二次聚類的無監(jiān)督行人重識別方法
2024-01-18 16:52:46熊明福肖應(yīng)雄胡新榮
計(jì)算機(jī)工程與應(yīng)用 2024年1期
熊明福,肖應(yīng)雄,陳 佳,胡新榮,彭 濤
1.武漢紡織大學(xué) 計(jì)算機(jī)與人工智能學(xué)院,武漢 430200
2.武漢大學(xué) 國家網(wǎng)絡(luò)安全學(xué)院,武漢 430072
行人重識別是針對同行人在不同時(shí)間地點(diǎn)下攝像機(jī)所采集的圖片進(jìn)行檢索和匹配的技術(shù),即給定一張?zhí)囟ǖ男腥藞D像,行人重識別的目的是匹配出該行人在其他不同攝像頭(相機(jī))下所出現(xiàn)的圖像[1-4]。其在視頻監(jiān)控、智能安防等領(lǐng)域有著極其重要的應(yīng)用。本質(zhì)上行人重識別可以視作為一項(xiàng)圖像檢索和匹配任務(wù),其特點(diǎn)在于訓(xùn)練集和測試集是由不同的行人所組成的。一般來說,行人重識別主要分為有監(jiān)督和無監(jiān)督的方法[5],其中有監(jiān)督行人重識別主要利用了有標(biāo)簽標(biāo)注的訓(xùn)練集數(shù)據(jù)對模型進(jìn)行訓(xùn)練,使得模型在未知的測試集上也具有一定的預(yù)測能力。此類方法在早期的科學(xué)研究中取得了不錯(cuò)的效果,然而其由于數(shù)據(jù)的標(biāo)注工作費(fèi)時(shí)耗力,從而限制了行人重識別在實(shí)際中的進(jìn)一步應(yīng)用。
近年來,無監(jiān)督的行人重識別方法得到了越來越多學(xué)者的關(guān)注[6-9],其主要思想為利用一個(gè)預(yù)訓(xùn)練好的基礎(chǔ)網(wǎng)絡(luò)來聚類生成偽標(biāo)簽并根據(jù)偽標(biāo)簽做有監(jiān)督學(xué)習(xí)。無監(jiān)督行人重識別領(lǐng)域通常可分為兩類:域自適應(yīng)的行人重識別(unsupervised domain adaptation person Re-ID)[10-13]和純無監(jiān)督行人重識別(purely unsupervised learning person Re-ID)[14-16]。其中在域自適應(yīng)行人重識別中,通常給定一個(gè)有標(biāo)簽的源域來訓(xùn)練網(wǎng)絡(luò),再使其遷移到目標(biāo)域中并取得良好的效果,兩個(gè)域有著不同的數(shù)據(jù)種類與數(shù)據(jù)風(fēng)格[5]。而純無監(jiān)督行人重識別無需借助任何標(biāo)注信息而僅僅只需要一個(gè)預(yù)先訓(xùn)練好的預(yù)訓(xùn)練模型,從而使得其在行人重識別任務(wù)中更具有挑戰(zhàn)性。由于其不需要事先進(jìn)行大量的數(shù)據(jù)標(biāo)注,在領(lǐng)域內(nèi)得到越來多的學(xué)者關(guān)注[17-18]。
因此,本文也主要關(guān)注純無監(jiān)督行人重識別方法。當(dāng)前最先進(jìn)的無監(jiān)督行人重識別方法[8-9,17]大多都是同時(shí)利用聚類算法聚類得到的偽標(biāo)簽和內(nèi)存字典中的特征實(shí)例做對比學(xué)習(xí),從而能夠以有監(jiān)督的方式進(jìn)行訓(xùn)練,在每個(gè)訓(xùn)練批次的開始前,所有訓(xùn)練集圖像的特征都由當(dāng)前網(wǎng)絡(luò)進(jìn)行特征提出,并由聚類算法類似DBScan[19]或者K-means[20]聚類生成偽標(biāo)簽,算法將聚類ID作為個(gè)人身份ID 被分配給每個(gè)圖像。與此同時(shí),大多數(shù)方法[8,17]都將初始化一個(gè)內(nèi)存字典,由神經(jīng)網(wǎng)絡(luò)進(jìn)行基于內(nèi)存字典的對比損失[21]訓(xùn)練。此類方法在一定程度上都取得了不錯(cuò)的效果,被廣大學(xué)習(xí)者所接受。但由于行人重識別本身就是一個(gè)復(fù)雜的問題[22],由于其本身從數(shù)據(jù)獲取和目標(biāo)檢索都有其獨(dú)特的性質(zhì),導(dǎo)致現(xiàn)有方法還有進(jìn)一步提升的空間,主要表現(xiàn)在以下兩個(gè)方面:
(1)現(xiàn)有行人重識別數(shù)據(jù)集大多數(shù)都由6至12臺攝像機(jī)采集而成,不同的攝像機(jī)采集地點(diǎn)不同,因而也導(dǎo)致了其圖像的光照環(huán)境也不盡相同,其相應(yīng)的灰暗程度也不同。如圖1(a)所示,針對同一數(shù)據(jù)集Market-1501[23],所抽取的6 張圖像均來源于同一行人,由于拍攝視角、光照強(qiáng)度等因素的影響,其中第一排三張圖像明顯暗于第二排的三張圖像,這種圖像風(fēng)格的差異性會(huì)影響后期聚類的精度,從而影響最終的模型準(zhǔn)確性。同時(shí),針對不同的數(shù)據(jù)集DukeMTMC-ReID[24]和Market-1501,如圖1(b)所示,前者采集于冬季國外校園,行人多著厚重的冬裝,色彩相對沉暗;而后者采集于夏天國內(nèi)校園,其行人多穿短袖,色彩相對鮮明。這種顯著的著裝風(fēng)格差異,降低了模型在這兩個(gè)數(shù)據(jù)集之間跨域使用的魯棒性,使得模型的泛化能力進(jìn)一步減弱,從而導(dǎo)致行人重識別效果的下降。同時(shí)上述問題會(huì)產(chǎn)生偽標(biāo)簽噪聲,所謂偽標(biāo)簽噪聲,即聚類算法不能保證樣本內(nèi)的偽標(biāo)簽生成與真實(shí)身份的真實(shí)對應(yīng),從而在訓(xùn)練過程中會(huì)累積偽標(biāo)簽的噪聲誤差,從而阻礙模型的準(zhǔn)確性。

圖1 行人在不同相機(jī)下呈現(xiàn)照片風(fēng)格不同F(xiàn)ig.1 Person showing different styles of photos under different cameras
(2)在利用偽標(biāo)簽進(jìn)行有監(jiān)督學(xué)習(xí)訓(xùn)練的過程中,因?yàn)槊總€(gè)聚類里實(shí)例的數(shù)量并不平衡,這是由數(shù)據(jù)集本身的數(shù)據(jù)分布特點(diǎn)和聚類算法的固有缺陷所帶來的客觀問題,實(shí)例少的聚類會(huì)比實(shí)例多的聚類更新更快。現(xiàn)有基于字典更新的方法由于內(nèi)存字典的大小并不能無限制地增大,模型很容易向?qū)嵗急容^小的樣本標(biāo)簽偏移,因此內(nèi)存字典的初始化與更新策略在模型的訓(xùn)練中起著至關(guān)重要的作用。
為了解決上述問題,本文提出了一種基于二次聚類的無監(jiān)督行人重識別框架來解決當(dāng)前方法存在的一些問題。針對聚類偽標(biāo)簽問題和更新速率不一致的問題,本文提出的框架主要包含兩個(gè)部分,即基于全局的二次聚類模塊以及基于聚類結(jié)果的有監(jiān)督學(xué)習(xí)模塊。前者主要解決跨相機(jī)間圖像風(fēng)格不一致的問題,后者主要解決網(wǎng)絡(luò)更新速率不一致的問題。兩個(gè)子模塊協(xié)同并行優(yōu)化,共同抑制因跨攝像機(jī)和環(huán)境因素的差異而導(dǎo)致行人重識別精度不高的問題,并且在公開數(shù)據(jù)集上相對于傳統(tǒng)方法取得了不錯(cuò)的效果。
總結(jié)來說,該框架由兩個(gè)模塊組成,首先通過基于全局的二次聚類模塊來分別以相機(jī)ID 和行人ID 聚類,然后通過基于聚類結(jié)果的有監(jiān)督學(xué)習(xí)模塊進(jìn)行有監(jiān)督學(xué)習(xí),雙模塊協(xié)同訓(xùn)練以共同抑制跨攝像頭間采集的圖像所產(chǎn)生錯(cuò)誤偽標(biāo)簽的問題。本文的創(chuàng)新工作主要表現(xiàn)在以下幾個(gè)方面:
(1)提出了一種基于二次重聚類的無監(jiān)督行人重識別方法,來解決因硬件差異和光照等因素帶來樣本錯(cuò)誤偽標(biāo)簽生成的問題。
(2)提出的方法包括無監(jiān)督聚類和有監(jiān)督訓(xùn)練學(xué)習(xí)模塊,前者基于全局二次聚類分別對相機(jī)ID 和行人身份ID 進(jìn)行無監(jiān)督分析,解決了同一行人在不同攝像機(jī)視角下的統(tǒng)一成像風(fēng)格問題;后者則采用有監(jiān)督學(xué)習(xí)方式改進(jìn)了內(nèi)存字典的初始化與更新方式,解決了模型在訓(xùn)練中偏移的問題。
(3)本文提出方法的兩個(gè)子模塊協(xié)同優(yōu)化,共同抑制因跨攝像機(jī)和環(huán)境因素的差異而導(dǎo)致行人重識別精度不高的問題,并且在公開數(shù)據(jù)集上相對于傳統(tǒng)方法取得了不錯(cuò)的效果。
1 相關(guān)工作
1.1 無監(jiān)督行人重識別
根據(jù)是否利用有標(biāo)注的源數(shù)據(jù)集,無監(jiān)督行人重識別可分為兩類:域自適應(yīng)的無監(jiān)督行人重識別(unsupervised domain adaptation,UDA)以及純無監(jiān)督行人重識別(purely unsupervised learning,USL)[14]。UDA嘗試?yán)糜袠?biāo)記的源域數(shù)據(jù)和沒有標(biāo)記的目標(biāo)域數(shù)據(jù)來綜合訓(xùn)練出一個(gè)在目標(biāo)域表現(xiàn)良好的行人重識別模型,其目標(biāo)是將從源域(source domain)學(xué)習(xí)到的知識遷移到目標(biāo)域(target domain),從而提升模型在真實(shí)部署環(huán)境下的性能表現(xiàn)。而USL 其在模型訓(xùn)練之中不需要借助任何有標(biāo)注的圖片信息,因此其在模型的訓(xùn)練之中更具有挑戰(zhàn)性。
雖然訓(xùn)練是在不同的數(shù)據(jù)條件下進(jìn)行的,但UDA和USL的大多數(shù)方法采用相似的學(xué)習(xí)策略:通過聚類算法生成偽標(biāo)簽,然后利用內(nèi)存字典進(jìn)行對比學(xué)習(xí)。Zhong等[25]提出了一種基于相機(jī)到相機(jī)的風(fēng)格轉(zhuǎn)移來對齊目標(biāo)樣本的訓(xùn)練數(shù)據(jù),Ge等[11]提出了一種基于域自適應(yīng)的教師學(xué)生模型來應(yīng)對域轉(zhuǎn)換的無監(jiān)督行人重識別,其利用了教師模型與學(xué)生模型兩個(gè)模型來共同訓(xùn)練抑制聚類中產(chǎn)生的標(biāo)簽不一致問題。Yang 等[9]提出了一種動(dòng)態(tài)和對稱交叉熵?fù)p失來處理嘈雜的樣本,并提出一種相機(jī)感知元學(xué)習(xí)算法來適應(yīng)相機(jī)偏移。
在本文中,主要關(guān)注的是USL 方法,提出的框架其針對的是無監(jiān)督行人重識別中的偽標(biāo)簽噪聲以及內(nèi)存字典[12]的更新問題,在下文中將詳細(xì)介紹這兩塊內(nèi)容。
1.2 偽標(biāo)簽噪聲
所謂偽標(biāo)簽噪聲,即聚類算法不能保證樣本內(nèi)的偽標(biāo)簽生成與真實(shí)身份的真實(shí)對應(yīng),從而在訓(xùn)練過程中會(huì)累積偽標(biāo)簽的噪聲誤差,從而阻礙模型的準(zhǔn)確性。
在最近的研究中,減少因?yàn)榫垲愃惴ǘ鴰淼膫螛?biāo)簽噪聲問題主要有以下幾種方法:偽標(biāo)簽更正法[18,26]和損失函數(shù)重設(shè)計(jì)法[27]。在訓(xùn)練過程中,他們重新加權(quán)計(jì)算權(quán)重以生成更為準(zhǔn)確的偽標(biāo)簽。Li 等[28]試圖通過訓(xùn)練一個(gè)額外的網(wǎng)絡(luò)來重新加權(quán)偽標(biāo)簽樣本。然而在網(wǎng)絡(luò)的優(yōu)化過程中,它需要額外干凈的數(shù)據(jù)作為測試集,這在實(shí)際應(yīng)用中是難以實(shí)現(xiàn)的。
面對偽標(biāo)簽噪聲問題,提出了基于全局的二次聚類模塊來抑制偽標(biāo)簽噪聲問題,其核心思想是對數(shù)據(jù)進(jìn)行二次聚類:以相機(jī)ID 為單位進(jìn)行全局間的一次聚類和在相機(jī)內(nèi)以行人ID為單位進(jìn)行二次聚類。詳細(xì)過程將在2.2節(jié)展開描述。
1.3 內(nèi)存字典
當(dāng)前大多數(shù)無監(jiān)督對比學(xué)習(xí)方法都會(huì)初始化一個(gè)內(nèi)存字典,由神經(jīng)網(wǎng)絡(luò)進(jìn)行基于內(nèi)存字典的對比損失訓(xùn)練,通過內(nèi)存字典的不斷動(dòng)態(tài)更新從而促進(jìn)對比無監(jiān)督學(xué)習(xí)。與無監(jiān)督的對比學(xué)習(xí)類似,當(dāng)前最先進(jìn)的USL方法也利用對比學(xué)習(xí)[8-9,17]構(gòu)建記憶字典。在訓(xùn)練過程中,內(nèi)存字典中的實(shí)例特征由同一個(gè)聚類中的實(shí)例特征動(dòng)態(tài)更新。
然而由于每個(gè)聚類中的實(shí)例數(shù)目并不相同,實(shí)例數(shù)目較小的聚類更新得較快,實(shí)例數(shù)目較多的聚類更新得慢,模型很容易向?qū)嵗急容^大的樣本標(biāo)簽偏移。基于此,提出了基于二次聚類結(jié)果的有監(jiān)督學(xué)習(xí)模塊,靈感來源于文獻(xiàn)[29],不再以實(shí)例特征為基準(zhǔn)而是以聚類特征為基準(zhǔn)來初始化與更新內(nèi)存字典,可以有效地防止網(wǎng)絡(luò)訓(xùn)練偏向?qū)嵗龜?shù)目較大的聚類,詳細(xì)過程將在2.3 節(jié)展開描述。
2 本文方法
針對以往的工作沒有考慮到不同相機(jī)對同一個(gè)行人所采集的圖片可能會(huì)出現(xiàn)較大反差繼而產(chǎn)生錯(cuò)誤的聚類偽標(biāo)簽,以及每個(gè)聚類里的實(shí)例數(shù)量不平衡導(dǎo)致的網(wǎng)絡(luò)更新速率不一致的問題,本文提出了一種基于二次聚類的無監(jiān)督行人重識別網(wǎng)絡(luò)框架。該框架主要包含兩個(gè)部分,基于全局的二次聚類模塊以及基于聚類結(jié)果的有監(jiān)督學(xué)習(xí)模塊。前者主要解決跨相機(jī)間圖像風(fēng)格不一致的問題,后者主要解決網(wǎng)絡(luò)更新速率不一致的問題。兩個(gè)模塊協(xié)同訓(xùn)練配合,使得網(wǎng)絡(luò)逐漸收斂,最終得到一個(gè)效果良好、泛化能力較強(qiáng)的行人重識別網(wǎng)絡(luò)。
2.1 整體結(jié)構(gòu)
本文使用ResNet 50[22]網(wǎng)絡(luò)作為本文的基礎(chǔ)網(wǎng)絡(luò)(Backbone),其所用到的Resnet50 核心層主要用到5 個(gè)卷積層,第一個(gè)卷積層的輸出為112×112,其內(nèi)部配置為7×7大小的卷積核,所設(shè)的步長為2。
圖2給出了本文所提出的整體網(wǎng)絡(luò)框架,主要是由基于全局的二次聚類模塊(global quadratic clustering module)以及基于聚類結(jié)果的有監(jiān)督學(xué)習(xí)模塊(supervised learning module based on quadratic clustering results)組成,為了方便描述,下文簡稱其GQCM模塊以及SLM模塊。
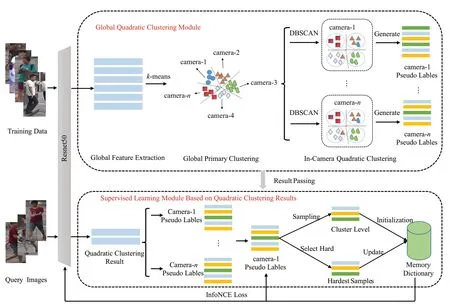
圖2 基礎(chǔ)網(wǎng)絡(luò)框架Fig.2 Basic network framework
首先,初始化了一個(gè)預(yù)訓(xùn)練好的ResNet50 網(wǎng)絡(luò)作為基礎(chǔ)網(wǎng)絡(luò)提取所有訓(xùn)練樣本特征,GQCM作為二次聚類模塊,針對所有特征做一次k-means 的均值聚類,主要作用為將圖片根據(jù)不同的相機(jī)成像風(fēng)格聚類為同一個(gè)簇心。將同一個(gè)簇心下的所有特征視為同一相機(jī)所采集到的圖片所生成的特征并為其生成相機(jī)ID 偽標(biāo)簽。接下來,對同一相機(jī)下的所有圖片特征做DBSCAN二次聚類并為其分配行人ID 偽標(biāo)簽。這樣,就得到了以相機(jī)為分類的帶有行人ID 偽標(biāo)簽的圖片特征,就可以有效地解決因跨相機(jī)成像風(fēng)格不統(tǒng)一而帶來的聚類偽標(biāo)簽噪聲問題。最后,GQCM模塊將帶有偽標(biāo)簽的圖片特征傳遞給SLM模塊,供其利用該偽標(biāo)簽做有監(jiān)督學(xué)習(xí)。
2.2 基于全局的二次聚類模塊(GQCM)
當(dāng)前大多方法普遍采用聚類算法生成偽標(biāo)簽,然而,對同一個(gè)行人不同相機(jī)所采集的圖像可能會(huì)出現(xiàn)較大反差繼而易產(chǎn)生錯(cuò)誤的聚類偽標(biāo)簽,即偽標(biāo)簽噪聲問題,聚類算法不能保證樣本內(nèi)的偽標(biāo)簽生成與真實(shí)身份的準(zhǔn)確對應(yīng)。
為了抑制偽標(biāo)簽的噪聲問題,本文提出基于全局的二次聚類模塊(GQCM),該模塊主要是針對全局圖像進(jìn)行二次聚類,即生成相機(jī)ID 偽標(biāo)簽與行人身份ID 偽標(biāo)簽,由于同一個(gè)相機(jī)所采集風(fēng)格相似的圖像,因此對此風(fēng)格相似的圖像進(jìn)行DBSCAN 聚類,相對會(huì)產(chǎn)生較少的偽標(biāo)簽噪聲,從而能有效地抑制因跨相機(jī)采集圖像而帶來的偽標(biāo)簽噪聲問題,該觀點(diǎn)會(huì)在后續(xù)的消融實(shí)驗(yàn)中得到驗(yàn)證。
基于此,對所有的訓(xùn)練樣本進(jìn)行二次聚類。在每個(gè)epoch 訓(xùn)練的開始,對所有的圖片進(jìn)行圖片增強(qiáng)然后輸入到基礎(chǔ)網(wǎng)絡(luò)中去提取所有的特征向量,然后對得到的特征進(jìn)行二次聚類,如圖3 所示:首先進(jìn)行一次聚類(primary clustering)得到相機(jī)偽標(biāo)簽ID,再根據(jù)相機(jī)ID對同一個(gè)相機(jī)內(nèi)的所有圖片特征進(jìn)行二次聚類(quadratic clustering)得到行人偽標(biāo)簽ID。

圖3 相機(jī)ID聚類與行人ID聚類Fig.3 Camera ID clustering and person ID clustering
針對相機(jī)內(nèi)的一次聚類,采用了k-means 聚類算法,選擇的原因是行人重識別系統(tǒng)無論是在真實(shí)環(huán)境中應(yīng)用還是數(shù)據(jù)集測驗(yàn),采集數(shù)據(jù)的相機(jī)個(gè)數(shù)是已知的,而k-means算法需要初始化k個(gè)聚類中心,這與本文的要求相符,其具體過程為給定數(shù)據(jù)樣本,包含了n個(gè)對象其中每個(gè)對象都具有m個(gè)維度的屬性。k-means 算法的目標(biāo)是將n個(gè)對象依據(jù)對象間的相似性聚集到指定的k個(gè)類簇中。每個(gè)對象屬于且僅屬于一個(gè)其到類簇中心距離最小的類簇中,然后通過計(jì)算每一個(gè)對象到每一個(gè)聚類中心的歐式距離,如下式所示:
式中,Xi表示第i個(gè)對象,Cj表示第j個(gè)聚類的中心,Xit表示第i個(gè)對象的第t個(gè)屬性。Cjt表示第j個(gè)聚類中心的第t個(gè)屬性。依次比較每一個(gè)對象到每一個(gè)聚類中心的距離,將對象分配到距離最近的聚類中心的類簇中,得到k個(gè)類簇,類簇中心就是類簇內(nèi)所有對象在各個(gè)維度的均值,其計(jì)算公式如下:
式中,Cl表示第l個(gè)聚類的中心,Sl表示第l個(gè)聚類簇中對象的個(gè)數(shù),Xi表示第l個(gè)類簇中第i個(gè)對象。算法的主要流程可以簡化為兩步:計(jì)算每一個(gè)對象到類簇中心的距離,依據(jù)類簇內(nèi)的對象計(jì)算新的簇類中心。
根據(jù)一次聚類得到的相機(jī)ID 偽標(biāo)簽結(jié)果,對每個(gè)相機(jī)ID 內(nèi)的圖片特征用DBSCAN 進(jìn)行輪巡二次聚類,為了防止同一目標(biāo)在不同相機(jī)中聚類ID不一致的情況,可采取以下兩種解決方案:(1)采取漸進(jìn)式策略,前20 epoch采用單次聚類,后40 epoch采用二次聚類,并且其更新memory dictionary 的特征系數(shù)為0.01。可一定程度地避免少量目標(biāo)在不同相機(jī)中聚類ID不一致所帶來的準(zhǔn)確率影響。(2)對模型進(jìn)行微調(diào),更改聚類順序,即先進(jìn)性全局聚類得到行人偽標(biāo)簽ID,后進(jìn)行二次聚類得到相機(jī)偽標(biāo)簽ID,從根源上解決目標(biāo)在不同相機(jī)中聚類ID 不一致的情況。經(jīng)過實(shí)驗(yàn)驗(yàn)證比較,本文在后續(xù)實(shí)驗(yàn)中采用方案1。
DBSCAN算法需要兩個(gè)超參數(shù),一個(gè)參數(shù)為聚類的相鄰樣本間最大距離x,其表示聚類中的邊界點(diǎn)與聚類核心Core point的最大距離;另外一個(gè)參數(shù)min samples是鄰域中最小的樣本個(gè)數(shù),若聚類簇心中的樣本值小于min samples,則識別為噪聲數(shù)據(jù)或異常值。在本文的實(shí)驗(yàn)中,分別將x設(shè)置為0.4,min samples設(shè)置為4。通過二次聚類,可以將聚類得到的結(jié)果分配給每個(gè)將要訓(xùn)練的圖片作為行人ID偽標(biāo)簽。
所有特征在經(jīng)過GQCM 模塊后,將得到的相機(jī)偽標(biāo)簽ID和行人偽標(biāo)簽ID傳輸?shù)絊LM模塊,進(jìn)行下一步處理。
2.3 基于聚類結(jié)果的有監(jiān)督學(xué)習(xí)模塊(SLM)
每個(gè)聚類中的實(shí)例數(shù)量不平衡,這是由數(shù)據(jù)集本身的數(shù)據(jù)分布特點(diǎn)和聚類算法的固有缺陷所帶來的客觀問題。針對該問題,本文所采用的解決方法是以聚類級特征[29]來做內(nèi)存字典的初始化與更新。基于聚類結(jié)果的有監(jiān)督學(xué)習(xí)模塊(SLM)的主要作用是基于偽標(biāo)簽下的有監(jiān)督學(xué)習(xí),該模塊的核心思想是,模塊采用聚類級實(shí)例來初始化和更新內(nèi)存字典,即在每個(gè)聚類的簇內(nèi)選擇一個(gè)特征作為該行人的ID樣本特征來初始化和更新內(nèi)存字典,基于此,使得實(shí)例少的聚類和實(shí)例多的聚類更新速率一致,避免模型在訓(xùn)練中偏向更新快的類別。
所謂聚類級實(shí)例,即每個(gè)聚類的簇內(nèi)選擇一個(gè)特征作為該行人的ID 樣本特征來初始化和更新內(nèi)存字典。關(guān)于同一個(gè)簇內(nèi)的樣本特征選擇問題,靈感來源于最難樣本挖掘[30],本文針對初始化和更新內(nèi)存字典采用了最難樣本選取,后文將做詳細(xì)介紹。
如圖4所示,針對同一相機(jī)下,在開始每個(gè)epoch訓(xùn)練前,將每個(gè)聚類級特征存入內(nèi)存字典對內(nèi)存字典進(jìn)行初始化,n代表的是聚類簇心的個(gè)數(shù)。由于網(wǎng)絡(luò)是實(shí)時(shí)更新的,n會(huì)隨著網(wǎng)絡(luò)的不斷更新而變化最終區(qū)域穩(wěn)定。隨機(jī)選取n個(gè)聚類級特征來初始化內(nèi)存字典,也就是從每個(gè)聚類的簇中隨機(jī)選一個(gè)特征作為該行人ID的對應(yīng)的內(nèi)存字典。也可以選擇離簇心最遠(yuǎn)的N個(gè)聚類特征樣本來更新內(nèi)存字典,但是在后續(xù)的實(shí)驗(yàn)中發(fā)現(xiàn)這樣并不會(huì)帶來準(zhǔn)確率的提高,為了方便起見,本文選擇隨機(jī)選取,公式如下:

圖4 有監(jiān)督學(xué)習(xí)模塊Fig.4 Supervised learning module
其中,U是一個(gè)簡單的選擇函數(shù),而Xi則表示第i個(gè)聚類中所有特征樣本,Ci表示內(nèi)存字典中對應(yīng)的行人ID特征。
在每個(gè)mini batch 開始前,選擇P個(gè)人員身份,每個(gè)身份選取K張樣本,就可以獲得一個(gè)P×K總共為q的查詢樣本(query images)圖片,將增強(qiáng)過后的訓(xùn)練圖片數(shù)據(jù)輸入進(jìn)基礎(chǔ)網(wǎng)絡(luò)就可以得到q個(gè)實(shí)例樣本的特征,此時(shí)使用InfoNCE loss[31]將其與內(nèi)存字典中的所有集群特征進(jìn)行比較,計(jì)算出對比損失,其計(jì)算過程如下:
其中,s為輸入樣本特征,c+為內(nèi)存字典中的正樣本特征,ci為內(nèi)存字典中的負(fù)樣本特征,當(dāng)s與其正樣本特征相似且與其他負(fù)樣本不相似時(shí),損失值較低。通俗地說,該損失函數(shù)在模擬的空間中會(huì)無限地拉近s的正樣本并推遠(yuǎn)s的負(fù)樣本,使得網(wǎng)絡(luò)朝目標(biāo)方向收斂。
在每個(gè)mini batch結(jié)束前,從n個(gè)行人身份中選擇n張最難實(shí)例樣本來動(dòng)量更新內(nèi)存字典。具體地來說,每個(gè)行人ID 都對應(yīng)K張照片,從K張照片中選取一張照片作為最難實(shí)例樣本來更新內(nèi)存字典,更新過程如下:
ci如公式(3)所示,其含義相同。m是滑動(dòng)平均更新參數(shù),qdif是張圖片中的一張最難樣本,也就是在一個(gè)聚類中與聚心特征相似度最小的樣本特征。
3 實(shí)驗(yàn)結(jié)果
3.1 數(shù)據(jù)集與評價(jià)方式
在四個(gè)常用的行人重識別數(shù)據(jù)集上評估了本文方法,分別為Market-1501[23]、DukeMTMC-ReID[24]、MSMT17[32]和PersonX[33]。同時(shí)為了證明本文模型的泛化能力,在一個(gè)常用的車輛重識別數(shù)據(jù)集VeRi-77[34]進(jìn)行了實(shí)驗(yàn)。其具體信息如表1所示。

表1 數(shù)據(jù)集基本信息統(tǒng)計(jì)Table 1 Basic statistics of datasets
對于上述數(shù)據(jù)集,本文采用mAP 和rank 1/5/10 的精度進(jìn)行評估。
3.2 實(shí)驗(yàn)細(xì)節(jié)
本文實(shí)驗(yàn)使用在ImageNet[35]上預(yù)訓(xùn)練ResNet-50作為骨干來提取特征,其所用到的ResNet-50 核心層主要用到5個(gè)卷積層,第一個(gè)卷積層的輸出為112×112,其內(nèi)部配置為7×7 大小的卷積核,所設(shè)的步長為2。同時(shí)使用SGD 用于優(yōu)化模型。ResNet-50 基本層的學(xué)習(xí)率為0.000 5[36],其他層的學(xué)習(xí)率為0.005。
與DBSCAN 論文中闡述的聚類方法一樣,使用DBSCAN和杰卡德距離(Jaccard distance)與鄰近的k個(gè)樣本特征進(jìn)行聚類,在使用中選擇k=30。對于DBSCAN中的超參數(shù),兩個(gè)樣本之間的最大距離設(shè)置為0.4,聚類簇中的最小樣本數(shù)設(shè)置為4。
本文所提出框架的實(shí)驗(yàn)平臺是基于RTX 2080Ti(顯存11 GB),算力為54.1 MH/s對應(yīng)功耗180 W。因考慮到跨相機(jī)間圖像風(fēng)格不一致的問題,本文所提出方法需對全局圖像進(jìn)行二次聚類,與傳統(tǒng)單次聚類的無監(jiān)督行人重識別方法相比,其算法復(fù)雜度有所增加。具體表現(xiàn)為,從空間復(fù)雜度上來看:單次聚類與二次聚類,顯卡顯存占用無明顯波動(dòng);從時(shí)間復(fù)雜度上來看:單次聚類每個(gè)epoch時(shí)間為32 min,而本文所提方法為47 min,時(shí)間多數(shù)消耗在二次聚類上即GQCM模塊。
3.3 與當(dāng)前最先進(jìn)的方法比較
將本文方法與Market-1501、DukeMTMC-ReID、MSMT17、PersonX 和VeRi-776 上最近的USL 方法進(jìn)行了比較,包括IICS[8]、ACT[17]、JNL[9]等方法。表2顯示了本文提出的框架與近些年其他的方法在Market-1501 與DukeMTMC-ReID數(shù)據(jù)集上的比較結(jié)果。表中的Source列表項(xiàng)用來區(qū)分該方法是USL方法還是UDA方法。
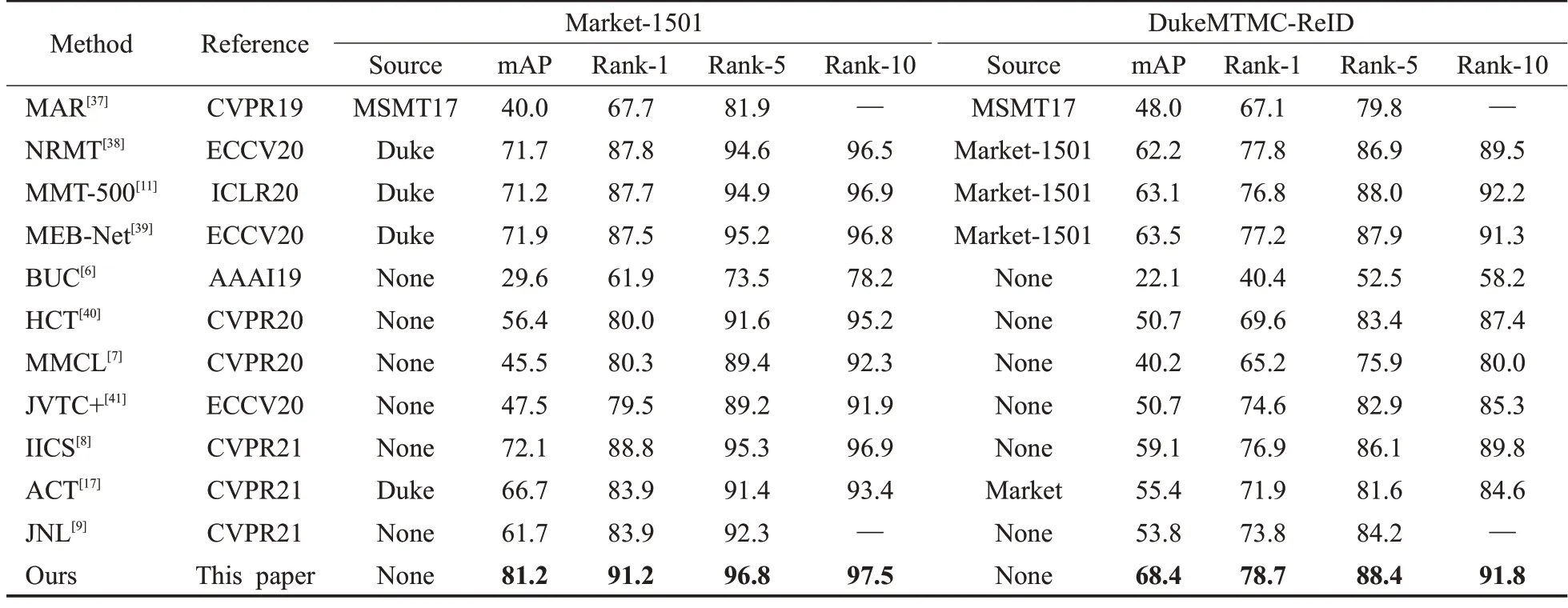
表2 與Market-1501和DukeMTMC-ReID數(shù)據(jù)集的性能比較Table 2 Performance comparison on Market-1501 and DukeMTMC-ReID datasets 單位:%
結(jié)果如表2所示,不僅將本文方法與傳統(tǒng)的USL方法進(jìn)行了比較,也與近期的一些UDA方法進(jìn)行了比較,由于UDA方法使用了額外的有標(biāo)簽數(shù)據(jù)進(jìn)行源域的訓(xùn)練,在大多數(shù)情況下,UDA方法比USl方法表現(xiàn)得要好,然而,本文提出的USL 方法卻超越了這些UDA 方法。在Market-1501數(shù)據(jù)集上,本文方法取得了mAP=81.2%和rank-1=91.2%的準(zhǔn)確率,在DukeMTMC-ReID 數(shù)據(jù)集上,本文方法取得了mAP=68.4%和rank-1=78.7%的準(zhǔn)確率,當(dāng)前最先進(jìn)的方法較分別提高了2.4和1.8個(gè)百分點(diǎn)的rank-1準(zhǔn)確率。
上述實(shí)驗(yàn)證明本文所提出的方法在很大程度上優(yōu)于當(dāng)前最先進(jìn)的方法,本文所提出的方法實(shí)現(xiàn)了當(dāng)前的最佳性能。這一顯著的改進(jìn)主要是由于本文方法考慮了不同相機(jī)間的成像風(fēng)格差異,有效地抑制了因聚類而產(chǎn)生的偽標(biāo)簽噪聲,并改進(jìn)了內(nèi)存字典的初始化與更新方式。
為了進(jìn)一步驗(yàn)證本文所提出方法的有效性,在一個(gè)更大、更具挑戰(zhàn)性的數(shù)據(jù)集MSMT17 和一個(gè)較為小眾的數(shù)據(jù)集PersonX上進(jìn)行了實(shí)驗(yàn)。令人感到驚喜的是,所提出的方法在這些數(shù)據(jù)集上表現(xiàn)依舊穩(wěn)定,如表3、表4所示:在MSMT17和PersonX上,所提出的方法分別完成了mAP=31.1%,rank-1=60.4%的準(zhǔn)確率和mAP=88.3%,rank-1=93.6%的準(zhǔn)確率,與當(dāng)前最先進(jìn)的方法較分別提高了6.0 和2.5 個(gè)百分點(diǎn)。上述實(shí)驗(yàn)清楚地證明了所提出方法的優(yōu)越性能。

表3 與MSMT17數(shù)據(jù)集的性能比較Table 3 Performance comparison on MSMT17 單位:%

表4 與PersonX數(shù)據(jù)集的性能比較Table 4 Performance comparison on PersonX 單位:%
同時(shí)為了證明所提出模型的泛化能力,在一個(gè)車輛重識別的數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),如表5所示,在VeRi-776上,mAP=68.4%和rank-1=78.7%的準(zhǔn)確率,其實(shí)驗(yàn)結(jié)果表明所提出的方法同樣可適用于車輛重識別任務(wù)中。

表5 與VeRi-776數(shù)據(jù)集的性能比較。Table 5 Performance comparison on VeRi-776 單位:%
3.4 消融實(shí)驗(yàn)
本節(jié)在Market-1501上進(jìn)行了消融實(shí)驗(yàn)來研究本文所提出的基于全局的二次聚類模塊(GQCM)與基于聚類結(jié)果的有監(jiān)督學(xué)習(xí)模塊(SLM)對實(shí)驗(yàn)結(jié)果的影響,同時(shí)驗(yàn)證不同的內(nèi)存字典初始化與更新機(jī)制對結(jié)果的影響,以全面衡量所提出方法的性能。
3.4.1 模塊間消融實(shí)驗(yàn)
如前文中所提到,本文所提出的網(wǎng)絡(luò)框架主要由兩個(gè)模塊組成:GQCM 模塊與SLM 模塊。全局圖片特征經(jīng)過GQCM模塊得到了以相機(jī)為分類的帶有行人ID偽標(biāo)簽的圖片特征,就可以有效的解決因跨相機(jī)成像風(fēng)格不統(tǒng)一而帶來的聚類偽標(biāo)簽噪聲問題。最后,GQCM模塊將帶有偽標(biāo)簽的圖片特征傳遞給SLM 模塊,供其利用該偽標(biāo)簽做有監(jiān)督學(xué)習(xí)。
為了證明本文所提出的網(wǎng)絡(luò)框架可以有效地降低偽標(biāo)簽噪聲對結(jié)果的影響,設(shè)計(jì)實(shí)驗(yàn)如下:實(shí)驗(yàn)中分兩次進(jìn)行,第一次實(shí)驗(yàn)中使用單次聚類只生成行人ID 偽標(biāo)簽,即只使用SLM 模塊。第二次實(shí)驗(yàn)即使用完整的網(wǎng)絡(luò)框架即生成相機(jī)ID 偽標(biāo)簽又生成行人ID 偽標(biāo)簽,即使用GQCM 模塊+SLM 模塊,結(jié)果如表6 所示,其mAP和rank-1分別提高了2.1和2.8個(gè)百分點(diǎn)。

表6 模塊間消融實(shí)驗(yàn)Table 6 Inter module ablation experiment 單位:%
為了進(jìn)一步說明所提出的網(wǎng)絡(luò)框架對偽標(biāo)簽噪聲有很好的抑制效果,從Market-1501 數(shù)據(jù)集中隨機(jī)選擇10張訓(xùn)練集樣本進(jìn)行聚類實(shí)驗(yàn),實(shí)驗(yàn)過程如下:第一次實(shí)驗(yàn)中使用單次聚類,第二次實(shí)驗(yàn)即使用完整的網(wǎng)絡(luò)框架進(jìn)行二次聚類,既生成相機(jī)ID 偽標(biāo)簽又生成行人ID偽標(biāo)簽,如圖5所示,該圖中,藍(lán)色條狀圖代表單次聚類結(jié)果中,正確的偽標(biāo)簽數(shù)量。而紅色的條狀圖則表示使用本文所提出的網(wǎng)絡(luò)框架進(jìn)行二次聚類所得到的正確結(jié)果數(shù)量。從實(shí)驗(yàn)結(jié)果看,本文所提出的二次聚類模塊可大幅度提高聚類偽標(biāo)簽生成的準(zhǔn)確率。
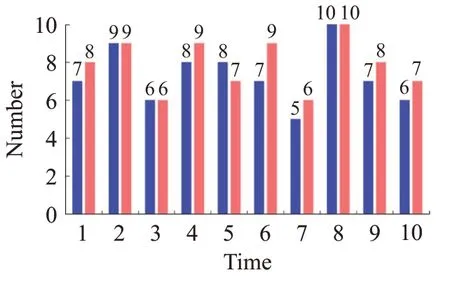
圖5 單次聚類與二次聚類的結(jié)果對比Fig.5 Comparison of results between single clustering and double clustering
從上述實(shí)驗(yàn)結(jié)果可知,GQCM模塊對樣本特征進(jìn)行二次聚類確實(shí)可以有效地降低偽標(biāo)簽噪聲對結(jié)果的影響,從而使得準(zhǔn)確率進(jìn)一步提高。
3.4.2 內(nèi)存字典的更新機(jī)制
SLM 模塊采用聚類特征為基準(zhǔn)來初始化與更新內(nèi)存字典,其目的防止網(wǎng)絡(luò)訓(xùn)練偏向?qū)嵗龜?shù)目較大的聚類從而影響模型最終的準(zhǔn)確率。為了進(jìn)一步探究SLM模塊對本文網(wǎng)絡(luò)框架影響,消融實(shí)驗(yàn)設(shè)計(jì)如下,分別以常規(guī)的實(shí)例級特征和SLM模塊的聚類級特征更新初始化內(nèi)存字典,其結(jié)果如表7所示。

表7 不同的更新機(jī)制比較Table 7 Performance comparison on PersonX 單位:%
實(shí)驗(yàn)結(jié)果表明,SLM模塊的聚類級特征,即每個(gè)聚類的簇內(nèi)選擇一個(gè)特征作為該行人的ID樣本特征來初始化和更新內(nèi)存字典,可以有效地提高網(wǎng)絡(luò)的準(zhǔn)確率。
4 結(jié)論
本文提出了一種基于二次聚類的無監(jiān)督行人重識別框架,該框架采用了二次聚類模塊來抑制因跨相機(jī)采集數(shù)據(jù)而帶來的偽標(biāo)簽噪聲問題,并在內(nèi)存字典的更新初始化機(jī)制上做出改進(jìn)。證明該框架可解決跨相機(jī)采集數(shù)據(jù)而帶來的偽標(biāo)簽噪聲問題,通過大量實(shí)驗(yàn)并在多個(gè)數(shù)據(jù)集上驗(yàn)證表明,本文方法在無監(jiān)督行人重識別研究中的有效性。
猜你喜歡
人大建設(shè)(2020年4期)2020-09-21 03:39:12
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
人大建設(shè)(2017年2期)2017-07-21 10:59:25
人大建設(shè)(2017年9期)2017-02-03 02:53:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
浙江人大(2014年4期)2014-03-20 16:20:16
