基于GRU-LSTM模型的云計算資源負載預測方法
2024-02-19 00:00:00周璇
中國新通信 2024年23期
關鍵詞:云計算


摘要:為解決傳統負載預測模型存在的精確度差、預測效率低等問題,提高負載預測的高效性和精確性,本文運用門控循環單元(Gated Recurrent Unit,GRU)和長短期記憶(Long-Short Term Memory,LSTM)網絡,設計了一種基于GRU-LSTM組合預測模型的云計算資源負載預測方法。首先,分析了云計算資源負載時間系列預測問題。其次,根據GRU、LSTM相關概念,完成了對基于GRU-LSTM的組合預測方法設計。最后,確定數據來源與處理,介紹了模型評價指標,并采用實驗分析的方式驗證了本文所提出的負載預測方法的有效性和可靠性。結果表明:本文所提出的負載預測方法具有均方誤差低、預測時間短等優勢,符合實際應用需求,可為后期類似預測方法的進一步優化提供有效依據和有益參考。
關鍵詞:GRU-LSTM模型;云計算;資源負載;預測方法
一、引言
云計算作為一種新型計算技術,綜合運用了參照虛擬化技術、網絡計算技術,增加了計算任務復雜度 [1]。這種云計算模式在具體應用中,需采用服務方式,借助互聯網向用戶提供數據資源、IT資源等,一定程度上降低了用戶的使用體驗。最近幾年,大量公司應用云計算模式完成云端部署和應用,從而增加了云數據中心的功耗波動幅度,不利于平衡后期云數據中心的資源利用率[2]。為解決以上問題,本文基于GRU-LSTM模型,設計一種新型的、先進的云計算資源負載預測方法。該方法有效繼承和發揚了GRU預測時間短、LSTM預測精確度高的優勢,可實現對云數據中心資源的最大化、平衡化利用。
二、云計算資源負載時間系列預測問題分析
(一)基于機器學習的時間序列預測方法
在基于機器學習的時間序列預測方法中,Khairalla等學者提出一種基于自回歸移動平均模型(Auto-Regression and Moving Average Model,ARIMA)與支持向量機(Support Vector Machine,SVM)的混合模型,運用該混合模型,可以有效預測金融時間序列,并將小波分解為若干個分量,從而實現對最終預測結果的重構。但是,該模型的預測精確度相對較低,需選用更好的數據平滑算法,對預測流程進行優化,以不斷提高最終預測結果的精確度。
三、基于GRU-LSTM模型的云計算資源負載預測方法設計
(一)LSTM模型
LSTM(長短期記憶網絡)是一種特殊的循環神經網絡(RNN),通過引入遺忘門、輸入門和輸出門三個控制單元,有效解決了傳統RNN在處理長序列數據時遇到的梯度消失和梯度爆炸問題。LSTM能夠捕捉序列數據中的長期依賴關系,適用于時間序列預測等任務[3]。在云計算資源負載預測中,LSTM模型憑借其強大的長期依賴捕捉能力,能夠準確分析歷史負載數據中的復雜模式和趨勢,從而提高預測的精確度。這對于資源調度和優化至關重要,有助于確保云計算服務的穩定性和高效性[4]。然而,LSTM模型也存在一些局限性。其復雜的結構導致參數數量較多,訓練過程相對耗時,對計算資源的要求較高。此外,當輸入序列過長或數據噪聲較大時,LSTM模型可能難以有效捕捉關鍵信息,影響預測效果。
(二)GRU模型
GRU(門控循環單元)模型是循環神經網絡(RNN)的一種變體,旨在解決傳統RNN在處理長序列數據時出現的梯度消失和梯度爆炸問題。GRU通過引入更新門和重置門兩個控制單元,有效地控制了信息的流動,使得模型能夠更好地捕捉序列數據中的長期依賴關系。同時,該模型憑借其簡潔的門控結構和較少的參數數量,顯著降低了模型的計算復雜度。這一特點使得GRU模型在預測時能夠迅速響應,提供近乎實時的預測結果,有效縮短預測時間。這對于需要快速調整資源分配以應對突發負載變化的云計算環境來說,具有極高的實用價值。盡管GRU模型在預測時間短方面表現出色,但其簡潔的結構也可能導致在捕捉復雜數據特征,尤其是長期依賴關系上存在一定的局限性。當云計算資源負載受到多種因素共同影響,且這些因素之間的時間滯后效應較長時,GRU模型可能難以準確捕捉這些長期依賴關系,從而影響預測的準確性[5]。
(三)GRU-LSTM組合預測模型
在基于GRU-LSTM模型的云計算資源負載預測方法中,GRU-LSTM組合預測模型結構設計采用了三層結構,旨在結合GRU與LSTM各自的優勢,以提高預測精度并縮短預測時間。具體來說,第一層采用GRU(門控循環單元)。GRU通過精簡的門控機制(更新門和重置門),有效減少了模型參數,使得訓練過程更加高效且易于收斂。這一層主要負責捕捉數據中的短期依賴關系,為后續層提供初步的特征提取。第二層和第三層則采用LSTM(長短期記憶網絡)。LSTM通過引入遺忘門、輸入門和輸出門,能夠更有效地捕捉數據中的長期依賴關系,緩解傳統RNN在長序列預測中容易出現的梯度消失或爆炸問題。這兩層結合LSTM參數多的優勢,進一步提升了模型的預測精度。在模型參數設置與優化策略方面,首先需要對數據集進行充分的預處理,包括缺失值處理、標準化等,以確保輸入數據的質量。隨后,通過隨機森林算法進行特征選擇,提取對預測結果影響顯著的特征,作為模型的輸入。在模型訓練過程中,需要調整多個超參數,如學習率、批大小、隱藏層大小等,以找到最優的參數組合。這通常可以通過交叉驗證、網格搜索或隨機搜索等方法來實現。此外,還可以引入正則化技術來防止模型過擬合,提高模型的泛化能力。最后,為了進一步提升模型的預測性能,可以考慮采用集成學習方法,將多個GRU-LSTM組合預測模型的預測結果進行組合,以獲得更加穩定和準確的預測結果。
四、基于GRU-LSTM模型的云計算資源負載預測方法驗證
(一)數據來源預處理
為驗證本文負載預測方法的有效性和可靠性,本文將阿里云平臺所公開的數據集“Cluster-trace-v2019”設置為本次實驗數據來源。該數據集真實有效地反映出5000臺機器在最近一周內的資源使用情況,數據記錄共3400條[7]。本次實驗將整個數據集劃分為兩類,一類是訓練集。訓練集中的數據占總數據量的70%;另一類是測試集。測試集中的數據占總數據量的30%。本研究從以下幾個方面入手,對數據集進行處理:1.缺失值處理。實驗人員運用均值填充法,結合原始數據集缺失率,對數據集進行缺失值舍棄或者填充。2.利用高效化收斂神經網絡,提高預測精確度。本研究運用歸一化方法,標準化處理3400個數據。3.特征選擇。在進行數據集特征選擇時,需從原始數據集特征中選出具有典型特征的數據子集,將數據維度降到最低,并進一步提高回歸模型構建性能。同時,運用隨機森林算法,深入分析數據集特征置換前后所對應的誤差值,并對各個數據庫所對應的特征重要程度進行打分。數據集特征重要程度得分越高,說明該數據集的特征重要程度越高。運用隨機森林算法,不僅可以確保各個數據集特征之間建立緊密的聯系,還能提高最終分析結果的精確度。所以,在進行數據集特征選擇時,實驗人員要優先選用森林隨機算法,在整個樣本數據的特征值中,CPU利用率和mem利用率的特征值得分最高,實驗樣本數據量所對應的負載值計算公式如下:
(三)實驗過程
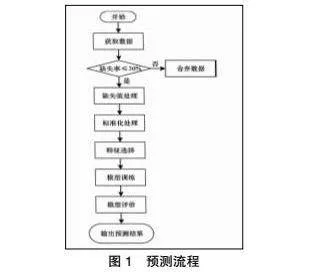
在本次實驗中,將GRU-LSTM模型設置為實驗組,將ARIMA模型、GRU模型、LSTM模型、Refined-LSTM模型、Stacked-LSTM模型、ARIMA-LSTM模型設置為對照組。不同模型預測流程如圖1所示。首先,獲取需要處理的原始數據,然后,結合原始數據缺失率對原始數據的缺失值進行補充和刪除。其次,運用隨機森林算法,從標準化處理后的大量數據特征中選出典型的特征。最后,運用以上五個評價指標,對模型最終預測結果進行評價[8]。
(四)實驗結果分析
本次實驗中,通過本文模型與ARIMA模型、GRU模型、LSTM模型等傳統模型進行實驗對比,獲得如圖2所示的不同模型負載預測結果及表1所示的模型指標評價結果。本文模型所獲得的預測結果均方誤差顯著降低(降低了6-9),同時,預測時間大幅縮短(縮短了10%左右),因此,本文模型具有預測精確度高、預測高效等特點,符合預期設計標準和要求。
五、結束語
綜上所述,本文基于GRU-LSTM模型,提出一套行之有效的云計算資源負載預測方法。運用GRU-LSTM模型,并采用實驗的方式,借助阿里云平臺公開的數據集,驗證GRU-LSTM模型的有效性和可靠性。
作者單位:周璇 廣州軟件學院
參考文獻
[1]胡應鋼,郭翔,趙海燕,等.基于粒子群優化GRU-RNN組合模型的云計算資源負載預測[J].內蒙古民族大學學報(自然科學版),2023,38(04):315-321.
[2]劉惠,董錫耀,楊志涵.融合Stacking框架的BiGRU-LGB云負載預測模型[J].西安電子科技大學學報(自然科學版), 2023,50(03):83-94,104.
[3]林濤,馮競凱,郝章肖,等.基于組合預測模型的云計算資源負載預測研究[J].計算機工程與科學,2020,42(07):1168-1173.
[4]徐達宇,丁帥.改進GWO優化SVM的云計算資源負載短期預測研究[J].計算機工程與應用,2017,53(07):68-73.
[5]楊哲興,謝曉蘭,李水旺.基于VDM-ISSA-LSSVM的云資源短期負載預測模型[J].實驗室研究與探索,2023,42(06):117-124.
[6]李英豪,郭昊龔,劉盼盼,等.基于時間卷積網絡的云平臺負載預測方法[J].計算機科學,2023,50(07):254-260.
[7]李浩陽,賀小偉,王賓,等.基于改進Informer的云計算資源負載預測[J].計算機工程,2024,50(02):43-50.
[8]王萍,付曉聰,許海洋.云計算中基于負載預測的虛擬資源調度策略[J].青島農業大學學報(自然科學版),2020,37(01):73-78.
猜你喜歡
數字技術與應用(2016年9期)2016-11-09 22:56:18
數字技術與應用(2016年9期)2016-11-09 00:07:05
知音勵志·社科版(2016年8期)2016-11-05 04:28:47
電腦知識與技術(2016年21期)2016-10-18 23:34:52
電腦知識與技術(2016年21期)2016-10-18 23:24:44
電腦知識與技術(2016年21期)2016-10-18 22:11:15
科技視界(2016年22期)2016-10-18 14:33:46
中國新通信(2016年16期)2016-10-18 10:49:17
大學教育(2016年9期)2016-10-09 08:54:03
科技視界(2016年20期)2016-09-29 13:34:06
