基于機器視覺的煤礦巷道人員定位研究
2024-01-25 02:47:22劉世平王利軍
礦山機械 2024年1期
王 端,劉世平,王利軍
國家能源神東煤炭公司烏蘭木倫煤礦 內蒙古鄂爾多斯 017200
煤 礦智能化是煤炭行業實現智能、高效開采的必由之路,煤礦井下人員的精確定位是煤礦安全生產的重要保障[1]。我國的煤礦開采方式多為井工開采,煤礦巷道內廣泛存在大量可燃性氣體及煤塵,成為制約煤礦人員定位問題的一大技術瓶頸。
近年來,國內外專家學者針對煤礦巷道人員識別、定位方法進行了大量的研究。郭瑜[2]研究了基于智能手機系統平臺和 ZigBee 技術的人員定位系統,提升了人員定位系統的抗干擾能力;張海軍等人[3]設計了一種煤礦井下超寬帶 (UWB) 人員定位系統,采用一種聯合定位算法解算標簽位置坐標,提高了定位精度;李勝利等人[4]使用卡爾曼濾波方法改進超寬帶定位系統,提升了在視距和非視距條件下的定位精度;李東輝[5]利用無線網絡對礦井骨干網絡進行部署,實現了井下人員的精確定位。其中,基于射頻卡的人員定位技術[6]是目前井下應用最廣泛的技術,其原理為通過巷道內大量布置的讀卡設備讀取作業人員攜帶的射頻卡,但無法測距及精確定位;基于移動網絡、WiFi 的人員定位技術[7-9],測距誤差較大,難以實現精確定位;超寬帶技術定位精度雖可精確至厘米級,但現有的 UWB 定位卡設備成本較高[10-11],并未在井下得到應用。
為進一步改善針對煤礦巷道內人員精確定位問題[12-14],筆者重點研究了 YOLOv5 目標檢測算法,并提出了一種基于改進 YOLOv5 的煤礦巷道人員定位模型。通過自制的巷道人員數據集訓練井下人員識別模型,利用 SE 注意力機制提升模型對人員的感知程度,結合雙目深度相機捕捉人員相對相機的三維坐標,最后將訓練得到的模型應用于巷道人員定位。
1 基于機器視覺的人員定位方法
1.1 人員智能識別與定位流程
煤礦巷道人員智能識別與定位流程如圖1 所示。首先,使用 Python 程序對巷道內人員活動視頻圖像進行切片處理,在 Anaconda 虛擬環境下通過標注軟件 LabelMe 對人員圖像進行逐張標注,并通過數據增強技術豐富原始人員數據集;然后,在目標檢測 YOLOv5 框架的有效特征層中加入 SE 注意力機制模塊,得到 SE-YOLOv5 模型;最后,利用 SEYOLOv5 模型在人員定位測試集中對人員進行識別,通過坐標轉化公式對雙目相機獲得的人員深度值進行求解,得到人員中心點相對相機的三維坐標。
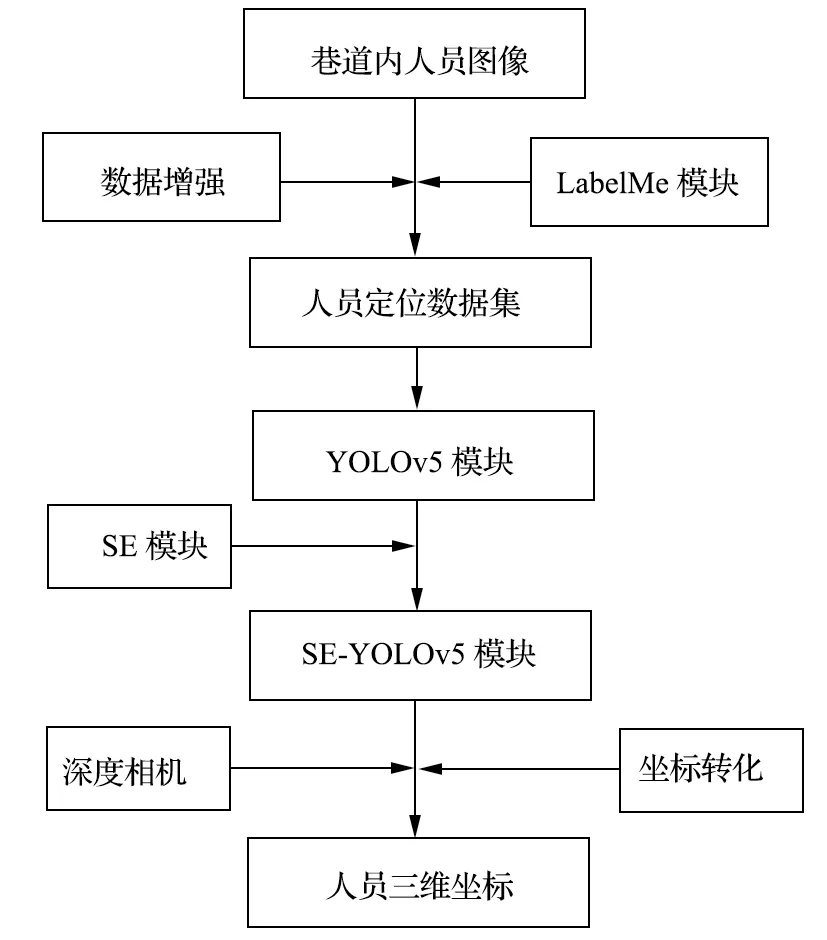
圖1 煤礦巷道人員智能識別與定位流程Fig.1 Intelligent identification and positioning process for personnel in coal mine roadway
1.2 SE-YOLOv5 模型構建
1.2.1 SE 模塊融入設計
由于煤礦巷道內存在大量煤粉和水霧,導致人員圖像分辨率不高、模糊不清,且巷道內環境復雜,在卷積神經網絡計算過程中易丟失人員的圖像信息,導致人員檢測效果不佳。為提升人員圖像信息在整張圖像信息中的關注度,降低特征圖的通道數以增大模型對圖像的整體感受視野,筆者使用 SE 注意力機制增加網絡對通道權重數值的學習,然后將學習的結果重新賦值給原先的特征通道,最終有效解決了由于圖像特征圖和通道數的比例不同給模型計算過程產生的損失問題。
注意力機制可以增強有效特征信息,抑制無效信息,有效提升神經網絡的檢測性能。SE 注意力機制自動學習圖像特征權重,具備“即插即用”的優良性質,其結構如圖2 所示。
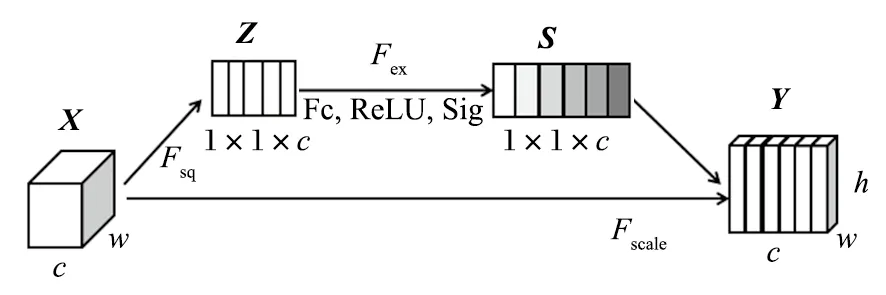
圖2 SE 模塊結構Fig.2 SE module structure
圖2 中,X、Y表示特征圖的輸入和輸出;c、h、w分別代表通道數和高、寬。該模塊由 3 部分組成,分別是擠壓部分 (SQ 網絡)、激勵部分 (EX 網絡)、縮放網絡 (SCALE 網絡)。
其中,擠壓部分對特征圖輸入X做全局池化操作,得到一個具有感受圖像全局視野功能的 1×1×1的一維矩陣。在實際操作中,將 SE 模塊增添在卷積模塊之后,也就是第 2 個 C3 和第 3 個 C3 模塊之間,實現將不同的權重值賦給不同圖像特征層的目的;相對應地,在 SPP 層網絡之后也加入該 SE 注意力機制模塊,旨在強化融合后的全部特征。
1.2.2 YOLOv5 模型部署
YOLOv5 是目標檢測領域最流行的網絡,作為一種直接預測目標位置和類別的一階段算法,具有模型尺寸小、本地部署成本低、高精確度與靈活性的特點。其主要由輸入網絡、特征提取網絡、特征融合網絡、輸出網絡組成。經 YOLOv4 發展而來,YOLOv5具備以下進步點:輸入網絡內采用 Mosaic 方式簡化特征尺寸為 640×640×3 的 RGB 圖像,錨框機制通過重復迭代更新,能夠更快找到錨框的最佳數值;特征提取網絡是由卷積模塊 Conv、C3、SPFF 等模塊組成的 CSPDarknet53 網絡、Focus 網絡對圖像進行切片操作,可有效減少運算過程的參數值,提升了運算速度完成不同池化層的圖像特征提取;特征融合部分沿用 YOLOv4 的 FPN+PAN 的特征融合方式,結合兩個方向的檢測層進行參數加聚操作,有效提高了密集目標場景下的檢測效果,并將融合后的目標圖像特征輸入輸出網絡;輸出網絡的輸出結果包含目標的位置、類別和置信度,可實現 80×80、40×40、20×20 不同尺度目標的位置預測。與 YOLOv4 相比,YOLOv5 更適用于煤礦井下的部署應用。因此,選擇 YOLOv5 作為煤礦巷道人員定位的基礎算法。SE-YOLOv5 模型結構如圖3 所示。
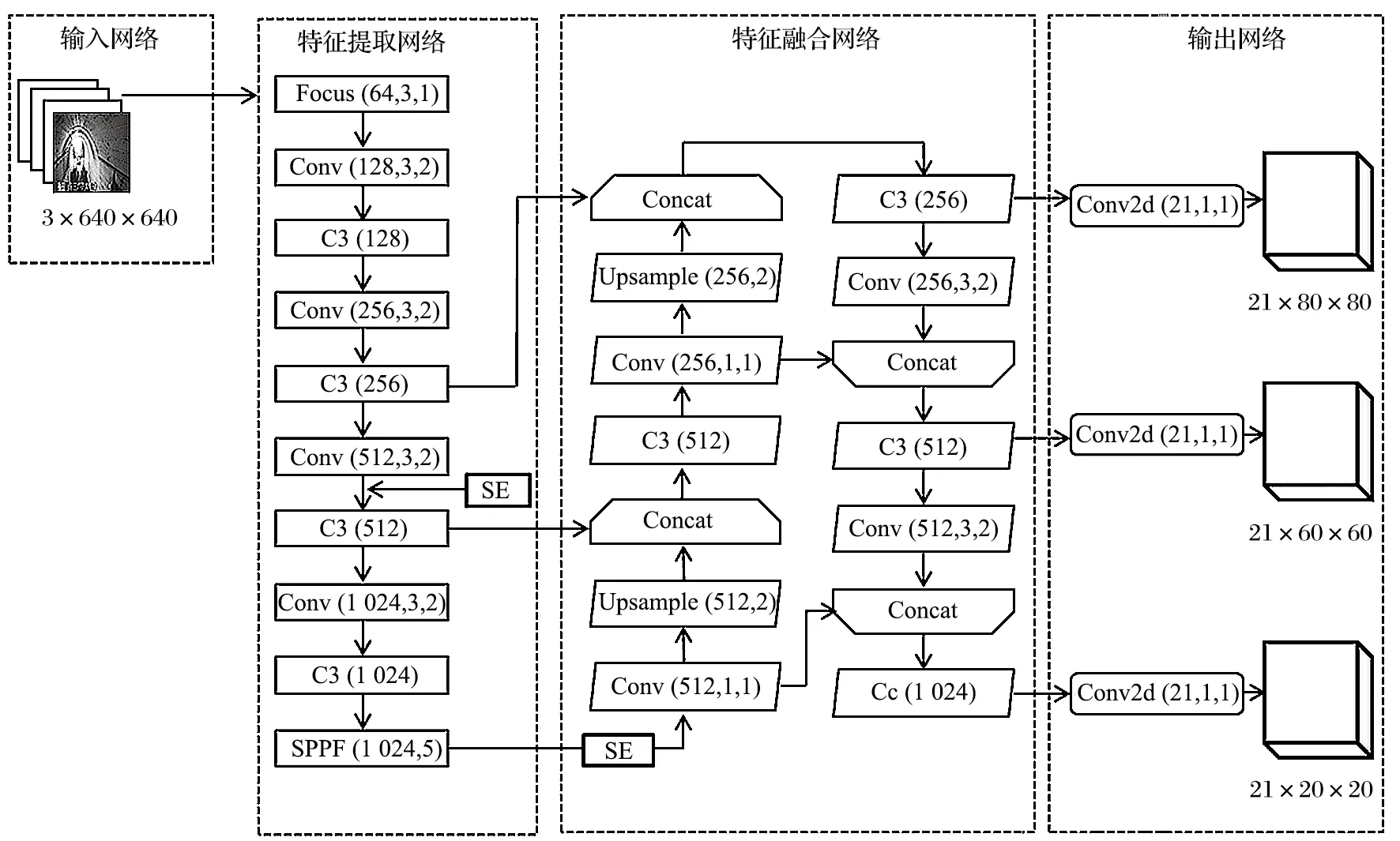
圖3 SE-YOLOv5 網絡結構Fig.3 SE-YOLOv5 network structure
2 基于機器視覺的人員定位方法
2.1 數據集構建
利用巷道內布置的監控攝像頭獲取到巷道內人員圖像,在 Anaconda 虛擬環境下使用 LabelMe 標注軟件對人員圖像進行逐張標注,并命名為 person,得到包含有人員位置的 json 格式文件,再通過格式轉化程序得到適用于 YOLOv5 的 txt 格式輸入文件。通過數據增強操作對巷道人員圖像進行縮放、剪切、旋轉等物理操作,可有效擴充數據集內圖像數量,進而提升模型的綜合性能。選取包含 1 200 張巷道人員的數據集,按照 7∶3 劃分為訓練集和測試集。數據增強效果圖如圖4 所示。

圖4 數據增強效果Fig.4 Data enhancement effect
試驗模型訓練、測試使用的硬件環境為 Intel(R)Core(TM) i7-9750H CPU@2.60 GHz 處理器、NVIDIAGTX 1660Ti 顯卡;軟件環境為 Windows 操作系統下 Pytorch1.8.1 深度學習框架。模型訓練過程中,學習率設置為 0.000 01,批尺寸為 16,迭代次數為 300。
2.2 模型評價指標
采用目標檢測領域的精確率P、召回率R、FPS作為模型性能的評價指標,原始的 YOLOv5 模型與筆者提出的 SE-YOLOv5 模型檢測性能對比情況如表1所列。其中,精確率表征模型的分類能力;召回率表征模型對待檢測目標的檢測能力;FPS為單位時間內圖像填充的幀數,表示模型的檢測速度。
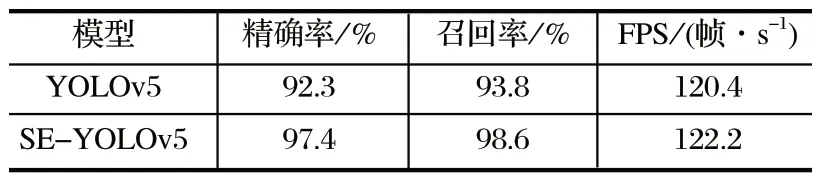
表1 模型改進前后性能對比Tab.1 Performance comparison before and after model improvement
式中:TP為正樣本被正確檢測出來的數目;FP為負樣本被檢測為正樣本的數目;FN為未被檢測出來的數目。
由表1 可以看出,SE-YOLOv5 模型相對于原始 YOLOv5 模型的精確率、召回率分別提高了 5.1、4.8 個百分點,檢測速度基本保持不變,說明 SEYOLOv5 模型改進方式能在不影響檢測速度的前提下有效提升檢測精確率。
2.3 模型效果驗證
為驗證 SE-YOLOv5 模型的人員檢測效果,利用改進前后的 2 種模型對測試數據集進行檢測試驗,選取部分檢測結果,如圖5 所示。

圖5 煤礦巷道人員檢測效果對比Fig.5 Comparison of personnel detection effects in coal mine roadway
由圖5 結果可知,原始 YOLOv5 算法存在有檢測人員失敗、漏檢的情況,而 SE-YOLOv5 模型能夠檢測成功,并且具有較高的置信度。這是因為 SE 注意力機制模塊增強了圖像內目標人員在整張圖像內的像素占比,且提升了人員圖像的特征信息,受到更多的關注,在一定程度上可以避免漏檢、錯檢的情況。
3 應用效果
為驗證 SE-YOLOv5 模型的實際應用效果,將煤礦巷道內的攝像頭 IP 作為程序輸入,進行實時檢測。基于機器視覺 SE-YOLOv5 模型的煤礦巷道人員定位系統如圖6 所示。利用 PyQt 編程語言編寫煤礦巷道人員定位系統交互界面,設置提前訓練好的人員定位模型作為權重文件,固定 IP 的攝像頭視頻流作為輸入,具備手動調節模型、信號輸入、置信度以及檢測前后的對比顯示功能。當成功檢測到人員后,通過坐標轉化公式求解出 person 區域中心點相對于深度相機的三維坐標。巷道人員定位坐標如表2 所列。
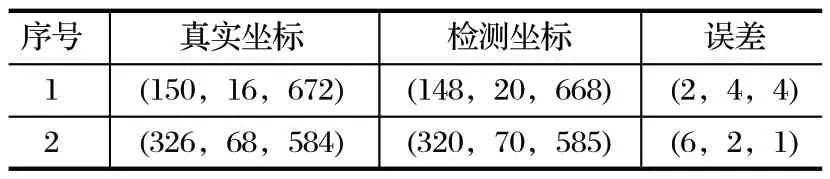
表2 煤礦巷道人員定位坐標對比Tab.2 Comparison of personnel positioning coordinates in coal mine roadway
4 結論
(1) 在原始機器視覺 YOLOv5 框架的卷積模塊之后加入了注意力機制 SE 模塊,有效解決了巷道內復雜背景、人員被遮擋條件下圖像特征信息丟失的問題。
(2) 相較于 YOLOv5 模型,SE-YOLOv5 模型的精確率提升了 5.1 個百分點,具有更高的檢測能力。
(3) 將改進后得到的 SE-YOLOv5 部署于煤礦巷道人員定位系統中,能夠快速識別人員,并且能夠顯示計算后人員相對于相機的三維坐標。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
工業設計(2016年4期)2016-05-04 04:00:23
現代企業(2015年8期)2015-02-28 18:55:34
現代企業(2015年6期)2015-02-28 18:51:50
