人工智能音色轉換模型可有效服務和促進電影創作生產
2024-01-05 06:47:38王薇娜
現代電影技術 2023年12期
迄今,人工智能(AI)技術已廣泛應用于電影聲音生成和制作領域,可精準模仿特定演員的聲音、語調和語速,以實現高度逼真的語音合成和自動配音,尤其適用于處理語言障礙或需要重新配音的情況;AI 還可根據特定文本生成自然流暢的語音,用于電影旁白、解說或虛擬角色對話。
但在實際應用過程中,AI 生成的人聲質量參差不齊,易出現音色模仿不夠精準等問題,其主要原因在于音色轉換質量。當前其他相關領域中AI音色轉換技術的創新應用可借鑒于電影制作中,以有效改善AI生成的人聲質量。
近期,國內音樂平臺出現歌手“AI 孫燕姿”的眾多作品,聲音與孫燕姿本人極為相似。“AI 孫燕姿”是一個虛擬歌手,是人工智能模型訓練的產物。最早的虛擬歌手是2007 年面世的初音未來,由日本克理普敦未來媒體有限公司(Crypton Future Media,INC.)以雅馬哈的VOCALOID 系列語音合成軟件為基礎開發。隨后,嗶哩嗶哩虛擬偶像洛天依、《英雄聯盟》衍生虛擬樂隊K/DA 女團等也采用了類似的“二次元形象+語音合成引擎”方式。然而,這些AI 歌手并沒有引起太大反響,其中一個重要原因是其通常具有鮮明的虛擬形象和電音音色,使人們很清楚這僅僅是一種娛樂產品,而不會“以假亂真”。而“AI 孫燕姿”的聲音和風格與真人極為相近,其將人們帶入到人工智能逐步逼近人類智能的前沿科技場景。
“AI 孫燕姿”使用的核心技術來源于Sovits4.0 歌聲轉換模型,其基于so-vits-svc 開源軟件研發。Sovits4.0模型是一種音色轉換模型,可將一個人的聲音轉換成另一個人的聲音,具有極高的準確性和逼真度。這意味著“AI 孫燕姿”可通過該模型學習并模仿孫燕姿的音色和唱腔特點,應用于其他歌手甚至其他語言的歌聲中,從而創造出逼真的孫燕姿風格歌曲。Sovits4.0 具體實現過程主要包括訓練數據集創建、模型訓練、模型推理等步驟。其中,訓練數據主要用于提取原聲特征,生成訓練模型;模型推理主要用于提取目標歌曲音調、音高,將翻唱者的音色訓練模型與目標聲音相匹配;最后,再對生成的歌聲進行后期優化,例如加入混響或簡單修音,一首AI翻唱歌曲即制作完成。
(1)訓練數據集創建
要想獲得逼真的歌手聲音,首先要模擬聲源,這是用來讓AI 模型訓練的聲音素材。對于歌手來說,可以搜集歌手的高品質歌曲并從中提取干凈人聲,或直接使用語音素材,至少需要準備30 分鐘以上的有效人聲素材,1~2 小時為佳。聲音素材的質量會極大影響訓練準確度,為提升人聲質量,可對語音素材做預加重、去噪等處理,然后對人聲文件進行分割,每段人聲不超過15 秒,便于訓練器計算。最后將訓練數據集放在模型要求的訓練目錄中。
(2)模型訓練
so-vits-svc 是一款開源免費的AI 語音轉換軟件,可實現“識別數據集→數據預處理→配置訓練超參數與設置信息→模型訓練”這一流程,其中數據預處理主要是對數據進行響度匹配、重采樣、生成配置文件、提取特征,并選擇適合的特征編碼器,表1列舉了該軟件提供的幾款基礎編碼器特點。
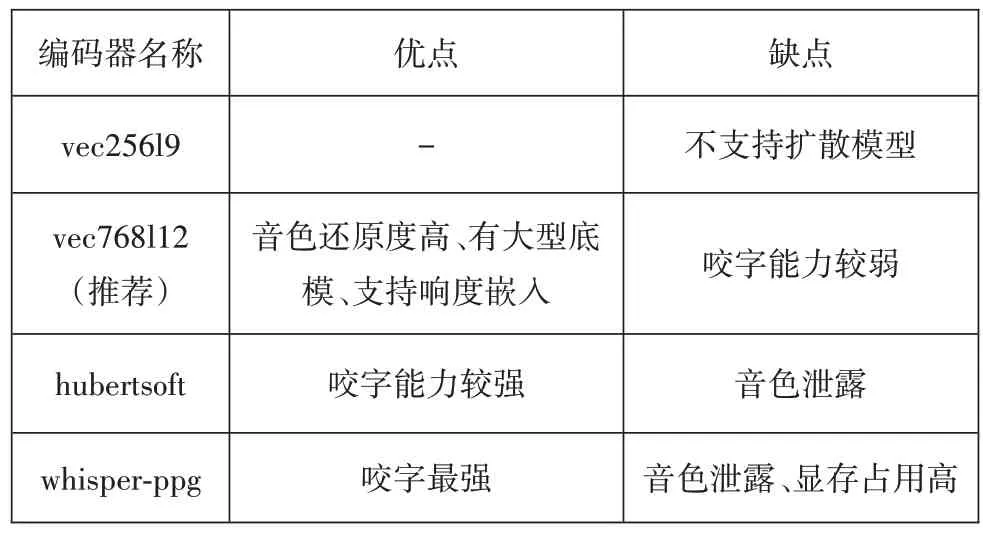
表1 特征編碼器對比
配置超參數是指選擇適合的批量大小、學習率以及保存訓練模型的訓練步數要求等。參數配置完成后,即可開始模型訓練,訓練中可通過觀察損失函數(Loss Function)曲線的收斂情況,及時終止訓練,進而獲得訓練模型。
(3)模型推理
模型推理是將目標歌曲的人聲替換為訓練模型文件的音色。在推理轉換過程中,除加載正確的訓練模型與配置文件外,還有可選推理參數幫助生成更加逼真的音色效果,包括變調參數、聚類模型混合比例、使用自動f0 預測、使用f0 均值濾波等。變調參數用于設置音色變調,參數范圍為-12~12,如男聲轉女聲需要升高,可設置為5~8,女聲轉男聲需要降低,可設置為-5~-8。聚類模型混合比例可控制使用聚類模型的占比,有限提升音色相似度,但會降低咬字準確度。該參數的范圍為0~1, 0 為不啟用,越靠近1, 則音色越相似,咬字越模糊。自動f0 預測用于將模型音高匹配到推理源音高,主要用于轉換語音,使用時會導致變調參數失效。f0 均值濾波開啟后能有效改善啞音,但可能會導致跑調。
模型推理完成后即可得到轉換后的人聲,如果轉換效果不理想,還可通過調整訓練迭代次數、編碼器參數設置、推理參數設置等,進一步優化模型,直到輸出滿意結果。后續通過合成伴奏,增加合理混響,即可得到AI歌手演唱的新歌。
Sovits4.0 的訓練生成過程雖已較為成熟,但“AI孫燕姿”的音色逼真程度高,很大程度還要歸功于歌手本人音色的獨特性,使AI 模型提取的特征更為顯著。值得注意的是,AI 歌手在情緒、咬字、換氣等細節處理上還有所欠缺,若應用于影片角色配音,還需進一步調整優化。
除音色轉換,AI 聲音制作還可服務于電影音樂和音效。音效方面,AI 可分析場景中的視覺元素,并自動生成相應的聲音效果,如爆炸聲、雨聲等。音樂方面,基于人工智能的音樂推薦創作系統可根據電影的情節、氛圍和風格,智能推薦或創作適合的背景音樂和配樂。2023 年1 月,谷歌發布有“音樂版Chat-GPT”之稱的MusicLM,可自由混搭不同類型的風格和樂器,通過輸入“晚宴上的爵士樂”這類指定地點和時間的文字,就能自動創作出符合當下情緒的樂曲。我國中央音樂學院開發的AI 自動作曲系統,可通過人工智能算法進行作曲、編曲、歌唱、混音,能夠在23 秒快速創作出一首歌曲,并達到一般作曲家的水平。迄今市場上已有許多AI 作曲的商業軟件,如Boomy、MURU、Amper Music、AIVA 等。以Amper Music 為例,該工具可通過幾次點擊設置音樂風格、樂器、時長、節奏,就可生成一首原創音樂,生成后還能繼續編輯音軌,包括調整音量、混響、節奏、旋律、添加或刪除樂器等。這些應用不僅提高了聲音制作的效率和質量,還為電影創作生產提供了更多創新升級的可能性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
家庭影院技術(2017年9期)2017-09-26 03:41:34
小康(2017年16期)2017-06-07 09:00:59
北方音樂(2017年4期)2017-05-04 03:40:10
學與玩(2017年6期)2017-02-16 07:07:16
光學精密工程(2016年6期)2016-11-07 09:07:19
