基于YOLOv3不同場景辣椒采摘機器人識別定位研究
2024-01-11 07:54:56劉思幸陳福康董佩璇
農機化研究 2024年2期
關鍵詞:模型
劉思幸,李 爽,繆 宏,柴 巖,陳福康,王 健,董佩璇
(1.揚州大學 機械工程學院,江蘇 揚州 225127;2.揚州市蔣王都市農業觀光園有限公司,江蘇 揚州 225127;3.江蘇億科農業裝備有限公司,江蘇 揚州 225231)
0 引言
識別不同形狀、尺寸和位姿的辣椒對人類而言十分簡單,對機器人來說卻是十分困難[1]。何嶼彤、李斌等[2]采用改進YOLOv3的方法對豬臉進行識別,平均精度均值比原模型高9.87%。畢松[3]等基于深度卷積神經網絡設計了對光照變化、亮度不均、前背景相似等自然環境下典型干擾因素具有良好魯棒性的柑橘視覺識別模型,識別平均精度均值達86.6%。李善軍[4]等針對柑橘表面檢測費時費力的問題,提出一種改進SSD深度學習模型,可同時對多個柑橘進行實時分類檢測。吳露露、馬旭[5]等根據病斑的形態特點提出一種基于邊緣檢測與改進Hough變換的病斑目標檢測方法,檢測圓擬合精度達87.01%,圓心定位誤差為4.44%。陳海燕[6]等針對自然環境下鼠兔毛色與背景顏色相似的問題,構建一種局部紋理差異性算子LTDC來表征目標和背景之間的細微差異,能實現高原鼠兔目標的準確定位。薛月菊[7]等針對豬舍晝夜交替光線變化、熱燈光照影響及仔豬與母豬粘連等問題,提出基于改進Faster-R-CNN的哺乳母豬姿態識別算法,平均精度均值達93.25%。此外,還有眾多學者對不同大小、顏色和形狀的果實[8-10]以及不同姿態、距離的動物[11-13]進行目標檢測實驗并獲得了良好效果。
本文采用YOLOv3模型對辣椒進行精準檢測,并對不同補光位置、枝葉遮擋和果實重疊場景做識別實驗[14-16]。為了準確獲取辣椒的空間三維坐標,構建基于YOLOv3和realsense深度相機的識別定位系統,旨在為采摘機器人對不同作業場景的理解以及控制模型建立提供理論參考。
1 新技術論述
1.1 樣本數據采集
樣本取自揚州大學機械工程學院現代農業裝備實驗室,使用S-YUE晟悅相機采集正向光、頂光、背光和側光4種不同位置,以及果實重疊和枝葉遮擋的辣椒圖像,共2000張。數據集按7:2:1比例配置,即訓練集1400張、測試集400張、驗證集200張。對數據集進行翻轉、增亮、變暗、加入椒鹽噪聲等操作,以增加模型魯棒性和泛化性。利用labelimg工具對數據進行標注,類型為PascalVOC,標注類別為pepper。
1.2 YOLOv3網絡模型
YOLOv3網絡框架如圖1所示。其主干網絡修改為Darknet-53,內部包含5個殘差塊,并采用跳躍式連接,緩解了神經網絡中因深度增加帶來的梯度消失問題[17]。與傳統卷積網絡不同,YOLOv3利用步幅為2的卷積層代替池化層進行下采樣,有效避免了低層級特征的損失。每一次卷積后分別進行Batch Normalization正則化與Leaky ReLU操作。

圖1 YOLOv3網絡結構圖Fig.1 YOLOv3 network structure
網絡輸出結果分為(13,13,75),(26,26,75)和(52,52,75)等3種感受野。維度75可拆分為3×(20+1+4),3代表先驗框個數,20代表預測目標類別數,1代表先驗框是否包含目標的置信度,4代表先驗框的4個微調參數bx、by、tx、ty。其數學表達式為
(1)
其中,tx、ty、Pw、Ph為網絡的輸出結果,bx、by分別為先驗框中心的橫縱坐標點;bw、bh為先驗框的寬和高;Cx、Cy為先驗框中心點相對圖像原點的偏移量。圖2為先驗框和預測框示意圖。

1.先驗框 2.預測框圖2 預測框回歸示意圖Fig.2 Schematic diagram of prediction box regression
1.3 目標三維定位方法
辣椒三維坐標中的深度Z通過realsense相機的SDK函數獲得。利用MatLab對相機的內外參作標定,從而建立像素坐標系到相機坐標系的映射模型,標定的平均誤差僅0.08,滿足精度需求。標定結果如圖3和圖4所示。
The study outcome was to evaluate the compliance of the Hospital personnel with a FIT-based screening program by measuring the personnel participation rates.
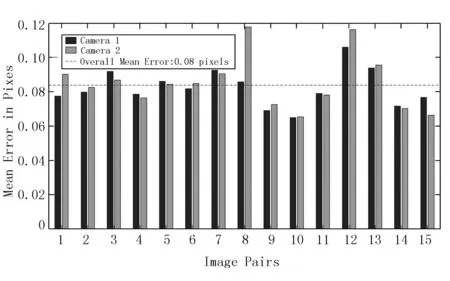
圖3 標定誤差直方圖Fig.3 Calibration error histogram

圖4 相機標定結果Fig.4 Calibration results of camera
假設相機坐標系中辣椒的空間位置Pc為(Xc,Yc,Zc),則像素坐標系與之映射關系為
(2)
2 應用的方式方法
2.1 實驗設計
采摘經常在傍晚、夜間或環境較暗的情況下進行,故一般搭載補光系統。為了研究光照角度、枝葉遮擋和果實重疊對識別效果的影響,基于YOLOv3算法對正向光、側光、背光和頂光4種光照情況以及果實重疊和枝葉遮擋場景進行識別實驗。
1)算法環境搭建:實驗采用的操作系統是Ubuntu20.04.2,CPU為酷睿i7,內存16G。GPU為NVIDIA GEFORCE RTX3070顯存,cuda版本10.0.1,cudnn版本10.0.1,深度學習框架為pytorch1.2.0。
2)實驗平臺搭建:將辣椒植株按株距330mm、壟距600mm和行距300mm布置于實驗室土槽中,參數如表1所示[18]。模擬枝葉遮擋和果實重疊將辣椒模型粘貼在植株的坐果位置。光源分別按正向光、頂光、背光和側光位置擺設。其中,頂光光源在植株正上方1m處;側光的光源在植株左側或右側斜45°1m處;背光的光源在植株正后方偏上45°處,距離1m;正向光在辣椒正面1m處。實驗過程如圖5所示。

表1 實驗環境與田間參數Table 1 Experimental environment and field parameters

圖5 辣椒采摘不同場景識別實驗流程圖Fig.5 Flow chart of different scene identification experiment for picking pepper
枝葉遮擋分為輕度遮擋、中度遮擋和重度遮擋。輕度遮擋即枝葉與果實遮擋面積為0~30%,中度遮擋即枝葉與果實之間的遮擋面積為30%~50%,重度遮擋即枝葉與果實之間的遮擋面積大于50%。
果實重疊分為輕微重疊、中度重疊和重度重疊。輕微重疊即果實與果實之間的重疊面積為0~30%,中度遮擋即果實與果實之間的遮擋面積為30%~50%,重度遮擋即果實與果實之間的遮擋面積大于50%。
2.2 性能評估指標
采用精確率(P)、召回率(R)以及平均精度均值(mAP)作為模型的評價指標。精確率用來評價識別的精確性,精確率越高模型的錯檢率越低;召回率用來評價識別的全面性,召回率越高模型的漏檢率越低。平均精度均值是指平均精度值(AP)在所有類別下的均值。評價指標的計算公式為
(3)
(4)
(5)
(6)
式中TP-預測正確的正例;
FP-預測錯誤的正例;
FN-預測錯誤的反例;
TN-預測正確的反例;
C-目標類別數。
3 獲得的效果和突破
3.1 不同光照場景識別效果
圖6所示為模型訓練結果。由圖6可知:召回率Recall在迭代300次時達0.98,平均精度均值mAP達0.95,精確率達0.854,滿足辣椒采摘識別精度需求。

圖6 模型訓練結果Fig.6 Training results of the mode
表2為不同光照場景識別結果對比。由表2可知:識別成功率由高到低依次為正向光、頂光、側光和背光,分別為92%、88%、84%和78%。
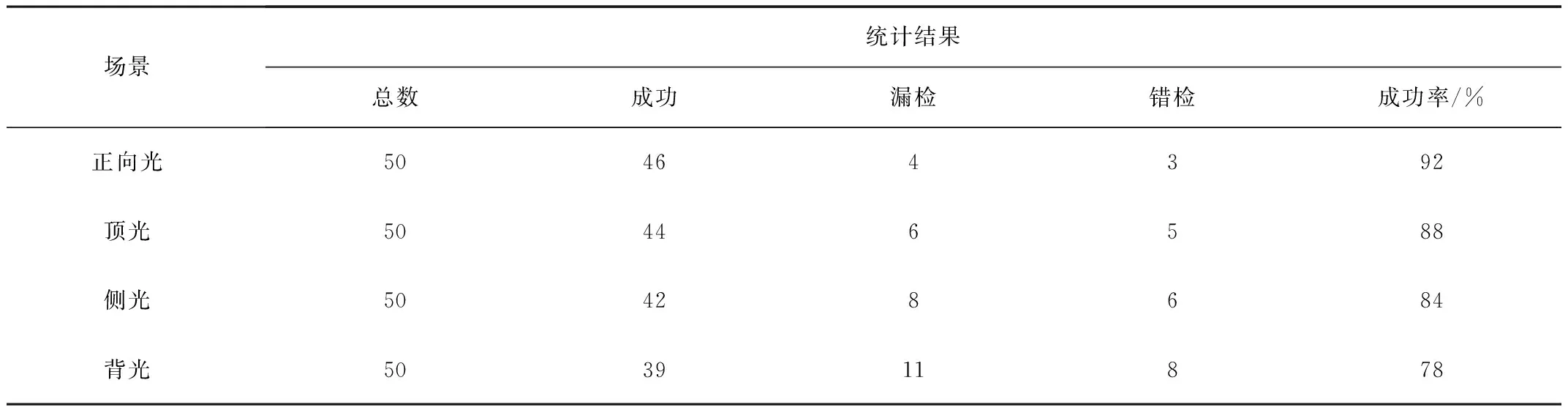
表2 不同光照場景識別結果對比Table 2 Comparison of recognition results under different lighting conditions
圖7為不同光照場景識別效果。由圖7可知:不同補光位置下,辣椒的果實、葉子顏色變化明顯,陰影交錯復雜;在正向光場景下,辣椒葉子和果實顏色基本不變;側光場景下,辣椒顏色泛白,特征信息丟失較多,嚴重影響果實識別精度;頂光場景下,辣椒顏色和形狀特征丟失較少,但光線稍顯暗淡。由于光照集中在頂部葉片,使得前景和背景區別明顯,有利于辣椒的精準識別。背光場景下,光線多從枝葉和辣椒之間穿透,模型輸入大量噪聲信息,且背光場景下葉片顏色更顯暗淡,背景信息更復雜,導致辣椒的特征更難提取。

圖7 不同光照場景識別結果Fig.7 Recognition results of different lighting scenes
3.2 果實重疊和枝葉遮擋識別效果
枝葉遮擋和果實重疊識別結果對比如表3所示。由表3可以看出:輕度遮擋和輕度重疊場景下,辣椒識別成功率達96%,滿足采摘識別精度需求;枝葉遮擋錯檢率高于果實重疊,漏檢率低于果實重疊,識別成功率總體高于果實重疊。這是因為做標簽遇到枝葉遮擋時,難免將枝葉部分框進ground truth中,導致模型在訓練時錯誤地將帶有枝葉的辣椒作為預測對象;而果實重疊場景識別成功率低是因為YOLO模型識別小目標和密集物體性能差。
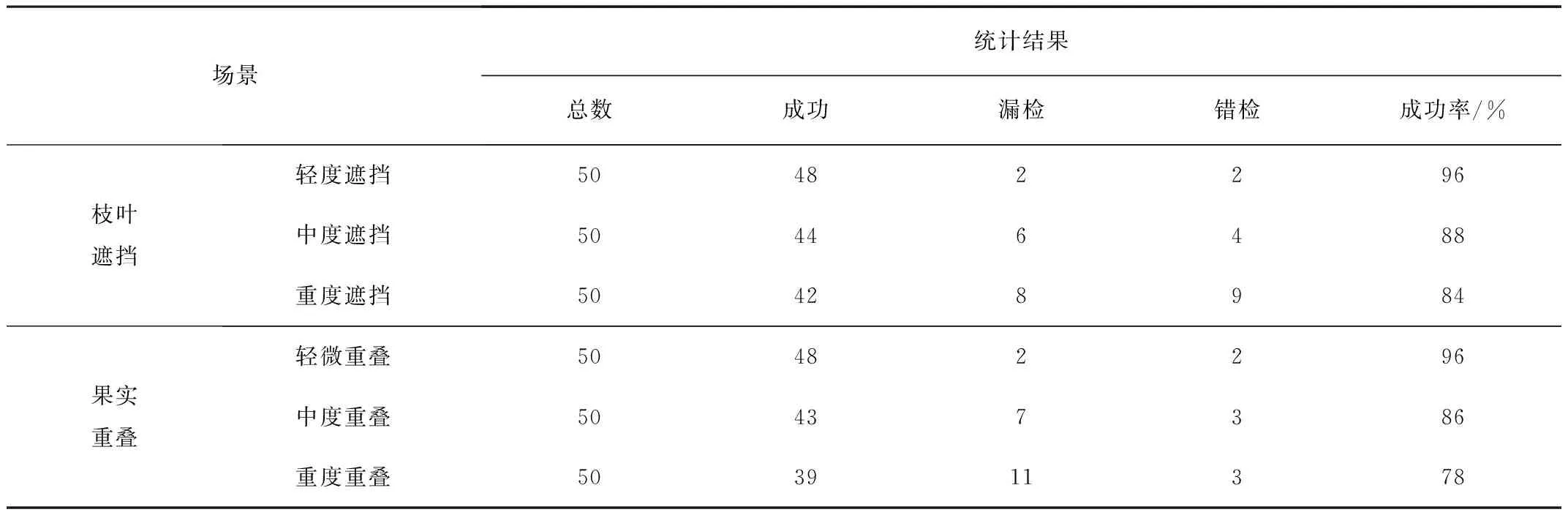
表3 枝葉遮擋和果實重疊識別結果對比Table 3 Comparison of recognition results of branch and leaf occlusion and fruit overlap
不同遮擋程度識別結果如圖8所示,不同重疊程度識別結果如圖9所示。中度遮擋和中度重疊時,模型錯檢數無明顯提升,兩者識別成功率分別為88%和86%。由圖8、圖9和表3可知:重度遮擋和重度重疊時,兩者漏檢數明顯增多,枝葉遮擋的錯檢率明顯高于果實重疊。

圖8 不同遮擋程度識別結果Fig.8 Comparison of recognition results of branch and leaf occlusion

圖9 不同重疊程度識別結果Fig.9 Comparison of recognition results of fruit overlap
3.3 三維定位實驗結果
辣椒在相機坐標系下的真實坐標為(X,Y,Z),利用模型測得的坐標為(X0,Y0,Z0),定位系統的測量誤差為ΔX、ΔY、ΔZ,則綜合定位誤差ΔE為
(7)
表4為辣椒三維坐標識別結果。實驗表明:基于YOLOv3和realsense深度相機的識別定位系統可實現辣椒的三維坐標定位,綜合定位誤差最大只有0.024m,滿足采摘精度需求。
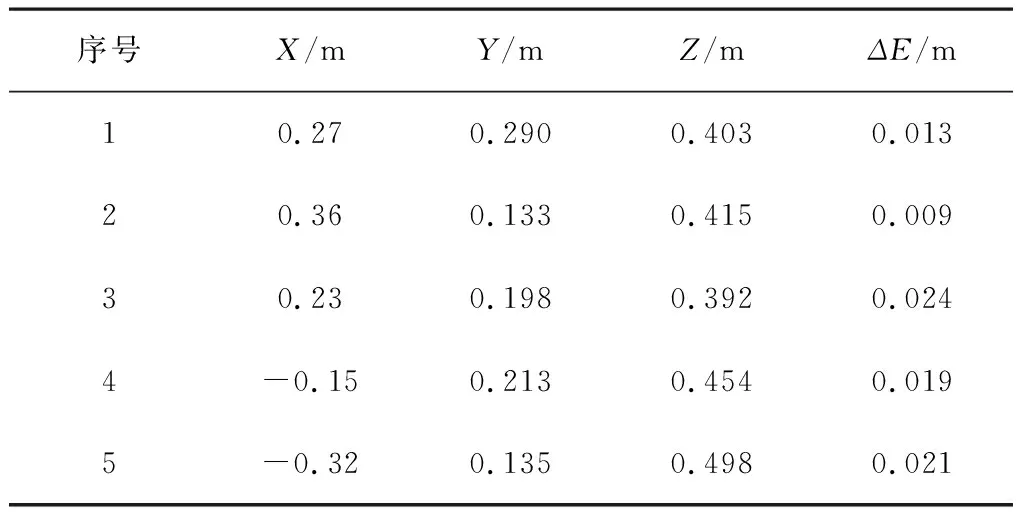
表4 辣椒中心點三維坐標計算結果Table 4 Results of 3D coordinate of pepper center points
4 結論
1)基于YOLOv3網絡模型搭建了辣椒識別系統,包含軟件環境和硬件平臺。實驗表明:召回率達0.98,平均精度均值達0.95,精確率達0.854,滿足辣椒采摘識別精度需求。
2)基于4種不同光照場景對YOLOv3模型識別效果做了對比,成功率由高到低依次為正向光、頂光、側光和背光。其中,正向光的識別成功率達92%,分別高于頂光、側光和背光4、8、14個百分點。
3)基于不同枝葉遮擋和果實重疊程度對模型識別效果做了對比實驗,結果表明:輕微遮擋或重疊時(遮擋或重疊面積小于30%),模型識別成功率幾乎不變,保持在96%左右;中度遮擋或重疊時(遮擋或重疊面積在30%~50%之間),模型的漏檢率有所上升,整體識別成功率達86%左右;重度遮擋或重疊時(遮擋或重疊面積大于50%),辣椒難以被識別,錯檢率和漏檢率皆明顯上升。
4)基于YOLOv3模型和realsense深度相機的識別定位系統可實現辣椒的三維坐標定位,綜合定位誤差最大僅0.024m,滿足采摘機器人的精度需求。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
