分布式張量網絡隨機化技術的大數據隱私保護
2023-12-04 12:56:38陳立軍陳孝如
計算機工程與設計 2023年11期
陳立軍,張 屹,陳孝如
(廣州軟件學院 軟件工程系,廣東 廣州 510990)
0 引 言
張量概念是矢量和矩陣概念的推廣,標量是零階張量,矢量是一階張量,矩陣是二階張量,三階或階數更高的張量被稱為高階張量,張量也可以被視為多維數組,一般所說的張量是高階張量。張量分解從本質上來說是矩陣分解的高階泛化,矩陣分解有3個很明顯的用途,即降維處理、缺失數據填補和隱性關系挖掘,其實張量分解也能夠很好地滿足這些用途。20世紀60年代以來多路數據分析中已有數十年歷史的數學技術[1],張量分解廣泛應用于從信號處理到機器學習領域[2];張量計算最近成為大數據處理的一種有前途的解決方案,因為它能夠對各種數據進行建模,例如圖形、表格、離散和連續數據[3],滿足不同數據準確性或缺失數據的算法[4],并為大數據速度提供實時分析,例如流分析[5],并且能夠捕獲大量數據中復雜的關聯結構,并為許多大數據分布式應用程序生成有價值的見解[6]。另一方面,張量網絡計算在數值社區中是一種成熟的技術,該技術提供了前所未有的大規模科學計算,其性能可與稀疏網格方法等競爭技術相媲美[7],張量網絡(TN)表示稀疏互連的低階核心張量(通常為3階或4階張量)中的數據或張量塊。TN于20世紀90年代首次在量子物理學中被發現,以簡約的方式捕獲和模擬糾纏量子粒子之間的多尺度相互作用[8]。TN于21世紀初獨立地被數值社區重新發現,并發現了從科學計算到電子設計自動化的廣泛應用[9]。
然而,大數據可能包含專有信息或個人信息,例如個人的位置、健康、情緒和偏好信息,需要適當的加密和訪問控制保護用戶的隱私。
TN以犧牲安全性為代價增加了多方計算的功能和性能,與基于模算術并在定點表示上工作的經典加密技術相反,它自然支持浮點和定點運算,此外,與加密計算技術不同,TN允許進一步壓縮,加密計算技術通常會增加存儲和通信開銷,因此,這通常會使加密計算無法用于大數據處理;而加密之前的數據壓縮通常會使數據表示失去一些功能,例如對原始數據的加密計算。憑借分布式TN在大規模科學計算和大數據分析中令人印象深刻的記錄,本文提出了一種基于張量網絡的新型密鑰共享方案,以保護大數據中的隱私安全。
1 相關工作
密鑰共享方案以較高的存儲和通信成本為代價,提供了信息理論的安全性,本文回顧了實際的密鑰共享方案。Krawczyk[10]提出了第一個計算密鑰共享方案,采用隨機生成密鑰的對稱加密方法對數據進行加密,利用Rabin的信息分散算法將加密后的數據分成多個塊,而加密或解密密鑰使用Shamir的密鑰共享方案進行分割,這樣收集一定的閾值塊數就足以進行密鑰重構,從那時起,計算密鑰共享方案的許多不同版本被提出,以提高數據安全性、數據冗余抵抗、數據完整性、碎片大小和不同機器可信度的管理[11]。由Rivest[12]引入的AONT解決了密鑰暴露問題,它通過在片段之間建立依賴關系,這樣只獲取密鑰而不獲取所有片段就不會導致立即的信息泄露。此外,使用新的加密密鑰僅對一個數據片段進行重新加密,大大降低了傳輸成本[13],然而,這種加密數據的用途是非常有限的,如搜索、更新和計算都必須重建原始數據[14]。
數據匿名化可能是目前廣泛采用的最簡單的低成本解決方案,用于在企業內部和跨企業之間為各種應用程序安全共享數據。數據匿名化技術包括刪除個人可識別信息(例如使用哈希或掩碼技術)和數據隨機或擾動技術(例如隨機噪聲、置換和轉換)[15]。隨機組件或函數必須精心設計,以保存訓練數據集中的重要信息,并確保模型性能[16]。最近一項關于不同隱私度量的系統調查可以在文獻[17]中找到,這些隱私度量基于信息理論、數據相似性、不可區分性度量以及對手的成功概率,為特定設置選擇合適的隱私度量取決于對抗模型、數據源、可用于計算度量的信息以及可度量的屬性。差分隱私(DP)[18]是一個數學框架,用于嚴格量化在統計數據庫或機器學習操作期間泄露的信息量[19],DP是一種已被業界廣泛采用的已被證明的隱私保護技術。最近一種有希望的數據匿名化方法是使用生成機器學習模型和計算機模擬,該數據類似于原始數據集中觀察到的統計分布或行為,這些模型是特定于應用程序的(即依賴于訓練數據集或物理模型),任何對合成數據的分析都必須在真實數據集上進行驗證。
雖然隱私保護矩陣和張量分解技術在文獻中已經得到了很好的研究[20],但尚未提出用于大數據隱私保護的分布式張量網絡表示和計算方法,與數據匿名化技術不同,張量分解是完全可逆和可壓縮的,重構精度可以是有損的,也可以是接近無損的。與數據分割不同,TN不需要代理服務器來管理元數據,但與計算密鑰共享方案相比,它提供了更好的分解數據的效用,但代價是更高的特權泄漏。為了處理大數據,隨機映射或投影技術利用一個投影矩陣,如高斯和隨機正交矩陣,在應用張量分解之前,將數據張量投影到更小的張量大小。隨機抽樣技術,近似整個數據張量,現有隨機映射和隨機抽樣算法對于大數據非常有用,張量分解塊通常是有損壓縮以至重建精度,這不同于本文提出的隨機張量分解,分解張量塊的隨機性也受到投影矩陣的分布和采樣過程的限制,以保證較小的誤差范圍,而本文提出的算法在張量分解算法中,通過在序列矩陣分解過程中應用大而可控的擾動,將大數據的復雜結構信息隨機分散到張量核中,與隨機投影或映射算法相比,該算法的時間消耗也很低,可以很容易地適應于現有的張量算法。盡管如此,所提出的張量擾動技術可以很容易地與現有的隨機投影或采樣算法相結合,用于大數據處理和隱私保護。張量分解在大數據降維中得到了廣泛的應用,但是對于張量網絡編碼方案的研究相對滯后,在撰寫本文時僅有少量的文獻[21,22]。
2 威脅模型和安全
客戶端的安全存儲和計算外包給一組不可信但不相互勾結的服務器S1,S2,…,Sn,客戶端在初始設置階段,在服務器之間秘密共享它們的輸入,然后服務器的存儲(例如加密)、計算和通信使用分散TN計算協議,這些服務器運行在不同的軟件堆棧上,以最大限度地減少它們受到惡意軟件攻擊的機會,并可以在不同的子組織下操作,以最大限度地減少內部威脅。在云場景下,密鑰共享可以被分發到同一個云服務提供商(CSP)提供的多個虛擬實例或不同的云(例如多云或混合云環境)中。本文假設一個半誠實的對手a,他能夠在任何時間損壞客戶機的任何子集和最多n-1臺服務器,與加密的數據處理不同,本文的安全定義要求對手只了解客戶端輸入的部分信息,而不知道過程中的敏感信息,基于信息理論和基于相似性的隱私度量對隱私泄露進行計算,基于TN的密鑰共享方案對每個服務器都是不對稱的,即每個服務器都包含特定于索引的信息,如第3節和第4節所示,每一個TN表示都需要高數據復雜度才能在多方設置中保護隱私。
3 基于分布式張量網絡的密鑰共享方案
在本節中,提出了一種基于分布式張量網絡(TN)表示的密鑰共享方案,以實現大數據存儲、通信、共享和計算的無縫安全。TN在語義層對數據塊進行分解,每個包含潛在信息的分解張量塊隨機分布在多個不相互勾結的服務器上,多路分量分析的成功可以歸因于有效的矩陣和張量分解算法的存在,以及通過引入稀疏性、正交性、平滑性和非負性[23]等約束條件提取具有物理意義分量的可能性。高階張量分解一般是非唯一的,每個張量核或因子矩陣包含索引特定的信息,由于分解的非唯一性,這些信息是不可鏈接和不可解釋的,因此它們通常用于降維和壓縮計算。
本文描述了在多方計算設置下的幾種基本張量模型,以增強原始張量的隱私保護,提出了基于擾動技術(一種數據處理和分析的方法,它可用于對離散事件動態系統的仿真模型進行結構或參數優化)的隨機算法,將每個數據塊分解為隨機張量塊,每個張量塊在執行張量分布后,可以使用張量舍入算法重新隨機化,多線性運算降低了張量秩復雜度,提高了存儲和計算效率。
塔克分解(TD)[24]是矩陣奇異值分解(SVD)在高維張量中的一種自然擴展,TD利用核心張量G捕捉潛在因子U(來自張量的模態矩陣化SVD)之間的相互作用,這個核心張量G反映了原始張量的每個模態的主要子空間變化并對其進行排序,對于三階張量A∈RI1×I2×I3,張量分解(TD)以通過不同的張量運算定義為
A(i1,i2,i3)?GX1
vec(A)?(
(1)
G∈RR1×R2×R3是一個3維核心張量,Uk∈RI1×Rk,k∈ {1,2,3} 是因子矩陣,Xn是n模乘積,?是張量積,vec(·)是向量化算子[24],〈·〉表示存儲在服務器中的私有共享,G是一個共享張量核心,用于在服務器之間交換以執行張量計算方案。TD是非唯一的,因為潛在因子可以在不影響重建誤差的情況下旋轉,然而,TD產生了一個良好張量的平方誤差低秩近似,當G是超對角線時,規范多元(CP)分解是TD的一個特例。CP由于其唯一性和易于解釋而在信號處理中非常流行,然而,這些特性也使得CP不適合隱私保護。
本文提出了分層塔克(HT)分解[25]以減少TD的內存需求,HT可以很好地近似高階張量(N?3),而不會受到維數災難的影響,HT基于二叉樹層次結構遞歸地分割張量的模式,使得每個節點包含模式的子集,因此,HT需要張量矩陣化二叉樹的先驗知識,HT定義如下
Ut?(Ut?Utr)〈Bt〉t
(2)
Bt是重構為RtRtr×Rt矩陣的“轉移”核心張量(或內部節點),Ut包含原始張量的Rt左奇異向量,t,tr分別對應左節點和右子節點,葉節點 〈U1〉1,〈U2〉2…〈UN〉N包含潛在因子,應用分布式存儲以確保隱私保護,當應用程序在物理模式上提供直觀和自然的層次結構時,HT特別有用。
張量列(TT)[26]將一個給定張量分解成一系列或級聯的連通核張量,因此TT可以解釋為HT的一種特殊情況,TT核心張量通過一個共同的簡約模式Rk連接,TT的定義如下
A(i1,i2,i3)?〈G[i1]〉1×〈G[i2]〉2×〈G[i3]〉3
(3)
其中,G[ik]是一個Rk-1×Rk矩陣,R0=R3=1,這個矩陣是乘法操作,TT格式及其變體非常有用,因為它們對許多分布式、多線性運算[27]具有靈活性,并且可以將其它基本張量模型(如CP、TD、HT)轉換為TT格式[23],類似的性質也適用于張量鏈或張量環格式(TR)[28],TR是TT格式的線性組合,即R1=R3>1,TR表示比TT表示更強大[28]。
3.1 存儲的復雜性
表1列出了這里提到的不同TN格式的存儲復雜性和邊界,低秩近似在張量網絡計算中非常有用,對于一些具有低秩結構的高相關張量數據結構或函數形式,在節省存儲、通信和計算成本的同時,精度損失可以忽略不計。塔克格式不適用于N>5張量,因為核心張量G的條目數以N為指數尺度,因此在處理高階張量[23]時,塔克格式的存儲和計算是不實用的。TT格式及其變體既具有穩定的數值特性,又具有合理的存儲復雜性。此外,TT允許控制TT分解和TT舍入算法中的近似誤差。

表1 不同張量格式的存儲復雜度
3.2 圖形化表示
TN可以用一組由邊相連的節點來表示,邊對應收縮模態,而不從一個張量到另一個張量的線對應開放(物理)模態,這對整個TN的總階數有貢獻,圖1顯示了不同TN表示的圖形表示,在張量上進行的數學運算(例如張量收縮和重塑)可以用張量的圖形簡單直觀地表達,而不用顯式地使用復雜的數學表達式,連接到節點的線數表示張量順序、等級和模式大小標記在邊緣上。
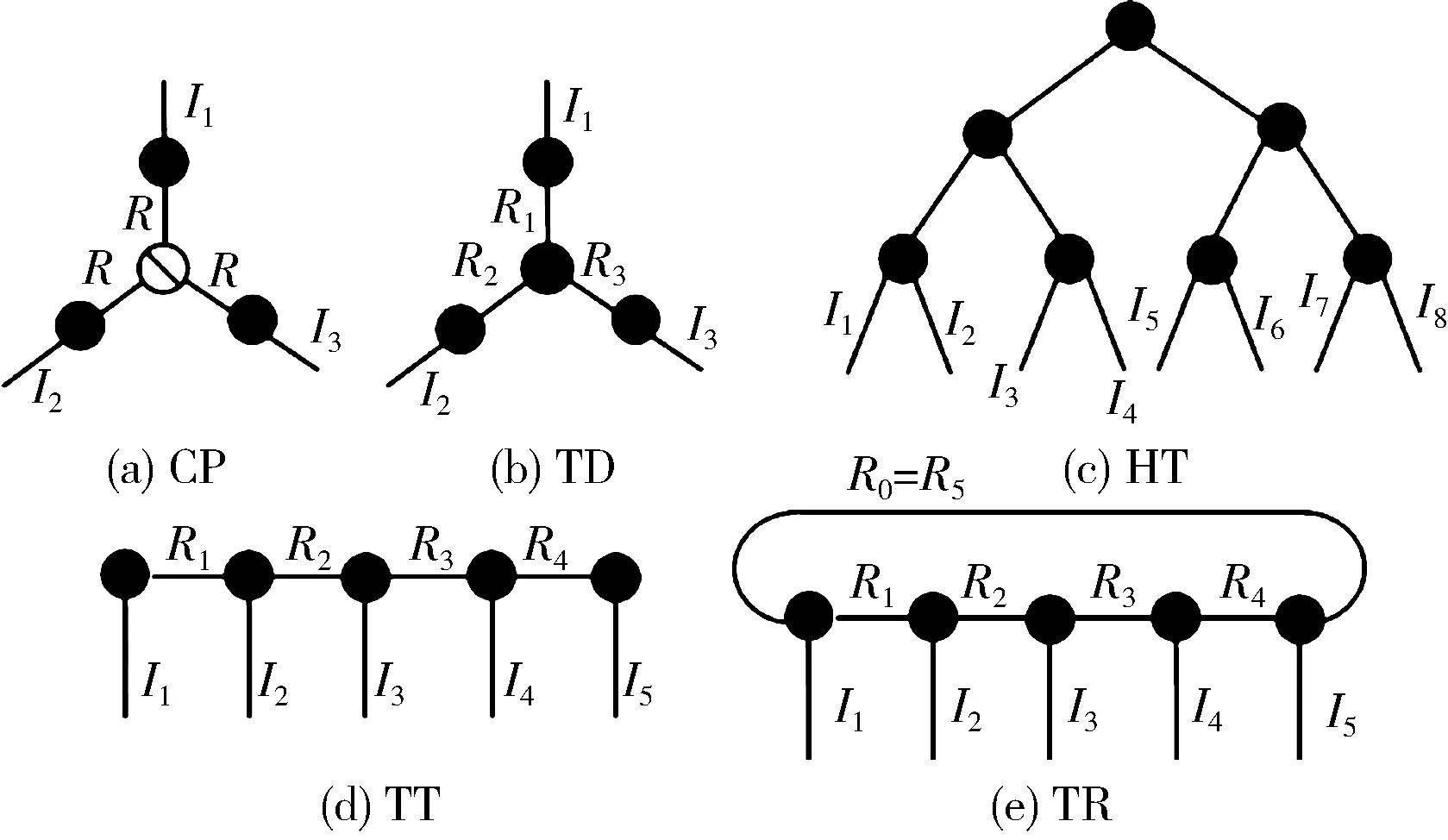
圖1 不同張量網絡(TN)分解的圖形表示
基于隨機張量分解的密鑰共享生成,算法1、2、3、4給出了本文提出的隨機rTD、rHT、rTT-SVD、rTR-SVD算法,通過應用擾動技術將大數據中的結構信息隨機分散到張量核中,將n維張量分解為隨機的秘密份額。算法1基于文獻[29]中提出的高階奇異值分解(HOSVD)對一個張量的每個模態進行SVD,提取潛在因子,然后得到核心張量,獲取潛在因子之間復雜的相互作用;算法2基于輸入張量的二叉樹矩陣化,遞歸地將rTD應用于每個張量節點;算法3和算法4分別基于文獻[26,28]中提出的TT-SVD和TR-SVD算法,TT-SVD和TR-SVD在張量上進行順序SVD分解,得到TT和TR表示。圖2(詳見算法1)和圖3(詳細信息參見算法3)顯示了提出的rTD和rTT-SVD算法的圖形表示,在執行算法1、2、3中的每一步SVD后,采用隨機離散。為了在壓縮和隨機性之間取得平衡,最大(隨機)擾動應該在基于每個奇異值的大小的某個閾值δ內,共享再生可以通過本文提出的基于文獻[26]的隨機TT四舍五入算法(見算法5)來完成,所有算法都在分布式服務器上以TT格式進行,但這并不推薦嵌入現有張量分解算法,因此計算復雜度沒有增加太多,只進行少量張量核收縮和SVD,存儲擾動因子的內存大小被認為可以忽略不計。
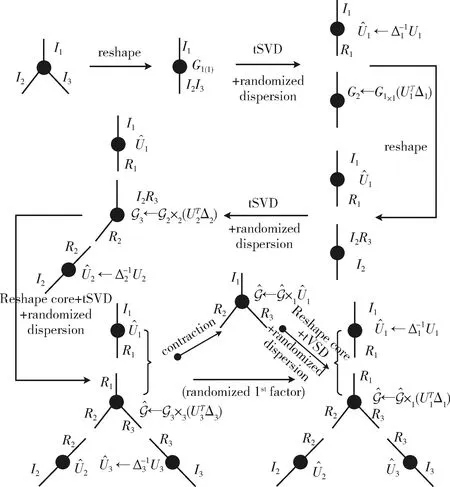
圖2 3階張量的rTD算法圖形表示
算法1:提出的基于高階SVD (HOSVD) 的隨機塔克分解 (rTD)
輸入:張量A∈Rl1×l2×…×IN和矩陣R1,R2…RN的秩。
初始化:G1=A;
修改從多重線性SVD 或N模式SVD:
fork=1 toNdo
[Uk,Sk,Vk]←tSVD(Gk(k),Rtrunc.=Rk);
用均勻分布打賭生成對角擾動矩陣
閾值δ和1,Δk~U([δ,1]);
End
隨機化第一個TD因子矩陣
算法2:通過遞歸節點式rTD提出的隨機分層塔克(rHT)分解。
輸入:張量A∈Rl1×l2×…×IN,矩陣R1,R2…RN的秩,和二叉樹T的矩陣化。
U1←A(1);
從樹T的根節點開始,選擇一個節點t:
設置t1和tr為t響應的左、右子節點;
Ift1is not singleton:Rt1←Rfull;
Iftris not singleton:Rtr←Rfull;
Ut←reshape(Ut,[tl,tr,t]);
在tl和tr上遞歸,直到tl和tr是單例。
算法3:隨機張量訓練-奇異值分解(rTT-SVD)算法。
輸入:張量A∈Rl1×l2×…×lN和錯誤的閾值ε。
初始化:TT的非零奇異值個數R0=1; 擾動閾值δ;
擾動參數δε=√Nε-1;
張量的形狀,[I1,I2,…,IN]←shape(A);
Mode-1:張量A的矩陣化,M1←A(1);
序列(SVD+隨機離散度):
fork=1toN-1do
擾動奇異值分解,[Uk,Sk,Vk]←tSVD(Mk,δrel.=δε);
TT的非零奇異值個數,Rk←shape(Sk,1);
用均勻網格生成對角擾動矩陣
閾值之間的距離δ和1,Δk~U([δ,1]);
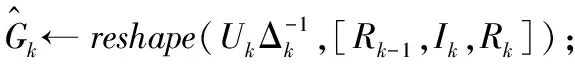
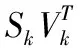
End
隨機分配第一個TT-core:
R1←shape(S1,1); Δ1~U([δ,1]);
算法4:隨機張量環奇異值分解 (rTR-SVD)。
輸入:張量A∈RI1×I2×…×IN和錯誤的閾值ε。
初始化:使得近似誤差δ;
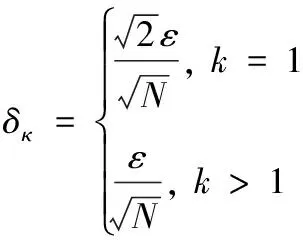
準備第一個TR核心:
張量形狀,[I1,I2,…,IN]←shape(A);
Mode-1:張量A的矩陣化,M1←A(1);
擾動奇異值分解,[U1,S1,V1]←tSVD(M1,δrel.=δ1);
Δ1~U([δ,1]); Split TT-ranksR0,R1:
Set TT-rank,RN←R0;
順序(SVD+隨機離散):
fork=2 toN-1do
[Uk,Sk,Vk]←tSVD(Mk,δrel.=δk);
Rk←shape(Sk,1); Δk~U([δ,1]);
End
建造最后一個核心,
隨機選擇第一個TR核心:
R1←shape(S1,1); Δ1~U([δ,1]);
算法5:隨機TT-rounding(rTTrounding)以減小TT-cores的大小
輸入:TT核的和N個存儲在服務器上的順序張量s,A=〈G1〉1〈G2〉2…〈GN-1〉N-1〈GN〉N和ε。
初始化:TT的非零奇值班的個數 〈R0〉1=1; 〈RN〉N=1;
擾動閾值δ;

從右到左的QR正交化:
fork=Nto 2do
[〈Rk-1〉k,〈Ik〉k,〈Rk〉k]←shape(〈Gk〉k);
〈Gk〉k←reshape(〈Gk〉k,[Rk-1,IkRk]);
End
從左到右(SVD壓縮+隨機分散):
[〈R0〉1,〈I1〉1,〈R1〉1]←shape(〈G1〉1);
fork= 1 toN-1do
〈Gk〉k←reshape(〈Gk〉k,[Rk-1,Ik,Rk]);
[〈Uk〉k,〈Sk〉k,〈Vk〉k]←tSVD(〈Gk〉k,δrel.=δε);
〈Rk〉k←shape(〈Sk〉k,1); 〈Δk〉k~U(δ,1);
End
3.3 隱私的安全性
基于隨機TN格式的密鑰共享的正確性是明顯的,如果數據允許低秩結構,張量表示是可壓縮的,隨機張量分解算法將大數據中復雜的結構信息隨機分解為不同的張量核或子塊,對于復雜的相關結構,即奇異值被緊密分離時,小擾動下SVD分解的敏感性是眾所周知的[30]。此外,所提出的算法通過不影響重構精度來隨機化TN分解,隱私泄露受每個指標的張量秩復雜度的限制,即具有足夠高秩復雜度的指標是隱私保護的,而張量核中只有0的指標意味著原始張量中與該指標對應的所有值都為0,但是,在TN分解之前,通過在原始張量中填充隨機噪聲增加復雜度,可以很容易地克服這個問題。在張量秩復雜度足夠高的情況下,非0值的大小、符號和精確位置即使被除一臺服務器外的所有服務器合謀也不會泄露。為了進一步增加不確定性,本文沿著每個張量維隨機排列模態變量,并存儲隨機種子進行重構,如果多維數據高度相關,則可以在TN分解后進行隨機排列,以確保可壓縮性,每個張量核只包含特定于索引的信息,因此在大規模數據泄露的情況下它們是不可鏈接的,將更復雜的TN結構劃分為私有和共享張量核,可以通過基于成對網絡距離的分層聚類和隨機分散張量計算實現,從而最小化隱私泄漏。
3.4 加法密鑰共享計劃
經典的加法密鑰共享方案定義為x=〈x1〉1+〈x2〉2+…,從經典方案到基于TN格式的密鑰共享方案的轉換相對簡單,每一方使用所提出的隨機張量分解算法分解各自的份額,并將相應的張量核發送給其它方,各方使用基于張量多線性運算的相應張量核執行加法運算,將生成的張量核分配給對應方并使用分布式張量操作更新所有張量核,除了一方之外,所有各方都將他們更新的張量核傳遞給剩下的一方(之前沒有生成隨機張量核)以生成他的密鑰份額。未來的工作可能會考慮如何防止惡意服務器破壞張量網絡計算協議。
3.5 大數據分散存儲、共享和通信
加密對于大數據分布式應用的密鑰管理來說是復雜的,加密需要由受信任的機構集中管理來進行身份驗證、授權和撤銷訪問,以防止可能導致大規模數據泄露的潛在密鑰泄漏。本文的提議結合了基于分布式TN和元數據隱私的密鑰共享方案,以無縫保護大數據的存儲、通信和共享。分布式信任可以通過分散片段、元數據加密和訪問控制機制實現,此外,元數據管理是靈活的,可以使用企業管理系統以集中或分散的方式進行,也可以在個人用戶側以分布式方式進行,如果允許訪問元數據信息和切碎的片段,任何軟件應用程序都可以重建原始數據,可以通過加密散列來確保數據完整性;而數據可用性可以通過集成在Hadoop分布式文件系統(HDFS)保證,用于安全數據隱私保護、壓縮、粒度訪問控制、可更新性和壓縮計算。
元數據充當用戶瀏覽信息和數據的邏輯“地圖”,它還可以幫助審計員進行系統審查和違約后損害評估,在使用本文提出的隨機張量分解算法分解大數據并將每個張量核或子塊分配到多個存儲位置后,主元數據文件更新為每個張量塊的位置和匿名文件名、張量結構、加密哈希、隨機種子用于置換模式變量,以及用戶的訪問權限;張量片段的存儲位置和文件名可以定期更新,以增強數據隱私保護。主元數據文件可以在用戶端進一步加密和密碼保護,存儲在分布式存儲位置的每個張量核的元數據僅包含匿名文件名和位置,以便在發生大規模數據泄露時無法鏈接;基于角色管理策略的數據加密和訪問控制可以以分散的方式實現,以保護張量核。系統架構和元數據組織超出了本工作的范圍,但將來會考慮到各種應用場景、系統不同大數據應用的性能和要求。
3.6 大數據分布計算
TN在大數據分解后使用較小的、互連的張量核自然支持分布式計算,塔克格式的一些基本算術運算在文獻[27]中導出,讓
A=[[GA;A(1),A(2),…,A(N)]]
B=[[GB;B(1),B(2),…,B(N)]]
(4)
其中,GL,L∈{A,B} 和A(k)/B(k),k∈{1,2,…,N} 分別對應塔克核心張量和因子矩陣

AB=[[GAGB;A(1)B(1),…,A(N)B(N)]]
AB=[[GAGB;A(1)B(1),…,A(N)B(N)]]
(5)
(1)對于所有變量,在每個張量核中獨立地添加或相乘可分離的分量;
(2)所有秩和在線性運算中相加,在雙線性運算中相乘。
在迭代計算期間,張量等級快速增長,尤其是乘法,因此,應為張量格式提供另一個稱為秩擾動的重要操作。
TT格式及其變體支持廣泛的多重線性運算,例如加法、乘法、逐矩陣或向量乘法、直接和、阿達瑪積、張量積和內積[23],如圖4所示,TT格式的多線性運算可以以分散的方式自然地執行,使其非常適合大數據處理和科學計算。TT等級隨著每個多線性運算而增長,并且很快變得計算量大,可以通過首先使用QR分解對張量核進行正交化,然后使用SVD分解進行壓縮,實現TT舍入(或重新壓縮)過程以減少TT秩,均以TT格式執行;算法3中提出的隨機化TT-SVD算法可以很容易地適應TT舍入過程的第二步;算法5顯示了一個用于N階張量的隨機rTT舍入算法示例。為了計算非線性函數,可以使用TT交叉逼近[31],張量交叉的思想是從TN中采樣,從樣本點重構和計算任意函數,分解樣本更新并相應地更新原始TN。
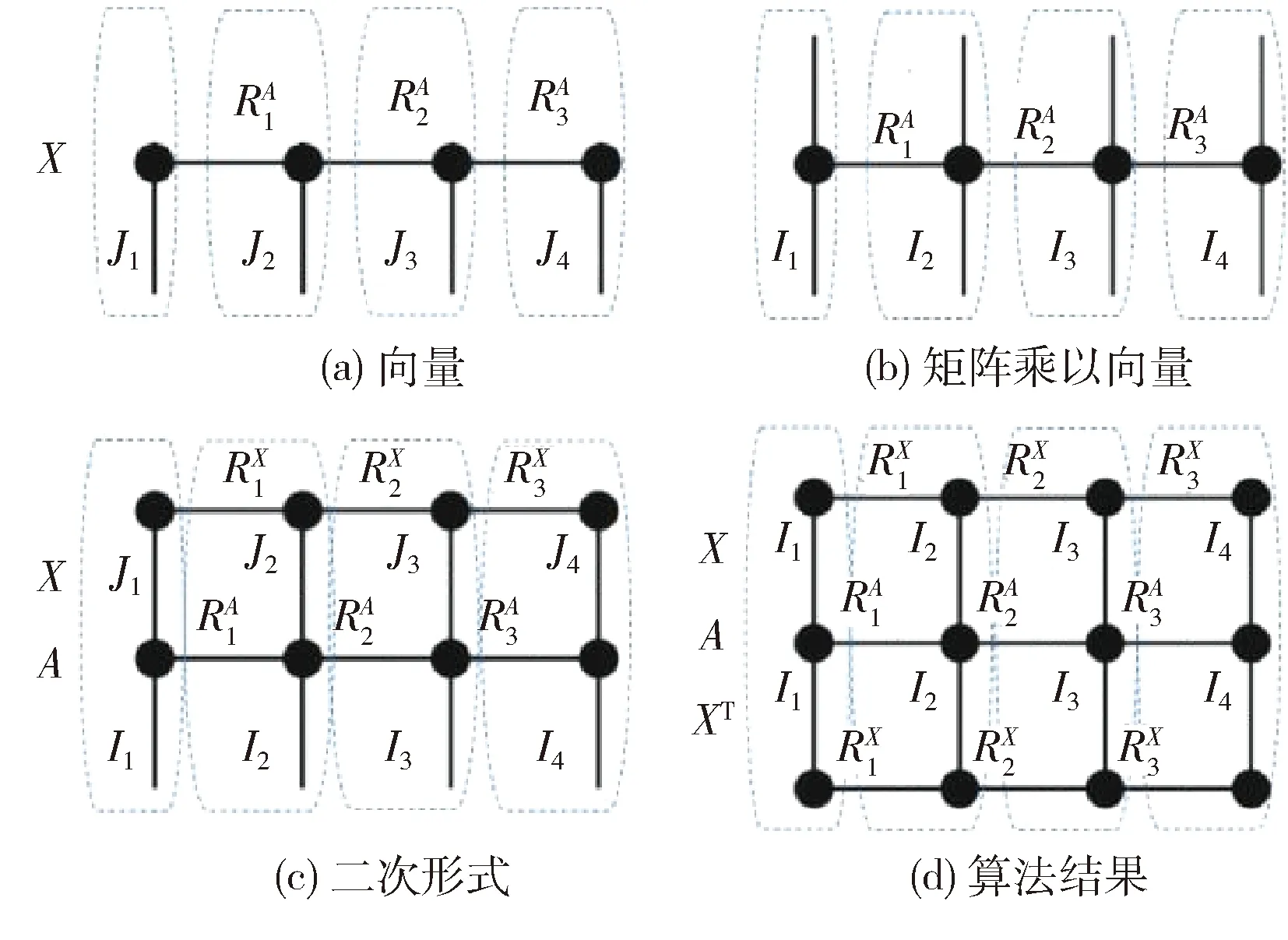
圖4 張量網絡
張量網絡計算自然支持浮點表示的多線性運算,只需最少的數據預處理,不像經典的安全多方計算(SMPC)方案,只支持有限的安全操作(例如加法和乘法),并且必須每次進行預處理才能執行不同的操作,因此,SMPC通常需要服務器之間進行多次通信,以計算復雜的功能。使用TN可以壓縮和分散的方式進行多重線性運算,而不需要重建原始張量,這是張量計算在克服大規模優化問題的維數禍害方面的主要優勢。張量多線性運算通常只需要在每個張量核上進行計算,但一些張量計算方案需要服務器之間的通信。與SMPC方案不同的是,該方案的通信主要是張量核,而不是原始張量的密鑰共享,其大小通常要小得多,然而,在通信過程中,離散張量計算比SMPC方案泄露更多的信息,克服這一問題的一種方法是在執行離散張量計算時不斷地從復雜數據中獲取新的熵。
4 實 驗
4.1 實驗環境
使用64位Intel?Xeon?W-2123 CPU 3.60 GHz,16.0 GB RAM的工作站進行。在計算速度、壓縮比、重構數據失真分析等方面,對原隨機TN分解方法和提出的隨機TN分解方法進行了進一步的比較。對于圖像數據,TN壓縮后的失真可以用歸一化L2不相似度來衡量,L2不相似度定義為
(6)
其中,xn,n∈{1,2,…,N} 是一組原始圖像,x′n,n∈{1,2,…,N′} 為TN壓縮后的重構圖像集,為歐幾里得范數。本文研究了提出的rTT-SVD、rTR-SVD和rTD算法,因為rTD是基于遞歸rTD的,因此表明rTD是隱私保護的,意味著rHT對于更大尺度的張量也是隱私保護的,所有實驗隨機化TN的擾動因子δ均設為0.05,因此對角擾動矩陣Δ均在[0.05,1]范圍內。
4.2 數據集
表2列出了本研究中所有數據集的樣本量和模式大小,在一維、二維和三維生物特征數據集上進行了實驗,以深入研究提出的隨機化TN算法在不同數據維度上的隱私保護。一般情況下,向量和矩陣數據在TN分解前都是被重塑為高階張量的,人類步態(Human Gait)傳感器數據庫使用智能手機的慣性傳感器進行記錄,采樣頻率為100 Hz,每次行走總距離為640 m;真假人臉(Real &Fake Face Images)檢測的訓練圖像由延世大學計算機科學系計算智能與擾影實驗室在Kaggle在線數據共享平臺上提供,實驗中只使用真實的人臉圖像;人臉圖像的RGB通道具有很高的光譜相關性,因此將通道進行三維疊加進行張量分解;耶魯面部(Yale Face Database)數據庫包含15名受試者的GIF圖像,每個人都有11種不同的面部表情或配置。最后,本文還為調查研究生成一個三維超對角張量 (i,i,i) (Super-diagonal Tensor)。
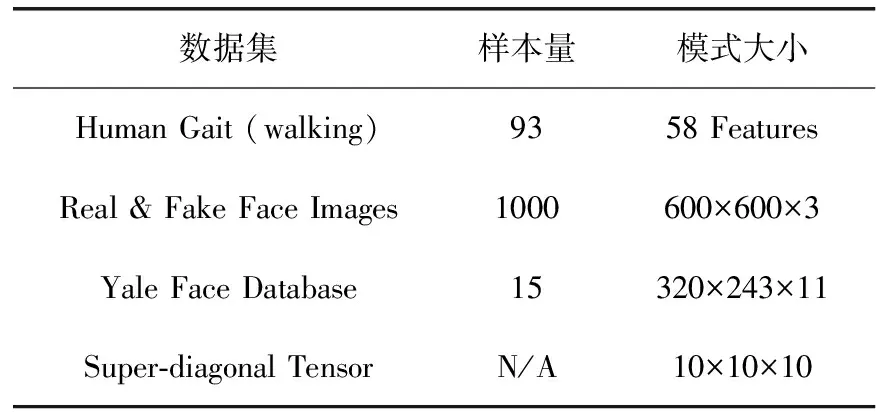
表2 實驗研究中使用的數據集
4.3 隨機TN分解的數據結構復雜性實驗分析
圖5(利用算法3)和圖6顯示了將噪聲數據填充到一個相對簡單的(全秩)超對角張量之前和之后對TT分解的影響,兩種方法重建后都是相同的超對角張量,然而,由于秩復雜度較高,帶有噪聲的樸素填充通常會導致TN計算和存儲成本較高,而本文提出的隨機TN算法只是利用大數據中常見的復雜相關結構,生成高度隨機的張量塊,從而使破解難度增大,進而使隱私得到保護。圖7為人體步行傳感器數據的隨機TT分解,為了在TN壓縮過程中保留重要的數據集特征,將每個屬性標準化到均值為零,方差為1,即z-score。
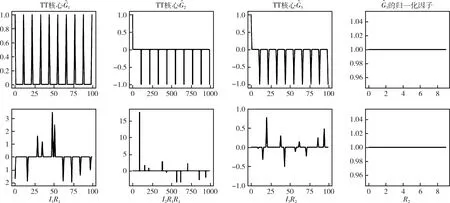
圖5 使用TT-SVD(上)和rTT-SVD(下)對超對角線張量進行分解
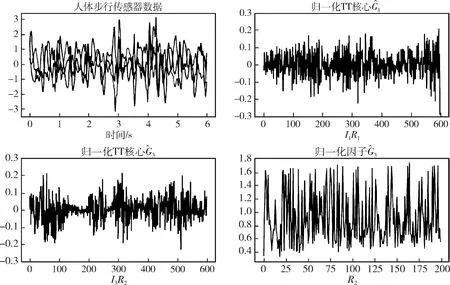
圖7 人體步態傳感器數據
4.4 隱私泄漏實驗分析
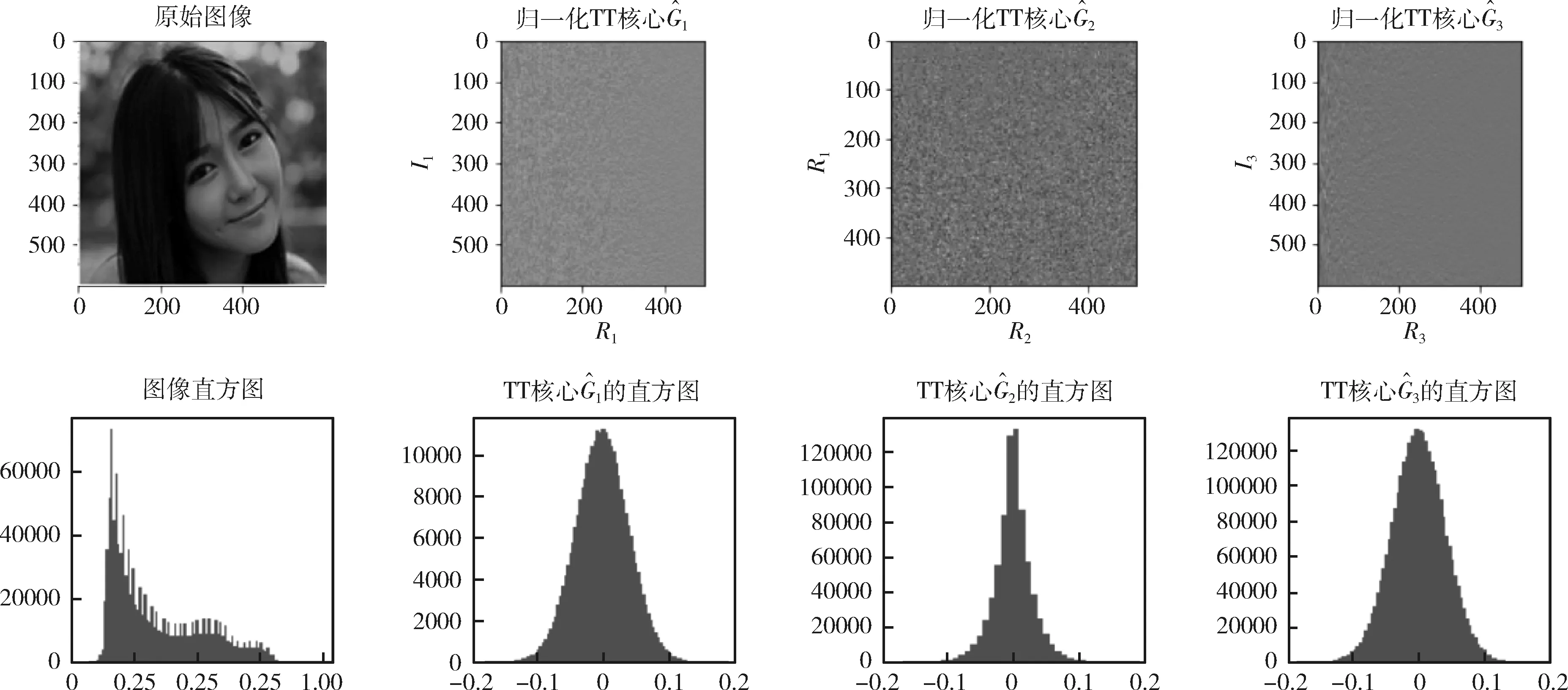
圖8 人臉圖像TT分解的直方圖分析
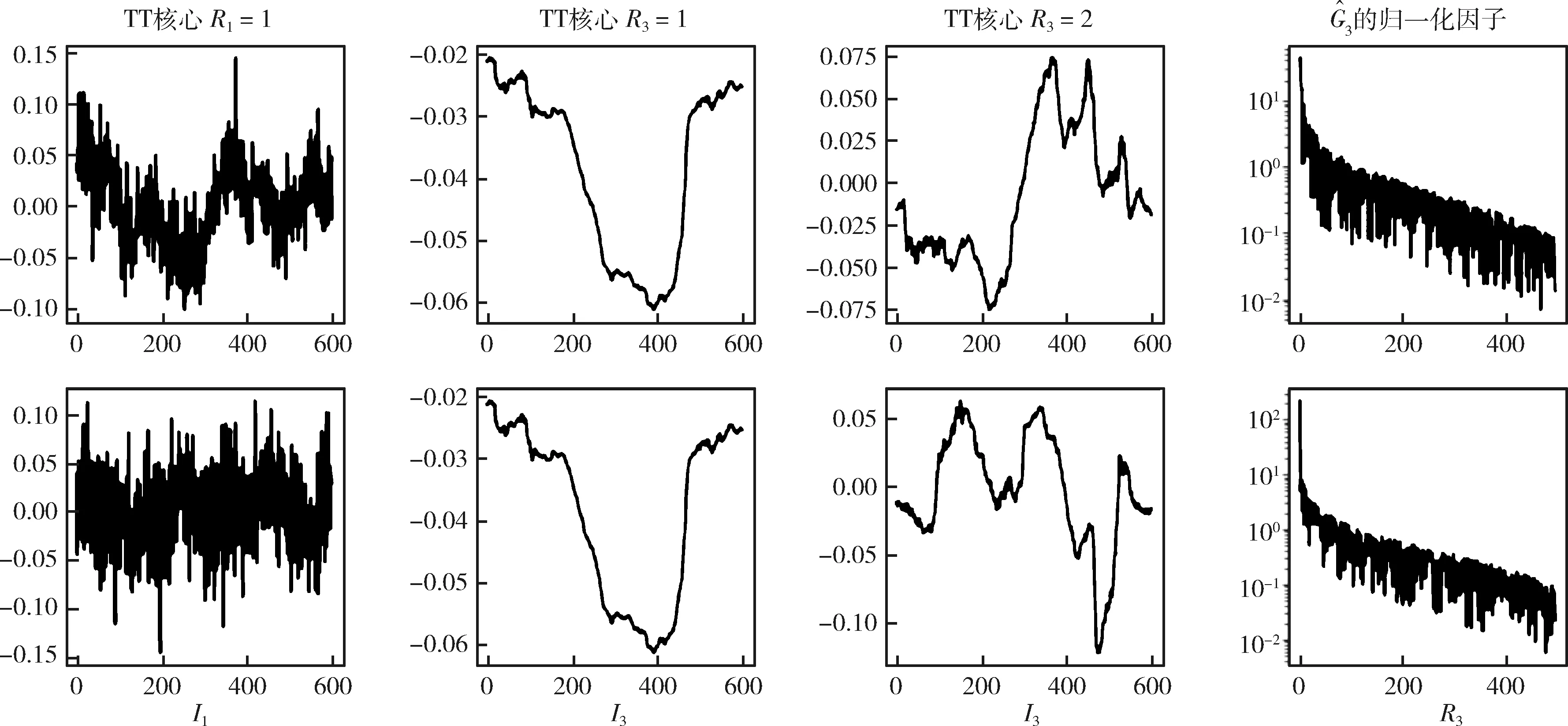
圖9 兩次隨機rTT-SVD分解后產生的歸一化TT核

圖10 將隨機化TN分解過程生成的張量核

圖11 不同隨機TNs的原始數據與重構數據的歸一化互信息

圖12 原始TT-SVD和隨機TT-SVD TT核皮爾森相關系數絕對值
4.5 數據壓縮性和算法效率實驗分析
表3測量了真實和虛假面部圖像數據庫的TN分解和重建的時間效率,與非隨機TN分解相比,隨機化TN分解通常需要稍長的時間,這主要是由于生成隨機化張量塊所需的額外SVD步驟,TR重建很長(約1 min),因為TN結構中有一個循環會浪費更多的時間。圖13顯示了Yale Face Database 在不同TN壓縮比下的圖像失真分析,與非隨機化TN算法相比,隨機化TN算法導致重構數據的失真略高,這是意料之中的,因為隨機化TN算法會產生次優分解,與隨機rTR和rTD分解相比,隨機TT分解產生的失真最低,尤其是在高壓縮比的情況下,TT表示在隱私保護、計算和存儲效率之間取得了良好的平衡。
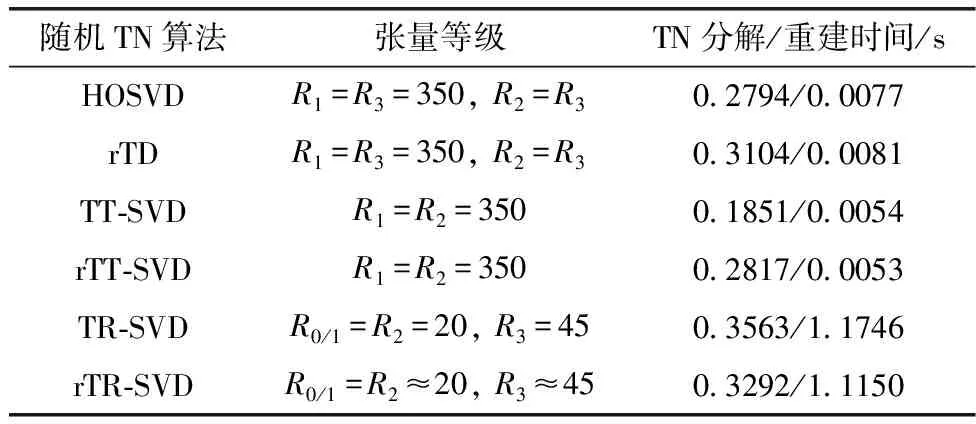
表3 真實和虛假面部圖像數據庫的TN分解和重建的時間效率
4.6 算法的時間復雜度
算法的時間復雜度如何?防攻擊、防破解性如何?華中科技大學的馮君博士對張量應用于大數據的分析與處理進行了詳細的研究,張量分解算法對用戶的在線破解是非常耗時和難以實現的。詳情請見文獻[32]。
5 結束語
可擴展性對于大數據分析的成功和隱私保護技術的廣泛采用都是一個重要的考慮因子。本文提出了一種簡單的擾動技術,可以很容易地適應于各種網絡結構的隨機分解,提出的基于離散張量網絡表示的密鑰共享方案由于支持離散張量計算,在存儲、計算和通信復雜度方面都非常有效。為了驗證該方案對半誠實對手的安全性,進行了隱私泄漏分析,但在進行離散張量操作時仍可能發生隱私泄漏,這需要進一步的研究。
