都要優于原始的DQN 算法.
受PER 算法的啟發,Brittain 等[44]考慮了連續經驗之間的關系,他們認為不僅應該為重要的經驗分配更高的采樣優先級,也應該增加導致重要經驗產生的前序經驗的優先級,并提出了一種優先序列經驗回放算法(Prioritized sequence experience replay,PSER).PSER 通過引入一個衰減因子ρ來依據當前經驗優先級pn對前序經驗的優先級進行更新
其中,m為前序經驗的遠近程度.在60 款Atari 游戲的實驗測試中,PSER 在其中的40 款都取得了優于PER 的收斂效果.
Lee 等[45]認為PER 存在包含大量有偏向性的優先化問題.針對這一問題,他們設計了三種不同的策略(TDInit、TDClip 和TDPred),并將它們綜合在一起提出了預測優先經驗回放算法(Predictive PER,PPER).PPER 在實驗測試中不僅消除了優先級的異常值的存在,還改善了經驗池中經驗的分布,平衡了經驗池中經驗優先性和多樣性,使得算法的穩定性得到了大幅改善和提升.
Cao 等[46]提出了高價值優先經驗回放方法(High-value PER,HVPER),將經驗對應的狀態–動作函數值和TD error 一同作為衡量其優先級的指標,并將優先級函數定義為
其中,pQ和pTD分別為歸一化后的Q 值和TD error,ui=表示學習次數ni對經驗優先級的影響.HVPER 在多種環境的測試實驗以及與多種異策略RL 算法的結合中都取得了不錯的效果.如果能夠設計一種基于經驗分布在線自適應地調整超參數λ的方法,則能有效提升HVPER 的適用性.
趙英男等[47]提出一種二次主動采樣算法(Twice active sampling method,TASM),來實現經驗的分批次優先利用.TASM 算法中的經驗是按照序列進行存儲的,在采樣時首先以單個序列的累積獎勵作為標準篩,從大經驗池中選出多個符合條件的序列構成小經驗池,第二輪再回歸PER 算法以TD error為標準從小經驗池中選擇經驗進行學習.TASM 的二次采樣有效地實現了經驗的高效利用并提升了策略的質量,但由于其在采樣時要對所有序列進行遍歷,算法的時間復雜度稍有提升.
Sun 等[48]則考慮了過去存儲的經驗中的狀態與智能體當前狀態的相似性,提出了注意力經驗回放算法(Attentive experience replay,AER),實現了比PER 更高的經驗利用率和算法收斂速度.如下式所示,針對向量形式狀態的環境和圖片形式狀態的環境,AER 分別設計了不同的相似性函數來計算狀態之間的相似性
其中,?是一個結構固定而初始值隨機的深度卷積神經網絡.除此之外,AER 還采用多輪次采樣的方法來調整優先采樣的程度以提高算法的適應性.然而,AER 在采樣時依次計算采樣到的大批量經驗與當前狀態之間的相似性并進行排序,會耗費大量的時間,并且相似狀態的重復出現導致大量的重復計算,也對其運行效率產生了不利影響.
Hu 等[49]同樣考慮了當前狀態與過去經驗之間的相似性,并針對于無人機自主運動控制場景提出了相似經驗學習算法(Relevant experience learning,REL).與AER 不同,REL 使用了一個更有針對性的函數來衡量智能體的狀態的價值,并將該函數值一同存入經驗池中,在采樣時直接根據該函數值的差異性來評價狀態之間的相似性,從而避免了AER 會出現的重復計算現象.REL 還采用了PER中的 “sum tree”結構來進行經驗的存取,大幅降低了尋找相似經驗的時間復雜度.除此之外,REL還調整了RL 中動作選擇和策略更新的順序,使得每一次的策略更新都能及時地作用在當前時間步的動作選擇上,從而充分發揮了過去經驗的作用,加快了算法的收斂速度.
Cicek 等[50]提出了一種基于KL (Kullback-Leibler)散度的批量優先經驗回放(Batch prioritized experience replay via KL divergence,KLPER),將單個經驗優先級排序擴展到批量經驗優先級排序.在每次采樣時,KLPER 先采樣出多個批量經驗并通過KL 散度對其優先級進行排序,最終找到其中與智能體的最新策略最相近的批量經驗進行學習.在多種連續的控制任務中,KLPER 在樣本效率和收斂性能上均優于隨機采樣的經驗回放算法和PER 算法.然而所學習的批量經驗不可避免地仍會包含一些價值較低的經驗,對這些經驗的剔除或替換則有望進一步提升KLPER 算法的性能.
為了使智能體能夠模擬人類的由簡到難的學習過程,Ren 等[51]首次將課程學習(Curriculum learning,CL)[52-53]的機制引入到經驗回放當中,提出了深度課程強化學習(Deep curriculum reinforcement learning,DCRL).DCRL 所定義的復雜性標準包括自定步長優先級和覆蓋懲罰.自定步長優先級反映了TD error 與當前課程難度之間的關系
其中,δ是經驗對應的TD error,而λ是隨訓練不斷增大的課程因子.覆蓋懲罰則用于避免同一經驗被多次重復學習
其中,cn是經驗被學習的次數.DCRL 通過復雜度函數 C I(xi)=SP(δi,λ)+ηCP(cni)來自適應地從經驗池中選擇合適的經驗,從而充分利用了經驗回放的優勢,提升了算法的收斂速度.但由于引入了CL來控制所回放經驗的難度,DCRL 額外加入了幾個環境敏感性較高的超參數,在實際使用時還需要依據環境特性進行調整.
上述的這些研究雖然用不同的方式在一定程度上彌補了PER 算法的不足,但PER 所存在的根本性問題尚未得到良好的解決.Hu 等[54]對PER 進行了詳細分析并總結了其4 個有待改進的問題: 1)TD error 的更新速度太慢會影響被采樣到的經驗的價值;2)PER 中的裁剪(clip)操作降低了不同經驗之間的差異性;3)賦予新經驗最大的優先級不能保證其優先性;4)僅根據TD error 進行采樣可能不是最優的采樣方法.
他們嘗試從根本上解決這些問題,并提出了異步課程經驗回放算法(Asynchronous curriculum experience replay,ACER).ACER 算法主要有以下幾個貢獻: 1)開啟一個子線程來異步更新經驗池中經驗的優先級;2)廢除PER 中的clip 操作來賦予經驗其真實的優先級;3)設計了一個臨時經驗池來充分利用最新產生的經驗;4)將FIFO 的經驗池進行了更替來使得經驗池滿時最無用的經驗會優先被替換;5)引入CL 使學習過程更為合理的同時解決無clip 操作帶來的問題.ACER 算法在收斂速度上比PER 取得了較大的提升,其穩定性也在多個不同的應用場景的測試中得到了驗證.
表2 對上述經驗優先回放類算法進行了總結,可以明顯看到,大多數經驗優先回放類算法還是在嘗試設計不同的評價指標來衡量經驗的優先級.KLPER 則是將單個經驗優先回放擴展到批量經驗優先回放.DCRL 則將CL 思想引入經驗回放中,為經驗優先回放提供了一種新的思路.在較為全面的分析和總結后,ACER 對PER 的缺點逐一做出了改進,但其所提供的理論支撐還不夠完善,且其作為彌補PER 算法所有缺點的第一次嘗試,一些設計在合理性和計算效率上有待進一步完善和提高.
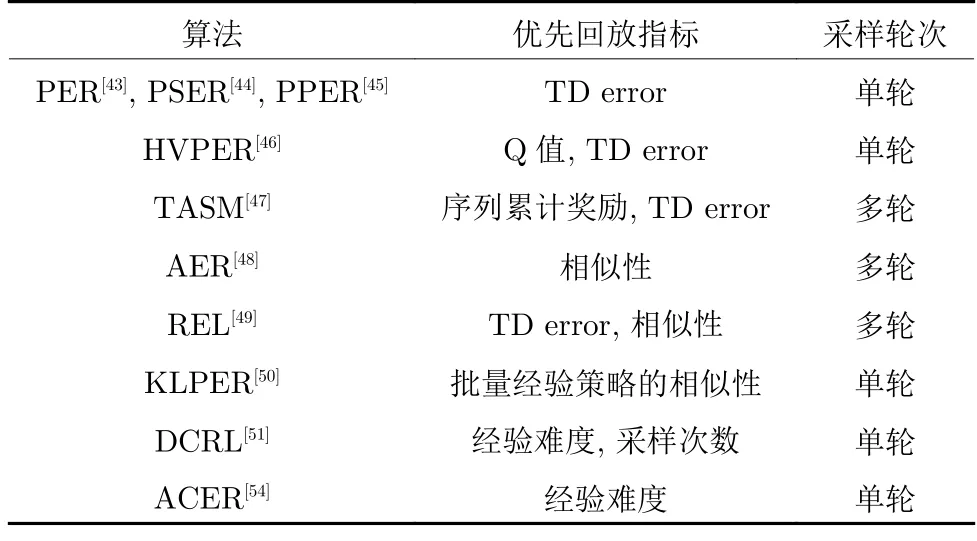
表2 經驗優先回放算法對比Table 2 Comparison of prioritized experience replay algorithms
2.1.2 經驗加權回放
相較于按照特定標準從龐大的經驗池中篩選經驗的經驗優先回放的方法,近年來一個更為靈活且計算復雜度更低的研究方向是通過重加權的方式賦予更為重要的經驗更高的權重,從而利用經驗回放在提高策略準確性的同時加速策略的收斂.
Kumar 等[55]針對Q-learning 和AC 算法缺少糾正性反饋(Corrective feedback)而導致這些算法所存在的易收斂到次優解、學習過程不穩定、信噪比較高時學習效果差等問題,提出了一種分布校正(Distribution correction,DisCor)的方法.DisCor使用神經網絡來估計Q 值的累計誤差 Δ?(s,a),并理論推導出了下式來計算所學習經驗在第k次更新時的權重wk
其中
通過對不同經驗的重加權來糾正Q 值的累計誤差,DisCor 在表格環境、連續控制環境甚至于多任務環境中都展現出了其策略收斂的高效性和穩定性.
受DisCor 的啟發,Lee 等[56]提出了一種不同的思路并設計了基于集成學習的強化學習框架(Simple unified framework for reinforcement learning using ensembles,SUNRISE).與A3C 類似,SUNRISE 集成了N對演員和評論家網絡,在使用采樣的經驗對每一個評論家網絡進行更新時,經驗的權重設計為
SUNRISE 顯著地提高了Q 值更新過程中的信噪比,使學習過程更加穩定.通過與SAC 算法和Rainbow 算法的結合,SUNRISE 在低維和高維環境下的連續和離散控制任務中均取得了優于最先進的RL 算法的收斂效果.
Sinha 等[57]則認為應該按照當前策略下的經驗分布來設計經驗在回放時權重的大小,并提出了一種無似然重要性加權方法(Likelihood-free importance weighting,LFIW),優先回放那些出現頻率較高的狀態–動作對 (s,a).LFIW 通過設計大小兩個經驗池Ds和Df來分別存儲過去不同策略指導下的經驗和最近策略指導下的經驗.除此之外,LFIW使用了一個參數為ψ的神經網絡來估計狀態–動作對 (s,a)的權重,并通過損失函數Lw(ψ)來進行參數更新
其中,f是一個滿足f(1)=0 的下半連續函數.LFIW使用一個常數T對權重網絡的輸出進行歸一化從而得到合理的經驗概率化權重
在與SAC 算法和TD3 算法結合后,LFIW 在大多數的Mujoco 環境中都展現出來優于PER 的性能.但其在更大規模的環境(例如Atari)中的表現有待進一步的實驗驗證.
基于TD error 的PER 算法和基于糾正性反饋的DisCor 算法都沒有直接針對RL 的目標最小化策略遺憾來進行經驗回放,而是采用其他的替代指標作為回放標準.經過大量的理論分析,Liu 等[58]提出了基于神經網絡的遺憾最小化經驗回放方法(Regret minimization experience replay using neural network,ReMERN),對以下幾種經驗在回放時賦予更高的權重: 1)具有更高的事后貝爾曼誤差的經驗;2)與當前策略更一致的經驗(LFIW 算法的關注點);3)與真實的最優價值估計更接近的經驗;4)行動概率較小的經驗.在結合了DisCor和LFIW 算法的優點后,ReMERN 算法也分別使用了兩個參數為?和ψ的神經網絡來估計Q 值的累計誤差和狀態–動作對的權重.ReMERN 算法中經驗的權重計算方式如下式所示
由于使用神經網絡來估計Q 值的累計誤差耗時較長且準確性難以保證,Liu 等[58]又提出了一種時間正確性估計的方法(Temporal correctness estimation,TCE)
在這種基于時序結構的遺憾最小化經驗回放方法(Regret minimization experience replay using temporal structure,ReMERT)中,經驗的權重計算方式變為
相較于DisCor、SUNRISE 和LFIW,ReMERN和ReMERT 較為全面地分析和證明了何種經驗具有較高的回放價值.除此之外,這兩種方法結合了多種經驗加權回放算法的優勢,是此類算法中目前較為成熟的算法.然而,由于對Q 值的累計誤差的估計方式不同,這兩種算法適用于不同類型的MDP.ReMERN 使用神經網絡來進行誤差估計,能夠適用于多種不同的環境,具有較強的魯棒性.而Re-MERT 在一些目標位置隨機的環境中,所提供的優先級權重差異性較大,從而可能對策略的收斂產生誤導,但其估計方式的簡便性仍是其不可忽略的優勢.
2.1.3 經驗分類回放
智能體與環境的大量交互經驗具有不同的特征,設定不同的指標(分類標準)來對經驗進行分類存儲和回放也是一種提升經驗利用效率的有效途徑.
經驗池中存儲的經驗是在不同的訓練階段產生的,Zhang 等[59]首先以經驗的新鮮程度為標準進行了嘗試,設計了時間復雜度為 O (1)的聯合經驗回放(Combined experience replay,CER)采樣方法,在智能體學習時將當前時間步的經驗與采樣的批量經驗相結合來研究當前經驗對算法性能的影響.在不同環境的測試實驗中,CER 可以有效減輕大規模經驗池所產生的消極影響,展現了強大的效率和穩定性.
由于CER 僅對最新的經驗(當前經驗)進行了回放,而沒有對這些基于最新策略產生的最新經驗進行充分利用.針對這一問題,Hu 等[54]從理論和實驗的角度分別驗證了最新經驗對于智能體策略收斂的重要性.他們所設計的ACER 算法根據經驗的新鮮程度設計了一個小容量的FIFO 臨時經驗池暫存最新的交互經驗.在采樣時,ACER 則將臨時池中的經驗完全復制并與原經驗池中優先采樣的經驗結合共同構成采樣的批量經驗,供智能體更新策略.
與經驗的新鮮程度類似,Novati 等[60]從策略的角度將經驗池中經驗按照其與當前策略的差異程度分為近策略(Near-policy)和遠策略(Far-policy),并提出記憶與遺忘經驗回放算法(Remember and forget experience replay,ReFER).ReFER 通過只使用近策略的經驗來更新策略,并利用KL 散度來限制策略的變化程度,使網絡更新和目標策略的收斂更為穩定.通過與多種異策略RL 算法的結合,ReFER 可以在多種連續控制任務中加快策略的收斂速度,使算法的性能得到了明顯提升.
不同于上述算法,時圣苗等[61]根據經驗的TD error 和獎勵大小來對經驗進行分類存儲,提出了時間差分誤差分類(TD error classification,TDC)和獎勵分類(Reward classification,RC)兩種經驗分類方法.這兩種方法采用同一訓練架構,均設定了兩個相同大小的經驗池來存儲經驗,采樣時采用固定比例的靜態采樣方法.在與DDPG 算法結合后,TDC 和RC 均在連續控制任務中表現出較優的結果.然而在訓練初期,TD error 和獎勵值較大的經驗的數量相對較少,從而導致這些較優的經驗被多次重復學習,這可能會對算法的穩定性產生影響.
劉曉宇等[62]同樣以TD error 作為經驗權重,提出了動態優先級并發接入算法(Concurrent access algorithm with dynamic priority,CADP),將經驗按照TD error 進行分類存儲.與TDC 算法不同的是,CADP 采取了一種變化比例的動態采樣方式分別從不同經驗池進行采樣學習
受AER算法啟發,智能體的狀態也可以作為經驗的分類標準.Hu 等[49]提出了經驗分割算法(Experience pool split,EPS)來實現根據智能體狀態的不同對經驗進行分類存儲和利用.在訓練前,EPS 需要根據過往經驗的比例對經驗池進行分割.訓練時,EPS 根據所設定的基于場景的評價指標將交互經驗存入對應經驗池,并依據當前智能體狀態從對應經驗池中采樣進行訓練,在訓練后期再將分割的經驗池進行合并并打亂所有經驗的排列順序.然而在訓練的過程中,經驗的比例是不斷變化的,如何確定EPS 中使結果最優的經驗池分割比例仍有待進一步探究.
相較于難以實現的對所有經驗進行分類存儲,朱斐等[63]從智能體狀態安全性的角度只考慮探索失敗時的危險狀態對應的經驗,提出了一種基于雙深度網絡的安全深度強化學習算法(Dual deep network based secure DRL,DDN-SDRL).DDNSDRL 在經驗回放方面設計了危險樣本經驗池和安全樣本經驗池來對經驗進行分類存儲,并引入安全強化學習的概念定義了兩種危險狀態: 1)智能體在任務失敗時的狀態;2)智能體在任務失敗前的m個時間步狀態.DDN-SDRL 方法針對性地學習了危險狀態的經驗,智能體在這些危險狀態附近的行動策略會受到較大影響,從而避免陷入局部最優,有效地限制了智能體向危險狀態方向的探索.
如表3 所示,經驗分類回放的標準無非還是經驗優先回放類算法的優先性標準及其變體,使用較多的仍是基于策略的、基于TD error 的和基于狀態的.從本質上講,經驗分類回放就是按照經驗優先回放的標準對經驗進行分類存儲,在采樣時利用特定的策略從而實現對這些符合標準的經驗的優先回放.大多數的經驗分類回放算法采用多經驗池的架構來減小經驗優先回放類算法的采樣時間復雜度,但這個做法會引入一個動態或靜態的采樣策略,該策略的好壞將會對算法的效果產生巨大的影響.
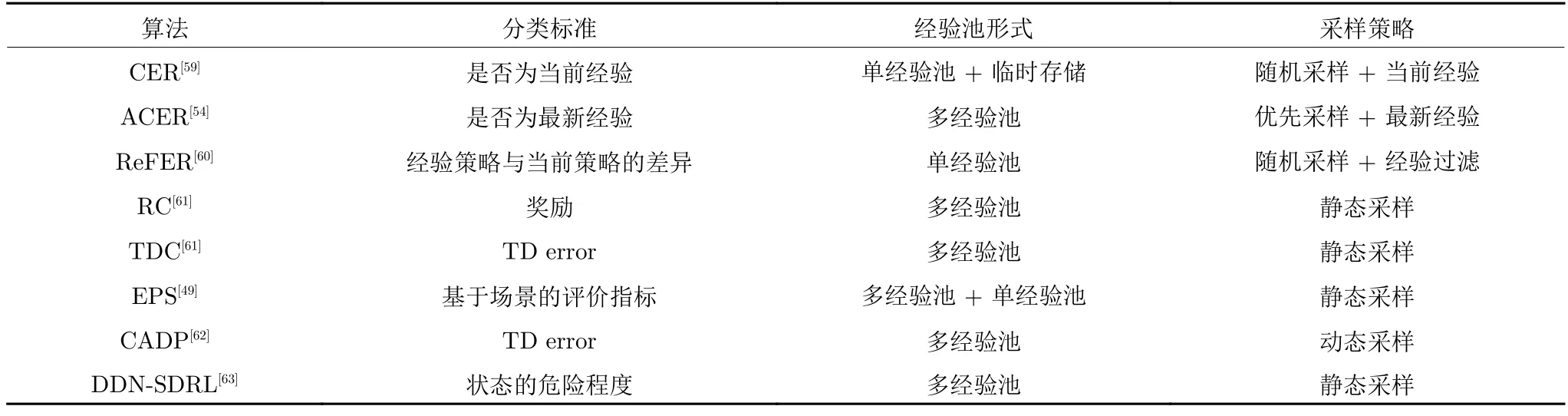
表3 經驗分類回放算法對比Table 3 Comparison of classification experience replay algorithms
2.1.4 經驗表示形式
在DRL 中,交互經驗 (si,ai,ri,si+1)通常是高維度的向量,使用大容量的經驗池存儲數以百萬計的經驗需要耗費大量的計算機內存.一些研究通過將向量形式的經驗轉換為其他的表示形式,從而實現對經驗更高效的存儲和利用.
Wei 等[64]創新性地將量子的一些特性引入到RL 中,來對經驗回放機制進行改進,提出了一種符合自然規律且易于使用的量子經驗回放方法(Quantum-inspired experience replay,QER).QER 通過將經驗轉換為量子化的表達,同時又對量子表達使用酉變化,使得RL 中容量為M的經驗池的狀態可以被表示為量子子系統張量積的形式
其中,|ψ(k)〉 為第k個經驗的量子表示形式.如圖7所示,QER 設計了準備操作和折舊操作兩種酉操作.準備操作可以使得量子化表達的經驗的概率幅與其TD error 相匹配,而折舊操作可以使同一經驗被多次重復學習的概率降低,使得采樣到的經驗更多樣化,回放更均勻.
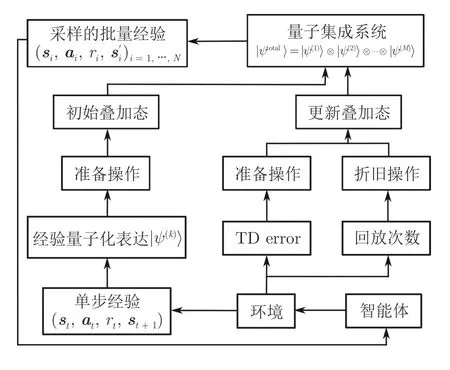
圖7 QER 的算法框架Fig.7 The framework of QER algorithm
在QER 的基礎上,Li 等[65]進行了更具有實際意義的探索.他們將無人機的導航任務映射到MDP上,考慮了時間成本和預期中斷持續時間的加權和的最小化問題,利用QER 制定了一種智能的無人機導航方法來幫助無人機在每個時間步內找到最佳飛行方向,并在復雜3D 環境任務中驗證了QER的有效性和穩定性.
Chen 等[66]設計了一種局部敏感性經驗回放算法(Locality-sensitive experience replay,LSER),該算法使用局部敏感的哈希法將RL 中的高維經驗映射到低維表示,解決了RL 應用于推薦系統時經驗維度過高的問題.除此之外,LSER 采用了一種狀態感知–獎勵驅動的采樣策略,即采樣與當前狀態位于同一哈希域中前N個具有最高獎勵值的經驗.LSER 可以高效地選擇所需要的經驗來訓練智能體,在多個仿真平臺的實驗中證明了其可行性以及相對于其他經驗回放方法的優越性.
對于經驗表示形式的相關研究相對較少,這是由于無論什么形式的經驗都需要被存儲,即使變換存儲形式來減小所需的內存空間,經驗的編碼和解碼也會對算法的效率產生一定的影響.除此之外,很難找到符合條件的一一映射來將高維經驗進行降維存儲,這也限制了此方向的進一步發展.
2.1.5 經驗存儲結構
設計良好的經驗存儲結構能夠更高效地實現大容量經驗池的存儲、更新和采樣等操作,這也是一種提升DRL 算法效率的有效途徑.
Schaul 等[43]在設計PER 算法時就考慮到了傳統數組或堆棧形式的數據結構在進行經驗優先利用時的過高的時間復雜度,設計了一種名為 “sumtree”的完全二叉樹的數據結構.如圖8 所示,“sumtree”的每一個葉子結點存儲的都是對應經驗的優先級,在采樣時遵循以下兩個步驟: 1)判斷當前節點是否為葉子節點,如果是,則當前節點是應該采樣的節點;2)比較輸入值與當前節點的左子節點的值.如果左子節點的值較大,則將左子節點設置為當前節點并重復步驟1),否則將右子節點設置為當前節點,并用輸入值與左子節點的值的差值替換輸入數據,然后重復步驟1).
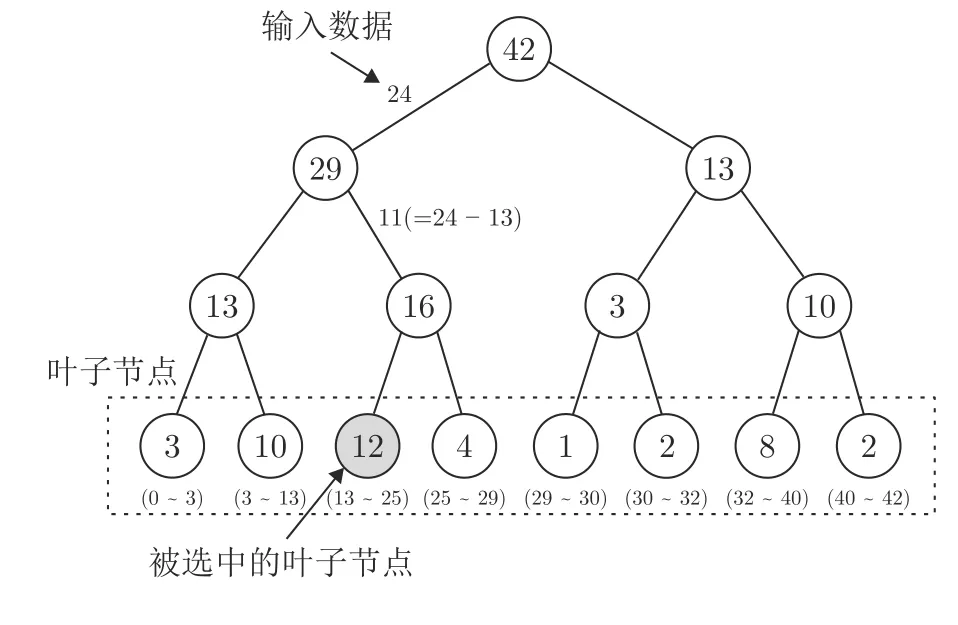
圖8 “sum-tree”采樣流程Fig.8 The sampling process of “sum-tree”
“sum-tree”的使用將采樣具有最大優先級的經驗和更新被采樣的批量經驗的優先級的時間復雜度分別降低至 O (1)和 O (log2N)(N為每次采樣的經驗數量),大幅降低了經驗選擇對算法運行速率的影響,有效地提升了PER 算法的效率.
Hu 等[54]提出的ACER 算法也在經驗池的數據結構上做出了改進.與PER 不同,他們認為當經驗池滿時,不應替換較古老的經驗而應該替換較無用的經驗,進而提出了一個先入無用出(First in useless out,FIUO)的數據結構 “double sum-tree”.
如圖9 所示,“double sum-tree”相較于 “sumtree”在每個葉子節點多存儲了對應經驗的優先級的倒數,使得經驗ei被替換的概率為
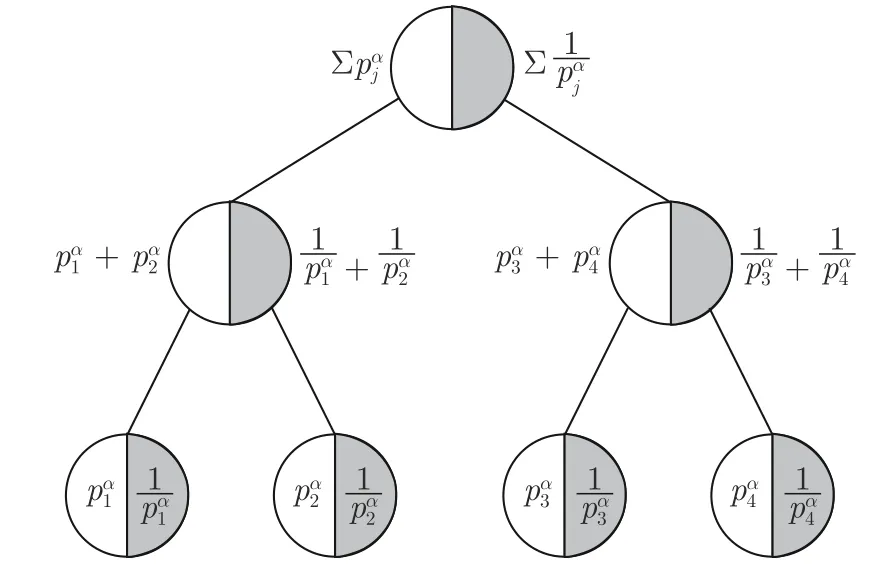
圖9 “double sum-tree”數據結構Fig.9 The data structure of “double sum-tree”
ACER 在每個時間步僅耗費了多于PER 算法O(log2N)的時間復雜度來更新優先級的倒數,這相較于其對算法性能的提升是可以被接受的.
類似地,Chen 等[66]提出的LSER 算法和Bruin 等[67]提出的基于分布的經驗保留算法(Distribution based experience retention,DER)也都嘗試從更新邏輯上對經驗進行改進.當經驗池滿時,LSER會優先替換經驗池中獎勵值較低的經驗,而DER則給出一種可以使得經驗池中的經驗保持在狀態–動作空間上近似均勻分布的方式來從經驗池中選擇經驗進行替換.然而,在不對數據結構進行改變的情況下,每一條新經驗的到來都需要在龐大的經驗池中篩選其要替換的經驗,這無疑會給算法的計算效率帶來巨大的壓力.
Li 等[68]則從硬件架構方面入手,使用了一種硬件–軟件協同的方法來設計基于關聯存儲器的優先經驗回放算法(Associative memory based PER,AMPER).AMPER 使用三元內容可尋址存儲器(Ternary content addressable memory,TCAM)取代了PER 一類算法中廣泛使用的較為耗時的基于樹結構遍歷的優先級采樣.除此之外,AMPER還使用了一種基于關聯存儲器的內存計算硬件架構,通過利用并行內存搜索操作來支持算法的運算.在文獻[68]所建議的硬件上運行時,AMPER 算法表現出與PER 算法相當的學習性能,同時實現了55~270 倍的延遲改進.
表4 給出了上述經驗回放算法在經驗存儲結構方面相較于傳統的經驗回放算法做出的優化.可以看到,目前大多數研究主要從數據結構、更新邏輯和硬件架構三個方面來對經驗池進行優化.除了傳統的FIFO 數據結構,目前經驗回放類算法最常使用的就是 “sum-tree”結構,而最近提出的 “double sum-tree”結構還未得到廣泛的認可和應用.經驗池的更新邏輯方面,除了傳統的經驗回放算法依據經驗的存儲時間進行更新,新的算法主要以TD error 和獎勵作為經驗被替換的標準.而AMPER首次從硬件的角度入手,為此方向的研究提供了一個新的思路.
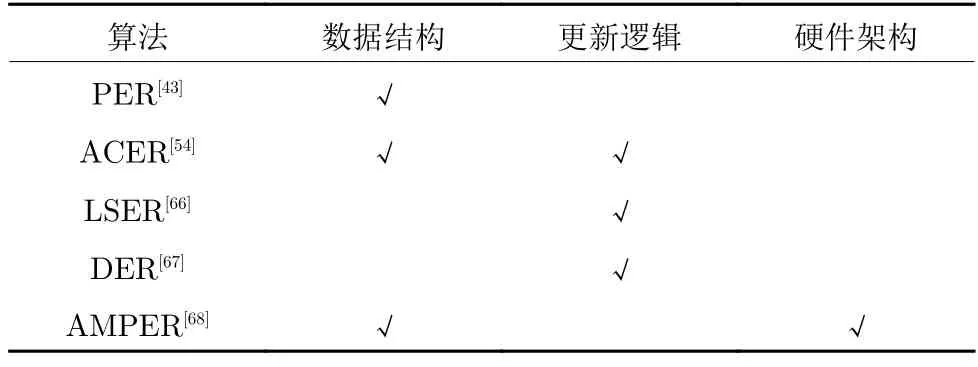
表4 經驗存儲結構算法的優化途徑Table 4 Optimization approaches of experience storage structure algorithms
2.2 經驗增廣
2.2.1 專家示范經驗
RL 算法通常需要大量數據才能使智能體獲得較為合理的策略.這對于在仿真平臺上的RL 任務來說也許是可以接受的,但這嚴重限制了RL 對許多實際任務的適用性.在RL 這種智能體從對環境一無所知經過不斷探索后找到最優策略的過程中,如果在訓練過程中能為智能體提供較為基礎可靠的行動策略,將大大減少智能體訓練前期的探索過程.一些研究者從經驗回放的角度使用模仿學習(Imitation learning,IL)[69-70]這種監督學習的思路將人類專家或其他來源的策略以不同形式的經驗記錄下來,以供智能體進行預訓練或在訓練過程中對智能體的策略進行修正和完善,從而改善RL 算法的性能.
Hester 等[71]從預訓練的角度提出了示范深度Q 學習(Deep Q-learning from demonstrations,DQfD).DQfD 的訓練分為預訓練和實際訓練兩個階段.在訓練開始前,先由人類專家在該游戲環境中操作3 到12 個回合來生成示范經驗.在訓練時,DQfD 會先根據人類的示范經驗進行固定回合的預訓練,隨后回歸原始的自主交互式的學習.實驗結果顯示,DQfD 在42 種視頻游戲中的14 種都超越了人類最佳的示范水平,并且在11 種游戲中取得了最先進的結果.然而這種利用專家示范經驗進行預訓練的算法,專家示范的經驗數量對其預訓練效果有很大影響,一般來說,專家經驗的數量越多,預訓練的效果就越好,其收集專家經驗所耗費的資源也就越多.
對于動作空間連續的任務場景,Vecerik 等[72]將這種專家示范的思路引入到了DDPG 算法中并設計了示范深度確定性策略梯度算法(DDPG from demonstrations,DDPGfD).與DQfD 不同,對于每一個任務,DDPGfD 都提前收集了100 個回合的人類示范經驗,并永久存入經驗池中以便后續學習.DDPGfD 使用經驗優先回放在示范經驗和交互經驗共同構成的經驗池中進行優先級排序,以一種自然的方式控制兩者之間的數據比例,其中經驗的優先級計算方法如下
其中,δ為TD error,ε是正向常數,εD是一個常數來增加示范經驗的優先級,λ是用來調整權重的常數,為作用于演員網絡的損失.在多種復雜度機械臂控制任務中,DDPGfD 不僅能夠很好地完成任務,并且能夠達到比人類示范更可靠的效果.
與DQfD 直接對網絡進行預訓練不同,Guillen-Perez 等[73]額外使用了一個名為 “Oracle”的演員網絡,在訓練時令 “Oracle”網絡直接從仿真平臺提供的示范經驗進行學習,并在每一次參數更新時對TD3 算法的演員網絡進行小規模的軟更新.這種從 “Oracle”示范中學習(Learning from Oracle demonstrations,LfOD)的方法在進行動作選擇時,智能體會按照一個隨訓練過程不斷變化的概率來選擇使用 “Oracle”或TD3 的演員網絡進行動作選擇.在經驗存儲方面,LfOD 有兩個規模不同的經驗池:Dimitation和Dreinforcement.Dimitation僅存儲由 “Oracle”選擇的動作產生的經驗,而Dreinforcement存儲所有演員網絡產生的經驗并使用PER 進行優先經驗回放.實驗表明,LfOD 能夠有效地提升RL 應用于自動路口管理(Autonomous intersection management)任務的效率.
Huang 等[74]提出的模仿專家經驗算法(Imitative expert priors,IEP)也通過訓練一個專家網絡來實現對專家策略的模仿,并通過正則化智能體策略πθ(·|si)與專家策略πE(·|si)之間的KL 散度來指導自動駕駛智能體的學習.IEP 提供了兩種不同的方式來實現智能體對專家經驗的充分學習:
1)對值函數添加懲罰項
2)在策略優化期間控制智能體策略與專家策略之間的偏差
實驗表明,使用這兩種方式的IEP 均能在多個城市駕駛場景中獲得最高的成功率,并能夠有效地表現出人類專家所展示的多樣化的駕駛行為,而對值函數添加懲罰項的IEP 算法在稀疏獎勵的場景中表現效果更優.
Hu 等[75]在處理無人機的運動控制問題時,設計了一個多經驗池算法(Multiple experience pool,MEP).MEP 通過使用模型預測控制(Model predictive control)來預測智能體在未來多個時間步的動作序列,并利用模擬退火算法(Simulated annealing)從預測結果中選擇最佳序列,從而利用傳統控制算法實現了對專家經驗的高效模擬.這種多經驗池的架構可以存儲多種不同來源的高質量經驗,使智能體可以在多種專家策略之間學習.但多種專家經驗之間的矛盾可能會給智能體策略的收斂造成困難,如何使智能體良好地平衡策略之間的差異性還有待進一步的研究.
Wan 等[76]則將這種使用其他算法來模擬專家經驗的思路應用到多智能體RL (Multi-agent RL,MARL)中,提出了一種混合經驗算法(Mixed experience,ME),并結合多智能體深度確定性策略梯度算法(Multi-agent DDPG,MADDPG)[77]在多無人車的運動規劃任務中展現了優越的效果.ME 算法通過一個基于人工勢場法(Artificial potential field)的經驗生成器在訓練時為智能體提供具有指導性的高質量經驗,并使用動態混合采樣的策略,以可變的比例混合來自不同來源的訓練經驗,來優化智能體的運動策略.
針對緊急情況下自主水下航行器在三維空間中的浮面控制問題,Zhang 等[78]提出了一種基于DDPG的無模型DRL 算法(Variable delay DDPG from demonstration,VD4).VD4 不僅使用與DQfD 類似的思路來利用專家示范經驗對目標網絡進行預訓練,還在實際訓練時按照比例對專家經驗和交互經驗進行采樣.這種做法有效地提升了算法的收斂速度,提高了應對對抗性攻擊時的魯棒性.除此之外,VD4 還采用了TD3 中的演員網絡延遲更新操作來提高算法的穩定性.在多種不同的復雜測試環境下,相較于DDPG、TD3 等算法,VD4 算法所訓練的智能體都能夠達到最高的任務成功率.
表5 對上述的專家示范經驗算法從專家經驗來源、作用方式、經驗池形式、采樣策略和算法應用場景進行了總結.總的來看,使用不同形式的專家示范來實現經驗的增廣能夠有效地提升DRL 算法的性能,尤其是在一些復雜的控制任務中.但由于專家示范時的思路或策略可能與智能體所學習的策略不同,甚至專家可能會使用一些智能體無法理解和表示的策略,這都會對智能體的策略收斂產生不利影響,如何縮小專家示范與交互經驗之間的差異性是在進行此方向研究時要考慮的主要問題.
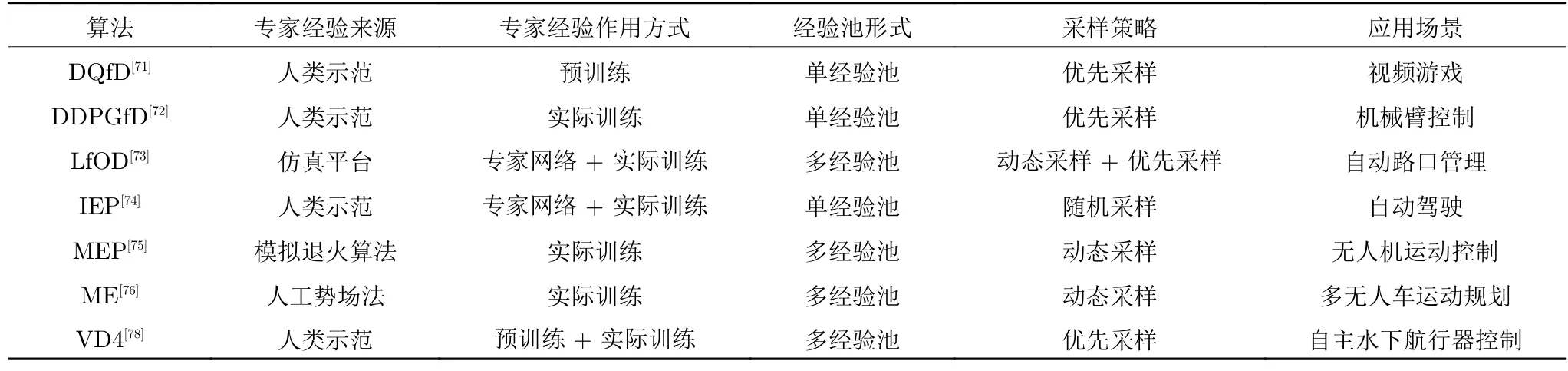
表5 專家示范經驗算法對比Table 5 Comparison of expert demonstration experience algorithms
2.2.2 模型經驗增廣
環境在RL 中主要起到根據智能體動作進行狀態轉移并給予其反饋的作用.一些研究者通過在RL 訓練過程中構建一個合理的環境模型來實現對環境的模擬.如圖10 所示,這類基于模型的經驗增廣方法在原始的RL 循環(虛線內所示)外增添了環境模型的訓練過程,在環境模型的準確性能夠保證的情況下,可以使智能體在與環境模型的交互過程中輕松獲得大量高質量經驗,從而實現策略的快速收斂.
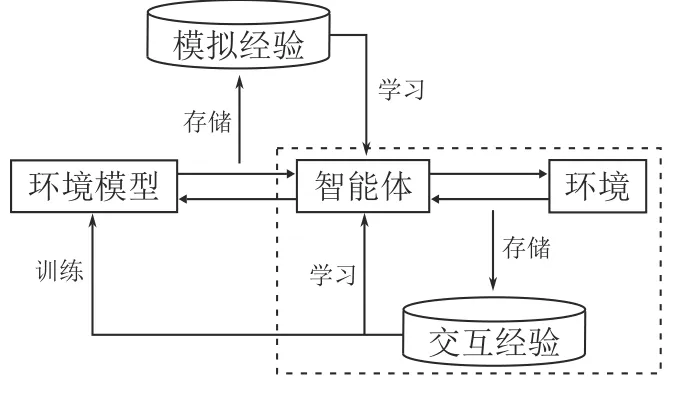
圖10 模型經驗增廣算法的框架圖Fig.10 The framework of model experience augmentation algorithms
Sutton 等[79]最先將建立環境模型的想法引入到Q-learning 算法中并提出了Dyna-Q 算法.在Dyna-Q 中,智能體與環境的在線交互經驗不僅用于智能體策略的更新,還用于環境模型的訓練.Dyna-Q 使用了一種Q-planning 的方法來隨機生成多個之前經歷過的狀態和在該狀態下執行過的動作作為輸入,與環境模型的輸出共同構成模擬經驗來更新狀態–動作值函數,從而實現經驗的增廣,使得智能體在實際任務中能夠獲得更優的策略.
Silver 等[80]在Dyna-Q 的基礎上進一步探索,提出了具有SARSA 算法的更新機制、永久和瞬態記憶以及線性函數逼近的Dyna-2 算法.Dyna-2 將Q 函數分為永久記憶Q(s,a)和瞬態記憶Q′(s,a).永久記憶根據智能體的交互經驗進行更新,而瞬態記憶則在與模型的模擬過程中得到更新來形成對永久記憶的局部校正.在每次動作選擇前,智能體會根據環境模型執行一個從當前狀態持續到回合結束的模擬過程,隨后根據完整的Q 值選擇動作
針對Dyna-Q 在生成模擬經驗時隨機性過大的問題,Santos 等[81]提出了一種結合啟發式搜索的算法框架 D yna-H.D yna-H設計了一個啟發式規劃模塊H,通過計算狀態s′與目標位置goal之間的歐氏距離來評價在狀態s下所選擇的動作a的好壞
其中,s′是環境模型給出的下一時刻狀態.在模型訓練時,D yna-H根據H選擇啟發式的動作ha來構成模擬經驗
實驗表明,相對于Dyna-Q,D yna-H是一種效率更高的算法,尤其適用于最優路徑搜索這一類決策問題.
針對在生成模擬經驗時搜索控制的局限性,Pan等[82]提出了一種爬山Dyna (Hill climbing Dyna,HC-Dyna).HC-Dyna 在學習到的值函數上使用了一種噪聲不變的投影梯度上升策略的爬山法來生成模擬經驗,并引入了一個閾值來保證模擬經驗之間的差異性,從而使智能體能夠提前更新其接下來可能訪問的區域.HC-Dyna 還使用了一種經驗混合機制,將搜索控制產生的模擬經驗和交互產生的真實經驗按比例采樣,共同用于智能體策略的更新.在多個Atari 游戲場景的實驗中,HC-Dyna 都顯示了優于DQN 的性能.
除了模擬經驗的質量,Dyna 框架中模擬經驗的使用順序也很重要.Pan 等[83]在研究了不同經驗的重要性后,引入了一種重加權經驗模型(Reweighted experience models,REM)的半參數模型學習方法來調整模擬經驗的使用順序.REM 具有以下幾個優勢: 1)可以快速地選擇和采樣某個經驗的前序或后序經驗;2)包含需要學習的參數較少,數據高效性較強;3)可以提供足夠的模型復雜性.實驗表明,REM 可以高效地使用模擬經驗和交互經驗.更進一步的探索表明,相較于線性模型和神經網絡模型,REM 是更適合Dyna 框架的模型.
構建環境模型能夠在減少智能體與環境交互的情況下產生大量的模擬經驗.從早期的 D yna-H到近幾年所提出的HC-Dyna,如何產生更優的經驗一直是此領域研究所關注的重點.REM 算法則對Dyna 框架下模擬經驗的利用順序進行了探索,為模型經驗增廣提供了一個新的研究方向.
2.2.3 事后經驗回放
除了上述通過智能體與環境交互過程外部提供增廣經驗的方式,一些研究者希望通過交互過程本身而不引入其他經驗來源的方式實現經驗的增廣.
Andrychowicz 等[84]創新性地提出了事后經驗回放(Hindsight experience replay,HER).作為一種多目標RL (Multi-goal RL,MGRL)[85]的方法,HER 在動作選擇和反饋獎勵時需要同時參考狀態s和目標g.對于要重塑的經驗 (st‖g,at,rt,st+1‖g),首先根據特定方法選擇附加目標g′,隨后根據附加目標評價在狀態st下動作at的好壞并獲取新的獎勵值從而構成一個新的經驗用于后續的采樣和訓練.HER 通過對過去經驗進行重塑,顯著地提高了稀疏獎勵環境中高質量經驗的百分比,從而加速了智能體的訓練過程.由于在任務中使用了固定的獎勵函數,HER 可以保證事后產生增廣經驗的高質量,并確保智能體收斂策略的統一性.
為了克服HER 基于均勻采樣來生成附加目標的局限性,Luu 等[86]提出了事后目標排名算法(Hindsight goal ranking,HGR).基于TD error,HGR使用了兩種優先化操作,即回合優先和目標優先
為了能夠使HER 算法適用于動態目標問題,Fang 等[87]提出了動態事后經驗回放算法(Dynamic hindsight experience replay,DHER).DHER 設計了一個存儲器來存儲所有的失敗回合.在回放時,DHER 會搜索滿足的兩條相匹配的失敗軌跡Ei和Ej(),其中是在回合i中時間步p時智能體的位置,是在回合j中時間步q時目標的位置.隨后將使用替換Ei中原始的目標位置,其中t≤min{p,q}來保證新生成的成功回合中的目標軌跡和智能體軌跡長度相等.
DHER 在處理動態目標問題時取得了很好的效果,但它仍然存在以下幾個缺點: 1)失敗的回合經驗的存儲需要大量的計算機內存;2)在存儲的失敗經驗中搜索和匹配的時間復雜度巨大;3)在高維連續狀態空間環境中很難找到兩條匹配的失敗軌跡;4)并非所有的增廣經驗都值得被存儲和學習;5)無法保證存儲在龐大經驗池中的增廣經驗可以被學習到.針對這些問題,Hu 等[88]提出了想象過濾事后經驗回放(Imaginary filtered hindsight experience replay,IFHER).IFHER 通過合理想象失敗回合中的目標軌跡來生成成功回合
從附加目標多樣性的角度出發,Fang 等[89]提出了一種課程指導的事后經驗回放算法(Curriculum-guided hindsight experience replay,CHER),通過對失敗經驗自適應地選擇來動態控制探索與利用的平衡.CHER 設計了如下的效用得分函數來評估附加目標優劣
其中,s im(·,·)是距離函數,用來估計兩個目標之間的相似性,A是采樣的批量大小,B是整個經驗池.前一項衡量了附加目標與真實目標的接近程度,后一項衡量了附加目標的多樣性.在訓練過程中,CHER逐漸增加權重λ的大小,在早期的訓練階段強制學習目標更多樣的經驗,并逐漸更改學習目標更接近真實目標的經驗.實驗結果表明,在多種具有挑戰性的機器人環境中,CHER 都可以進一步提升當前最優算法的表現.
Yang 等[90]則將環境模型引入HER,并提出了模型事后經驗回放算法(Model-based hindsight experience replay,MHER).在為經驗(st‖g,at,rt,st+1‖g)選擇附加目標時,MHER 會先使用環境模型根據狀態st向前進行n個時間步的模擬,隨后從這些狀態中選擇附加目標進行經驗重塑.MHER 主要具有以下幾個優勢: 1)通過模型交互產生的附加目標不再局限于真實經驗;2)附加目標的生成遵循一種策略指導的高效課程;3)策略更新同時利用了強化學習和監督學習.在多種連續的多目標任務中的實驗表明,MHER 具有優于HER 和CHER的樣本效率.
事后經驗回放發展至今,從HER 的均勻采樣,到HGR 基于TD error 的采樣,再到目前基于課程和基于模型采樣的CHER 和MHER,如何為一條失敗的軌跡確定附加目標始終是研究者們關注的重點.采用特定的策略、選擇合適的附加目標,從而生成高質量的增廣經驗來提升算法的效率在今后依然會是此類方法的主要研究目標.
3 總結與展望
RL 通過智能體與環境的交互過程不斷獲取經驗,來優化智能體自身的行動策略以期獲得最大的累積獎勵.作為一種數據驅動的機器學習算法,經驗(數據)決定了RL 智能體最終策略的優劣.在異策略RL 中,經驗池的存在造就了經驗回放這一研究熱點.通過經驗回放,智能體能夠按照需求合理利用多來源的經驗,避免災難性遺忘的發生,更快地得到更優的行動策略,減小訓練過程中的成本代價.因此,對經驗回放機制進行研究有著十分重要的實際意義和發展前景.本文從RL 的基礎知識出發,介紹了常用的異策略RL 算法,并從經驗利用和經驗增廣兩個角度對經驗回放機制的相關研究進行了詳細的介紹和總結,彌補了國內相關研究領域的空缺.
現有的經驗回放方法已經取得了初步的成果,理論和實踐都證明了經驗回放對于異策略RL 的重要性,但其仍面臨著一些問題和挑戰.
1)算法的適用性: 很多算法過分關注于某類問題而局限了其適用范圍.而且大量的算法使用了神經網絡或引入了大量的超參數,參數敏感性無疑會影響經驗回放算法對不同環境的適用效果.除此之外,作為RL 的一個模塊,經驗回放算法同樣面臨著虛擬到現實的落地困難的窘境.
2)算法的可解釋性: RL 作為人工智能領域的一個研究方向,毫無疑問在經驗回放的研究過程中,會有很多思路和設計來源于對人類或其他物種的行為模擬.然而,這些所謂移植性創新往往缺乏可靠的理論支撐,可解釋性較差,有時難以讓人信服.
3)算法的效率: 無論是在數以百萬計的經驗池中進行篩選或排序,還是從無到有地增廣數以百萬計的經驗,經驗回放算法的運算效率始終面臨著嚴峻的考驗.
針對上述問題,本文仍從經驗利用和經驗增廣兩個方面分別指出各個方向可能的突破口,為相關領域的學者提供一些研究思路.
在經驗利用方面:
1)經驗優先利用標準: 除了已得到廣泛認可的TD error 常用來作為經驗優先利用的標準外,經驗與當前狀態的相似性、經驗難度等指標也逐漸被應用于各種RL 控制問題中.調整智能體對經驗池中所存儲的經驗的學習順序,在不同的訓練階段使得最適合當前智能體策略更新的經驗被學習,仍然是一種提高RL 效率的有效辦法[51].除了上述的優先標準,將其他領域例如人類教育學、心理學或者生物學的知識或現象進行建模,設計出普適于多種任務環境的參數不敏感的優先回放標準仍是經驗回放領域今后研究的重點.
2)經驗加權回放的適用性: 經驗加權回放是近幾年經驗回放領域新興的研究方向,相關的研究還相對較少.目前較為成熟的算法還難以簡便、準確地應用于所有的實驗環境.因此,設計更具有普適性且計算更為簡潔的經驗加權回放方法仍是現階段需要主要考慮的問題[58].除此之外,由于發展時間較短,還尚未有研究將此類方法延伸于真實的應用環境,其在真實環境中是否仍具有較好的效果還有待進一步研究.
3)經驗池的結構設計: 隨著任務復雜程度的提升,經驗池的規模也在不斷擴大,經驗池的結構設計面臨著巨大的壓力.通過改變原有數組形式的存儲結構,采用樹、隊列、堆棧甚至于圖等數據結構來構建經驗池,能在降低計算機內存消耗的同時提升算法的采樣效率.合理設計經驗池的更新邏輯也能夠充分發揮各種經驗優先利用算法的優勢[54].除此之外,對計算機的硬件架構進行針對性的設計也是進一步提升經驗回放算法效率的有效途徑.
4)經驗的表示形式及轉換效率: 利用其他領域例如量子力學的理論,將原始向量形式的經驗進行編碼,隨后進行存儲.在使用時也可以結合不同的優先利用算法來進行優先采樣,將采樣后的經驗重新解碼以便智能體進行學習.這種從經驗的表示形式入手的方法也是近年來經驗回放領域的一個新興研究方向,具有一定的研究價值.但這種先編碼后解碼的過程需要耗費一定的計算資源,如何提升經驗編碼和解碼的效率是此類方法需要考慮的重點.
在經驗增廣方面:
1)多來源數據的準確性: 在處理較為復雜任務時,結合不同來源的指導經驗進行學習可以大幅減少智能體與環境的交互,提升算法的收斂速度.但如何確保其他數據的準確性和有效性是此研究方向不可避免的問題.專家經驗通常是基于專家自身實際操作經驗,智能體的交互經驗是在獎勵函數的指導下產生的.專家經驗與交互經驗所蘊含的策略的統一性,將在很大程度上影響智能體的表現[49].環境模型也是在智能體訓練過程中不斷優化的,其收斂速度直接導致了智能體用于訓練的模擬經驗的準確性[79].如何設計更準確的模型結構并提升模型的收斂速度是此方向需要長期關注的問題.
2)經驗重塑算法的效率: 在固定獎勵函數的情況下,對智能體自身的交互經驗進行重塑以實現經驗的大規模增廣是經驗回放領域近年來的研究熱點.附加經驗的準確性和策略一致性保證了收斂后智能體優秀的性能.在龐大的經驗中選擇合適的附加目標以期產生高質量的附加經驗仍然是此類方法關注的重點.但毫無疑問,大規模的搜索和重塑會對算法的計算效率產生影響[88],使用多線程進行并行計算或設計其他高效的計算框架或許是經驗重塑類方法提升效率的有效途徑.
猜你喜歡
黨課參考(2021年20期)2021-11-04 09:39:46
小哥白尼(軍事科學)(2019年6期)2019-03-14 05:49:56
文苑(2018年23期)2018-12-14 01:06:06
黨課參考(2018年20期)2018-11-09 08:52:36
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
