基于困難感知元學(xué)習(xí)和用戶冷啟動的推薦系統(tǒng)研究*
2023-12-09 08:50:32許東升劉傳才
計算機與數(shù)字工程 2023年9期
許東升 劉傳才
(南京理工大學(xué)計算機科學(xué)與工程學(xué)院 南京 210094)
1 引言
傳統(tǒng)的推薦系統(tǒng)通常可以分為基于協(xié)同過濾、內(nèi)容過濾和混合推薦系統(tǒng)。基于協(xié)同過濾推薦系統(tǒng)的研究由來已久,早在1992 年,研究人員利用協(xié)同過濾的方式解決垃圾郵件分類問題[1],其核心思想是:通過收集用戶和物品的相關(guān)性數(shù)據(jù)構(gòu)建評分矩陣,從而優(yōu)先向新用戶推薦評分較高的物品。然而基于協(xié)同過濾的推薦系統(tǒng)面臨著一些難題,如數(shù)據(jù)稀疏性問題和冷啟動問題[2]。數(shù)據(jù)稀疏性問題是指用戶實際消費過的物品只占平臺所有物品中很少一部分,這造成用戶、物品評分矩陣的大部分是缺失的,從而形成一個高度稀疏的矩陣。冷啟動問題是指當用戶和推薦系統(tǒng)之間未發(fā)生任何關(guān)聯(lián)時,用戶、物品評分矩陣數(shù)據(jù)是缺失的,從而影響推薦系統(tǒng)的效果。基于內(nèi)容過濾的推薦系統(tǒng)常被應(yīng)用于電子商務(wù)平臺[3],其核心思想是:通過收集用戶歷史行為、偏好記錄或評分記錄,將用戶、物品的一些特征量化,例如年齡、性別、物品屬性等數(shù)據(jù)。推薦系統(tǒng)通過學(xué)習(xí)用戶這些偏好,將相似物品推薦給相似的目標用戶。然而隨著用戶對隱私泄露擔憂的加劇,通過挖掘用戶歷史數(shù)據(jù)以達到良好推薦效果的方法顯得不合時宜。另外一些推薦系統(tǒng)的作法是將協(xié)同過濾和內(nèi)容過濾兩種方式進行結(jié)合,達到取長補短的目的[4~6]。
近年來,得益于深度學(xué)習(xí)的迅猛發(fā)展,一些基于深度學(xué)習(xí)的推薦系統(tǒng)被提出:Covington 等[7]將深度神經(jīng)網(wǎng)絡(luò)(DNN)融入到了視頻推薦領(lǐng)域中,使用youtube 數(shù)據(jù)做仿真實驗,能夠在大量的數(shù)據(jù)中針對單個用戶進行個性化推薦。Huang等[8]結(jié)合知識圖譜和循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)建立了一種可以實時捕捉到用戶興趣點變化的序列化推薦系統(tǒng),能夠?qū)⒍嘣串悩?gòu)數(shù)據(jù)(圖形數(shù)據(jù)、文本數(shù)據(jù)和視覺數(shù)據(jù))同時輸入到模型,具有較強的融合能力。Van 等[9]提出了基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的推薦系統(tǒng),有效地解決了音樂推薦領(lǐng)域面臨的冷啟動問題。與上述利用深度學(xué)習(xí)構(gòu)建推薦系統(tǒng)的思路不同,一些研究人員嘗試將元學(xué)習(xí)引入推薦系統(tǒng)中,并取得了良好的效果。通常來說,深度學(xué)習(xí)總是從零開始訓(xùn)練,通過在訓(xùn)練數(shù)據(jù)集上的大量訓(xùn)練,以期在測試數(shù)據(jù)集上獲得同樣良好的表現(xiàn)。這樣做的缺點是比較耗時,并且當數(shù)據(jù)集規(guī)模較小時,難以獲得理想的結(jié)果。元學(xué)習(xí)的通常做法是將規(guī)模較小的數(shù)據(jù)集以隨機抽樣的方式切分成許多個任務(wù),經(jīng)過測試集任務(wù)的訓(xùn)練后,模型能很好地適應(yīng)和泛化新任務(wù)。由于這個過程類似于人類利用先驗知識學(xué)習(xí),因此元學(xué)習(xí)也被稱為“Learning to learn”。推薦系統(tǒng)與元學(xué)習(xí)具有相似的特征,專注于使用少量數(shù)據(jù)預(yù)測用戶的偏好。Lee等提出了基于元學(xué)習(xí)的冷啟動推薦系統(tǒng)MeLU[10],通過學(xué)習(xí)用戶的歷史行為數(shù)據(jù)來預(yù)估新用戶的偏好。然而該模型并未考慮任務(wù)間難易程度差異對元學(xué)習(xí)器的影響,導(dǎo)致元學(xué)習(xí)器訓(xùn)練階段處理簡單任務(wù)時表現(xiàn)良好,在處理困難任務(wù)時表現(xiàn)不佳。本文提出一種結(jié)合困難感知元學(xué)習(xí)的推薦系統(tǒng),通過減輕簡單任務(wù)的偏重,加重困難任務(wù)的偏重,避免系統(tǒng)被簡單任務(wù)主導(dǎo),導(dǎo)致“簡單的任務(wù)被很好的學(xué)習(xí),困難的任務(wù)被錯誤的分類”[11]。相較于調(diào)整前模型的性能得到了提升。
2 相關(guān)理論
2.1 MAML
MAML 模型訓(xùn)練過程如圖1,通常由內(nèi)循環(huán)和外循環(huán)兩次循環(huán)構(gòu)成[12]。模型從數(shù)據(jù)集按照設(shè)置的batch size 切分出對應(yīng)數(shù)值的任務(wù),被稱為一批任務(wù)(batch tasks),再按照設(shè)置的比例將一批任務(wù)分為訓(xùn)練數(shù)據(jù)集Dtrain和驗證數(shù)據(jù)集Dvar兩部分,也被稱作支持集(Support set)和查詢集(Query set)。一批任務(wù)訓(xùn)練之后更新外循環(huán)θ為。在一批任務(wù)訓(xùn)練中,模型的隨機初始化參數(shù)θ在支持集的任務(wù)Ti上經(jīng)過訓(xùn)練學(xué)習(xí)更新為θi,將參數(shù)θi作用于查詢集,通過損失函數(shù)衡量初始化參數(shù)在當前任務(wù)上的表現(xiàn),計算??i對參數(shù)做梯度下降優(yōu)化,從而完成一次訓(xùn)練過程。為了簡化模型的計算過程,MAML使用查詢集上的任務(wù)計算損失函數(shù)。

圖1 MAML模型訓(xùn)練過程

圖2 基于MAML的推薦系統(tǒng)MetaCS
Bharadhwaj 等提出了基于MAML 的冷啟動推薦系統(tǒng)MetaCS[13]。主要思想是利用初始化參數(shù)θ,在每一個任務(wù)上進行學(xué)習(xí),這里的任務(wù)表示單個用戶和與之對應(yīng)的歷史行為數(shù)據(jù)。通過在所有任務(wù)上學(xué)習(xí)得到了一個較好的參數(shù)θ*,當遇到新的任務(wù)即冷啟動用戶時,參數(shù)θ*只需要少量的更新就可在處理新任務(wù)時擁有較強的泛化能力,冷啟動用戶也能獲得良好的推薦效果。
2.2 MeLU
Lee 等提出了基于MAML 的推薦系統(tǒng)MeLU[14]抽象如圖3,模型對用戶和電影評分數(shù)據(jù)做向量化操作,作為網(wǎng)絡(luò)的輸入層。衡量用戶的屬性包括性別、年齡、職業(yè)以及郵政編碼。衡量電影的屬性包括發(fā)行年份、評級、類型、導(dǎo)演和主演。該模型對輸入的數(shù)據(jù)做了Task2Vec,將用戶數(shù)據(jù)和對應(yīng)的電影評分數(shù)據(jù)做了連接處理。經(jīng)過網(wǎng)絡(luò)的學(xué)習(xí),給出新用戶所推薦的電影列表。
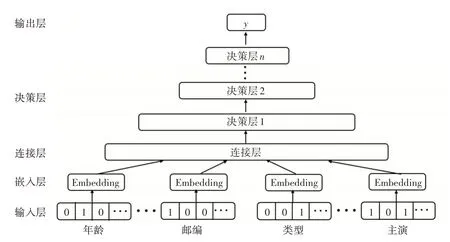
圖3 MeLU模型網(wǎng)絡(luò)結(jié)構(gòu)

圖4 MeLU模型更新過程
MeLU 模型利用嵌入過程來提取用戶、電影評分記錄中的特征,對于輸入的用戶數(shù)據(jù),假定衡量用戶的屬性維度為p,那么用戶i的嵌入向量Ui表示如式(1)。
eip表示用戶i的某個屬性特征對應(yīng)的獨熱碼(one-hot code),cip表示系數(shù);假定衡量電影的屬性維度為q,那么電影j的嵌入向量Mj表示如式(2)。
ejq表示電影j的某個屬性特征對應(yīng)的獨熱碼,cjq表示系數(shù)。由于不同用戶的電影評分記錄長度不一致,從而導(dǎo)致用戶的嵌入向量Ui和電影j的嵌入向量Mj的維度可能是不相等的。因此,MeLU 將決策層構(gòu)建為N層全連接神經(jīng)網(wǎng)絡(luò),而不是使用需要相等嵌入維度的廣義矩陣分解層。輸出層是決策層的后續(xù)層,用來輸出用戶偏好的預(yù)測數(shù)據(jù),在MeLU 模型中,對應(yīng)的是電影的評分數(shù)據(jù)。圖3網(wǎng)絡(luò)表示如式(3)。
x0表示輸入數(shù)據(jù),Wi和bi表示第i層網(wǎng)絡(luò)的權(quán)重和偏置,Wo和bo表示輸出層網(wǎng)絡(luò)的權(quán)重和偏置,y?ij表示模型對于用戶i對電影j的偏好預(yù)測,MeLU 模型使用線性整流函數(shù)(ReLU)[15]作為激活函數(shù)a,線性函數(shù)作為激活函數(shù)σ。式(1)和式(2)里的參數(shù)用θ1表示,式(3)里的參數(shù)使用θ2表示,θ1、θ2的初始化由隨機數(shù)完成。
與MAML 模型內(nèi)外兩次循環(huán)類似,MeLU 模型的更新分為局部更新和全局更新。為了確保學(xué)習(xí)用戶偏好過程中的穩(wěn)定性,局部更新期間不更新用戶和物品的輸入數(shù)據(jù),這意味著模型認為用戶和物品沒有發(fā)生變化。模型根據(jù)用戶獨特的歷史行為數(shù)據(jù)更新決策層和輸出層中的參數(shù)θ2,使用式(4)所示的損失函數(shù)?i對更新后參數(shù)θ2進行評估。
Hi表示用戶i電影評分集合,yij表示用戶i對電影j的實際評分,y?ij表示模型對于用戶i對電影j的偏好預(yù)測。模型在局部更新期間對用戶個性化的偏好進行學(xué)習(xí),訓(xùn)練過程中局部更新次數(shù)可以設(shè)置為一次或多次。局部更新完成之后,模型將更新后的參數(shù)在查詢集計算損失函數(shù),全局更新參數(shù)θ1和θ2。模型重復(fù)上述過程直到θ1和θ2收斂。
2.3 調(diào)整MeLU模型中任務(wù)偏重
元學(xué)習(xí)在處理分類任務(wù)、推薦領(lǐng)域取得了不錯的性能,但存在一個基本問題:如何更有效地將先前任務(wù)中學(xué)到的全局知識,用于處理新的任務(wù)。針對上述問題,研究人員提出了不同的改進方案。Li等[11]提出了更加專注于處理困難任務(wù)的模型DAML,該作者認為由于元訓(xùn)練階段任務(wù)的差異性特征,將導(dǎo)致模型在元訓(xùn)練階段簡單的任務(wù)被很好地學(xué)習(xí),困難的任務(wù)學(xué)習(xí)不足。作者利用任務(wù)的測試損失值的大小衡量任務(wù)困難與否,即將測試損失值較大的任務(wù)視為困難任務(wù),反之亦然。因此,作者調(diào)整了查詢集中任務(wù)偏重,通過降低簡單任務(wù)的偏重,增加困難任務(wù)的偏重,使得模型相比調(diào)整前更擅長處理困難任務(wù)。Muhammad 等[16]提出了任務(wù)無偏的模型TAML,該作者認為由于元訓(xùn)練階段任務(wù)的差異性特征,當模型在處理新任務(wù)時難以保持一致的性能,將導(dǎo)致元學(xué)習(xí)器在更新參數(shù)時難以給出足夠好的更新方案,可能導(dǎo)致在新任務(wù)上泛化能力不夠理想。因此,作者采用最大熵方法和差異最小化方法使任務(wù)盡可能達到無偏的效果。Liu等提出了任務(wù)自適應(yīng)推薦模型TaNP[14],通過引入一種新的任務(wù)自適應(yīng)機制,直接將觀察到的每個用戶的交互映射到預(yù)測分布,回避了基于梯度的元學(xué)習(xí)模型中的一些訓(xùn)練問題,使模型能夠?qū)W習(xí)不同任務(wù)的相關(guān)性,并將全局知識定制為與任務(wù)相關(guān)的解碼器參數(shù),以估計用戶偏好,實證結(jié)果表明,TaNP 對幾個最先進的元學(xué)習(xí)推薦器產(chǎn)生了一致的改進。
DAML 模型利用困難感知的方式提升元學(xué)習(xí)模型學(xué)習(xí)的有效性,即動態(tài)的減輕簡單任務(wù)的偏重,加重困難任務(wù)的偏重,使得元學(xué)習(xí)器更擅長處理困難任務(wù),任務(wù)偏重調(diào)整方法如式(5)。
?Ti表示模型在支持集更新后的參數(shù)在查詢集上計算的損失函數(shù)值,η表示縮放系數(shù),ε表示使得max(ε,1-?Ti)>0 成立的最小正整數(shù),?daml表示經(jīng)過任務(wù)偏重調(diào)整后重新計算的損失函數(shù)值。由于作者使用對數(shù)函數(shù)和指數(shù)函數(shù)對原始的任務(wù)損失函數(shù)進行調(diào)整,造成調(diào)整前后數(shù)據(jù)的非線性。導(dǎo)致在一批任務(wù)損失函數(shù)值相差不大的情況下,難以有效的區(qū)分簡單任務(wù)和困難任務(wù)。鑒于此,本文提出利用式(6)對任務(wù)偏重進行調(diào)整,流程簡述如下:選取一批任務(wù),將初始參數(shù)θ1和θ2輸入,在每個任務(wù)上,根據(jù)任務(wù)在支持集上的交叉熵損失對θ2進行更新,得到對應(yīng)每個任務(wù)的θ2',然后計算θ2' 在查詢集任務(wù)上對應(yīng)的測試損失,利用式(6)對測試損失進行動態(tài)縮放得到?d,然后利用?d更新參數(shù)θ2。上述方法通過動態(tài)地削減簡單任務(wù)所占的不當份額,避免了模型被簡單任務(wù)主導(dǎo),將更多的注意放到處理困難任務(wù)中去。
?Ti表示模型在支持集更新后的參數(shù)在查詢集上計算的損失函數(shù)值,η表示縮放系數(shù),?ˉTi表示模型在查詢集計算出的損失函數(shù)平均值,?d表示經(jīng)過任務(wù)偏重調(diào)整后重新計算的損失函數(shù)值。
3 實驗
3.1 MovieLens數(shù)據(jù)集
本文采用的數(shù)據(jù)集為MovieLens 數(shù)據(jù)集,MovieLens 數(shù)據(jù)集包括MovieLens1M、MovieLens 10M、MovieLens 20M 三個不同的版本。這里采用MovieLens 1M 數(shù)據(jù)集進行測試。MovieLens 數(shù)據(jù)集經(jīng)常用來作為推薦系統(tǒng)、機器學(xué)習(xí)的測試數(shù)據(jù)集。數(shù)據(jù)集包含了用戶個人信息和有關(guān)電影的相關(guān)評分數(shù)據(jù),數(shù)據(jù)集的一些詳細信息如表1所示。

表1 數(shù)據(jù)集的相關(guān)數(shù)據(jù)
實驗數(shù)據(jù)隨機抽取數(shù)據(jù)集中80%的用戶作為現(xiàn)有用戶,其余的作為新用戶。每個用戶的電影評分記錄長度在13~100 之間,在用戶的電影歷史評分記錄中隨機選取10 個作為查詢集,其余的數(shù)據(jù)作為支持集,每一名用戶的電影評分記錄長度從3到90 不等,它將用于模型學(xué)習(xí)用戶的偏好。本文采用歸一化折損累計增益(nDCG)對算法性能進行比較,計算方式如式(7)和(8)所示。
其中Rir表示用戶i對排名r商品的真實評分,U表示測試數(shù)據(jù)中用戶集合,表示用戶i最好的。
3.2 實驗結(jié)果
為了凸顯調(diào)整任務(wù)偏重策略對模型性能的影響,本文實驗中模型的關(guān)鍵參數(shù)設(shè)置和MeLU 原模型一致。決策層為2 層,每層有64 個節(jié)點,嵌入向量的維度設(shè)置為32,超參數(shù)α和β的步長設(shè)置借鑒MeLU模型實驗結(jié)果,分別為5×10-6和5×10-5,局部更新的次數(shù)為1 次和5 次,batch size 和epoch數(shù)分別設(shè)置為32和30。
本文實驗采用nDCG@1 和nDCG@3 作為評估指標。為了比較不同因子對于實驗結(jié)果的影響,實驗中模型局部更新次數(shù)分別在1次和5次的條件下開展。同時,在局部更新次數(shù)保持一致的條件下驗證了縮放因子η的取值對實驗結(jié)果的影響。從表2可以看出,在采用相同評估指標計算的前提下,模型局部更新次數(shù)為5次相比局部更新1次性能有小幅度下降,分析原因是由于模型過擬合導(dǎo)致的,也說明了通過增加局部更新次數(shù)提升模型性能的做法不顯著。在模型局部更新次數(shù)保持一致條件下,隨著任務(wù)偏重調(diào)整系數(shù)η的增大,實驗結(jié)果與Me-LU 模型結(jié)果相比有了明顯的提升,在任務(wù)偏重調(diào)整系數(shù)η取4 的條件下,此時的nDCG@1 表現(xiàn)最佳為0.7827;可以看出,結(jié)合了困難感知的推薦系統(tǒng)相較于原系統(tǒng)性能提升明顯,分析原因是由于元學(xué)習(xí)器通過在困難任務(wù)中學(xué)習(xí),在新任務(wù)良好泛化導(dǎo)致的。在局部更新次數(shù)為5 次,任務(wù)偏重調(diào)整系數(shù)η取3 的條件下,此時的nDCG@1 表現(xiàn)最佳為0.7815;通過分析實驗結(jié)果,可以得出:在相同的實驗條件下,通過增加任務(wù)偏重調(diào)整系數(shù)η,模型評價指標呈現(xiàn)先上升后下降的趨勢。顯然不可能通過一味的增大任務(wù)偏重調(diào)整系數(shù)η從而期望模型性能遞增不減,因為元學(xué)習(xí)器的參數(shù)在收斂后,性能提升將變得困難。在局部更新次數(shù)保持一致的情況下,nDCG@3 的結(jié)果好于nDCG@1,說明隨著推薦列表的增加,推薦模型的性能表現(xiàn)更穩(wěn)定。

表2 模型評分結(jié)果
4 結(jié)語
針對元學(xué)習(xí)推薦模型MeLU 在元訓(xùn)練階段未對任務(wù)間的差異化做出相應(yīng)的處理,本文提出了一種較為可行的任務(wù)偏重調(diào)整方法,減輕了簡單任務(wù)的偏重,增加了困難任務(wù)的偏重。避免了元學(xué)習(xí)器在訓(xùn)練階段處理簡單任務(wù)時表現(xiàn)較好,處理困難任務(wù)時學(xué)習(xí)效果不佳。在Movielens 數(shù)據(jù)集上測試表明,結(jié)合了任務(wù)偏重調(diào)整的MeLU 模型相比改進前在處理用戶冷啟動場景下的推薦問題時性能提升明顯。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業(yè)設(shè)計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
商用汽車(2016年11期)2016-12-19 01:20:16
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
