面向雷達多目標跟蹤應用的專用片上系統設計
2023-12-20 02:27:06王榮陽曲國遠徐佩園
計算機工程與設計 2023年12期
王榮陽,曲國遠,童 歆,徐佩園,李 威
(中國航空無線電電子研究所 電子部,上海 200233)
0 引 言
雷達多目標跟蹤應用的核心問題是對多傳感器在某時刻獲取的多目標點跡信息進行點跡-航跡關聯,并判斷各點跡與航跡的關聯效果[1]。目前主流的關聯處理算法為最近領域類算法[2],此類算法先對點跡航跡坐標進行大量雙精度歐式距離計算,然后通過條件比較、強數據關聯運算對關聯結果進行判斷。這類算法專有的數據流通路和對算力的高要求導致其使用通用處理器(CPU)和圖形處理器(GPU)實現運算效率不高[3,4]。這是因為CPU擅長管理和調度,比如數據讀取、文件管理、人機交互等,面對稠密計算的數據處理應用,CPU的固有優勢無法發揮出來。而GPU擅長規則化的單指令多數據并行處理,沒有為多目標匹配算法設計專有數據通路和訪存通路,且硬件底層細節隱蔽,面對專用加速時能效比不高。在目標數量較多時,傳統處理平臺對于算法的整體處理延時較大,導致系統感知能力變弱。
本文借鑒領域專用處理器的設計思想[5,6],通過對雷達多目標點跡-航跡關聯算法的分析,設計了一種低延時專用片上系統,該片上系統由主處理器和專用加速器構成,通用主處理器用來處理算法中數據、指令收發、判斷、分支跳轉操作,專用加速器對算法中的主要計算瓶頸如統計距離計算和多目標匹配進行加速,在FPGA平臺上設計、優化片上系統并驗證了專用加速器對于這類應用的有效性,為后續的領域專用計算架構設計思想、方法奠定了基礎。
1 問題分析
多目標跟蹤的核心是進行目標點跡和航跡關聯,這是一個在復雜約束條件下進行組合優化得到最優解的問題[7]。點跡航跡關聯算法分為統計距離計算、篩選、多目標匹配、整合4個步驟,如圖1所示。
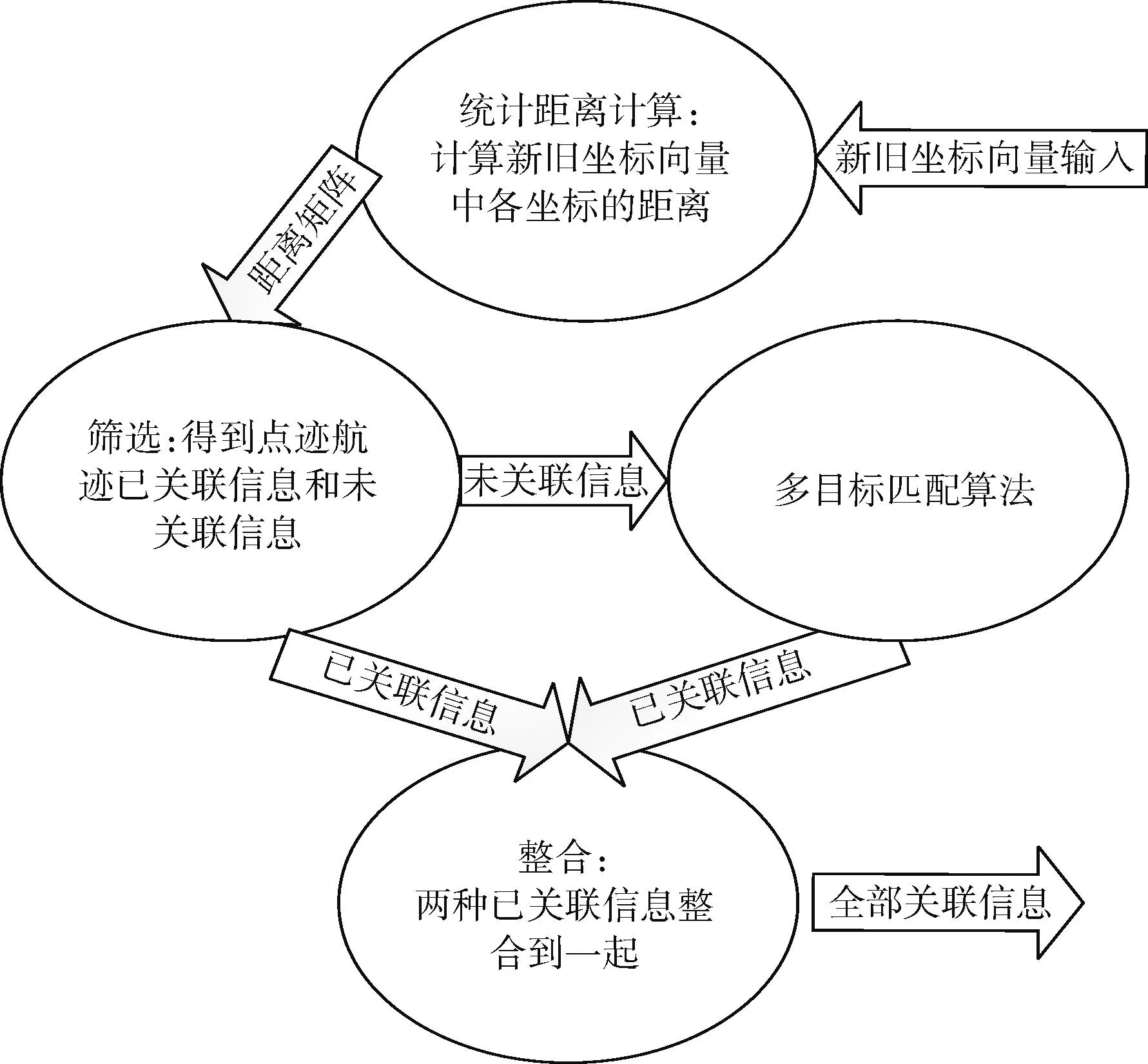
圖1 點跡航跡關聯算法流程
其中,統計距離計算將多個傳感器新探測到的目標點跡坐標與已知航跡坐標按照預定公式進行運算,得到統計距離矩陣,涉及大規模矩陣運算;篩選是將統計距離矩陣的所有元素進行閾值比較、條件篩選,得到一批已關聯上的點跡航跡信息和一批未關聯上的點跡航跡信息;多目標匹配將未關聯的點跡和航跡通過匹配算法進行處理,得到最優的點跡航跡關聯信息;整合是將前兩步的已關聯信息整合到一起,送給后續步驟進行航跡生成或更新。
在整個多目標點跡航跡關聯算法的運行過程中,統計距離計算和多目標匹配是最耗時的兩個步驟,涉及到定制化的大規模矩陣運算以及重復迭代運算,適合專用加速處理;而篩選和整合運算量不大,但涉及到分支判斷跳轉等操作,適合采用通用處理器處理。
目前針對特定算法設計專用加速器有兩種常用的方案,一種是在輸入輸出接口處放置硬件加速器的方式,數據在輸入到輸出的過程中即完成運算,這種類型的加速器稱為通道加速器。例如,文獻[8]中設計了基于以太網口的多核并行CNN硬件加速器,利用運算器內嵌緩存、運算過程分割和數據復用,減少運算器和存儲器之間的數據交互,提高CNN運算的并行度,提升了訓練和推理效率。另一種為協處理器方案,將加速器嵌入主處理器的內存或流水線中,通過自定義指令的形式來調用,實現主處理器與協處理的緊耦合。文獻[9]中基于RISC-V(reduced instruction set compute-V)擴展指令集設計實現了一個低功耗嵌入式卷積神經網絡協處理器,該協處理器內核擴展4條自定義神經網絡指令,最大程度復用了原RISC-V的數據通路和功能模塊,減小了額外的功耗和芯片面積等資源開銷。
面向算法的不同特征,合理采用不同的硬件加速器設計方案可以最大程度的對算法定制化加速,提高運算效率。根據對點跡航跡關聯算法和硬件加速器方案的分析,對于統計距離計算和篩選步驟中的閾值比較部分,本文將設計多運算單元的通道加速器實現并行加速,運算結果交由主處理器調用;對于多目標匹配算法將設計RISC-V自定義擴展指令及對應協處理器完成對算法的細粒度加速。第2節將對這兩種硬件加速器設計進行詳細闡述。
2 片上系統設計
面向多目標跟蹤應用的低延遲專用片上系統主要由3部分組成,即主處理器、用于統計距離計算的通道加速器、用于多目標匹配算法的自定義指令協處理器,片上系統的整體架構如圖2所示。
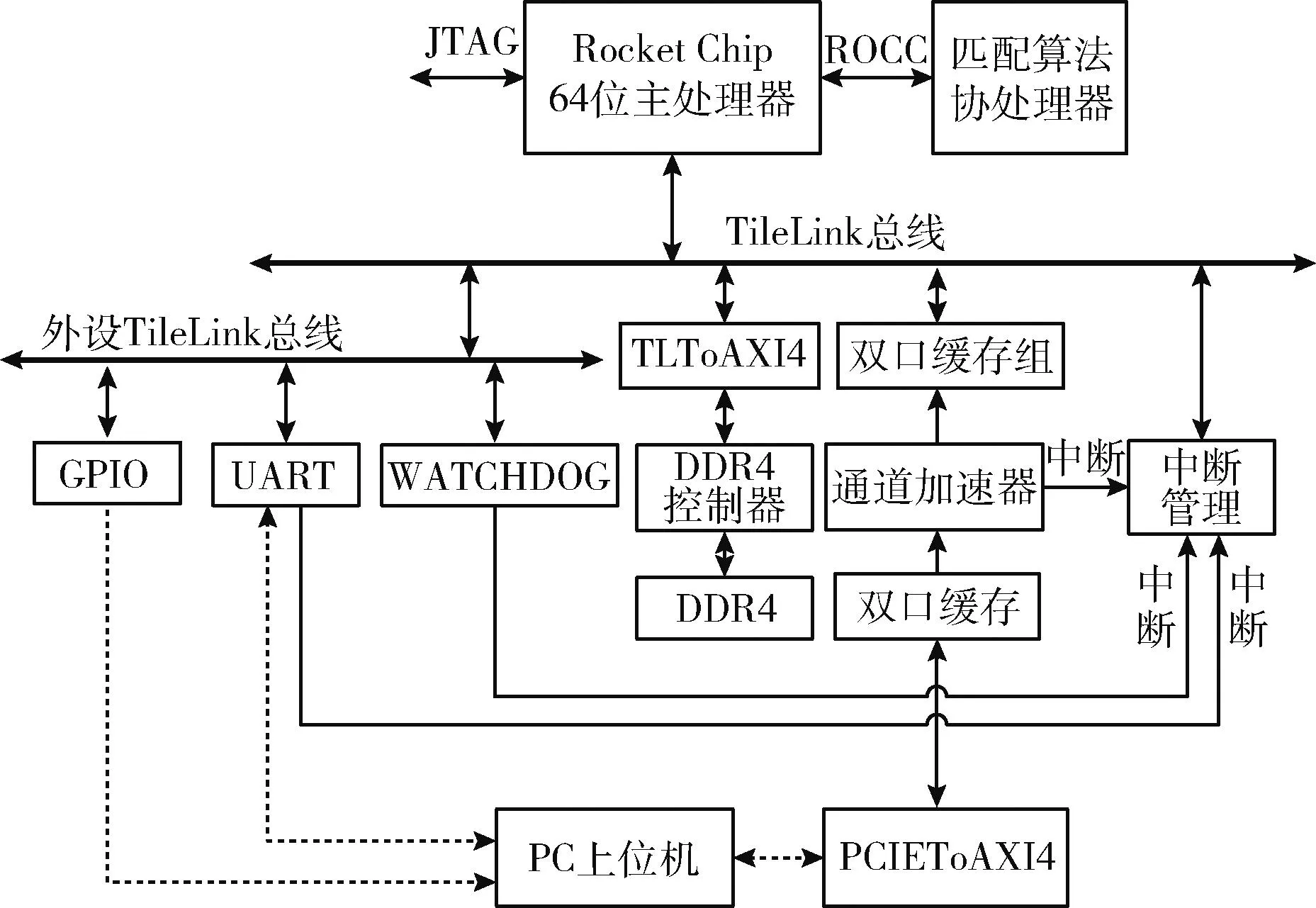
圖2 面向多目標跟蹤應用的專用片上系統框架
RISC-V作為一款新型指令集具有輕量化、開發效率高等特性,自提出至今,得到越來越多的應用[10,11]。RISC-V指令集創新性地提供了4類自定義指令格式,允許片上系統開發者按照需求設計相關的協處理器電路,實現主處理器和協處理器的緊耦合。通過設計自定義指令及對應協處理器,開發者可以容易的在復雜算法代碼中插入對應的自定義指令,從而實現對算法的細粒度加速。本文在伯克利官方開發的開源RISC-V架構片上系統生成平臺Rocket Chip[12]上設計實現片上系統,同時在處理器內配置浮點運算單元(float processing unit,FPU)。主處理器與協處理器之間通過RoCC接口實現緊耦合,RoCC接口用于主處理器與協處理器間的通信以及協處理器對內存的訪問。為了提高協處理器的數據存取效率,將一級數據緩存配置成Scratchpad的形式,即作為一塊有地址的片上存儲使用。此外片上系統還配置了用于數據存儲的DDR4控制器、用于與上位機通信和調試的UART接口、PCIE接口以及用于向上位機發送計算完成信號的GPIO接口。
片上系統的運算流程如圖3所示:PC上位機將不同傳感器的多個目標坐標由PCIE總線發送至片上系統的PCIEtoAXI4接口處理模塊,通過內部AXI4總線將數據存儲至雙口緩存中。數據接收完成后通道加速器開始進行統計距離計算,同時將有效的結果由寫入雙口緩存組,通道加速器計算完成后通過中斷管理模塊向處理器發送中斷信號。主處理器收到中斷信號后開始執行篩選運算。當執行到可以進行協處理器加速的多目標匹配計算步驟時,主處理器會向協處理器發送自定義指令,協處理器接收到自定義指令后開始啟動相應的計算,通過RoCC總線從內存中讀取數據并進行流水線計算,計算結束后將結果寫回內存固定位置。根據RoCC接口的定義,主處理器在等待協處理器的過程采用了寫回目的寄存器的方式,這種處理方式主處理器會暫停運行,關閉流水線,直到協處理器完成工作寫回目的寄存器后再開始工作。全部算法運行完成后,主處理器通過GPIO通知PC上位機將結果取回。
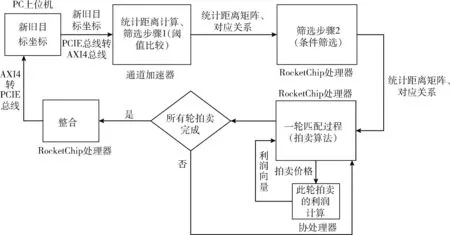
圖3 面向多目標跟蹤應用的專用片上系統數據流程
2.1 主處理器配置與設計
本設計中主處理器核需要處理浮點比較、浮點加減等運算,且算法中產生的中間數據比較多,因此配置主處理器核時需要較高的性能、較大的內存容量以及浮點運算單元。為了使用協處理器加速多目標匹配階段的運算,還需配置協處理器RoCC接口。主處理器與協處理器的耦合關系框架如圖4所示,當主處理器收到自定義擴展指令后會在寫回階段將該指令通過擴展指令發送模塊發往協處理器。協處理器端指令響應和解碼模塊負責接收和解碼對應的指令,運算控制邏輯模塊控制計算模塊與內存控制模塊從內存中讀取、寫入相應的值。由于協處理器和主處理器都會訪問內存,故設置一個仲裁模塊來仲裁二者對內存的訪問權限。
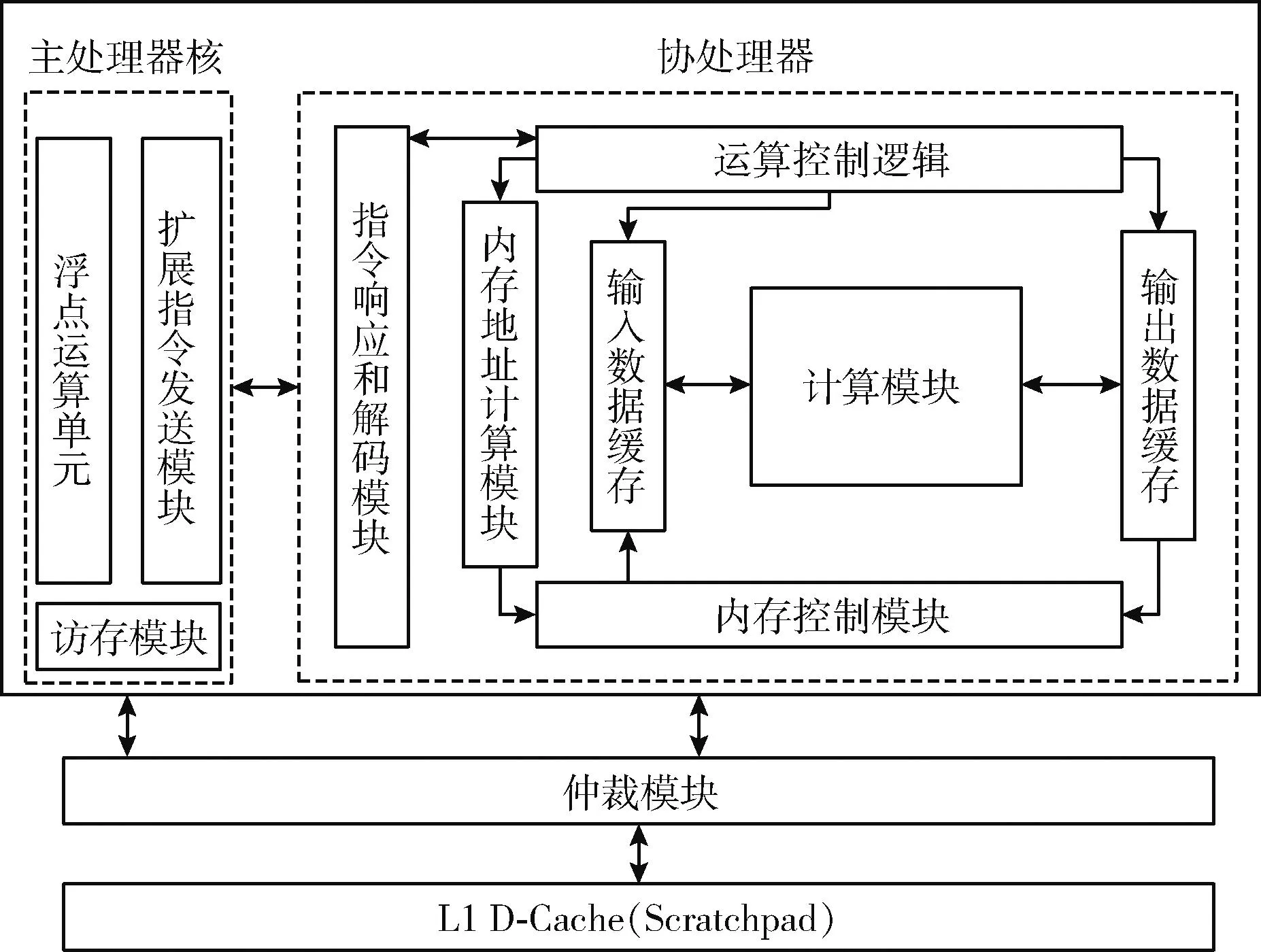
圖4 主處理器與協處理器耦合關系框架
主處理器采用基于RISC-V指令集的開源處理器核Rocket Chip。RISC-V擴展指令集定義的標準擴展指令中,“I”表示基本整數操作,包含整數計算、load、store和控制流指令,RV64代表整數寄存器寬度為64位,“M”表示標準整數乘法和除法擴展,“A”代表標準原子指令擴展,“F”代表標準單精度浮點擴展,“D”表示標準雙精度浮點擴展,一個基本整數內核加上這4個標準擴展(“IMAFD”)組成一個通用的標量指令集。本文采用RV64IMAFD架構,主要參數配置見表1。
RISC-V自定義指令的格式如圖5所示,各個字段的含義可參考文獻[13]。當一條指令進入流水線被解碼后,主處理器會判斷這條指令的格式是否為自定義指令,而后其會在執行完這條指令后保證這條指令之前的指令執行完畢,如果xd為1,則在這條自定義指令執行完成發往RoCC接口后關斷流水線,如果xd為0則在自定義指令后繼續執行。

表1 主處理器核參數配置
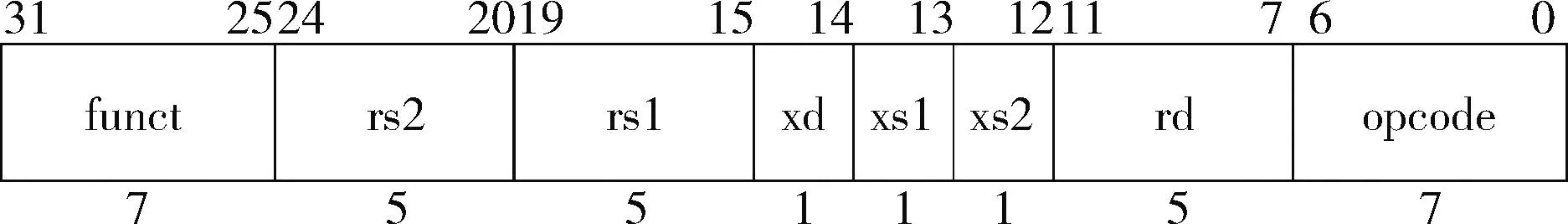
圖5 RoCC自定義指令格式
2.2 通道加速器架構設計
通道加速器特指一類在數據輸入輸出通路上進行計算的硬件加速器,輸入數據經過該類加速器后可直接獲得的預期的運算結果。本文通道加速器的結構如圖6中虛線框內所示,該通道加速器依附于輸入數據通道,主要由多路分配器、控制邏輯、乒乓緩存、10個通道計算單元以及與每個通道計算單元對應的3個雙口緩存組成。
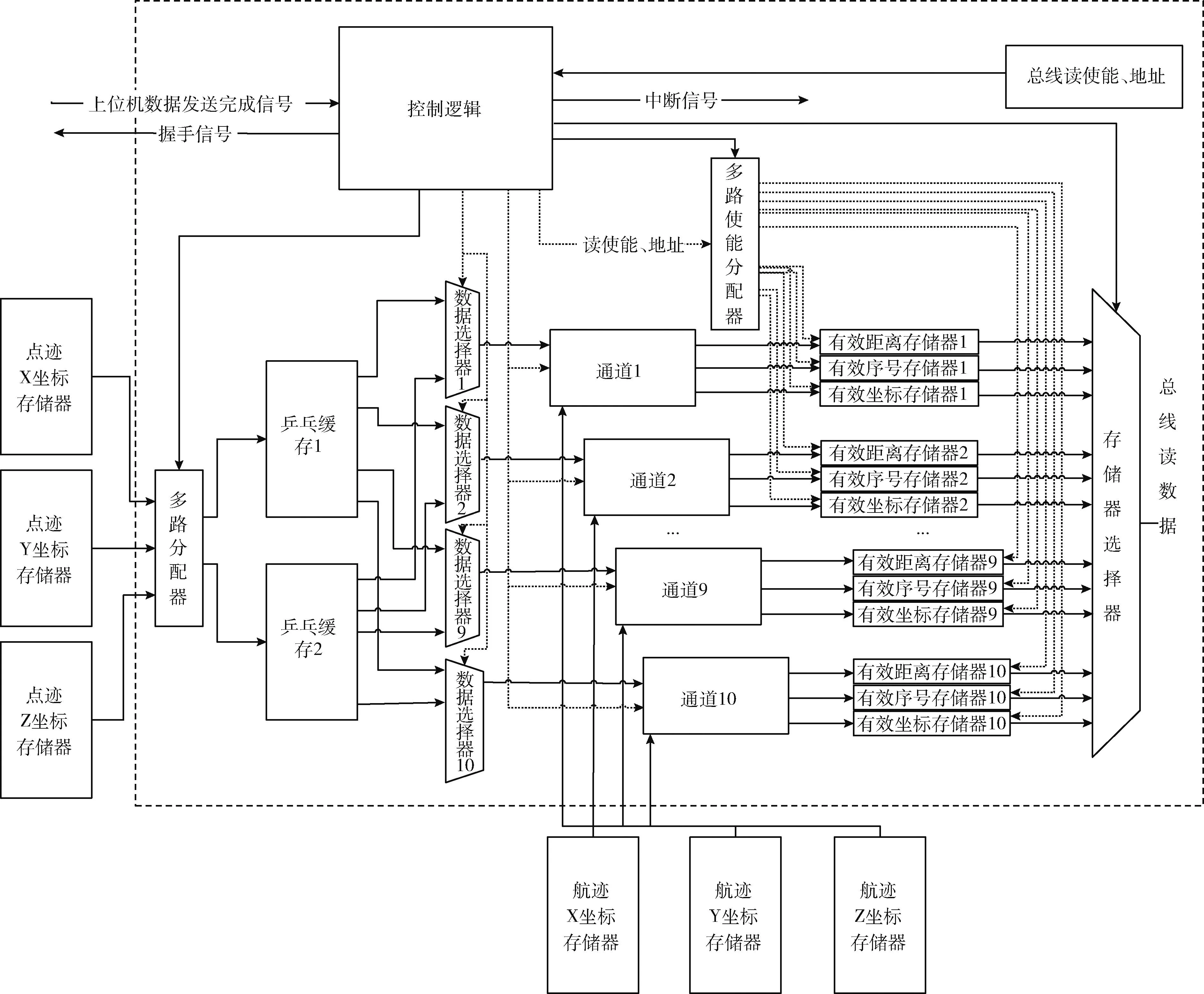
圖6 通道加速器結構框架
上位機通過PCIE將待計算的數據發往與通道加速器對應的點跡、航跡坐標存儲器,數據發送完成之后向通道加速器的控制邏輯發送完成信號,通道加速器的控制邏輯收到該信號后返回握手信號并開始數據運算。首先讀取點跡的3個坐標緩存,先將乒乓緩存1中寫滿10組點跡的XYZ坐標,10組坐標分別與10個計算通道對應。而后每個時鐘周期依次從航跡對應的3個坐標存儲器中讀出一組XYZ坐標送入10個計算通道,并開始與點跡的XYZ坐標進行預定公式的統計距離計算。同時,控制邏輯會再次從點跡坐標存儲器中讀取10組坐標存于乒乓緩存2,當航跡坐標存儲器的所有坐標取完后將乒乓緩存2的10組坐標發送給10個計算通道,再從航跡坐標存儲器中依次讀取所有的坐標并送入10個通道進行計算。接下來,再從點跡坐標存儲器中讀取10組坐標存入乒乓緩存1,按照上述步驟循環,直到點跡所有坐標被取走且與航跡所有坐標完成統計距離計算后停止。
通道計算單元內部采用浮點流水線設計,分別采用浮點減法、浮點乘法、浮點除法單元。為了節約片上緩存資源,本設計根據算法的特點在通道計算單元中加入了浮點比較器,將計算結果與設定的閾值作比較,若計算結果小于閾值則將該值保存,同時將該結果對應的航跡序號記錄,再將點跡序號對應的數值加一。這兩個保存的數值和序號,可以減少原算法篩選步驟中的大量運算,從而對篩選部分起到加速效果。每個通道加速器的存儲器組包含有效距離、有效坐標、有效序號存儲器3種類型。當處理器通過總線發送地址、使能信號訪問雙口緩存時,控制邏輯根據全局地址范圍譯碼使能對應的存儲器供主處理器訪問。
通道加速器完成計算任務后將有效數據存儲于對應的存儲器組,并向中斷管理模塊發送中斷信號,中斷管理模塊經過仲裁決定響應后將中斷信號發往主處理器,最終將處理的結果取回。
2.3 自定義指令協處理器設計
多目標匹配算法作為最近領域類算法的核心,一直是最優關聯研究的難點和熱點問題。當下比較常用的多目標匹配算法有拍賣算法、遺傳算法以及粒子群算法等[14-16]。粒子群算法是較早出現的用于解決最優化的搜索算法,自提出以來得到諸多研究,基礎粒子群算法存在局部搜索能力差、過早收斂等問題,因此在不斷的衍生改進;拍賣算法和遺傳算法都為較成熟算法,文獻[17]根據不同的作戰方法分別采用遺傳算法和拍賣算法對目標關聯進行了研究,發現遺傳算法對全局優化分配占優勢,而針對重點目標,從局部采用拍賣算法效果更好,且拍賣算法的實時性更高,這更加符合雷達多目標跟蹤應用場景的需求。
拍賣算法的基本思想源于實際拍賣的過程,其過程為將n個物品拍賣給m個買家,每個買家對每件商品都有一個預期價值,假設買家j對物品k的心理價值為ajk(當該買家想獲得該物品需要支付價格pjk大于該買家對該物品的心理價值時則該買家不會購買該物品),對于j買家來說其購買k商品的預期利潤為ajk-pjk,對每個買家來說該預期利潤應該為最大值。當每個買家都得到了最大利潤時,這組物品與買家的分配就達到了整體最優。在實際算法實現過程中引入一個用于打破循環的正數ε,每個物品的每次競標價格需要比上一次至少增加ε。本文將為新舊未跟蹤坐標視為買家的物品,利用拍賣算法將未關聯信息對進行匹配。
基于拍賣算法的多目標匹配在每一輪的運算中都會計算一次買家拍賣一件物品的利潤,通過合理設計算法,將該步運算從算法中獨立出來,為買家設置一個利潤向量,通過調用協處理器執行拍賣利潤計算,并采用流水線形式將該買家對當前所有的物品利潤全部計算完,主處理器再依次從該向量中取對應的值用于拍賣。運行過程中,提前將有效信息寫入兩個源寄存器,包括價格向量在內存中的基地址、標價向量在內存中的基地址、待計算的數量、計算結果存于內存的基地址。由于算法中存在數據依賴性,故設置了目的寄存器有效,當協處理器在工作時主處理器會暫停并等待協處理器寫回目的寄存器。拍賣利潤計算自定義指令的格式見表2。
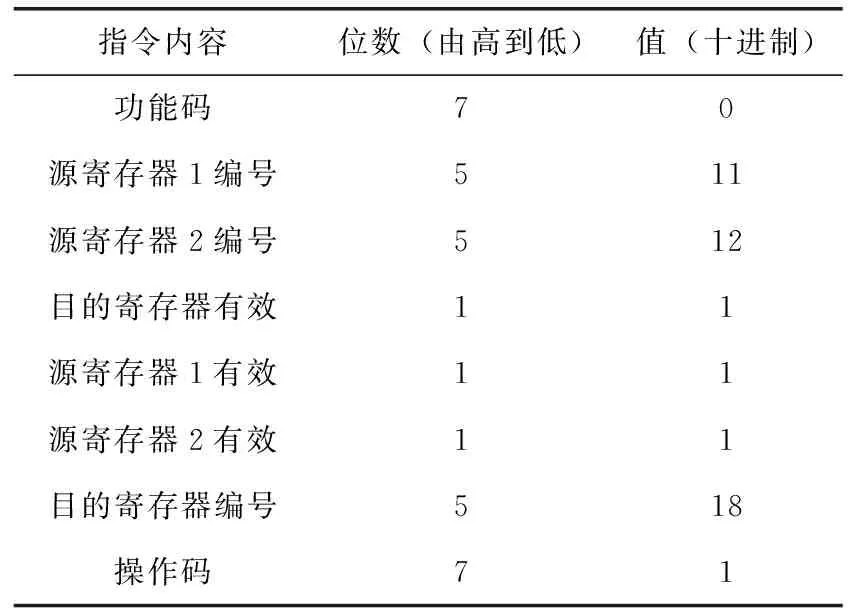
表2 自定義指令格式
本文設計的協處理器結構如圖7所示。圖中粗實線代表數據線,細實線代表控制線。其工作過程為:當指令響應和解碼模塊收到對應指令后將該指令對應的源寄存器中有效數據保存在對應寄存器中,運算控制邏輯控制輸入數據內存地址計算模塊,從寄存器中對應的基地址開始計算取數地址并發往內存控制模塊,內存控制模塊負責與內存接口進行通信,當內存可響應時將對應地址發出,并將內存發來的數據存入對應的緩存中。當兩個取數緩存中的數據存完后,運算控制邏輯控制拍賣利潤計算模塊開始從兩個緩存中讀取數據并以流水線形式進行拍賣利潤計算。每計算完一個結果就將結果保存在輸出數據緩存中,當所有輸出數據都計算完后運算控制邏輯再計算輸出數據對應的內存地址并由輸出控制模塊將這些數據存入內存對應位置。整個流程結束后協處理器在目的寄存器寫零,處理器從利潤向量中取數并進行下一步運算。
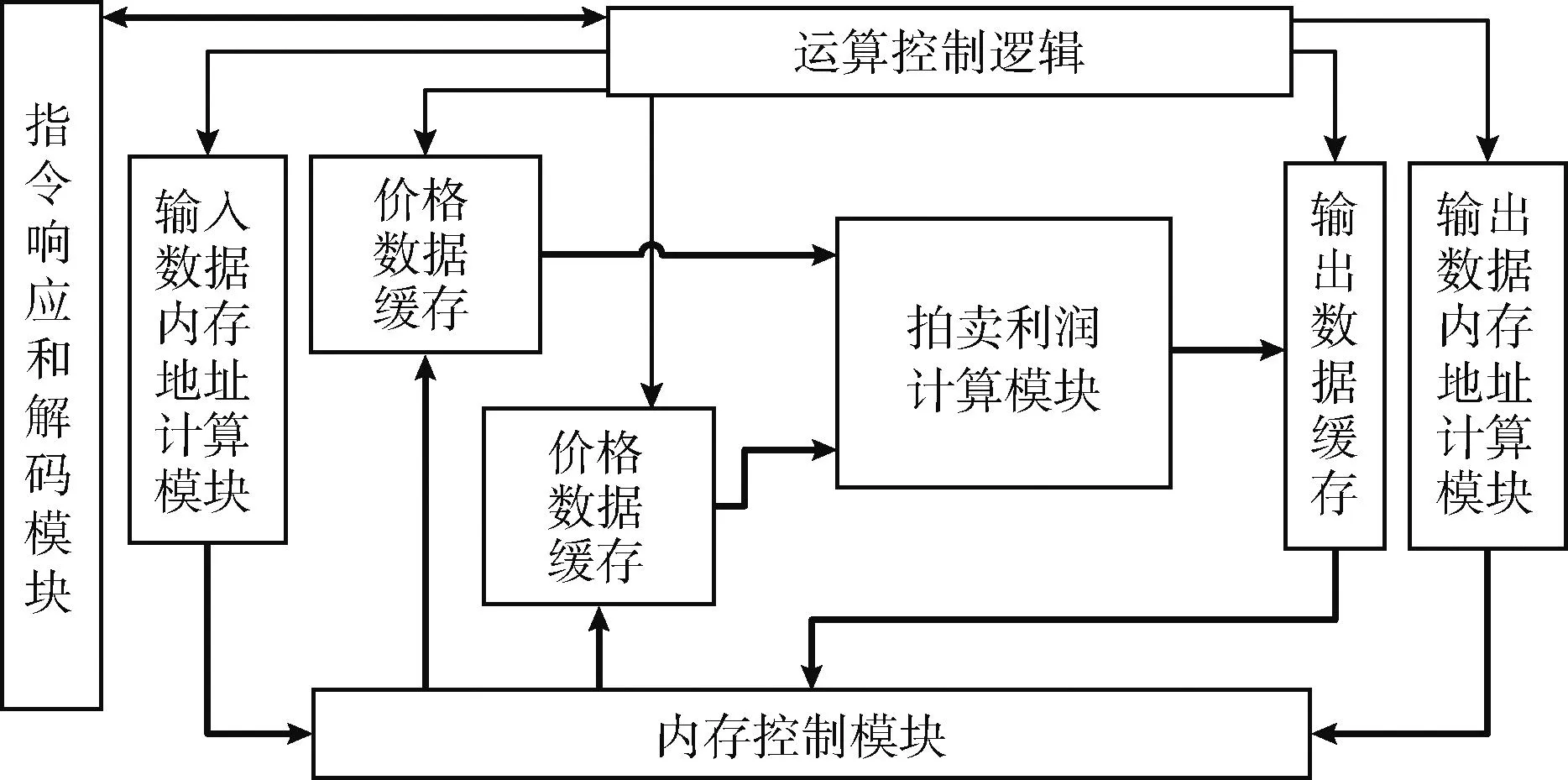
圖7 協處理器結構框架
3 實驗結果與分析
本文使用PC上位機以及主芯片為Xilinx XCKU040-2FFVA1156i FPGA的開發板進行專用片上系統原型測試驗證。測試所用的數據按照雷達多目標跟蹤典型應用情況生成,開發板如圖8所示。

圖8 專用片上系統測試驗證開發板
PC上位機通過PCIE發送點跡、航跡原始數據到開發板,接收并記錄各個步驟運行時間。專用片上系統包含RISC-V主處理器、兩種加速器、片上存儲資源以及內嵌邏輯分析儀。在KU040 FPGA上部署后,各項資源使用情況見表3。其中PCIE-AXI4和通道加速器的主頻為250 Mhz,Rocket Chip核的主頻為100 Mhz。
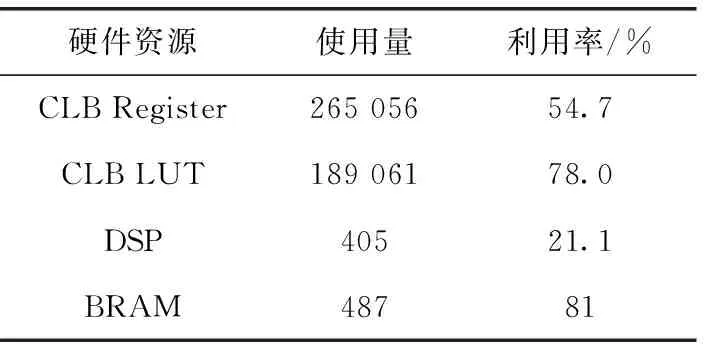
表3 FPGA資源使用情況
為了對比Rocket Chip和加速器的實際性能,選用相同平臺未搭載加速器的片上系統以及同為RISC-V架構的開源處理器蜂鳥E200片上系統進行測試。圖9為內嵌邏輯分析儀對信號進行捕獲的截圖,圖中XA、YA、ZA、XB、YB、ZB為點跡航跡坐標數據,cmd_valid為過程觸發,使能cmdReady進行運算,Calvalid信號表示出現一個有效的值并存儲,最終通過中斷向處理器提出響應。統計并記錄了完整運行同一算法時3種片上系統的耗時,見表4。未掛載加速器的Rocket Chip片上系統運行原始算法時間為536 ms,掛載了通道加速器和協處理器的Rocket Chip專用片上系統運行算法時間為96 ms,蜂鳥E200片上系統運行算法時間為1624 ms。
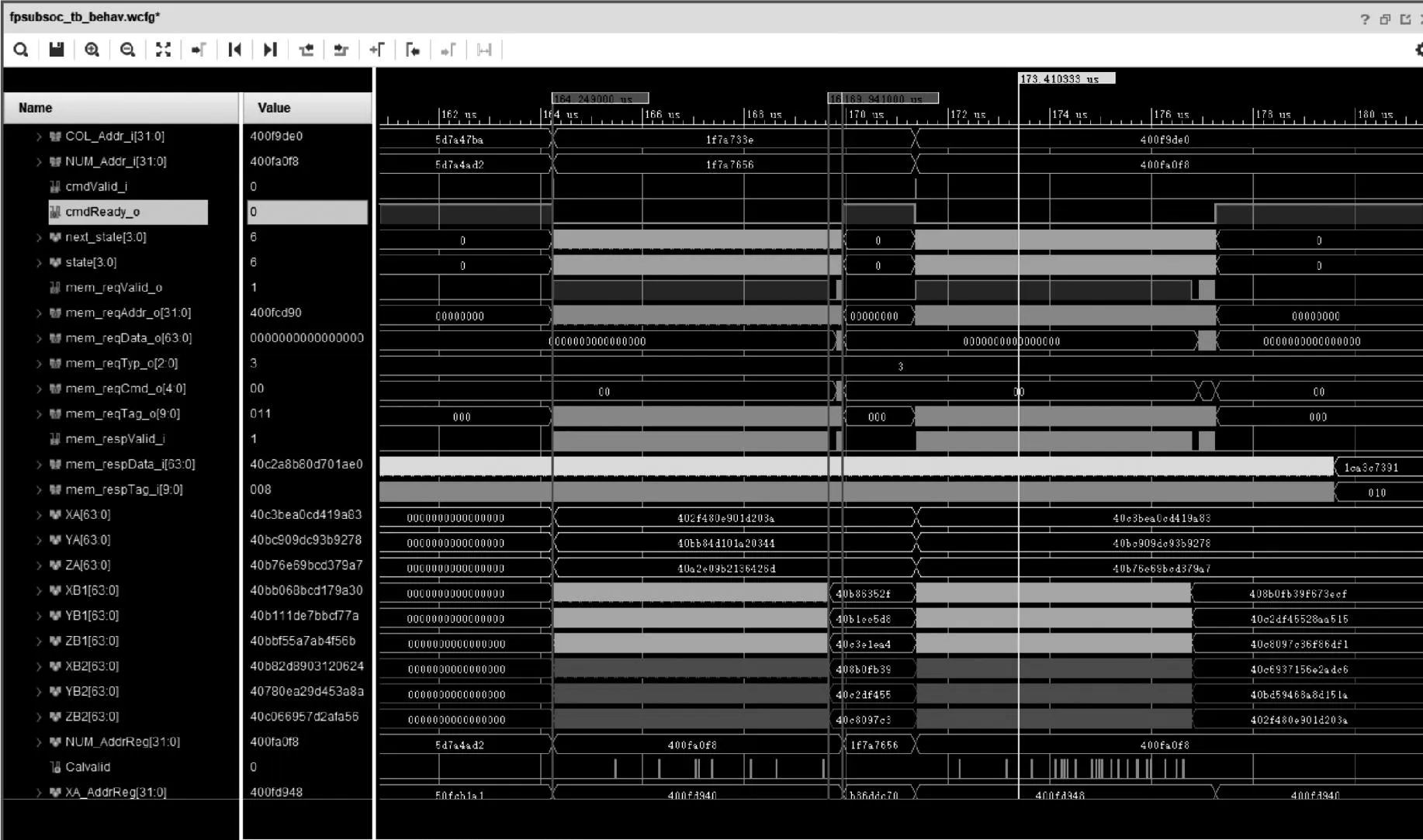
圖9 內嵌邏輯分析儀信號捕獲

表4 幾種片上系統性能對比
從總體運算時間來看,本片上系統相比Rocket Chip處理器原始片上系統的加速比為5.6倍;相比蜂鳥E200處理器片上系統的加速比為16.9倍。本算法應用場景是以運算速度為主要優化目標,該處理器架構符合領域專用計算目標需求,可以預見,在替換為更高性能的RISC-V核后,本文設計的RISC-V擴展指令集架構的片上系統將獲得更高的能效比。
4 結束語
多目標跟蹤應用算法復雜的數據流導致當前的主流運算平臺對這類算法的運算效率不高。本文通過對當前主流最近領域類算法結構及數據流分析,設計了面向多目標跟蹤應用的專用片上系統架構,通過合理設計硬件通道加速器、面向拍賣利潤計算的自定義擴展指令以及對應的協處理器實現了對該算法的硬件加速。
在FPGA原型驗證平臺的實際測試表明,該協處理器片上系統本算法的性能相較于原平臺有顯著提升。面向此類應用,本設計具有一定的領域通用性,對于其它最近領域類算法,只需更改處理器運行的軟件代碼就可以繼續調用加速器實現通用性的加速,也可以設計新的自定義指令來進行針對性硬件加速,為領域專用片上系統設計提供了思路和現實參考。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
電信科學(2016年10期)2016-11-23 05:11:56
西安航空學院學報(2014年5期)2014-07-13 01:27:52
