基于XGBoost的多重加權譜比降噪方法
2023-12-14 10:22:58韓復興宋炳宣陳雨貝吳林駿黃夢婷潘延杰
吉林大學學報(地球科學版) 2023年6期
韓復興,宋炳宣,陳雨貝,吳林駿,黃夢婷,潘延杰
吉林大學地球探測科學與技術學院,長春 130026
0 引言
微動H/V譜比方法(又稱HVSR(horizontal to vertical spectral ratio)方法)是一種快速、經濟的非侵入探測方法,它在城市地球物理勘探中發揮重要作用。1989年日本學者Nakamura[1]率先提出用同一地表測點地脈動水平分量與豎向分量的傅里葉幅值譜比值,即H/V譜比,來估計場地的共振頻率和放大因子。H/V譜比法認為H/V譜比曲線的峰值頻率對應于場地剪切波的共振頻率,通過該頻率可以獲得場地的放大系數和沉積層厚度,進而推測地下地層構造。
微動H/V譜比方法對于劃分土石分界面、檢索剪切波阻抗變化等信息實際應用效果好,且具有便捷高效、勘探周期短的優點。與野外地球物理勘探相比,城市地球物理探測一方面精度要求高,另一方面需要考慮城市復雜的噪聲和人文環境[2-3]。微動H/V譜比方法作為以非地震引起的微弱震動為觀測對象的非侵入探測方法,契合以上兩方面特點,故在城市地球物理勘探中應用較多。但城市中震動干擾因素眾多,如車輛震動噪聲、施工噪聲等,采集的一手譜比數據用于譜比計算效果較差;因此需要對原始的三分量數據進行信噪分析,獲得精細化處理后的優質譜比曲線。
H/V譜比法的數據精細化處理環節可在時域和頻域上分別或結合進行。文獻資料表明,目前國內外基于時域識別瞬態干擾信號多采用長短時窗平均振幅比(short time average/long time average, STA/LTA)方法[4],如:2018年Setiawan等[5]在南澳大利亞州阿德萊德市進行了環境噪聲測量,在此基礎上通過STA/LTA方法排除瞬態干擾,選擇環境噪聲中最穩定的部分,并運用H/V譜比法研究地震場地劃分;張若晗等[6]選用微動H/V譜比法對濟南中心城區的土石分界面展開研究,在計算每個時窗的H/V譜比之前先采用反觸發STA/LTA方法剔除瞬態干擾;在SESAME(site effects assessment using ambient excitations)團隊的H/V譜比技術實施指南中[7],該算法也被推薦用于時窗選擇。
同樣是基于時間域,2016年D’Alessandro等[8]提出通過層次聚類算法實現時窗的自動選擇。該算法通過提取HVSR曲線的自洽聚類來對數據進行處理,消除了STA/LTA方法中閾值和時窗長度選取的主觀因素影響,提高了數據分析的客觀性。
近年,基于頻域的降噪算法也逐漸得到研究者的關注。Cox等[9]提出了一種基于頻域的拒絕算法,在進行計算時,該方法可有效剔除峰值頻率與峰值頻率均值相差過大的時間窗口,對數據進行降噪。Dal等[10]同樣通過譜比曲線峰值提出了對多峰譜比曲線進行降噪的頻域方法。
此外,2015年Liu等[11]結合希爾伯特-黃變換適合處理非平穩信號的特點,提出采用希爾伯特-黃變換來對微動數據進行分析。該方法通過經驗模態分解,將原始信號分解為固有模態函數,并將頻率最高的固有模態函數去除,剩余部分作為微動信號的有效部分進行希爾伯特-黃變換以實現對原始信號的去噪處理。
除了自動降噪算法,還有一些人工方法被用于降噪,例如:根據數據使用帶通濾波器,使用0.5~20.0 Hz的帶通濾波器對福州地區進行微動探測[12];或對圖譜進行目視檢查,手動刪除受局部干擾影響的部分[13]。
上述方法在實際運用過程中均存在面對高噪聲數據信號提取困難、受主觀因素影響大、參數調整困難等問題。對此,本文提出一種基于XGBoost(extreme gradient boosting)的多重加權譜比方法對譜比曲線進行預處理操作,從而實現較高噪聲下的微動信號提取。本方法在訓練集建立后,只需將原始數據讀入軟件即可自動完成信號提取,在提取過程中無需調參,降低了微動數據信號提取的工作量,實現了微動信號噪聲壓制的智能化。
1 算法技術路線
1.1 多重加權譜比算法
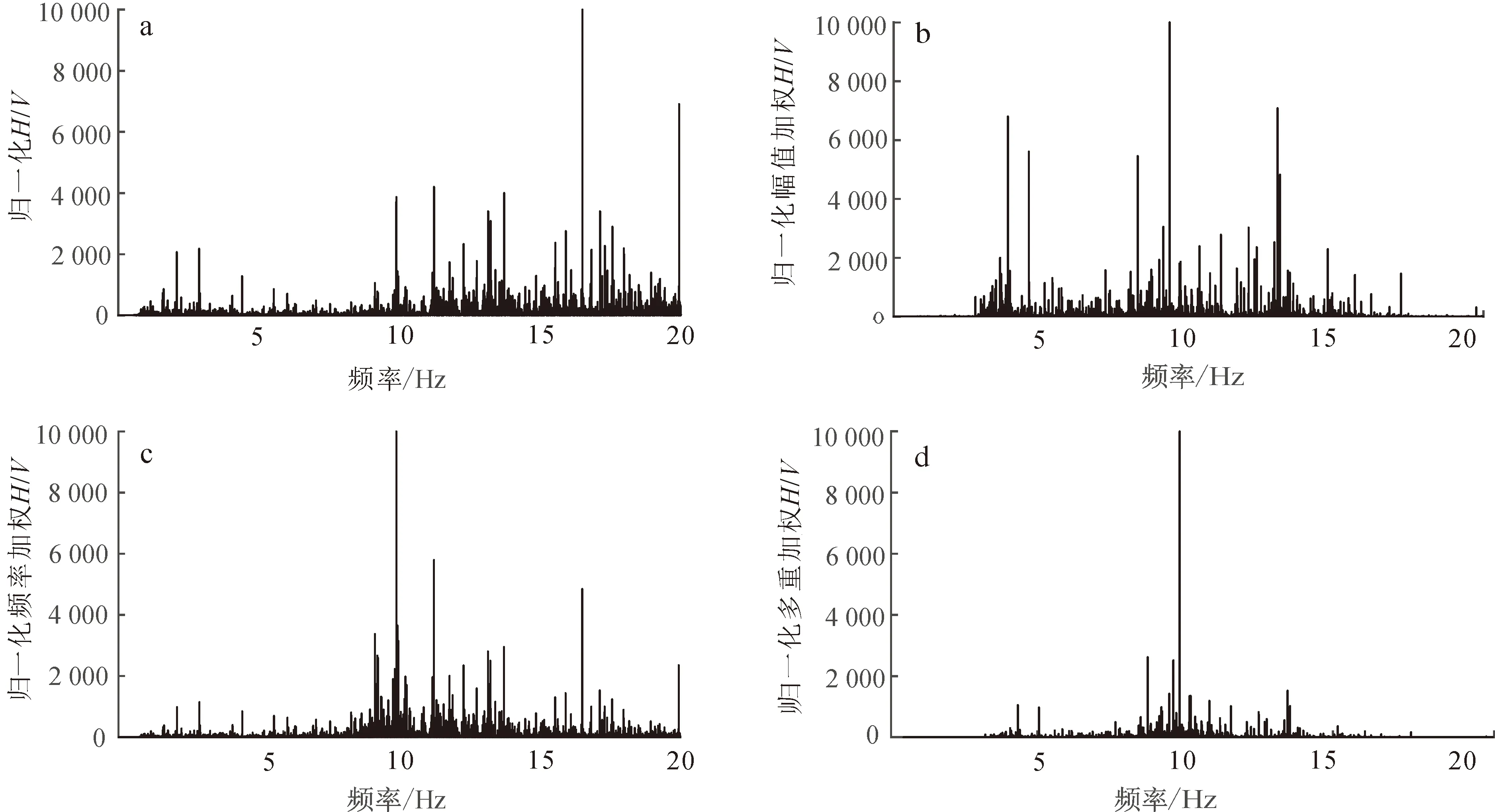
微動數據可用時間序列X(H1,H2,V)表示(H1、H2為水平分量,V為垂直分量)。在數據處理過程中,X應由X′(f,I,H/V)代替(f為樣本點頻率,I為樣本點傅里葉頻譜幅值,H/V為水平分量與垂直分量的傅里葉幅值比)。顯然,僅從X′的3個維度(f,I,H/V)難以直接判斷該采樣點是否為噪聲,故應對X′進行升維,在更高維空間中尋找噪點與信號的特征。
1.1.1 幅值加權譜比
幅值加權譜比可表示為
(1)
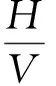
由原始譜比數據(圖1a)與幅值加權的譜比數據(圖1b)對比可見,具備穩定信號且譜比值較大的數據位于幅值加權譜比曲線的頂端。
a. 原始譜比數據;b. 幅值加權譜比;c. 頻率加權譜比;d. 多重加權譜比。
由地脈波穩定、長周期的特點可知,加權譜比應當篩選出幅值穩、譜比接近峰值的采樣點。故引入經驗常數λ,一方面改造了極點,使程序簡單,另一方面符合加權譜比的意義。加權譜比是幅值賦權下的H/V,采樣點的加權譜比值應由幅值與H/V值共同決定,加權后二者對加權譜比的數值影響相當。
1.1.2 頻率加權譜比
常見H/V譜比曲線有個明顯的峰值頻率,單臺數據無法區分微動是由體波還是面波組成,很難判斷H/V峰值是由體波中的剪切波在松散沉積層的共振引起,還是由瑞利面波的極化作用或勒夫波的震相引起。通過Sylvette等[14]的模擬實驗發現,微動H/V譜比曲線峰值頻率與波場組成關系不大,而與松散沉積層的共振頻率相吻合,峰值頻率接近或等于松散沉積層的共振頻率。從場地效應的傳遞函數出發,可推導出H/V譜比曲線峰值頻率與松散覆蓋層的平均剪切波速和厚度的關系如下:
(2)
式中:f0為H/V譜比曲線峰值頻率;vS為覆蓋層平均剪切波速;Dov為松散覆蓋層厚度,可由測井等工程資料直接獲得。H/V譜比曲線關注峰值頻率,故給出頻率加權譜比:
(3)
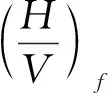
如圖1c所示,在頻率加權譜比曲線中,兼具信號位于峰值信號附近且譜比值較大的數據處于加權譜比曲線的頂端。
1.1.3 多重加權譜比
由式(1)(3),可定義多重加權譜比:
(4)
如圖1d所示,在多重加權譜比曲線中,兼具信號穩定、位于峰值信號附近且譜比值較大的數據處于加權譜比曲線的頂端。
由式(1)(3)(4)可對X′進行升維,得到
由地脈波穩定的特點與HVSR對峰值頻率的需要,可得信號點均位于X″中多重加權譜比曲線的頂端,故經升維后的X″可在此高維空間中將信號與噪聲較好地分離。
1.2 XGBoost算法
(5)
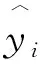
XGBoost旨在通過迭代方式集成弱分類器以形成預測精度和魯棒性更高的模型。每一次迭代都是在前一步的基礎上增加一棵樹,而新增的樹視為擬合上次預測的殘差。迭代過程為:
(6)
目標函數是研究一切機器學習問題的出發點,求解目標函數最低數值即為求解機器學習問題解。XGBoost的目標函數由損失函數和正則項兩部分組成。正則項用于控制模型的復雜度,模型的預測精度由偏差和方差共同決定。由于本研究面向成分復雜、易出現極端數值的微動數據,故需要利用正則項防止模型過擬合:
(7)
式中:T為節點數量;ωj為葉子節點j的分數;γ和ε均為系數。
綜上,XGBoost的目標函數為
(8)
XGBoost采用增量訓練的方式進行迭代,以最大化減小目標函數值。在t輪迭代之后,目標函數更新為
(9)
為了使損失函數梯度收斂更快、更準確,XGBoost利用泰勒展開式對所有二階可導的損失函數做近似替換,目標函數近似為
(10)
將每個數據的損失函數疊加,去掉無關項,得到
(11)
(12)
上述ωj相互獨立,當新增樹的結構已知時,可以求得葉節點對應的最優權重和最優目標函數:
(13)
(14)
在實際運用中,只需保存訓練好的XGBoost模型,并將待預測數據輸入使用即可。
1.3 訓練集建立
幅值在幅值均值附近的信號符合地脈波穩定的特征,實際應用效果顯示,對干擾較大的數據,幅值中位數對幅值均值的衡量效果優于幅值算術平均值的衡量效果;因此,將傅里葉頻譜幅值位于幅值中位數鄰域的信號標注為關注信號。頻率方面,用地層已知的HVSR曲線進行訓練集建立,將f0鄰域內的數據標注為關注信號,對基頻進行重點提取。對地層未知的曲線可選取關注的頻率窗口,如本文采取頻率位于0.05~20.00 Hz之間的信號為有效信號,實現關注窗口的重點提取。綜合上述,幅值與頻率的選取可建立訓練集。
1.4 算法適用范圍分析
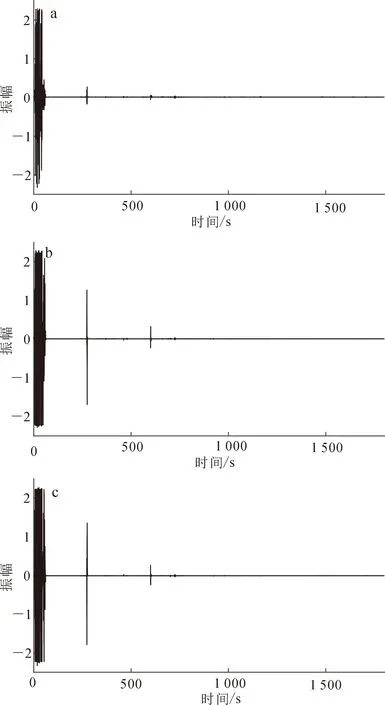
顯然,本算法流程中多重加權譜比算法的建立效果決定了本算法的適用范圍。對于受低頻高振幅噪聲污染嚴重的微動數據,如圖2所示,有效信號幅值遠小于干擾數據幅值,加權譜比算法建立效果較差,難以提取有效信息。
a. 南北方向;b. 東西方向;c. 垂直方向。
2 實測微動數據信號提取分析
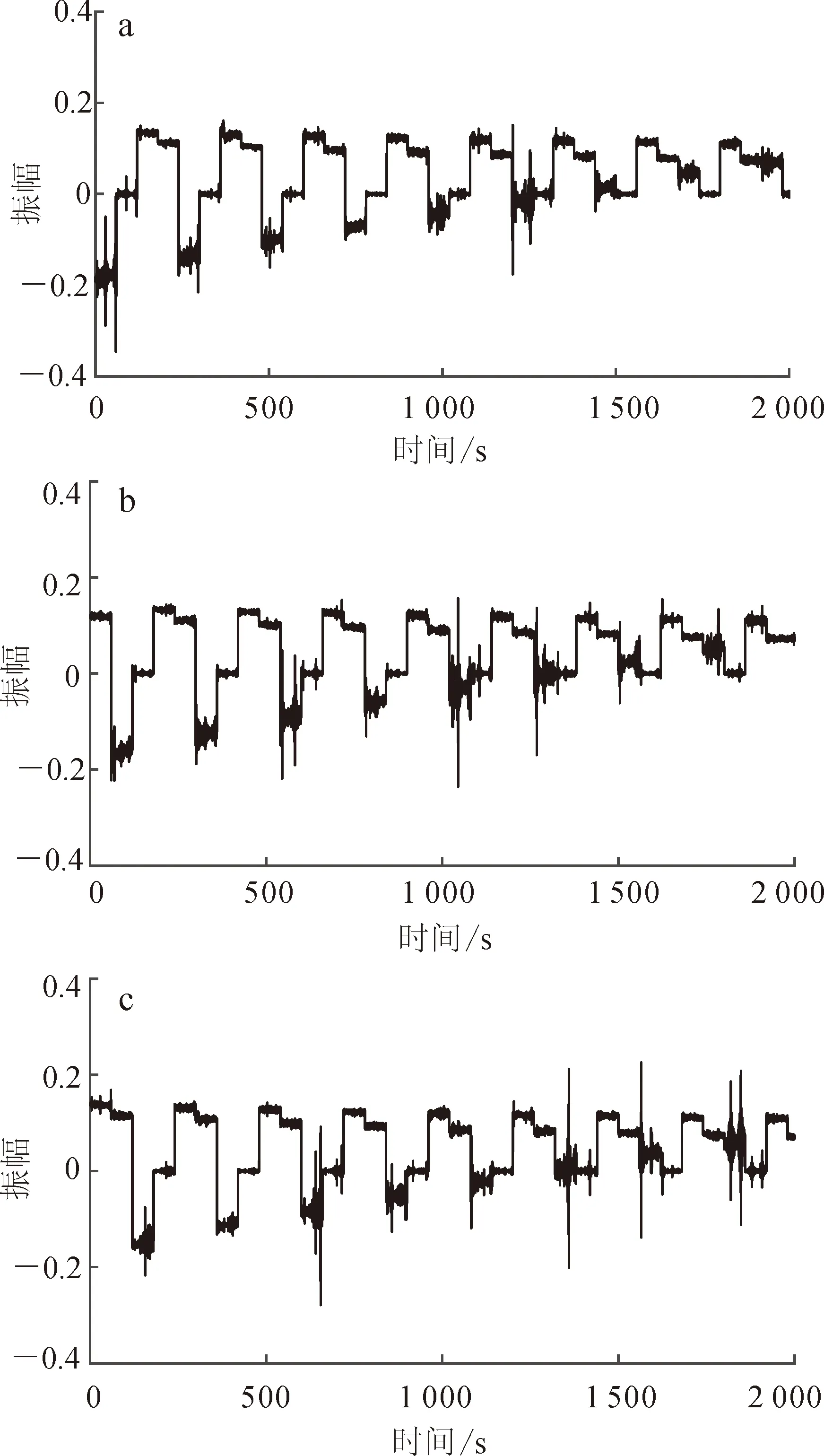
為了檢驗基于XGBoost的多重加權譜比降噪方法的有效性,本文應用該方法與STA/LTA方法分別對吉林大學朝陽校區的微動譜比數據進行處理。朝陽校區臨近文化廣場,有多種文娛活動在此開展,噪聲復雜,干擾較大。圖3為三分量微動儀記錄的原始數據,可見前72 s內信號幅值巨大,72 s后信號幅值難以辨認。圖4為較大干擾事件的局部數據放大圖,可見前72 s干擾嚴重。
a. 南北方向;b. 東西方向;c. 垂直方向。
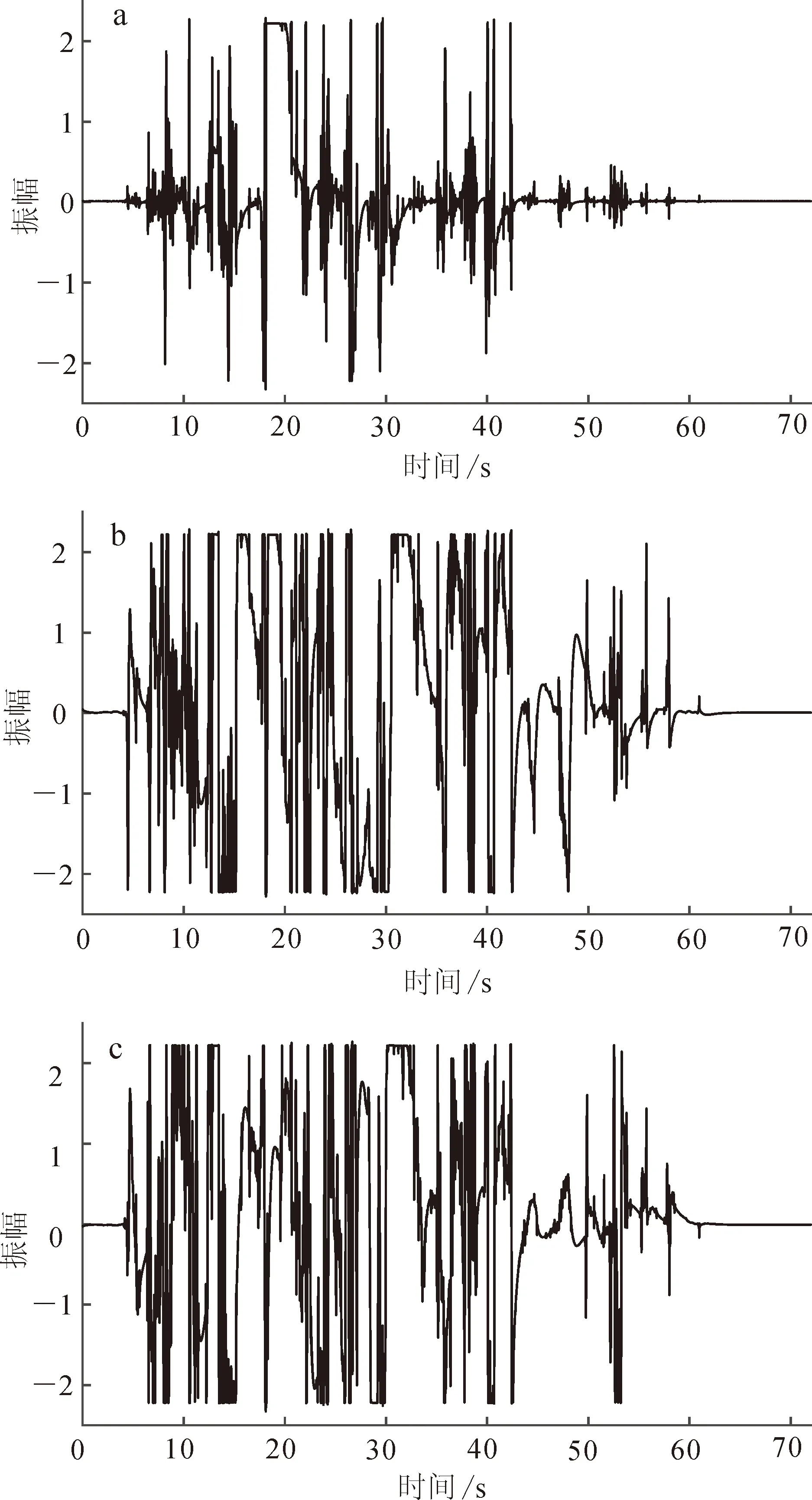
a. 南北方向;b. 東西方向;c. 垂直方向。
圖5為STA/LTA方法篩選后的時間序列數據,可見前72 s存在的大振幅干擾事件并沒有被去除,這是STA/LTA方法固有缺陷所導致的。在STA/LTA方法中,閾值的設定和時窗的選取具有主觀性且對降噪效果的影響較大。閾值和時窗主要基于統計規律來確定,當高振幅噪聲持續時間較長、超過長時窗所截時段,且閾值選擇較高時,該噪聲難以被去除。而時窗選擇過長,閾值選擇較低,可能導致有效信息不足。在該組數據的處理中,前72 s內的噪聲持續時間長、振幅大,故STA/LTA方法難以去除,且過濾了較多有效信息,導致譜比曲線峰值不清晰。
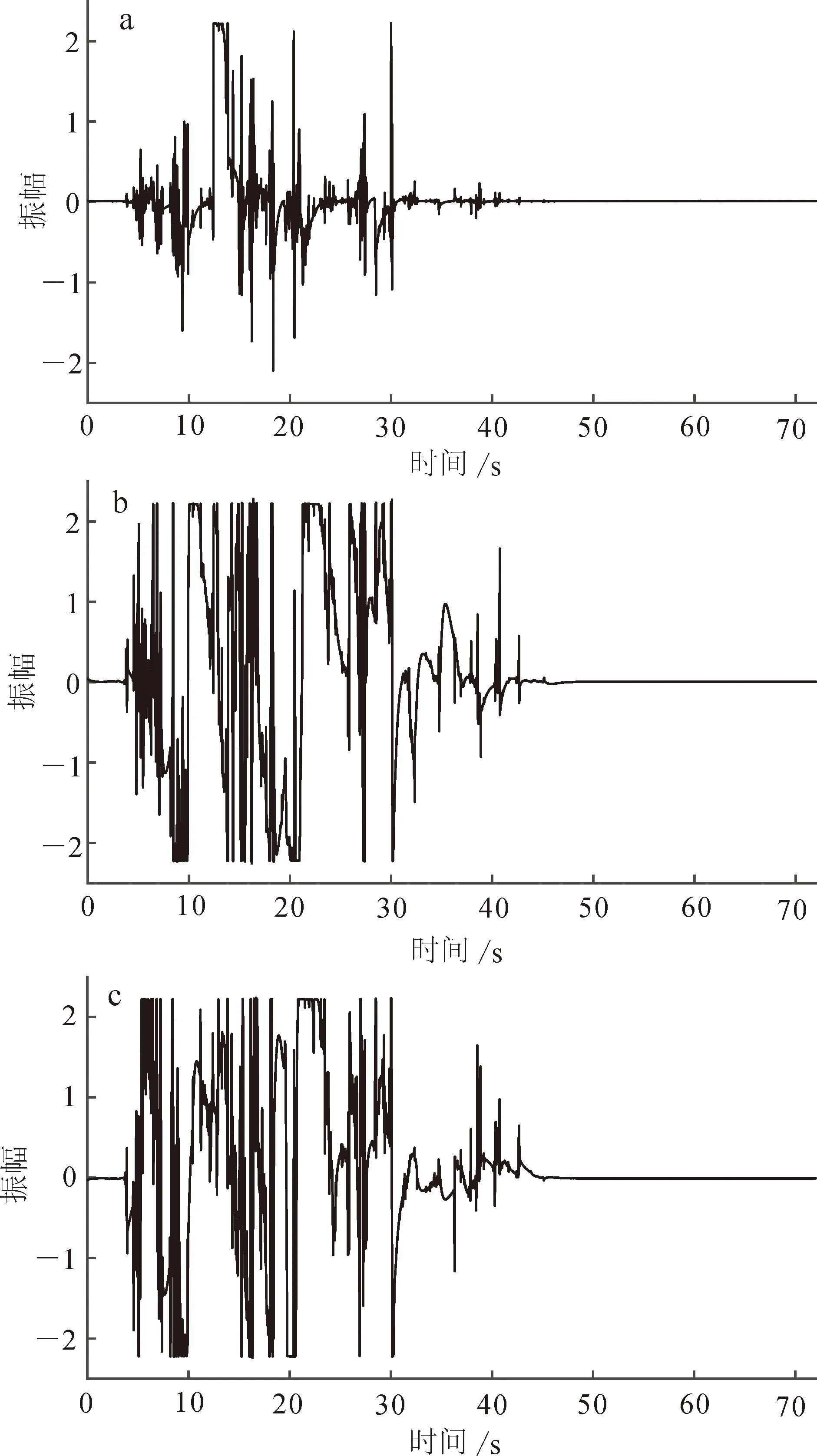
a. 南北方向;b. 東西方向;c. 垂直方向。
分別對該信號利用STA/LTA方法與本文方法進行信號提取,圖6為兩種方法提取結果的譜比曲線。可見本文方法基頻峰值與高頻的譜比峰值均得到有效提取,SLA/LTA方法難以識別曲線峰值。在面對較復雜環境時,STA/LTA方法難以識別微動信號中的有效數據,導致譜比曲線峰值無法識別,本文方法可清晰識別譜比曲線峰值。
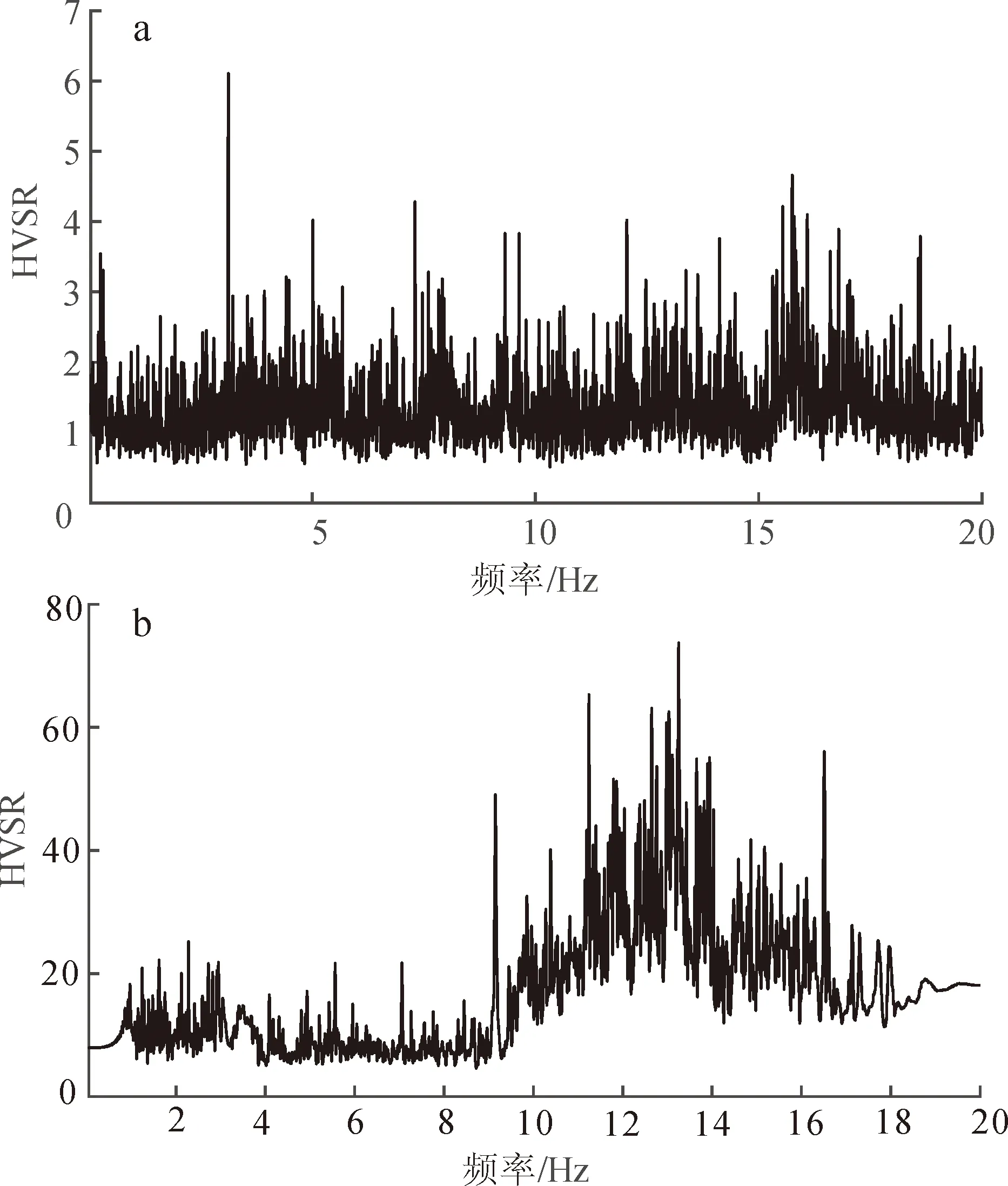
圖6 STA/LTA方法(a)與多重加權降噪方法(b)譜比曲線對比
在智能化程度方面,相較于STA/LTA方法需要依靠經驗判斷時窗與閾值,本文方法在模型訓練結束后,無需調整任何參數即可實現信號提取,實現信號提取智能化,增加提取結果客觀程度,減少因調參產生的主觀性和不確定性。
在算法效率方面,使用平臺為AMD RyzenTM7 5800H 3.2 GHz。由于本算法的計算時長主要取決于使用模型大小,以16 GB模型為例,本文方法用時728 s,STA/LTA方法用時28 s。雖然用時大幅上升,但STA/LTA方法無法處理上文中的高噪聲微動數據,且本文方法使用時無需調參,更為智能化。
3 結論
1)本文針對復雜環境下高噪聲微動數據的降噪需求,提出了基于XGBoost的多重加權譜比降噪方法。
2)對高噪聲的實際數據應用顯示,本文方法信號提取的準度優于STA/LTA方法。同時,本文方法在模型訓練完畢后無需調整參數,在智能化程度上也優于傳統STA/LTA方法。但本文方法訓練模型較大,耗時較長,在干擾信號振幅大于微動數據振幅時方法失效。
針對本文方法的缺陷,未來將重點研究干擾信號振幅大于微動數據振幅的強干擾數據信號提取,并加入并行算法,使現有方法運行效率更高。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國生殖健康(2019年3期)2019-02-01 06:12:26
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
