數(shù)字化讀圖時代多模態(tài)翻譯能力與培養(yǎng)策略
2023-12-23 08:01:56吳靜龍明慧
外國語文 2023年6期
吳靜 龍明慧
(重慶師范大學 外國語學院,重慶 401331)
0 引言
21 世紀是一個數(shù)字化時代,也是一個讀圖的時代。 在這個時代,數(shù)字、網(wǎng)絡和新媒體技術在各個領域得到廣泛使用,人們的閱讀習慣出現(xiàn)視覺化轉向,整合語言文字、圖片、影像等多種符號的多模態(tài)信息傳播日益成為信息傳播的主流方式。 相應地,在翻譯領域,翻譯的對象也已遠超出傳統(tǒng)線性文本范疇(王少爽 等,2018),譯者在更多時候需要處理的是整合文字、圖像、聲音、影像等多種模態(tài)符號的多模態(tài)文本,進行多模態(tài)翻譯。 能夠處理多模態(tài)文本,以及運用多模態(tài)手段進行翻譯的多模態(tài)翻譯人才的培養(yǎng)也變得極為必要。
多模態(tài)翻譯有不同于單一語言模態(tài)翻譯的特點,最突出的就是在翻譯過程中涉及多種模態(tài)符號的意義構建。 因此,相對于單一語言模態(tài)翻譯,多模態(tài)翻譯對譯者有著不同的要求。 然而,在當前的翻譯教學領域,雖然越來越多的聲音倡導多模態(tài)教學,但學者們提及的多模態(tài)翻譯教學主要限于利用多媒體技術、多媒體網(wǎng)絡平臺或多模態(tài)材料作為輔助工具來進行語言翻譯教學活動。 這些方法旨在培養(yǎng)語言翻譯人才,尚未深入研究多模態(tài)翻譯實踐本身的特點及其對譯者提出的新要求,以解決多模態(tài)翻譯人才培養(yǎng)的問題。 能力的培養(yǎng)是翻譯人才建設的核心(唐昉,2022)。 那么,培養(yǎng)多模態(tài)翻譯人才的核心問題就是培養(yǎng)學生的多模態(tài)翻譯能力。 因此,本文結合多模態(tài)翻譯的特點,構建多模態(tài)翻譯能力模式以及多模態(tài)翻譯能力的具體培養(yǎng)策略,為培養(yǎng)更能適應時代需求的多模態(tài)翻譯人才提供借鑒。
1 數(shù)字化讀圖時代的多模態(tài)翻譯能力模式
翻譯能力一直是翻譯研究,特別是翻譯教學研究的一個重要話題。 對于翻譯能力,學者們一般從不同角度,通過翻譯的“子能力”對翻譯能力進行詮釋。 紐博特(Neubert)(2000:3-18)認為翻譯能力包含語言能力、文本能力、主題能力、文化能力和轉換能力。 麥肯齊(Mackenzie)(2004:32-33)指出,翻譯能力不僅包括語言文化運用能力,還包含溝通能力、計算機運用能力、營銷能力和管理能力。 西班牙PACTE 專項研究小組提出翻譯能力“六成分說”,即翻譯能力包括雙語子能力、語言外子能力、翻譯知識子能力、工具子能力、心理生理要素和策略子能力等六大子能力(PACTE,2005; 祝朝偉,2015)。 譚載喜(2012:115)從“綜合”的概念出發(fā)來考察對譯者或翻譯專才的教育,認為譯者或翻譯專才應該具備基本的 “子能力”,即認知能力、相關雙語能力、技術輔助能力和轉換能力。 而我國2020 年發(fā)布的《翻譯專業(yè)本科教學指南》借鑒國外翻譯能力研究的相關成果,經(jīng)由國內翻譯學界對翻譯能力內涵的持續(xù)探討,將翻譯能力界定為:“能運用翻譯知識、方法與技巧進行有效的語言轉換,一般包括雙語能力、超語言能力(如百科知識、話題知識等)、工具能力、策略能力等。”(趙朝永 等,2020)
目前學界提出的翻譯能力,不管是語言能力還是語言外能力,最終指向的都是依靠并運用這些能力順利地將一種語言文本表述的信息用另一種語言表述出來。 也就是說,學者們在探討翻譯能力時都是以語言為意義載體的翻譯為默認對象。 而多模態(tài)翻譯涉及對多種模態(tài)符號的意義處理,對譯者翻譯能力自然會有更多要求。 譯者除了要具備單一語言模態(tài)翻譯要求的能力以外,還需要具有非語言視覺符號處理能力以及將語言符號和非語言符號進行有機整合的能力。 因此,我們可參照學界對翻譯能力的解釋,將多模態(tài)翻譯能力分為語言翻譯能力、視覺讀寫能力①雖然有的多模態(tài)文本也包含聽覺信息,但目前翻譯涉及的大多數(shù)多模態(tài)文本,最突出的意義構建資源還是語言符號和非語言視覺符號,因此本文重點研究涉及視覺信息的多模態(tài)翻譯能力培養(yǎng),將視覺讀寫能力而非聽覺讀寫能力作為多模態(tài)翻譯能力的一個子能力。和多模態(tài)整合能力這三個子能力。 而這三個子能力又可以進一步進行細分,具體如下圖所示:
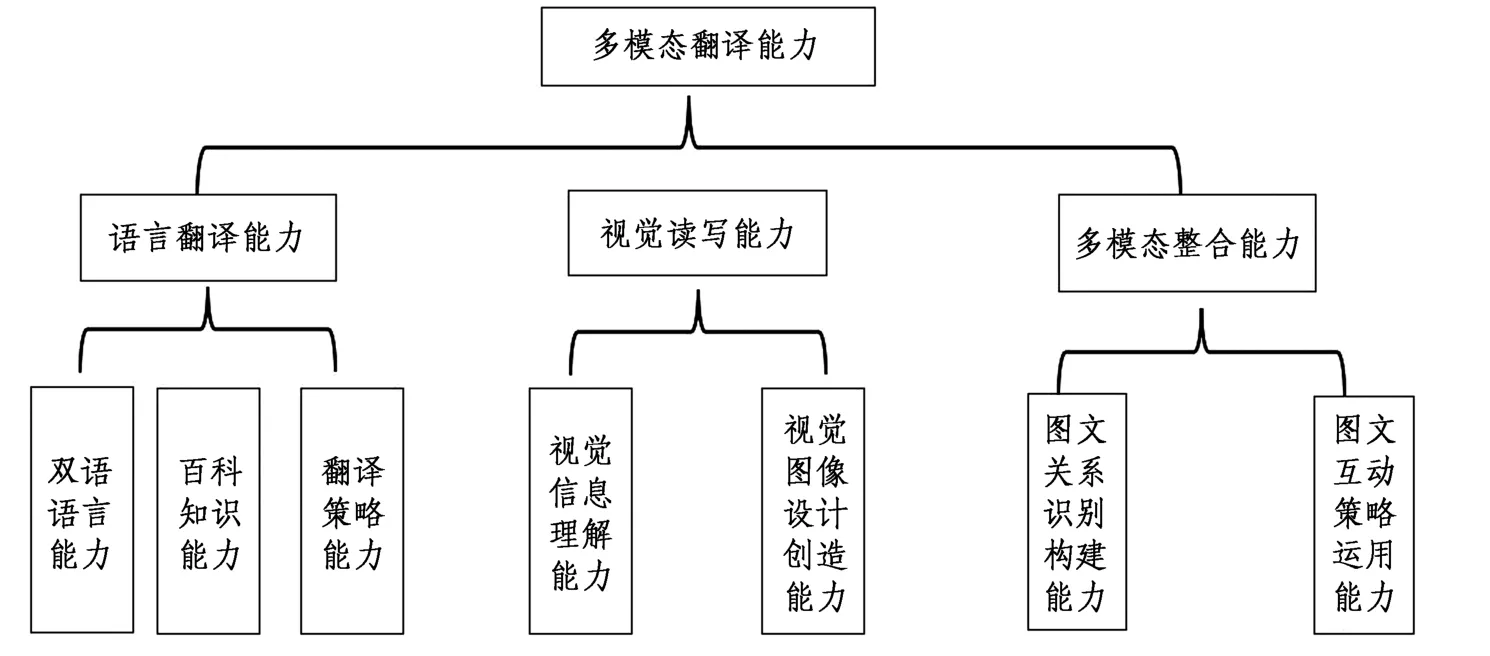
圖1 多模態(tài)翻譯能力模式
1.1 語言翻譯能力
語言翻譯能力就是迄今學界所討論的翻譯能力,即從事語言翻譯涉及的各種能力。 具體而言,就是理解原文語言承載的信息,并結合讀者需求,以合適的方式將其用目標語言再現(xiàn)出來的能力。 要正確全面地理解原文語言承載的信息并將其轉換為另一種語言,譯者首先需要具備雙語能力,能夠理解和熟練運用翻譯所涉及的兩種語言。 然而,語言并非存在于真空中,而是凝聚了各種文化、社會和歷史因素。 因此,除了雙語能力外,譯者還需要具備語言之外的百科知識能力,掌握社會文化知識、主題知識等。 要獲取這些知識,自然離不開運用輔助工具的能力。 此外,由于不同語言、文化之間的差異,以及翻譯環(huán)境、讀者需求方面的差異,譯者在用譯文語言呈現(xiàn)原文信息時,往往需要進行一些調整和改動,這就需要譯者具有翻譯策略能力。
關于語言翻譯能力,學界已有廣泛而深入的闡述。 本文不再贅述其詳細內涵,而將重心置于對視覺讀寫能力以及多模態(tài)整合能力的探討。
1.2 視覺讀寫能力
視覺讀寫能力是“一種就像計算、信息技術和識字一樣的跨學科文化技能”(Hughes,1998:117)。具體說來,就是指理解和應用圖像的能力,包括運用圖像進行思考、學習和表達自己的能力。 換言之,擁有視覺讀寫能力就是要能夠創(chuàng)造或選擇合適的圖像來表達從具體信息到抽象概念中的各種意義。同時,可以閱讀、解釋和提取他人創(chuàng)造的各類視覺信息(劉成科 等,2014)。 因此,視覺讀寫能力至少應該包括視覺信息理解能力和視覺圖像設計創(chuàng)造能力這兩個子能力。
1.2.1 視覺信息理解能力
視覺信息理解能力是指能夠識別各種視覺設計元素,理解視覺符號的意義,了解一般人對某個圖像會產生什么樣的反應,并能解釋其原因。
而視覺符號的意義,和語言符號的意義一樣,并不局限于表層意義。 早在1955 年,德國藝術史學家潘諾夫斯基(Panofsky)在論述如何理解藝術品圖像時就提出了理解藝術品圖像的三個階段,即:(1)前圖像志階段(preiconographic)、圖像志階段(iconographic)、圖像學解釋階段(iconological)。 這三個階段對應視覺圖像的三個意義層次,即事實意義、表現(xiàn)意義和內在意義(Serafini,2011)。
第一個階段前圖像志階段,聚焦圖像的事實意義,主要是對視覺形式最基本、最自然的意義的解釋,涉及將視覺形式與我們從實際經(jīng)驗中認識的對象簡單等同起來。 簡言之,就是能夠識別視覺圖像所指代的實際事物。
第二個階段圖像志階段,聚焦圖像的表現(xiàn)意義,主要是對視覺形式從屬的或約定俗成的意義的解釋,要求觀察者跳出表面意象,結合實際社會和特定文化理解視覺形式所代表的意義。 比如豎大拇指在中國文化中表示稱贊,但在其他文化中可能有不同的意義。 又如同樣的顏色、動植物在不同的社會文化中也可能具有不同的含義。 而理解視覺圖像這一層次的意義對于從事多模態(tài)翻譯極其重要。 翻譯總是涉及兩種文化之間的轉換,譯者在理解原文涉及的視覺符號時,就必須考慮該視覺符號在原語文化中約定俗成的意義,同時考慮目標讀者在理解該視覺符號時可能會和原文讀者產生不同的反應,以及如何避免目標讀者對視覺符號可能產生的誤解或理解困難。 若是使用多模態(tài)手段對單一語言模態(tài)原文進行翻譯,在選擇視覺符號時更要考慮來自不同文化背景的目標語讀者對視覺符號的接受情況,避免出現(xiàn)文化誤解。
第三個階段圖像學解釋階段,聚焦圖像的內在意義的解釋。 圖像總是產生于特定的社會、政治和歷史語境之中,并因此獲得特定的意識形態(tài)和文化意義。 要正確理解圖像的這一意義,就需要觀察者將圖像置于特定社會、政治和歷史語境中進行分析。 如萬字符“卐”本是佛祖釋迦牟尼胸部所現(xiàn)的“瑞相”,象征吉祥福瑞,具有“萬德吉祥”的含義,但自二戰(zhàn)后成為德國納粹的黨徽,具有了血腥、暴力和恐怖的象征意義。
視覺符號這三個層次的意義其實剛好對應語言的指稱意義、內涵意義和象征意義。 這三種意義中,第一個層次的意義,也就是視覺符號的事實意義,由于圖像的直觀形象性,最易理解。 而要理解第二個、第三個層次的意義,則需要進行系統(tǒng)學習。 因此培養(yǎng)學生理解多模態(tài)文本中視覺符號在特定文化的內涵意義和象征意義應成為培養(yǎng)學生視覺讀寫能力的重點目標。
1.2.2 視覺圖像設計和創(chuàng)造能力
視覺讀寫能力中解碼與編碼兩種能力同等重要(Braden et al., 1982)。 除了解碼能力,即理解視覺信息的能力,視覺信息的編碼能力,進行視覺圖像的設計和創(chuàng)造的能力也是視覺讀寫能力不可或缺的部分。 視覺圖像的設計和創(chuàng)造能力,就是基于對視覺元素的了解,能夠運用一定的工具,選擇合適的原創(chuàng)圖片或者根據(jù)視覺傳播的基本原則對基本視覺元素進行綜合設計,傳遞想要表達的意義,引起讀者認知和情感上的反應。
鑒于視覺圖像往往具有如上所述的三種意義,進行視覺圖像的設計和創(chuàng)造就不能僅限于運用視覺圖像來傳達其事實意義,而是要能夠運用合適的視覺符號在特定文化、特定社會、政治和歷史語境中傳達更深層次的意義,確保讀者能夠理解圖像的內涵意義或是象征意義,從而產生共鳴。
對于運用多模態(tài)手段對單一語言模態(tài)文本進行翻譯,譯者的視覺圖像設計和創(chuàng)造能力是十分重要的。 雖然存在從事圖像創(chuàng)作的專業(yè)人士,但不同于藝術領域內的藝術創(chuàng)作,翻譯中設計創(chuàng)造圖像的目的是更有效地輔助傳達原文的意義和內容。 單單依靠從事圖像創(chuàng)作的專業(yè)人士所設計的圖像未必能滿足多模態(tài)翻譯的需求,例如為了追求藝術效果,有些圖像設計者往往傾向于設計一些抽象、模糊、寫意的圖像。 但對于這類圖像,普通讀者未必能夠理解。 因此,進行多模態(tài)翻譯,還需要譯者具備基本的圖像設計創(chuàng)造能力,能夠立足原文信息的傳達以及目標讀者的文化背景,靈活運用色彩、聲音、動畫、人物或事物形象等,選擇合適角度、焦點和背景生成圖像或影像傳達原文各個層次的意義,特別是傳達原文無法用語言表述清楚,或是目標讀者單單依靠語言無法實現(xiàn)全面理解的信息。 同時考慮視覺符號文化特殊性,避免出現(xiàn)在目標語文化中屬于文化禁忌,或是讓目標語讀者困惑、誤解的視覺信息。 在多模態(tài)翻譯過程中,即使視覺圖像的創(chuàng)作由專門的圖像制作者完成,譯者仍然需要積極參與并與他們進行有效的溝通。 要實現(xiàn)與圖像制作者的有效交流,譯者也需要具備基本的視覺圖像設計和創(chuàng)作能力。 這樣,譯者才能更好地理解和傳達原文的內容和意義,并確保翻譯文本與所生成的圖像之間的一致性和準確性。
1.3 多模態(tài)整合能力
進行多模態(tài)翻譯,不是僅僅理解和創(chuàng)造視覺文本,而是要理解和創(chuàng)造語言和非語言符號整合而成的文本。 要做到這一點,除了語言翻譯能力和視覺讀寫能力外,多種模態(tài)的整合能力也必不可少。 而多模態(tài)整合能力具體又可以細分為圖文關系識別和構建能力以及圖文互動策略能力這兩個子能力。
1.3.1 圖文關系識別和構建能力
對于多模態(tài)語篇,圖文關系將直接影響語篇意義的生成與理解(劉成科,2014)。 而從事多模態(tài)翻譯,不管是理解多模態(tài)原文,還是生成多模態(tài)譯文,譯者首先需要明確的便是圖文關系。
當翻譯的對象是多模態(tài)文本時,如影視、繪本、配圖廣告、新聞等,譯者首先需要識別語言符號和非語言符號這兩種不同的符號體系如何相互聯(lián)系并生成意義,非語言符號和語言符號是呈現(xiàn)同樣信息的冗余關系,還是表達不同內容的互補關系,亦或是非語言符號提供語言信息的背景,或是對語言文本的裝飾。 譯者只有在明確這些關系的基礎上才能確定在翻譯過程中是否要對非語言符號進行特別處理。例如,若原文中非語言符號和語言符號是冗余關系,譯者幾乎不需要對非語言圖像進行特別處理。 但如果在原文語境下非語言符號是對語言符號提供的信息進行進一步補充,譯者便需要做出研判:在目標語環(huán)境下,目標語讀者是否能夠理解這些補充信息? 若不能,是需要更換圖像,還是對圖像進行額外的解釋? 譯者甚至可能還需要考慮原文的圖文關系是否適合用于目標語語境中,譯文是否要改變原文的圖文關系。
若是運用多模態(tài)手段對單一語言模態(tài)文本進行翻譯,譯者則需要確定對于原文完全用語言表達的信息,需要使用什么樣的視覺符號。 視覺符號和語言符號以一種什么樣的關系才能更好地傳達原文的意義,且更容易為目標語讀者所理解。 確定譯文的圖文關系后,譯者才能據(jù)此選擇、設計合適的非語言符號,并對這些非語言符號進行排版布局,最終生成有效的多模態(tài)譯本。
1.3.2 圖文互動策略能力
圖文互動策略能力是指在使用語言符號和非語言符號共同構建譯本時,能夠運用一定的策略,使語言符號和非語言符號互相整合,成為一個有機整體,共同傳遞文本意義。 比如,在用多模態(tài)手段翻譯單一語言模態(tài)原文時,若是在文本中插入了插圖且這些插圖明確表述了原文文本的某些信息,那么譯文在語言描述上便可以進行適當?shù)膭h除和簡化。 若是插圖中出現(xiàn)令讀者理解困難、可能產生誤解的信息,就需要在語言描述中增加適當?shù)慕忉尅?又如譯者在翻譯多模態(tài)文本時,若是發(fā)現(xiàn)在原文語境中,本來彼此關聯(lián)的原文語言和非語言符號,到了目標語環(huán)境中由于語言和目標讀者文化認知語境的不同,語言和非語言符號失去了關聯(lián),譯者便需要調整語言表達或非語言符號,實現(xiàn)譯文語篇中語言符號和非語言符號的連貫重構,使語言符號和非語言符號在目標語語境中重新成為一個有機整體。
由于多模態(tài)翻譯本身的特殊性,譯者要從事多模態(tài)翻譯,語言翻譯能力、視覺讀寫能力以及多模態(tài)整合能力這三個子能力缺一不可。 然而,目前翻譯專業(yè)和外語專業(yè)的學生普遍缺乏視覺讀寫能力和多模態(tài)整合能力的培養(yǎng)。 這兩種能力的培養(yǎng)需要采用與語言翻譯能力培養(yǎng)不同的策略和方法。 因此,當前需要著重探索針對視覺讀寫能力和多模態(tài)整合能力的培養(yǎng)策略,以滿足日益增長的多模態(tài)翻譯需求。
2 數(shù)字化讀圖時代的多模態(tài)翻譯能力培養(yǎng)策略
如前所述,數(shù)字化時代的多模態(tài)翻譯能力應該包括語言翻譯能力、視覺讀寫能力以及多模態(tài)整合能力。 對于語言翻譯能力的培養(yǎng),學界已有大量論述,本文在此主要探討從事多模態(tài)翻譯所需要的視覺讀寫能力和多模態(tài)整合能力的培養(yǎng)策略。
視覺讀寫能力主要包括視覺信息理解能力和視覺圖像設計創(chuàng)造能力,而多模態(tài)整合能力則包括圖文關系識別構建能力和圖文互動策略能力。 要培養(yǎng)這幾個能力,可以通過具體的多模態(tài)翻譯實踐案例,教授學生識別各種視覺元素,再以視覺語法為指導,了解視覺圖像的意義構建原則和方式,激發(fā)學生視覺符號的文化差異意識,繼而訓練學生識解各種圖文關系,熟悉多模態(tài)整合策略。
2.1 引導學生識別視覺元素,以視覺語法為指導,了解視覺圖像意義構建原則
視覺信息通過視覺圖像呈現(xiàn),而視覺圖像則是由各種視覺元素整合構成。 不管是理解視覺圖像的意義,還是設計創(chuàng)造視覺圖像,都需要熟悉構成視覺圖像的各種元素。 因此,培養(yǎng)學生視覺符號的理解和運用能力,首先需要教會學生識別各種視覺元素,了解各種視覺元素如何構建意義。
視覺元素包括線條、形狀、色調、色彩、圖案、紋理和形式等,是藝術作品的基本構件①對視覺元素的具體詳細介紹可參見https:∥www.artyfactory.com/art_appreciation/visual-elements/visual-elements.html.,相當于語言中的字和單詞。 這些基本元素本身具有豐富的意義,同時又根據(jù)一定的原則組合起來傳達更多的意義。 如不同的色彩,除了指代色彩本身以外,還有不同的聯(lián)想象征意義。 色彩和形狀、線條、圖案組合起來又會傳達不同的意義。 如陳絲雨繪圖、孫見坤進行文字注解的《山海經(jīng)》圖文版,其中的插圖使用了黑、白、紅三種顏色,剛好契合中國人民歷來對這三種顏色的偏愛以及這三種顏色代表的深厚文化內涵①對于黑白紅三色在中國文化中的特有內涵和重要意義,參見李彥彬,2009.中國傳統(tǒng)色彩中的黑白情結. 藝術教育[J].(7):156-157,以及“中國傳統(tǒng)‘紅’與‘黑’色彩元素的文化探源https:∥wenku.so.com/d/41c454e150cfac599049b75ba083ba66.。
對于各種視覺元素如何表達意義,克萊斯等(Kress et al., 1996) 在韓禮德的系統(tǒng)功能語法理論的基礎上提出的視覺語法為我們提供了一套系統(tǒng)的分析框架。 兩位學者將韓禮德(Halliday)提出的語言的三大元功能延伸到視覺圖像,認為視覺圖像具有再現(xiàn)意義、互動意義和構圖意義,分別對應語言的概念、人際和語篇的三大元功能。 其中,再現(xiàn)意義可分為敘事再現(xiàn)和概念再現(xiàn)兩大類。 敘事再現(xiàn)主要分為行動過程、 反應過程、 言語和心理過程。 概念再現(xiàn)則主要分為分類過程、分析過程和象征過程。 體現(xiàn)再現(xiàn)意義的符號資源包括表征參與者、過程和環(huán)境。 表征參與者是指被描繪的,“我們所談論的、書寫的或是為之生成圖像的”的參與者(Kress et al.,1996: 48),例如圖像中的人物、事物和地方。 過程指圖像中描繪的動作和關系。 環(huán)境則指圖像中描繪的場景。
視覺圖像中的互動意義指圖像制作者、圖像所呈現(xiàn)的世界與圖像觀看者之間的關系,同時表達圖像觀看者對表征事物應持有的態(tài)度(張敬源 等,2012)。 實現(xiàn)互動意義主要依賴接觸(contact)、社會距離(social distance)、態(tài)度(attitude)和情態(tài)(modality)四個要素。 接觸指圖像中的參與者與觀看者通過目光建立起來的一種想象中的關系。 社會距離決定圖像參與者和觀看者之間的親疏關系,進而展示一種社會關系。 這種親疏關系主要通過鏡頭取景的框架大小得以體現(xiàn),特寫或近鏡頭、長鏡頭、中鏡頭分別表示不同的親疏關系。 態(tài)度指圖像觀看者對圖像參與者的態(tài)度,主要通過視角體現(xiàn),水平角度體現(xiàn)觀看者介入圖像世界的程度,垂直角度則體現(xiàn)兩者的地位差異。 情態(tài)強調圖像世界反映現(xiàn)實的真實度,與色彩飽和度(color saturation)、色彩區(qū)分度(color differentiation)、色彩協(xié)調度(color modulation)、語境化(contextualization)、再現(xiàn)(representation)、深度(depth)、照明(illumination)和亮度(brightness)相關。 以色彩飽和度為例,如果顏色傳達情感,那么飽和度就是這種情感的飽滿度,飽和度等級就等同于感情從最強烈到最柔和的等級。 圖像飽和度高可能代表一種積極的、冒險肆意的或充滿活力的情感,而飽和度低則可能表達一種平淡、壓抑和陰郁的情感(Chen,2021)。
視覺圖像的構圖意義指圖像如何整合其再現(xiàn)意義和互動意義,從而形成一個有意義的整體,主要通過信息值(information value)、顯著性(salience)和取景(framing)實現(xiàn)。 信息值通過圖像中元素的位置安排來實現(xiàn),通過位置安排可以判斷圖像元素的地位、角色和重要性(Kress et al., 1996)。 也就是說,圖像元素在整個圖像的中央、邊緣、左側、右側、上方、下方等方位會傳遞不同的意義;取景指通過分割線條或分割框架來連接或隔斷圖像中的元素,來表達意義上的從屬或不從屬關系(張敬源 等,2012);顯著性指圖像元素對讀者注意力的吸引程度,通過前景、背景、相對大小、色調、清晰度等方面體現(xiàn)(Chen,2021)。
基于視覺符號傳遞信息的特點,要培養(yǎng)學生的視覺讀寫能力,我們可以首先引導學生認識單個視覺元素,讓其了解單個視覺元素的不同形式所表達的意義以及人們會如何感知這些視覺元素,會對這些視覺元素的不同形式產生何種聯(lián)想。 例如,線條的不同形式:曲線表達什么意義,直線、鋸齒線、水平線、垂直線又分別表達什么意義。 哪種顏色有什么具體及抽象的聯(lián)想意義,不同色調如何傳達不同的信息等等。
在學生了解基本視覺元素后,可以以視覺語法為指導,讓學生了解由各個視覺元素組合而成的圖像如何通過相對大小、位置安排、前景背景設置、色調、色彩飽和度、分割線、鏡頭長短、視角、人物目光注視方向等細節(jié)設置實現(xiàn)再現(xiàn)意義、互動意義和構圖意義。 在具體操作上,可以給學生呈現(xiàn)一幅圖片,然后以提問的方式引導學生對圖像意義進行深度理解。 比如可以問學生:什么是前景? 什么是背景?圖中人物在看什么? 圖中人物是用長鏡頭拍攝,還是中、短鏡頭? 這樣的拍攝給你什么樣的感覺? 某個人物或物體在整幅圖像占據(jù)中心位置,還是邊緣位置,是在左邊還是右邊,上面還是下面? 這樣的位置傳達出什么信息? 圖像使用了什么色調? 這種色調給你什么樣的感覺?
除了提問引導,還可以通過圖像對比的方式加深學生對圖像細節(jié)設置的認知。 比如呈現(xiàn)一幅圖畫中兩個人物大小、位置的差異,讓學生推敲這種差異代表什么意思,是否代表兩個人物地位的不同? 也可選擇報道同一事件的不同新聞圖片,讓學生分析圖片中的前景和背景設置的差異,或是物像色彩飽和度等的差異,進而解讀作者看待該事件的不同視角和態(tài)度。
培養(yǎng)學生的視覺讀寫能力,就如同培養(yǎng)學生的語言讀寫能力一樣,可以從單個視覺元素到元素整合的規(guī)則和方式,讓學生逐步學會對視覺圖像進行深入細致的分析,為多模態(tài)翻譯奠定基礎。 不過,多模態(tài)翻譯涉及跨文化的圖像理解和創(chuàng)造,而圖像也和語言一樣,具有文化特殊性,因此在學生了解基本的視覺符號及其意義構建方式后,還需要培養(yǎng)學生的視覺符號文化差異意識。
2.2 激發(fā)學生視覺符號文化差異意識
如前所述,圖像和語言一樣,具有多重意義。 除了事實意義以外,其表現(xiàn)意義和內在意義都和圖像所處的文化背景有著非常密切的關系,具有文化特殊性。 對于同一個視覺符號,在不同的文化背景中,其所表達的表層含義或者隱性意義也會因此產生偏差。 如因漢民族先祖之一軒轅氏經(jīng)常穿黃衣,加之“黃”和“皇”諧音,黃色在中國便具有了皇權、尊貴之意。 而在西方文化中,由于背叛耶穌的猶大喜歡穿黃色衣服,黃色便有了背叛、卑鄙的聯(lián)想意義。
此外,視覺符號相比文字符號更具多義性,在編碼和解碼的過程中由于文化差異極易出現(xiàn)誤讀。人們在理解文本時,一般都會下意識地基于自身的文化背景、生活經(jīng)歷和文化立場進行理解。 理解語言文本如此,理解視覺文本則更是如此。 如生活在中國文化背景下的讀者普遍能對龍鳳、麒麟、虎獅、如意、八卦等文化符號產生心理情感共鳴,而西方讀者則鮮有這樣的聯(lián)想。 若是在多模態(tài)翻譯中,譯者沒有這樣的意識,對這些圖像缺乏必要的解釋和說明,國外讀者便無法像中國讀者一般產生同樣的反應。 因此在進行跨文化多模態(tài)翻譯時,譯者必須要具有較強的視覺符號文化差異意識,在翻譯多模態(tài)文本時,一方面要立足原語文化語境理解圖像意義,同時也要預測目標讀者可能對原文圖像的反應,必要時增加語言解釋或改變圖像以避免目標讀者對圖像的誤讀,幫助讀者理解圖像所代表的真正含義。此外,在運用圖像對原語語言文本進行翻譯時,更是要選擇目標讀者易于接受的圖像,輔助傳達原文意義。 若是無法進行視覺圖像的歸化處理,就需要通過語言對視覺圖像進行額外解釋,避免讀者對圖像產生誤讀。
因此,培養(yǎng)學生的視覺讀寫能力,非常有必要激發(fā)學生對于圖像的文化差異意識。 這可以分兩個層面進行。 首先是通過對比,讓學生了解單個視覺元素的文化特殊性,如圖像的色彩、位置所代表含義的文化差異。 然后再展示不同國家、民族和文化在傳遞某一主題內容的圖像,引導學生挖掘圖像所傳遞的獨特文化信息,以強化學生的文化意識,使學生在進行多模態(tài)翻譯的過程中,能夠識別展現(xiàn)了獨特文化信息的視覺元素,進而判斷這些視覺元素是否可能給目標讀者帶來理解困難或是引起誤讀。 如有,則需在語言翻譯上進行解釋。 例如,在浙江嘉興的宣傳片中,出現(xiàn)了一艘紅船。 這艘紅船代表著什么樣的含義? 又比如在《話說中國節(jié)》宣傳視頻中介紹冬至演變成祭天祭祖的節(jié)氣,為什么畫面只呈現(xiàn)了點燃的香燭? 介紹立冬補冬為什么呈現(xiàn)的是煲湯的畫面? 提到以二十四節(jié)氣為靈感的美食菜品,為什么會搭配餃子的畫面? 介紹七夕時為什么畫面會出現(xiàn)一對鴛鴦? 多模態(tài)文本中存在的不少文化細節(jié)能讓原文讀者感知并產生情感共鳴,但他國文化的讀者未必能理解其中的內涵。 在翻譯這樣的多模態(tài)文本時,譯者若不能識別這類文化信息并進行額外處理,目標觀眾便很難理解這些圖像的深層文化意義,導致文本整體意義的傳達受到影響。
2.3 訓練學生識解各種圖文關系,熟悉多模態(tài)整合策略
多模態(tài)文本總是通過語言和非語言模態(tài)共同構建意義。 在進行多模態(tài)翻譯時,譯者必須清楚多模態(tài)文本中的圖像和文字是如何進行互動協(xié)調的,以及在傳遞某個信息時圖像和文字之間的關系是怎樣的,才能確定如何整合圖像和文字以實現(xiàn)信息的最佳傳播效果。 例如,若是圖像和語言文本傳遞同樣的信息,語言翻譯時便可以酌情刪減某些信息。 若是在傳達某個信息時,圖像展示更多細節(jié)信息,是對文本部分內容的例證,翻譯時語言翻譯便可以采用泛化策略。 若是圖像解釋拓展文本,提供了更為具體的信息,譯者也可以根據(jù)圖像信息將文本內容具體化。 如葛浩文在翻譯陳絲雨配圖的《山海經(jīng)》時,很多時候都結合圖像,對原文進行了泛化或具體化處理。 以對蠱雕的翻譯為例,原文為“水有獸焉,名曰蠱雕,其狀如雕而有角,其音如嬰兒之音,是食人”。 陳絲雨為蠱雕繪制了非常精致的插圖,呈現(xiàn)了更多的細節(jié)信息,葛浩文的英譯本則根據(jù)插圖所呈現(xiàn)的蠱雕形象,對蠱雕進行了更為具體的描述:
It was the source of the Zegeng River, which flowed east and emptied into the Pang River, where lived a strange man-eating creature that resembled, but was not, an ordinary bird. A horned vulture, the Gudiao had a richly feathered body, a serpentine tail, and a head with a hooked beak and a single horn from which several pointed ends bent backward(Goldblatt, 2021 : 22-23).

圖2 蠱雕
原文對蠱雕外形的描述非常簡單,只提到了“其狀如雕而有角”,但譯文卻進行了非常詳細的描述,增加了“richly feathered body, a serpentine tail, and a head with a hooked beak and a single horn from which several pointed ends bent backward”諸多細節(jié)信息。 同時,該譯本使用了指涉極為廣泛的“creature”翻譯原文的“獸”。 若是沒有插圖,“creature”很難讓人對所指對象產生具體的想象,但配上插圖,這一泛化表達便絲毫無損目標讀者對這一異獸形象的理解和認知。
因此,要培養(yǎng)學生的多模態(tài)翻譯能力,除了前面提到的熟悉視覺元素及其意義構建方式,了解視覺符號的文化差異,還需要訓練學生識解圖文關系,并在此基礎上使用恰當?shù)膱D文整合策略,充分利用圖文各自的優(yōu)勢傳遞信息。 對于這一點,也可以分為兩個步驟進行。 首先可以給學生呈現(xiàn)大量體現(xiàn)不同圖文關系的多模態(tài)文本,引導學生分析文字和圖像分別傳遞什么信息,兩者各自傳遞的信息有什么關系。 然后再引導學生將圖文結合的信息用另一種語言翻譯出來,設置一些如空間、時間因素限制,或者告知學生目標讀者不同于原文讀者的認知習慣,提示學生在圖像保持不變的情況下,語言可以進行什么樣的調整,或者能否根據(jù)翻譯目的和目標語境的要求,調整圖像形式,若是圖像進行調整,語言又可以進行什么樣的改動。 例如下面這部杭州宣傳片中出現(xiàn)一幅說明杭州變化的片段:

圖3 杭州宣傳片片斷
這幅畫面背景模糊化,凸顯了居于畫面中間的蝴蝶破蛹而出這一意象,以表達杭州的蛻變成長。原文,也就是中文字幕“成蛹、破繭、化蝶”和圖像是一種“冗余”關系,即圖像與語言兩種不同的模態(tài)符號表達的是同樣的信息。 若是將“成蛹、破繭、化蝶”都譯為英文,英文字幕便幾乎要占據(jù)整排屏幕空間,目標讀者未必能夠在圖像停留的短暫時間內看完所有字幕。 因此,翻譯這句字幕時便可以提醒學生,不必譯出原文所有內容,而是只選擇“破繭”這一中間階段進行翻譯,譯為“emerging from its cocoon”,這一英文表達結合圖像,同樣可以完整呈現(xiàn)原文語言和圖像表達的意義。
除了通過多模態(tài)文本的翻譯訓練學生對多模態(tài)翻譯策略的使用,也可以給學生一篇純語言表達的文本,讓學生分析文本中哪些內容可以使用圖像來傳達,圖像和文本可以形成什么樣的關系。 使用了圖像后,語言的翻譯又可以進行什么樣的調整。 通過諸如此類的反復訓練,逐漸扭轉學生僅僅使用語言傳達信息的習慣,強化其整合使用語言模態(tài)和非語言模態(tài)的意識。 如此,在進行多模態(tài)翻譯時,才能真正有效地利用多模態(tài)優(yōu)勢傳遞原文信息。
3 結語
如今我們已經(jīng)進入一個數(shù)字化時代。 在這樣的時代,圖像無處不在,讀圖成為一種風尚,思想和信息越來越依賴視覺形式進行傳播,多模態(tài)語篇成為信息傳播的主流。 相應地,在翻譯領域,多模態(tài)翻譯也必定會占據(jù)越來越重要的位置。 要滿足這個時代翻譯市場的需求,就必然需要譯者具備多模態(tài)翻譯能力。 多模態(tài)翻譯涉及多種模態(tài)符號的意義處理,那么多模態(tài)翻譯能力除了包括語言翻譯能力,就還應該包括非語言視覺符號處理能力以及將語言符號和非語言符號進行有機整合的能力。 歸納起來,就是語言翻譯能力、視覺讀寫能力和多模態(tài)整合能力。 視覺讀寫能力又具體包含視覺信息理解能力和視覺圖像設計創(chuàng)造能力,多模態(tài)整合能力具體包括圖文關系識別構建能力以及圖文互動策略能力。 要培養(yǎng)這些能力,我們首先需要引導學生識別基本視覺元素,然后以視覺語法為指導,了解由視覺元素組合而成的視覺圖像的意義構建原則和方式,同時激發(fā)學生視覺符號文化差異意識,通過文化對比,讓學生學會理解圖像深層含義,然后訓練學生識解各種圖文關系,熟悉多模態(tài)整合策略,逐步培養(yǎng)學生的多模態(tài)翻譯能力,滿足數(shù)字化讀圖時代翻譯市場的需求。
猜你喜歡
新少年(2022年9期)2022-09-17 07:10:54
幼兒園(2021年6期)2021-07-28 07:42:14
小天使·一年級語數(shù)英綜合(2020年6期)2020-12-16 02:56:41
小學生學習指導(低年級)(2019年11期)2019-11-25 07:31:48
小學生導刊(2017年13期)2017-06-15 20:29:38
湖北經(jīng)濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
天津科技大學學報(2015年4期)2015-04-16 04:55:11
北極光(2014年8期)2015-03-30 02:50:51
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
