基于自適應特征融合的無人機小目標檢測算法
2024-01-02 00:00:00趙濱淋陳功李勝
山東農業大學學報(自然科學版) 2024年6期




摘 要: 本文提出了一種針對無人機捕獲圖像的目標檢測算法,旨在解決無人機視角下小目標檢測存在漏檢現象嚴重、檢測精度低的問題。主要改進包括重新設計聚類算法生成更準確的先驗框,引入自適應特征融合模塊以使模型更靈活地學習上下文特征信息,更改檢測頭在較大的特征層上進行目標檢測并解耦分類和回歸任務。通過在VisDrone2019 數據集上進行廣泛實驗,改進后的YOLOv5s 模型相較于基準模型在mAP50 上提高了5.8%,并且保持了較高的幀率(67 FPS)。實驗結果表明該改進方法能夠顯著提高模型的檢測性能,使其適用于復雜的無人機捕獲場景。
關鍵詞: 小目標檢測;檢測頭;特征融合;聚類算法
中圖法分類號: TP391.4 文獻標識碼: A 文章編號: 1000-2324(2024)06-0814-12
隨著無人機技術的發展,無人機視角下的目標檢測在軍事、安防、農業、環境檢測、自動駕駛、災害響應等領域具有廣泛的應用,所以研究無人機視角下的目標檢測技術具有極大的應用價值。在計算機視覺領域,目標檢測一般分為傳統目標檢測和基于深度學習的目標檢測。傳統的目標檢測的算法主要有Hough Forest[1]、BoostedCascade of Simple Features[2]、Template MatchingTechniques[3]等方法。這些方法在被提出時是非常有影響力的,但是這些方法具有對光照和視角變化敏感、難以處理遮擋、不適應復雜背景、手工設計特征的限制以及不支持端到端學習等劣勢,這些劣勢導致了深度學習方法的興起。深度學習方法通過卷積神經網絡(CNN)自動學習特征,并在端到端的框架中優化整個目標檢測系統。如今深度學習方法在目標檢測領域取得了顯著的進展,特別是在處理復雜場景和大規模數據時具有明顯的優勢,所以基于深度學習的目標檢測方法逐漸取代了傳統方法,取得了更好的性能。
基于深度學習的目標檢測技術主要分為兩種。一種是先生成候選框,再對這些候選框進行分類和回歸的兩階段目標檢測算法,主要以RCNN[4]、Faster-RCN[5]為代表。另外一種是通過單個前向傳播過程直接完成目標的分類和位置回歸的單階段目標檢測算法,主要以YOLO系列算法[6-9]、SSD[10]、RetinaNet[11]為代表。隨著對深度學習方法的深入研究,基于深度卷積神經網絡的目標檢測算法基本上可以滿足各場景需求,但是大多數的目標檢測算法是為自然場景圖像設計的,如果直接應用以前的目標檢測模型來解決無人機視角下的目標檢測主要存在問題如下:(1)無人機飛行高度變化大,所以目標尺度變化不一,拍攝圖像中的物體尺寸各異。(2)無人機拍攝的圖像小、物體多、密度大。(3)物體之間存在重疊,難以捕獲正確目標。(4)無人機拍攝的圖像由于覆蓋面積大,包含豐富的地理元素,所以系統很難進行區分。以上問題使得無人機視角下的小目標檢測具有極大的挑戰性。周華平等人[12]在YOLOv5 基礎上引入通道注意力,提升了對小目標的檢測效果。齊向明等人[13]針對小目標圖像檢測中存在相互遮擋、背景復雜和特征點少的問題,基于YOLOv7 提出一種重構SPPCSPC 與優化下采樣的小目標檢測算法,但是在輕量化方面還需要有所改進。Zhu 等人[14]提出了TPH-YOLOv5,通過在YOLOv5 中添加了一個預測頭,并在頭部應用了Transformer 編碼器塊以形成Transformer檢測頭,提高了無人機圖像中高密度遮擋小物體的檢測,但是極大的提高了計算量。Liu 等人[15]提出SEC2F,提升網絡對小目標的敏感性,以及提出改進空間金字塔池化層以提高目標檢測的準確率,但是檢測效果并不是很好。Xu 等人[16]在骨干網絡中引入可變形卷積,從而在不同感受野提取特征,同時利用上下文特征提高了小目標的檢測精度。考慮到實時性,谷歌采用深度可分離卷積替換傳統卷積,提出了MobileNet[17]骨干網絡,大幅度降低了計算量,從而使模型能夠部署在邊緣設備上。
研究無人機下的小目標檢測對農業有望提供更全面、準確的信息,幫助農業實現智能化、高效化管理,提高產量和質量,降低生產成本,對農業可持續發展具有積極的推動作用。結合無人機拍攝圖像的特點以及考慮到單階段目標檢測的優點,本文采用YOLOv5s 算法作為基準算法,改進該算法用于解決無人機視角下的小目標檢測存在的漏檢和誤檢問題。主要工作如下:改進K-means 聚類算法中的距離度量,使用IOU作為距離度量。使用重構的C2F 模塊替換原有的C3模塊,加強對小目標的識別能力。更換檢測頭,在較大的特征層上進行檢測,使更多小目標能被檢測到。將檢測頭進行解耦,采用兩個分支進行分類和回歸,使網絡能夠進行差異性學習。
1 YOLOv5s 基準算法
YOLO目標檢測算法是全卷積的單階段目標檢測算法,YOLOv5s 相對較小的模型設計使得它在實時目標檢測方面表現優異。這對于需要低延遲響應的應用,如自動駕駛、實時監控等領域非常重要。所以YOLOv5s 非常適合用于無人機視角下的目標檢測。
YOLOv5s 主要由Backbone、Neck、Head 三部分組成。其中Backbone 由Conv 模塊和C3 模塊構成,負責從輸入圖像中提取特征。作用是逐漸降低圖像分辨率,同時增加特征圖的深度,以在不同層次上捕獲圖像的語義信息。這些特征圖將被傳遞給后續Neck 和Head。在YOLOv5中,Neck 部分采用了PANet(Path AggregationNetwork)結構,該結構通過橫向連接和信息傳遞來實現多尺度特征融合,從而實現不同層的特征圖進行上下文信息融合。有助于提高模型對不同尺寸目標的檢測能力。Head 通過1×1 的卷積進行通道數的調整,從而完成目標分類和目標位置回歸。
2 改進YOLOv5s
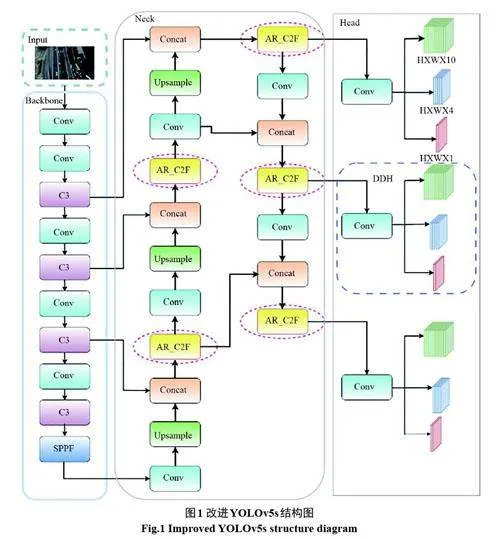
針對無人機視角下的小目標檢測存在的難點,考慮到檢測精度以及檢測速度,對YOLOV5s算法進行改進。首先,改進K-means 聚類算法,使生成的錨框更加適合小目標,同時為了保留更多的小目標特征信息,設置輸入網絡的圖片尺寸為960×960,并且把個別檢測頭更改為適合小目標的檢測頭。其次,使用自適應的上下文特征融合模塊,使網絡自適應自融合的整合上下文信息,幫助模型進行檢測。最后,對檢測頭解耦為兩個分支,使兩個分支分別做目標分類和邊界框回歸,提高目標分類準確率和邊界框回歸的精度,從而增強網絡對小目標的捕獲能力。本文的總體架構如圖1所示。
2.1 改進K-Means聚類算法
YOLOv5s 是一種基于先驗框的單階段檢測算法,如果網絡一開始選擇了合適的先驗框,那么神經網絡更容易去學習特征,得到較好的檢測模型。K-Means 是一種經典且有效的聚類方法,通過計算樣本之間的相似程度將較近的樣本聚為同一簇。在使用K-Means 聚類生成anchors時,如何衡量兩個樣本之間的相似性對聚類效果相當重要。YOLOv5s 采用K-Means 聚類算法加上遺傳算法,使用歐式距離作為衡量樣本之間的相似性。首先,該算法隨機生成K個點作為初始聚類中心,將每個數據點分配到最近的聚類中心。然后,根據數據點重新計算聚類中心的位置。最后,重復上述步驟直至收斂。但是使用歐式距離衡量樣本之間的相似性對離群值敏感,可能會導致一些離群值對聚類結果產生較大影響。對于尺度差異較大的邊界框,因為尺度較小的樣本框在歐式距離計算中受到較大的懲罰。可能會導致對小目標的樣本框聚類效果不佳。
IOU(boxes, anchors)[18,19]是目標檢測中常用的評價指標,它度量了兩個邊界框的重疊程度,所以本文采用IOU作為衡量樣本的相似性。IOU相對于絕對坐標更加具有魯棒性,有助于克服使用歐式距離時可能出現的尺度差異問題,能夠更好地抵抗尺度變換。使用IOU 作為距離度量也可以更好地考慮目標框之間的重疊情況,這對于物體檢測任務中存在物體重疊的情況非常重要。盡管GIOU、DIOU等一系列IOU變形考慮了邊界框形狀和中心距離,可能在某些情況下優于IOU。考慮到其計算效率和計算復雜度,本文選擇IOU作為改進K-Means聚類算法的距離度量標準。
算法具體實現:(1)在所有的boxes 中隨機挑選K個boxes作為簇中心。(2)計算每個boxes離這K個boxes 的距離(1-IOU)。(3)把每個boxes 分配到離K個簇中心中距離最小的那個簇。(4)根據每個簇中的boxes重新計算簇中心。(5)重復(3)、(4)直到每個簇中的元素不再發生變化。
2.2 自適應特征融合模塊
無人機拍攝的圖像由于覆蓋面積大,包含地理元素,所以圖像背景復雜,目標尺度較小。所以在網絡模型中引入注意力機制是一種常見的方法,可以幫助模型更加集中地關注圖像中的重要區域,從而提高檢測性能。注意力機制通過對不同空間位置或通道的信息賦予不同的權重,使網絡能夠更自適應的關注與任務相關的區域特征。通道注意力機制更加關注對當前任務有用的通道,有助于網絡更好地理解通道之間的關系。空間注意力機制能夠更集中地關注對當前任務有用的區域,有助于模型更好地理解圖像的空間結構。
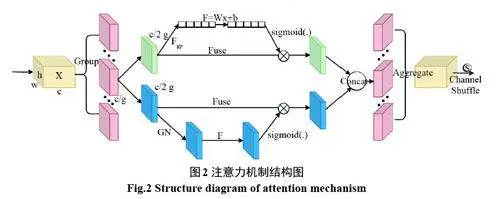
同時使用這兩種注意力機制,能更全面地捕獲圖像特征,能達到更好的效果,但無疑也增大了計算量。而Shuffle Attention[20]結合了這兩種注意力機制,使用多分支結構,并且使用組卷積降低了計算量。Shuffle Attention 使得網絡自適應的整合了局部特征及其全局依賴關系。其結構圖如圖2 所示,首先將輸入的特征圖劃分為g個組,把每個組中的特征圖沿通道維度分為兩個分支,一個分支使用通道注意力機制,另一個分支使用空間注意力機制。然后把兩個分支進行拼接,將組內的信息進行融合。最后使用Channel Shuffle 操作對特征組進行重排,從而使組間信息沿通道維度流動。
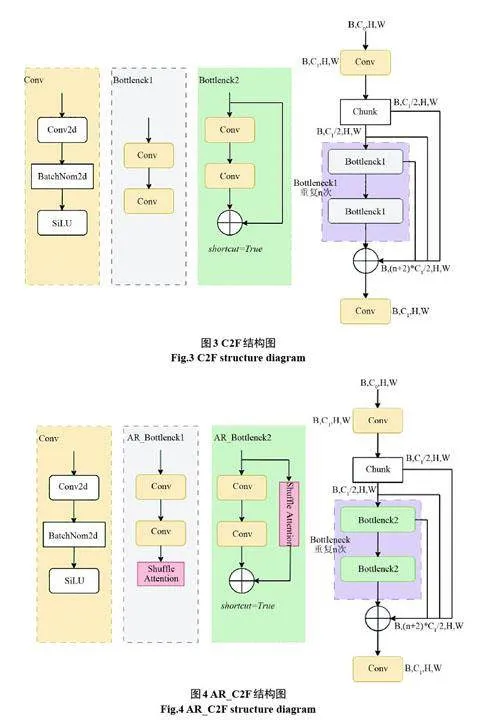
C2F 模塊是在C3 模塊基礎上改進的,上層特征圖經過一個卷積后,在通道維度上分為兩個分支,一個分支經過n 個Bottleneck block 所得到的輸出直接與另一個分支進行拼接。其結構圖如圖3 所示。在C2F 模塊中的Bottlenck 中加入Shuffle Attention 注意力機制把C2F 重構為AR_C2F 模塊,如圖4 所示。這樣不僅能提供更豐富的梯度信息還能保證模型更加輕量化,同時還能使得模型自適應的整合了局部特征及其全局依賴關系,從而有助于提高模型的查全率以及準確率。
2.3 更換檢測頭
由于無人機視角下的目標大多數是小目標,所以本文更換檢測頭(Change detection head),使得訓練出的模型更加適合小目標檢測。
更大的特征圖通常也意味著減少了對圖像的下采樣次數,有助于保留更多的細節信息,這樣模型能更好地捕獲目標的細節信息,這對于小目標而言尤其重要,因為小目標的細節信息可能決定了它們的類別和位置。在更大的特征圖上進行位置回歸,尤其是在目標尺寸較小時,模型更有可能準確定位目標的邊界框,這樣有助于提高目標檢測的準確性。采用更大的特征圖也可以降低誤檢率,降低將背景誤認為目標的可能性。而且在密集場景中,目標可能相互靠近,更大的特征圖也能使模型更容易分辨和定位這些密集的小目標,提升了模型的魯棒性。
2.4 混合解耦檢測頭
YOLOv5 的檢測頭原本是一個耦合頭,借助一個1×1 的卷積調整通道數,目標分類和位置回歸兩個任務耦合在一起進行。但是在目標檢測任務中,分類和回歸任務的難度是不盡相同的,分類任務常常會受到類別不均衡或者某些類別難以區分的樣本的影響,耦合頭這種設計可能會導致兩個任務互相干擾。耦合頭難以區分分類和回歸任務的優先級,在一些情況下,對于某些目標,可能位置回歸更為重要,而在其他情況下,目標分類可能更為重要。
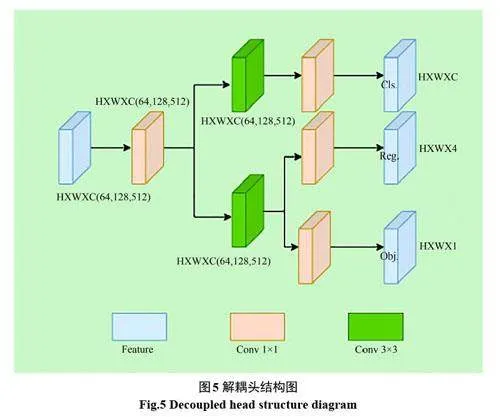
本文對檢測頭進行解耦處理,其結構如圖5所示。使用解耦頭(Decoupled detection head)后,解耦為兩個分支,使其分類和回歸任務的學習過程相互獨立,模型在學習不同任務時更加靈活,兩個任務之間不會相互干擾,可以提高模型的泛化能力。解耦頭也有助于模型更好地適應不同尺度的目標,特別在涉及小目標場景中,由于回歸任務得到獨立的學習,可以期望在目標定位上取得更加準確的效果。而且不同的應用場景可能對分類和回歸任務的需求不同,解耦頭允許模型在這兩個任務上進行有差異性的學習,從而更加適應不同的需求。
算法具體實現:(1)使用1×1的卷積調整通道數。(2)將輸入特征復制兩份,各自經過3×3 的卷積。(3)一個分支通過1×1的卷積把通道調整為類別數,本文為10 類別。(4)另一個分支通過1×1 的卷積,然后把該層特征復制成兩份,其中一個分支通過1×1的卷積把通道調整為4,用于確定目標的坐標以及寬高。另一個分支通過1×1的卷積把通道調整為1,從而確定目標的置信度。
3 實驗分析
3.1 實驗環境與數據集
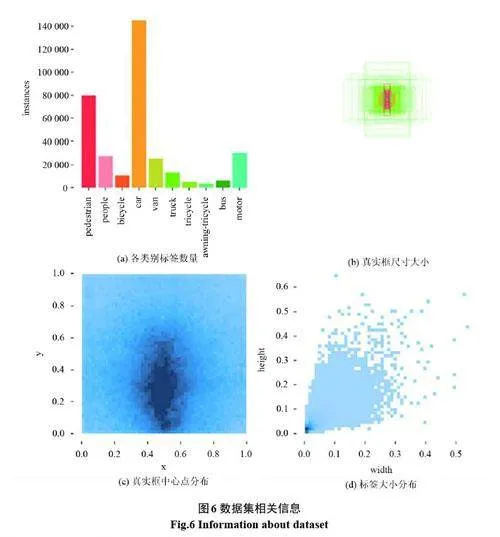
本文使用天津大學AISKYEYE團隊采集并制作的VisDrone2019 數據集[21],該數據集主要用于評估和推動無人機視覺任務中的目標檢測和跟蹤算法的發展。數據集是在不同場景、不同天氣和不同光照條件下使用不同型號的無人機收集的,人工標注了超過260 萬個真實框或感興趣的目標點,主要包括了十個類別,分別是:行人(pedestrian)、人(people)、自行車(bicycle)、轎車(car)、貨車(van)、卡車(truck)、三輪車(tricycle)、遮陽篷三輪車(awning-tricycle)、公共汽車(bus)、摩托車(motor)。該數據集也已經分別劃分好了訓練集、驗證集、測試集。數據集相關信息如圖6 所示。可以看出數據集中的類別分布極其不平衡,某些樣本數量遠遠多于其他類別,就引入了一定的數據偏斜問題,影響了模型在其他類別上的性能。
查看數據集,如圖7 所示。無人機視角下的圖像通常包含復雜的場景、具有大量小目標,這使得區分目標與背景變得復雜。由于無人機在飛行過程中的不同高度和視角,圖像中的目標會出現大幅度的尺度變換,特別是小目標。由于拍攝過程中,受到陰影或者強光的影響,造成圖片模糊或者失真。以上因素都造成了該數據集在目標檢測和識別任務中面臨著一些挑戰和困難。
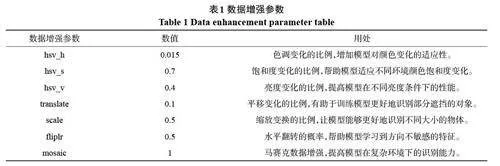
實驗過程中采用的windows 電腦配置如下:Intel(R)i5-12400F 的CPU,32G 內存,NVIDIAGeForce GTX 3060 12G 的圖像處理器。Python版本3.7.16,Pytorch 版本為1.11.0。訓練輪次(epoch)初始為200,批處理大小為8,采用SGD梯度下降優化器。數據增強參數如表1 所示,表中未提及參數都默認為0,這些數據增強方法通過隨機地應用圖像變換,有效地擴展了訓練數據集的多樣性,從而提高了模型對于實際應用場景的適應性和魯棒性。
3.2 評價指標
為了驗證模型性能,本文選用精確率(Precision, P)、召回率(Recall, R)、平均精度均值(mean average precision, mAP)和檢測速度FPS來評估模型的檢測性能。
3.3 消融實驗
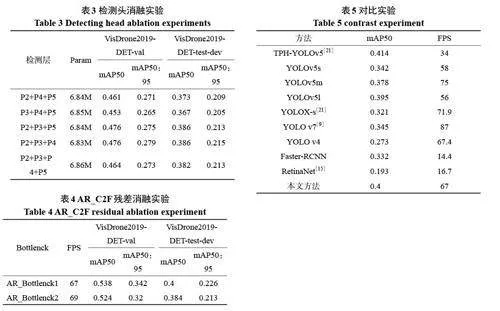
為了驗證本文設計的改進K-Means 聚類算法、自適應特征融合模塊(AR_C2F)、更換檢測頭(CDH)、解耦檢測頭(DDH)的有效性。本文在YOLOv5s 原模型的基礎上進行改進,對于以上改進部分進行消融實驗。在VisDrone2019-DET-test-dev 數據集上進行測試,采用mAP50 和FPS作為評價參數。
從表2 可以看出,在原有的模型上分別改進四個模塊后,mAP50 分別提升了2%、2.3%、4.4%、3.9%。可以看出,這四個模塊分別對小目標檢測任務都有一定的提升作用。實驗E,當同時使用改進K-Means、AR_C2F、CDH等模塊時,可以看到在該測試集上,mAP50 達到了39%,提升了4.8%。實驗F,當同時使用改進K-Means 聚類、CDH、DDH等模塊時,在該測試集上,mAP50達到了39%,提升了4.8%。最后在實驗G上,當四個模塊進行耦合時,可以看到與未改進的YOLOv5s 相比,mAP50 達到了40%,提升了5.8%。
3.4 檢測頭消融實驗
為了驗證選取的檢測頭是否有效,如表3 所示,可以看出使用P2+P3+P4 檢測層后,mAP50為0.386,并且參數量最低。證明更換后的檢測頭,保留了更多小目標的特征信息,降低了小目標的漏檢和誤檢。同時減少了網絡的冗余,減少了參數量。加快了網絡的收斂速度。
3.5 AR_C2F殘差消融實驗
在AR_C2F 中,Bottlenck 有兩種結構,即一種是帶殘差連接的,一種是不帶殘差連接的。經過一系列實驗,研究Bottlenck 模塊中的殘差連接對目標檢測性能的影響,并探究其對性能的貢獻。結果如表4 所示。實驗結果表明,在殘差連接下,模型的性能達到最佳水平,移除殘差連接導致了精度的下降,特別是在小目標檢測方面。所以采用帶殘差的模塊構建最終模型。
3.6 對比實驗
通過進行大量實驗對比了改進后的算法與其他主流算法在VisDrone2019-DET-test-dev 數據集的表現效果,以驗證改進方法的有效性。對比結果如表5所示。
從表5 可以看出,本文方法與雙階段算法相比,如Faster-RCNN,本文mAP50 高出6.8%。而對比專注于小目標算法的TPH-YOLOv5 算法,由于引入了Transformer 預測頭,導致計算量較大,所以推理速度較慢,本文方法在精度上與之差別甚微,但是速度上相比卻更有優勢。對比YOLOV4、V7 以及其他所提到的YOLO 系列變形,本文方法的精度更高。可以看出本文方法在小目標檢測任務上有一定優勢,可以提高小目標檢測精度。
3.7 可視化分析
為了確認本文改進方法是否有效,本文選擇了小目標、多目標密集場景下的圖像進行可視化。對TP、FP、FN 指標分別使用綠色、藍色、紅色進行可視化。TP 代表了正確檢測的樣本,FP表示誤檢的樣本,FN表示漏檢的樣本。
圖8(a)為小目標場景下的對比效果,其中第一行的圖片為YOLOv5s 下的預測結果,第二行為使用本文方法預測的結果,第三行為原始的標注圖片。從圖上可以看出在小目標場景下,使用本文方法更能準確識別小目標。
圖8(b)為多目標密集場景下的對比效果,從圖上可以看出在多目標密集且存在遮擋現象時,本文方法更能區分目標種類,也能降低漏檢的概率。
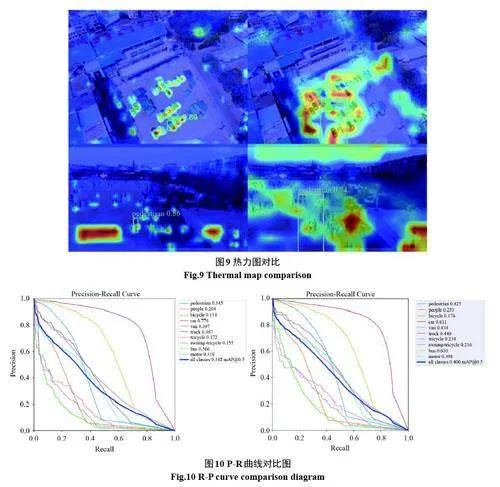
圖9 展示的是YOLOv5s 和本文算法的預測框中心點的熱力圖,左邊圖片是本文方法可視化結果,右邊是YOLOv5s 算法可視化結果,可以看出本文提出的自適應特征融合模塊使感知區域更為準確。
圖10 展示的是在原始YOLOv5s 模型(左)和本文改進算法(右)在測試數據集上進行推理得出的P-R 曲線,可以看出改進算法在各個類別上的平衡點比原始YOLOv5s 模型都更接近右上角,改進算法得到的模型較原始模型更能降低漏檢率,提高檢測準確率。說明本文改進算法對小目標的檢測精度具有較大提升并且同時能夠降低漏檢率。
4 結束語
本文在YOLOv5s 算法基礎上進行改進。提出了一種基于自適應特征融合的無人機小目標檢測算法。該算法采用IOU 作為K-Means 聚類算法中的距離度量生成先驗框;接著重構C2F模塊替換原有的C3 模塊,以提高網絡的自適應特征融合的能力;最后更換并解耦適合小目標檢測的檢測頭,這使得更多的小目標能夠被檢測到。同時允許分類和回歸任務獨立進行互不干擾,從而提升了檢測精度;經過一系列實驗證明,本文方法在無人機視角下的小目標檢測具有較好的檢測效果。能夠有效的完成密集小目標的檢測任務,該算法也可以遷移到很多農業場景,如精準農業管理、早期病蟲害檢測、水稻田和果園管理。但后期工作需要對模型進行優化,可以采用一系列剪枝算法、蒸餾算法對模型進行壓縮,提高其推理速度,使模型能夠在無人機上實際部署應用。
參考文獻
[1] Gall J, Yao A, Razavi N, et al. Hough forests for
object detection, tracking, and action recognition[J].
IEEE transactions on pattern analysis and machine
intelligence, 2011, 33(11): 2188-2202.
[2] Viola P, Jones M. Rapid object detection using a
boosted cascade of simple features[C]//Proceedings
of the 2001 IEEE computer society conference on
computer vision and pattern recognition. CVPR
2001. Ieee, 2001,1:I-I.
[3] Banharnsakun A, Tanathong S. Object detection
based on template matching through use of best-so-far
ABC[J]. Computational intelligence and neuroscience,
2014, 2014:919406.
[4] Girshick R, Donahue J, Darrell T, et al. Rich feature
hierarchies for accurate object detection and
semantic segmentation[C]//Proceedings of the IEEE
conference on computer vision and pattern
recognition. 2014: 580-587.
[5] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards
real-time object detection with region proposal
networks[J]. Advances in neural information
processing systems, 2015, 28.
[6] Redmon J, Divvala S, Girshick R, et al. You only
look once: Unified, real-time object detection[C]//
Proceedings of the IEEE conference on computer
vision and pattern recognition. 2016:779-788.
[7] Redmon J, Farhadi A. Yolov3: An incremental
improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
[8] Bochkovskiy A, Wang CY, Liao HYM. Yolov4:
Optimal speed and accuracy of object detection[J].
arXiv preprint arXiv:2004.10934, 2020.
[9] Wang CY, Bochkovskiy A, Liao HYM. YOLOv7:
Trainable bag-of-freebies sets new state-of-the-art
for real-time object detectors[C]//Proceedings of the
IEEE/CVF Conference on Computer Vision and
Pattern Recognition. 2023:7464-7475.
[10] Lyu Z, Jin H, Zhen T, et al. Small object recognition
algorithm of grain pests based on ssd feature fusion[J].
IEEE Access, 2021, 9: 43202-43213.
[11] Lin TY, Goyal P, Girshick R, et al. Focal loss for
dense object detection[C]//Proceedings of the IEEE
international conference on computer vision. 2017:
2980-2988.
[12] 周華平,郭 偉. 改進YOLOv5 網絡在遙感圖像目標
檢測中的 應用[J]. 遙感信息,2022,37(5):23-30.
[13] 齊向明,柴 蕊,高一萌. 重構SPPCSPC 與優化下采
樣的小目標檢測算法[J]. 計算機工程與應用,2023,
59(20):158-166.
[14] Zhu X, Lyu S, Wang X, et al. TPH-YOLOv5: Improved
YOLOv5 based on transformer prediction head for
object detection on drone-captured scenarios[C]//
Proceedings of the IEEE/CVF international conference
on computer vision. 2021:2778-2788.
[15] 劉 濤,高一萌,柴 蕊,等. 改進YOLOv5 的無人機視
角下小目標檢測算法[J/OL]. 計算機工程與應用:1-
16[2024-01-11].
[16] 徐 堅,謝正光,李洪均. 特征平衡的無人機航拍圖像
目標檢測算法[J]. 計算機工程與應用,2023,59(06):
196-203.
[17] Howard AG, Zhu M, Chen B, et al. Mobilenets:
Efficient convolutional neural networks for mobile
vision applications[J]. arXiv preprint arXiv:
1704.04861, 2017.
[18] Zheng Z, Wang P, Liu W, et al. Distance-IoU loss:
Faster and better learning for bounding box
regression[C]//Proceedings of the AAAI conference
on artificial intelligence. 2020, 34(07):12993-13000.
[19] Rezatofighi H, Tsoi N, Gwak JY, et al. Generalized
intersection over union: A metric and a loss for
bounding box regression[C]//Proceedings of the
IEEE/CVF conference on computer vision and
pattern recognition. 2019:658-666.
[20] Zhang QL, Yang YB. Sa-net: Shuffle attention for
deep convolutional neural networks[C]//ICASSP
2021-2021 IEEE International Conference on
Acoustics, Speech and Signal Processing (ICASSP).
IEEE, 2021:2235-2239.
[21] 彭晏飛,趙 濤,陳炎康,等. 基于上下文信息與特征
細化的無人機小目標檢測算法[J/OL]. 計算機工程
與應用,1-8[2024-03-06].
