基于YOLOv5 改進(jìn)的輕量級目標(biāo)檢測模型
2024-01-05 07:21:16厲振坤付蕓
長春理工大學(xué)學(xué)報(自然科學(xué)版) 2023年6期
厲振坤,付蕓
(長春理工大學(xué) 光電工程學(xué)院,長春 130022)
目標(biāo)檢測的研究一直以來都是CV 領(lǐng)域中最基本、最具有挑戰(zhàn)性的研究課題之一。 旨在通過確定目標(biāo)在圖像中的位置以及分類,從而達(dá)到視覺感知的效果。 特別是近年來,隨著互聯(lián)網(wǎng)技術(shù)和人工智能技術(shù)的發(fā)展,硬件設(shè)備的升級更新,以及自動駕駛、人臉檢測、視頻監(jiān)控等需求不斷多樣化和豐富化,吸引越來越多的研究者和研究機構(gòu)投入到目標(biāo)檢測的研究熱潮中。在城市人口不斷增加、交通擁堵、安全問題日益嚴(yán)重的今天,城市公共場所的治理已經(jīng)備受關(guān)注,實時監(jiān)控系統(tǒng)的完善可以有效地改善城市公共治理問題。
早期的目標(biāo)檢測在探測感興趣對象時一般經(jīng)過預(yù)處理、滑動窗口、特征提取、特征選擇、特征分類、事后處理、輸出操作等6 個過程。然而,傳統(tǒng)目標(biāo)檢測算法有很多缺陷。 一方面,由于物體的大小和縱橫比不同,且照片中物體的位置不確定,就需要很多尺度的滑動窗口來搜索整個圖像。因此就會產(chǎn)生很多不必要的滑動窗口。 再加上會產(chǎn)生很難確定數(shù)量的冗余候選框,計算量也會大大增加。另一方面,特征提取算法經(jīng)過人為設(shè)計,很難成為一種既能描述各種對象又具有較高通用性的完美算法。
隨著科技的發(fā)展,算力不斷提升,又因卷積神經(jīng)網(wǎng)絡(luò)的出現(xiàn),基于深度學(xué)習(xí)的計算機視覺處理方法得到越來越廣泛的應(yīng)用。 其中,基于深度學(xué)習(xí)的目標(biāo)檢測方法是通過構(gòu)建深層神經(jīng)網(wǎng)絡(luò)模型,經(jīng)過學(xué)習(xí)不斷優(yōu)化網(wǎng)絡(luò)參數(shù),從訓(xùn)練集中提取特征信息,從而完成目標(biāo)檢測的任務(wù)。目前,許多深度學(xué)習(xí)雖然相比于傳統(tǒng)算法,算力上有很大程度的提升,但在實際應(yīng)用場景中,龐大且復(fù)雜的深層神經(jīng)網(wǎng)絡(luò)依舊難以應(yīng)對移動端移植的問題。 在自動駕駛、邊緣穿戴等實際任務(wù)中,能夠同時滿足精度高、速度快和硬件要求低的網(wǎng)絡(luò)在市場中備受青睞。 因此,使用各種方法對深度學(xué)習(xí)模型進(jìn)行壓縮和加速,降低模型的參數(shù)量和計算量,使其能夠應(yīng)用于存儲和計算資源有限的場景中,一直是研究人員努力探索的目標(biāo)。
有人嘗試將緊湊型網(wǎng)絡(luò)應(yīng)用于目標(biāo)檢測任務(wù)的深層神經(jīng)網(wǎng)絡(luò)中。 然而,由于這種網(wǎng)絡(luò)的參數(shù)量低,其特殊的結(jié)構(gòu)難以與其他的壓縮和加速方法聯(lián)合使用,且泛化能力較差,不適合作為預(yù)訓(xùn)練模型幫助訓(xùn)練其他模型,因而無法滿足目標(biāo)檢測任務(wù)所需的精度和泛化性的要求。為了解決這些問題,本文開展了相關(guān)的研究。針對YOLOv5 網(wǎng)絡(luò)架構(gòu),首先,采用ShuffleNetv2[1]作為主干網(wǎng)絡(luò),ShuffleNetv2 是一種在ShuffleNetv1[2]及MobileNetv2[3]基礎(chǔ)上通過分析兩者的缺陷并進(jìn)行改進(jìn)的輕量化網(wǎng)絡(luò),具有精度高、速度快的優(yōu)點[4]。相比于CSPDarkNet53,該網(wǎng)絡(luò)具有極小的參數(shù)量。其次,添加Stem 模塊,確保較強的特征表達(dá)能力,且能夠減少大量的參數(shù)。 還使用coordinate attention 加強對重要信息的聚焦。 再次,針對改進(jìn)后的網(wǎng)絡(luò)架構(gòu)以及VOC2007 數(shù)據(jù)集檢測任務(wù)中類別的互斥性,使用二元交叉熵?fù)p失函數(shù)。在保證精度的前提下,本文優(yōu)化了YOLOv5網(wǎng)絡(luò)結(jié)構(gòu)的計算量和參數(shù)量,得到了高性能輕量化目標(biāo)檢測模型。最后,在PASCAL VOC2007 數(shù)據(jù)集上進(jìn)行了實驗。
1 輕量級目標(biāo)檢測模型
YOLO 是Redmon 等人[5]提出的一種端對端實時對象檢測算法,它使用卷積神經(jīng)網(wǎng)絡(luò)來執(zhí)行圖像的特征提取、對象分類與定位,具有高效的優(yōu)點,但在精度方面存在欠缺。YOLOv2 算法利用K-means 聚類預(yù)處理先驗框的大小,將先驗框聚類為長寬不同的9 類,以檢測大小尺度不同的目標(biāo),從而彌補了YOLO 精度方面的缺陷。盡管如此,YOLOv2 沒有關(guān)注不同尺寸圖像的訓(xùn)練問題,在小目標(biāo)檢測中效果不佳。在后來的研究中,YOLOv3 的出現(xiàn),在YOLOv2 的基礎(chǔ)上,使用特征金字塔網(wǎng)絡(luò)以改善檢測性能,尤其是在小目標(biāo)檢測中提升顯著。不過,YOLOv3 在檢測復(fù)雜特征的物體時性能仍然有待提升。在YOLOv3的基礎(chǔ)上,從數(shù)據(jù)處理、主干網(wǎng)絡(luò)、網(wǎng)絡(luò)訓(xùn)練、激活函數(shù)、損失函數(shù)等各個方面進(jìn)行了不同程度的優(yōu)化。YOLOv4 算法用于林火檢測中,使模型的性能得到了提升。YOLOv5 網(wǎng)絡(luò)開源架構(gòu)使得YOLO 系列目標(biāo)在計算機視覺應(yīng)用上更進(jìn)一步[6-7]。 YOLOv5 在Backbone 上采用了CSPDarknet53、Mish 激活函數(shù)和Dropblock,在Neck 中采用了SPP 結(jié)構(gòu)等。同時,借鑒了CutMix[8]方法在輸入端采用了mosaic 數(shù)據(jù)增強,有效解決了模型訓(xùn)練中最頭疼的“小目標(biāo)問題”。YOLOv5 的提出推動了YOLO 模型的輕量化和精準(zhǔn)化的發(fā)展。
近年來,很多學(xué)者根據(jù)YOLO 的網(wǎng)絡(luò)特點對其進(jìn)行了有針對性的改進(jìn),以利于YOLO 系列網(wǎng)絡(luò)在各個領(lǐng)域中的應(yīng)用。彭玉青等人[9]對YOLO網(wǎng)絡(luò)的層數(shù)和參數(shù)進(jìn)行調(diào)整,基于空間金字塔池化方法對圖像進(jìn)行多尺度輸入。深度卷積網(wǎng)絡(luò)在進(jìn)行特征提取時,不同層次的特征圖所包含信息的側(cè)重不同[10],Kim 等人[11]對YOLO-V3進(jìn)行改進(jìn),采用空間金字塔池化方法,并引入五個不同尺度的特征圖加強網(wǎng)絡(luò)提取特征的能力。Li 等人[12]使用四個檢測層以提高YOLO-V3對小目標(biāo)的檢測性能。He 等人[13]增加了另一個快捷連接,在兩個“剩余單元”之間連接兩個CBL,以提高信息傳輸特征提取網(wǎng)絡(luò)的性能。
2 本文方法
YOLOv5 模型在目標(biāo)檢測領(lǐng)域取得了非常好的效果,然而其參數(shù)量有待進(jìn)一步優(yōu)化。 本文的方法使用較少的模型參數(shù)量和計算量,提高了模型的檢測速度。
(1)采用ShuffleNetv2 替換YOLOv5 原有的CSPDarkNet53。
(2)加入Stem Block,確保特征提取網(wǎng)絡(luò)擁有較強的特征表達(dá)能力,以彌補更換特征提取網(wǎng)絡(luò)后丟失的精度,且該模塊只占據(jù)很小的參數(shù)量。
(3)在主干網(wǎng)絡(luò)的末端添加CA(Coordinate Attention),雖然模塊有一定的參數(shù)量,但整體上比YOLOv5 仍減少了90% 的參數(shù)量,且提升了精度。
(4)使用二元交叉熵?fù)p失函數(shù),針對數(shù)據(jù)集進(jìn)行設(shè)計,利用類別間互斥性提升訓(xùn)練效果。改進(jìn)后的模型架構(gòu)如表1 所示。

表1 改進(jìn)模型的提取網(wǎng)絡(luò)結(jié)構(gòu)
2.1 輕量級特征提取網(wǎng)絡(luò)
ShuffleNetV1 結(jié)構(gòu)中引入了“通道隨機播放”操作,可以使用不同信道的通信。同時,還采用瓶狀結(jié)構(gòu)和逐點群卷積的技術(shù),以提高準(zhǔn)確性。
對于輕型級模型來說,逐點群卷積與瓶頸狀結(jié)構(gòu)增加了內(nèi)存訪問的成本(Memory Access Cost,MAC),與G1 和G2 相違背,這一成本大大增加了輕型網(wǎng)絡(luò)的負(fù)擔(dān)。并且,group 的過多使用也違反了G3。同樣,shortcut connection 中element-wise add操作也違反了G4。所以,本文要解決的問題是,如何在不密集卷積和分組過多的前提下,還可以保持大量的且同樣寬的信道。
ShuffleNetV2 的出現(xiàn),針對ShuffleNetV1 的問題做出了改進(jìn),如圖1(c)所示,在每個單元的開始,c 特征通道會輸出兩個分支(ShuffleNetV2 中對channels 分成兩半)。 根據(jù)G3,group 不能過多,所以,其中一個分支不改變,由三個卷積組成另一個分支,它們具有相同的輸入和輸出通道以滿足G1。 為了滿足G2,兩個1×1 卷積由組卷積改變?yōu)槠胀ǖ木矸e操作。經(jīng)過卷積操作將兩個分支連接起來,而并非相加(G4)。所以,此時通道數(shù)不變(G1)。然后,再使用“channels shuffle”操作來實現(xiàn)兩個分支之間的信息通信,這里使用的“channels shuffle”與ShuffleNetV1 中使用的操作是相同的。此時,不再使用ShuffleNet v1 中的“Add”(累加)操作。由于對空間下采樣單元的修改(移除通道分離操作符),輸出的通道量相比原來增加了一倍,如圖1(d)。圖1(c)、圖1(d)的構(gòu)建塊與由此產(chǎn)生的網(wǎng)絡(luò)就是ShuffleNet V2。因此可以得出結(jié)論,它遵循了所有的指導(dǎo)原則,該體系結(jié)構(gòu)的設(shè)計也是高效的。
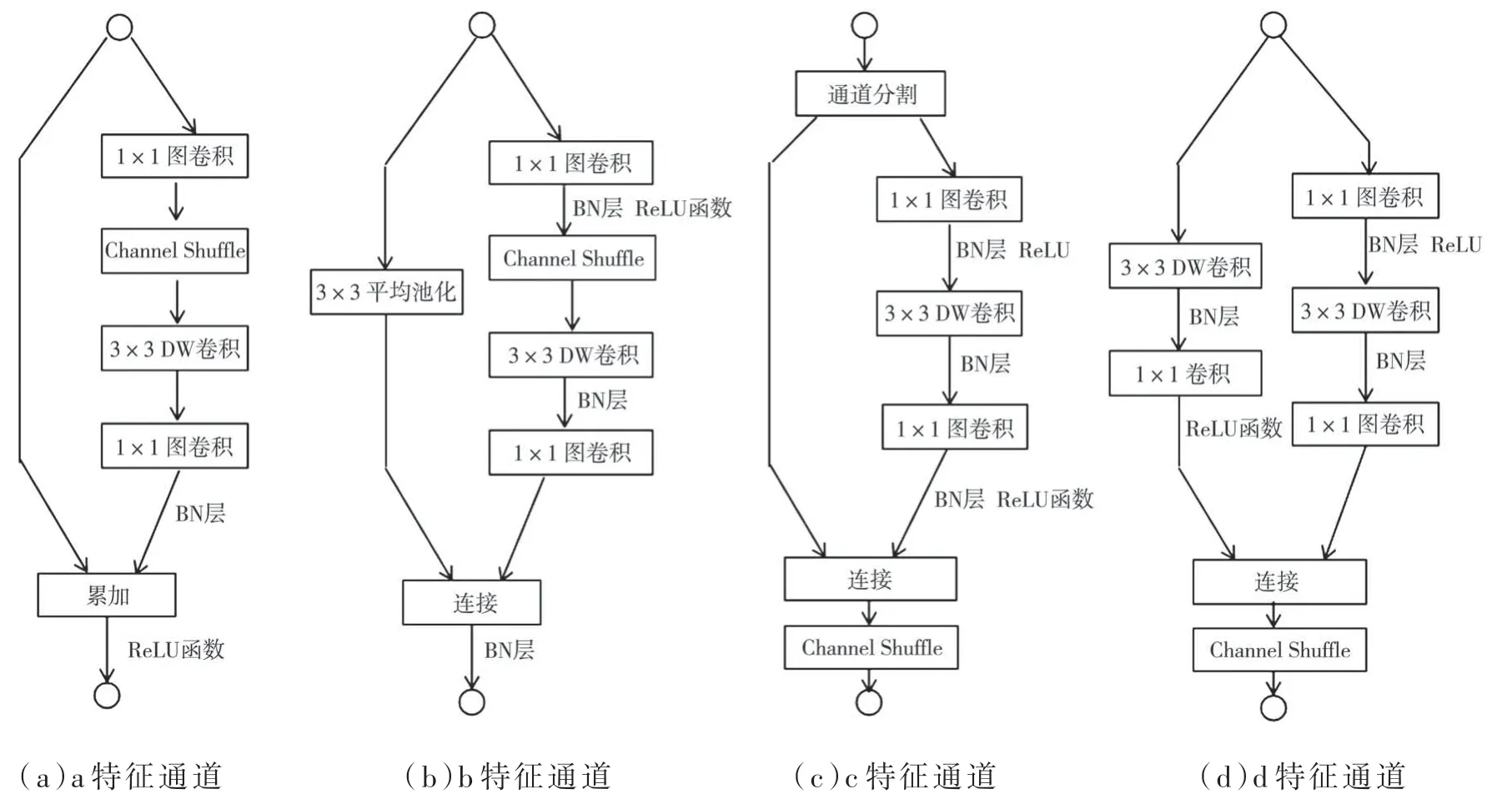
圖1 ShuffleNetV2 結(jié)構(gòu)
2.2 Stemblock
Stemblock 結(jié)構(gòu)是PeleeNet 中用于下采樣的方法。 在模型中添加Stemblock,使其擁有很強的特征表達(dá)能力。其結(jié)構(gòu)如圖2 所示。
在該結(jié)構(gòu)中,首先,對輸入特征圖進(jìn)行卷積操作并改變其通道數(shù),此時卷積核大小為3×3。其次,特征圖通過網(wǎng)絡(luò)結(jié)構(gòu)的兩個分支同樣分為了兩個部分。其中,一個分支的特征圖會通過最大池化下采樣的操作,而特征圖的另一部分會先進(jìn)行1×1 卷積,此時通道數(shù)只有原來的1/2,接著進(jìn)行3×3 的卷積。接著,再將兩個分支的輸出的特征圖進(jìn)行拼接,最后,使用1×1 卷積操作還原通道數(shù)量。與原始卷積運算相比,Stemblock結(jié)構(gòu)的優(yōu)勢是在減少參數(shù)量的同時,又更好地保留了語義信息,最大可能地減少了信息的丟失。
2.3 Coordinate Attention
這種新的注意力機制可以讓網(wǎng)絡(luò)使用很小的計算成本,將位置信息嵌入到通道注意力中,并參與更大的區(qū)域信息計算。所以可以先將通道注意力分為兩個并行的特征編碼分支,目的是使注意力圖包含整個的空間信息,由此減輕2D 全局池化所引起的位置丟失。簡單來說,就是將水平與垂直方向的兩個輸入特征通過兩個一維的全局池化操作,聚合成兩個獨立的擁有方向感知的特征圖。這兩個特征圖被嵌入了特定的方向信息,還被編碼成兩個注意力圖,所以,每個由此生成的注意力圖都很好地保存了位置信息。 為了能更好地強調(diào)感興趣的信息,這里將兩個注意力映射經(jīng)過乘法應(yīng)用到輸入的特征映射中。 這種操作能夠區(qū)分空間方向,同時生成坐標(biāo)感知注意力圖,因此,注意力方法也稱為坐標(biāo)注意力,如圖3 所示。

圖3 注意力機制原理圖

圖4 使用Labellmg 進(jìn)行數(shù)據(jù)集的標(biāo)注
注意力機制將輸入特征與兩個單一方向的垂直和水平識別特征相結(jié)合。兩個具有嵌入式方向特定信息的特征映射分別被編碼為兩個內(nèi)存映射,每個內(nèi)存映射捕獲輸入空間方向的特征映射的遠(yuǎn)程依賴性。 因此,位置信息可以存儲在生成的注意映射中。 然后,通過乘法將兩個注意力映射應(yīng)用于輸入特征映射以強調(diào)興趣的表示。
坐標(biāo)注意力不僅可以獲取位置敏感信息和方向感知,還能獲取跨通道信息,所以能夠很好地獲取感興趣的對象和信息。 同時,由于該方法具有輕量和靈活的特點,可以隨意地插入到移動網(wǎng)絡(luò)。最后,作為預(yù)訓(xùn)練模型,協(xié)調(diào)注意力可以為移動網(wǎng)絡(luò)的下游任務(wù)帶來顯著的性能提升,特別是對于那些密集預(yù)測的任務(wù)。
本文將該注意力機制模塊用在改進(jìn)后目標(biāo)檢測網(wǎng)絡(luò)的特征提取網(wǎng)絡(luò)的末端,目的是加強注意力的聚焦程度,從而彌補替換特征提取網(wǎng)絡(luò)所引起的提取能力的降低。
2.4 二元交叉熵?fù)p失函數(shù)
在YOLOv5 中,原先采用的是BCEWithLogitsLoss,其將Sigmoid 添加到loss 函數(shù)中。 Sigmoid概率和不為1,需要將sigmoid 函數(shù)應(yīng)用于每個原始的輸出值,輸出預(yù)測將是那些能夠超過概率閾值的類,因此,同一目標(biāo)可能會劃為多個類別,這是考慮到自然場景下同一個目標(biāo)可能屬于多個類別。
然而,在VOC2007 數(shù)據(jù)集中,所有的類別都是互斥的,不存在同一個目標(biāo)具有多個類別的屬性。因此,使用二元交叉熵?fù)p失函數(shù),該損失函數(shù)同時使用了LogSoftmax 和NLLLoss。 關(guān)于LogSoftmax,每個元素都會在0 到1 的范圍內(nèi),元素加起來就是1。這樣就可以理解為概率分布,其輸入數(shù)字越大,概率越大。 它確保所有的輸出概率之和等于1(或接近1)。在處理流程中,對輸入數(shù)據(jù)先做log_softmax,再過NLLLoss。交叉熵公式如下:
3 實驗與結(jié)果
3.1 實驗配置
為了避免測試數(shù)據(jù)因?qū)嶒灜h(huán)境的不同而發(fā)生變化,本文中所有測試均在相同的硬件和軟件環(huán)境下進(jìn)行。硬件環(huán)境配置參數(shù)如表2 所示,軟件環(huán)境配置如表3 所示。
表2 硬件環(huán)境配置

表3 軟件環(huán)境配置
為了滿足實驗要求,本文使用VOC2007 數(shù)據(jù)集進(jìn)行訓(xùn)練,VOC 數(shù)據(jù)集有20 類,針對監(jiān)控系統(tǒng)下實時檢測類的數(shù)量可以很好的滿足,由于本模型注重對車輛和行人的檢測,所以選取1 182張車輛數(shù)據(jù)集,和1 327 張行人數(shù)據(jù)集并使用LabelImg 進(jìn)行標(biāo)注。
為了證明方案的有效性,使用原YOLOv5 模型,只替換過主干網(wǎng)絡(luò)的YOLOv5-Shuffle 模型和本文改進(jìn)后的三個模型進(jìn)行訓(xùn)練和測試。
訓(xùn)練開始前,為了避免縱橫比不匹配對訓(xùn)練結(jié)果的影響,本文將數(shù)據(jù)集中的所有圖像均裁剪成512×512 大小。考慮到GPU 顯存大小,參數(shù)設(shè)置如下:Batch_size(批尺寸)為12,Initial learning rate(初始學(xué)習(xí)率)為0.002,每次訓(xùn)練300 epochs。本文將VOC2007 劃分為訓(xùn)練集、驗證集和測試集,并將訓(xùn)練集、測試集和驗證集進(jìn)行7∶2∶1 的劃分。
采用Xavier initialization 來初始化神經(jīng)網(wǎng)絡(luò)的每一層。實驗所涉及的所有超參數(shù)如表4 所示。

表4 實驗參數(shù)設(shè)置
3.2 評價指標(biāo)
在目標(biāo)檢測領(lǐng)域,樣本可分為四種類型:true positive( TP )、false positive( FP )、true negative( TN)和false negative( FN ),根據(jù)其真實類和預(yù)測類的組合進(jìn)行劃分。
為了量化所提出的網(wǎng)絡(luò)與其他網(wǎng)絡(luò)的性能比較,本文使用典型的評價指標(biāo),比如,精確率(P)和召回率(R),公式如下:
平均精度(AP)是P-R curve 下方的面積,就是對P-R curve 的Precision 值求均值。 對于P-R curve 來說,使用定積分來進(jìn)行計算:
在目標(biāo)檢測性能測試的實際計算中,還要對P-R curve 進(jìn)行平滑處理。 對P-R curve 上的每個點,Precision 值計算公式如下:
mAP 是對多個類別mAP 求平均值。由于本文的方法只對路面物體進(jìn)行檢測,所以mAP 和AP 在本文的含義是相同的。mAP 是目標(biāo)檢測中衡量性能的最重要的一個指標(biāo)。
Params 和FLOPs 是用于衡量模型復(fù)雜性的指標(biāo)。 FPS 代表檢測器每秒可以處理的圖片幀數(shù),數(shù)值越大代表檢測速度越快。
3.3 實驗結(jié)果
橫坐標(biāo)是訓(xùn)練輪次,縱坐標(biāo)是mAP 值,原模型與本文改進(jìn)模型mAP 的對比如圖5 所示。

圖5 模型的mAP 對比
改進(jìn)后的模型檢測效果如圖6 所示。

圖6 改進(jìn)模型檢測效果
表5 為原模型與改進(jìn)模型復(fù)雜度和幀數(shù)的對比。

表5 模型的測試結(jié)果對比
從圖5 與表5 顯示的實驗結(jié)果可知,替換主干網(wǎng)絡(luò)后的YOLOv5-Shuffle 模型會造成很大的精度損失,平均精確度降低了0.15,對于車輛和行人擁擠的場景下,這樣的模型不適合用于實時監(jiān)控領(lǐng)域。而本文提出的改進(jìn)方法將參數(shù)量和計算量都減少到了原來的1/10 左右,檢測幀數(shù)同樣提高了17 點,而平均精確度只降低0.08,所以本模型在大幅度提高了模型的運算速度前提下,很好地控制了精度損失。
4 結(jié)論
本研究基于YOLOv5 提出了一種改進(jìn)的目標(biāo)檢測算法。采用ShuffleNetv2 替換了原先的CSPDarknet53,并且使用Stem Block、Coordinate Attention、二元交叉熵?fù)p失函數(shù)彌補了替換特征提取網(wǎng)絡(luò)引起的精度損失。其中,使用Stem Block 對網(wǎng)絡(luò)進(jìn)行輕量化處理,填補替換特征提取網(wǎng)絡(luò)后對網(wǎng)絡(luò)實時性能造成的損失。 Coordinate Attention耗費很小的結(jié)構(gòu),提升了網(wǎng)絡(luò)的精度和目標(biāo)框邊界的回歸能力。本文所提出的輕量級的網(wǎng)絡(luò)架構(gòu)可以用于自動駕駛等領(lǐng)域中。考慮到駕駛環(huán)境的復(fù)雜性和多變性,網(wǎng)絡(luò)仍需進(jìn)一步完善。因此,未來的工作中將對網(wǎng)絡(luò)進(jìn)一步輕量化并使其更好地應(yīng)用于目標(biāo)跟蹤領(lǐng)域。 另外,Head階段中上采樣部分仍可繼續(xù)改進(jìn),如何使用一些復(fù)雜度較低的圖像超分辨算法,可以更好地檢測出小目標(biāo)。
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫(yī)學(xué)工程學(xué)報(2017年6期)2017-02-10 05:11:45
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
