基于Q-learning的多業務網絡選擇博弈策略
2023-12-04 12:06:54王軍選
西安郵電大學學報 2023年4期
王軍選,趙 縣,王 穎
(1.西安郵電大學 陜西省信息通信網絡及安全重點實驗室,陜西 西安 710121;2.北京郵電大學 信息安全中心,中國 北京100876)
隨著移動互聯網的蓬勃發展,智能設備和移動應用的數量飛速增長,全球移動數據流量顯著增加,預計到2026年全球移動數據數量相較于2021年將增長6倍以上[1]。學術界和工業界為第五代移動網絡(5th Generation Mobile Networks,5G)提出了兩種解決方案。第一種解決方案是通過改進物理層和介質訪問控制(Medium Access Control,MAC)技術提高許可頻譜利用效率,但當前可用頻偏基本已被分配殆盡。第二種解決方案是將蜂窩通信的帶寬擴展到現有的未許可頻帶[2]。由于WiFi接入點目前被運營商廣泛部署,同時又具有高帶寬、高移動性等特點,用WiFi對蜂窩網絡中的數據進行分流可以解決授權頻段擁擠的問題,因此很多網絡選擇研究將WiFi作為異構網絡提供額外頻譜資源的重要候選者[3]。
目前,在異構網絡中網絡選擇解決方案的研究主要集中在為不同的用戶提供滿足偏好的同時訪問高質量網絡的機會[4]。解決接入網絡選擇的方法可以分為以網絡為中心和以用戶為中心兩種。在以網絡為中心的方法中[5-7],網絡端決策通過集中控制器進行。集中控制器通過用戶報告的本地信道條件,為用戶分配最匹配的服務網絡,這種方法要求系統中各種無線接入網絡之間高度耦合。在以用戶為中心的方法中[8-10],每個用戶根據自己的偏好實現接入網絡的垂直切換,而無需任何信令開銷或不同接入網絡之間的協調,因此以網絡為中心算法的整體吞吐量優于以用戶為中心的算法。由于以網絡為中心的算法需要網絡與用戶協作,因而造成顯著的通信開銷。此外,不同的網絡運營商很少有合作的動機。在以用戶為中心的方法中,用戶自主選擇適合的網絡,可以提供個性化服務。
5G采用以用戶為中心的接入網架構,可以滿足不同的通信需求[11]。文獻[8]提出了一種智能網絡接入策略,考慮了信道狀態和網絡服務質量(Quality of Service,QoS)要求,并根據用戶訪問請求執行網絡選擇。文獻[9]提出了多用戶深度強化學習方案以控制每個集群中用戶之間的切換,首先集中控制器根據移動模式對用戶進行聚類,再使用強化學習為相同群集的用戶獲得最佳切換控制器。在隨機環境中,智能體需要長時間搜索獲得全局最優結果,這會導致收斂緩慢[10]。
針對以用戶為中心的方法網絡吞吐量低、收斂慢的問題,擬提出一種在5G異構網絡場景下,基于Q學習(Q-learning)的多業務網絡選擇博弈(Multi-Service Network Selection Game based on Q-learning,QSNG)策略。該策略將通過模糊推理和綜合屬性評估得到的多業務網絡效用函數作為Q-learning的獎勵,以滿足用戶選網Qos偏好。同時,通過博弈算法預測Q-learning選網收益,從而避免用戶訪問負載較重的網絡。為了驗證QSNG策略的有效性,將其與基于Q-learning的網絡輔助反饋(Reinforcement Learning with Network-Assisted Feedback,RLNF)策略與無線網絡選擇博弈(Radio Network Selection Games,RSG)策略進行比較。
1 系統模型
所提QSNG策略的框架采用兩階段決策過程,包括基于Q-learning的多業務網絡選擇(Multi-Service Network Selection based on Q-learning,QSNS)過程和網絡選擇博弈(Network Selection Game,NSG)兩個過程。QSNG策略流程如圖1所示。

圖1 QSNG策略流程
QSNS針對異構網絡中不同用戶業務需求,利用模糊過程,得到與QoS相關的各屬性權重與各屬性效用函數。根據屬性權重和屬性效用函數計算網絡QoS效用,將QoS效用與網絡價格效用的線性組合作為Q-learning的獎勵。同時,用戶的狀態為用戶所連接網絡的QoS和價格情況,動作為候選網絡選擇。用戶做切換決策之前,首先判斷此時策略是否產生更高選網收益,避免接入狀況較差的網絡。NSG采用了802 .11協議中分布協調功能的思想,通過二進制指數退避策略降低了多個用戶并發性接入某一節點的概率,克服了現有技術中由于未考慮并發性接入導致用戶體驗差的問題。
在分析網絡博弈中,根據MAC協議將吞吐量模型分為吞吐量-公平模型和比例-公平模型[12]兩類。
模型1吞吐量-公平模型。用戶M連接在網絡k上獲得的吞吐量取決于連接到相同網絡的特定用戶的集合,連接到同一網絡的所有用戶實現相同的吞吐量。用戶M連接到網絡k的吞吐量[12]可以表示為
(1)

模型2比例-公平模型。用戶M連接到網絡k上獲得的吞吐量僅取決于共享相同網絡的所有用戶的總數nk,而不是特定的用戶組合。用戶M連接到網絡k的吞吐量[12]可以表示為
(2)
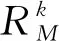
在高斯假設下,吞吐量均值等于實際吞吐量,標準差等于噪聲值e和實際吞吐量的乘積。因此,用戶M連接到網絡k的瞬時吞吐量服從的概率分布為
(3)

將異構網絡中的網絡選擇問題建模為非合作博弈,其中用戶以分布式方式選擇網絡以增加其自身的吞吐量。因此,參與者是用戶集合,策略是網絡選擇結果。
2 相關技術
2.1 模糊推理系統
為了降低模糊規則的復雜性,引入了并行模糊推理系統。對于用戶的不同業務請求先得到用戶對網絡屬性的偏好,再利用模糊邏輯量化用戶的偏好得到網絡屬性的權重。在解模糊過程中,使用模糊評分法將模糊推理得到的模糊數轉換為對應的明晰數。最后,計算出歸一化屬性權重,用于為特定用戶業務計算不同網絡QoS的效用。具體的模糊推理系統過程如圖2所示。

圖2 模糊推理系統過程
QoS效用函數的限制條件如下。
(4)
(5)
(6)
(7)
式中:U(Q)表示QoS效用函數;U(i)表示第i個QoS屬性的效用函數;H表示QoS屬性的總個數;xi表示函數U(i)的自變量。式(5)表明,QoS效用函數中每個決策屬性的效用的單調性與相應的決策屬性效用的單調性一致。
網絡選擇的決策屬性包括QoS和價格,根據決策屬性的效用函數,設計網絡k的網絡選擇模型的表達式[13]為
Uk=ωQ·(Uk(b))ωb·(Uk(d))ωd·(Uk(p))ωp·(Uk(j))ωj+ωc·Uk(c)
(8)
式中:Uk(b)、Uk(d)、Uk(p)和Uk(j)分別表示第k個網絡的帶寬、時延、丟包率和抖動的效用函數;Uk(c)為第k個網絡價格的效用函數;ωb、ωd、ωp和ωj分別表示通過模糊推理得到的網絡業務對帶寬、時延、丟包率和抖動的偏好權重,ωb+ωd+ωp+ωj=1;參數ωQ和ωc分別為QoS和價格的權重,并且ωQ+ωc=1。
2.2 智能網絡博弈
在將Q-learning算法應用于網絡選擇前,需要將系統狀態、動作和獎勵等因素映射到實際的接入模型中,具體的映射過程如下。
1)t時刻用戶i的狀態表示為
(9)

2)t時刻用戶i的動作是從服務列表中選擇合適的服務網絡,其由WiFi1、WiFi2、5G和長期演進(Long Term Evolution,LTE)等4個部分組成。
3)t時刻用戶i的獎勵表示為
(10)
式中,Uk(t)表示t時刻用戶i選擇網絡k的基于業務類型的選網效用。

(11)

將網絡選擇問題建模成非合作網絡選擇博弈,利用NSG策略輔助Q-learning進行網絡選擇,提升Q-learning選網準確性,同時加快收斂速度,文獻[12]證明了NSG策略可以收斂到納什均衡。在任何特定時間內,當通過QSNS選擇的網絡吞吐量大于當前連接的網絡,才進行切換。t+1時刻參與者i從網絡v切換到網絡w,定義預期的切換收益為
(12)

(13)
式中,λ為切換增益閾值,且λ≥1 。
為了提高策略準確性,期望吞吐量應接近可用吞吐量。但是,如果多個參與者同時選擇相同的網絡,則預期吞吐量和可用吞吐量實際值可能相差較大,這將導致不好的用戶體驗。考慮網絡上的并發切換的數量,類似于802.11協議中分布式協調功能中的二進制指數退避,當參與者i發現網絡發生并發切換,則將其并發性接入概率設置為
ρ=ρmi
(14)
式中:0<ρ<1;mi表示參與者i觀察并記錄的過去連續并發切換數量。在QSNG策略中,只有當切換后吞吐量提高并且滿足并發性切換條件時,用戶才會執行切換。
3 仿真分析
3.1 仿真設置
為了驗證策略的性能和穩定性,采用仿真軟件對所提策略進行仿真。仿真環境基于由3種網絡組成的異構網絡區域,設置40個用戶設備(User Equipment,UE)隨機分布在網絡覆蓋區域,具體的仿真環境如圖3所示。
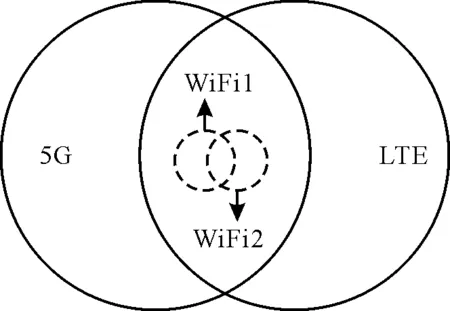
圖3 異構網絡仿真環境


表1 主要仿真參數
為了比較不同網絡選擇策略的公平性,采用被廣泛應用的Jain公平性指數[15],其表達式為
(15)
式中,xi是用戶i的平均吞吐量。根據定義可知,該值越大,說明系統公平性越高。
為了驗證所提策略的性能,將所提策略與以下兩個策略相比。
1)RLNF策略。使用網絡輔助信息改善網絡選擇的性能,該策略收斂于相關均衡,仿真時使用Q-learning模擬強化學習算法。
2)RSG策略。所有網絡都將其業務量信息推送給所有用戶。在每次迭代時,用戶選擇提供最高吞吐量的網絡,該策略收斂于納什均衡。
3.2 NSG策略有效性
通過任選UE3和UE26兩個用戶驗證NSG策略的有效性。兩個用戶的網絡選擇結果具體對比情況如圖4所示。

圖4 兩個用戶的網絡選擇結果
由圖4(a)和圖4(b)可以看出,UE3頻繁地在4個網絡之間切換,而UE26沒有發生顯著的頻繁切換。由圖4(a)和圖4(c)可以看出,當使用了NSG策略之后,UE3的頻繁切換明顯減少,這是由于通過預先評估網絡收益,與其他網絡相比,5G可以提供更穩健的服務。由圖4(b)和圖4(d)可以發現,利用NSG策略可以減少正常用戶UE26接入非最合適網絡的數量并且加速收斂速率。
3.3 業務類型對網絡選擇的影響
以會話業務為例,當只有40個用戶時,近37%的用戶選擇訪問5G。隨著網絡負載的增加,信道資源可能會被耗盡,策略只能滿足最低QoS的要求。因此,訪問5G用戶比例逐漸降低,4個業務的網絡分配比率如圖5所示。

圖5 4個業務網絡分配比率對比結果
由于Q學習的隨機探索和網絡博弈的影響,當用戶數量增加時,圖5(c)中連接到WiFi1的用戶并不總是減少。由于后臺業務的用戶對QoS屬性的要求較低,因此用戶傾向于選擇實惠的網絡,如圖5(d)所示,用戶剛開始就傾向于訪問WiFi1。
總體來說,當用戶數量較少的時候,系統信道資源足夠多,大部分用戶都可以根據自己的偏好選擇適合自己業務的網絡。
3.4 與現有策略的性能比較
為了驗證QSNG策略吞吐量,將所提QSNG策略與RLNF策略、RSG策略等策略的系統吞吐量進行對比,具體如圖6所示。由圖6可以看出,在RLNF策略中,用戶使用網絡輔助反饋更準確地估算其收益函數,由于該策略用戶切換次數很多,因而損失了部分吞吐量。RSG策略能夠準確建模每個用戶的決定對其他用戶的影響。QSNG策略和RSG策略類似,不同之處在于,QSNG策略可以根據實際傳輸情況和用戶業務需求動態地調整信道資源,因此可以獲得較高的吞吐量。由于引入了Q-leaning算法,通過系統學習,當前信道資源被合理地占用,從而減少了信道沖突,提高了信道利用率。

圖6 3種策略的系統吞吐量對比結果
通過Jains指數將3種策略的公平性隨著迭代次數增加的變化趨勢進行對比,從而驗證QSNG策略的公平性。Jains指數對比情況具體如圖7所示。
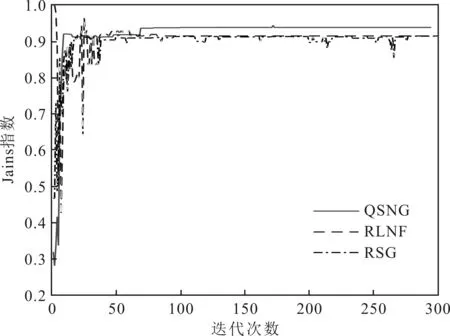
圖7 Jains指數對比結果
由圖7可以看出,由于上述3種策略都收斂于相應的博弈均衡狀態,因此都獲得了非常好的公平性指數。不同之處在于RLNF策略剛開始公平性波動很大,而RSG策略收斂較慢。QSNG策略剛開始就獲得了很好的公平性,而且公平性相比于其他兩種策略來說一直保持在很好的狀態。
對于QSNG策略的穩定性,可以將所提QSNG策略和其他兩種對比策略的切換次數和迭代次數進行對比,3種策略的切換次數對比情況如圖8所示。

圖8 3種策略的切換次數對比結果
由圖8(a)可以看出,3種策略中的用戶都嘗試探索周圍環境以達到最終的選網均衡狀態,每次迭代用戶切換次數越來越少。圖8(b)顯示的切換次數遠遠低于對比策略,而且策略收斂速度最快。在QSNG策略中,用戶可以根據QoS效用和價格函數確定適合其業務的網絡。因此,用戶可根據預測指標訪問更穩定的網絡。此外,用戶可以在執行策略之前預測網絡選擇收益,能夠避免切換到重負載網絡。QSNG策略還利用二進制指數退避策略顯著減少了并發切換,避免網絡擁塞,從而提高了切換增益和服務質量。
4 結語
針對5G異構網絡中多業務網絡選擇的問題,提出了一種QSNG策略。在QSNG策略中,通過模糊過程獲得各種業務對網絡QoS的量化值。然后,將網絡QoS選擇模型與價格決策屬性結合起來以評估備選接入網絡。QSNG策略中引入了強化學習和博弈算法,不僅考慮了服務質量而且還考慮了負載選擇網絡,目的是在滿足用戶QoS偏好的同時最大化平均系統吞吐量。此外,由于博弈算法在選擇網絡之前已經預估了吞吐量情況,因此可以提升強化學習選網準確性,進而加快強化學習收斂速度。QSNG策略還考慮了切換效果和并發性,可以減少不必要的信令開銷并保證切換效果。實驗結果表明,通過使用所提的QSNG策略,在大多數情況下可以通過合理數量的迭代過程實現全局優化。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
