從感知認知到智能決策,持續推進AI創新
2023-12-22 02:17:10
信息化建設 2023年10期
本刊記者
通用大模型,被譽為“AI時代”的靈魂,是指一種集成了多種功能的AI系統。其在語音識別、自然語言處理、圖像識別等領域的應用,極大地推動了人工智能技術的發展。
然而,一個普遍的事實是,當前,通用大模型存在算力成本高、本地化部署難、數據泄漏風險高、領域專業知識弱等痛點難點,市場需求難以得到滿足。
在2023“直通烏鎮”全球互聯網大賽人工智能(大模型及數字人)專題賽上,北京中科聞歌科技有限公司(以下簡稱“中科聞歌”)以“雅意”大模型為參賽項目,針對行業的痛點問題,帶來了中科聞歌的解決方案。
聞弦歌知“雅意”,善推理知決策
“聞歌”二字起源于《呂氏春秋》中的“聞弦歌知雅意”,從創立伊始,中科聞歌便將人工智能的內涵蘊藏于企業名字之中。“我們的愿景是通過大數據分析、人工智能技術洞悉行業難題及本質,解決隱藏其中的難點,以技術服務國家戰略需求。”中科聞歌相關負責人說道。
而中科聞歌此次帶來的“雅意”大模型,更是與企業名字暗合,聞弦歌、知雅意,善推理、會決策,“雅意”大模型的定位便是一款人工智能認知與決策技術領域的企業級通用大模型。
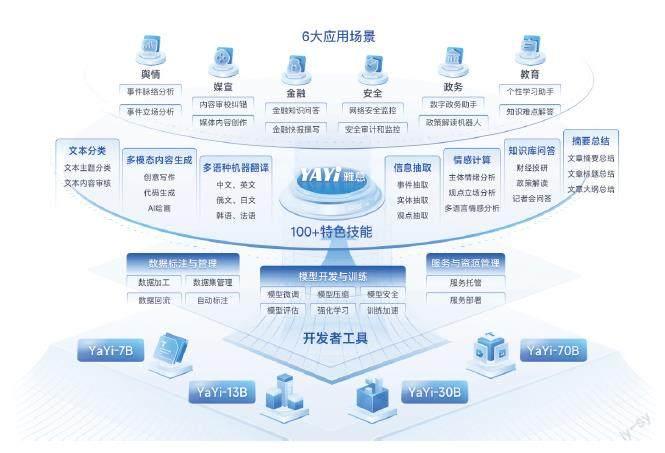
據介紹,“雅意”大模型由中科聞歌自主研發,擁有五大核心功能,包括實時聯網問答、領域知識問答、復雜場景信息抽取、多語言內容理解、多模態內容生成,共100余項特色技能,支持云端MaaS使用、本地一體機部署、自主私有訓練部署三種使用方式,可快速對接政府、企業數據并一鍵生成大模型專屬應用服務。
作為垂直領域的專屬大模型,“雅意”圍繞行業垂直生態,推出“5+N”計劃,面向媒體、宣傳、金融、治理、安全等五大方向進行針對性訓練,并泛化到家居、醫療、教育等行業,可適配多樣化、專業的業務場景。目前,“雅意”已搭載在中科聞歌多款行業產品中,包括面向輿情信息領域的“晴天”多模態信息洞察平臺、面向媒體數字化領域的“紅旗”智能媒體操作系統,以及面向金融領域的“多投”投研資管平臺等。
5到700,500萬到10億,0到4億
許多人不知道的是,中科聞歌還藏著“國家隊”的基因。2017年,“人工智能”首次被寫入全國“兩會”政府工作報告,報告提出,“要全面實施戰略性新興產業發展規劃,加快新材料、人工智能、集成電路、生物制藥、第五代移動通信等技術研發和轉化,做大做強產業集群”。
在國家科技政策的鼓勵支持下,人工智能市場迎來了發展高潮,出現萬億級的“時代賽道”。彼時,已在中國科學院深耕AI和大數據研究十余年的王磊等五位青年技術人員,選擇走出實驗室,在180平方米的辦公室,拿著500萬元的天使啟動資金,就這樣“下海”了。
“國家隊”的基因為中科聞歌團隊之后的研發成果輸出,奠定了良好的科技基礎。從王磊等人的中科院工作經歷算起,到今天,前后共17年,核心團隊一直堅持在人工智能與復雜數據解析核心技術創新領域。如今,企業研發人員占比達60%,碩博人才占比高,僅學術帶頭科學家便達20余人。有了科技基因和科技成果的中科聞歌,第三步便是發揮市場化基因,為此,企業建立了完全市場化的經營模式,組建起一支多元化的人才隊伍。
從5個人到700人,從500萬啟動資金到10億的資產規模,從0到年銷售額達4億元,從北京到全國15家分公司,中科聞歌一路穩扎穩打,逐步在人工智能領域走出了自己的道路。
今年9月1日,由國家信息互聯網辦公室發布的第二批境內深度合成服務算法備案名單中,中科聞歌“雅意”大模型算法便位列其中。目前,雅意大模型的性能在國內權威C—EVAL評測的所有模型中,名列第四,在國際權威評測LLM leaderboard評測的同等參數規模模型中同樣名列前茅。
專注前沿科技創新,服務國家人工智能戰略需求
習近平總書記曾指出,“新一代人工智能是我們贏得全球科技競爭主動權的重要戰略抓手,是推動我國科技跨越發展、產業優化升級、生產力整體躍升的重要戰略資源”。從2016年3月,“人工智能”一詞寫入國家“十三五”規劃綱要開始,近年來,國家的重視為人工智能的發展提供了強勁的動能,而一大批像中科聞歌這樣的科技企業,一直沖鋒在攻克各項技術壁壘的前沿,為這個萬億賽道助力。
從梳理技術選賽道開始,中科聞歌幾乎是一腳便站上了最難的賽道。從感知智能向認知和決策智能進軍,這個研究方向在業界被稱為人工智能皇冠上的明珠,是人工智能取得進一步突破的關鍵瓶頸,也是形成更大產業規模的關鍵技術。
在“雅意”研發過程中,技術壁壘便是層出不窮。據介紹,“雅意”是基于BigScience發布的bloomz—7b—mt模型(開源可商用的預訓練模型,70億參數)和Hugging Face發布的StarCoder(開源可商用的預訓練模型,150億參數)權重作為初始化權重,并基于詞表進行擴展,前后經歷了三個階段的訓練:第一階段是面向通用技能領域,使用聞海自有數據篩選高質量多樣性樣本數據364萬條,進行指令微調;第二階段是在人工構造的高質量領域數據上,進行領域性指令微調,包括媒體、輿情、安全、金融、治理等五大領域數百種自然語言指令任務,共計80萬條高質量知識數據;第三階段則是針對安全性/毒性等場景,做了針對性訓練,訓練數據約5萬條,并結合人工反饋優化增加模型的忠實性和安全性。
在經過內部構建的55個任務綜合評測后,“雅意”與目前主流的幾個大模型相比,取得了不俗的性能,在基礎能力測試方面,其整體性能與目前開源的同等規模參數的大模型能力相當。
“中科聞歌一直致力于引領人工智能從感知向認知、決策技術跨越,目前正在訓練的一個千億規模的大模型,在數據、模型、應用等方面擁有完全自主知識產權,希望將來能以先進的大模型技術服務行業數智化轉型,服務國家層面的人工智能戰略需求。”
談及此次烏鎮之旅,項目團隊負責人表示,通過大賽,不僅接觸到了最新的大模型和數字人技術,通過與專家和同行的交流,項目團隊還了解到了更多的新研究方向和應用場景,這對中科聞歌未來的研究和實踐有很大的幫助,同時對國內大模型和數字人賽道的未來發展前景充滿信心。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
西安航空學院學報(2022年2期)2022-07-04 07:45:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
光學精密工程(2016年6期)2016-11-07 09:07:19
南風窗(2016年19期)2016-09-21 16:51:29
南風窗(2016年19期)2016-09-21 04:56:22
