基于邊緣智能的分布式協同推理策略
2023-12-04 12:51:54趙宏偉柴海龍董昌林潘志偉
計算機工程與設計 2023年11期
趙宏偉,柴海龍,李 思,董昌林,潘志偉
(1.沈陽大學 信息工程學院,遼寧 沈陽 110044;2.沈陽大學 碳中和技術與政策研究所,遼寧 沈陽 110044)
0 引 言
人工智能的廣泛應用和物聯網設備(Internet of things,IoT)數量爆發式的增長共同促進了邊緣智能技術的快速發展,深度神經網絡(deep neural network,DNN)作為支持現代智能應用的骨干技術[1],通常需要大量的計算量,然而現有的多數智能應用只在云端運行,邊緣物聯網設備只起到數據的收集和上傳作用,這給云端帶來了沉重的負擔[2],為了緩解邊緣設備計算能力有限與DNN資源需求巨大之間的差異[3],經典解決方法如分割深度學習模型,將部分計算任務推到網絡邊緣,通過設備間的協作解決問題[4],這種方式既減少了邊緣與云之間的網絡流量,同時避免了數據傳輸過程中的安全和隱私泄露風險。然而,現有的協同推理方面的研究大多集中在對模型本身的優化,并沒有充分考慮模型和數據的并行性對推理過程的加速作用。跨邊緣設備集群分布式執行DNN推理任務的方法是一個低成本且有效的解決方案。
因此,該文針對基于邊緣智能的分布式協同推理策略進行研究,提出一種結合模型層粒度分區和數據并行執行的分布式推理策略(distributed edge cluster DNN,DecDNN),在資源受限的邊緣設備簇中,該策略能有效協同邊緣設備并行執行DNN推理任務,減少整體執行時間。
1 相關工作
現有研究已經提出多種方法來加速DNN在邊緣的推理,包括模型分區[5-8]、數據分區[9-12],及分布式協同推理策略研究[13-16]。
模型分區,Kang Y等提出的Neurosurgeon框架能夠在移動設備和云中自動劃分DNN模型,能夠適應不同的DNN架構并選擇最佳延遲和最佳能耗的分區點[5]。李恩等提出Edgent模型結合模型水平分區和模型提前退出機制來進一步降低模型協同推理的時延[6]。郅佳琳等提出基于卷積核的分割方案[7]。王諾等提出了一種基于網絡模型壓縮與切割技術的深度模型邊云協同加速機制[8],但是這些文獻對于DNN模型的支持有限,并且沒有考慮到協同推理的并行性。
數據分區,數據分區將數據分配給設備并行執行,DeepThings中的單個任務涉及整個CNN,導致重疊計算和冗余任務[9]。Stahl等側重于全連接層的分區,實現全分布式執行[10]。Bai Y等提出通過減少同步梯度的數據量來緩解數據并行DNN訓練中的通信瓶頸問題[11]。DeepScaling框架將模型分區與數據分區結合[12],這些系統研究很少關注CNN結構和調度策略的多樣性,而理論研究往往忽略設備間的同步代價。
分布式協同推理框架,Zhang J等提出了一種利用鄰近工作節點實現網絡集群中各種神經網絡遷移和動態優化分配的系統[13]。張帆等設計提出一種三層計算系統框架,并在邊緣層提出了一種高效的資源調度策略[14]。He W等提出了將DL任務卸載到部署在MEC服務器上的DNN分區以提高推理速度的解決方案[15]。Xiao W等提出了一種用于深度神經網絡模型服務配置的協作式云邊服務認知框架,以提供動態靈活的計算服務[16],以上研究針對不同優化目標提出了不同的模型劃分方法和執行方法,實現了IoT邊緣環境中模型的并行性。
在本文中,提出了一種整體的、協作的、自適應的、低延遲的DNN推理分布式策略DecDNN,本文的主要貢獻總結如下:①一個新穎的分布式DecDNN框架及其實現;②一種自適應模型分割算法(adaptive model cutting algorithm,AMCA);③一種基于全局置亂切分的分布式隨機梯度下降算法;④一種聚合輸出方案。仿真實驗結果表明。與目前先進的協同推理架構相比,提出的DecDNN協同推理策略在降低通信開銷和整體執行時延方面具有良好的性能。
2 系統框架與模型
2.1 網絡模型
傳統的基于“云-邊-端”的DNN協同推理體系結構只考慮順序層次之間的協同推理,該結構雖然能在一定程度上加速DNN推理過程,但加速效果不夠明顯,沒有充分利用邊緣設備的并行特性。因此,提出了一種分布式邊緣集群的網絡模型,如圖1所示,該結構分為三層,設備層是指產生大量數據的IoT設備,邊緣層是指在物聯網網關中部署的一簇邊緣服務器。云中心是大規模數據存儲與分析、智能模型訓練以及對邊緣節點進行管理的云平臺。
首先通過云服務器訓練深度學習網絡模型。通過訓練階段將深度神經網絡模型劃分為兩個模塊。其中部分切片包括靠近輸入數據的較低層,而另一部分模型切片包括靠近輸出數據的較高層。將較低層的部分復制部署到邊緣服務器簇中的每一個服務器,將較高層的部分部署到云端進行協同推理。因此,收集到的數據被輸入到邊緣服務器,數據在邊緣服務器之間進行分割,以并行的方式進行推理。邊緣聚合器從底層加載中間數據,將各個邊緣服務器的輸出進行聚合,然后將聚合后的數據作為上層的輸入數據傳輸到云服務器,云服務器根據邊緣端上傳的數據完成最終任務推理并將推理結果下發到邊緣端。
“云-邊緣簇-端”的模型具有云端的計算與存儲優勢、邊緣端數據的實時性優點,同時將經過邊緣服務器處理的中間數據上傳至云端可以避免數據隱私泄露,降低網絡傳輸帶寬壓力。將終端設備通過低延遲和高帶寬的無線網絡接入到無線接入點AP(access point)。智能主機、邊緣服務器都位于同一個局域網(local area network,LAN)中。而邊界主機和云主機之間通過廣域網相連。
2.2 DecDNN框架
如圖2所示,系統由3部分組成:①建立預測模型,分析DNN模型和節點性能并預測最優分割;②由多個邊緣節點組成的分布式網絡集群;③執行數據分區和模型分區的中間件,分別執行模型分區算法和數據分區算法。
2.2.1 性能預測模型
DecDNN對任意神經網絡架構的每層延遲和能量消耗進行建模。在不執行DNN的情況下估計DNN組成層的延遲和能耗。由于每種層類型與層配置之間的延遲差異較大,因此,為了構造用于每種層類型的預測模型,通過改變該層的可配置參數并且測量用于每種配置的延遲和功耗。使用這些配置參數為每種層類型建立回歸模型,以根據其配置預測層的延遲和功耗。使用GFLOPS(每秒千兆浮點運算)作為性能指標。根據層類型,使用線性函數作為回歸函數。
卷積層、局部層和池化層的可配置參數包括輸入特征映射維度、數目、大小和過濾器的大小。卷積層的回歸模型基于兩個變量:輸入特征圖中的特征數量,以及(濾波器大小)2×(濾波器數量),表示應用于輸入特征圖中每個像素的計算量。對于池化層,使用輸入和輸出特征映射的大小作為回歸模型變量。在全連接層中,輸入數據乘以學習的權重矩陣以生成輸出向量。使用輸入神經元數目和輸出神經元數目作為回歸模型變量。與其它層相比,激活層具有較少的可配置參數,因為激活層在其輸入數據和輸出之間具有一對一的映射關系。
2.2.2 數據隱私保護
首先,DecDNN通過模型分割法將AI模型以水平分割的方式分為兩個部分,一部分在邊緣集群上處理,另一部分在云端處理,由于上傳至云端的數據是經過邊緣集群推理后的中間數據,而非原始終端數據,因此在傳輸過程中不會對原始數據造成泄漏。
其次,全局置亂切分法可以將原始數據集分成若干個子集,每個子集中的樣本都經過置亂處理,從而使得每個子集中的數據都失去了原來的身份信息。即使攻擊者獲取了某個子集的數據,也無法通過這個子集中的數據推斷出其它子集或整個數據集中的數據。因此,全局置亂切分法可以防止攻擊者通過對部分數據的分析推斷出整個數據集的隱私信息。DecDNN框架通過等同于兩次數據加密過程保證了原始數據的安全性。
3 模型與數據分區算法
3.1 深度神經網絡模型劃分算法
DecDNN利用分層性能預測模型,動態選擇最優的DNN模型分割點,首先將目標DNN模型部署到當前網絡的云服務器上,然后運行整個神經網絡,得到神經網絡模型各層的計算量和輸出量。該預測模型根據當前網絡狀態下每個節點的負荷和節點間的數據傳輸速率,結合以上所得到的神經網絡各層的計算量和輸出量,可以在不執行DNN的情況下估計出當前DNN網絡層的最優分配方案。定義模型最佳分割點為p,即在模型第p層將模型分割,目標DNN的總層數為N,每層的配置定義為 {Li|i=1,2,…,n},第i層在邊緣服務器上的運行時間EDi,在云端運行的時間ECi,Dp是第p層的輸出,在特定帶寬B下,利用輸入數據Input,當第p層為模型切割點時計算總的推理時延Ai,p表示為
(1)
當p=1時,表示當前目標DNN模型僅運行在云服務器端,此時EDi=0,Dp-1/B=0,當p=Ni時,表示DNN模型僅在邊緣設備上運行,此時ECi=0,Dp-1/B=0,Input/B=0,此時就可以在給定時延要求下找到模型中的最佳分區點。具體如算法1所示。
算法1:自適應模型分割算法(AMCA)
輸入:N:DNN中層的總數;{Li|i=1,2,…,n}:DNN中的層;{Di|i=1,2,…,n}:每個層的數據大小;B:無線網絡上行鏈路帶寬;Input:數據;latency:時延;f(Lj):測的回歸模型;
輸出:模型最佳分割點p
(1)程序
(2) forj=1,…,Nido
(3) 計算云端運行的時間ECi
(4) 計算邊緣服務器運行的時間EDi
(5) end for
(6) 計算Ai,p
(7) ifAi,p≤latencythen
(8) return 最佳模型分割點,執行模型分割;
(9) end if
(10)end for
3.2 數據分區算法
假設邊緣工作節點中沒有共用內存,只有容量相對有限的本地內存,而訓練數據的規模很大,無法存儲于本地內存,因此需要對數據集劃分。數據分區處理可以提高數據處理和模型訓練的效率,減少計算和存儲資源的消耗,同時也可以有效解決數據隱私和安全問題。
利用全局置亂切分法對邊緣IoT設備產生的原始數據進行隨機置亂,然后按照邊緣設備個數將打亂后的數據順序劃分成相應的小份,隨后將這些滿足邊緣設備本地存儲條件的小份數據分配到各個邊緣設備上。使各個工作節點上的訓練樣本更加獨立并具有更加一致的分布。具體的,假設訓練數據集有n個樣本,簡記為[n]=[1,…,n],每個樣本由d維特征表示,并行環境中有K個工作節點。需要把n個樣本[n]隨機置亂成π([n]),然后基于置亂的結果把數據順序均等地切分成K份,既
(2)
再將其分配到K個工作節點上進行訓練。
基于全局置亂切分的并行隨機梯度下降法如算法2所示,假定目標函數是光滑的,算法的收斂速度為
(3)
其中,n為樣本數,b為小批量規模,S為輪數。
算法2:基于全局置亂切分的分布式隨機梯度下降算法
輸入:訓練數據集樣本n;工作節點數K;
輸出:K份基于置亂的數據集
初始化:初始模型W00,工作節點數K,小批量規模b,訓練輪數S,每輪迭代數T=n/bK
fors=0,1,…,S-1 do
W0s+1=WTS
全局置換:隨機置換數據集,均分成K個局部數據集。
fort=0,1,…,T-1 do
for 工作節點k=1,…,k in parallel do
讀取當前模型Wts
從局部數據集隨機抽取小批量數據Dks(t)
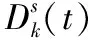
end for
end for
end for
3.3 DecDNN聚合方案
在DecDNN系統中,假設邊緣設備集合為N={1,2,…,n},低層網絡模型在邊緣設備上進行初步推理后得到的中間數據必須進行聚合,以便作為云端模型推理的輸入數據,本文提出了幾種不同的聚合輸出方案,不同的聚合會導致不同的推理精度,最后通過實驗選擇出最優的一種聚合方案。
提出的聚合方案如下:
(1)取最大值法(mc):通過取每個分量的最大值來聚合輸入向量,表達式為
(4)
其中,n表示聚合輸入數據的個數(既邊緣服務器的個數),vij表示輸入向量的第j個分量,Vj表示輸出結果的第j個分量。
(2)取平均值法(pc):通過取每個分量的平均值來聚合輸入向量。表達式為
(5)
這里n是輸入的個數,vij是輸入矢量的第j個分量,Vj是輸出矢量的第j個分量。平均可以減少在某些終端設備中出現的噪聲輸入。
(3)串聯法(cc):串聯法只是將輸入向量連接在一起。串聯法保留所有對高層有用的信息,這些高層可以使用完整的信息來提取更高層次的特征。
4 仿真實驗
4.1 實驗環境
DecDNN框架基于深度學習框架Pytorch實現,使用一臺運行Ubuntu系統的PC機模擬云端運行環境,由5個相同配置的Raspberry PI3模擬邊緣集群,一個交換機和一個路由器分別表示有線連接和無線連接。默認情況下使用路由器。在模擬測試環境上實現DecDNN。測試平臺配置信息見表1。

表1 仿真平臺配置信息
4.2 仿真實驗結果及分析
4.2.1 數據分區驗證
將CIFAR-10數據集的訓練集通過基于全局置亂切分的分布式隨機梯度下降算法進行全局置亂并均等地切成K份子集,分別使用每個子集作為原始數據對網絡模型進行評估和最佳分割點選擇。數據集置亂切分對比結果見表2。為了驗證數據分區算法是否能夠影響DecDNN框架的整體性能,本文通過將全局置亂切分前后的數據分別在5種網絡模型上進行訓練評估,訓練結果見表3。相比普通數據分區,置亂切分數據集的準確率更接近通過原始數據集的訓練的準確率。驗證全局置亂切分數據分區算法能在不影響推理結果的情況下有效解決數據隱私和安全問題。

表2 數據集置亂切分對比
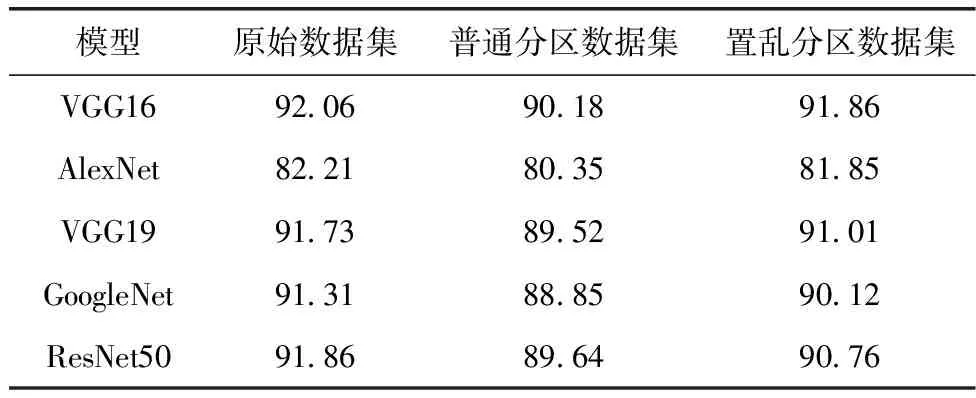
表3 模型訓練準確率/%
4.2.2 對比實驗
將DecDNN與較為先進的兩種協同推理策略進行了比較:Edgent[6]框架和DeepSlicing[12]框架。為了實現3種框架,使用多個Raspberry PI3模擬邊緣環境,帶有Ubuntu系統的PC機模擬云端,默認通過無線網絡進行連接,無線網絡平均傳輸速率為62.3,通過VGG16網絡模型進行框架的評估,實驗過程中,分別在有線和無線情況下測量了每個邊緣設備的平均執行時間和傳輸代價,找到并實現最優的并行執行方式。
模型推理執行時間的比較如圖3所示。Edgent采用基于模型的橫向劃分方法,由單個邊緣設備參與,不需要多個設備的處理和協調,其處理速度比DeepSlicing和DecDNN都快。隨著邊緣設備數量的增加,Edgent的最優劃分點被確定,Edgent的推理時延穩定在一定范圍內不再降低。而在DeepSlicing和DecDNN中,隨著劃分粒度的增大和邊緣設備數量的增加,調度策略可以利用分布式并行執行的優勢,可以協同更多的計算資源進行推理。因此,推斷延遲隨著邊緣設備數量的增加而減小。此外,在不同的邊緣設備數量下,DecDNN比DeepSlicing有更好的推理時延,平均高出約9%。DecDNN在有線和無線網絡連接下都具有更好的推理時延。
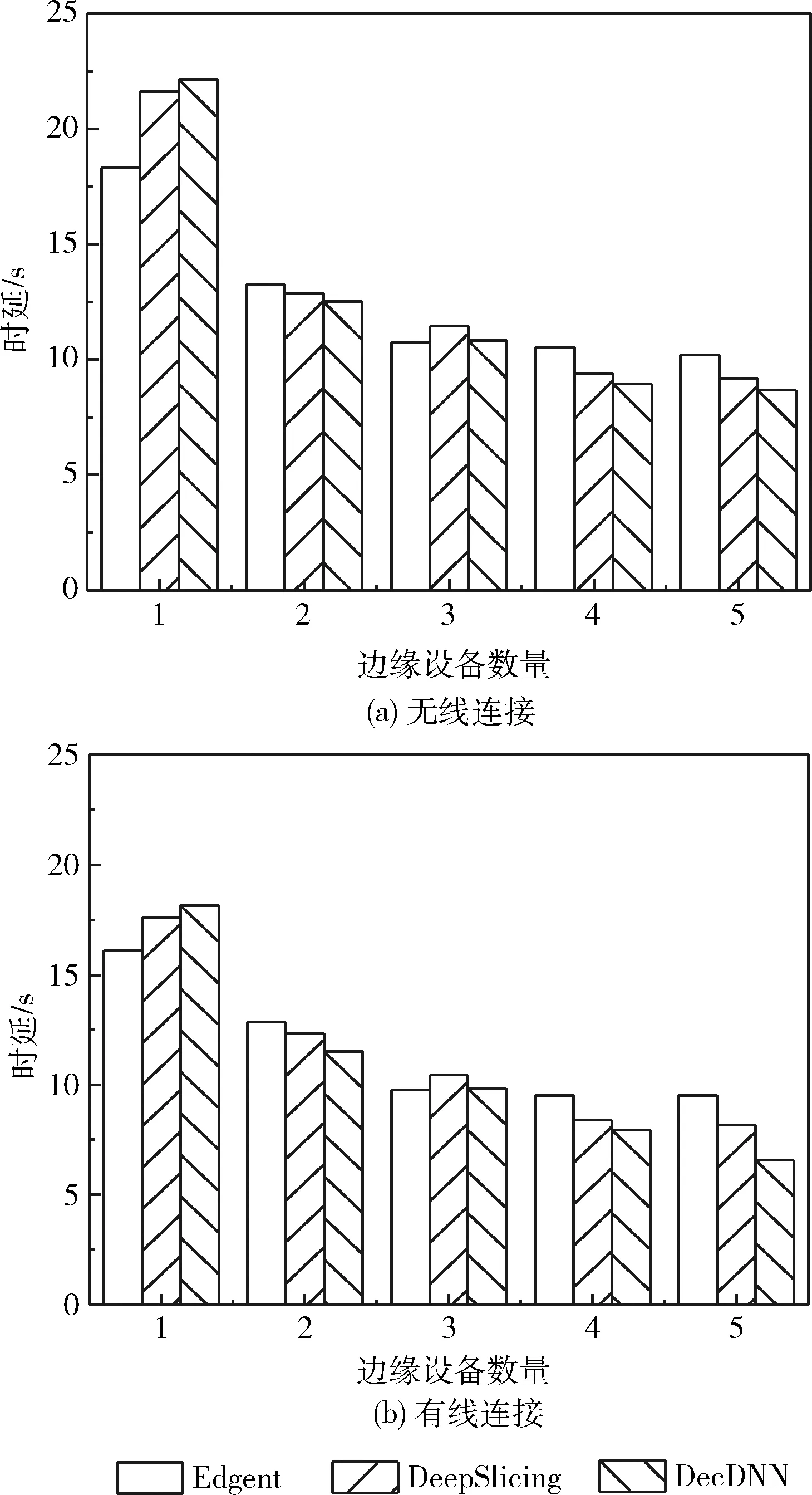
圖3 平均推理執行時間對比
其次,測量了這3種方案的數據通信開銷和總計算時間,如圖4(a)所示,Edgent基于層粒度的劃分方法,其中數據的傳輸量大,通信開銷遠高于其它兩種方法。但如圖4(b)所示,由于Edgent的計算主要在云端運行,因此計算所需時間明顯更小。更多邊緣設備協同完成推斷任務,也意味著邊緣設備之間的總通信開銷增加,總計算時間減少。隨著邊緣設備數量的增加,DecDNN框架擁有更低的數據通信開銷和更少的計算時間。
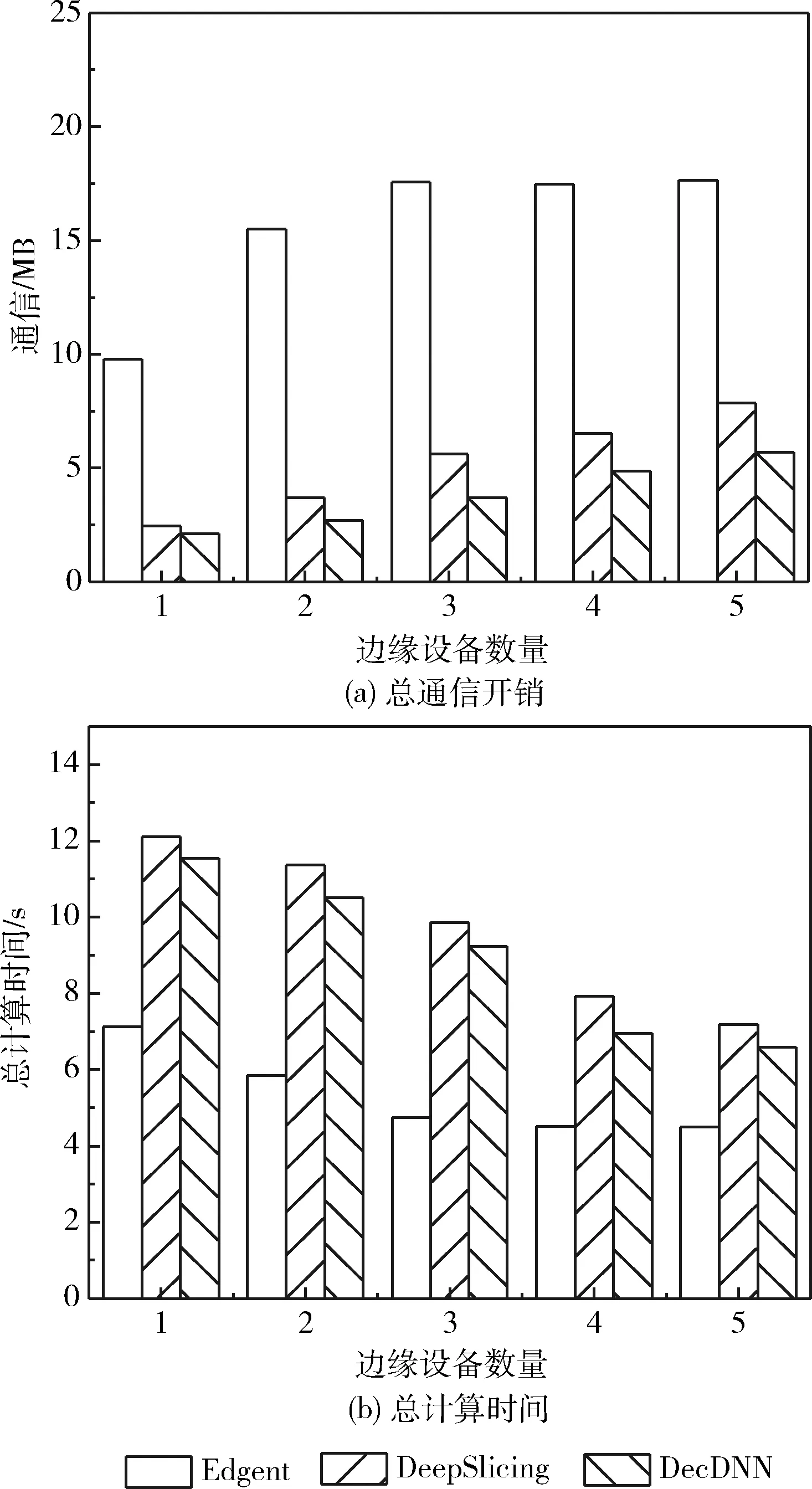
圖4 總計算時間和通信大小的比較
4.3 聚合方案影響
為了得到云端模型推理的輸入數據,必須聚合來自多個邊緣服務器推理得到的中間數據,本文考慮3種聚合方案(取最大值法、取平均值法、串聯法),不同的聚合方案的推理精度見表4。

表4 聚合方案推理精度
本地聚合器向量中的元素對應于相同的特征,因此,取最大值法對應于所有終端設備上的每個類采取最大響應,并顯示出良好的性能。取平均值法表現的性能比取最大值法較差,這是因為一些終端設備在給定幀中沒有對象,而平均值法是取終端設備所有輸出的平均值,這損害了對象所在終端設備的強輸出。連接本地信息不會在多個設備上的同一類的輸出之間強制任何關系,因此串聯法表現的更差,基于這些結果,DecDNN框架中采用了取最大值法聚合方案。
4.4 DecDNN模型評估
實驗分別在本地及不同節點的環境下使用本文的最優分配算法對VGG16網絡模型進行評估。如圖5所示,隨著工作節點數量的增加,用于數據傳輸的時間也會增加,但總體執行時間顯著減少。當工作節點數為5時,整體執行時間已經減少到神經網絡本地執行時間的一半,表現出最佳的優化效果。
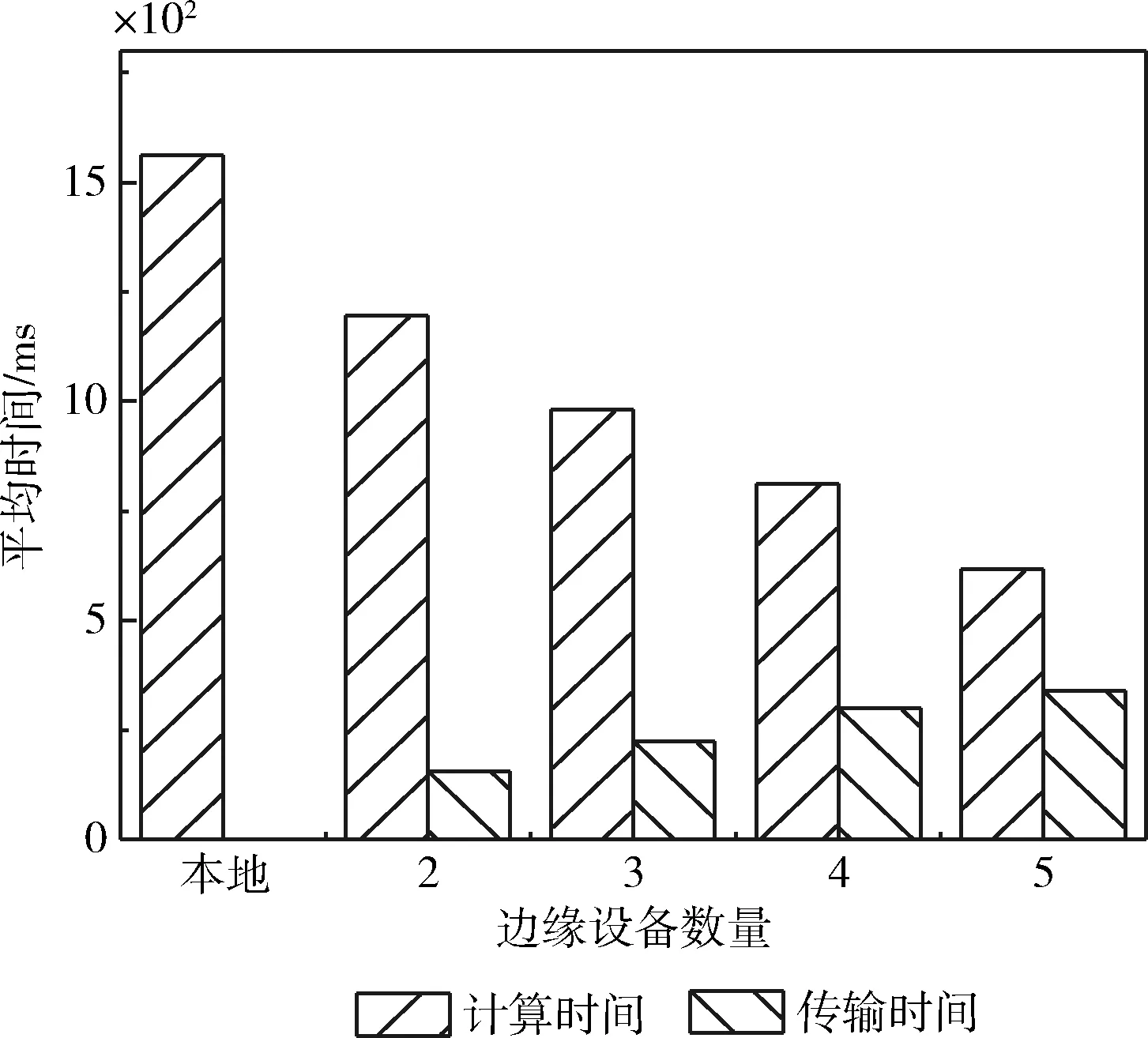
圖5 不同節點下總體執行時間
為了進一步驗證DecDNN框架對不同模型的支持性以及優化效果,仿真實驗比較了4個典型的CNN(AlexNet、VGG19、GoogLeNet和ResNet50)上3個框架的層完成時間。還提供了單機的推理延遲以供比較。使用4個獨立的相同配置的Raspberry PI3作為邊緣服務器。如圖6所示。顯示了DecDNN架構的優勢。當CNN結構簡單時(AlexNet和VGG19),MoDNN的性能優于單機。然而,當CNN結構較為復雜時(GoogLeNet和ResNet50),MoDNN比單機執行表現更差。相反,DecDNN比單個機器、DeepSlicing和MoDNN的性能分別高2.63倍(VGG19)、1.27倍(ResNet50)和2.85倍(ResNet50)。
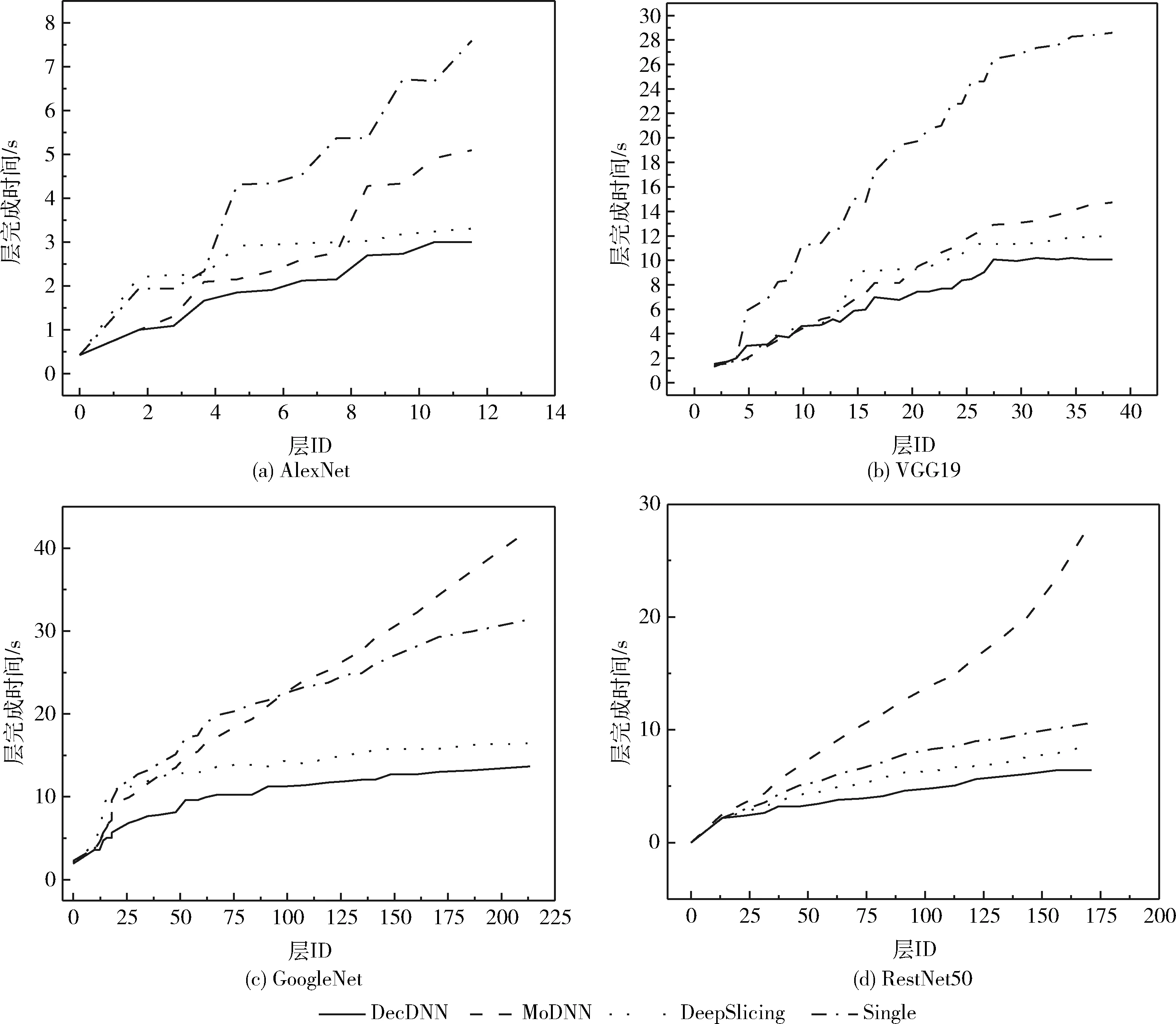
圖6 不同神經網絡模型在多個框架的層完成時間比較
5 結束語
本文深入研究了在具有資源約束的物聯網邊緣部署DNN所遇到的問題,提出了一種邊緣環境下DNN分布式協同推理策略DecDNN。仿真實驗結果表明,與其它調度方案相比,該策略具有良好的推理性能,有效降低通信開銷和整體執行時延,有效避免數據隱私泄露并且能夠支持多種常見的深度學習模型推理。DecDNN策略對于解決智慧城市、車聯網等場景下在資源受限的邊緣設備中部署并執行DNN推理任務的問題具有重要意義,下一步將繼續深入研究如何將DecDNN應用于實際場景中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國特種設備安全(2022年6期)2022-09-20 02:52:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
經濟技術協作信息(2018年22期)2019-01-19 03:00:18
電子制作(2018年11期)2018-08-04 03:26:08
光學精密工程(2016年6期)2016-11-07 09:07:19
工業設計(2016年12期)2016-04-16 02:52:00
核科學與工程(2015年4期)2015-09-26 11:59:03
設備管理與維修(2015年12期)2015-04-09 06:57:00
