基于集群信息熵的分布式網絡入侵數據自主防御方法*
2024-01-25 12:15:40趙可英
寶雞文理學院學報(自然科學版) 2023年4期
牟 凱,趙可英
(1.四川商務職業學院 實踐教學中心(信息中心),四川 成都 611131;2.內江師范學院 數學與信息科學學院,四川 內江 641100)
分布式網絡由于自身的局限性以及開放性等特征,導致遭受攻擊的現象頻繁發生。盡管當前針對網絡攻擊的檢測以及防御研究已經積累了一定經驗,但是與之對應的攻擊方式也在不斷升級,因此,必須提出更加全面的防御模式,以應對層出不窮的網絡攻擊。隨著網絡攻擊技術不斷演進和復雜化,自主防御研究變得尤為關鍵。通過深入研究分布式網絡入侵的特點和方式,建立先進的威脅識別和防御系統,有助于提高網絡的安全性,保護重要數據免受不法分子的侵害。有學者基于彈性搜索,對網絡入侵數據防御控制展開研究,將探測器、中央處理器和存儲器應用于設計系統中,同時結合采用數據預處理器、入侵規則分析器進行輔助,并通過入侵警報模塊和節點控制模塊,實時監測網絡運行情況,實現對網絡入侵數據的自主防御控制[1]。還有研究人員通過隸屬度函數(Membership Function, MF)的預檢測方法檢測網絡流量數據的輕量級異常,采用深度學習(Deep Learning, DL)的神經網絡模型對異常數據流量進行高精度分類,基于隸屬函數檢測機制和深度學習檢測機制,設計了一種DDoS攻擊快速防御方法,并利用Anti-Fre響應算法實現流量定向阻斷,完成主動防御[2]。雖然上述方法能夠實現入侵數據的自主防御,但是在檢測出攻擊行為后,通常都是根據節點漏洞之間的關聯,匹配出對應的防御規則,從而展開防御響應,導致帶寬利用率較高。因此這種單向入侵檢測后再觸發主動防御屬性已經無法滿足當前網絡發展趨勢。
為解決上述方法的不足,本文基于集群信息熵,設計了一種分布式網絡入侵數據自主防御方法。集群信息熵作為有監督離散化算法中的重要組成部分,能夠集中體現出數據結構的混亂程度。對于入侵數據的檢測與自主防御具有重要作用。因此,在集群信息熵的推動下,研究分布式網絡入侵數據的自主防御方法具有較高的上升空間。
1 檢測分布式網絡攻擊行為
分布式網絡的攻擊行為檢測作為主動防御的基本依據,具有重要地位。由于在實際應用環境中,大部分攻擊代碼和攻擊手段都比較復雜,單一的檢測程序存在漏檢和誤檢的現象。因此,需要詳細描述攻擊手段的攻擊路徑以及帶來的危害。在僵尸網絡攻擊類型中,主要是利用服務器與多臺計算機之間的緊密聯系進行攻擊。而當主服務器的職責包括服務器和客戶端2種任務時,其被感染后的攻擊性會在原有基礎上升級。DDoS攻擊在發動攻擊之前,會先聯系主控制器,以獲取對應的用戶信息,并將正常訪問行為反饋給服務器。在這種情形下,服務器通常會采取利用域名變化隱藏IP地址的方式避免被封閉。在此環節引入馬爾科夫鏈算法,建立網絡攻擊行為規則庫。在已知分布式網絡攻擊樣本集的條件下,將歷史攻擊行為映射到同質馬爾科夫鏈中,則本次攻擊行為發生的條件概率數學公式如下:
(1)
其中,s表示攻擊行為樣本集,m表示前一次的攻擊行為,n表示當前攻擊行為。由此可知,分布式網絡攻擊行為具有一定的周期性。在掃描分布式網絡和相關設備的過程中,通常情況下檢測時間有限,無法實現理想化的檢測效果。因此,需要重新建立服務器域名,并適當減少逆向破解環節所消耗的時間。近年來,一次分布式網絡攻擊行為能夠成功模擬用戶正常訪問行為,并同步上傳有關信息。此外,勒索病毒網絡攻擊頻繁地出現在大眾視野中,這種攻擊行為能夠通過DNS查詢,采用公鑰加密文件的形式,對注冊表信息等文件進行破壞,導致無法正常讀取文件。在上述描述的基礎上,完成檢測分布式網絡攻擊行為的步驟。
2 基于集群信息熵提取流量特征貢獻度
集群信息熵作為機器學習算法中的重要體現,主要用于描述數據的概率分布。為了能夠快速明確分布式網絡流量數據集的特征,將分布式網絡入侵數據看作一個隨機事件。利用集群熵信息能夠總結出不同攻擊行為數據集概率分布的相似程度,并以此作為區分是否正常訪問行為的判斷依據。在能夠確定分類標簽的基礎上,描述主動防御方法中分類模式的熵,具體如下:
(2)
其中,V表示分布式網絡流量類別集合,E表示攻擊行為記錄標簽,u表示流量種類。同時,如果出現某項特征與流量類型的匹配度較高時,說明對于準確分類的關聯性較大。當攻擊行為的條件熵接近于0時,說明集群信息增益更趨近于1。此外,為了計算集群信息熵的增益值,必須充分考慮數據集中包含的連續性特征和離散性特征。受集群信息熵的性質約束,需要將數據集中的連續性特征進行離散化處理。當入侵數據的條件熵的不確定性降低之后,整個數據集的熵值也會隨之變小,這也說明流量特征的貢獻度趨于穩定[3-4]。而一旦整體分布情況基本固定,流量特征貢獻度即可等同于數據集的信息增益。以γ為流量特征,將其取值概率作為計算流量特征貢獻度的基礎數據,則γ的平均條件熵計算公式為:
(3)
其中,L表示樣本數,?表示數據集屬性,i表示i個取值。同時,根據集群信息熵的具體分裂點數量,定義分割后的數據集屬性,分別為二值離散數據和一階數據。
3 識別入侵數據多階段特征
在分布式網絡規模逐漸變大的背景下,一些入侵者無法直接連接到攻擊目標,可能會與實際情況有一定偏差。而在入侵數據逐漸接近攻擊目標的過程中,會伴隨著時間流逝呈現出不同的階段性特征。一旦入侵數據完成滲透攻擊環節,其破壞范圍則會隨之變大。入侵數據實時攻擊時,首要步驟就是掃描偵查現有的防御手段,然后制作攻擊武器,并鎖定目標發動攻擊。上述步驟皆屬于感染階段,作為發動攻擊的初始時期,入侵數據在該階段的主要目的就是建立相應的據點,通過定位并追蹤可利用的主機,對其投遞病毒進行入侵。接下來就進入了利用階段,具體表現為入侵數據的攻擊呈現出橫向滲透移動的特點。同時,在主機周圍持續探測目標,并利用存在的網絡漏洞,展開階段性滲透。最后對目標數據或者文件信息安裝植入病毒,對分布式網絡的通信及控制模塊發動攻擊,從而實現竊取數據資產的目的。同時,將該階段定義為具體損害階段,并且攻擊者主要是為了對敏感數據進行篡改和盜取。由此得出分布式網絡中入侵數據的階段感知表達公式:
Q=∑(R,Y)+max(γ→Y)
(4)
其中,R表示分布式網絡中的主機數量,Y表示當前滲透信息表。將(4)式作為高效準確感知入侵數據攻擊階段的已知條件,生成新的狀態轉移規則。
4 設計自主防御方法
在主動防御架構中,分布式網絡的域名服務日志包含了大部分的正常用戶訪問行為,在獲取用戶行為規律以及預測攻擊行為等方面具有更好的延伸效果。分布式網絡的動態IP地址聯動能夠以最簡單的方式將主動防御的流量導向新的客戶端中。在無防御場景中,一些分布式網絡主機的IP地址是固定的,且主機中不存在部署指紋偽裝主機的情況下,假設入侵數據有ε次掃描機會,在隨機掃描的場景中,如果入侵數據滿足超幾何分布,可以得出攻擊成功率的數學表達式為:
(5)
其中,φ表示分布式網絡中的地址跳變空間,T表示地址跳變狀態持續時間,λ表示每次掃描到主機的概率。從主動防御的角度出發,如果對應的地址跳變周期過小或者過大,都無法實現主動防御的最佳效果。因此,在分布式網絡正常運行的狀態下,保證主動防御狀態下的分布式網絡最小跳變間隔周期小于攻擊分析時間。在實際的主動防御場景中,可以采取主動指紋偽裝機制。為了避免流量牽引策略引起入侵數據的懷疑,將偽裝源IP地址的方法進行優化升級[7]。除了將防火墻設置在分布式網絡的內部和外部的中間地帶之外,還可以設置多個具有相同功能的訪問控制代理,以增強主動防御方法的抗攻擊能力。在此種布置下,入侵數據等攻擊者的識別概率可以表示為:
(6)
其中,σ表示入侵數據的初始攻擊能力,k表示入侵數據的學習能力線性系數,ψ表示指紋偽裝主機的相似系數。通過掌握入侵數據的攻擊能力,并對其攻擊時間進行預測,從而制定合理的主動防御策略。由于在實際網絡攻防過程中存在一定的不確定因素,因此,必須將分布式網絡中的數據加以離散化處理,直至符合集群信息熵的增益閾值。
5 仿真實驗
5.1 部署實驗環境
集群信息熵的開發工具為Python軟件,包括Mininet平臺、OpenvSwitch交換機和Ryu控制器,然后利用實驗工具搭建具體的SDN網絡拓撲。電腦的配置為:Windows10操作系統,CPU為Intel(R) Core(TM) i5-7500,內存為SamsungDDR4 4GB。并配置CPU為Intel(R) Core(TM) i5-7500,內存為DDR4 16GB,系統為Ubuntu 18.04 LTS的主機。
5.2 分析實驗結果
為了得出準確度較高的測試結果,采用基于彈性搜索的網絡入侵數據防御方法[1]和基于MF-DL的DDoS攻擊快速防御方法[2]與本文的分布式網絡入侵數據自主防御方法進行對比參照。由于帶寬利用率直接影響分布式網絡的性能,因此本次仿真實驗將帶寬利用率作為測試指標。而在實際場景中,過高的帶寬利用率會造成網絡堵塞,因此網絡帶寬利用率正常需保持在30%以下。3種網絡入侵數據自主防御方法的帶寬利用率越低,證明主動防御效果越好。分別測試在UDP Flood和U2R攻擊類型下3種方法的帶寬利用率變化,具體如圖1和圖2所示。
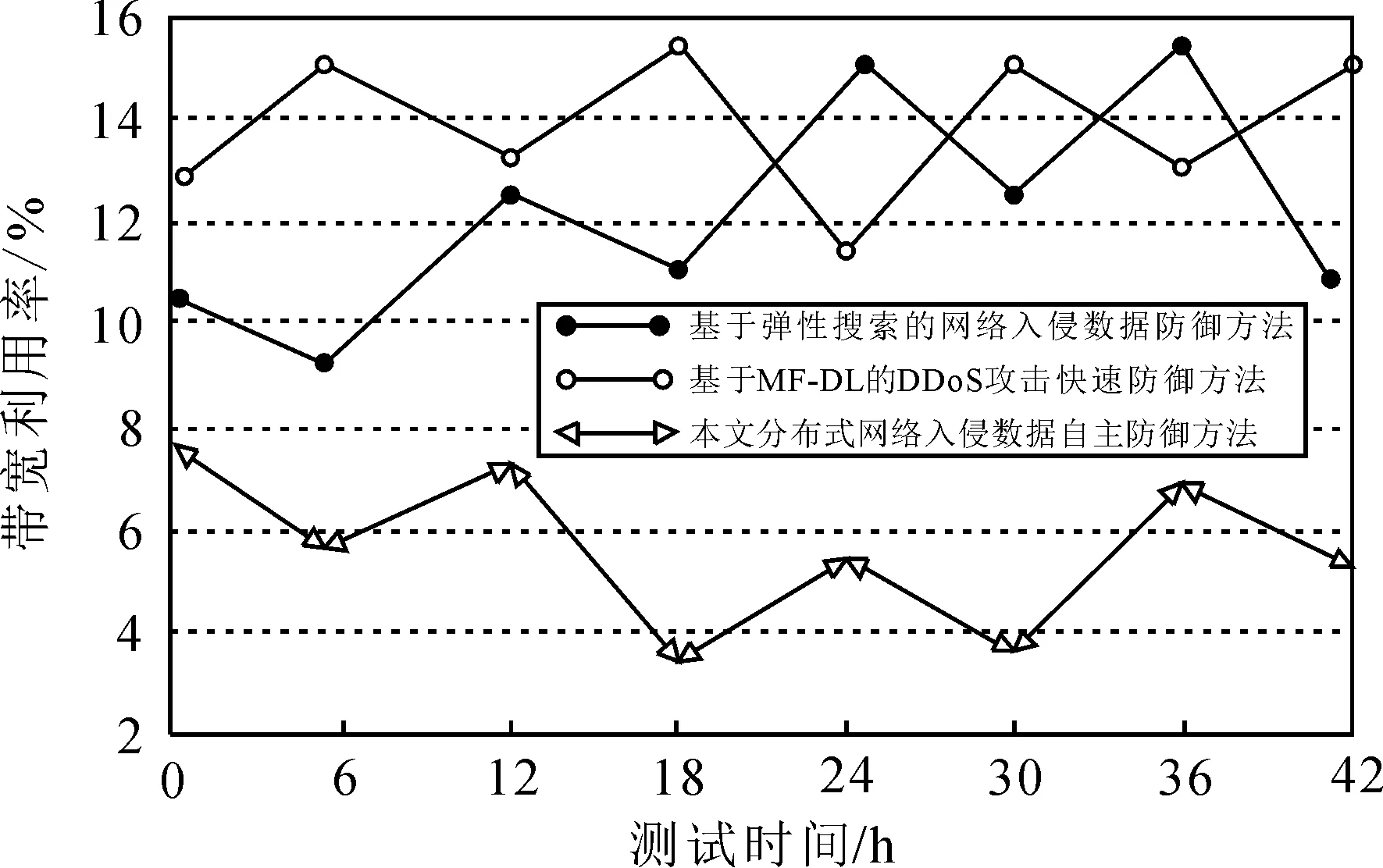
圖1 UDP Flood攻擊帶寬利用率Fig. 1 UDP Flood attack bandwidth utilization

圖2 U2R攻擊帶寬利用率Fig. 2 U2R attack bandwidth utilization
可以看出,UDP Flood攻擊相對來說比較容易檢測并采取防御措施,因此,整體帶寬利用率較低。而U2R攻擊類型隱蔽性則更強,3種網絡入侵數據自主防御方法的帶寬利用率均有所升高。
3種網絡入侵數據自主防御方法的帶寬利用率均值如表1所示。

表1 帶寬利用率均值/%Tab. 1 Average bandwidth utilization/%
根據表1可知,本文的分布式網絡入侵數據自主防御方法的帶寬利用率均值為14.276%,基于彈性搜索的網絡入侵數據防御方法的帶寬利用率均值為17.324%,基于MF-DL的DDoS攻擊快速防御方法的帶寬利用率均值為17.210%。本文設計方法的帶寬利用率低于對比方法,具有較好的自主防御效果,在實際應用中具有較好的性能。
6 結束語
為解決現有方法在入侵數據自主防御過程中存在帶寬利用率較高的不足,本文基于集群信息熵設計了一種分布式網絡入侵數據自主防御方法。對分布式網絡攻擊行為進行檢測,基于集群信息熵提取流量特征貢獻度并識別入侵數據多階段特征,通過主動指紋偽裝機制實現分布式網絡入侵數據自主防御。實驗證明,該方法的帶寬利用率較低,均值僅為14.276%,具有較好的應用性能。在未來的研究中還將重點關注入侵數據的更多類型,逐步完善設計方法,提高網絡的防護能力,保護網絡數據的安全性和完整性,為數據安全和關鍵信息資產的安全提供技術支持。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
