基于隨機森林的抗乳腺癌候選藥物的優化
2023-12-02 15:26:28湯仕星曾瑩
湖北工業大學學報 2023年1期
湯仕星 曾瑩
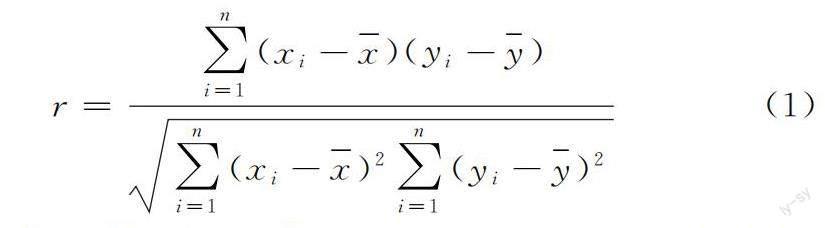
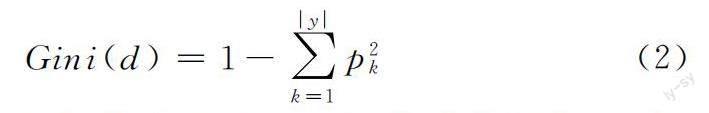
[摘 要]充分利用藥物大數據平臺和臨床資源,運用數據分析方法預測抗乳腺癌候選藥物的ADMET性質和抗乳腺癌活性,為實驗室研制抗乳腺癌新藥過程提供參考方向。針對1974種化合物的分子描述符變量數據,分別構建以ADMET性質和pIC50值為因變量的隨機森林預測模型,模型的預測精度分別為88.7%和91.3%。基于隨機森林模型求得的重要影響因子貢獻率確定出4個變化顯著的共同重要影響因子的取值范圍,分別為MLFER_BH(0.56,2.65)、MLFER_S(1.30,4.41)、WTPT-5(0.00,10.01)和SdssC(-1.92,2.76),對實現抗乳腺癌藥物的優化具有指導意義。
[關鍵詞]抗乳腺癌藥物;抗乳腺癌活性;ADMET性質;相關性檢驗;隨機森林
[中圖分類號]F213.5 [文獻標識碼]A
乳腺癌是指在多種致癌因子的作用下,乳腺的上皮細胞發生增值失控的一種現象,是目前世界上最常見的致死率較高的癌癥之一。對于治療乳腺癌的藥物研究,國內外已有不少學者在乳腺癌分子靶點和靶向治療方向上取得顯著進展,已發現不少抗乳腺癌活性表現良好的化合物,且在臨床實踐中取得明顯療效[1],例如查耳酮類化合物、他莫昔芬和雷諾昔芬;靶向治療的優越性在于能在細胞分子水平上基因調控,代謝通路,某一靶點特異性結合而達到治療作用,最終導致部分癌基因表達失調、腫瘤增殖減弱、受體表達缺失等。特別是雌激素受體α亞型(ERα)作為乳腺癌內分泌療法的主要靶點[2],在超過70%的乳腺癌患者[3-5]中過度表達,因此拮抗ERα活性的化合物可能是治療乳腺癌的候選藥物。
近年來隨著藥物大數據平臺的實現,豐富的原始臨床試驗數據[6]為構建化合物的定量結構-活性關系奠定了數據基礎,不少學者在研究治療乳腺癌過程中運用數據挖掘方法得到重要結論。例如秦璞應用隨機森林和支持向量機對三陰性乳腺癌基因數據的降維和篩選[7],得到部分基因和三陰性乳腺癌的轉移或者預后有相關性等;隨著抗乳腺癌藥物的生物活性被逐漸深入研究,評價抗乳腺癌藥物的副作用的研究也越發受到關注,例如魏靜通過實驗研究得到羧甲基β-葡聚糖聯合阿霉素具有協同抗乳腺癌以及減輕心臟毒性的功能[8]。國內外學者研究表明藥效性和藥代動力學的研究可以為新藥研發提供指導,進而優化藥方設計,通過將其與藥物的靶點、理化性質等各方面信息相結合,可以發現其中存在的客觀規律,為藥物研究提供新思路。
隨機森林是基于分類回歸樹的集成算法[9]。對于海量數據的研究,區別于傳統的多元線性回歸模型[10],隨機森林算法在處理回歸問題時能夠克服協變量之間復雜的交互作用,且毋需預先設定函數形式[11],相較于神經網絡[12],隨機森林算法在處理分類問題時不易過度擬合,因而隨機森林算法被廣泛應用于各領域研究并取得較好效果,為此將隨機森林模型應用于拮抗ERα活性的抗乳腺候選藥物的ADMET性質的研究。相較于國內外學者通過臨床試驗探求新藥的藥效性的同時還要對新藥的副作用進行驗證的漫長過程,構建隨機森林預測模型,充分挖掘臨床試驗數據的內在價值,不僅能更準確得到化合物的ADMET性質和生物活性,而且可以篩選出能共同影響化合物ADMET性質和生物活性的重要因子,進而優化抗乳腺癌候選藥物的篩選過程,為尋求潛在的優質抗乳腺癌藥物提供實證研究。
1 模型和數據
從阿爾伯塔大學的DrugBank藥物分子數據庫中獲取針對ERα靶點的化合物樣本集[13]。DrugBank數據庫擁有獨特的生物信息學和化學信息學資源,它將詳細的藥物數據和全面的藥物目標信息結合起來,以便科學家們研究藥物機制和探索新型藥物[14]。數據集包含了1974個化合物樣本,并給出了每個化合物的SMILES式,每個化合物樣本都有729個分子描述符變量,1個生物活性數據(IC50為測定值、pIC50為轉化值)和5個ADMET性質數據(Caco-2、CYP3A4、hERG、HOB和MN)。
1.1 符號說明
Erα:雌激素受體α亞型;IC50:ERα的生物活性值(值越小代表生物活性越大,對抑制ERα活性越有效);pIC50:IC50值轉化而得的ERα的生物活性指標(與生物活性具有正相關性);ADMET:藥代動力學性質和安全性;Caco-2:小腸上皮細胞滲透性;CYP3A4:細胞色素P450酶(Cytochrome P450, CYP)3A4亞型;hERG:化合物心臟安全性評價;HOB:人體口服生物利用度;MN:微核試驗。
1.2 模型設定
1.2.1 相關性檢驗 本文采用皮爾遜相關系數[15]判斷不同的變量之間的相關程度,其公式為:
其中:n代表樣本的個數,xi,yi分別表示兩個變量的第i個樣本值,相關系數r的取值范圍為[-1,1]。r值越大,表示其相關性越強,當r>0,表示兩個變量間呈現正相關,r<0,表示兩個變量為負相關。
1.2.2 隨機森林 決策樹是一種基于IF-then-else規則的算法,屬于有監督學習算法[16]。它是一種樹形的結構,每個節點表示其一個樹形上的判斷,每個分支表示其一個判斷結果的輸出,它是根據基尼系數通過訓練數據統計而得到的。基尼系數的大小代表數據集中樣本的差異程度大小,基尼系數越大說明數據集的種類越多,即說明有多種的分類結果。其計算公式為:
決策樹的缺點就是可能會對訓練的數據過擬合,而隨機森林通過構造很多棵樹的方式,在得知每棵樹的預測結果的情況下,綜合分析每棵樹的分類和回歸預測結果,不僅可以減少過擬合,而且還能很好的保持樹的預測效果。
1.3 數據準備
1.3.1 數據預處理 對分子描述符變量值進行初步的分析發現:樣本集中數據不存在缺失值,除了化合物的SMILES屬性是字符型外,其他字段的變量都是數值型且有明確含義,數據是完備的。依據相關性檢驗,通過R軟件循環遍歷求出pIC50指標與729個變量的相關系數,發現存在225個缺失值,即有225個分子描述符變量的取值全為零,可認為其包含有用信息的可能性較少,這些分子描述符的變量值在化合物樣本的分類和回歸問題無區分度。考慮到隨機森林會出現樹的冗余現象,為提高算法的計算效率,數據處理時剔除這些無差別的變量,將剩余的504個變量組成一個新訓練集。
1.3.2 確定IC50和pIC50函數關系 為了保持生物活性指標與生物活性具有正相關關系,通常將實驗測定值IC50通過對數變換進而轉換為pIC50值來表示生物活性的強弱,IC50值越小,表明生物活性越強,進而pIC50值越大,實際中它們滿足一種特定的函數關系,因此本文引進中間變量ln(IC50)來對數據進行分析,求得ln(IC50)和pIC50的相關系數為-1,證實了pIC50和IC50的負對數滿足確定的函數關系。利用R軟件對兩者進行線性擬合,求得pIC50=-0.4343*ln(IC50)+9,因此可將pIC50作為生物活性指標用于新化合物抗乳腺癌活性的預測,進而也可通過預測出的pIC50值求出IC50實驗測定值。
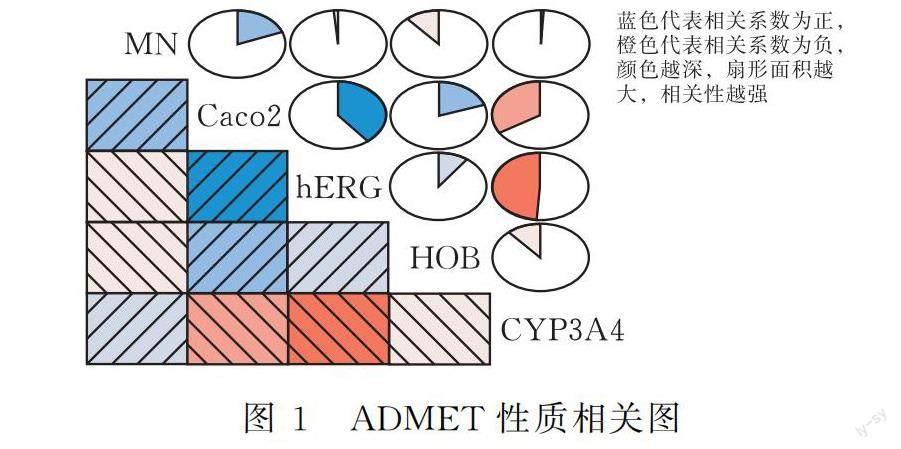
1.3.3 ADMET性質相關性 在化合物樣本的ADMET性質數據中,分類變量hERG與MN用“1”表示具有毒性,“0”則表示沒有毒性,這與其他3種性質分類變量數據表示的一致性相反,與意識中認為的“1”代表性質好,“0”代表性質劣的邏輯相反,于是先對分類變量hERG與MN進行重編碼。在R軟件中將hERG與MN的數據重新賦值,將原始數據中的“1”賦值為“-1”,再將hERG與MN的全部數據進行加1操作,使得hERG與MN性質數據中原有的“1”轉化為“0”,“0”轉化為“1”,于是ADMET性質可同趨勢化。然后可以求出ADMET性質兩兩之間的相關關系,并在R軟件中畫出ADMET性質相關圖(圖1)。
從圖1中可以看出Caco-2與hERG(0.393)、HOB(0.201)、MN(0.190)之間都存在較弱的正相關性,而CYP3A4與hERG(-0.487)、Caco-2(-0.337)和HOB(-0.113)之間都存在較弱的負相關性,MN與hERG(-0.019)和CYP3A4(-0.010)之間的相關性很小,這使得化合物同時滿足ADMET性質最優的情況較少,藥代動力學性質和安全性之間很難達到最優。于是可對每個樣本的5種ADMET性質變量進行求和,將其記為化合物的ADMET性質得分,ADMET性質得分越高,代表化合物的藥代動力學性質和安全性越好。
在1974個化合物樣本中ADMET性質得分為3的樣本有444個,得分為4的樣本有177個,ADMET性質最優即得分5的樣本個數僅為11,再求出pIC50和ADMET性質得分的相關系數為-0.261,存在弱負相關性,符合現實中藥效性和藥代動力學性質與安全性俱佳的化合物很少的現象。為了擴大候選藥物的篩選范圍,將ADMET性質得分大于等于3定義為ADMET性質較優的化合物并記為“1”,ADMET性質得分小于3定義為ADMET性質較差的化合物并記為“0”,使得將ADMET性質得分二分類。
2 實證分析
2.1 隨機森林分類
為了判定不同化合物的藥代動力學性質和安全性,用于對抗乳腺癌藥物的副作用研究,對于新藥的生產提供可參考性建議。將基于化合物的分子描述符變量構成訓練得到隨機森林分類器用于對化合物的藥代動力學性質和安全性的判定,進而篩選出ADMET性質得分更高的化合物,并尋找出影響ADMET性質得分的重要因子。
對于剔除無差別變量后的數據,在R軟件中分別構建5種分類變量ADMET性質與504個分子描述符變量的隨機森林分類模型,采用默認棵數500,隨機抽取90%的樣本作為訓練集,對分類器進行訓練,剩下10%的樣本作為測試集用于對模型的評估,分別計算出模型的預測精度。為減小隨機因素的影響,再采用R軟件中的ipred包的errorest函數進行10折交叉驗證,用于計算分類模型的錯分率,進而可判斷出隨機森林分類器的效果(表1)。
表1結果顯示,5個隨機森林分類模型的預測精度都在85%以上,最高精度達到96%,模型的錯分率大部分在10%以內,因此可認為隨機森林分類模型的分類準確率都較高,模型具有可行性。
為了尋找出對ADMET性質影響更重要的分子描述符變量,結合ADMET性質得分的優劣,隨機森林分類預測模型也可應用于二分類后的ADMET性質得分。考慮到影響ADMET性質得分的因素的復雜性,設置決策樹的棵數為1000,將訓練后的模型用于測試集的分類預測,然后畫出隨機森林預測ADMET性質得分效果圖(圖2)。
通過繪制模型的均方誤差圖和ROC曲線可見,將ADMET性質較差的化合物錯判成ADMET性質較好的錯誤率為7.94%,將ADMET性質較好的化合物錯判成ADMET性質較差的錯誤率為26.7%,AUC=0.854,95%的置信區間為(0.746,0.962),計算得到模型的錯分率為13.9%,預測精度為88.7%。較單個分類模型預測效果有所下降,可能是因為ADMET性質之間的相關性,造成現有的樣本數據的價值信息不足,進而提高了錯分率。
2.2 隨機森林回歸
隨機森林作為集成學習常用的模型,通過建立多個決策樹不僅可以用于解決分類預測問題,也常用于解決回歸預測問題,且模型的準確率較高。將基于化合物分子描述符構成數據訓練得到的隨機森林預測模型用于對化合物抗乳腺癌活性的檢測,便于篩選出生物活性更好的化合物作為抗乳腺癌候選藥物,并找出影響抗乳腺癌活性的重要分子描述符。
針對含有504個不同分子描述符變量和pIC50值的數據集,隨機將1974個樣本平均分成10份,取出9份用于隨機森林預測模型的訓練,另外1份作為用于評估模型預測精度的測試集。通過R軟件構建以pIC50值為因變量的隨機森林預測模型,將訓練后的模型用于測試集的預測,然后畫出隨機森林回歸模型的預測效果圖(圖3)。
從圖3可以看出真實值與預測值的散點均勻分布在y=x直線的兩側,且散點在一個狹長的范圍內;通過真實值和預測值的數據概況可以發現,真實值的分布相對均勻,適合作為測試集代表一般預測樣本,預測值的均值和真實值的中位數大致相等,分布相對真實值更為集中,這和隨機森林在同一類樣本中取特征的平均值作為輸出有關。通過R軟件計算可知預測值與真實值之間的相關系數為0.913,在訓練數據變量如此之多和測試集預測樣本較大的情況下,可解釋性方差還能達到75.73%,殘差平方均值為0.507,相對多元線性回歸模型的預測準確率好很多,因此認為隨機森林用于抗乳腺癌活性的檢測是有效的,具有一定的優越性。
2.3 隨機森林優化
為了尋找出藥效性良好同時具有良好的藥代動力學性質和安全性的候選藥物,即在化合物保持抗乳腺癌活性良好的同時具有更高的ADMET性質得分。需要找到能共同影響生物活性pIC50值和ADMET性質得分的重要因子,而隨機森林在預測pIC50值的同時可根據分子描述符變量的可解釋性方差的大小計算出各變量的貢獻率,在處理ADMET性質得分的分類問題時,可根據各個分子描述符變量的袋外誤差率與原誤差率的差值大小計算出分子描述符變量的重要程度。依據上述研究,通過隨機森林模型可分別求出影響pIC50值大小和ADMET性質得分排名的前30個重要影響因子,利用R畫出重要影響因子曲線圖(圖4)。
由圖4可以發現:在影響pIC50值和ADMET性質得分的前30個重要變量中,能共同顯著影響pIC50和ADMET性質得分的變量共有9個,分別是MLFER_BH、MLFER_S、ETA_Shape_Y、minHBa、MDEC-33、VCH-7、ATSc2、WTPT-5和SdssC。
為了進一步優化候選藥物的篩選,可參考化合物在共同重要影響因子上的表達,劃定共同重要影響因子的取值范圍作為候選藥物的基本條件。可在研究治療乳腺癌候選藥物時充分利用藥物大數據平臺和臨床資源,大大節省人力和物力成本,而劃定共同重要影響因子的取值范圍顯得尤為重要。
確定共同重要影響因子的取值范圍需要滿足分子描述符變量在化合物樣本中顯著表達的特征,于是設定在所有化合物樣本中抗乳腺癌活性排名前25%且藥代動力學性質和安全性較好的化合物屬于優質抗乳腺癌候選藥物。通過判斷pIC50值是否大于上四分位數7.57和ADMET得分是否大于等于3,篩選出69個優質抗乳腺癌候選藥物,對比優質抗乳腺癌候選藥物和總體化合物樣本在共同重要影響因子上的取值范圍。發現優質抗乳腺癌候選藥物的部分共同重要影響因子的取值范圍較大,相較于總體化合物樣本的共同重要影響因子的區間長度衰減并不明顯,這樣得到的共同重要影響因子的取值范圍對于候選藥物的優化意義不大,于是設定區間長度衰減的閾值為20%,即衰減后的區間長度小于全局區間長度的20%認定為表達更顯著的重要影響因子。通過迭代優化,從9個共同重要影響因子中找到了4個變化更為顯著的變量,并求出其取值范圍見表2,然后在R中畫出表達顯著的共同重要影響因子在優質抗乳腺癌候選藥物中的分布直方圖(圖5)。
從表2可以看出:共同重要影響因子MLFER_BH(0.56,2.65)、MLFER_S(1.30,4.41)、WTPT-5(0.00,10.01)、SdssC(-1.92,2.76)的衰減區間長度均大于總體區間長度的85%以上,因此可以認為這些因子在優質抗乳腺癌候選藥物中表達更顯著,它們的取值將更有可能共同影響抗乳腺癌候選藥物的抗乳腺癌活性和ADMET性質。
由圖5可以發現:優質抗乳腺癌候選藥物的共同重要影響因子除了相對總體樣本取值的分布更為集中之外,它們的分布還近似滿足某一區間內的正態分布,因此可以認為這些共同重要影響因子在優質抗乳腺癌藥物中有在其均值附近波動的趨勢,共同重要影響因子不在此區間范圍之內的化合物有可能在藥效性和藥代動力學性質與安全性中表達異常,便于篩選出劣質抗乳腺癌候選藥物,簡化抗乳腺癌藥物的優化過程。
3 結論
針對實驗室研發抗乳腺癌新藥的艱難而漫長的過程,為了提高新藥物研發的效率、縮短研發周期、節省時間和成本。本文選取1974種化合物的高維分子描述符變量數據,分別構建了以ADMET性質為因變量的隨機森林分類預測模型和以pIC50值為因變量的隨機森林回歸預測模型,模型的預測精度都較好,判定模型具有可行性。基于隨機森林計算得到的袋外誤差與原始誤差的差值大小和可解釋性方差的大小判定重要因子貢獻率,從ADMET性質和pIC50值排名前30的重要影響因子中篩選出9個共同影響因子,再通過設定優質抗乳腺癌候選藥物的衰減閾值為20%確定4個表達顯著的共同重要影響因子,并求出其取值范圍,分別為MLFER_BH(0.56,2.65)、MLFER_S(1.30,4.41)、WTPT-5(0.00,10.01)和SdssC(-1.92,2.76)。隨著藥物大數據平臺和合成藥物技術的發展以及進一步臨床試驗的數據驗證,控制變化顯著的4個共同重要影響因子在最優的取值范圍之內,將更容易實現抗乳腺癌新藥物滿足良好的生物活性且具有良好ADMET性質,達到抗乳腺癌候選藥物優化的目的。
[ 參 考 文 獻 ]
[1] DE LAURENTIIS M, CIANNIELLO D, CAPUTO R, et al. Treatment of triple negative breast cancer (TNBC): current options and future perspectives[J]. Cancer Treatment Reviews, 2010, 36(suppl.3):80-86.
[2] 寧文濤, 胡志燁, 董春娥等. 抗乳腺癌雙靶點藥物研究進展[J]. 中國藥物化學雜志,2020,12(30):778-788.
[3] HARBECK N, PENAULT-LLORCA F, CORTES J, et al.Breast cancer[J].Nat Rev Dis Primers, 2019,5(01):66.
[4] GUAN J, ZHOU W, HAFNER M, et al.Therapeutic ligands antagonize estrogen receptor function by impairing its mobility[J]. Cell,2019,178(04):949-963.
[5] SIEGEL R L,MILLER K D,JEMAL A.Cancer statistics,2018[J].CA Cancer J Clin,2018,68(01) :7-30.
[6] 袁升月, 金羿, 廖俊. 藥物大數據平臺在抗乳腺癌藥物藥代動力學/藥效學研究中的應用[J]. 中國臨床藥理學雜志,2017,23(33):2464-2467.
[7] 秦璞, 郭志旺, 郭維恒等. 應用隨機森林和支持向量機對三陰性乳腺癌基因數據的降維和篩選[J]. 中國衛生統計, 2020,37(03):71-76.
[8] 魏靜,李婷英,張瑩等. 羧甲基β-葡聚糖聯合阿霉素抗乳腺癌以及減輕心臟毒性的實驗研究[J]. 中國臨床藥理學雜志,2021,37(03):275-279.
[9] BREIMAN L. Random Forests [J]. Machine Learning,2001(45):65-68.
[10]吳喜之.多元統計分析[M].北京:中國人民大學出版社, 2019:245-247.
[11]曹桃云,陳敏瓊.基于學生化極差分布的隨機森林變量選擇研究[J].統計與信息論壇,2021,36(08):15-22.
[12]王奕森. 隨機森林和深度神經網絡的若干關鍵技術研究[D].北京:清華大學,2018.
[13]LEI T L, SUN H Y, KANG Y, et al. ADMET evaluation in drug discovery. 18. reliable prediction of chemical-induced urinary tract toxicity by boosting machine learning approaches[J]. Molecular Pharmaceutics, 2017, 14(11): 3935-3953.
[14]許美賢, 鄭琰, 李炎舉,等.基于PSO-BP神經網絡與PSO-SVM 的抗乳腺癌藥物性質預測[J].南京信息工程大學學報,2022,1.18:3.
[15]孫兆亮. 數學建模算法與應用[M].北京:國防工業出版社, 2017:425-428.
[16]丘佑瑋. 機器學習與R語言實踐[M].北京:機械工業出版社, 2016:146-170.
Optimization of Anti Breast Cancer Drug
Candidates based on Random Forests
TANG Shixing,ZENG Ying
(School of Science, Hubei Univ. of Tech., Wuhan 430068,China)
Abstract:By making full use of big pharmaceutical data platforms and clinical resources, we used data analysis methods to predict ADMET properties and anti-breast cancer activity of anti-breast cancer drug candidates. It provided a reference for the process of developing new anti-breast cancer drugs in the laboratory. Random forests were constructed for the molecular descriptor variable data of 1974 compounds, and the dependent variables of prediction models were ADMET properties and pIC50 values. The prediction accuracies of the models were 88.7% and 91.3% respectively. Based on the random forest model, we obtained the contribution rate of important impact factors. Then we established the ranges of four common significant influencers that varied significantly. They were MLFER_BH (0.56,2.65), MLFER_S (-1.30, 4.41), WTPT-5 (-0.00, 10.01) and Sdssc (-1.92, 2.76). The result was instructive to optimize the anti-breast cancer drugs.
Keywords:anti-breast cancer drugs; anti-breast cancer activity; ADMET properties; correlation test; random forest
[責任編校:閆 品]
