SDN中基于模型劃分的云邊協(xié)同推理算法
2024-01-09 13:20:06朱曉娟
蘭州工業(yè)學院學報 2023年6期
關鍵詞:模型
許 浩,朱曉娟
(安徽理工大學 計算機科學與工程學院,安徽 淮南 232001)
深度神經網絡(Deep Neural Network,DNN)是計算密集型網絡在依靠單一的云端或邊緣節(jié)點執(zhí)行推理任務時,會造成推理時延難以預測、推理性能明顯下降等問題[1]。為解決此類問題,眾多云邊協(xié)同處理方案應用而生,如基于云邊協(xié)同的分布式推理算法[2-4],通過將部分推理任務分配到邊緣節(jié)點以緩解云端的負載壓力,從而達到推理低時延、高可靠性的目的。而在實際的應用場景中,如何在網絡狀態(tài)和任務需求動態(tài)變化下協(xié)同多個邊緣節(jié)點合理分配推理任務,實現邊緣集群與云端協(xié)作以優(yōu)化推理時延和負載均衡是一個值得深入研究的問題[2]。
目前,已有大量的研究來加速DNN模型推理,例如將云計算環(huán)境中的推理計算問題建模為最短路徑和整數線性規(guī)劃問題并結合模型壓縮方法以減少通信成本[5];針對模型劃分方法,以DNN模型每層的神經元為單位,采用深度強化學習(Deep Reinforcement Learning,DRL)自適應卸載策略在各個物聯(lián)網設備上完成運算,實現在資源受限的物聯(lián)網設備上低時延的推理目標[6]。以上方法雖然有效降低模型的推理時延與資源需求,但可能會帶來模型推理精度的損失。因此,如何在網絡狀態(tài)和任務需求的動態(tài)變化中尋找最佳劃分點是我們研究的目標。
隨著深度強化學習被廣泛應用于感知決策領域,通過與網絡環(huán)境的不斷交互來實現優(yōu)化目標的最優(yōu)策略[7-8];SDN則可以通過控制器獲取實時網絡狀態(tài)信息,從而更加靈活地控制網絡、提高網絡性能[9]。本文結合SDN技術提出了基于模型劃分的云邊協(xié)同推理算法(Cloud-Edge collaborative inference algorithm based on model partition in SDN,SDN-CEP),以優(yōu)化推理時延和網絡資源的合理利用。通過將DNN模型分別部署在云邊端中,并設計任務預測器決策任務的執(zhí)行環(huán)境。邊緣環(huán)境中協(xié)同多個計算節(jié)點參與DNN推理,以解決單一節(jié)點算力不足的問題,并結合深度強化學習中的DQN算法實現推理模型的自適應劃分與卸載。SDN-CEP算法結合SDN技術從全局感知推理任務與網絡資源信息,通過協(xié)同架構的南向接口屏蔽邊端設備之間的差異,使用全局視圖進行網絡資源管理,并通過邊端控制器的北向接口按需配置并調用資源,為推理任務提供差異化的資源和服務保障,從而達到提高資源利用效率和優(yōu)化推理時延的目標。試驗結果表明,SDN-CEP算法能顯著降低DNN推理時延與計算成本,尤其是在動態(tài)網絡環(huán)境中。
1 系統(tǒng)架構
1.1 基于SDN的云邊協(xié)同架構
SDN是解決超低延遲的一種新型網絡創(chuàng)新架構,擁有獲取實時網絡狀態(tài)信息的能力[4,9],使得運用SDN技術加速云邊協(xié)同推理更加可行,如圖1所示。結合SDN技術創(chuàng)建的協(xié)同網絡架構能夠更好的發(fā)揮云與邊的優(yōu)勢,進而滿足協(xié)同推理任務在資源調度和信息集控制的需求。

圖1 基于SDN的云邊協(xié)同架構
1.2 協(xié)同推理框架
結合SDN技術的云邊協(xié)同推理框架如圖2所示,該框架主要有3部分組成:① 任務預測階段,在邊端控制器中建立一個預測器來判斷任務復雜度。② 推理選擇與劃分階段,經過任務預測器的判斷機制分配任務執(zhí)行環(huán)境。對于部署在邊端的模型,根據實時網絡帶寬、節(jié)點計算資源、節(jié)點數量以及模型層粒度大小等因素,結合DRL得到模型的劃分與卸載策略。③ 任務卸載階段,根據任務復雜度的預測函數與邊端中的卸載策略來卸載任務。并通過SDN的全局視圖進行傳遞和控制。

圖2 系統(tǒng)框架
1.3 任務復雜度預測
現有的協(xié)同推理研究過多關注于推理模型和網絡環(huán)境,忽視對模型輸入數據的處理[10]。本文通過對輸入數據提取特征進行復雜度預測,使其能夠選擇合適的推理環(huán)境來降低推理時延,通過在邊端控制器上的預測函數q(x)∈[0,1]來判斷輸入數據的復雜度,以決定任務的執(zhí)行環(huán)境,并通過SDN全局視圖傳遞云-邊整體環(huán)境信息。具體而言就是采用基于閾值的方法來選擇任務的執(zhí)行環(huán)境,即如果q(x)大于某個閾值δ,則將任務卸載到云端中處理f0。否則在邊端進行處理f1,利用SDN控制器合理調度邊端資源,將邊端模型分割并卸載到邊緣節(jié)點上進行協(xié)同處理,以保證推理精度和速度。所以,任務復雜度預測器可以抽象為(f0,f1,q)的組合,即預測器對于特定輸入x,最終輸出為
(1)
2 邊端模型的劃分與卸載
使用深度強化學習尋找問題的最優(yōu)解,需將問題建模為馬爾科夫決策過程(Markov Decision Process,MDP)[11],即問題模型用一個四元組(S,A,P,R)來表示。
(1)狀態(tài):S={B,ES,D},其中B表示當前網絡的傳輸速率;ES=(ES1,ES2,...,ESn)表示n個邊緣節(jié)點的計算資源;D=(D1,D2,...,Dm)表示m層推理模型的各層輸出數據大小。
(2)動作:當前網絡狀態(tài)的DNN模型有m-1個劃分點,邊緣環(huán)境中有n個邊緣節(jié)點。而動作空間由所有可能的動作組成。所以,動作空間A={N1,N2,...,Nm-1;ES1,ES2,...,ESn},其中{N1,N2,...,Nm-1}表示推理模型劃分點的集合;{ES1,ES2,...,ESn}表示當前所有可用的邊緣節(jié)點。
(3)獎勵:獎勵值越大表示選擇的動作越好。但在執(zhí)行推理任務中,因以優(yōu)化時延為目標,所以根據時延特征將獎勵值定義為
r=-((1-ω)Tall+ωCall),
(2)
式中:ω為獎勵函數中的權重因子,用來調節(jié)延遲-代價權衡。具體來說,用戶可以根據不同的應用需求,通過調整時延和代價的上界進行設置,假設時延和代價的上界分別為Tu和Cu,則權重因子可以表示為Tu/Cu[12]。
本文通過DQN算法結合SDN全局視圖來處理邊緣環(huán)境中推理模型的劃分與卸載問題。如圖3所示,DQN算法由2個參數不同但結構相同的卷積神經網絡構成,在算法的訓練過程中,Q(s,a,θ)評估網絡計算當前正確狀態(tài)動作的估計價值,θ表示評估網絡的參數。目標網絡則計算在所有動作下狀態(tài)s′所對應的Q(s′,a′,θ′),根據最大值選擇動作a′并計算目標價值函數,即

圖3 基于DQN的自適應推理模型劃分與卸載
Qt=r+γmaxa′Q(a′,s′,θ′),
(3)
式中:γ表示折扣因子;r表示獎勵值。
DQN算法訓練本質是為了使得當前Q值無限接近于目標Qt值,但由于目標函數中含有Q函數,導致目標函數變化,給訓練增加了一定的難度,因此,為更好的訓練神經網絡,消除樣本數據之間的依賴性,本文在DQN算法結構中結合SDN的全局視圖來讀取邊端網絡環(huán)境中的信息數據,通過模型輸出與目標值之間的均方誤差來表示損失函數。算法定義的損失函數如下
Loss(θ)=E[(Qt-Q(s,a,θ))2].
(4)
3 推理時延與成本
3.1 任務推理時延
假設DNN模型有m層,邊緣節(jié)點數量為n。第i層的輸出數據大小為Di。系統(tǒng)整體框架在執(zhí)行DNN推理任務時,同批次任務T的推理時延Tk主要由3部分組成:①邊緣節(jié)點執(zhí)行時間Tedge;②云端的執(zhí)行時延Tcloud;③數據上傳到云邊的時延Ttrans。由于推理結果往往很小,其返回的傳輸時間被忽略。
(5)
基于回歸模型預測DNN每層在邊緣節(jié)點上的執(zhí)行時間,即每張圖片在邊緣推理的時間可以表示為
(6)
式中:EDj表示第j層在邊緣節(jié)點上所需的執(zhí)行時間;Dp為推理模型第p層輸出數據的大小;B為當前的網絡傳輸速率。云端的推理時延則為
(7)
假設任務T中包含k張圖片,其中有i張在邊緣節(jié)點中執(zhí)行,k-i張在云端中執(zhí)行,則傳輸時延Ttrans為
(8)
式中:Dk表示在邊緣環(huán)境中執(zhí)行數據的大小;Dk-i為云端執(zhí)行數據的大小。綜上,目標函數為
(9)
式中:C1,C2,C3為目標函數的約束條件,C3表示算法所選的策略在網絡所有可選的策略中;M和C分別表示邊緣節(jié)點的內存與其CPU的計算資源;t則表示當前執(zhí)行的任務數量。
3.2 任務計算成本
任務的總成本由任務計算成本Cexe和傳輸成本Ctrans組成[11]。任務T的計算成本可以表示為
(10)
(11)
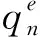
Ctrans=Dk·bc,
(12)
式中:Dk為傳輸數據的大小;bc為單位數據的傳輸成本。所以系統(tǒng)的總傳輸代價可以表示為
Call=Cexe+Ctrans.
(13)
3.3 SDN-CEP算法
算法的偽代碼如下:
算法1:SDN中基于模型劃分的云邊協(xié)同推理算法
輸入:
網絡傳輸速率B、各邊緣節(jié)點與云端資源、原始輸入數據及模型各層輸出數據大小,推理任務T、預測器閾值δ。
輸出:
DNN推理模型與任務的劃分和卸載策略
1:初始化試驗所需的參數;
2:for episode inTdo:
3:for each task do:
4:讀取圖像數據并計算特征;
5:利用特征計算圖像的復雜度;
6:if complexity_score≥δ
7:任務傳輸到云端處理,根據公式(7)計算時延;
8:else
9: 獲取可用的邊緣節(jié)點與模型劃分點的集合A;
10:通過SDN全局視圖得到環(huán)境s并傳遞給智能體agent;
11:使用DQN算法在A選擇模型的劃分點及其卸載的邊緣節(jié)點;
12:邊端節(jié)點協(xié)同完成任務,根據公式(6)計算時延;
13:根據公式(2)計算獎勵值;
14:更新DQN算法的最優(yōu)策略;
15:end for
16:SDN從全局感知任務和資源信息,按需配置并調用資源;
17:返回步驟2;
18:end for 。
4 試驗分析
4.1 試驗平臺
本文通過EdgeCloudSim[13]來搭建仿真試驗環(huán)境。試驗模擬的網絡環(huán)境和邊緣節(jié)點性能采用隨機生成的方式,DNN模型與DQN算法采用PyTorch框架實現。SDN的全局視圖消息則使用統(tǒng)一的格式將其封裝到一個XML文件中,使網絡全局視圖消息的形式靈活且易于擴展。在算法中,將學習率設置為0.01,折扣因子為0.09,經驗池大小為500,訓練批次大小為64。預測器復雜度的閾值為0.6,閾值的大小決定任務卸載到云邊中的數量,因時延與獎勵值是正相關的,所以閾值與獎勵值也呈正相關,圖4為不同閾值下SDN-CEP算法對應的獎勵值,可以看出當閾值為0.6時,只需要600輪訓練就可以快速使獎勵收斂到更高的值,比其他的閾值可以使算法具有更好的收斂性。
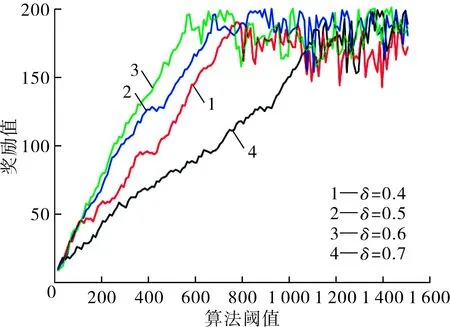
圖4 算法閾值與獎勵值的關系
4.2 SDN-CEP算法評估
4.2.1 推理時延評估
通過在不同的網絡環(huán)境下執(zhí)行ResNet[14],AlexNet[15],GooleNet[16]等3種DNN模型,并與現有的推理算法進行對比來衡量本文提出的SDN中基于模型劃分的云邊協(xié)同推理算法(SP)對DNN模型推理時延的優(yōu)化效果。
(1) 僅云計算(OC):DNN推理任務全部分配到云端進行處理。
(2) 僅邊計算(OE):推理任務全部卸載到邊緣節(jié)點中執(zhí)行。
(3) Neurosurgeon(NN):依據預測模型動態(tài)的選擇推理模型的最優(yōu)劃分點,結合網絡帶寬進行云邊協(xié)同推理計算[13]。
(4) DPTO算法(DP):使用DRL對推理任務進行按需劃分,將任務卸載到邊端計算資源最多的設備并與云端進行協(xié)同處理[14]。
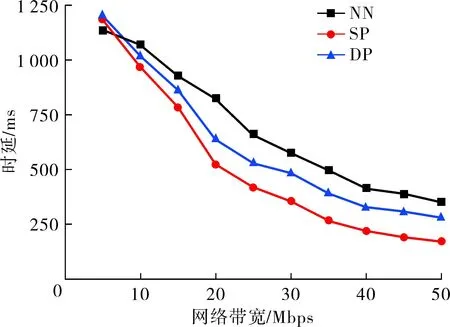
圖5(a)展示了在不同網絡傳輸速率環(huán)境下,NN、DP和SP這3種協(xié)同推理方法使用AlexNet網絡模型處理相同批次任務所需時延效果。當網絡速率一定時,SP方法的效果明顯優(yōu)于其它2種方法。在NN推理方法中,當網絡環(huán)境的傳輸速率過低時,推理任務在邊緣環(huán)境中執(zhí)行,系統(tǒng)的DNN推理時延相對較低,此時面對需要高算力的任務時推理性能較差,所以當網絡傳輸速率較高,NN方法傾向于將所有任務傳輸到云端處理,這與DP推理方法相近,但DP方法是使用DQN算法對任務進行按需劃分與卸載并通過云邊協(xié)同處理,所以其推理時延優(yōu)于NN。由于網絡傳輸速率的差異,SP方法的推理時延也存在差異,通過預測器將圖片分別傳輸到云、邊端執(zhí)行,傳輸速率越快,傳輸時延越小,SP方法的總時延也相對較小。
(a) 網絡帶寬與時延關系
圖5(b)展示了各算法在不同任務數量下使用AlexNet網絡模型的推理時延效果。在推理任務數量較少的情況下,邊端計算能力足以支撐,無需上傳到云端進行處理,此時OE方法的執(zhí)行時延小于OC方法的傳輸時延,所以OE的推理時延優(yōu)于OC,且推理時延與NN方法相近。但隨著任務數量的增多,邊緣服務器負載變大、計算能力有限,導致OE方法的響應時間大于OC方法的傳輸時延,此時OC方法表現更優(yōu)。SP方法利用基于SDN的云邊協(xié)同架構優(yōu)勢,結合SDN全局調度的特點進行動態(tài)任務調度,算法還考慮了任務復雜度和邊緣服務器在獎勵狀態(tài)下的計算能力,所以相比其他3種算法,隨著任務數量的增多,SP方法的推理時延相對較優(yōu)。
為進一步驗證算法的性能,本文隨機選取任務并在WiFi網絡下與NN、DP相比較,各算法推理的時延效果如圖5(c)所示:可以看出當網絡狀態(tài)與任務需求同時發(fā)生變化時,會導致時延性能的波動,這對加載模型、傳輸中間結果等數據都有影響。所以當邊緣節(jié)點的數量或模型劃分點增加時,通信條件對算法延遲有很大的影響,在不同的網絡狀態(tài)下會表現出明顯的波動,而SP算法因其通過SDN全局視圖對網絡狀態(tài)進行實時的觀察與更新,算法的狀態(tài)空間還考慮了傳輸距離,所以和其他2種協(xié)同算法相比較,網絡狀態(tài)對其影響相對較小。
各DNN模型在不同環(huán)境下推理的時延效果如圖6所示,協(xié)同環(huán)境相對于其它2種環(huán)境表現更優(yōu)。云計算將DNN卸載到云端執(zhí)行,其推理性能受限于網絡傳輸速率,在某些限定條件下不能有效展示推理性能,邊緣計算的推理性能則受限于邊緣服務器的計算能力,而協(xié)同計算在這些方面的劣勢不明顯。SP協(xié)同環(huán)境中算法將SDN技術與深度強化學習相結合處理模型的劃分與卸載問題,通過SDN控制器的南北向接口連接云和邊,實現云邊環(huán)境的協(xié)調控制,從全局感知資源信息進行合理分配,并通過全局視圖來反映網絡資源的動態(tài)變化。此外,在網絡資源限定的條件下,模型的推理時延與其本身的復雜程度呈正相關,所以,面對計算密集型神經網絡任務,利用協(xié)同環(huán)境處理是必要的。
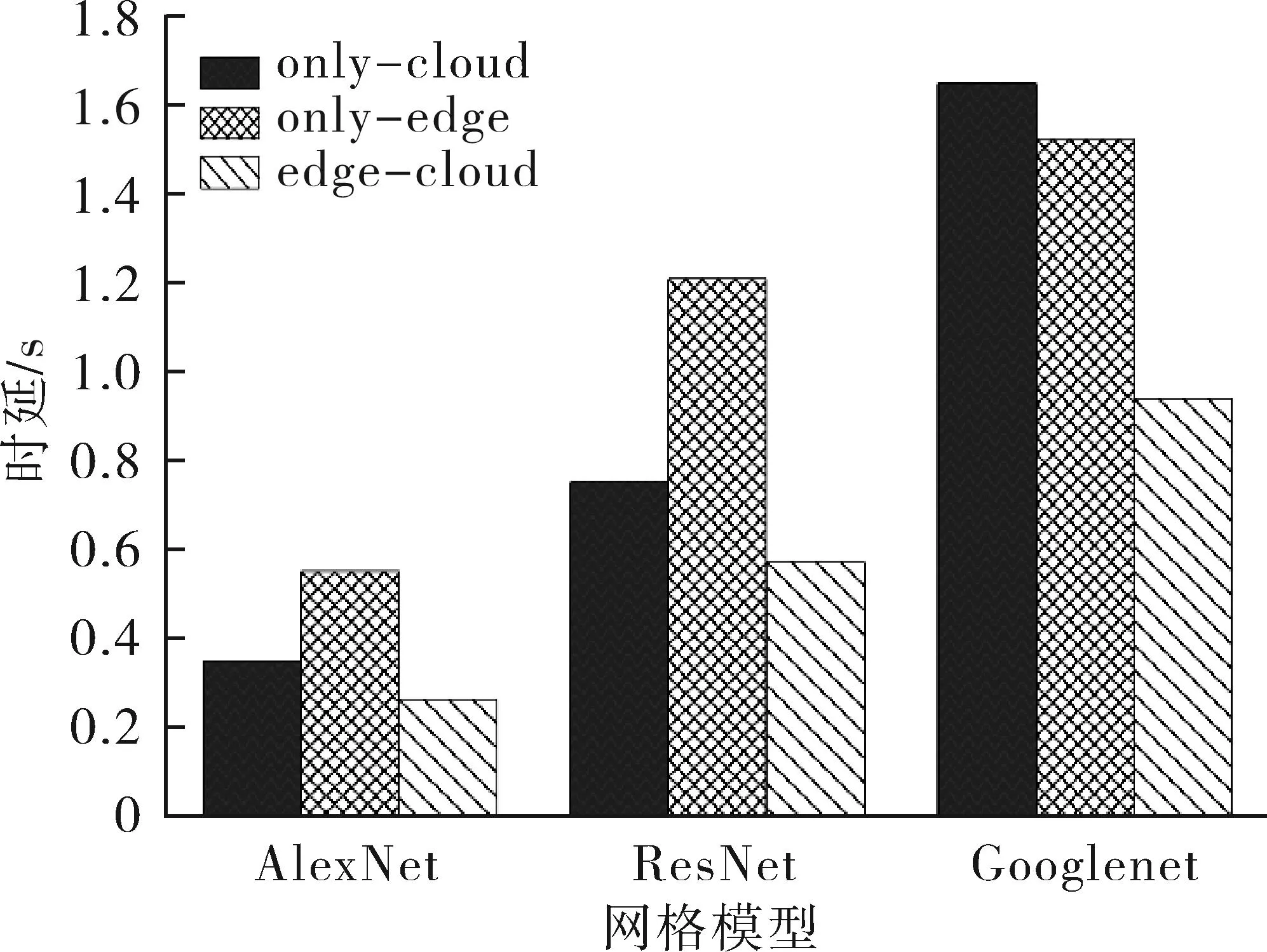
圖6 推理環(huán)境對時延的影響
4.2.2 計算代價評估
各方法在使用AlexNet模型執(zhí)行不同任務數量的推理性能如圖7所示。相比于邊緣計算環(huán)境和云計算環(huán)境,云邊協(xié)同環(huán)境下的系統(tǒng)成本更低。OC方法中云傳輸成本較高,但執(zhí)行成本較低,而OE方法則相反。SP方法采用基于SDN的云邊協(xié)作機制,充分結合邊緣和云的優(yōu)點,并采用深度強化學習劃分邊緣環(huán)境中的推理模型,其算法的狀態(tài)空間考慮了邊緣服務器的計算能力與任務復雜度,從而可以根據獎勵和損失不斷的更新環(huán)境中的卸載策略,在獎勵函數中,還考慮了系統(tǒng)成本以減少任務在分配過程中產生不必要的代價,所以SP方法的系統(tǒng)成本要優(yōu)于其它幾種推理方法。
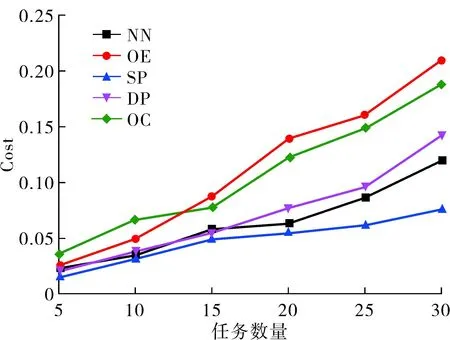
圖7 任務數量與算法的計算成本
5 結語
當前,深度神經網絡快速發(fā)展并廣泛應用于各種智能服務行業(yè),如自然語言處理、計算機視覺和語音識別等領域。為了加速DNN模型的推理速度并優(yōu)化其性能,本文結合SDN技術提出了基于模型劃分的云邊協(xié)同推理算法。該算法能夠對動態(tài)環(huán)境下的邊端推理模型進行自適應劃分與卸載,通過將傳統(tǒng)的DQN算法與SDN的全局視圖相結合,得到邊端模型的最優(yōu)劃分與卸載策略,構建任務復雜度預測器并結合SDN控制器分配任務執(zhí)行環(huán)境。試驗分析表明,與現有推理方法相比,算法的推理時延顯著降低。在后續(xù)的工作中,我們將重點研究邊邊協(xié)同的異常中斷問題以及邊端協(xié)同問題,以確保云邊端三方協(xié)同推理的魯棒性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
