基于概率猶豫模糊綜合距離測度的決策方法研究
2024-01-03 07:44:02劉贏關(guān)欣吳斌
西北工業(yè)大學(xué)學(xué)報 2023年6期
劉贏,關(guān)欣,吳斌
(1.海軍航空大學(xué),山東 煙臺 264000; 2.國防大學(xué) 聯(lián)合作戰(zhàn)學(xué)院,北京 100192)
決策是一個基于決策者認(rèn)知、偏好從多個方案中確定最終方案的過程。隨著問題研究的不斷深入,決策中的不確定性因素越來越多,面向精確數(shù)據(jù)的數(shù)學(xué)模型漸漸無法滿足決策的需求,基于這種背景,針對不確定性數(shù)據(jù)的決策問題研究成為現(xiàn)代決策理論發(fā)展的重要內(nèi)容。
Zadeh[1]于1965年首次提出模糊集的概念,通過模糊數(shù)表征專家的評估值,解決了決策信息的模糊表達(dá)問題。隨后,Torra[2]又提出猶豫模糊集的概念,它允許隸屬度可以是多個不同的值,但猶豫模糊集將每一個隸屬度的概率看作是相同的,無法將專家的偏好信息表達(dá)出來。
為了彌補(bǔ)上述缺陷,朱斌[3]將概率信息應(yīng)用到猶豫模糊集中,提出了概率猶豫模糊集(probability hesitant fuzzy set,PHFS)的概念。隨后,Zhang等[4]又通過減弱概率信息需要滿足的條件,改進(jìn)了PHFS的定義。得益于對概率信息的有效應(yīng)用,以及完善的數(shù)學(xué)表現(xiàn)形式,PHFS得到了學(xué)者的廣泛關(guān)注,也在集成算子、偏好關(guān)系理論以及決策方法等方面取得了一系列成果。其中,在集成算子的研究中,具有代表性的有歸一化集成算子[4]、基于Einstein運(yùn)算的集成算子[5]以及優(yōu)先權(quán)集成算子[6]等。此外,概率猶豫模糊偏好關(guān)系也有著較大的應(yīng)用前景,Zhou等[7]提出了預(yù)期一致性指標(biāo)用于評估概率猶豫模糊偏好關(guān)系的一致性程度;Li等[8]先后基于概率猶豫模糊偏好關(guān)系的加性一致性和Hausdorff距離,提出了建立群體內(nèi)部共識的算法,并且在可乘傳遞性的基礎(chǔ)上提出了概率猶豫積性偏好關(guān)系[9]。He等[10]將參考理想方法與PHFS相結(jié)合,提出了3種決策方法來解決多屬性決策問題。此外,相關(guān)學(xué)者在概率猶豫模糊聚類方法[11]、區(qū)間概率猶豫模糊集[12]以及概率對偶猶豫模糊集[13]等領(lǐng)域也做了相關(guān)研究,為概率猶豫模糊決策理論做了重要補(bǔ)充。
在PHFS的研究中,距離測度是研究人員十分感興趣的一個領(lǐng)域,但是這方面的研究并不多。其中,Gao等[14]研究了概率猶豫模糊環(huán)境下的應(yīng)急決策問題,首次定義了概率猶豫模糊數(shù)(probability hesitant fuzzy element,PHFE)的漢明距離;Su等[15]研究了基于距離的PHFS熵測度,并提出了傳統(tǒng)的漢明距離與歐式距離;方冰等[16]又在此基礎(chǔ)上提出了改進(jìn)的新型距離測度,并對其有效性和合理性進(jìn)行了數(shù)學(xué)證明。
事實(shí)上,現(xiàn)有PHFS的距離測度大多是在猶豫模糊集基礎(chǔ)上做簡單推廣,并沒有深入研究其內(nèi)部規(guī)律。現(xiàn)有距離測度的問題主要體現(xiàn)在3個方面:一是元素個數(shù)不同時,需要通過一定的規(guī)則進(jìn)行延拓補(bǔ)值,這也導(dǎo)致了誤差的引入;二是PHFE的元素多是按照數(shù)值大小順序重排;三是距離測度計算時,對隸屬度和概率兩者的考慮較為簡單,僅是對其進(jìn)行某種組合以建立兩者之間的聯(lián)系。事實(shí)上,概率猶豫模糊距離測度的定義要更為復(fù)雜,需要考慮的因素更多。
為了解決現(xiàn)有概率猶豫模糊距離測度的不足,本文定義了聚集性、離散性、模糊性和一致性4種特征,并基于這4種特征提出一種新的綜合特征距離測度,很好地克服了傳統(tǒng)距離測度的順序重排和隸屬度個數(shù)要求等限制條件。
本文首先介紹了PHFS的基本概念,通過分析現(xiàn)有概率猶豫模糊比較法則的不足,給出一種更為完善的比較法則,之后分析了當(dāng)前的概率猶豫模糊距離測度的缺陷,并提出了新的綜合距離測度,然后給出了熵權(quán)法的屬性權(quán)重確定方法以及基于TODIM的多屬性決策方法,最后通過仿真實(shí)例分析,驗(yàn)證了本文方法的合理性和有效性。
1 概率猶豫模糊集
本節(jié)簡要介紹PHFS的基本概念。
定義1[17]給定任意非空集合X,PHFSH定義為集合X到區(qū)間[0,1]上的一個概率分布函數(shù)映射,其數(shù)學(xué)表達(dá)式為
H={〈x,hx(Px)〉|x∈X}
(1)
式中:h(x)表示x屬于某集合E的隸屬度集合,取值為[0,1]上的子集;Px為h(x)中元素對應(yīng)的概率解釋,同樣為[0,1]上的子集。hx(Px)為PHFE,簡寫為h(P),其數(shù)學(xué)表達(dá)式為
h(P)={γλ|Pλ,λ=1,2,…,|h(P)|}
(2)

2 概率猶豫模糊比較法則
本節(jié)主要分析現(xiàn)有概率猶豫模糊比較法則的不足,并給出一種更為完善的比較法則。
2.1 傳統(tǒng)概率猶豫模糊比較法則
定義2給定任意PHFEh(P)={γλ|Pλ,λ=1,2,…,|h(P)|},其得分函數(shù)[18]定義為

(3)
在得分函數(shù)基礎(chǔ)上,離散函數(shù)[18]定義為
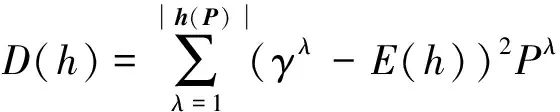
(4)
則對于任意2個PHFEsh1和h2,傳統(tǒng)比較法則描述如下:
1) 如果E(h1)>E(h2),則h1>h2;
2) 如果E(h1)=E(h2),則進(jìn)一步比較離散函數(shù):
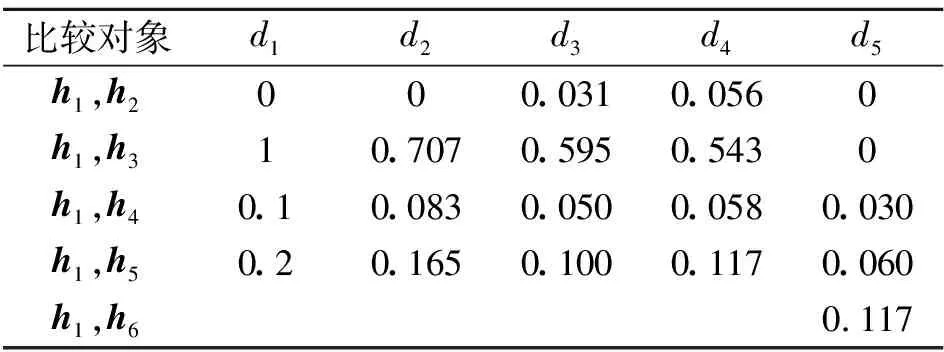
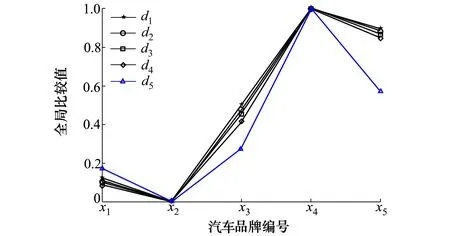
如果D(h1)>D(h2),則h1 如果D(h1)=D(h2),則h1=h2。 然而上述概率猶豫模糊比較法則存在一定的局限,當(dāng)兩PHFE的得分函數(shù)與離散函數(shù)都相等時,便無法對其進(jìn)行比較,通過例1進(jìn)行說明。 例1考慮最簡單的情況,給定兩PHFE 計算其得分函數(shù)和離散函數(shù)分別為 此時,根據(jù)上述比較法則進(jìn)行比較,會得到h1=h2的結(jié)論,顯然不合理。 上述分析表明,僅根據(jù)得分函數(shù)和離散函數(shù)并不能很好地解決PHFE的比較問題,因此需要對現(xiàn)有的比較法則進(jìn)行改進(jìn)。 實(shí)際上,PHFE中隸屬度本身包含認(rèn)知信息,當(dāng)隸屬度為0.5時,認(rèn)為其模糊和不確定性最大,此時,決策者對方案最不確定;當(dāng)隸屬度特別小或特別大時,決策者對方案的判決都很確定。因此可以根據(jù)隸屬度與0.5的接近程度來定義隸屬度的模糊度,將其納入新的比較法則。 定義3給定任意PHFEh(P)={γλ|Pλ,λ=1,2,…,|h(P)|},則隸屬度γλ的模糊度定義為 f(γλ)=1-2|γλ-0.5| (5) 于是可以得到h(P)中全部隸屬度的模糊度,實(shí)際上便得到了一個新的PHFEh(f) h(f)={f(γλ)|Pλ,λ=1,2,…,|h(P)|} (6) 容易得到,PHFEh(f)中的隸屬度為h(P)中對應(yīng)隸屬度的模糊度。分別定義h(f)的得分函數(shù)和離散函數(shù) 根據(jù)模糊度定義可知,h(P)中γλ的模糊度越大,則γλ描述的信息越不確定,此時對應(yīng)的PHFE應(yīng)該越小,這與客觀認(rèn)知相符。因此可以在得分函數(shù)、離散函數(shù)的基礎(chǔ)上,附加模糊度的概念,定義新的比較法則,給定任意2個PHFEsh1和h2,其模糊度對應(yīng)的PHFEs為h(f1)和h(f2),則新的比較法則描述為: 1) 如果E(h1)>E(h2),則h1>h2; 2) 如果E(h1)=E(h2),則進(jìn)一步比較離散函數(shù): 如果D(h1)>D(h2),則h1 如果D(h1)=D(h2),進(jìn)一步比較模糊度的得分函數(shù); 3) 如果E(f1)>E(f2),則h1 如果E(f1)=E(f2),進(jìn)一步比較模糊度的離散函數(shù): 4) 如果D(f1)>D(f2),則h1>h2; 如果D(f1)=D(f2),則h1=h2。 定義4記PHFEh1,h2,d(h1,h2)為h1,h2之間的距離測度,需要滿足以下公理性條件[14]: 1) 非負(fù)性:d(h1,h2)≥0; 2) 交換性:d(h1,h2)=d(h2,h1); 3) 反身性:d(h1,h2)=0?h1=h2。 同時,根據(jù)文獻(xiàn)[14-15]可知,PHFE間距離計算的前提是元素個數(shù)相等,當(dāng)不滿足這一前提時,需要通過一定手段對元素個數(shù)較少的PHFE進(jìn)行擴(kuò)充,如根據(jù)某種風(fēng)險規(guī)則重復(fù)添加隸屬度最大或者隸屬度最小的元素,并令其概率為0,這也是大部分文獻(xiàn)采用的方法[16]。 (9) 傳統(tǒng)歐式(Euclidean)距離定義為 (10) 定義6文獻(xiàn)[16]在上述距離測度的基礎(chǔ)上進(jìn)行改進(jìn),定義了一種改進(jìn)的漢明距離 d3(h1,h2)= (11) 相應(yīng)的,改進(jìn)的歐式距離定義為 d4(h1,h2)= (12) 但以上2種改進(jìn)的距離測度都存在相同缺陷,即要求PHFE的元素個數(shù)必須相等,否則無法適用,若不滿足,便需要通過一定方法進(jìn)行元素的延拓補(bǔ)全,這也導(dǎo)致了人為誤差的引入。因此,需要對現(xiàn)有的概率猶豫模糊距離測度做出改進(jìn)。 通過分析可知,現(xiàn)有概率猶豫模糊距離測度的限制主要為2個方面:①參與距離計算的PHFEs的元素個數(shù)必須相等;② PHFE中的元素需按照隸屬度大小重新排列,隸屬度相同的情況下,按照概率值大小排列。這2個條件,不僅人為引入了誤差,也限制了距離測度的應(yīng)用范圍和場景。因此,本節(jié)通過定義新的概率猶豫模糊距離,消除上述限制條件,從而達(dá)到擴(kuò)展距離測度應(yīng)用范圍的目的。 3.2.1 基于距離矩陣的PHFE距離測度 本節(jié)通過引入距離矩陣構(gòu)造新的距離測度,其中,距離矩陣中的元素由PHFE間的隸屬度距離對構(gòu)成。 定義7記h1,h2為任意兩PHFE,兩者元素個數(shù)分別為|h1|,|h2|,則h1和h2之間的距離矩陣定義為 Dh1,h2= (13) (14) 則基于距離矩陣的距離測度可通過矩陣中元素的均值定義,具體表達(dá)式為 (15) 分析(15)式可知,參與距離計算的PHFEs的元素個數(shù)|h1|,|h2|不需要相等,元素順序也不需要降序排列。因此,距離矩陣的引入很好地解決了現(xiàn)有距離測度的制約條件,完全保留了PHFE的原始信息,避免了人為誤差的引入。 然而,對新的距離測度需滿足的三要素進(jìn)行證明后發(fā)現(xiàn),本節(jié)基于距離矩陣的距離測度不滿足反身性條件,通過例2進(jìn)行說明。 例2分別采用文獻(xiàn)[15]中的距離測度d1,d2,文獻(xiàn)[16]中的距離測度d3,d4,以及本節(jié)基于距離矩陣的距離測度d5,對若干個典型PHFE的距離進(jìn)行計算,不同測度的計算結(jié)果如表1所示。 表1 不同距離測度計算結(jié)果 表中: h1={0.8|0.7,0.2|0.3},h2={0.7|0.8,0.3|0.2}, h3={0.3|0.2,0.7|0.8},h4={0.8|0.6,0.2|0.4}, h5={0.8|0.5,0.2|0.5},h6={0.8|0.6,0.3|0.2, 0.2|0.2}。 分析表1,可以得出以下結(jié)論: 1)d1~d4均無法度量h1與h6間的距離,且根據(jù)d5(h1,h6)=0.117,表明本節(jié)基于距離矩陣的距離測度d5解決了PHFE間元素個數(shù)不同條件下的距離計算問題; 2) 根據(jù)d5(h1,h2)=d5(h1,h3),表明新的距離測度下元素是否進(jìn)行順序重排對計算結(jié)果沒有影響; 3)d5(h1,h2)=0這一反例表明距離測度d5不滿足上述證明過程中的反身性,因此仍然存在一定的不足。 經(jīng)過上述分析,本節(jié)基于距離矩陣的距離測度雖然較好地解決了現(xiàn)有距離測度的限制,但仍存在一定缺陷。同時現(xiàn)有距離測度在一定程度上均屬于均值距離,衡量的是PHFE的部分特征,因此,為了完善本節(jié)的距離測度,還需要綜合考慮其他特征參數(shù)。 3.2.2 PHFE綜合特征距離 根據(jù)上節(jié)可知,基于距離矩陣的距離測度僅僅衡量了PHFE的部分特征,為了進(jìn)一步完善距離測度,本節(jié)定義了4種PHFE特征:聚集性、離散性、模糊性和一致性,并基于以上4種特征定義新的PHFE距離測度。其中,聚集性通過基于距離矩陣的距離測度表征,離散性通過離散函數(shù)表征,模糊性通過模糊度表征,一致性與元素數(shù)量有關(guān)。 在僅考慮PHFE元素個數(shù)的前提下,元素個數(shù)越少,表明專家進(jìn)行判斷時,觀點(diǎn)越一致,即不確定性越小。當(dāng)元素個數(shù)為1時,一致程度最大;隨著個數(shù)增加,一致性程度逐漸降低。 因此,將PHFEh的一致性定義為 (16) 式中,|h|表示PHFEh中的元素數(shù)量。 根據(jù)4種PHFE特征分別給出4種概率猶豫模糊特征距離的定義。 1) 聚集距離 (17) 2) 離散距離 (18) 3) 模糊距離 df(h1,h2)=|E(f1)-E(f2)|= (19) 4) 一致距離 (20) 基于以上4種特征距離,定義新的PHFE廣義綜合特征距離為 (21) 式中,αg,αd,αf,αc為4種特征的權(quán)重,滿足αg+αd+αf+αc=1。 廣義綜合特征距離可以理解為一種廣義閔式距離,當(dāng)p=1或2時,分別轉(zhuǎn)化為廣義曼哈頓距離和廣義歐式距離。 可以發(fā)現(xiàn),本節(jié)基于特征參數(shù)的綜合距離克服了此前概率猶豫模糊距離中元素個數(shù)相等和降序重排的限制,并且只有當(dāng)全部特征距離都等于0時,才可以得到兩者相等的結(jié)論,可以看作一種全距離。 3.2.3 PHFS綜合特征距離 在PHFE綜合特征距離的基礎(chǔ)上,本節(jié)基于廣義加權(quán)平均(GWA)算子給出PHFS綜合特征距離的計算方法。 (22) 式中,d(hA(Pxk),hB(Pxk))根據(jù)PHFE綜合特征距離計算,dGWA(A,B)根據(jù)λ取值的不同有多種形式: 若λ=1,得到加權(quán)平均(WA-based)距離 (23) 若λ=2,得到加權(quán)平方平均(WQA-based)距離 (24) 若λ=-1,得到加權(quán)調(diào)和平均(WHA-based)距離 (25) 基于以上,便實(shí)現(xiàn)了PHFS綜合特征距離的構(gòu)造,其基本流程如圖1所示。 圖1 概率猶豫模糊綜合特征距離構(gòu)造流程 屬性權(quán)重是決策的重要內(nèi)容,熵可以度量信息的不確定性,屬性的熵值越小,表明該屬性提供的信息量越大,在評價中所起的作用也越大,相應(yīng)的權(quán)重也越大。因此,本文通過熵權(quán)法[19]來計算屬性的客觀權(quán)重,具體描述如下: (26) (27) 由于本文主要對PHFS的距離測度進(jìn)行研究分析,并未對多屬性決策方法進(jìn)行深入研究,因此,僅在傳統(tǒng)TODIM方法[20-21]的基礎(chǔ)上,基于本文所提出的綜合特征距離,提出一種概率猶豫模糊環(huán)境下的多屬性決策模型,具體步驟描述如下。 已知決策矩陣H=[hi(Cj)]m×n,相關(guān)描述同第4節(jié)中一致。 若Cj為效益型,則 (28) 若Cj為成本型,則 (29) 式中:ρ為損失衰退參數(shù),用于模擬決策者心理,ρ≥1,其取值是前景理論的體現(xiàn),PHFE的比較和距離計算分別采用本文新的比較法則和PHFE綜合特征距離。 步驟2根據(jù)熵權(quán)法計算屬性客觀權(quán)重ω。 步驟3集成各屬性下的比較矩陣得到綜合比較矩陣Φ=[Φik]m×m,Φik的數(shù)學(xué)表達(dá)式為 (30) 式中,μ為集成參數(shù),一般取值為1,得到加權(quán)平均(WA-based)比較矩陣。 步驟4計算各方案的全局比較值ηi。 (31) 步驟5根據(jù)全局比較值對各方案進(jìn)行排序,即全局比較值最大的方案為最優(yōu)方案。 為了便于對比分析,采用文獻(xiàn)[22]中的實(shí)例對本文方法進(jìn)行驗(yàn)證。 現(xiàn)有3位專家di(i=1,2,3)對5種汽車品牌(別克(x1)、豐田(x2)、福特(x3)、奧迪(x4)和特斯拉(x5))的安全性進(jìn)行評估,專家權(quán)重為(0.4,0.4,0.2),通過制動系統(tǒng)a1、防抱死系統(tǒng)a2、穩(wěn)定系統(tǒng)a3、輔助約束系統(tǒng)a4和車身材料a5進(jìn)行評估,5種屬性均為效益型,評估值通過PHFE表示。 參數(shù)設(shè)置:聚集性、離散性、模糊性和一致性的權(quán)重分別為(0.4,0.2,0.2,0.2);綜合特征距離的特征集成參數(shù)λ=1,即采用加權(quán)平均距離;綜合比較矩陣中的集成參數(shù)μ=1,即采用加權(quán)平均比較矩陣;衰退損失參數(shù)ρ=1。3位專家的評估結(jié)果分別見表2~4。 表2 專家d1的評估結(jié)果 表3 專家d2的評估結(jié)果 表4 專家d3的評估結(jié)果 步驟1根據(jù)文獻(xiàn)[23]的集成方法計算PHFS中各隸屬度的總概率值,得到綜合評估信息如表5所示。 表5 綜合評估結(jié)果 步驟2計算屬性權(quán)重。 根據(jù)(3)式計算表5對應(yīng)得分函數(shù)矩陣見表6。 表6 得分函數(shù)矩陣 根據(jù)(26)式計算各屬性的熵值 e=(0.997 5,0.998 6,0.996 7,0.998 5,0.999 4) 根據(jù)(27)式計算各屬性的權(quán)重 ω=(0.268,0.152,0.351,0.162,0.067) 步驟3計算綜合比較矩陣。 以屬性a1下x1,x2的評估信息為例進(jìn)行說明 則根據(jù)新的比較法則 E(h1(C1))=0.658,E(h2(C1))=0.546 分別計算得到dg=0.017 5,dd=0.005 5,df=0.144,dc=0.083 3。 則有 重復(fù)上述過程,分別計算得到各屬性下的比較矩陣為 根據(jù)(30)式計算得到綜合比較矩陣為 步驟4計算各品牌汽車的全局比較值ηi。 η1=0.172,η2=0,η3=0.278,η4=1,η5=0.572 步驟5根據(jù)全局比較值進(jìn)行排序,得到 x4>x5>x3>x1>x2 因此,判定x4為安全性最好的汽車品牌,判定結(jié)果與文獻(xiàn)[22]中保持一致,證明了本文算法的有效性。 本節(jié)分別對綜合特征距離的特征參數(shù)權(quán)重、衰退損失參數(shù)以及距離集成參數(shù)進(jìn)行敏感性分析。 6.2.1 特征參數(shù)權(quán)重敏感性 為驗(yàn)證本文綜合距離測度的有效性和全面性,對距離測度的特征參數(shù)權(quán)重進(jìn)行敏感性分析,分別依次設(shè)置4種特征參數(shù)權(quán)重為0.7,其余特征權(quán)重均為0.1,對全局比較值進(jìn)行求解,得到的對比結(jié)果如圖2所示。 圖2 不同特征參數(shù)權(quán)重下綜合距離評估結(jié)果 由圖2可知,不同權(quán)重下的排序結(jié)果均為x4?x5?x3?x2?x1,這表明本文綜合距離測度具有一定的穩(wěn)定性,但對特征參數(shù)的側(cè)重不同,得到的結(jié)果也存在差別。如當(dāng)一致距離的權(quán)重為0.7時,x3的全局比較值與其他3種權(quán)重下的全局比較值差距較大,這是由于一致距離僅考慮評估信息中的元素個數(shù)這一參數(shù),沒有涉及具體的數(shù)值大小,因此在實(shí)際應(yīng)用中應(yīng)當(dāng)僅作為輔助決策的工具,而不是主要評估依據(jù);當(dāng)模糊距離的權(quán)重為0.7時,x1與x3的全局比較值差距極小,幾乎難以區(qū)分,且與聚集距離權(quán)重為0.7時計算得到的全局比較值差距更大。 上述分析可知,本文綜合特征距離具備一定的穩(wěn)定性,且對特征參數(shù)具有一定的敏感性,在實(shí)際應(yīng)用中應(yīng)合理分配權(quán)重,一般地,將聚集距離和離散距離作為主要評估依據(jù),模糊距離和一致距離作為重要指標(biāo)進(jìn)行輔助決策。 6.2.2 衰退損失參數(shù)敏感性 衰退損失參數(shù)ρ是前景理論的體現(xiàn),相比傳統(tǒng)決策方法,能夠充分考慮決策者規(guī)避損失的主管心理,能夠產(chǎn)生更有說服力的結(jié)果。因此,有必要研究各汽車品牌在不同的衰退損失參數(shù)下的排序情況。由于本文采用熵權(quán)法計算屬性權(quán)重,沒有考慮主觀因素,為使結(jié)論更讓人信服,本節(jié)參考了文獻(xiàn)[4]的屬性權(quán)重結(jié)果,分別在2種屬性權(quán)重下,對衰退損失參數(shù)的敏感性進(jìn)行分析,圖3~4分別為不同屬性權(quán)重下的全局比較值隨ρ的變化情況。 圖3 全局比較值隨衰退損失參數(shù)的變化圖 圖4 全局比較值隨衰退損失參數(shù)的變化圖 1)ω=(0.268,0.152,0.351,0.162,0.067) 2)ω=(0.2,0.2,0.2,0.2,0.2) 分析圖3~4可知,不同屬性權(quán)重的情況下,隨著ρ逐漸增大,排序結(jié)果未發(fā)生變化,但呈現(xiàn)出隨著全局比較值逐漸增大,其他品牌與最優(yōu)品牌間的差距逐漸減小的趨勢。其中,情景2)的排序結(jié)果為x4?x5?x1?x3?x2,與情景1)排序結(jié)果不同,這是由于不同的屬性權(quán)重影響了x1與x3最終的排序結(jié)果,同時x1與x3的全局比較值差距不斷逼近0。通過上述分析,表明本文多屬性決策方法及距離測度對衰退損失參數(shù)的敏感性較低。 6.2.3 距離集成參數(shù)敏感性 為研究特征距離集成參數(shù)λ的敏感性,保持其他參數(shù)設(shè)置與6.1節(jié)中一致,分別令λ為-1,0,1,2,構(gòu)成加權(quán)調(diào)和平均距離、加權(quán)幾何平均距離、加權(quán)平均距離和加權(quán)平方平均距離,則圖5為不同集成參數(shù)下全局比較值的變化情況。 圖5 全局比較值隨特征距離集成參數(shù)的變化圖 由圖5可知,當(dāng)集成參數(shù)為0,1,2時,排序結(jié)果均為x4?x5?x3?x1?x2;但當(dāng)集成參數(shù)為-1時,x2的全局比較值明顯增大并超過x1,且與x3的全局比較差值很小,此時的排序結(jié)果變?yōu)閤4?x5?x3?x2?x1。 上述分析表明,本文的決策方法對特征距離集成參數(shù)較為敏感,在解決問題時需要根據(jù)實(shí)際情況選擇合適的特征距離集成參數(shù),否則可能會得到不同的判決結(jié)果。 6.3.1 與現(xiàn)有距離測度對比分析 為了驗(yàn)證本文改進(jìn)距離測度的優(yōu)越性,采用6.1節(jié)中的實(shí)例,分別采用現(xiàn)有距離測度,即文獻(xiàn)[15]中的d1,d2,文獻(xiàn)[16]中的d3,d4進(jìn)行仿真實(shí)驗(yàn),對其排序結(jié)果進(jìn)行對比分析,仿真結(jié)果如圖6所示。 圖6 不同距離測度下的全局比較值 分析上圖可知,5種測度的排序結(jié)果一致,均為x4?x5?x3?x1?x2,但分析各品牌的全局比較值可以發(fā)現(xiàn),除x2與x4的全局比較值相同外,d1~d4的計算結(jié)果與本文距離測度結(jié)果有明顯差別。如本文測度下x5的全局比較值為0.572,而d1~d4的計算結(jié)果則更為接近,聚集在0.85附近,x1與x3也有類似的情況。 分析原因可知,d1~d4在距離計算時,當(dāng)PHFE元素個數(shù)不等時,采用風(fēng)險規(guī)則進(jìn)行擴(kuò)充,改變了數(shù)據(jù)的原始信息,從而引入了人為誤差,而本文改進(jìn)距離測度通過定義不同的特征距離,很好地解決了這一問題,使得最終的計算結(jié)果與現(xiàn)有測度有明顯不同,體現(xiàn)了本文改進(jìn)測度的優(yōu)越性。 6.3.2 與其他方法對比分析 為了說明本文方法的有效性,分別與文獻(xiàn)[4]和文獻(xiàn)[22]進(jìn)行對比。其中,文獻(xiàn)[4]運(yùn)用概率猶豫模糊加權(quán)平均算子(PHFWA),同時利用PHFE得分函數(shù)進(jìn)行比較分析,屬性權(quán)重為(0.2,0.2,0.2,0.2,0.2);文獻(xiàn)[22]分別采用3種不同的對稱交叉熵和總猶豫度進(jìn)行決策分析,采用基于離差最大化和廣義對稱交叉熵的模型求解屬性權(quán)重。將上述方法與本文算法的計算結(jié)果進(jìn)行比較,如表7所示。由表7可知,本文方法與其他文獻(xiàn)的排序結(jié)果雖然存在部分差異,但對x4和x5的決策結(jié)果一致,即都將x4判為安全性最高的品牌。而在最差汽車品牌的選擇上,文獻(xiàn)[22]中的3種方法均把x3判定為最差選擇,而本文的決策方法判定x2為最差汽車品牌,這是由于文獻(xiàn)[22]的符號距離主要是通過衡量PHFE的信息不確定度進(jìn)行計算,相比本文的綜合距離測度,并沒有綜合考慮元素中蘊(yùn)含的其他信息,對PHFE信息的表征不夠準(zhǔn)確。 表7 不同方法結(jié)果比較 需要說明的是,文獻(xiàn)[22]采用基于離差最大化和廣義對稱交叉熵的模型求解屬性權(quán)重時,與本文的屬性權(quán)重不同,供讀者參考。 通過本節(jié)的仿真分析,本文的決策方法具有以下優(yōu)勢:①本文的綜合特征距離測度在PHFE元素個數(shù)不等和不做順序重排的情況下,均可以進(jìn)行距離計算,相比傳統(tǒng)距離測度,避免了各種反直覺現(xiàn)象的發(fā)生,同時多種特征也使得計算結(jié)果更加準(zhǔn)確、全面;②熵權(quán)法能夠較為客觀地確定屬性權(quán)重,與文獻(xiàn)[4]相比減少了決策者的主觀隨意性;③本文模型能夠充分考慮決策者規(guī)避損失的心理,更加符合決策者的實(shí)際經(jīng)歷,因此能夠產(chǎn)生更有說服力的結(jié)果。 同時本文方法也存在以下局限:關(guān)于如何確定衰退損失參數(shù)、特征集成參數(shù)等并未深入研究,雖然相比傳統(tǒng)識別方法,本方法在計算過程上更容易理解,但計算過程仍然較為繁瑣,是否適應(yīng)大規(guī)模數(shù)據(jù)背景下的計算需求還需進(jìn)一步討論。 本文對概率猶豫模糊集的距離測度進(jìn)行了深入研究,針對傳統(tǒng)距離測度存在的缺陷,綜合考慮PHFE的聚集性、離散性、模糊性和一致性4種特征,提出新的比較法則和距離測度,釋放了傳統(tǒng)距離測度的元素個數(shù)和順序重排等限制,拓展了概率猶豫模糊距離測度的應(yīng)用場景和范圍,并推廣至廣義綜合距離測度,然后基于TODIM方法提出了一種PHFS多屬性決策方法,通過與現(xiàn)有方法的分析比較,驗(yàn)證了本文距離測度和決策方法的有效性和全面性。2.2 改進(jìn)概率猶豫模糊比較法則
3 概率猶豫模糊距離測度
3.1 傳統(tǒng)概率猶豫模糊距離測度
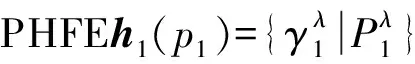
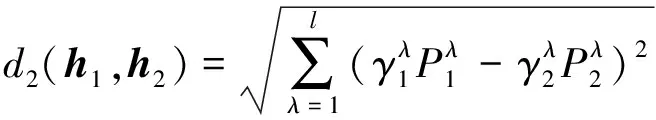
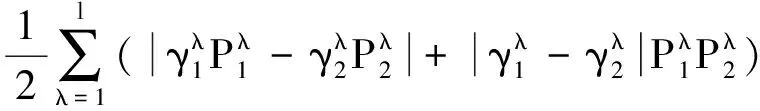
3.2 新型概率猶豫模糊距離測度
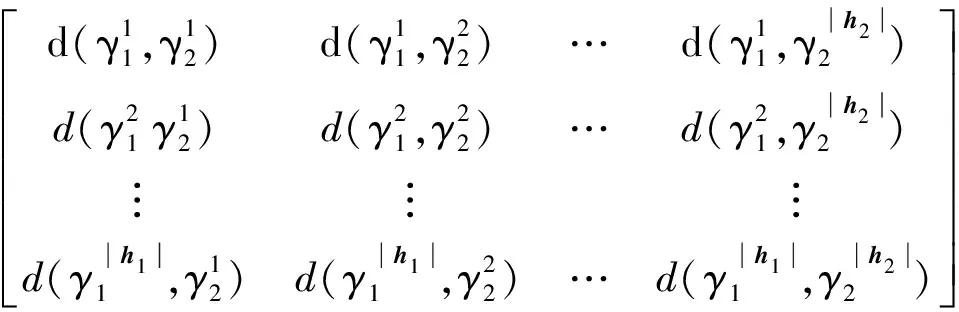

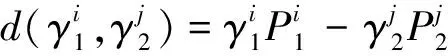
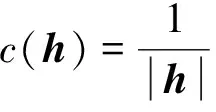

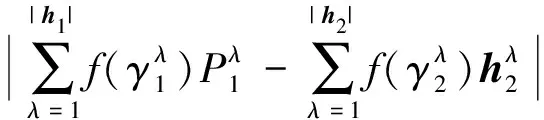
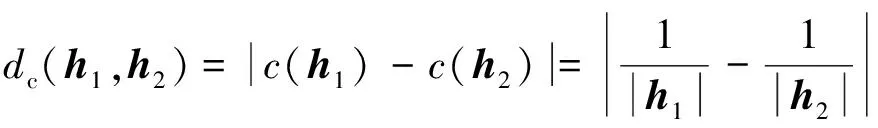
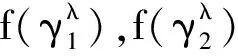
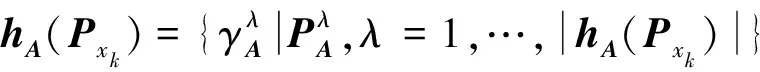
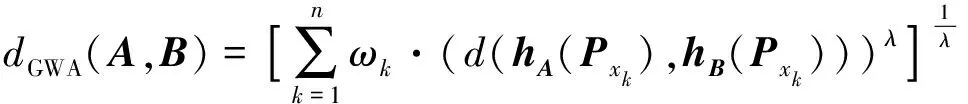


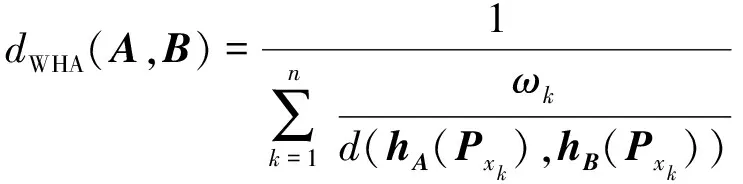
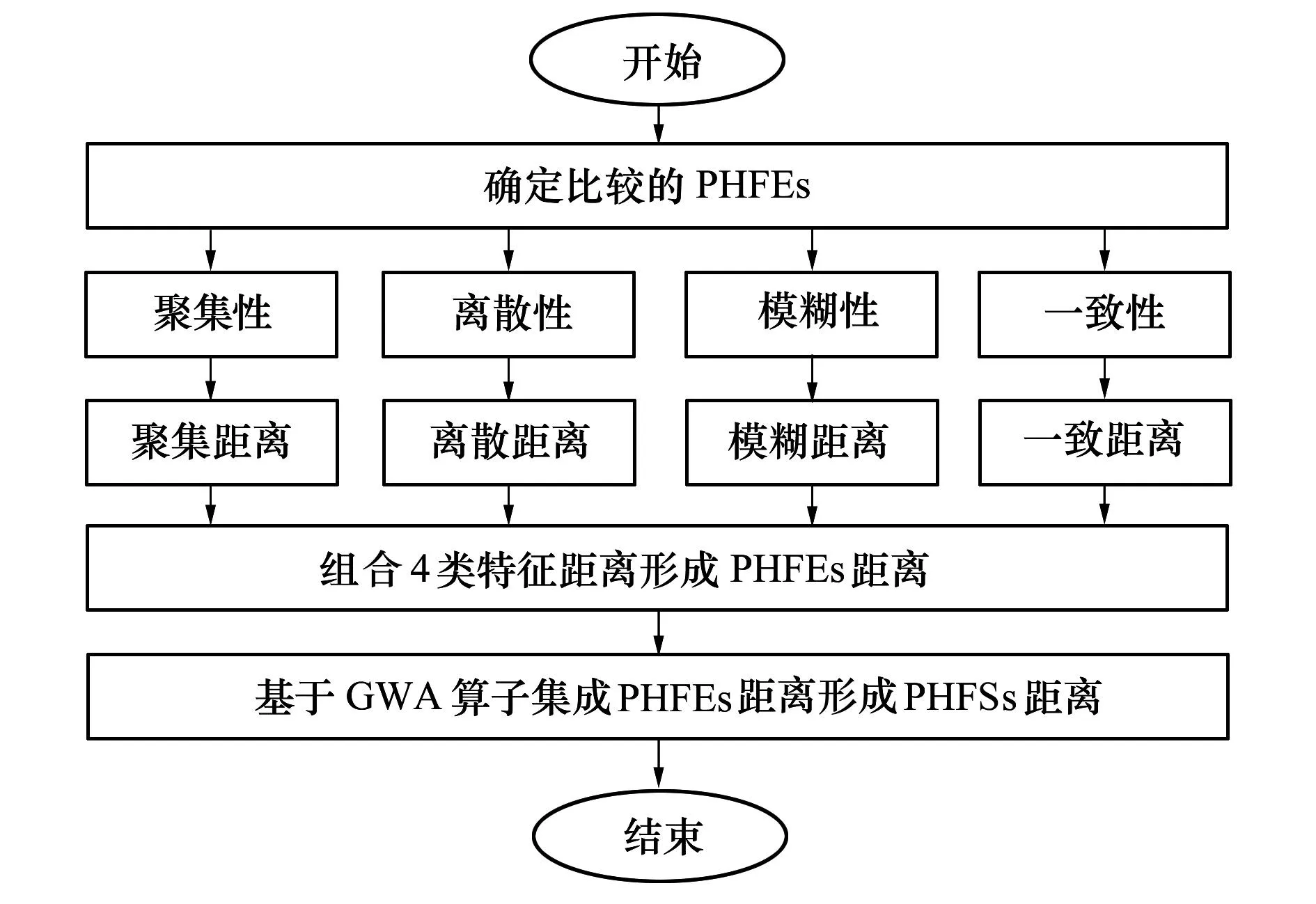
4 熵權(quán)法確定屬性權(quán)重

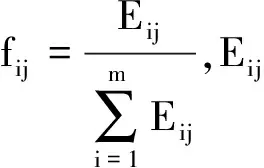

5 基于TODIM的識別決策方法
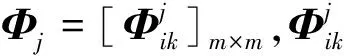

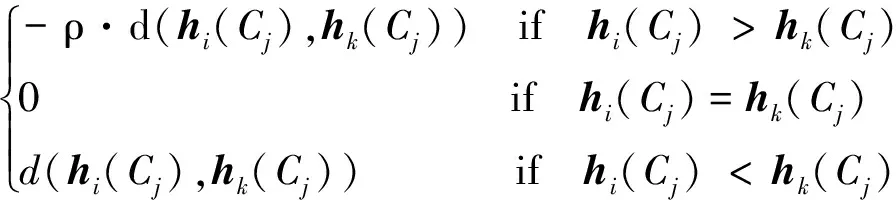

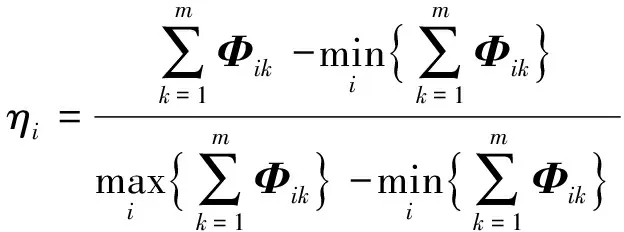
6 實(shí)例分析
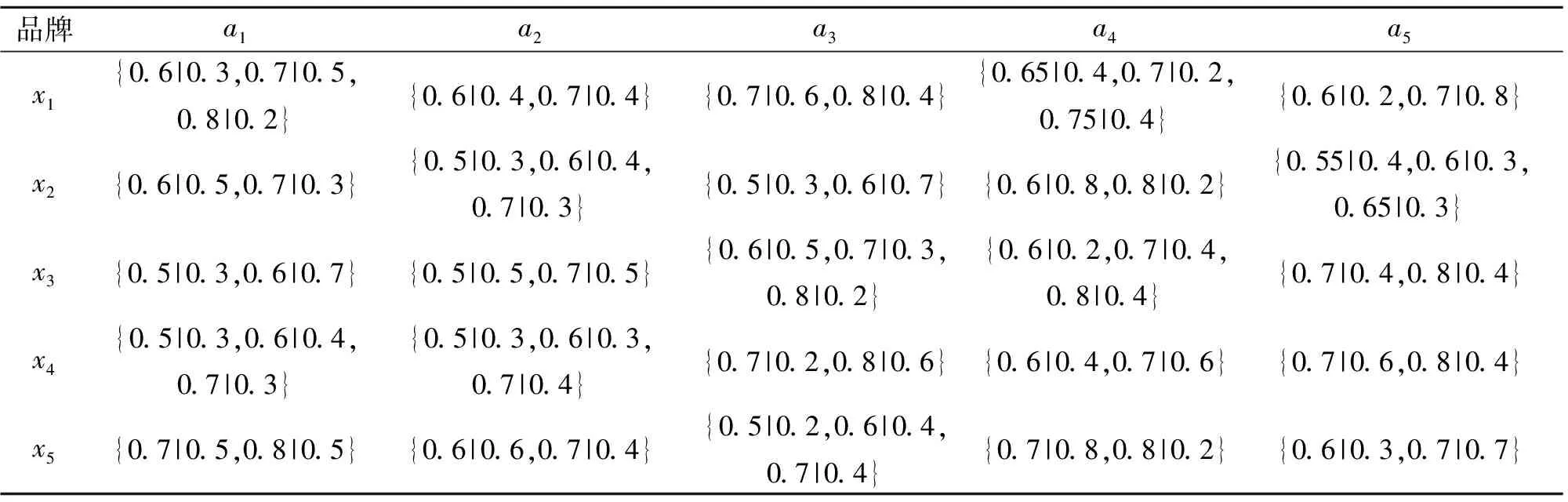
6.1 實(shí)例



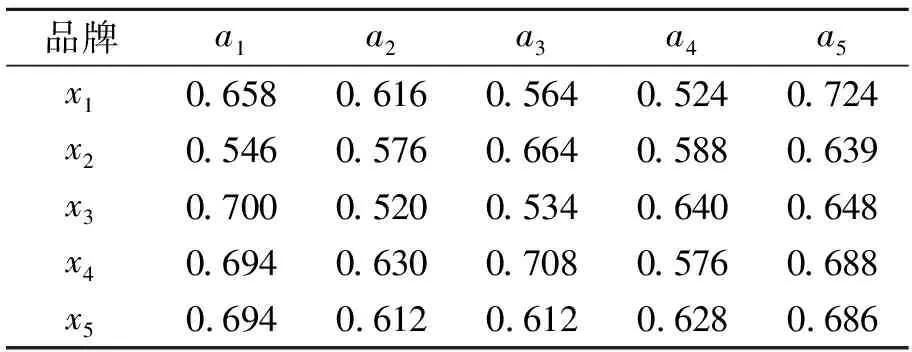
6.2 參數(shù)敏感性分析

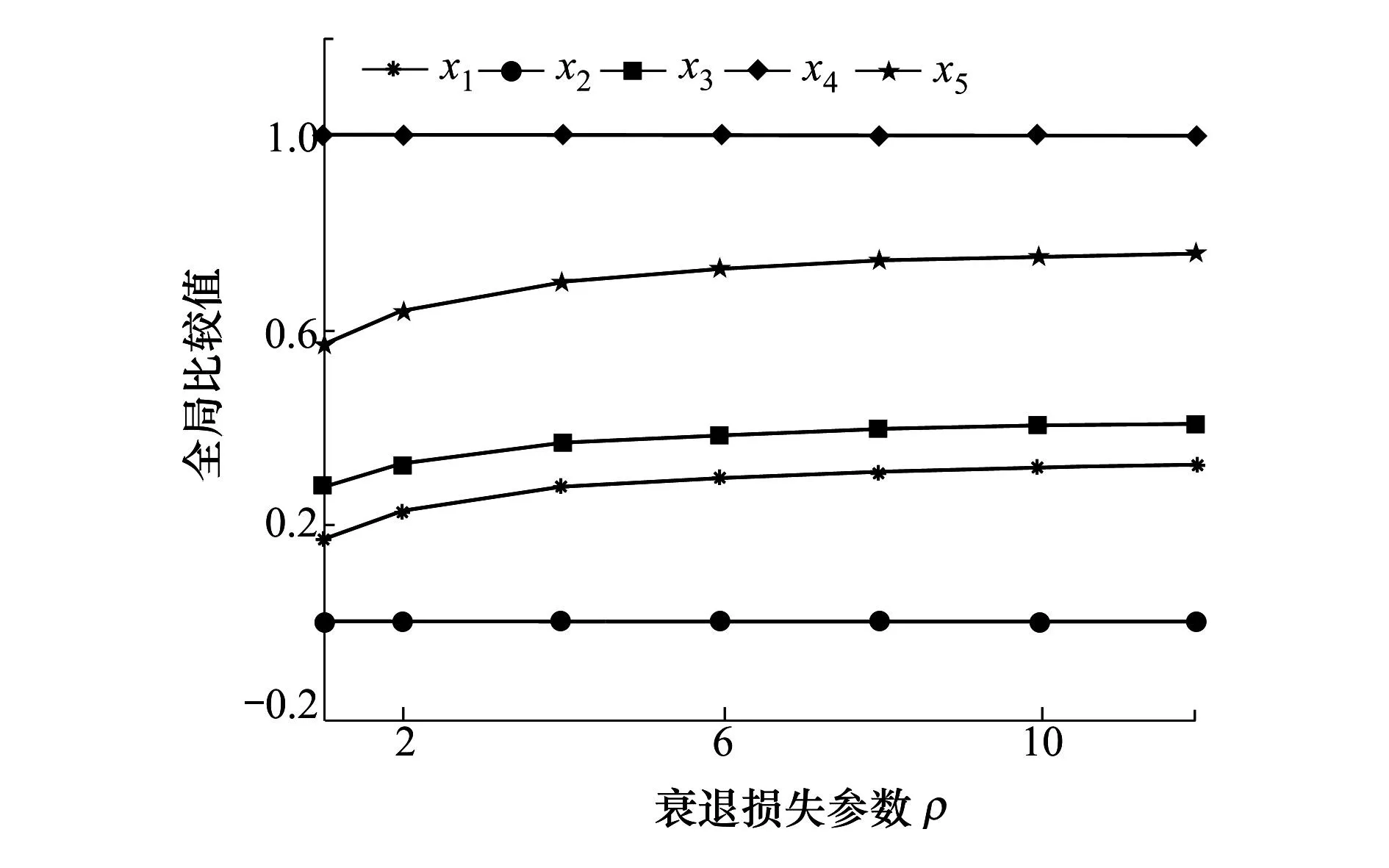

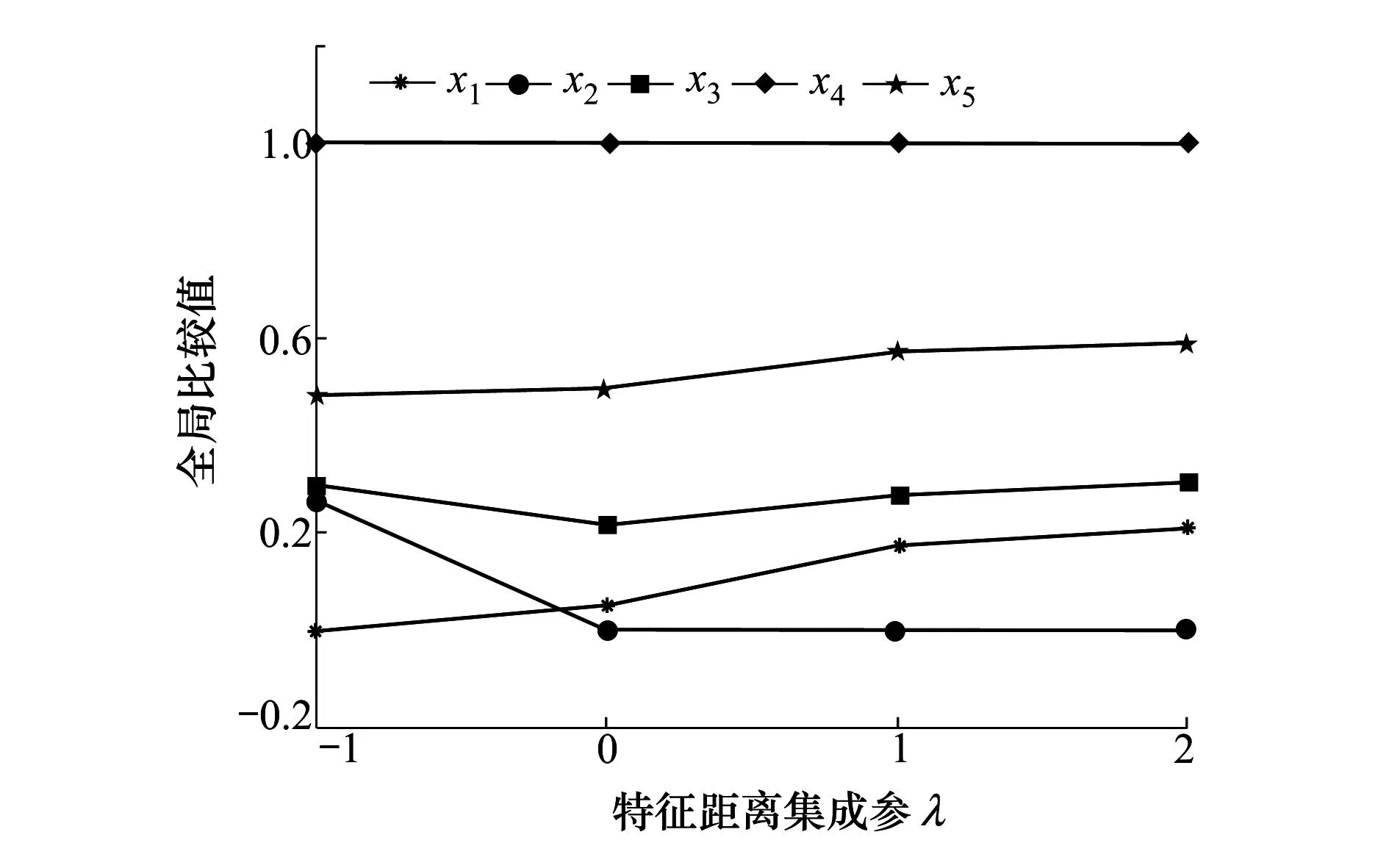
6.3 比較分析

7 結(jié) 論
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28海峽姐妹(2020年9期)2021-01-04 01:35:44VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28當(dāng)代陜西(2019年10期)2019-06-03 10:12:04數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54山東青年(2016年1期)2016-02-28 14:25:25河南科技(2014年23期)2014-02-27 14:19:15當(dāng)代修辭學(xué)(2014年3期)2014-01-21 02:30:44
